16.1 DPO(直接偏好优化)
在上一章中,我们详细讨论了 RLHF 的标准流程:先训练奖励模型(Reward Model),再通过 PPO 等在线强化学习算法优化策略模型。这个流程虽然有效,但代价不菲——需要同时维护 四个模型(Actor、Critic、Reward Model、Reference Model),训练过程复杂且容易发散。2023 年,Rafailov 等人提出了 DPO(Direct Preference Optimization,直接偏好优化),用一个精巧的数学变换将整个 RLHF 流程压缩为一个简单的分类损失函数,彻底绕过了显式奖励模型和在线采样。
本节将从 RLHF 的目标函数出发,完整推导 DPO 的数学原理,然后从零实现 DPO 损失函数,最后介绍如何使用 trl 库的 DPOTrainer 进行实战训练。
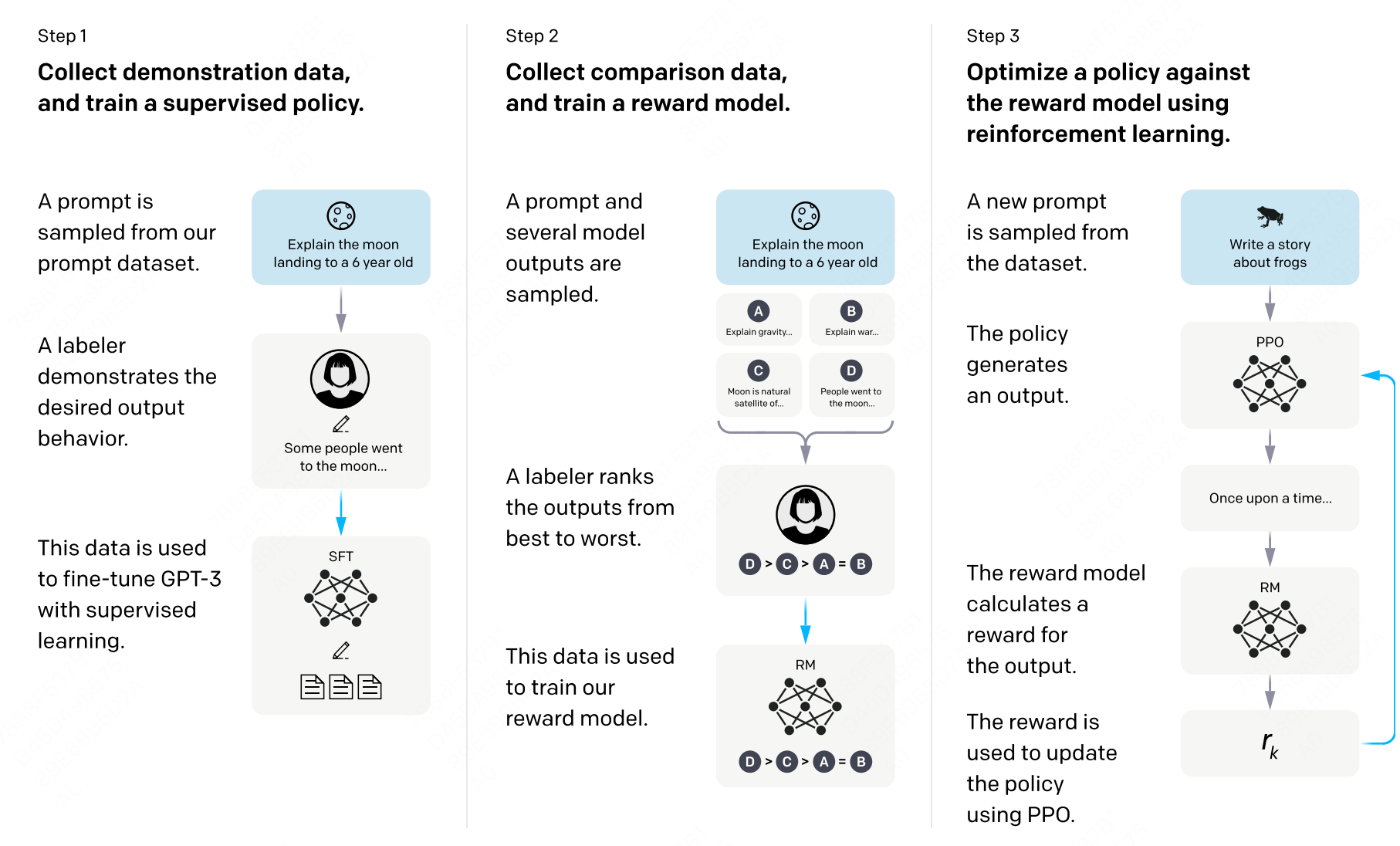
图 16-1:RLHF 标准三阶段流程。DPO 将奖励模型训练和强化学习两个阶段合并为一步直接优化。
16.1.1 从 RLHF 到 DPO:为什么要"绕过"奖励模型?
