26.4 GRPO 训练推理模型(代码实战)
前面几节搭建了推理模型所需的"脚手架"——生成引擎、评估流水线、推理时间缩放策略。但这些都还是在固定权重上做文章。要让模型本身学会推理,必须把强化学习引入训练循环。本节实现一套完整的 RLVR + GRPO(Reinforcement Learning with Verifiable Rewards + Group Relative Policy Optimization)训练代码,涵盖采样、奖励计算、优势估计、策略梯度更新的每一个环节,并给出调参经验和常见 debug 技巧。
前置依赖:GRPO 的算法原理已在 [16.3 节] 详细推导,训练管线的宏观设计见 [18.2 节]。本节聚焦代码实现,不再重复理论推导,而是把每个公式直接映射到 PyTorch 代码。
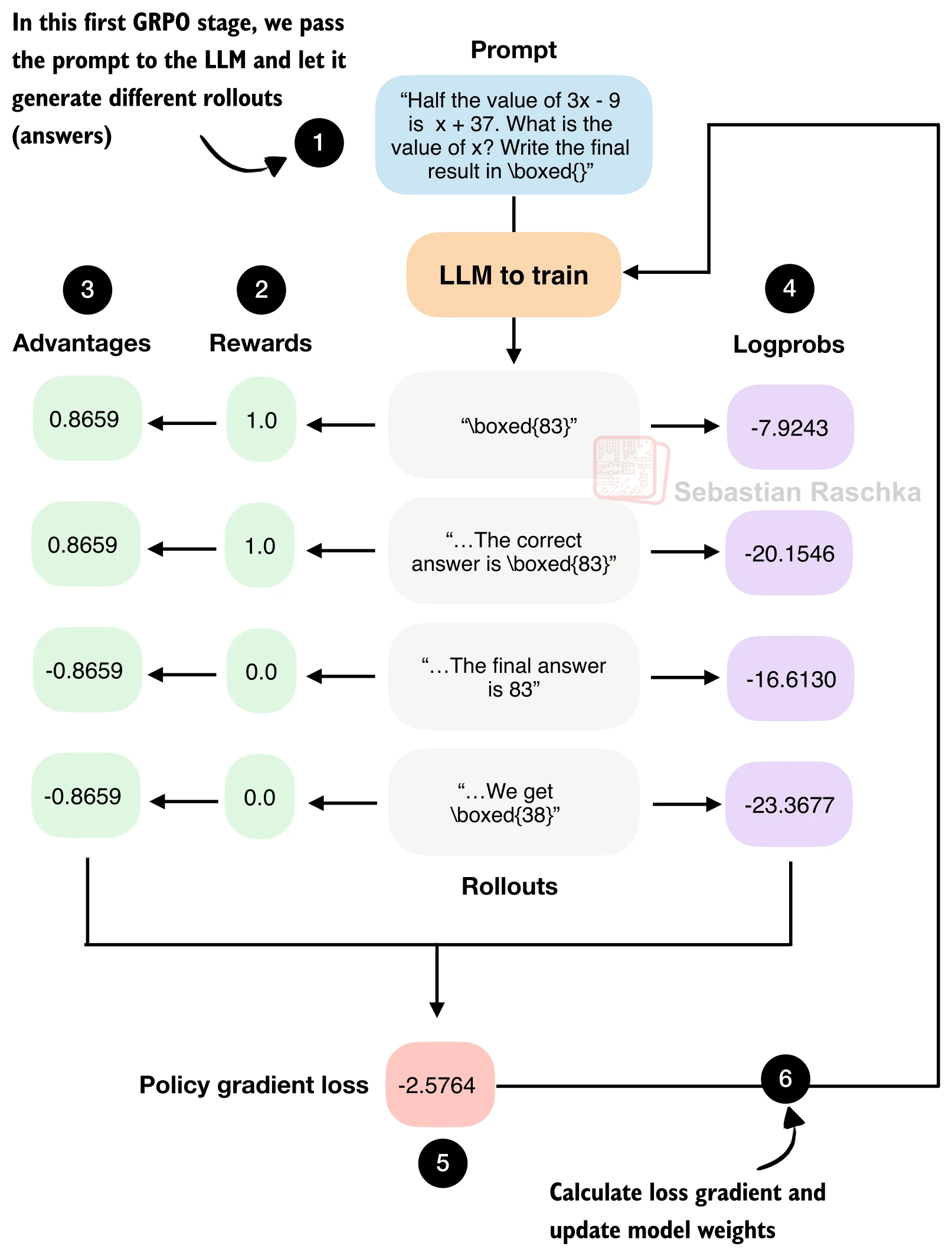
一、全局视角:GRPO 训练的五个阶段
一轮 GRPO 训练步骤可以拆为五个阶段:
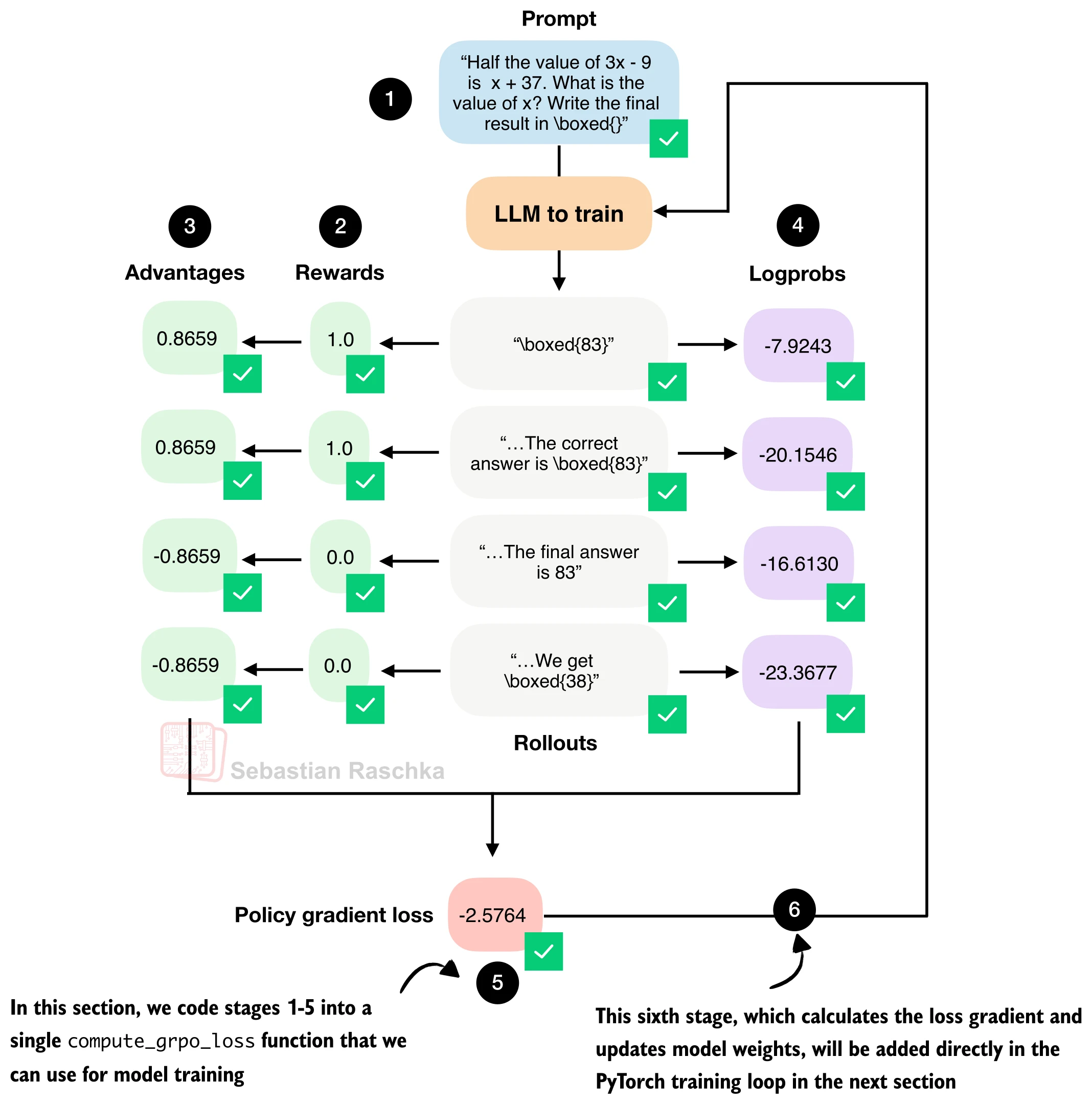
- 采样(Rollout Generation):对同一道数学题,模型生成
条候选回答(rollout)。 - 奖励计算(Reward):用规则验证器判断每条回答的正确性,返回 0/1 奖励。
- 优势估计(Advantage):在组内做标准化,得到每条回答的相对优劣。
- 对数概率计算(Log-Probability):重新前向传播,计算每条回答的序列级对数概率。
- 策略梯度更新(Policy Gradient):用优势加权对数概率构造损失,反向传播更新权重。
下面按这五个阶段逐一实现。
二、采样:生成多条候选回答
GRPO 的核心思想是组内对比——同一道题生成多条回答,比较它们的相对优劣来构造学习信号。采样阶段需要一个支持 temperature + top-p 的自回归生成函数:
import torch
@torch.no_grad()
def sample_response(model, tokenizer, prompt, device,
max_new_tokens=512, temperature=0.8, top_p=0.9):
