7.5 Tiny Aya:多语言与并行 Transformer 块
前几节介绍的 Llama、Qwen3 和 Gemma 3 虽然在注意力策略和前馈网络上各有创新,但它们的 Transformer 块内部都遵循同一种串行布局:先计算注意力、加残差,再计算 MLP、加残差——两个子层前后依赖,无法重叠执行。Cohere 发布的 Tiny Aya 3.35B 打破了这一惯例,采用并行 Transformer 块(Parallel Transformer Block),将注意力和 MLP 从同一份归一化输入并行计算,一步合并到残差流中。与此同时,Tiny Aya 作为当前 3B 量级最强的多语言开放模型,覆盖超过 60 种语言,并在滑动窗口注意力、LayerNorm 选型等方面做出了与主流趋势不同的设计决策。
本节将以 Tiny Aya 3.35B 为对象,重点解析并行 Transformer 块的原理与代码实现,分析其与串行块的结构差异,并梳理 3:1 SWA 混合、LayerNorm 等架构特色。
图 7-17:Tiny Aya 的多语言覆盖体系。围绕亚太、非洲、南亚、欧洲、西亚五大区域推出特化模型,所有变体共享同一架构。
7.5.1 多语言覆盖:60+ 种语言的区域化模型
Tiny Aya 由 Cohere 实验室推出,定位为 3B 参数量级中多语言能力最强的开放权重模型,在多语言基准上超越了 Qwen3-4B、Gemma 3 4B 和 Ministral 3 3B。其核心特色是围绕区域化设计了一系列变体:
| 区域 | 覆盖语言 | 优化模型 |
|---|---|---|
| 亚太 | 繁体中文、粤语、越南语、塔加洛语、爪哇语、高棉语、泰语、缅甸语、马来语、韩语、老挝语、印尼语、简体中文、日语 | tiny-aya-water |
| 非洲 | 祖鲁语、阿姆哈拉语、豪萨语、伊博语、斯瓦希里语、科萨语、沃洛夫语、绍纳语、约鲁巴语、尼日利亚皮钦语、马尔加什语 | tiny-aya-earth |
| 南亚 | 泰卢固语、马拉地语、孟加拉语、泰米尔语、印地语、旁遮普语、古吉拉特语、乌尔都语、尼泊尔语 | tiny-aya-fire |
| 欧洲 | 加泰罗尼亚语、加利西亚语、荷兰语、丹麦语、芬兰语、捷克语、葡萄牙语、法语、立陶宛语、斯洛伐克语、巴斯克语、英语、瑞典语、波兰语、西班牙语、斯洛文尼亚语、乌克兰语、希腊语、挪威语、罗马尼亚语、塞尔维亚语、德语、意大利语、俄语、爱尔兰语、匈牙利语、保加利亚语、克罗地亚语、爱沙尼亚语、拉脱维亚语、威尔士语 | tiny-aya-water |
| 西亚 | 阿拉伯语、马耳他语、土耳其语、希伯来语、波斯语 | tiny-aya-earth |
表 7-6:Tiny Aya 区域化模型与语言覆盖。
除了上述区域特化版本,还提供 tiny-aya-global(全球均衡版本)和 tiny-aya-base(基础版本)。所有变体共享同一套模型架构,仅在训练数据配比上有所不同。
7.5.2 并行 Transformer 块:核心创新
标准的串行 Transformer 块(如 Llama、Qwen3、Gemma 3 所用)执行如下计算流程:
注意力的输出先加回残差流得到
Tiny Aya 采用的并行 Transformer 块将这一流程改为:
注意力和 MLP 从同一份归一化输出
串行 vs. 并行:代码对比。 以下代码直接展示两种布局的结构差异:
# ===== 串行 Transformer 块(Llama/Qwen3/Gemma 3 等) =====
class SerialTransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = GroupedQueryAttention(cfg)
self.ff = FeedForward(cfg)
self.norm1 = RMSNorm(cfg["emb_dim"])
self.norm2 = RMSNorm(cfg["emb_dim"])
def forward(self, x, mask, cos, sin):
# 第一步:注意力 + 残差
shortcut = x
x = self.norm1(x)
x = self.att(x, mask, cos, sin)
x = x + shortcut