回顾 RLHF-PPO 的训练流程,它需要同时管理四个模型:
| 模型 | 作用 | 是否训练 |
|---|---|---|
| Actor Model | 待优化的策略语言模型 | 是 |
| Critic Model | 预估状态价值(优势函数计算) | 是 |
| Reward Model | 对生成结果打分 | 否(冻结) |
| Reference Model | KL 约束的锚点 | 否(冻结) |
这种设计带来三个核心痛点:
- 工程复杂度高:四个模型需要同时加载到 GPU,显存开销巨大;PPO 的实现涉及 37 条以上的工程细节。
- 训练不稳定:在线采样、优势函数估计、裁剪比率等环节都可能引入不稳定性。
- 超参数敏感:clip range、KL 系数、学习率衰减策略等需要精细调优。
DPO 的核心洞察是:最优策略与奖励函数之间存在解析关系(closed-form relationship)。如果我们能用策略模型的参数直接表达奖励,就不需要单独训练奖励模型,也不需要在线强化学习——整个对齐过程退化为一个类似 SFT 的监督学习问题。
图 16-2:PPO 与 DPO 的结构对比。DPO 通过数学变换省去了奖励模型训练和在线 RL 两个阶段。
16.1.2 DPO 的数学推导 [必读]
DPO 的推导链条清晰而优美,分为四步:写出最优策略的解析解、反推奖励函数、代入 Bradley-Terry 偏好模型、得到最终损失函数。
第一步:KL 正则化 RLHF 目标的最优策略
RLHF 的标准目标函数为:
其中
将最大化问题转为最小化问题并整理:
其中
由于 KL 散度非负且当两个分布相同时取到最小值 0,最优策略的解析形式为:
直觉理解:最优策略在参考策略的基础上,按奖励的指数进行"重加权"——奖励越高的回复,概率被放大得越多,
控制放大的幅度。
第二步:从策略反推奖励(重参数化)
对最优策略公式两边取对数并整理,得到奖励的重参数化表达:
核心发现:奖励可以完全由策略与参考策略的对数比率表示(加上一个只依赖于 prompt
第三步:代入 Bradley-Terry 偏好模型
Bradley-Terry(BT)模型假设人类偏好由潜在奖励决定:
其中
将重参数化的奖励代入上式:
关键:
第四步:最大似然 → DPO 损失函数
给定偏好数据集
定义隐式奖励(Implicit Reward):
则 DPO 损失可以简洁地写为:
一句话总结推导:DPO 先证明最优策略与奖励有解析关系,再利用这个关系把奖励"替换"为策略的对数比率,代入偏好模型后配分函数消去,最终得到一个只需要策略模型和参考模型的监督损失。
16.1.3 DPO 梯度的直觉解读 [选读]
对 DPO 损失求梯度,可以得到:
这个梯度有非常清晰的直觉:
- 第一部分
:提高优选回复的概率(与 SFT 梯度方向相同)。 - 第二部分
:降低劣选回复的概率("远离坏回答")。 - 权重
:当模型"判断错误"(即隐式奖励给了 更高分)时, 接近 1,梯度很强;当模型已经"判断正确"时, 接近 0,梯度很弱。
这实际上是一种隐式的困难样本挖掘(Hard Negative Mining)——模型自动把更多的学习力度分配给它尚未正确区分的偏好对。
16.1.4 DPO 损失函数的从零实现
下面我们用 PyTorch 从零实现 DPO 损失函数。代码完全自包含,可以直接运行。
import torch
import torch.nn.functional as F
def compute_log_probs(logits: torch.Tensor, labels: torch.Tensor,
mask: torch.Tensor) -> torch.Tensor:
"""
计算序列的平均对数概率。
Args:
logits: 模型输出 logits, shape [B, T, V]
labels: 目标 token ids, shape [B, T]
mask: 有效位置掩码, shape [B, T] (1=有效, 0=padding)
Returns:
每个序列的平均 log probability, shape [B]
"""
# 将 logits 转为 log_softmax
log_softmax = F.log_softmax(logits, dim=-1)
# 取出目标 token 对应的 log prob: [B, T]
per_token_logp = torch.gather(
log_softmax[:, :-1, :], dim=-1, index=labels[:, 1:].unsqueeze(-1)
).squeeze(-1)
# 对齐 mask(跳过第一个位置)
mask = mask[:, 1:]
# 按 mask 求平均 log prob
seq_lengths = mask.sum(dim=1).clamp(min=1)
avg_log_prob = (per_token_logp * mask).sum(dim=1) / seq_lengths
return avg_log_prob
def dpo_loss(policy_chosen_logps: torch.Tensor,
policy_rejected_logps: torch.Tensor,
ref_chosen_logps: torch.Tensor,
ref_rejected_logps: torch.Tensor,
