附录H:科研方法论与论文设计
定位:本附录面向准备从"学习者"转变为"研究者"的读者。前面正文已系统覆盖了大语言模型从基础到前沿的技术知识,本附录提供一套可操作的科研方法论工具箱——从如何选题、如何读论文、如何设计实验,到如何写作和投稿。每一节都以"拿来就能用"为目标,配以 AI/ML 领域的具体示例。
H.1 研究问题拆解:四种选题路径
对于刚刚入门科研的研究生来说,"找不到问题"往往是最大的困扰。这里介绍四种经过验证的选题路径,它们并非互斥,一个好的研究课题常常同时具备多条路径的特征。
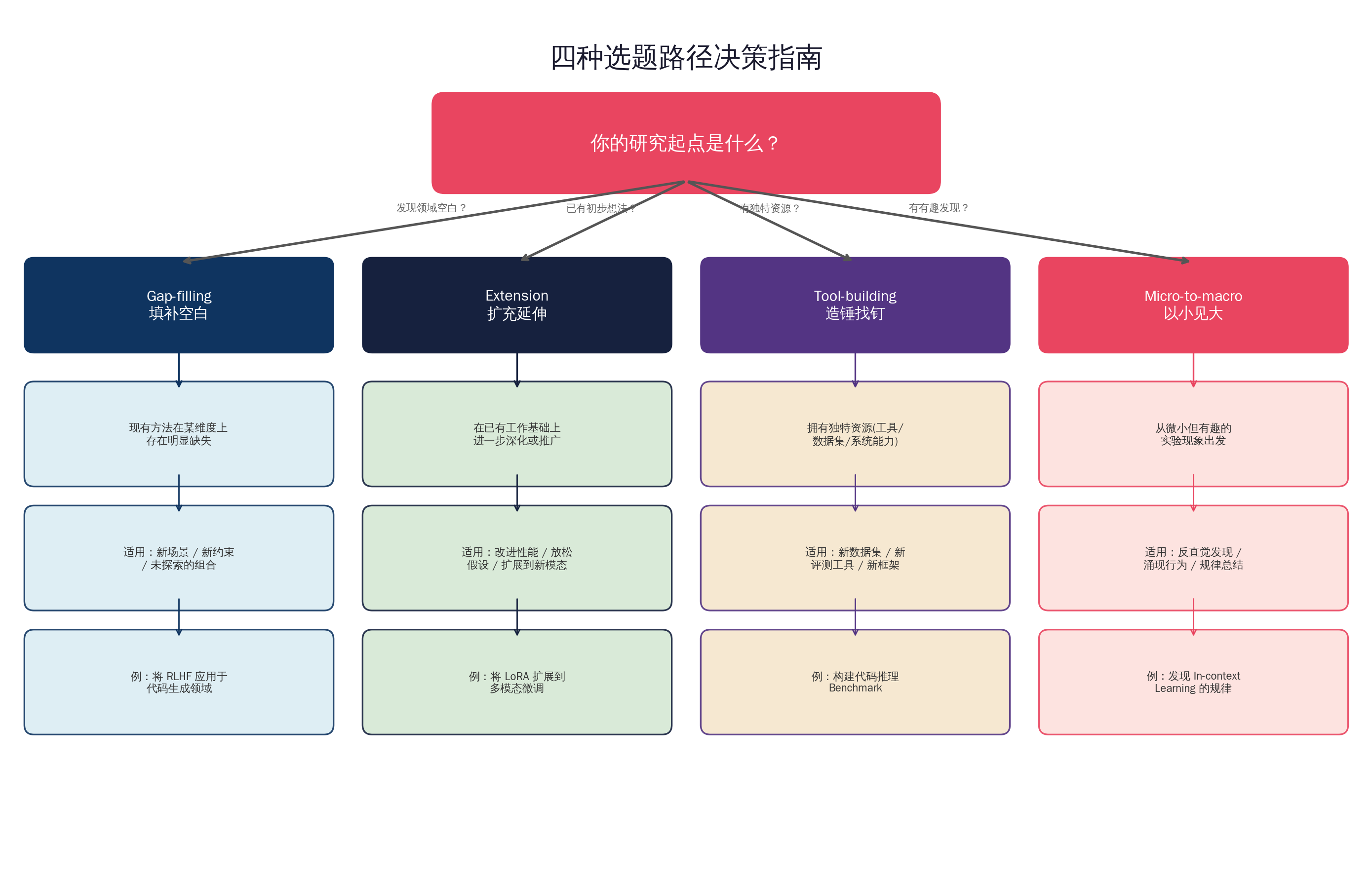
路径一:Gap-filling(填补空白)
核心思路:通过系统阅读文献,记录下已有工作在系统、方法、技术、数据集等方面的前提假设和属性特点,进行维度上的比较,找到其中尚未被涉足或考虑的部分。
操作方法:
- 列出目标领域的代表性工作,为每篇论文标注其核心假设、适用场景、方法特征。
- 构建一个"方法-场景"矩阵,找出空白格。
- 验证空白格是否有实际意义——有些组合之所以没人做,可能是因为没有价值。
AI/ML 示例:2023 年之前,RLHF(人类反馈强化学习)主要应用于通用对话场景。研究者发现在代码生成领域缺乏系统的人类偏好对齐工作,于是提出了针对代码的 RLHF 方法,这就是典型的"方法 + 新领域"的空白填补。
适用情境:你对某个领域已有一定了解,发现"这个方向没人做过",并且能论证"为什么值得做"。
路径二:Extension(扩充延伸)
核心思路:如果已经在某个方向有了一些研究思路,就可以继续顺着这条线深入,看到别人不容易发现的维度。关键在于将自己的思路与不同的领域进行交叉组合,或者抽象前提假设,验证其是否具有普适性。
