3.5 从零实现 GPT
前面几节分别介绍了 Transformer 的宏观架构(3.1 节)、核心组件——层归一化、前馈网络与残差连接(3.2 节)、以及旋转位置编码 RoPE(3.3 节)。这些组件就像散落在桌面上的零件:每一个我们都已经检视过、理解了其工作原理,但还没有将它们组装成一台完整的机器。
本节的目标正是完成这个组装过程——从零实现一个完整的 Decoder-Only Transformer 语言模型(即 GPT 架构),并让它真正运行起来生成文本。我们将按照数据流的顺序,自底向上逐层搭建:词嵌入与位置编码、因果自注意力、Transformer 块、完整模型,最后实现文本生成函数。所有代码均为自包含的 PyTorch 实现,可直接运行。
3.5.1 架构总览
GPT 系列模型采用 Decoder-Only 架构,即仅保留原始 Transformer 的解码器部分,移除编码器和编码器-解码器交叉注意力。整个模型的数据流如下:
每个 TransformerBlock 内部的结构为:
这里采用 Pre-Norm(归一化在子层之前),这是现代 LLM(LLaMA、GPT-3 及之后的模型)的标准做法,相比原始 Transformer 的 Post-Norm 具有更好的训练稳定性(详见 3.2 节的讨论)。
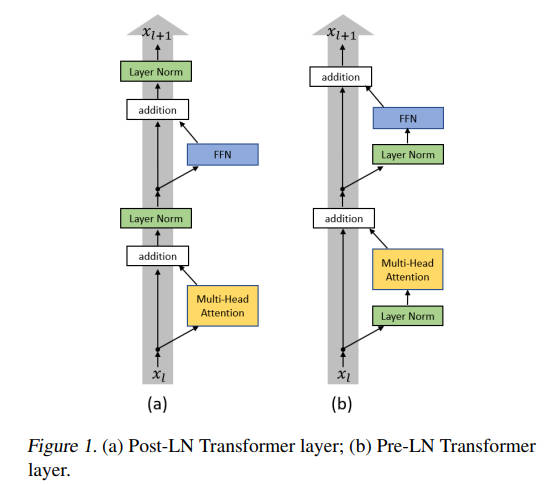
图 3-10:Post-LN(左)与 Pre-LN(右)Transformer 层的结构对比。Post-LN 将 Layer Norm 放在残差连接之后,Pre-LN 将 Layer Norm 放在子层(Multi-Head Attention 或 FFN)之前。Pre-LN 的梯度流更稳定,是 GPT-3 及后续模型的标准选择。
与 Encoder 中的自注意力不同,Decoder 的自注意力必须加入因果掩码(Causal Mask),确保位置
下面我们逐一实现每个组件。
3.5.2 基础组件
首先导入依赖并实现两个基础模块:LayerNorm 和 GELU 激活函数。
import torch
import torch.nn as nn
import math
class LayerNorm(nn.Module):
"""层归一化(带可学习缩放和偏移)。"""
def __init__(self, dim: int, eps: float = 1e-5):
super().__init__()
self.eps = eps
self.scale = nn.Parameter(torch.ones(dim)) # gamma
self.shift = nn.Parameter(torch.zeros(dim)) # beta
def forward(self, x: torch.Tensor) -> torch.Tensor:
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
return self.scale * (x - mean) / torch.sqrt(var + self.eps) + self.shift
class GELU(nn.Module):
"""GELU 激活函数(Tanh 近似)。
GPT-2 使用的激活函数。现代模型(如 LLaMA)转向了 SwiGLU,
但 GELU 仍然是理解 GPT 架构的标准选择。
"""
def forward(self, x: torch.Tensor) -> torch.Tensor:
return 0.5 * x * (1.0 + torch.tanh(
math.sqrt(2.0 / math.pi) * (x + 0.044715 * x.pow(3))
))关于归一化方案的选择。 本节采用 LayerNorm 以贴合经典 GPT-2 的设计。读者如果想对齐 LLaMA 风格的实现,只需将 LayerNorm 替换为 3.2 节实现的 RMSNorm,并将 GELU 替换为 SwiGLU 门控前馈网络。核心架构逻辑不变。
3.5.3 因果自注意力
因果自注意力(Causal Self-Attention)是 GPT 的核心引擎。与 3.1 节介绍的编码器自注意力相比,唯一的区别在于注意力矩阵的上三角部分被掩码为
class CausalSelfAttention(nn.Module):
"""多头因果自注意力。
Args:
d_model: 模型隐藏维度
n_heads: 注意力头数
max_seq_len: 支持的最大序列长度(用于预生成因果掩码)
dropout: 注意力权重的 Dropout 概率
"""
def __init__(
self,
d_model: int,
n_heads: int,
max_seq_len: int,
dropout: float = 0.0,
):
super().__init__()
assert d_model % n_heads == 0, "d_model 必须被 n_heads 整除"
self.n_heads = n_heads
self.head_dim = d_model // n_heads # 每个头的维度
# Q, K, V 投影矩阵(合并为三个独立的线性层)
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_model, bias=False)
self.W_v = nn.Linear(d_model, d_model, bias=False)