beta: float = 0.1,
label_smoothing: float = 0.0) -> tuple:
"""
计算 DPO 损失。
Args:
policy_chosen_logps: 当前策略对优选回复的 log P, shape [B]
policy_rejected_logps: 当前策略对劣选回复的 log P, shape [B]
ref_chosen_logps: 参考模型对优选回复的 log P, shape [B]
ref_rejected_logps: 参考模型对劣选回复的 log P, shape [B]
beta: KL 正则化系数
label_smoothing: 标签平滑系数 (0 = 标准 DPO)
Returns:
(loss, chosen_rewards, rejected_rewards)
"""
# 计算隐式奖励 r_hat = beta * log(pi / pi_ref)
chosen_rewards = beta * (policy_chosen_logps - ref_chosen_logps)
rejected_rewards = beta * (policy_rejected_logps - ref_rejected_logps)
# logits = r_hat(y_w) - r_hat(y_l)
logits = chosen_rewards - rejected_rewards
# DPO 损失(含可选的标签平滑)
losses = (
-F.logsigmoid(logits) * (1 - label_smoothing)
- F.logsigmoid(-logits) * label_smoothing
)
loss = losses.mean()
return loss, chosen_rewards.detach(), rejected_rewards.detach()
# ==================== 验证示例 ====================
if __name__ == "__main__":
torch.manual_seed(42)
B = 4 # batch size
# 模拟:策略模型对优选回复给出更高概率
policy_chosen = torch.tensor([-2.0, -2.5, -1.8, -2.2])
policy_rejected = torch.tensor([-3.5, -4.0, -3.2, -3.8])
# 参考模型的概率(作为 baseline)
ref_chosen = torch.tensor([-2.5, -2.8, -2.3, -2.6])
ref_rejected = torch.tensor([-3.2, -3.5, -3.0, -3.4])
loss, r_chosen, r_rejected = dpo_loss(
policy_chosen, policy_rejected,
ref_chosen, ref_rejected,
beta=0.1
)
print(f"DPO Loss: {loss.item():.4f}")
print(f"Chosen rewards: {r_chosen.tolist()}")
print(f"Rejected rewards: {r_rejected.tolist()}")
print(f"Reward margin: {(r_chosen - r_rejected).mean().item():.4f}")
# 验证:loss 应接近 -log(sigmoid(正数)) ≈ 较小正数
# chosen_rewards > rejected_rewards 说明模型正确偏好了优选回复运行结果示例:
DPO Loss: 0.6565
Chosen rewards: [0.05, 0.03, 0.05, 0.04]
Rejected rewards: [-0.03, -0.05, -0.02, -0.04]
Reward margin: 0.0762代码要点解读:
- 长度归一化:
compute_log_probs中除以了序列有效长度,计算的是平均每 token 的对数概率。这是一个常用的工程 trick——如果不做归一化,长回复的累积 log prob 绝对值天然更大,会导致训练偏向短回复。 - Label Smoothing:当
label_smoothing > 0时,损失函数不再完全相信标注——它混入一小部分"反向目标",防止模型过于极端地拉大偏好差距。 - 隐式奖励追踪:
chosen_rewards和rejected_rewards使用.detach()脱离计算图,仅用于监控训练进展。在健康的 DPO 训练中,前者应逐步上升,后者应逐步下降。
16.1.5 使用 trl DPOTrainer 实战训练
在实际项目中,不必从零实现 DPO——HuggingFace 的 trl 库提供了开箱即用的 DPOTrainer。
数据格式
DPO 需要偏好数据集(Preference Dataset),每条样本包含三个字段:
# 标准格式(推荐显式 prompt)
preference_example = {
"prompt": "解释什么是机器学习",
"chosen": "机器学习是人工智能的一个分支,它通过数据驱动的方式...",
"rejected": "机器学习就是让电脑自己学习,不需要编程..."