"""自回归采样一条回答,返回 (完整token序列, prompt长度, 生成文本)"""
input_ids = torch.tensor(tokenizer.encode(prompt), device=device)
cache = KVCache(n_layers=model.cfg["n_layers"])
model.reset_kv_cache()
logits = model(input_ids.unsqueeze(0), cache=cache)[:, -1]
generated = []
for _ in range(max_new_tokens):
if temperature and temperature != 1.0:
logits = logits / temperature
probas = torch.softmax(logits, dim=-1)
probas = top_p_filter(probas, top_p) # nucleus sampling
next_token = torch.multinomial(probas, num_samples=1)
token_id = next_token.item()
generated.append(token_id)
if token_id == tokenizer.eos_token_id:
break
logits = model(next_token, cache=cache)[:, -1]
full_ids = torch.cat([
input_ids,
torch.tensor(generated, device=device, dtype=input_ids.dtype)
])
return full_ids, input_ids.numel(), tokenizer.decode(generated)关键设计:
- 使用
@torch.no_grad()而不是@torch.inference_mode()。后者会过度优化,导致后续对同一 token 序列计算梯度时报错。采样阶段不需要梯度,但生成的 token 序列会在第四阶段重新前向传播时参与梯度计算。 - KV Cache 逐 token 生成时复用已计算的键值矩阵,避免重复计算 prompt 部分。
