21.3 经典智能体案例
从 AlphaGo 击败围棋世界冠军,到 Voyager 在 Minecraft 中自主探索制造钻石工具,再到 Hilbert 让大模型成为形式化数学的利器——智能体(Agent)技术在过去十年间经历了从"专用任务的强化学习系统"到"通用大语言模型驱动的自主系统"的深刻演进。
本节将通过一系列经典案例,帮助读者理解智能体的核心设计范式:感知、推理、行动、记忆四要素如何在不同场景下被实例化,以及大语言模型的引入为何从根本上改变了智能体的构建方式。我们将先回顾游戏智能体的早期历史,再深入剖析 LLM 时代的代表性系统。
21.3.1 游戏智能体的早期历史
在大语言模型出现之前,游戏一直是智能体研究最重要的试验场。游戏环境具备明确的规则、可量化的胜负指标以及快速的交互循环,是验证智能体算法的理想平台。这一时期的代表性成果——AlphaGo、OpenAI Five 和 Dreamer——共同展示了强化学习驱动的智能体所能达到的惊人高度,同时也暴露了"专用智能体"范式的根本局限。
AlphaGo:神经网络与搜索的结合
2016 年,DeepMind 的 AlphaGo 在与围棋世界冠军李世石的对弈中以 4:1 获胜,成为人工智能历史上的标志性事件。从智能体的四要素框架来理解 AlphaGo:
- 感知:获取棋盘上所有棋子的位置与当前胜负状态
- 推理:由策略网络(Policy Network)预测每个位置的落子概率,由价值网络(Value Network)评估当前局势的胜率,再配合蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)进行多步前瞻,最终确定最优落点
- 行动:在棋盘上落子
- 记忆:棋局本身构成了隐式的"记忆"

图 21-7:AlphaGo 的围棋对弈。策略网络与价值网络的双网络架构配合 MCTS 搜索,使其在这一特定任务上远超人类水平。
AlphaGo 的训练分为两个阶段:首先通过监督学习从大量人类棋谱中学习基本策略,然后通过自我对弈(Self-Play)配合强化学习不断提升。其后继版本 AlphaGo Zero 更是完全抛弃了人类棋谱,仅凭自我对弈就达到了更高的水准。
但 AlphaGo 的局限也非常明显:它是一个纯粹的专用智能体。学会下围棋的网络无法下象棋,更不可能完成任何非棋类任务。它的"智能"是在一个高度结构化、规则完全已知的封闭环境中训练出来的。
OpenAI Five:大规模强化学习的极致
如果说 AlphaGo 展示了在完全信息博弈中的突破,那么 OpenAI Five(2018-2019)则将挑战推向了复杂得多的不完全信息多人实时对战游戏 Dota 2。OpenAI Five 是首个能够在 Dota 2 中击败职业冠军队伍的智能体系统。

图 21-8:OpenAI Five 团队。五个独立的 LSTM 网络通过大规模 PPO 训练协作对战,最终在公测中对人类玩家取得 99.4% 的胜率。
OpenAI Five 的核心是一个大型的 LSTM 循环神经网络。每个英雄由一个独立的网络控制,网络的输入是一个约 20,000 维的游戏状态向量——注意,它不通过游戏画面获取信息,而是直接读取游戏后端 API 提供的结构化数据(英雄位置、血量、技能冷却、经济等)。网络的输出则包括各种动作的概率分布和价值预测。