# 第二步:MLP + 残差(必须等第一步完成)
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = x + shortcut
return x
# ===== 并行 Transformer 块(Tiny Aya) =====
class ParallelTransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = GroupedQueryAttention(cfg)
self.ff = FeedForward(cfg)
self.norm = CohereLayerNorm(cfg["emb_dim"]) # 只需一个归一化层
def forward(self, x, mask, cos, sin):
shortcut = x
h = self.norm(x) # 共享归一化输入
x_attn = self.att(h, mask, cos, sin) # 路径 A:注意力
x_ff = self.ff(h) # 路径 B:MLP
x = shortcut + x_attn + x_ff # 一步合并
return x对比两段代码可以看出三个关键差异:
- 归一化层数量:串行块需要两个归一化层(注意力前一个、MLP 前一个),并行块只需一个——因为两个子层共享同一份归一化输出。
- 残差加法次数:串行块执行两次残差加法,并行块合并为一次。
- 数据依赖关系:串行块中 MLP 的输入
依赖注意力的输出,形成顺序依赖链;并行块中两条路径完全独立,理论上可以在硬件层面同步执行。
7.5.3 并行块的效率优势与代价
为什么并行块更快? 在 GPU 执行模型中,串行块的两个子层构成一条依赖链:注意力的所有 CUDA kernel 必须执行完毕,其输出写回全局内存后,MLP 的 kernel 才能启动。这意味着两个子层的延迟是累加的。并行块消除了这一依赖——注意力和 MLP 的 kernel 可以被调度器重叠执行(在多 SM 的 GPU 上),或者至少减少了中间同步点的开销。即使在实际执行中未能完全重叠,减少一次归一化计算和一次残差加法本身也带来了确定性的计算节省。
代价是什么? 并行块的 MLP 看不到注意力的输出——它只能基于归一化后的原始输入进行计算。在串行块中,MLP 的输入已经融合了注意力层提取的上下文信息,理论上具有更强的表达能力。并行布局牺牲了这一层间交互,换取计算效率。实践表明,在足够深的网络中(Tiny Aya 有 36 层),这种单层内的信息损失可以通过跨层传播来弥补,对最终模型质量的影响有限。
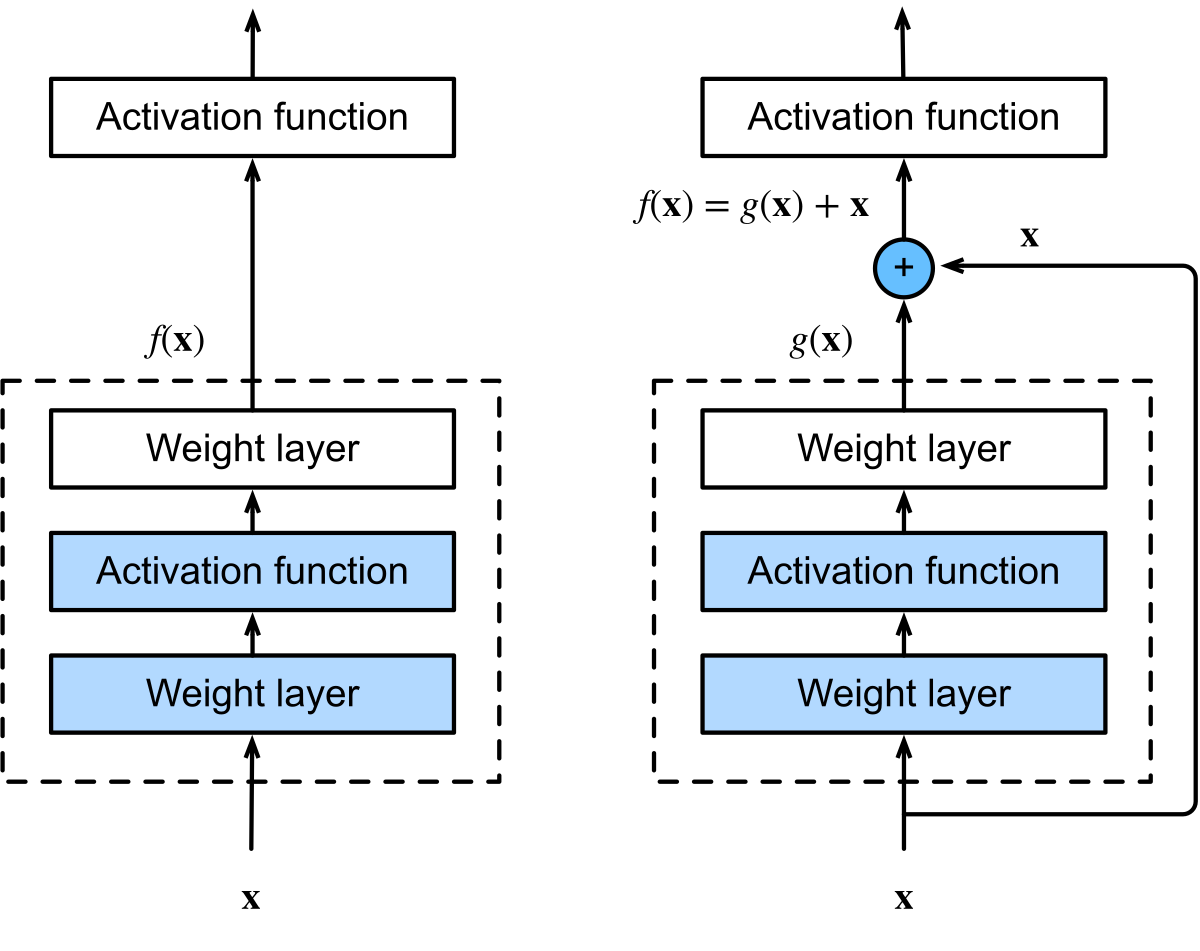
图 7-18:并行 Transformer 块与串行 Transformer 块的结构对比。串行块中注意力和 MLP 依次执行,并行块中两者从同一输入并行计算后合并。
GPT-J 和 PaLM 等早期模型已经验证了并行块在大规模训练中的可行性。Tiny Aya 延续了这一设计。
7.5.4 3:1 滑动窗口混合注意力
与 §7.3 介绍的 Gemma 3(5:1 比例)类似,Tiny Aya 也采用滑动窗口注意力(SWA)与全局注意力(Full Attention)的混合策略,但比例为 3:1——每 4 层中有 3 层使用滑动窗口、1 层使用全局注意力。36 层的具体排列为:
层 0–2: sliding, sliding, sliding
层 3: full_attention
层 4–6: sliding, sliding, sliding
层 7: full_attention
...(重复 9 组)36 层中有 27 层滑动窗口、9 层全局注意力。滑动窗口大小为 4096,远大于 Gemma 3 的 512。
RoPE 的选择性应用。 Tiny Aya 的一个独特设计是:滑动窗口层使用 RoPE,全局注意力层不使用任何位置编码(NoPE)。这与 Gemma 3(两种层都用 RoPE,但基频不同)和 Llama(所有层统一 RoPE)都不同。NoPE 的理由是:全局注意力层负责整合远距离信息,去除位置编码后,注意力分数完全由内容相似度决定,不受位置偏置的干扰,更有利于捕获与位置无关的语义关联。局部层则保留 RoPE 以编码精确的相对位置信息,满足语法、搭配等局部依赖的需求。