top_p_filter实现 nucleus sampling:只保留累积概率达到top_p的最高概率 token 集合,其余置零后重新归一化。
三、奖励计算:规则验证器
RLVR 的"V"代表 Verifiable——奖励来自可自动验证的规则,而非人类标注或神经网络奖励模型。对于数学推理任务,奖励函数非常简洁:
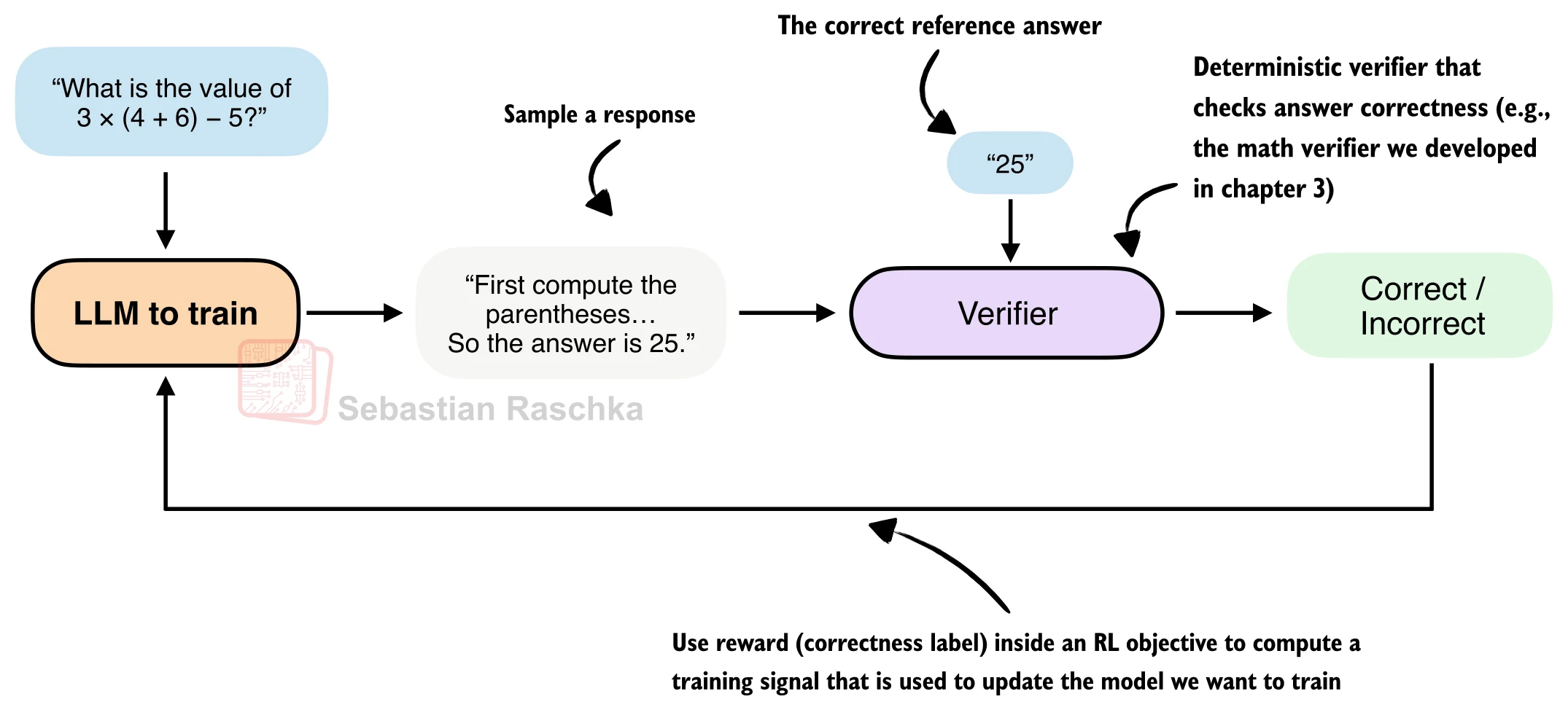
def reward_rlvr(answer_text, ground_truth):
"""RLVR 奖励函数:答案正确返回 1.0,否则返回 0.0"""
extracted = extract_final_candidate(answer_text, fallback=None)
if not extracted:
return 0.0
correct = grade_answer(extracted, ground_truth)
return float(correct)这里复用了 [26.2 节] 搭建的评估组件:extract_final_candidate 从生成文本中提取 \boxed{} 内的答案,grade_answer 通过符号计算判断数学等价性。
设计选择:为什么不用过程奖励模型(PRM)? DeepSeek-R1 团队在实验中发现,PRM 对中间步骤的打分会引入噪声,反而不如只看最终答案正确性的简单 0/1 奖励来得有效。对于数学任务,结果可以精确验证,这是 RLVR 天然的优势场景。
四、优势估计:组内标准化
GRPO 名称中"GR"(Group Relative)的含义:在同一道题的
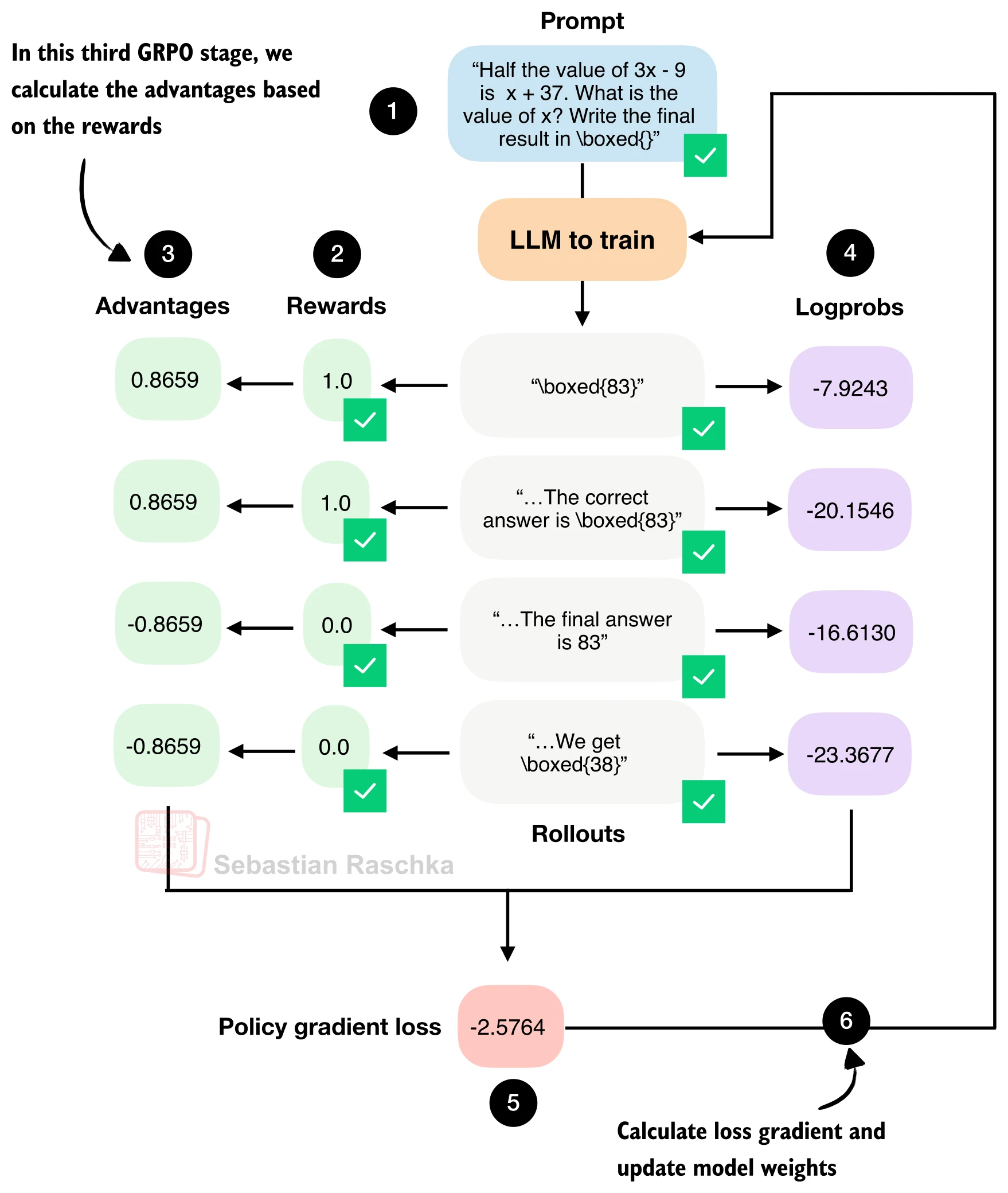
其中
rewards = torch.tensor(rollout_rewards, device=device)
advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-4)以 4 条回答为例,若奖励分别为
>>> rewards = torch.tensor([1., 1., 0., 0.])