# 输出投影
self.out_proj = nn.Linear(d_model, d_model, bias=False)
self.attn_dropout = nn.Dropout(dropout)
# 预计算因果掩码:上三角为 True(需要被屏蔽的位置)
mask = torch.triu(torch.ones(max_seq_len, max_seq_len), diagonal=1).bool()
self.register_buffer("causal_mask", mask)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: (batch_size, seq_len, d_model)
Returns:
(batch_size, seq_len, d_model)
"""
B, T, D = x.shape
# 线性投影
q = self.W_q(x) # (B, T, d_model)
k = self.W_k(x)
v = self.W_v(x)
# 拆分多头: (B, T, d_model) -> (B, T, n_heads, head_dim) -> (B, n_heads, T, head_dim)
q = q.view(B, T, self.n_heads, self.head_dim).transpose(1, 2)
k = k.view(B, T, self.n_heads, self.head_dim).transpose(1, 2)
v = v.view(B, T, self.n_heads, self.head_dim).transpose(1, 2)
# 缩放点积注意力: (B, n_heads, T, T)
scores = (q @ k.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 应用因果掩码:将未来位置的分数设为 -inf
scores = scores.masked_fill(self.causal_mask[:T, :T], float("-inf"))
# Softmax + Dropout
attn_weights = torch.softmax(scores, dim=-1)
attn_weights = self.attn_dropout(attn_weights)
# 加权聚合: (B, n_heads, T, head_dim)
out = attn_weights @ v
# 合并多头: (B, n_heads, T, head_dim) -> (B, T, d_model)
out = out.transpose(1, 2).contiguous().view(B, T, D)
# 输出投影
return self.out_proj(out)代码要点。
- 掩码的预计算:因果掩码是一个固定的上三角布尔矩阵,通过
register_buffer注册为模型的常量缓冲区(不参与梯度计算,但会随模型一起移动到 GPU)。前向传播时只需按实际序列长度截取[:T, :T]。 - 缩放因子:
防止当 head_dim较大时点积值过大导致 Softmax 饱和(梯度趋近于零)。 contiguous()的必要性:transpose操作改变了张量在内存中的布局,后续的view要求内存连续,因此需要先调用contiguous()。
3.5.4 前馈网络
GPT-2 使用标准的两层前馈网络,中间维度为
class FeedForward(nn.Module):
"""Position-wise 前馈网络。
结构: Linear(d_model -> 4*d_model) -> GELU -> Linear(4*d_model -> d_model)
"""
def __init__(self, d_model: int, dropout: float = 0.0):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, 4 * d_model),
GELU(),
nn.Linear(4 * d_model, d_model),
nn.Dropout(dropout),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)FFN 对序列中的每个位置独立作用(参数共享但计算独立),其本质是为模型提供非线性变换能力——注意力层完成了"位置之间的信息交互",FFN 则负责"逐位置的特征变换"。
3.5.5 Transformer 块
一个 Transformer 块将注意力和 FFN 用 Pre-Norm 残差连接串联起来:
class TransformerBlock(nn.Module):
"""单个 Transformer 解码器块(Pre-Norm 结构)。"""
def __init__(
self,
d_model: int,
n_heads: int,
max_seq_len: int,
dropout: float = 0.0,
):
super().__init__()
self.norm1 = LayerNorm(d_model)
self.attn = CausalSelfAttention(d_model, n_heads, max_seq_len, dropout)
self.norm2 = LayerNorm(d_model)