}
# 对话格式(多轮对话场景)
preference_example = {
"prompt": [{"role": "user", "content": "解释什么是机器学习"}],
"chosen": [{"role": "assistant", "content": "机器学习是人工智能的..."}],
"rejected": [{"role": "assistant", "content": "机器学习就是..."}]
}最简训练代码
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset
# 加载偏好数据集
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
# 配置训练参数
training_args = DPOConfig(
output_dir="./dpo_output",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=5e-7, # DPO 通常使用较低学习率
beta=0.1, # KL 正则化系数
loss_type="sigmoid", # 标准 DPO 损失
num_train_epochs=1,
logging_steps=10,
bf16=True,
)
# 创建 Trainer 并训练
trainer = DPOTrainer(
model="Qwen/Qwen3-0.6B",
args=training_args,
train_dataset=dataset,
)
trainer.train()结合 LoRA 低秩适配
对于大模型,通常使用 LoRA 进行参数高效训练:
from trl import DPOTrainer, DPOConfig
from datasets import load_dataset
from peft import LoraConfig
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
# LoRA 配置
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
task_type="CAUSAL_LM",
)
training_args = DPOConfig(
output_dir="./dpo_lora_output",
per_device_train_batch_size=4,
learning_rate=1e-5, # LoRA 适配器通常使用较高学习率
beta=0.1,
num_train_epochs=1,
bf16=True,
)
trainer = DPOTrainer(
model="Qwen/Qwen3-0.6B",
args=training_args,
train_dataset=dataset,
peft_config=peft_config,
)
trainer.train()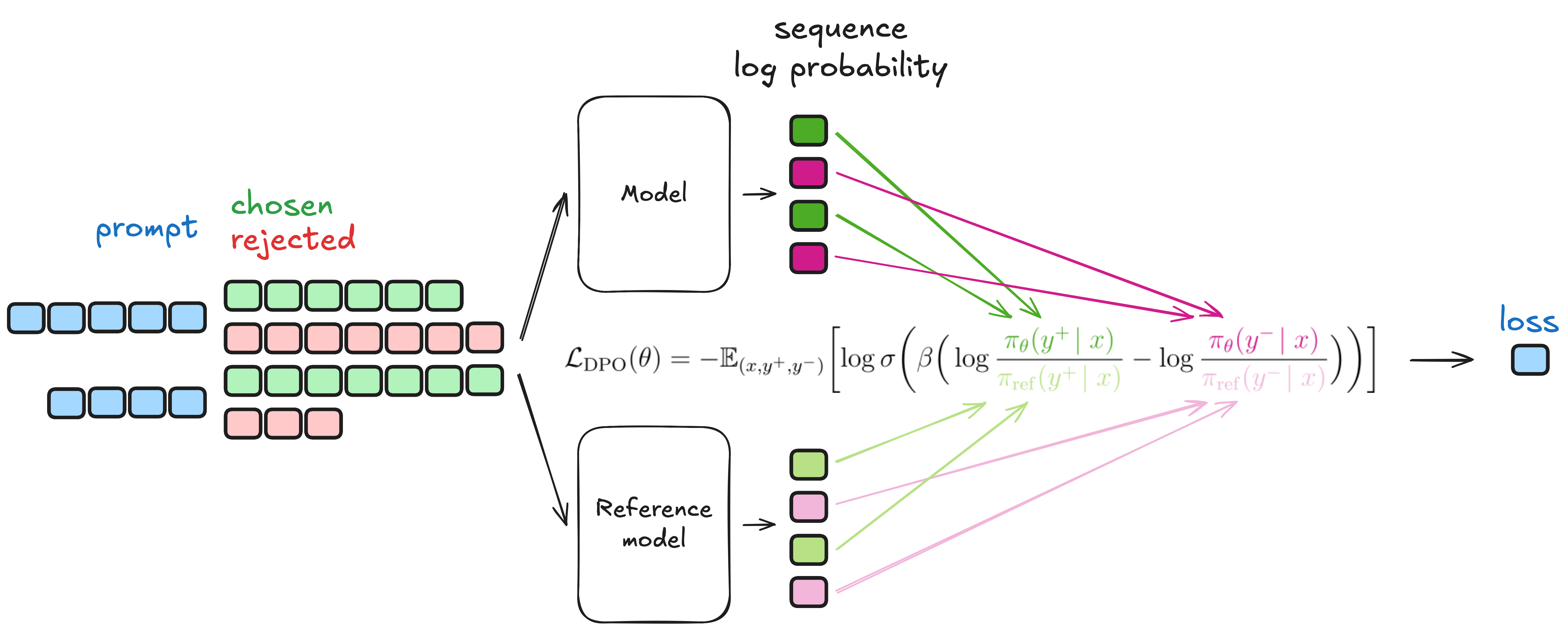
图 16-3:DPO 损失计算流程(图源:trl 文档)。策略模型和参考模型分别对优选和劣选回复计算对数概率,经 logsigmoid 变换得到最终损失。
DPOTrainer 的关键监控指标
训练过程中应关注以下指标以判断训练是否健康:
| 指标 | 含义 | 健康趋势 |
|---|---|---|
rewards/chosen | 优选回复的隐式奖励 | 逐步上升 |
rewards/rejected | 劣选回复的隐式奖励 | 逐步下降 |
rewards/margins | 两者之差 | 逐步增大 |
rewards/accuracies | 隐式奖励正确排序偏好对的比例 | 逐步趋近 1.0 |
logps/chosen | 策略对优选回复的 log prob | 变化不宜过大 |
图 16-4:DPO 训练曲线示例。左图为 loss 下降曲线,中图为学习率调度,右图为每 epoch 耗时。
16.1.6 DPO 与 PPO 的全面对比
| 特性 | PPO | DPO |
|---|---|---|
| 训练阶段 | 两阶段:先 RM 训练,再 RL 微调 | 单阶段:直接用偏好数据优化策略 |
| 所需模型数 | 4 个(Actor + Critic + RM + Ref) | 2 个(策略 + 参考模型) |
| 采样方式 | On-Policy(需在线生成回复) | Off-Policy(使用离线偏好数据) |
| 训练稳定性 | 依赖 RL 技巧,需精细调参 | 类似监督学习,相对稳定 |
| 计算开销 | 高(多模型 + 在线采样 + GAE 计算) | 低(仅前向传播 + 损失计算) |
| 超参数 | clip range、KL 系数、GAE | 主要是 |
| 探索能力 | 有(在线采样可发现新回复) | 无(受限于离线数据分布) |
| 奖励过优化风险 | 可能 hack 奖励模型 | 不存在(无显式奖励模型) |