通过 PPO(Proximal Policy Optimization)强化学习算法的大规模训练,OpenAI Five 自发涌现出了令人惊叹的策略行为:
- 团战中精确的站位协作
- 对经济节奏与推塔时机的把控
- 反打与绕后策略
- Roshan(关键中立怪物)的争夺时机
- 补刀、拉野等高级操作技巧
在公测阶段,OpenAI Five 在线对阵人类玩家的胜率达到了 99.4%。然而,必须指出的是,由于方法的限制,OpenAI Five 的能力几乎无法泛化到 Dota 2 之外的任何环境。它所依赖的 20,000 维特征向量是为 Dota 2 量身定制的,换一个游戏就需要从零开始。
Dreamer 系列:在"梦境"中学习的通用方案
DreamerV1 到 V4(2020-2025)系列提出了一种与 OpenAI Five 截然不同的思路。Dreamer 不依赖游戏专用的特征工程,而是直接从游戏画面像素出发,将图像编码到隐空间(Latent Space),在隐空间上展开训练。
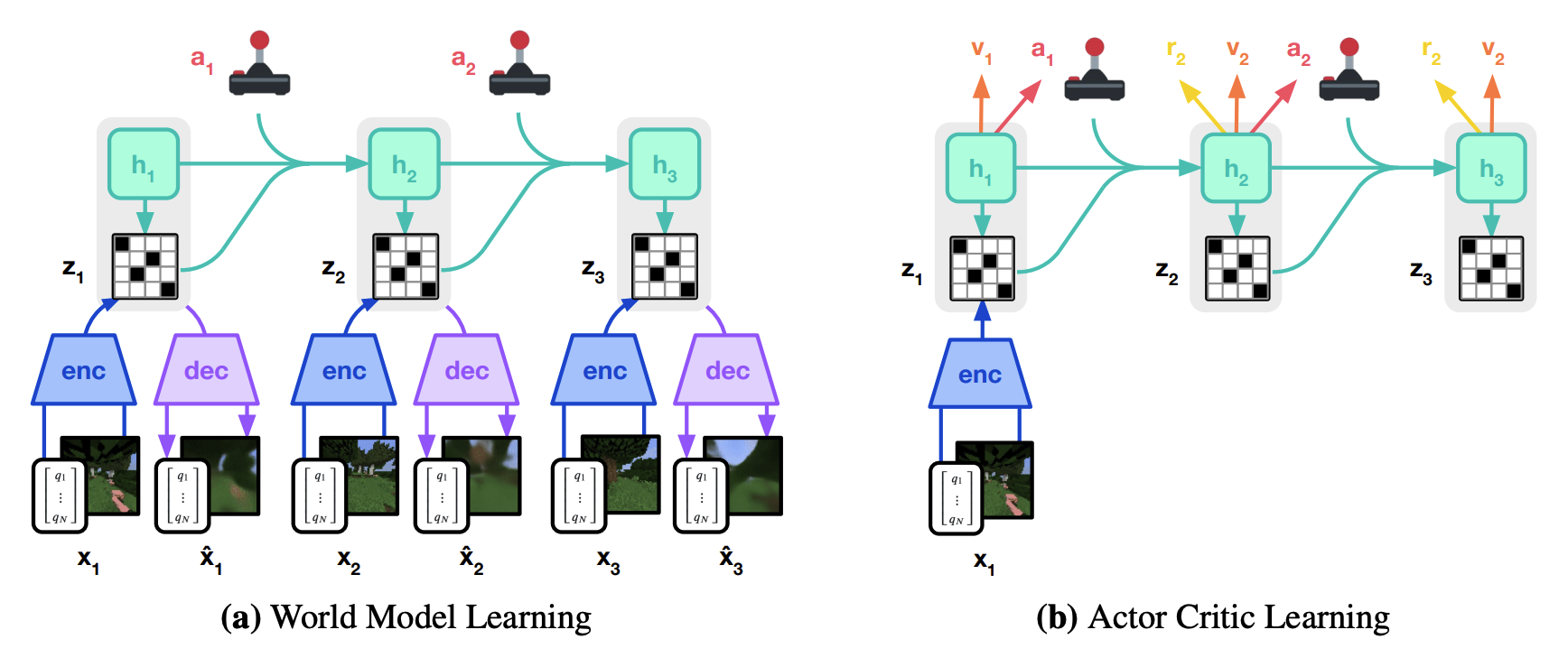
图 21-9:Dreamer 的架构。左侧展示世界模型学习:编码器将游戏画面编码为隐变量
Dreamer 的核心创新在于训练隐空间中的世界模型(World Model)。从当前状态的隐变量
# Dreamer 核心训练循环(简化)
def dreamer_training_step(world_model, actor, critic, replay_buffer):
# 1. 从经验池中采样真实轨迹
observations, actions, rewards = replay_buffer.sample()
# 2. 训练世界模型:编码观测、预测下一步
latents = world_model.encode(observations) # 图像 -> 隐变量
predicted_next = world_model.predict(latents, actions) # 预测下一隐变量
world_model_loss = reconstruction_loss + prediction_loss
world_model.update(world_model_loss)
# 3. 在"梦境"中展开想象轨迹
imagined_trajectory = []
h = latents[0]
for step in range(imagination_horizon):
action = actor(h) # 策略网络选择动作
h = world_model.predict(h, action) # 世界模型预测下一步
value = critic(h) # 价值网络评估状态
imagined_trajectory.append((h, action, value))
# 4. 用想象轨迹训练 Actor 和 Critic
actor.update(imagined_trajectory) # 最大化想象回报