self.ffn = FeedForward(d_model, dropout)
self.drop = nn.Dropout(dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 子层 1: 归一化 -> 注意力 -> 残差连接
x = x + self.drop(self.attn(self.norm1(x)))
# 子层 2: 归一化 -> FFN -> 残差连接
x = x + self.drop(self.ffn(self.norm2(x)))
return x残差连接的作用在 3.2 节已有详细讨论:它允许梯度直接沿恒等映射回传到浅层,是深层 Transformer 能够稳定训练的关键保障。Pre-Norm 将归一化放在子层输入端,确保子层接收到的信号始终处于良好的数值范围内。
3.5.6 完整 GPT 模型
现在将所有组件组装成完整的 GPT 模型:
class GPTModel(nn.Module):
"""完整的 GPT(Decoder-Only Transformer)语言模型。
Args:
vocab_size: 词表大小
d_model: 隐藏维度
n_heads: 注意力头数
n_layers: Transformer 块的层数
max_seq_len: 支持的最大序列长度
dropout: Dropout 概率
"""
def __init__(
self,
vocab_size: int,
d_model: int,
n_heads: int,
n_layers: int,
max_seq_len: int,
dropout: float = 0.0,
):
super().__init__()
self.max_seq_len = max_seq_len
# --- 嵌入层 ---
self.tok_emb = nn.Embedding(vocab_size, d_model) # 词嵌入
self.pos_emb = nn.Embedding(max_seq_len, d_model) # 可学习绝对位置编码
self.drop_emb = nn.Dropout(dropout)
# --- Transformer 主干 ---
self.blocks = nn.Sequential(
*[TransformerBlock(d_model, n_heads, max_seq_len, dropout)
for _ in range(n_layers)]
)
# --- 输出层 ---
self.final_norm = LayerNorm(d_model)
self.lm_head = nn.Linear(d_model, vocab_size, bias=False)
# 权重初始化
self.apply(self._init_weights)
def _init_weights(self, module: nn.Module):
"""参照 GPT-2 论文的权重初始化策略。"""
if isinstance(module, nn.Linear):
nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx: torch.Tensor) -> torch.Tensor:
"""
Args:
idx: (batch_size, seq_len),token ID 序列
Returns:
logits: (batch_size, seq_len, vocab_size),每个位置在词表上的未归一化分数
"""
B, T = idx.shape
assert T <= self.max_seq_len, f"序列长度 {T} 超过最大值 {self.max_seq_len}"
# 词嵌入 + 位置嵌入
tok_emb = self.tok_emb(idx) # (B, T, d_model)
pos_emb = self.pos_emb(torch.arange(T, device=idx.device)) # (T, d_model)
x = self.drop_emb(tok_emb + pos_emb) # (B, T, d_model)
# 通过 N 层 Transformer 块
x = self.blocks(x) # (B, T, d_model)
# 最终归一化 + 线性投影到词表
x = self.final_norm(x) # (B, T, d_model)
logits = self.lm_head(x) # (B, T, vocab_size)
return logits设计说明。
- 位置编码:本实现采用可学习的绝对位置编码(即
nn.Embedding),与 GPT-2 一致。如果想使用 RoPE,需要将位置嵌入从模型顶层移入注意力模块内部,对 Q 和 K 施加旋转(实现代码已在 3.3 节给出),而非在嵌入阶段相加。 - 权重初始化:所有线性层和嵌入层使用均值为 0、标准差为 0.02 的正态分布初始化。这一策略来自 GPT-2 论文,是让深层 Transformer 稳定训练的重要经验。
lm_head无偏置:输出投影层不加偏置项是现代 LLM 的通用做法。部分模型还会将lm_head.weight与tok_emb.weight绑定(Weight Tying),共享参数以减少显存占用——这在小模型中效果显著。
3.5.7 模型配置与实例化