操作方法:
- 选定你熟悉的一个方法或框架。
- 问自己三个问题:它在更大/更小的规模上是否成立?它在不同模态上是否适用?放松某个假设后会怎样?
- 顺着这些方向做预实验,验证可行性。
AI/ML 示例:LoRA 最初被提出用于单一文本模态的参数高效微调。后续研究者将其扩展到视觉-语言多模态微调(如 VeRA、QLoRA 的多模态变体),这就是典型的扩充延伸。
适用情境:你已有初步想法或前期工作,想"做深做广"。
路径三:Tool-building(造锤找钉)
核心思路:如果你拥有独特的专业知识、系统、甚至数据集,那么可以充分利用它们寻找有趣的问题来解决。这条路径的优势在于你的"锤子"是别人没有的,天然具备差异化竞争力。
操作方法:
- 盘点你手中的独特资源:独有数据集、专业领域知识、系统级开发能力。
- 向社区发出信号:展示你的工具/数据集能解决什么问题。
- 让社区的反馈帮助你定义最有价值的研究方向。
AI/ML 示例:HumanEval、MBPP 等代码评测基准的提出者并没有提出新的算法,而是构建了一套高质量的评测工具。这些 Benchmark 本身就成为了高影响力的研究工作(回顾 §20 章评估方法中的讨论)。
适用情境:你手中有"别人没有的东西"——数据、平台、或专业领域知识。
路径四:Micro-to-macro(以小见大)
核心思路:从一个微小但有趣的实验现象出发,将这个发现深入研究,确定是否可以构成一个体系化的理论,足以支撑一篇可被发表的论文。
操作方法:
- 在实验中保持好奇心,记录所有"意料之外"的现象。
- 对有趣的现象进行系统化验证:它是否可复现?它是否在不同设置下都存在?
- 尝试给出解释:是否能用理论框架解释这一现象?