critic.update(imagined_trajectory) # 准确预测想象价值这种"先学世界模型,再在想象中训练策略"的方案使 Dreamer 能够跨游戏通用——同一套架构无需修改就可以应用于 Atari、DeepMind Control Suite、Minecraft 等多种环境。DreamerV3 的论文发表在 Nature 上,作者称其为"通用的、跨领域的决策引擎"。
从专用到通用的第一次飞跃:AlphaGo 和 OpenAI Five 的成功依赖于大量领域特定的工程设计(棋盘特征、游戏 API 等),而 Dreamer 通过世界模型实现了从像素到决策的端到端学习,迈出了通向通用智能体的第一步。但它仍然需要大量的环境交互来训练,且每个新环境都需要重新训练。真正的通用性飞跃,要等到大语言模型的登场。
21.3.2 Voyager:LLM 智能体的里程碑
Voyager(Wang et al., 2023)诞生于 GPT-4 刚刚发布的大模型时代早期,却已经成功展示了一种全新的智能体构建范式:不需要环境交互训练,不需要奖励函数设计,仅通过精心设计的 Prompt 工作流,就能让大语言模型在 Minecraft 中进行持续的自主探索。Voyager 是 LLM 智能体领域公认的经典之作。
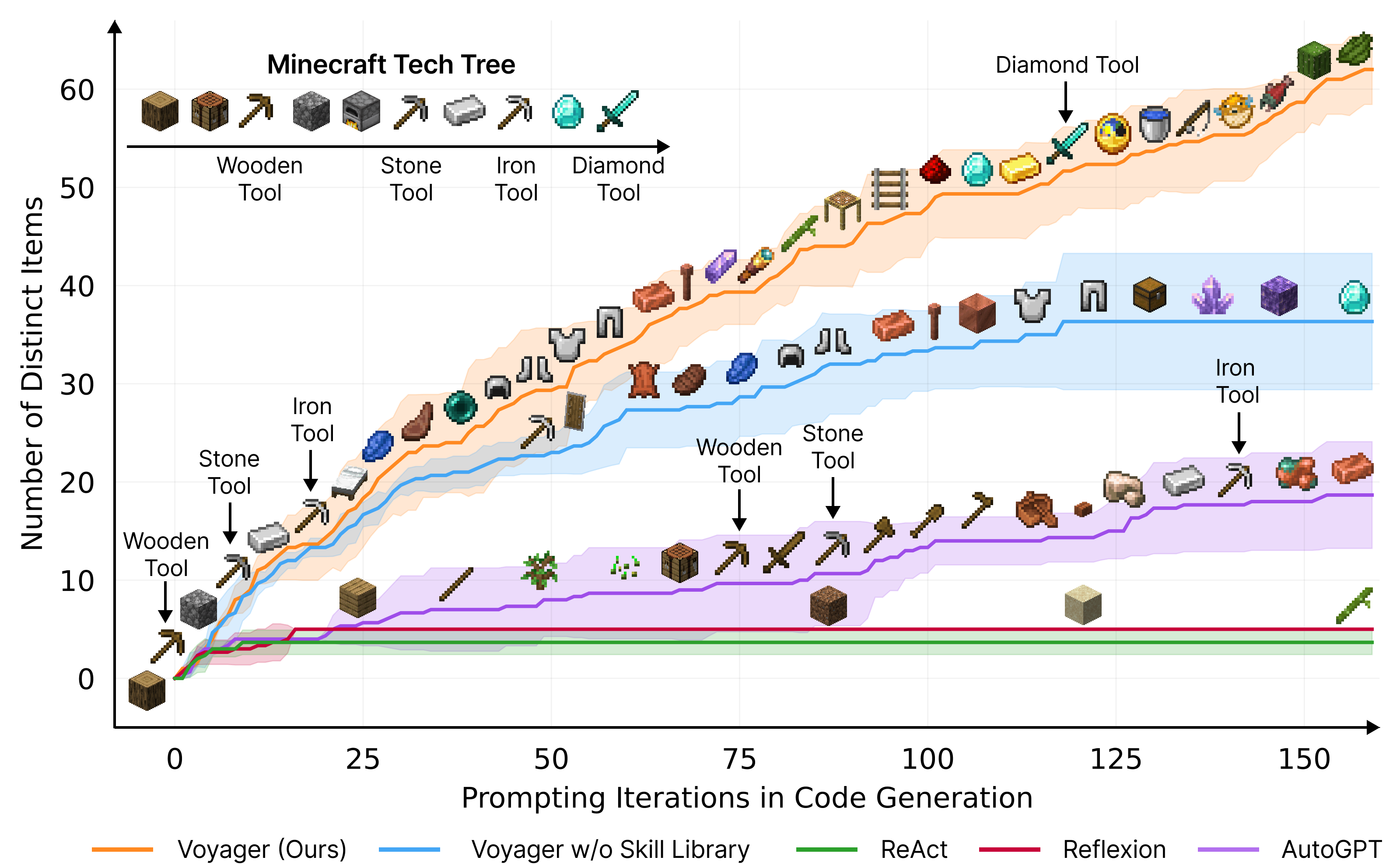
图 21-10:Voyager 的探索成果对比。横轴为代码生成的迭代轮次,纵轴为发现的不同物品数量。Voyager(橙色线)远超其他基线方法,成功解锁了从木制工具到钻石工具的完整科技树。
架构总览
Voyager 的核心设计理念是 "Code as Actions"——让 GPT-4 生成 JavaScript 代码作为游戏中的执行动作,而非直接输出离散的游戏操作。它通过 Mineflayer API(一个 Minecraft 的 JavaScript 编程接口)与游戏后端交互,将游戏状态以纯文本形式呈现给模型,再将模型生成的代码提交给 API 执行。
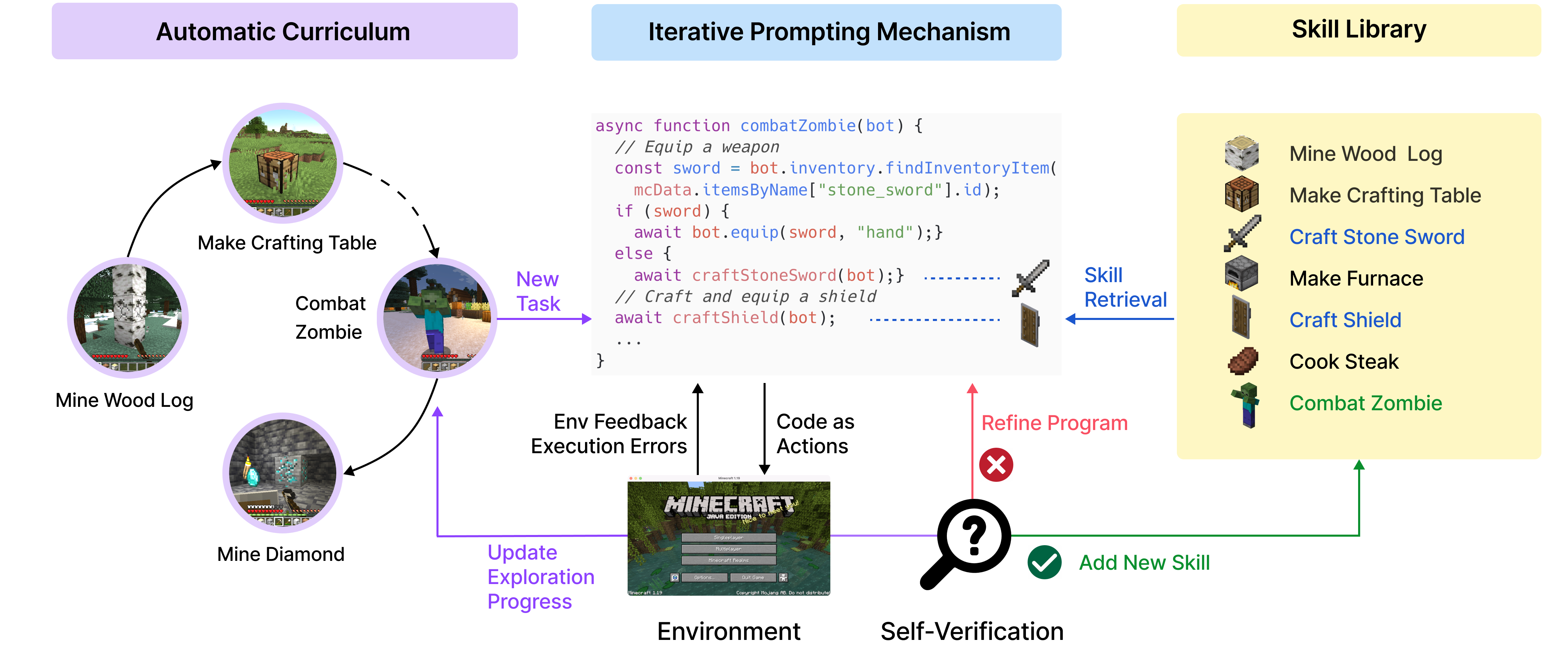
图 21-11:Voyager 的系统架构。左侧为自主课程(Automatic Curriculum),中间为迭代提示机制(Iterative Prompting),右侧为技能库(Skill Library)。三者协同工作,形成持续自我进化的闭环。
整个系统由三大核心组件构成,它们实际上都由 GPT-4 配合不同的 Prompt 实现:
1. 自主课程(Automatic Curriculum)
传统的强化学习需要人为设计奖励函数来引导智能体学习,但 Voyager 让 GPT-4 根据当前的探索进度自主提出下一步任务。模型会接收当前的物品栏状态、所处的生物群系、附近的实体信息,然后推理出合理的下一步目标。

图 21-12:自主课程的工作方式。GPT-4 根据当前物品栏和环境信息,推理出合理的下一步任务。例如:"既然你有了木镐和一些石头,升级到石镐会更高效。"
这种设计的精妙之处在于:GPT-4 在预训练中已经学习了大量关于 Minecraft 的知识(攻略、教程、Wiki 等),因此它天然具备制定合理探索策略的能力,无需任何额外训练。
2. 自我验证与反馈修正(Self-Verification)