定义一个与 GPT-2 Small(124M 参数)对齐的配置,并验证模型可以正确前向传播:
# GPT-2 Small 配置
GPT_CONFIG = {
"vocab_size": 50257, # GPT-2 的 BPE 词表大小
"d_model": 768, # 隐藏维度
"n_heads": 12, # 注意力头数 (head_dim = 768/12 = 64)
"n_layers": 12, # Transformer 层数
"max_seq_len": 1024, # 最大序列长度
"dropout": 0.1, # Dropout 概率
}
# 实例化模型
model = GPTModel(**GPT_CONFIG)
# 统计参数量
num_params = sum(p.numel() for p in model.parameters())
print(f"模型参数量: {num_params:,}") # 约 124M
# 验证前向传播
dummy_input = torch.randint(0, GPT_CONFIG["vocab_size"], (2, 128)) # batch=2, seq_len=128
logits = model(dummy_input)
print(f"输入形状: {dummy_input.shape}") # (2, 128)
print(f"输出形状: {logits.shape}") # (2, 128, 50257)输出的 logits 张量形状为 (batch_size, seq_len, vocab_size),表示每个位置对词表中所有 token 的打分。训练时,我们取 logits[:, :-1, :] 与 targets[:, 1:] 计算交叉熵损失(即"用前一个 token 预测下一个 token");推理时,我们只关心最后一个位置的 logits,从中采样出下一个 token。
3.5.8 文本生成与推理策略
模型训练完成后(训练过程将在后续章节介绍),就可以进行自回归文本生成了。其基本流程是一个循环:将当前序列输入模型,取最后一个位置的 logits,从中选出下一个 token,将其追加到序列末尾,然后重复。
贪心解码
最简单的策略是贪心解码(Greedy Decoding):每一步都选择概率最高的 token。
@torch.no_grad()
def generate_greedy(
model: GPTModel,
idx: torch.Tensor,
max_new_tokens: int,
) -> torch.Tensor:
"""贪心解码:每步选概率最高的 token。
Args:
model: 训练好的 GPT 模型
idx: (batch_size, seq_len),初始 prompt 的 token ID
max_new_tokens: 要生成的新 token 数量
Returns:
(batch_size, seq_len + max_new_tokens),包含原始 prompt 和生成内容
"""
model.eval()
for _ in range(max_new_tokens):
# 截断到最大上下文长度
idx_cond = idx[:, -model.max_seq_len:]
# 前向传播得到 logits
logits = model(idx_cond)
# 只取最后一个时间步: (B, vocab_size)
logits = logits[:, -1, :]
# 贪心:选 argmax
next_token = logits.argmax(dim=-1, keepdim=True) # (B, 1)
# 追加到序列
idx = torch.cat([idx, next_token], dim=1)
return idx贪心解码的优点是确定性强、实现简单,但缺点同样明显:它总是选择"最安全"的 token,生成的文本往往单调重复,缺乏多样性。
带温度的采样
为了让生成更加多样和自然,实际应用中通常使用带温度的采样结合 Top-k 截断:
@torch.no_grad()
def generate(
model: GPTModel,
idx: torch.Tensor,
max_new_tokens: int,
temperature: float = 1.0,
top_k: int | None = None,
) -> torch.Tensor:
"""带温度和 Top-k 的采样生成。
Args:
model: 训练好的 GPT 模型
idx: (batch_size, seq_len),初始 prompt 的 token ID
max_new_tokens: 要生成的新 token 数量
temperature: 温度系数。>1 使分布更平坦(更随机),<1 使分布更尖锐(更确定)
top_k: 若指定,只从概率最高的 k 个 token 中采样
Returns:
(batch_size, seq_len + max_new_tokens)
"""
model.eval()
for _ in range(max_new_tokens):
idx_cond = idx[:, -model.max_seq_len:]
logits = model(idx_cond)
logits = logits[:, -1, :] # (B, vocab_size)
# 温度缩放
if temperature != 1.0:
logits = logits / temperature