AI/ML 示例:In-context Learning 的发现就是典型的以小见大。研究者在使用 GPT-3 时观察到,仅通过在 prompt 中给出少量示例,模型就能完成新任务。这个最初的"有趣现象"后来催生了一系列关于 ICL 机制的理论研究。
适用情境:你在实验中发现了反直觉或新颖的现象,想把它"做成一个完整的故事"。
H.2 文献发现:多层搜索方法
高效的文献发现是科研的基础功。许多初学者只会在 Google Scholar 上搜关键词,这远远不够。下面介绍一套从宏观到微观的多层方法。
第一层:综述文章(Survey)——建立全景视图
目标:快速了解领域全貌、关键问题、主要方法脉络和发展趋势。
在 Google Scholar 或 arXiv 上搜索 "survey" + 你的领域关键词,优先选择近 1-2 年、高引用的综述。综述的价值不仅在于内容本身,更在于它的参考文献列表——这是你下一步精读的起点。
注意:综述往往滞后于领域前沿 6-12 个月。它帮你"入门",但不能替代对最新工作的跟踪。
第二层:Google Scholar 关键词搜索——定位核心论文
目标:找到目标方向的高影响力论文。
使用精确的技术关键词搜索并按引用量排序,善用高级搜索功能指定作者、时间范围和发表场所。Google Scholar 的"被引用"和"相关文章"功能可以帮助你有效扩展搜索范围。
第三层:顶会论文——追踪前沿
目标:掌握领域最新的研究动态。
选择与你研究方向最相关的顶级会议(NeurIPS、ICML、ICLR、ACL、EMNLP、CVPR 等),浏览近 1-2 年的 accepted papers 列表并按关键词筛选。重点关注 Oral/Spotlight 论文——它们代表了审稿人眼中该年度最好的工作。此外,顶会论文的 Related Work 部分本身就是优质的文献索引。
第四层:作者网络——发现隐藏线索
目标:跟踪核心研究者的最新进展。
当你找到一篇高质量论文后,查看作者的个人主页和 Google Scholar 主页,关注他们的最新预印本和正在进行的项目。Follow 活跃研究者的 Twitter/X 账号——许多重要工作在正式发表前就会在社交媒体上预热。同时关注知名研究团队(如 DeepMind、OpenAI、Meta FAIR)的博客和技术报告。
补充渠道
| 渠道 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| arXiv 每日更新 | 最新、最快 | 未经同行评审 | 跟踪前沿进展 |
| Scholar Inbox | AI 推荐、个性化 | 需要一定使用时间才能准确 | 日常文献跟踪 |
| 技术公众号 | 中文、时效性高 | 同质化严重、可能有广告 | 快速了解热点 |
| 技术博客(Medium 等) | 制作精良、深度解读 | 部分需付费 | 深度理解特定论文 |
| Papers with Code | 论文-代码-基准绑定 | 覆盖面有偏 | 查找可复现工作 |
H.3 如何读一篇论文:三遍读法
论文阅读是一项需要训练的技能。Keshav (2007) 提出的"三遍读法"(Three-pass Approach)被广泛采用,这里结合 AI/ML 论文的特点进行改编。
前提条件
有效阅读论文需要两项基础能力:一是英文阅读能力,能够快速浏览并抓取关键词;二是学科知识基础,对相关学科背景及其经典技术有基本了解。建议在开始大量阅读之前,先精读几篇领域内的经典高被引论文,培养科研鉴赏力,了解学科经典方法。
第一遍:速读(5-10 分钟)
目标:快速了解论文的大致内容和定位。
阅读顺序和关注点:
- 标题和摘要:判断论文是否与你的研究相关,以及论文属于什么类型(方法创新、系统设计、实证分析等)。
- Introduction:理解研究背景和动机——解决什么问题?为什么这个问题重要?用一种什么样的方法解决?心里有什么关键发现?