每当一段代码被执行后,Voyager 会调用另一个 GPT-4 实例来评判任务是否完成。评判模型接收执行前后的物品栏变化、环境反馈以及可能的报错信息,给出"成功/失败"的判断,并在失败时提供改进建议(Critique)。

图 21-13:自我验证示例。GPT-4 根据物品栏变化和任务描述判断是否成功,失败时给出具体的改进建议。
如果任务失败,生成代码的模型会收到错误信息和改进建议,重新生成修改后的代码。这个迭代修正循环最多执行若干轮,直到任务成功或达到最大重试次数。

图 21-14:代码迭代修正示例。左图:模型发现缺少材料后,在代码中加入了自动获取材料的逻辑。右图:模型修正了错误的物品名称。
3. 技能库(Skill Library)
Voyager 最具创造性的设计是技能库——一个不断增长的代码仓库,存储所有成功执行过的代码片段。每个技能附带一段自然语言描述,通过文本嵌入(Embedding)建立索引。当面对新任务时,Voyager 通过检索增强(RAG)从技能库中找到最相关的已有技能,将它们作为参考加入 Prompt,帮助模型生成新的代码。
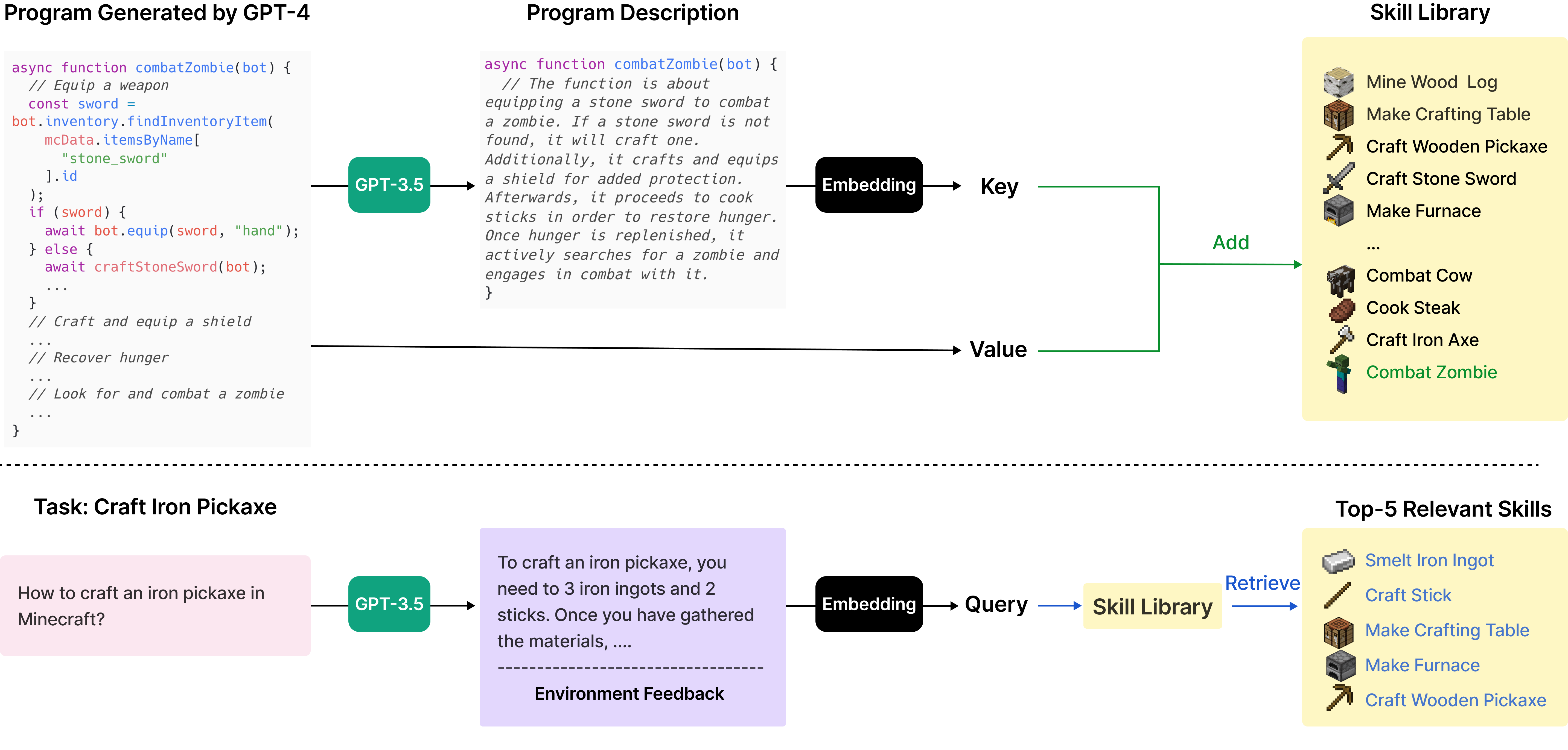
图 21-15:技能库的工作机制。上方展示技能的存储过程:成功的代码经 GPT-3.5 生成描述后以嵌入向量的形式加入库中。下方展示检索过程:新任务的描述同样被编码为向量,检索出最相关的已有技能作为参考。
用伪代码总结 Voyager 的完整工作流:
# Voyager 主循环(简化伪代码)
skill_library = SkillLibrary() # 初始为空的技能库
while exploring:
# 1. 自主课程:根据当前状态提出任务
game_state = get_game_state() # 物品栏、位置、生物群系等
task = gpt4_curriculum(game_state, exploration_history)
# 2. 技能检索:从技能库中找到相关已有技能
relevant_skills = skill_library.retrieve(task, top_k=5)
for attempt in range(max_retries):
# 3. 代码生成:结合任务、游戏状态、已有技能生成代码
code = gpt4_generate_code(task, game_state, relevant_skills)
# 4. 执行并获取反馈
result, errors = mineflayer_execute(code)
# 5. 自我验证:判断任务是否成功
success, critique = gpt4_verify(task, game_state, result)
if success:
# 6. 成功的代码加入技能库
description = gpt4_describe_skill(code)
skill_library.add(code, description)
break
else:
# 失败时将错误信息和改进建议加入下一轮 Prompt
game_state.update(errors=errors, critique=critique)为什么 Voyager 如此重要? 它开创性地证明了:大语言模型的预训练知识可以直接作为智能体的"先验策略",不需要强化学习训练就能完成复杂的开放世界探索任务。"Code as Actions"的范式也为后续大量 LLM 智能体工作提供了核心灵感。