# 在 GroupedQueryAttention.forward 中
if self.attn_type == "sliding_attention":
queries = apply_rope(queries, cos, sin)
keys = apply_rope(keys, cos, sin)
# 全局注意力层:不应用 RoPE7.5.5 CohereLayerNorm:回归 LayerNorm
当前主流 LLM 几乎一致采用 RMSNorm(Llama、Qwen3、Gemma 3 均如此),原因是 RMSNorm 省去了均值计算步骤,计算量更小且性能相当。Tiny Aya 逆势选择了 LayerNorm 的一个变体——无偏置 LayerNorm:
class CohereLayerNorm(nn.Module):
def __init__(self, emb_dim, eps=1e-5):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(emb_dim))
def forward(self, x):
input_dtype = x.dtype
x = x.to(torch.float32)
mean = x.mean(dim=-1, keepdim=True)
variance = (x - mean).pow(2).mean(dim=-1, keepdim=True)
x = (x - mean) * torch.rsqrt(variance + self.eps)
return (self.weight.to(torch.float32) * x).to(input_dtype)与标准 LayerNorm 的区别是去掉了偏置参数 shift),与 Llama 系列的"移除所有偏置项"原则一致。与 RMSNorm 相比,CohereLayerNorm 保留了减均值步骤——先计算 mean,再计算 (x - mean) 的方差,而 RMSNorm 直接计算 x.pow(2).mean()。三者的关系可以用公式概括:
| 归一化方法 | 公式 | 参数 |
|---|---|---|
| LayerNorm | ||
| CohereLayerNorm | ||
| RMSNorm |
Tiny Aya 选择保留减均值步骤的可能原因是:在多语言场景中,不同语言的 token 嵌入分布可能存在较大的均值偏移(mean shift),减均值操作有助于将不同语言的特征拉回同一基准线,提升跨语言的归一化一致性。不过这一额外的均值计算仅增加了极少的开销——在并行块减少了一个归一化层的背景下,总归一化成本甚至低于使用两个 RMSNorm 的串行块。
7.5.6 完整模型配置
图 7-19:Tiny Aya 在多语言基准上的性能雷达图。不同区域化模型在各自目标语言上展现出显著优势,体现了"一套架构、多套数据"的区域化策略。
Tiny Aya 3.35B 的完整配置如下:
TINY_AYA_CONFIG = {
"vocab_size": 262_144, # 256K 词表
"context_length": 500_000, # 最大上下文长度
"emb_dim": 2048, # 嵌入维度
"n_heads": 16, # 查询头数
"n_layers": 36, # Transformer 层数
"hidden_dim": 11_008, # FFN 中间维度
"head_dim": 128, # 每头维度
"n_kv_heads": 4, # KV 头数(GQA:16/4 = 每组 4 个查询头)
"attention_bias": False, # 注意力投影无偏置
"sliding_window": 4096, # 滑动窗口大小
"layer_types": [ # 3:1 SWA:Full 混合
"sliding_attention", "sliding_attention", "sliding_attention",
"full_attention",
# ... 每 4 层重复一次,共 9 组
],
"rope_base": 50_000.0, # RoPE 基频
"layer_norm_eps": 1e-5, # LayerNorm epsilon