- 图表:好的论文会把核心贡献浓缩在图表中——看图往往比看文字更快理解方法。
- 结论:确认论文的主要声明和自述贡献。
速读后的判断:这篇论文值得精读吗?如果与你的研究高度相关,进入第二遍;否则记录关键信息后放下。
第二遍:精读(1-2 小时)
目标:深入了解论文的技术细节。
段落和首句:每个段落的第一句话往往是该段的中心论点,逐段阅读并标注你不理解的部分。胜利性 vs. 防御性:在实验比较中,论文作者通常会强调自己方法胜出的场景(胜利性表述),同时对表现不佳的场景给出解释(防御性表述),作为读者需要识别这两种表述并客观评估方法的真实表现。比较性阅读:在读方法部分时,对照该论文引用的 baseline 方法,理解"新在哪里"。记录问题:把不理解的符号、存疑的假设、想进一步探索的方向记录下来。
第三遍:摘抄与重构(选做)
目标:储备好词好句,提升写作能力,深度内化论文内容。
摘录好句:分类整理不同场景下的学术表达句式(过渡句、递进句、对比句等),优秀的华人学者的论文文风朴实、逻辑清晰,非常适合模仿学习。逻辑重构:尝试用自己的话重新表述论文的核心贡献和方法——如果你能清晰地向别人解释,说明你真正理解了。批判性笔记:记录论文的局限性、隐含假设、以及可能的改进方向,这些往往是你自己研究问题的来源。
H.4 论文设计心法
从"有了 idea"到"写出好论文"之间,存在一系列设计决策。以下心法来源于审稿人视角和论文设计经验,帮助你避开常见陷阱。
心法一:排名优于绝对分数
在陈述模型表现时,单纯的绝对分数可能难以说明问题。排名(Ranking)往往更有说服力,因为它天然提供了相对参照。
反面示例:我们的方法在 HumanEval 上达到了 67.3% 的 pass@1。
正面示例:在 2024 年 CCPC 决赛的 13 道题目中,o4-mini-high 仅解决了 1 道,排名在 121 支人类队伍中位列第 118 名。
排名提供了丰富的上下文信息:读者无需了解绝对分数的"好坏标准",就能直观理解模型的相对水平。
心法二:跨学科理论借鉴
讲一个好故事往往需要从其他学科借鉴成熟的理论框架。大语言模型领域有很多跨学科借鉴的成功案例:
例如,MemGPT 借鉴了操作系统的虚拟内存层级(缓存-内存-外存)来管理 LLM 的上下文窗口限制;一些 Long-term Memory 工作借鉴了心理学中的艾宾浩斯遗忘曲线,为模型记忆的优先级和衰减提供理论支撑;多智能体交互的工作常借鉴经济学中的纳什均衡和机制设计理论;Transformer 的注意力机制本身就借鉴了神经科学中人类认知的选择性注意理论。
跨学科借鉴不仅能让你的"故事"更有深度,还可能启发出全新的方法设计。
心法三:复杂公式必须消融验证
原则:如果你把公式搞得很复杂,就必须证明简单的方法行不通。
这是审稿人的核心关注点之一。一个包含多个乘法项或加权项的复杂损失函数,必须配以完整的消融实验(Ablation Study),逐项验证每个组件的必要性。如果去掉某个复杂项后性能几乎不变,审稿人会质疑你的方法设计是否合理。
实操建议: 先用最简单的方法建立 baseline,然后每次只添加一个新组件并记录性能变化,最后在论文中以消融表的形式呈现,让读者清晰看到每个设计选择的贡献。
心法四:避免子集陷阱(Subset Trap)
问题:你在某个特定子问题上做得很深,但这个子问题可能只是已有工作的一个特例。虽然你在这一个子集上做得更深,但如果没有强有力的理由说明为什么这个子集值得单独写一篇论文,审稿人会认为这是退步而非进步。
避免方法: 明确论证你的子问题为什么具有独立的研究价值,并展示在更广泛的场景下,专注子问题带来的洞见是通用方法无法给出的。如果无法有效论证,考虑将范围扩大到覆盖更一般的问题。
心法五:需要有信息熵——Insight 驱动
核心标准:一篇好的论文需要有"信息熵",而不是看完标题就知道结论。独特性通常伴随着反直觉的发现或新的洞察。
一个合格的 Idea 的逻辑结构应当包含:
- Idea 的背景——为什么这个问题重要?
- 一个具体的研究问题。
- 别人是怎么做的?别人的方法存在什么问题?为什么会出现这些问题?
- 你发现了什么新的现象或信息,并利用这一现象提出了新的方法来避免前人的问题——这就是 Insight。
- 你的方法面临的真正挑战是什么?你提出的具体设计是什么?