21.3.3 Lumine:视觉语言模型驱动的游戏智能体
如果说 Voyager 通过 API 获取结构化的游戏信息,那么字节跳动 Seed 团队于 2025 年公布的 Lumine 则走向了另一个极端——完全模拟人类的输入输出方式。Lumine 直接观看游戏画面,通过输出键盘和鼠标指令来操控角色,就像一个真正坐在电脑前玩游戏的人类玩家。

图 21-16:Lumine 项目。左图:Lumine 模拟人类玩家坐在电脑前玩原神。右图:它需要具备探索、策略、交互、规划等多种能力才能完成开放世界的各类任务。
模型架构
Lumine 建立在 Qwen2-VL-7B-Base 视觉语言模型之上,采用端到端的 Vision-Language 模式。模型接收 720P、5FPS 的游戏画面序列作为视觉输入,以特定格式的文本输出来操控鼠标和键盘——这些动作文本同时会参与到 Transformer 后续的自回归生成中,使模型能根据自己之前的操作来决定接下来的行为。
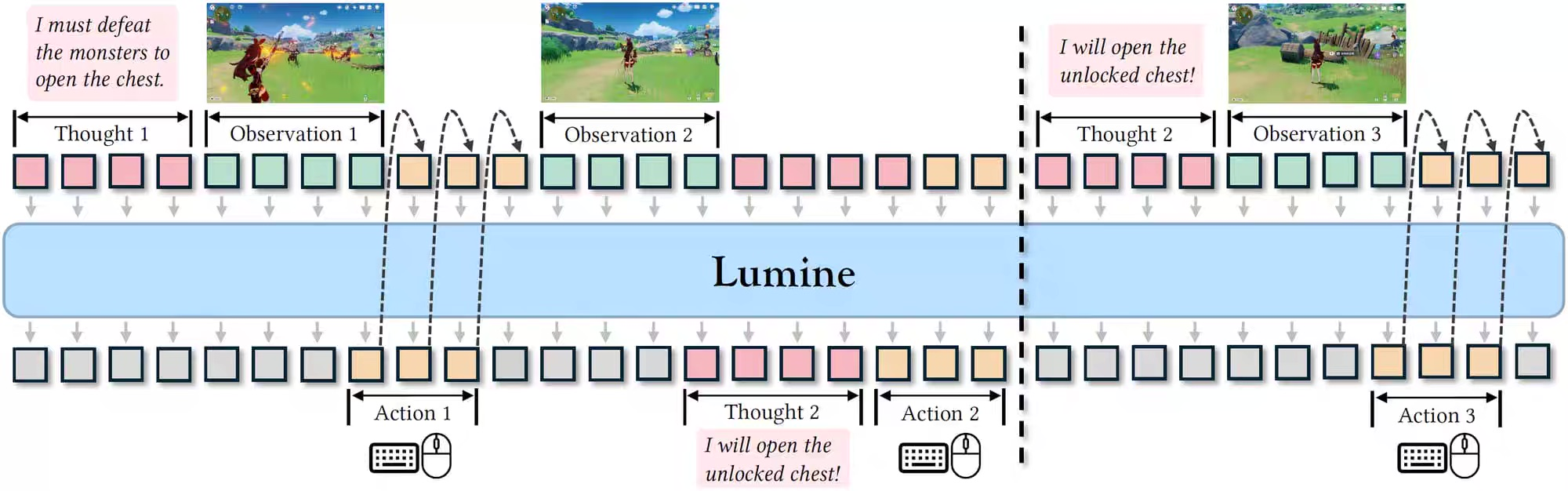
图 21-17:Lumine 的推理过程。模型交替生成"思考"(Thought)和"动作"(Action),观测游戏画面后先推理当前局势("我需要打败怪物才能开箱子"),再输出具体的操控指令。
训练方案
Lumine 的训练策略同样值得关注——它没有使用强化学习或复杂的工作流编排,而是采用了数据工程 + SFT(监督微调) 的方案:
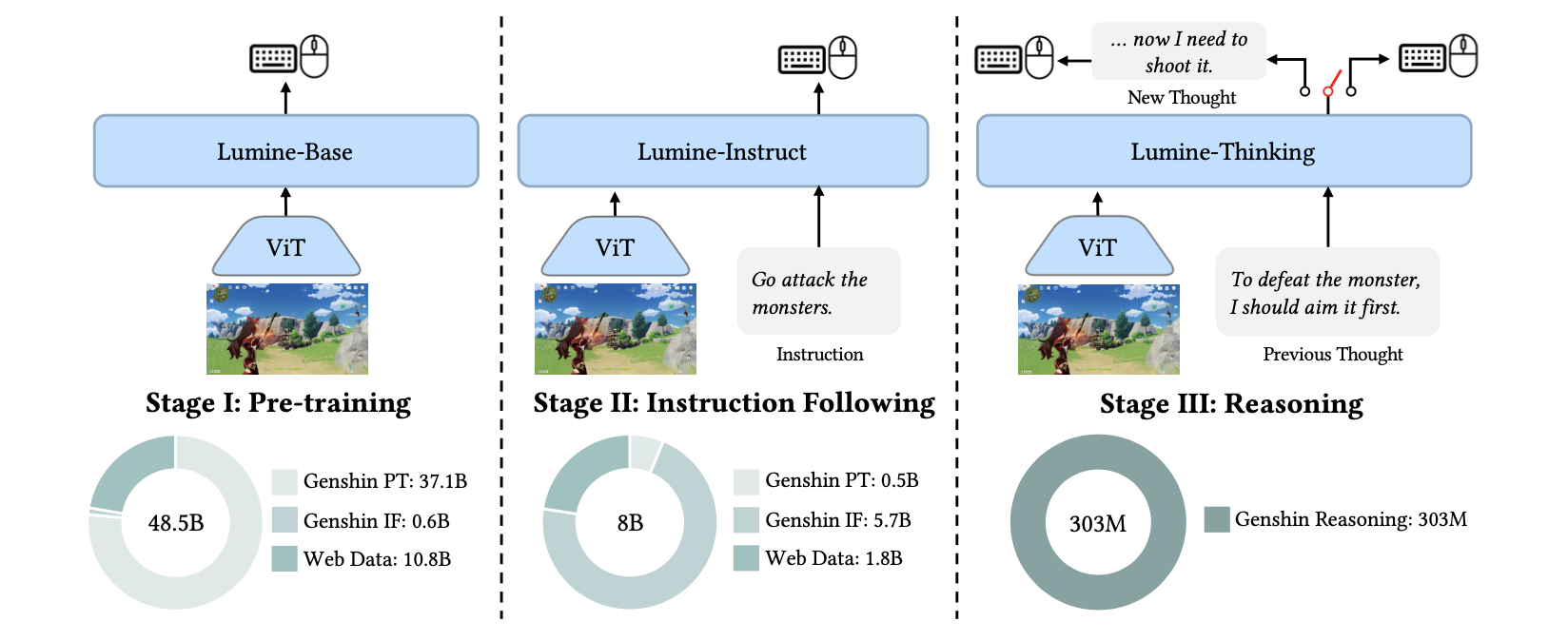
图 21-18:Lumine 的三阶段训练流程。从预训练(大规模游玩数据)到指令跟随(添加文字指令),再到推理增强(加入 Thinking 能力)。
团队首先收集了 2424 小时带有键盘/鼠标操作记录的人类游玩录像。经过精细的标注和清洗后,数据被划分为三个阶段使用:
- 预训练阶段(Lumine-Base):使用大量游玩录像训练模型的基本操控能力,让模型学会"看到画面后做什么"
- 指令跟随阶段(Lumine-Instruct):在录像上添加自然语言指令标注,训练模型按照文字指令执行任务
- 推理增强阶段(Lumine-Thinking):加入显式的"思考"步骤,使模型在执行动作前先进行自然语言推理
Lumine 成功完成了原神中约五小时的蒙德主线任务。更令人兴奋的是,这种能力表现出了显著的跨游戏迁移能力——在原神上训练的模型可以直接在崩坏:星穹铁道和鸣潮等游戏中运行,无需针对新游戏重新训练。这种迁移能力得益于 VLM 的通用视觉理解能力和统一的键鼠操控输出格式。
21.3.4 Agent Hospital:模拟环境中的医疗智能体
将目光从游戏转向现实应用,Agent Hospital(Li et al., 2024)展示了 LLM 智能体在医疗诊断领域的潜力。它构建了一个完整的模拟医院环境,让多个大模型驱动的智能体在其中扮演不同角色——医生、患者、检验科医师等——通过反复的模拟诊疗交互来积累医学经验。
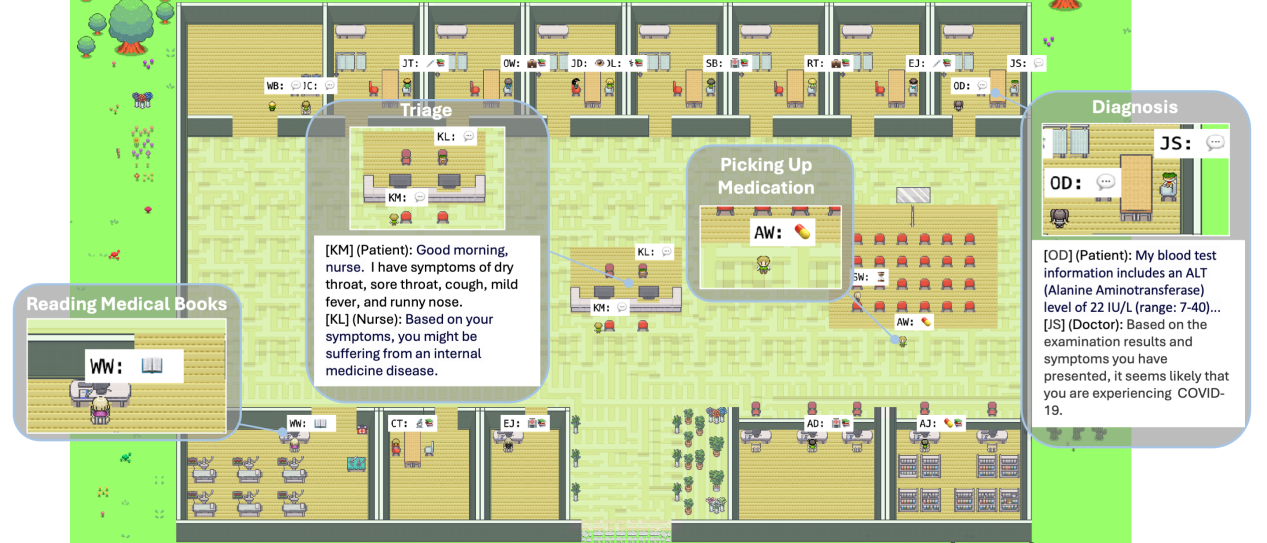