"tie_word_embeddings": True, # 权重绑定
"dtype": torch.bfloat16,
}几个值得关注的配置细节:
词表 262,144(256K)。 与 Gemma 3 相同,远大于 Llama 3 的 128K 和 Qwen3 的 152K。超大词表对多语言模型尤为关键——60+ 种语言中有大量非拉丁字母(阿拉伯文、天城文、缅甸文、埃塞俄比亚文等),更大的词表能为这些文字系统提供更高效的编码,减少 token 数量。
GQA 配置:16 头查询 / 4 头 KV。 每组 4 个查询头共享 1 组 KV,压缩比为 4:1,与 Llama 3 8B 的配置一致。
权重绑定(Weight Tying)。 输入嵌入层和输出投影头共享权重。嵌入矩阵大小为
RoPE 基频 50,000。 介于 Llama 2 的 10,000 和 Llama 3 的 500,000 之间,是一个相对保守的选择。
7.5.7 完整模型实现
将并行 Transformer 块、混合注意力和 CohereLayerNorm 组装为完整模型:
class TransformerBlock(nn.Module):
def __init__(self, cfg, attn_type):
super().__init__()
self.attn_type = attn_type
self.att = GroupedQueryAttention(
d_in=cfg["emb_dim"],
num_heads=cfg["n_heads"],
num_kv_groups=cfg["n_kv_heads"],
head_dim=cfg["head_dim"],
attention_bias=cfg["attention_bias"],
dtype=cfg["dtype"],
attn_type=attn_type,
)
self.ff = FeedForward(cfg)
self.input_layernorm = CohereLayerNorm(
cfg["emb_dim"], eps=cfg["layer_norm_eps"]
)
def forward(self, x, mask_global, mask_local, cos, sin):
attn_mask = mask_local if self.attn_type == "sliding_attention" else mask_global
shortcut = x
x = self.input_layernorm(x)
x_attn = self.att(x, attn_mask, cos, sin)
x_ff = self.ff(x)
x = shortcut + x_attn + x_ff # 并行残差合并
return x
class TinyAyaModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.cfg = cfg
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"])
# 按 layer_types 列表创建异构 Transformer 块
self.trf_blocks = nn.ModuleList([
TransformerBlock(cfg, t) for t in cfg["layer_types"]
])
self.final_norm = CohereLayerNorm(cfg["emb_dim"], eps=cfg["layer_norm_eps"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False, dtype=cfg["dtype"]
)
cos, sin = compute_rope_params(
head_dim=cfg["head_dim"],
theta_base=cfg["rope_base"],
context_length=cfg["context_length"],
)
self.register_buffer("cos", cos, persistent=False)