审稿人评判标准:从重要性依次排列为——(1) 研究的问题是否重要且困难;(2) 实验是否有说服力,是否能证明在实际场景中解决了问题;(3) 方法是否优雅且有创造性;(4) 深入分析和特色部分是否让工作更完整。
心法六:论文写作 ≠ 科研逻辑
科研的逻辑是逐个解决新的困难,不断迭代形成一个扎实工作的过程——先提出 idea,实现 idea,遇到困难,解决困难,循环往复。但论文写作的逻辑不同:它需要顶层设计,从已经有了全部答案的角度出发,逐个介绍每处细节,重点是告诉读者其动机和意义。
两条核心写作原则: 原则一:不断提醒读者当前阅读的部分在整体框架中的位置和作用。原则二:一次只给读者提供一个新的信息,在两个信息之间要有过渡。
科学的表达应该是简单且有趣的——假设你的读者是一个普通的计算机本科生,没有专门搞过你这个细分领域。如果他能看懂你的论文,说明你写得足够清晰。
H.5 Benchmark 与指标设计
好的 Benchmark 和评测指标是推动领域进步的基础设施。不少高影响力的工作本身就是 Benchmark 论文(如 GLUE、SuperGLUE、MMLU、HumanEval 等)。
需求驱动的指标设计思路
与其直接寻找复杂的花里胡哨的数学公式,不如从需求出发来驱动设计过程。具体流程如下:
第一步:明确需求——当你设计某种类型或具有某种特征的任务时,先明确这个任务需要一个什么样的评测指标。例如,如果你的任务是开放式文本生成,你需要一个能同时衡量质量和多样性的指标。
第二步:推导性质——思考这个指标需要满足什么样的数学性质。例如: 是否需要对称性(A 和 B 的相似度 = B 和 A 的相似度)?是否需要有界性(取值在 [0, 1] 之间)?是否需要满足三角不等式?对极端情况(空输出、完全复制输入等)应如何处理?
第三步:数学实例化——在明确了性质要求后,再去寻找一个符合这些要求的数学公式。这样就形成了一个从一般到特殊、由需求驱动的设计思路。通过这种方式,整个设计过程会更加合理且有理论支撑,而非为了复杂而复杂。
Benchmark 设计的实践要点
| 维度 | 关键问题 | 常见陷阱 |
|---|---|---|
| 覆盖性 | 是否覆盖了目标能力的各个方面? | 只测试简单场景,忽略边界和困难情况 |
| 区分度 | 不同水平的模型能否被有效区分? | 任务过于简单,所有模型都能拿满分 |
| 公平性 | 是否对所有方法一视同仁? | 评测指标偏向某一类方法 |
| 可复现性 | 他人能否完全复现你的评测? | 数据预处理步骤不明确 |
| 时效性 | 是否考虑了数据污染问题? | 测试集可能已出现在训练语料中 |
H.6 投稿检查清单
以下是经过实战检验的 11 维投稿检查清单。建议在投稿前 48 小时开始逐项核对,不要留到最后一刻。
1. 格式与排版
- [ ] 使用官方 LaTeX/Word 模板(NeurIPS/ICLR/CVPR/ACL 等各有要求)
- [ ] 页数、字数、单栏/双栏符合要求(不超页)
- [ ] 字体、行距、页边距完全符合规范
- [ ] 没有 "overfull hbox" 或文字溢出警告
- [ ] 所有图片/图表清晰,分辨率 ≥ 300 dpi
- [ ] 图表在黑白/灰度模式下仍然可辨识