图 21-19:Agent Hospital 的模拟医院环境。系统模拟了挂号大厅、诊室、检验科、药房等完整的医院科室布局。患者智能体描述症状,医生智能体进行问诊、开具检查、作出诊断,整个过程完全由 LLM 驱动。
Agent Hospital 的核心思想可以概括为**"在模拟中学习,在真实中应用"**:
- 环境构建:搭建包含多个科室的虚拟医院,定义完整的就诊流程(挂号 -> 问诊 -> 检查 -> 诊断 -> 治疗)
- 角色分配:患者智能体根据预设的疾病档案描述症状,医生智能体通过多轮问诊收集信息
- 经验积累:每次诊疗结束后,医生智能体会获得反馈(诊断是否正确),并将成功和失败的案例都记录到经验库中
- 持续学习:在后续的诊疗中,医生智能体会检索过往的相似病例作为参考,逐步提升诊断准确率
# Agent Hospital 诊疗流程(简化伪代码)
class DoctorAgent:
def __init__(self, llm, experience_db):
self.llm = llm
self.experience_db = experience_db # 经验数据库
def diagnose(self, patient_description):
# 1. 检索相似病例经验
similar_cases = self.experience_db.retrieve(patient_description)
# 2. 多轮问诊收集信息
conversation = [patient_description]
for _ in range(max_questions):
question = self.llm.generate(
prompt=f"已有信息: {conversation}\n相似病例: {similar_cases}\n"
f"请提出下一个诊断性问题:"
)
answer = patient_agent.respond(question)
conversation.append((question, answer))
# 3. 综合所有信息给出诊断
diagnosis = self.llm.generate(
prompt=f"患者信息: {conversation}\n参考病例: {similar_cases}\n"
f"请给出诊断结果和治疗方案:"
)
return diagnosis
def learn_from_feedback(self, case, correct_diagnosis, was_correct):
# 4. 将本次诊疗记录为经验
self.experience_db.store(case, correct_diagnosis, was_correct)经过大量模拟诊疗的迭代学习后,Agent Hospital 中的医生智能体在多种疾病的诊断准确率上超越了人类专家医师的水准。这一结果表明,LLM 智能体通过在模拟环境中的大规模练习,可以系统性地积累和应用领域知识。
21.3.5 Hilbert:混合编排的数学证明智能体
数学定理的形式化证明是人工智能领域的一座高峰。Hilbert(Zhao et al., 2025)展示了一种令人印象深刻的方案:混合编排自然语言推理大模型与形式化证明器,以极低的工程成本实现了远超专用证明模型的性能。