>>> advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-4)
>>> print(advantages)
tensor([ 0.8659, 0.8659, -0.8659, -0.8659])正确回答获得正优势,错误回答获得负优势。如果所有回答的奖励相同(全对或全错),则
五、序列级对数概率
GRPO 需要计算每条回答的序列级对数概率(不是 token 级平均),用于衡量当前策略对该回答的"赞同程度":
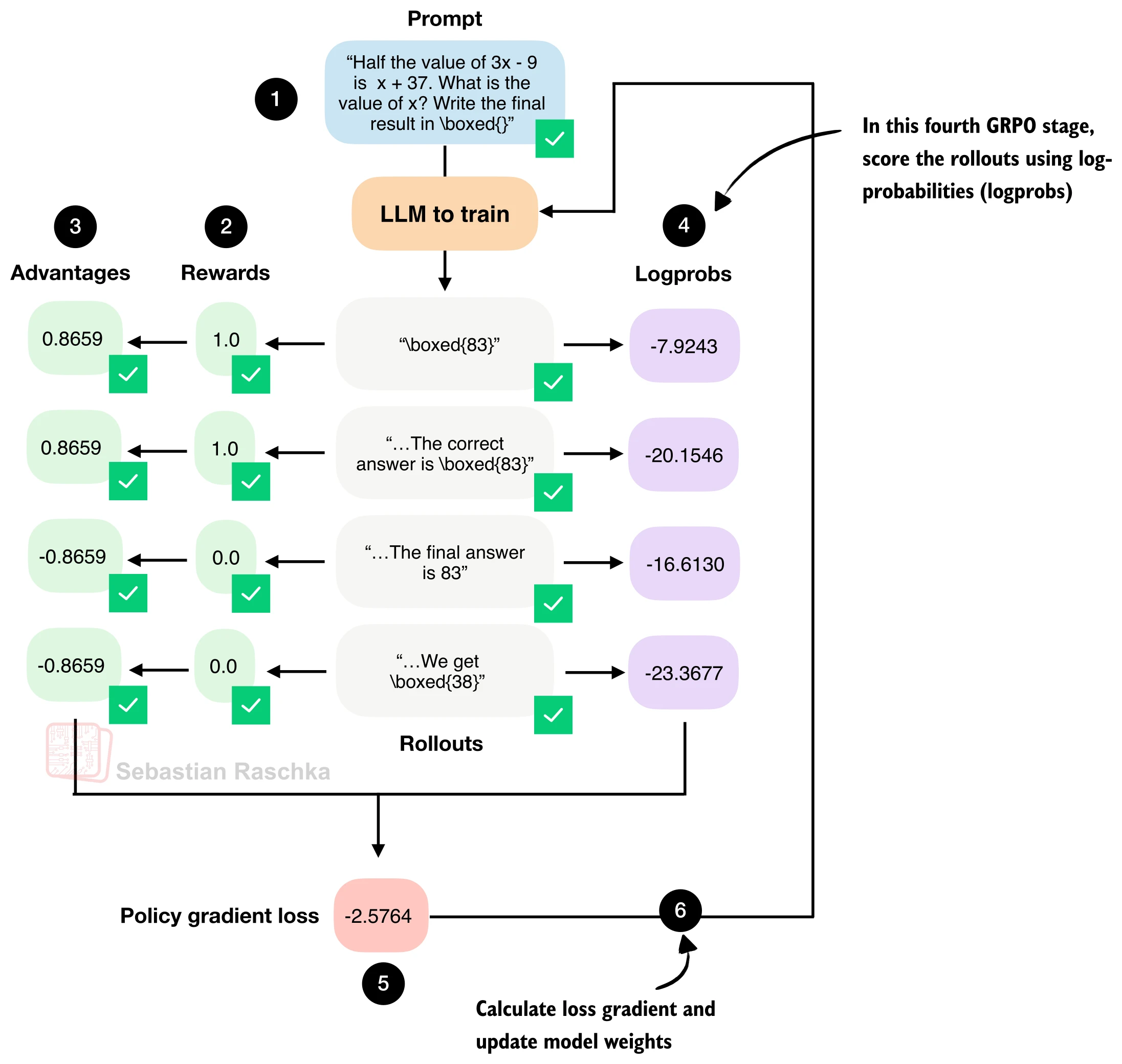
def sequence_logprob(model, token_ids, prompt_len):
"""计算回答部分的序列级对数概率(带梯度)"""
logits = model(token_ids.unsqueeze(0)).squeeze(0).float()
logprobs = torch.log_softmax(logits, dim=-1)
targets = token_ids[1:]
selected = logprobs[:-1].gather(1, targets.unsqueeze(-1)).squeeze(-1)
return selected[prompt_len - 1:].sum()为什么用 sum 而不用 mean? token 级平均对数概率适合"打分"(使不同长度的回答可比),但 GRPO 中每条回答已有独立的优势值作为权重。使用序列级 sum 可以正确地将梯度信号传播到每个 token 位置;如果用 mean,短回答和长回答的梯度量级会被人为拉平,扭曲策略更新方向。直觉上,summed log-prob 天然鼓励模型生成更简短的正确答案——两条同样正确的回答,更短的那条 log-prob 更高(更不负),因此获得更大的梯度推动。
六、策略梯度损失
将优势与对数概率结合,构造 GRPO 的策略梯度损失:
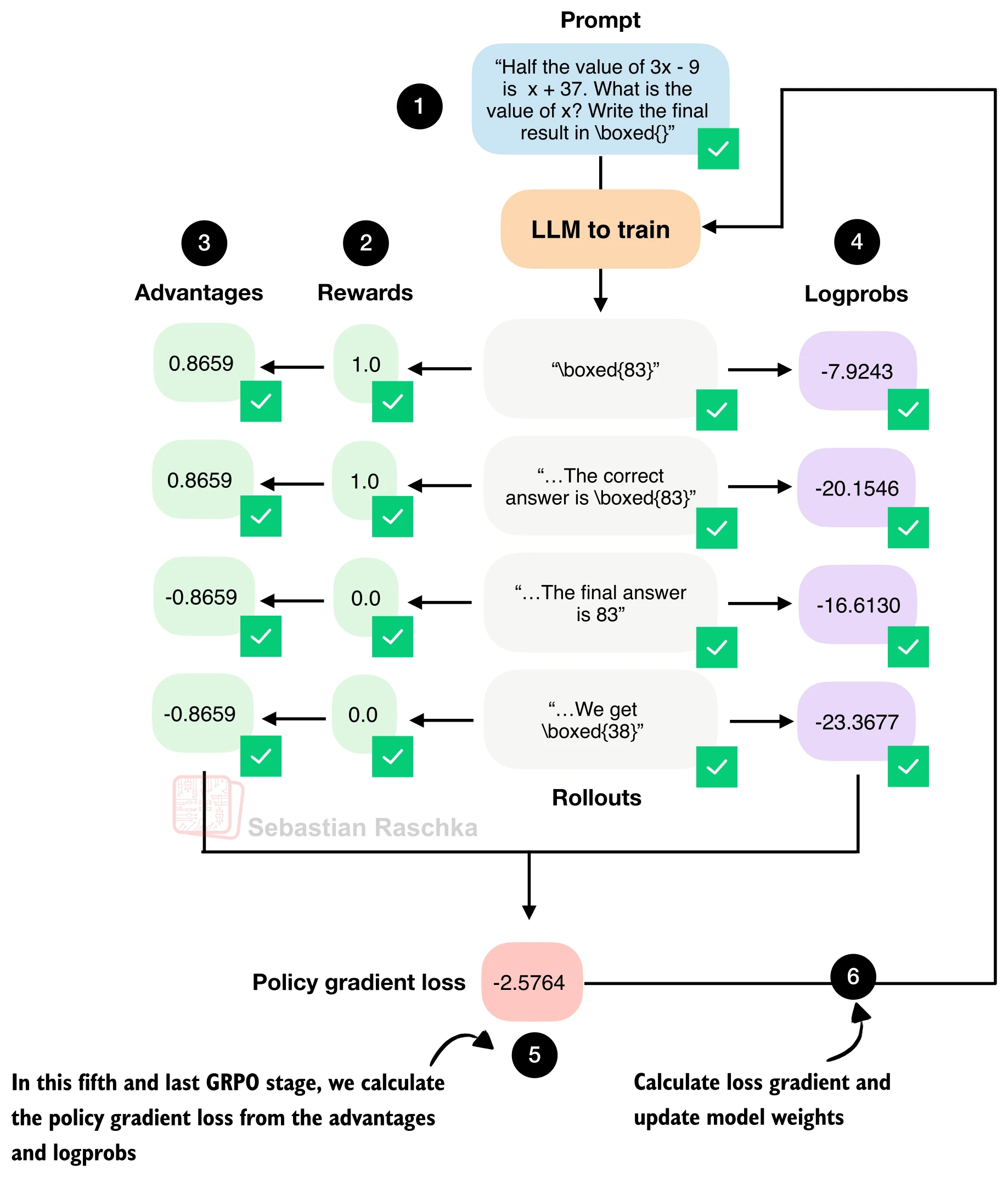
logps = torch.stack(rollout_logps) # [G] 每条回答的序列 logprob
pg_loss = -(advantages.detach() * logps).mean()两个细节值得注意:
advantages.detach():优势值是固定的学习信号,不参与反向传播。梯度只流经logps。- 负号:PyTorch 优化器默认做最小化,但我们希望最大化高优势回答的概率,因此取负。
与完整 GRPO 公式的区别:原始 DeepSeekMath 论文中的 GRPO 还包含一个 KL 散度惩罚项
,用来防止策略偏离参考模型太远。但后续研究(DAPO、Dr. GRPO、OLMo 3 等)发现,在数学推理任务上去掉 KL 项反而效果更好。本节实现的是去除 KL 项的简化版本。
七、组装:完整的 GRPO 损失计算
将上述组件组装为一个 compute_grpo_loss 函数:
def compute_grpo_loss(model, tokenizer, example, device,
num_rollouts=4, max_new_tokens=512,
temperature=0.8, top_p=0.9,
skip_zero_adv=False):
"""计算单个训练样本的 GRPO 损失"""
roll_rewards, samples, rollout_data = [], [], []
prompt = render_prompt(example["problem"])
# 阶段 1: 切换到 eval 模式进行采样(关闭 dropout 等)
was_training = model.training
model.eval()
for _ in range(num_rollouts):
token_ids, prompt_len, text = sample_response(
model, tokenizer, prompt, device,
max_new_tokens=max_new_tokens,