- [ ] 表格对齐良好,避免跨页或过宽单元格
- [ ] 页码、作者信息处理正确(按匿名要求删除)
- [ ] 文件大小未超过提交系统限制(一般 ≤ 10MB)
2. 匿名性(Double-blind Review)
- [ ] 删除作者姓名、机构、邮件
- [ ] 引用自己论文时使用中性表述(如 "prior work [X]")
- [ ] 补充材料、代码链接不包含个人信息
- [ ] GitHub 仓库做匿名化处理(匿名仓库或第三方平台),注意 README 中不要链回原始账号
- [ ] 避免暗示机构、合作方或实验室内部项目
3. 论文内容完整性
- [ ] 标题简洁准确,避免过长
- [ ] 摘要清晰陈述问题、方法、贡献和结果
- [ ] 引言包含研究动机、挑战、研究问题和贡献点
- [ ] 相关工作覆盖最新文献(包括本年度顶会/顶刊和 arXiv 热点)
- [ ] 方法部分符号定义清晰、公式推导无误、流程图完整
- [ ] 实验部分设置合理,包含充分的 baseline 对比
- [ ] 结果部分有对比分析和讨论
- [ ] 结论总结贡献与局限,并指出未来方向
4. 实验复现性
- [ ] 提供代码或伪代码描述核心算法
- [ ] 提供匿名开源代码链接(强烈建议)
- [ ] 固定随机种子,保证结果可重复
- [ ] 说明训练时间、GPU 数量、计算资源消耗
- [ ] 提供公开数据集下载方式;若用私有数据,需说明获取途径
5. 语言与写作
- [ ] 全文无语法错误,无中式英语
- [ ] 段落衔接自然,逻辑顺畅
- [ ] 图表 caption 独立可读(即使不看正文也能理解图表含义)
- [ ] 符号/缩写首次出现时给出定义
- [ ] 避免过度形容词,保持学术风格
- [ ] 拼写检查通过(推荐使用 Grammarly 或 LaTeX linter)
6. 引用与参考文献
- [ ] 格式严格符合会议要求(BibTeX 样式正确)
- [ ] 文献条目完整:作者、年份、标题、会议/期刊、DOI/arXiv 号
- [ ] 避免重复引用、幻觉引用(AI 生成的虚假引用)
- [ ] 相关工作引用足够新(≤ 2 年的研究应被充分覆盖)
- [ ] 引用范围平衡:不只引用自己或小圈子论文
7. 附录与补充材料
- [ ] 附录内容不包含作者信息
- [ ] 额外实验、证明、伪代码、消融实验补充完整
- [ ] 数据预处理步骤、额外可视化结果齐备
- [ ] 确认补充材料文件大小符合提交系统要求
8. 代码与数据提交
- [ ] 代码已上传至匿名仓库,运行无报错
- [ ] 提供 README,包含依赖、运行方法、参数说明
- [ ] 提供最小可运行示例(Minimal Reproducible Example)
- [ ] 若涉及大规模数据集,给出下载链接或清楚说明
- [ ] 确认不含个人信息、隐私数据或公司内部机密
9. 伦理与合规性
- [ ] 检查是否涉及敏感数据(医疗、隐私、人类受试者)
- [ ] 如有必要,添加 Ethics Statement(部分会议强制要求)
- [ ] 确认不违反版权(数据、代码、图片)
- [ ] 遵守数据集许可协议(如 CC-BY、MIT License)