图 21-20:Hilbert 的递归证明工作流。Prover 尝试直接证明目标定理,失败后进行子目标分解(Subgoal Decomposition),将问题拆分为更小的子定理,再递归地对每个子目标重复"证明 -> 分解"的过程。
Hilbert 的工作流巧妙地将两种截然不同的能力结合在一起:
- 推理器(Reasoner):一个通用的大语言模型(如 GPT-4 或 Claude),负责进行自然语言的数学推理,生成证明草稿(Proof Sketch)
- 证明器(Prover):利用 LLM 将自然语言推理翻译为形式化证明语言(如 Lean 4),尝试填充证明中的每一步
- 验证器(Verifier):形式化验证工具(如 Lean 的类型检查器),对证明的正确性给出确定性的判断——要么通过,要么不通过,没有灰色地带
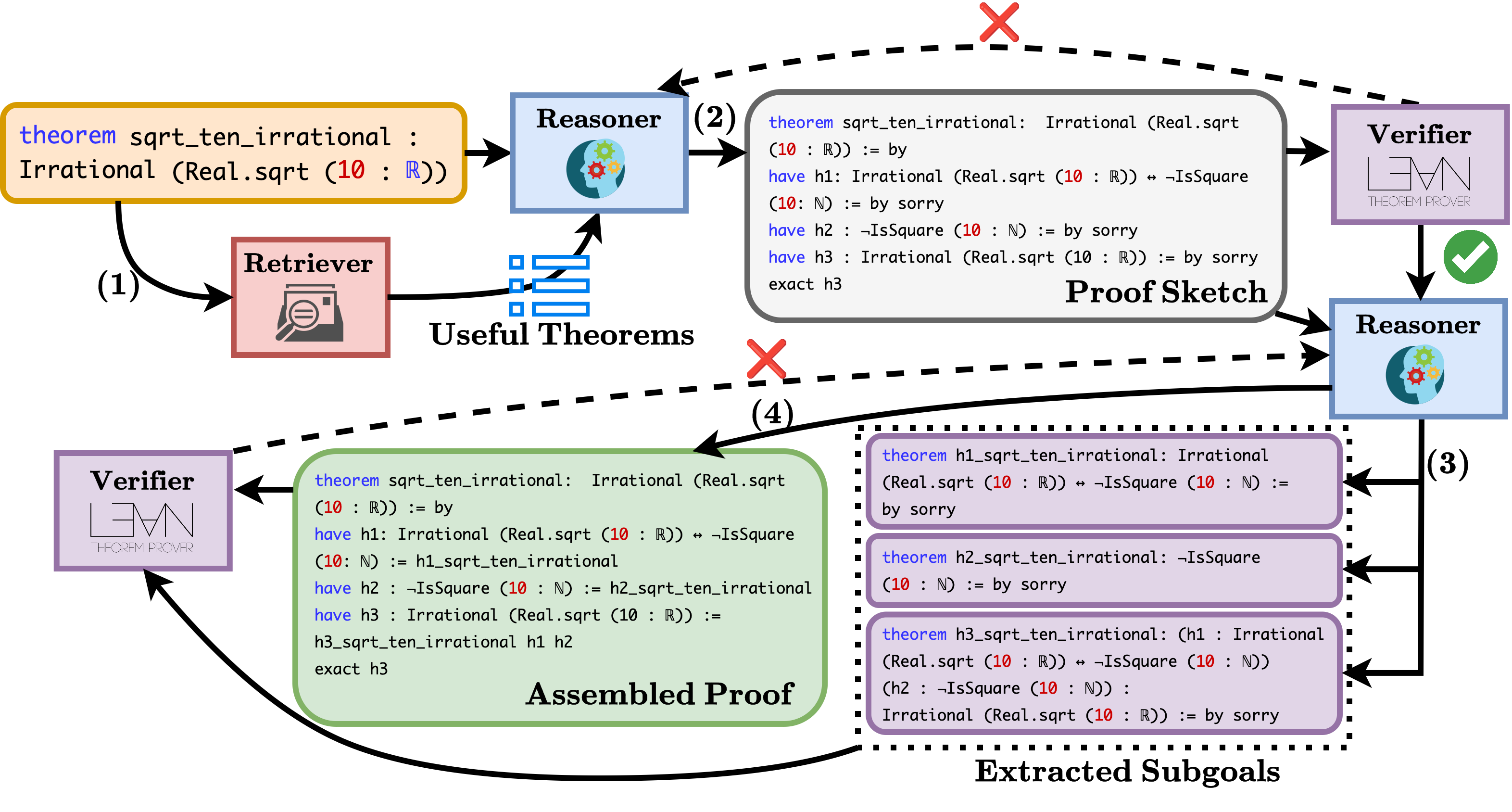
图 21-21:Hilbert 的完整证明过程示例。(1) 检索相关已证明的定理作为参考;(2) Reasoner 生成证明草稿;(3) 提取子目标并分别证明;(4) 将所有子证明组装为完整的形式化证明,最终由 Verifier 验证通过。
Hilbert 的关键设计洞察在于:自然语言大模型擅长高层次的数学推理和策略规划("这个定理可以通过先证明 A 再利用 A 推出 B 来解决"),但不擅长精确的形式化表述;而形式化证明器恰恰相反,它无法自主发现证明策略,但可以对给定的证明进行绝对严格的验证。将两者编排在一起,就形成了互补的智能体系统。
# Hilbert 工作流(简化伪代码)
def hilbert_prove(theorem, retriever, reasoner, prover, verifier, depth=0):
if depth > max_depth:
return None # 递归深度限制
# 1. 检索相关的已证明定理
useful_theorems = retriever.search(theorem)
# 2. Prover 直接尝试证明
proof = prover.attempt(theorem, useful_theorems)
if verifier.check(proof):
return proof # 直接成功
# 3. 直接证明失败 -> Reasoner 生成证明草稿
sketch = reasoner.generate_sketch(theorem, useful_theorems)
# 4. 从草稿中提取子目标
subgoals = extract_subgoals(sketch)
# 5. 递归证明每个子目标
sub_proofs = []
for subgoal in subgoals:
sub_proof = hilbert_prove(
subgoal, retriever, reasoner, prover, verifier, depth + 1
)
if sub_proof is None:
return None # 某个子目标无法证明
sub_proofs.append(sub_proof)
# 6. 组装完整证明并验证
full_proof = assemble_proof(theorem, sub_proofs)