temperature=temperature, top_p=top_p,
)
reward = reward_rlvr(text, example["answer"])
roll_rewards.append(reward)
rollout_data.append((token_ids, prompt_len))
samples.append({
"text": text, "reward": reward,
"gen_len": token_ids.numel() - prompt_len,
})
if was_training:
model.train()
# 阶段 2-3: 奖励 -> 优势
rewards = torch.tensor(roll_rewards, device=device)
advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-4)
# 优化:全零优势时跳过更新
is_zero_adv = torch.allclose(
advantages, torch.zeros_like(advantages), atol=1e-8, rtol=0.0
)
if skip_zero_adv and is_zero_adv:
return {"loss": 0.0, "loss_tensor": None,
"rewards": roll_rewards, "samples": samples,
"is_zero_adv": True}
# 阶段 4: 计算序列对数概率(此时模型在 train 模式,有梯度)
roll_logps = []
for token_ids, prompt_len in rollout_data:
logp = sequence_logprob(model, token_ids, prompt_len)
roll_logps.append(logp)
logps = torch.stack(roll_logps)
# 阶段 5: 策略梯度损失
pg_loss = -(advantages.detach() * logps).mean()
return {"loss": pg_loss.item(), "loss_tensor": pg_loss,
"rewards": roll_rewards, "samples": samples,
"is_zero_adv": False}skip_zero_adv 优化:当一组回答全对或全错时,优势全为零,loss_tensor 也为零。虽然数学上无害,但仍会触发完整的前向传播和反向传播,白白消耗计算。开启此选项后直接跳过,既节省时间也降低显存峰值(因为超长回答往往是错误回答——模型生成到 max_new_tokens 还没给出 \boxed{},这些序列消耗的内存最多)。
八、训练循环
将 GRPO 损失嵌入标准的 PyTorch 训练循环:
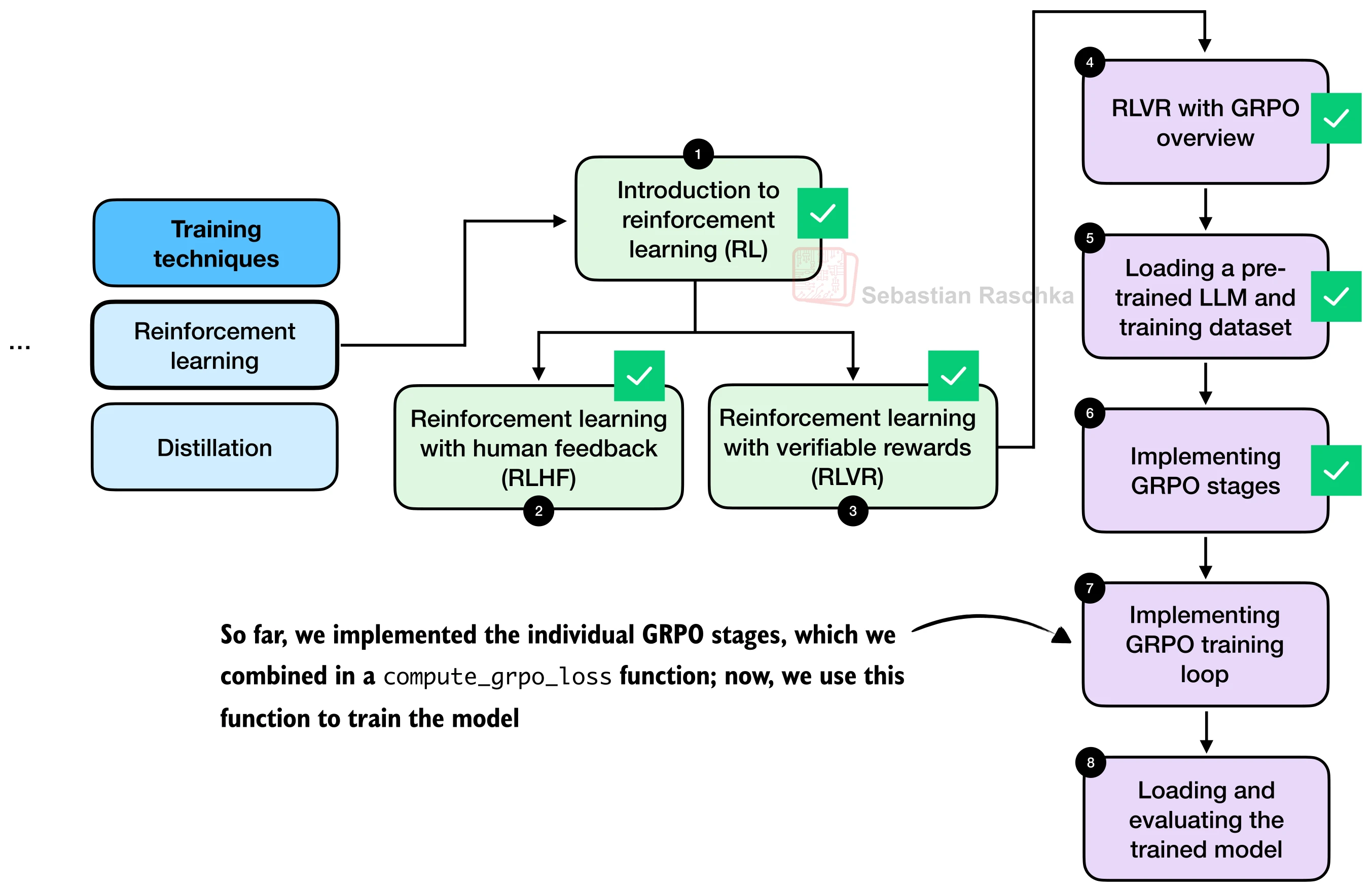
def train_rlvr_grpo(model, tokenizer, math_data, device,
steps=100, num_rollouts=8, max_new_tokens=512,
temperature=0.8, top_p=0.9, lr=1e-5,
checkpoint_every=50):
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
model.train()
for step in range(steps):
example = math_data[step % len(math_data)]
# 计算 GRPO 损失
stats = compute_grpo_loss(
model, tokenizer, example, device,
num_rollouts=num_rollouts,
max_new_tokens=max_new_tokens,
temperature=temperature, top_p=top_p,
skip_zero_adv=True,
)
# 仅当有有效损失时才更新
if stats["loss_tensor"] is not None:
optimizer.zero_grad()
stats["loss_tensor"].backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
reward_avg = sum(stats["rewards"]) / len(stats["rewards"])
print(f"[Step {step+1}/{steps}] "
f"loss={stats['loss']:.4f} reward_avg={reward_avg:.3f}")
# 定期保存检查点
if (step + 1) % checkpoint_every == 0:
path = f"grpo-step{step+1:05d}.pth"
torch.save(model.state_dict(), path)
print(f"Saved checkpoint: {path}")梯度裁剪 clip_grad_norm_(model.parameters(), 1.0) 是 RL 训练的必备操作。由于序列级 log-prob 随长度线性增长,长回答的梯度量级天然更大,不裁剪容易导致参数跳变。
九、批量采样与多 GPU 扩展
上述代码是"逐条采样"的简洁实现。在实际训练中有两个常见优化:
1. 批量采样(Batched Rollouts)
将
@torch.no_grad()
def sample_responses_batched(model, tokenizer, prompt, device,
batch_size, max_new_tokens=512,
temperature=0.8, top_p=0.9):
prompt_ids = torch.tensor(tokenizer.encode(prompt), device=device)
input_ids = prompt_ids.unsqueeze(0).expand(batch_size, -1)
cache = KVCache(n_layers=model.cfg["n_layers"])
model.reset_kv_cache()
logits = model(input_ids, cache=cache)[:, -1]
eos_id = tokenizer.eos_token_id
finished = torch.zeros(batch_size, dtype=torch.bool, device=device)
generated_steps = []
for _ in range(max_new_tokens):
if temperature and temperature != 1.0:
logits = logits / temperature
probas = torch.softmax(logits, dim=-1)
probas = top_p_filter(probas, top_p)
next_token = torch.multinomial(probas, num_samples=1)
# 已结束的序列填充 EOS,避免继续采样
eos_tok = next_token.new_full((batch_size, 1), eos_id)
next_token = torch.where(finished.view(-1, 1), eos_tok, next_token)
generated_steps.append(next_token)
finished = finished | (next_token.squeeze(1) == eos_id)
if torch.all(finished):
break
logits = model(next_token, cache=cache)[:, -1]
# 按序列裁剪到各自的 EOS 位置
gen_tokens = torch.cat(generated_steps, dim=1)
results = []
for idx in range(batch_size):
row = gen_tokens[idx]