# Top-k 截断:将排名 k 之外的 logits 设为 -inf
if top_k is not None:
top_values, _ = torch.topk(logits, top_k, dim=-1)
threshold = top_values[:, -1].unsqueeze(-1) # 第 k 大的值
logits = logits.masked_fill(logits < threshold, float("-inf"))
# 转为概率分布并采样
probs = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1) # (B, 1)
idx = torch.cat([idx, next_token], dim=1)
return idx温度(Temperature)的直觉。 Softmax 的输入除以温度
Top-k 采样的作用。 即使经过温度调节,概率分布的长尾中仍可能存在语义不连贯的低概率 token。Top-k 截断将候选集限制在概率最高的
端到端演示
以下是使用 tiktoken(OpenAI 的 BPE 分词器)进行端到端文本生成的完整示例:
import tiktoken
def demo_generate():
"""端到端文本生成演示。"""
# 初始化
torch.manual_seed(42)
model = GPTModel(**GPT_CONFIG)
model.eval()
tokenizer = tiktoken.get_encoding("gpt2")
# 编码 prompt
prompt = "The meaning of life is"
input_ids = tokenizer.encode(prompt)
idx = torch.tensor([input_ids]) # (1, seq_len)
# 生成(未训练的模型会输出随机文本,此处仅验证流程)
output_ids = generate(
model, idx,
max_new_tokens=30,
temperature=0.8,
top_k=40,
)
# 解码并打印
generated_text = tokenizer.decode(output_ids[0].tolist())
print(f"Prompt: {prompt}")
print(f"Generated: {generated_text}")
if __name__ == "__main__":
demo_generate()需要注意的是,上面实例化的模型权重是随机初始化的,因此生成的文本不会有任何语义。要让模型生成有意义的文本,需要经过大规模语料的预训练——这将是后续章节的内容。此处的目的是验证整个模型的数据流和生成流程是正确的。
3.5.9 从 GPT-2 到现代 LLM:架构改进一览
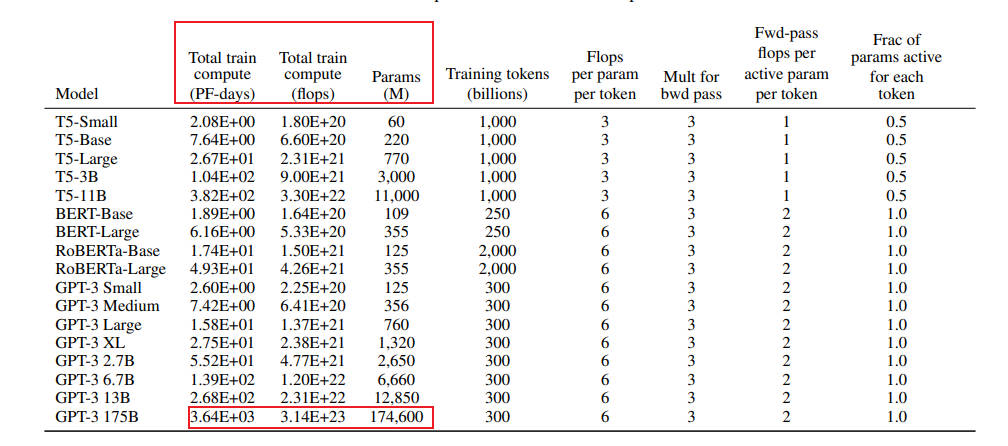
图 3-11:GPT-3 论文中各模型的训练计算量(PF-days)、参数量和训练数据量对比。从 125M 到 175B,模型规模跨越三个数量级,训练计算量从 2 PF-days 增长到 3640 PF-days。注意所有 GPT-3 变体均训练了 300B tokens,体现了当时"固定数据量、增大模型"的缩放策略。
本节实现的模型忠实复现了 GPT-2 的架构设计。在此基础上,以 LLaMA 为代表的现代 LLM 做了一系列针对性改进。下表总结了关键差异:
| 组件 | GPT-2(本节实现) | LLaMA 风格(现代实践) |
|---|---|---|
| 归一化 | LayerNorm(含均值居中) | RMSNorm(省略均值,更快) |
| 归一化位置 | Pre-Norm | Pre-Norm(一致) |
| 位置编码 | 可学习绝对位置编码 | RoPE(旋转位置编码,见 3.3 节) |
| 激活函数 | GELU | SwiGLU(门控激活,表达能力更强) |
| FFN 维度 | ||
| 偏置项 | 部分保留 | 全部移除 |
| 注意力变体 | 标准多头注意力(MHA) | 分组查询注意力(GQA) |
| 权重绑定 | 可选 | 小模型常用 |
这些改进中,最核心的三项是 RMSNorm(训练稳定性和速度)、RoPE(更好的长度泛化能力)和 SwiGLU(更强的非线性表达)。它们的实现已分别在 3.2 节和 3.3 节给出,读者可以在本节代码的基础上逐一替换,搭建出自己的"LLaMA-like"模型。
本节小结
本节从零实现了一个完整的 GPT 模型,完成了从散落零件到可运行系统的组装过程:
- CausalSelfAttention 通过上三角因果掩码确保了自回归生成的因果性,每个 token 只能关注自己和过去的 token。
- TransformerBlock 以 Pre-Norm 残差连接将注意力和 FFN 串联起来,是模型的基本重复单元。
- GPTModel 将词嵌入、位置编码、
层 TransformerBlock 和输出投影组装为完整的语言模型。 - 文本生成方面,我们实现了贪心解码和带温度的 Top-k 采样两种策略。贪心解码确定性强但缺乏多样性;温度和 Top-k 的组合则在质量与多样性之间提供了灵活的调控手段。
至此,我们拥有了一个结构完整但权重随机的 GPT 模型。接下来的章节将介绍如何用大规模文本数据对其进行预训练,让这些随机的参数逐渐学到语言的统计规律,最终生成连贯、有意义的文本。