if verifier.check(full_proof):
return full_proof
return NoneHilbert 的成功传递了一个重要信息:在许多需要严格正确性保证的领域,让 LLM 负责创造性推理、让专用工具负责验证的混合编排模式,往往比端到端地训练一个专用模型更加有效且成本更低。
21.3.6 从专用到通用:智能体的演进轨迹
回顾本节介绍的所有案例,我们可以清晰地看到智能体技术的演进脉络:
| 阶段 | 代表系统 | 感知方式 | 决策方式 | 通用性 |
|---|---|---|---|---|
| 专用 RL 智能体 | AlphaGo (2016) | 棋盘特征 | MCTS + 策略/价值网络 | 仅限围棋 |
| 大规模 RL 智能体 | OpenAI Five (2018) | 20K 维特征向量 | LSTM + PPO | 仅限 Dota 2 |
| 通用 RL 智能体 | Dreamer (2020-2025) | 游戏画面像素 | 世界模型 + Actor-Critic | 多种游戏通用 |
| LLM 工作流智能体 | Voyager (2023) | 游戏 API 文本 | GPT-4 代码生成 | 零训练即用 |
| VLM 端到端智能体 | Lumine (2025) | 游戏画面 | VLM 直接输出操控指令 | 跨游戏迁移 |
| 领域模拟智能体 | Agent Hospital (2024) | 文本对话 | LLM 多角色协作 | 领域经验积累 |
| 混合编排智能体 | Hilbert (2025) | 定理文本 | LLM 推理 + 形式化验证 | 数学证明通用 |
这条演进路径揭示了几个关键趋势:
第一,从手工特征到端到端感知。 AlphaGo 和 OpenAI Five 都依赖精心设计的特征工程来表示环境状态,而 Dreamer 和 Lumine 直接从原始像素学习,感知模块变得越来越通用。
第二,从大量训练到零样本迁移。 早期的 RL 智能体每换一个环境就需要从零训练数百万步,而 Voyager 凭借 GPT-4 的预训练知识实现了零训练的自主探索,Lumine 则展示了跨游戏的迁移能力。
第三,从单一模型到多组件协作。 现代 LLM 智能体不再依赖一个单一的神经网络完成所有工作,而是通过精心编排多个专长不同的模块(规划器、执行器、验证器、记忆库)来解决复杂任务。Hilbert 将这一理念发挥到了极致——让 LLM 做它擅长的推理,让形式化工具做它擅长的验证。
第四,"Code as Actions" 成为核心范式。 Voyager 开创的"让模型生成代码来执行动作"的思路,已经成为当前编码智能体(Coding Agent)、计算机使用智能体(Computer Use Agent)等众多系统的基石。代码既是精确的行动指令,又是可复用的知识载体——这正是技能库得以运作的基础。
从 AlphaGo 到 Voyager,从专用到通用,智能体技术正在经历从"训练一个能做特定事情的模型"到"编排一个能做任何事情的系统"的范式转换。这一转换的底层驱动力,正是大语言模型作为通用推理引擎所提供的前所未有的灵活性。在下一节中,我们将深入探讨支撑这些系统的核心技术——工具调用与函数调用机制。