- [ ] 如果使用大模型或众包标注,明确说明来源与合规性
- [ ] 注明 LLM 使用情况(部分会议要求)
10. 提交流程
- [ ] 确认截止日期和时区(通常是 Anywhere on Earth, AoE,即北京时间 +1 天的 20:00)
- [ ] 检查提交系统(CMT/OpenReview/EasyChair)是否可正常上传
- [ ] 上传 PDF 后下载检查(防止编译错误或缺失字体)
- [ ] 确认元信息(标题、作者、关键词)与 PDF 一致
- [ ] 确认 Track/Submission Type 选择正确
11. 最终自检
- [ ] 主文档(PDF)已准备就绪
- [ ] 附录(Supplementary PDF/ZIP)格式正确(ICLR 合并在一起,NeurIPS 分开提交)
- [ ] 源码与数据已上传
- [ ] 以上所有匿名化、格式、语法检查均已通过
- [ ] 最后通读一遍,确认无遗漏
经验之谈:第一次投稿的常见失误不是方法不行,而是格式错误、超页、忘记匿名化、或者补充材料中泄露了身份信息。这些"低级错误"完全可以通过检查清单避免。
H.7 深度进阶三阶段
科研深度的提升是一个渐进过程。下面描述三个典型阶段,帮助你认清自己所在的位置,并明确下一步的成长方向。
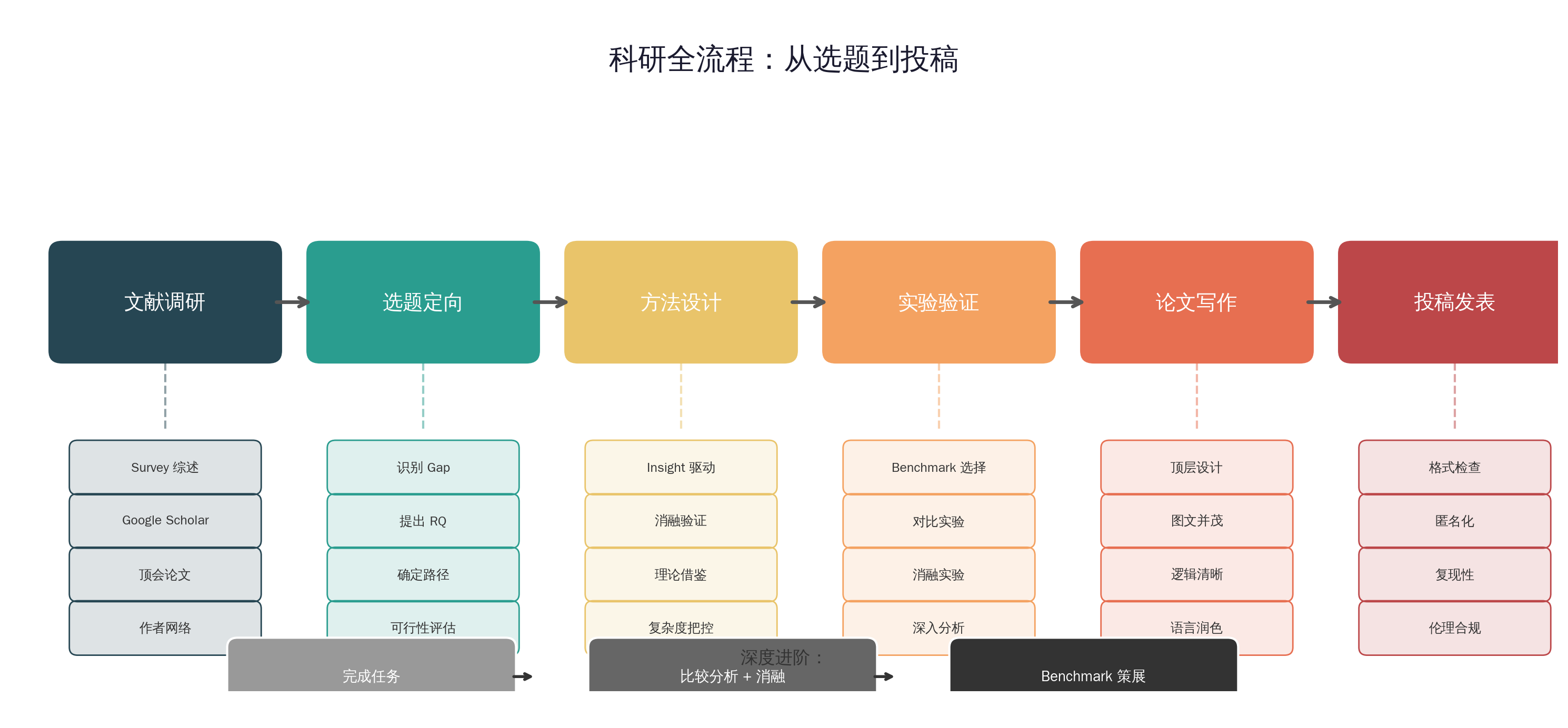
第一阶段:完成任务——"解题者"
特征:拿到一个任务(课程项目、导师交代的工作),用现有工具把它做完。
这个阶段的典型表现是:用 GPT 或现有框架完成任务,自己只做少量微调。结果虽然能跑,但感觉过于"水"——如果要讲述你做了什么,你只能说"我实现了 XX 的细节",而不是"我尝试了 XX 方法并发现了 XX"。
核心问题:你的逻辑是"完成某个东西",而不是"把这个东西做好"。
如何突破:开始思考"具体问题具体分析"——面对一个任务时,不要只想到一种实现方式,而是考虑多种方案并比较它们的优劣。
第二阶段:比较分析 + 消融——"分析者"
特征:在做每一个决策时,考虑多种实现方向,分析不同方向带来的不同效果,形成有理有据的技术叙事。
这个阶段的典型表述是:"我们在做 XX 时,尝试了方向 A 与方向 B,发现 A 方向效果更好,因为 XX;我们推测原因是 XX,然后分析了 A 与 B 的 XX 指标,证实了我们的判断/提出了新的主张 C……"
操作方法:
- 对于每个设计决策,列出至少 2-3 种可选方案。
- 对每种方案进行实验对比,记录量化结果。
- 不仅记录"哪个更好",更要分析"为什么更好"。
- 利用文献检索工具(如结合 Obsidian 和 LLM 推荐)反复检索 2-3 次,快速洞察相关领域的全貌。
结果:你可以自信地和别人讨论某个方向的细节,因为你真正做过比较研究。这就是大多数人做出的"增量"工作的水平。
第三阶段:Benchmark 策展——"出题者"
特征:不仅能"做事",更能"定义什么是好事"——你开始设计评测标准,塑造 Benchmark。
这个阶段需要回答两个核心问题:
- 我们最终要提升什么指标?——如果现有指标不能准确衡量你关心的能力,你需要自己设计指标。