eos_pos = (row == eos_id).nonzero(as_tuple=True)[0]
if len(eos_pos) > 0:
row = row[:eos_pos[0] + 1]
full_ids = torch.cat([prompt_ids, row])
results.append((full_ids, prompt_ids.numel(),
tokenizer.decode(row.tolist())))
return results批量采样的吞吐量显著优于逐条采样,但显存开销与 batch_size * max_new_tokens 成正比。如果 rollout 数量较大(如 8 或 16),可以分多个 micro-batch 依次采样。
2. FSDP 多卡并行
对于多 GPU 环境,可以用 PyTorch FSDP(Fully Sharded Data Parallel)将模型参数切分到多张卡上:
import torch.distributed as dist
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
def setup_distributed(rank, world_size):
dist.init_process_group(backend="nccl", rank=rank,
world_size=world_size)
# 将模型包装为 FSDP
model = FSDP(model, device_id=device, use_orig_params=True)
# 训练数据按 rank 分片
math_data_shard = math_data[rank::world_size]FSDP 的关键是 use_orig_params=True,这样 model.parameters() 返回的仍然是原始参数引用,与 AdamW 优化器兼容。保存检查点时需要用 FullStateDictConfig 将分片参数聚合回完整状态字典。
十、实验结果与调参经验
以 Qwen3-0.6B 为基础模型,在 MATH 训练集(12,000 道不与 MATH-500 重叠的题目)上训练,MATH-500 测试集上评估:
| 方法 | 训练步数 | Max Tokens | Rollouts | MATH-500 准确率 | 平均回答长度 |
|---|---|---|---|---|---|
| 基础模型(无推理) | - | - | - | 15.2% | 78.85 |
| 推理模型(蒸馏训练) | - | - | - | 48.2% | 1369.79 |
| GRPO(无 KL)50 步 | 50 | 512 | 8 | 47.4% | 586.11 |
| GRPO(无 KL)100 步 | 100 | 512 | 8 | 44.0% | 555.95 |
| GRPO(含 KL)50 步 | 50 | 512 | 8 | 33.4% | 910.33 |
| GRPO(含 KL)100 步 | 100 | 512 | 8 | 0.4% | 1168.05 |
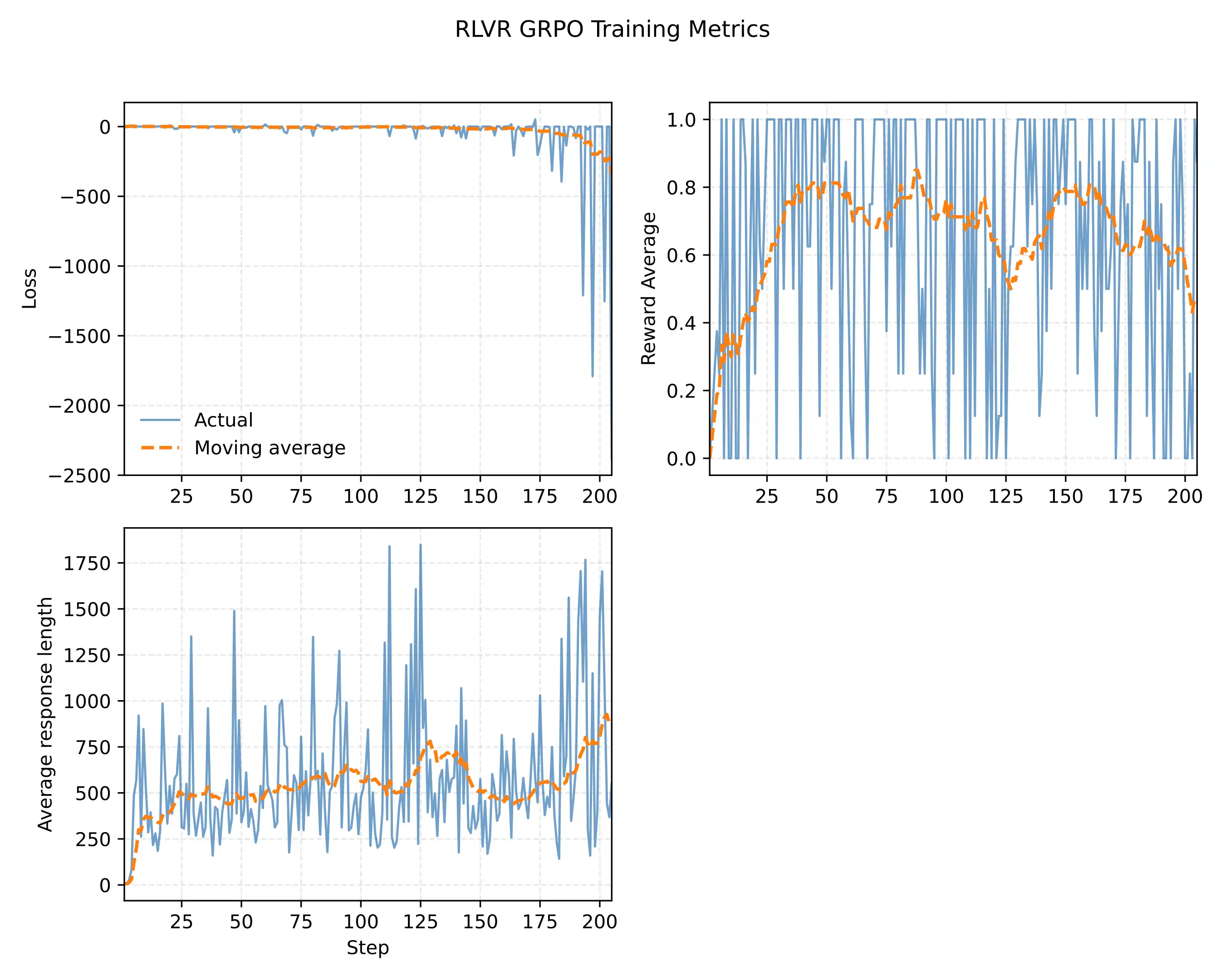
关键观察:
- 去掉 KL 项效果显著:无 KL 版本 50 步即达 47.4%,接近蒸馏训练的推理模型(48.2%);而含 KL 版本 100 步后直接崩溃到 0.4%。这验证了 DAPO 等工作的发现:KL 惩罚在数学任务上弊大于利。
- 训练并非越长越好:从 50 步到 100 步,准确率从 47.4% 降到 44.0%。原始 GRPO 在长训练下不够稳定,需要后续改进(如 clip ratio、token 级奖励加权等)才能支持长时间训练。
- 回答长度大幅缩短:GRPO 训练后平均回答从 1369 token 降到 586 token,同时保持近似的准确率。这是序列级 log-prob 鼓励简洁输出的直接效果。
显存与 rollout 数量的权衡:
| Rollouts | Max Tokens | 显存需求 |
|---|---|---|
| 8 | 1024 | 30.50 GB |
| 8 | 512 | 20.31 GB |