self.register_buffer("sin", sin, persistent=False)
if cfg["tie_word_embeddings"]:
self.out_head.weight = self.tok_emb.weight
def forward(self, input_ids):
x = self.tok_emb(input_ids)
num_tokens = input_ids.shape[1]
mask_global, mask_local = self.create_masks(num_tokens, x.device)
for block in self.trf_blocks:
x = block(x, mask_global, mask_local, self.cos, self.sin)
x = self.final_norm(x)
return self.out_head(x.to(self.cfg["dtype"]))注意 TransformerBlock 的 forward 方法仅有 5 行有效代码——一次归一化、两次并行子层计算、一次残差合并。与串行块相比,代码更简洁,数据流更清晰。
7.5.8 与同章其他模型的对比
下表从并行块、注意力混合、归一化、位置编码四个维度对比 Tiny Aya 与本章已介绍的模型:
| 特性 | Llama 3 | Qwen3 | Gemma 3 | Tiny Aya |
|---|---|---|---|---|
| Transformer 块布局 | 串行 | 串行 | 串行 | 并行 |
| 归一化层 / 块 | 2 个 RMSNorm | 2 个 RMSNorm | 4 个 RMSNorm | 1 个 LayerNorm |
| 归一化类型 | RMSNorm | RMSNorm | RMSNorm(零中心) | 无偏置 LayerNorm |
| SWA:Full 比例 | 无(全 Full) | 无(全 Full) | 5:1 | 3:1 |
| 滑动窗口大小 | — | — | 512 | 4096 |
| SWA 层 RoPE | — | — | RoPE( | RoPE( |
| Full 层 RoPE | RoPE( | RoPE( | RoPE( | NoPE(无位置编码) |
| QK 归一化 | 无 | QKNorm (RMSNorm) | QKNorm (RMSNorm) | 无 |
| FFN 类型 | SwiGLU | SwiGLU | GeGLU | SwiGLU |
| 词表大小 | 128K | 152K | 256K | 256K |
| 多语言覆盖 | 30+ 种 | 100+ 种 | 100+ 种 | 60+ 种(区域特化) |
表 7-7:本章模型架构对比。
Tiny Aya 最突出的两个差异点是并行 Transformer 块和全局注意力层的 NoPE 设计,前者减少了层内串行依赖,后者在全局层中完全移除了位置编码。
图 7-20:Tiny Aya 的并行 Transformer 块。注意力和 MLP 从同一份归一化输入并行计算,一步合并到残差流中,减少了层内串行依赖。
本节小结
本节以 Tiny Aya 3.35B 为案例,解析了并行 Transformer 块的设计原理和完整实现:
- 并行 Transformer 块:注意力和 MLP 从同一份归一化输入出发并行计算,一步合并到残差流。相比串行块,减少了一个归一化层、一次残差加法和层间数据依赖,在深层网络中(36 层)对模型质量的影响有限,但带来了确定性的计算效率提升。
- 3:1 混合注意力:36 层中 27 层使用滑动窗口注意力(窗口 4096),9 层使用全局注意力。滑动窗口层使用 RoPE 编码局部相对位置,全局注意力层不使用位置编码(NoPE),使注意力完全由内容驱动。
- CohereLayerNorm:在主流模型普遍采用 RMSNorm 的背景下,Tiny Aya 选择了无偏置 LayerNorm,保留减均值步骤以适应多语言嵌入分布的均值偏移。在并行块仅需一个归一化层的前提下,总归一化开销反而低于串行块的两个 RMSNorm。
- 多语言区域化:围绕亚太、非洲、南亚、欧洲、西亚五大区域推出特化模型,所有变体共享同一架构,仅在训练数据配比上分化,体现了"一套架构、多套数据"的多语言扩展策略。