- 如何产出一个高质量的产出报告?——报告本身的质量也需要"指标"来衡量。
Benchmark 策展方法:
- 初始化:从以下角度构建指标体系(按重要性排序)——(1) 基于给定需求塑造;(2) 参考以往相关工作;(3) 自己和团队的补充;(4) 利用 LLM 辅助生成候选指标。
- 迭代:初始化指标后,只需做两件事——(1) 针对性"打榜",优化已有指标;(2) 在实践中不断补充新的指标。
身份转变:从"做卷人"(解题者)到"出卷人"(出题者),你的思考深度和研究视野会发生质的飞跃。
H.8 论文写作工具推荐
最后,分享一些实用的论文写作辅助工具,帮助你提高效率。
文献管理与调研
| 工具 | 用途 |
|---|---|
| Zotero + ZotFile + Better BibTeX | 文献管理、PDF 整理、BibTeX 导出的标准组合 |
| Google Scholar | 文献搜索和引用追踪 |
| Scholar Inbox (scholar-inbox.com) | 基于 AI 的个性化论文推荐 |
| Papers.cool | 论文浏览与发现 |
| Connected Papers | 可视化论文引用关系图 |
写作与润色
| 工具 | 用途 |
|---|---|
| Overleaf | 在线 LaTeX 协作编辑 |
| Grammarly | 英文语法检查 |
| AI 辅助写作 | 润色语言表达(注意:需声明 LLM 使用情况) |
绘图与可视化
| 工具 | 用途 |
|---|---|
| Matplotlib / Seaborn | Python 绘图(学术论文标准工具) |
| TikZ / PGFPlots | LaTeX 原生绘图 |
| draw.io | 流程图与架构图 |
| 颜色选择器 (htmlcolorcodes.com, colorkit.co) | 选择论文配色方案 |
审稿与评审
| 工具 | 用途 |
|---|---|
| PaperReview.ai | AI 辅助预审稿 |
| CSPaper.org | 计算机科学论文索引 |
提醒:工具只是手段,科研的核心竞争力始终是你的研究问题、方法设计和实验洞察。不要把时间花在工具上而忽视了内容本身。
H.9 本附录小结
科研是一项系统工程。本附录梳理了从选题到投稿的完整方法论:
- 选题有四条路径——填补空白、扩充延伸、造锤找钉、以小见大——根据你的起点选择最合适的路径。
- 文献发现采用多层搜索——从综述的全景视图到作者网络的精准追踪,层层递进。
- 论文阅读遵循三遍读法——速读定方向、精读抓细节、摘抄练写作。
- 论文设计需要心法——排名优于分数、跨学科借鉴、复杂公式需消融验证、避免子集陷阱、Insight 驱动。
- Benchmark/指标设计从需求出发——需求驱动 → 性质推导 → 数学实例化。
- 投稿前用 11 维检查清单逐项核对——大多数投稿失败不是因为方法不行,而是因为可以避免的"低级错误"。
- 深度进阶分三个阶段——从"解题者"到"分析者"再到"出题者",你的身份转变标志着研究能力的质变。
这些方法论不是空中楼阁,而是可以立即运用到你的下一篇论文中的实操指南。祝你在科研道路上走得又深又远。