| 4 | 512 | 14.60 GB |
| 4 | 256 | 10.59 GB |
如果显存不足,可降低 num_rollouts 或 max_new_tokens,但这会影响训练质量。减少 rollout 数量后,可通过增大 accum_steps(梯度累积)来部分补偿,代价是训练时间变长。
十一、常见 Bug 与 Debug 技巧
1. loss 恒为零
如果 loss 一直是 0 且 reward 全为 0 或全为 1,说明所有 rollout 得到相同的奖励,优势全部为零。可能原因:
max_new_tokens太小,模型无法在限制内生成完整推理链和\boxed{}答案;temperature太低,所有 rollout 几乎相同;- 评估器有 bug,总是返回同一结果。
调试方法:打印每一步的 rollout 文本和奖励,检查模型是否在生成合理的推理过程。
2. loss 爆炸或 NaN
序列级 log-prob 随长度线性增长,当某条 rollout 特别长(接近 max_new_tokens)时,loss 绝对值可能很大。检查项:
- 确认
clip_grad_norm_已开启(阈值 1.0); - 确认
sequence_logprob中使用了.float()将 logits 转为 FP32 计算,避免 BF16 下的数值溢出; - 检查学习率是否过大(推荐
1e-5或5e-6)。
3. 训练后模型输出变成乱码
这通常是**策略崩溃(policy collapse)**的信号——模型被过度优化到某个局部最优。常见于:
- 训练步数过多而没有 KL 约束或 clip ratio;
- rollout 数量太少(如 2),优势估计方差过大。
缓解方法:从最后一个有效检查点恢复,减少训练步数或增加 rollout 数量。
4. eval/train 模式切换遗漏
compute_grpo_loss 内部在采样前切换到 model.eval(),采样后切换回 model.train()。如果忘记切换回来,后续的 sequence_logprob 调用虽然不影响梯度计算,但 dropout 等层的行为会不一致。代码中用 was_training 记录并恢复原始状态是最佳实践。
5. 检查点保存与恢复
训练中断时自动保存检查点是 RL 训练的"保命"机制。恢复训练时注意:
# 恢复检查点
model = Qwen3Model(config)
state_dict = torch.load("grpo-step00050.pth", map_location="cpu")
model.load_state_dict(state_dict)
model.to(device)
# 注意:优化器状态未保存,学习率调度从头开始如果需要精确恢复训练状态,应同时保存 optimizer.state_dict()。
十二、训练监控清单
一个健康的 GRPO 训练应满足以下指标模式:
| 指标 | 健康范围 | 异常信号 |
|---|---|---|
| reward_avg | 前 10 步: 0.1-0.3, 50 步后: 0.5-0.8 | 持续 0 或持续 1 |
| loss | 在 0 附近波动,偶尔出现较大值 | 单调递增或出现 NaN |
| avg_response_len | 逐渐缩短(1000+ -> 400-600) | 突然降到 <10(模型只输出 EOS) |
| tok/sec | 相对稳定 | 突然大幅下降(可能 OOM) |
建议每隔 50 步在验证集上评估一次准确率,并保存检查点。用 plot_metrics.py 等脚本绘制训练曲线,观察趋势比单看数字更直观。
本节小结
本节从零实现了完整的 RLVR + GRPO 训练流程:从采样多条候选回答、用规则验证器计算 0/1 奖励、组内标准化得到优势、计算序列级对数概率,到最终的策略梯度更新。代码在 Qwen3-0.6B 上仅 50 步训练就将 MATH-500 准确率从 15.2% 提升到 47.4%,接近蒸馏训练的推理模型水平,同时将平均回答长度缩短了 57%。去掉 KL 散度惩罚项是在数学任务上的关键发现,批量采样和 FSDP 多卡并行则为工程部署提供了可扩展的解决方案。