核心权衡:DPO 用简单性换取了探索能力。PPO 通过在线采样可以不断发现新的、更好的回复,而 DPO 只能在已有数据上学习区分好坏。这意味着当偏好数据覆盖面不足时(例如数学推理场景中正确答案可以被验证但偏好数据稀疏),PPO 可能更具优势。
16.1.7 DPO 的局限与变体 [选读]
DPO 虽然简洁优雅,但并非没有缺陷。社区在此基础上发展出了多种改进方案。
Off-Policy 的局限。 DPO 是离线算法——它使用预先收集的偏好数据训练,不从当前策略采样。这意味着随着训练进行,策略
长度偏差。 研究表明 DPO 训练的模型倾向于生成更长的回复,因为更长的文本在 log probability 上有更大的"操作空间"被优化。SimPO 通过引入长度归一化来缓解这一问题。
主要变体一览:
| 变体 | 核心改进 | 损失形式 |
|---|---|---|
| IPO | 用恒等变换替代 logit 变换,防止过拟合 | |
| SimPO | 去除参考模型,添加长度归一化和边际约束 | $-\log\sigma\left(\frac{\beta}{ |
| KTO | 不需要成对数据,只需单个回复的好/坏标签 | 基于前景理论的非对称损失 |
| RSO | 使用 Hinge Loss 替代 Sigmoid Loss |
trl 库通过 DPOConfig 的 loss_type 参数支持多种损失变体,包括 "sigmoid"(标准 DPO)、"ipo"、"hinge"(RSO)等。
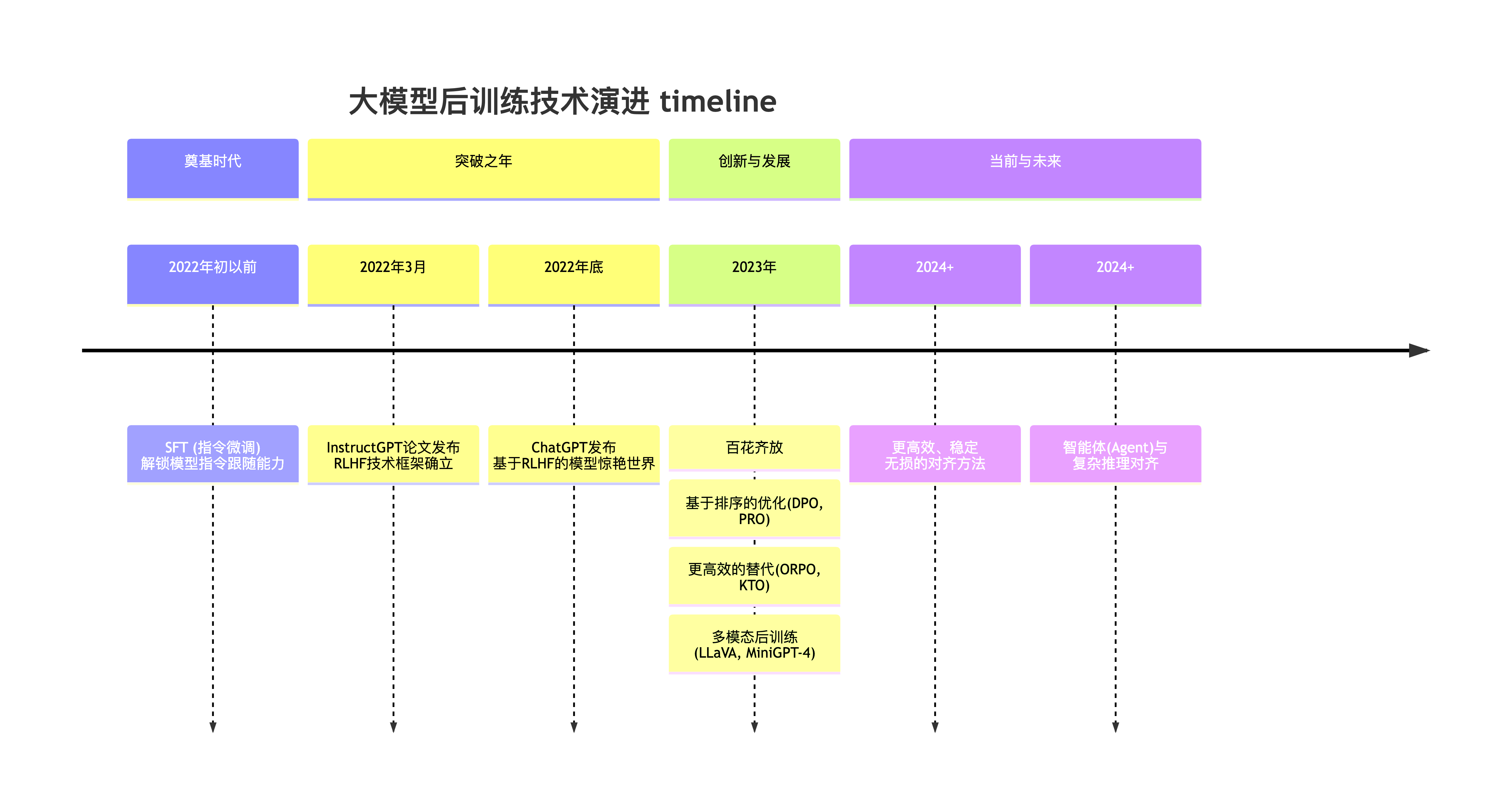
图 16-5:大模型后训练技术演进。DPO 是 2023 年兴起的关键范式,推动了更高效对齐方法的发展。
16.1.8 小结
DPO 的数学推导虽然涉及多个步骤,但其核心逻辑可以用一段话概括:RLHF 的最优策略有解析解,用这个解析解可以把奖励函数重写为策略的对数比率;代入 Bradley-Terry 偏好模型后,配分函数恰好消去,最终得到一个只需要前向传播的监督损失函数。 这个损失在形式上与奖励模型的训练损失完全相同,区别仅在于用"策略与参考模型的对数比率"替代了"奖励模型的打分"。
DPO 的核心价值在于将复杂的在线强化学习问题转化为了简单的离线监督学习问题。它需要的模型更少(2 个 vs 4 个)、训练更稳定、实现更简单,是当前开源社区中最广泛使用的偏好对齐方法。然而,它在需要探索能力的场景(如可验证奖励的数学推理)中可能不如 PPO 等在线方法。在下一节中,我们将讨论 RLHF 的更多变体和前沿进展。