21.6 Context Engineering(上下文工程)
"The context window is the new RAM." —— Andrej Karpathy
在 21.1 节中,我们将 LLM 智能体形式化为 POMDP:智能体无法直接观测真实环境状态
本节将系统讲解以下内容:(1)从 Prompt Engineering 到 Context Engineering 的范式迁移;(2)上下文衰退(Context Rot)的底层机制;(3)五大核心管理策略——卸载与检索、上下文压缩、多 Agent 上下文隔离、分层动作空间、KV Cache 最大化;(4)Prompt Caching 的多层架构与缓存销毁机制;(5)Manus 团队总结的六条实战原则。
21.6.1 范式迁移:从 Prompt Engineering 到 Context Engineering
Prompt Engineering(提示工程) 关注的是"内容层面"——如何编写一段精妙的指令,让模型在单次调用中表现最佳。它的经典技巧包括 few-shot 示例、Chain-of-Thought 提示、角色扮演等,适用于单轮任务。
Context Engineering(上下文工程) 关注的是"系统架构层面"——如何高效组织指令、工具定义、对话历史和外部信息,让 Agent 系统在多轮交互中整体高效且低成本地运转。它的核心定义如下:
在有限的上下文窗口与算力成本下,精确控制将什么信息、在什么时间、以什么形式输入给模型,从而最大化模型下一步正确行动的概率。
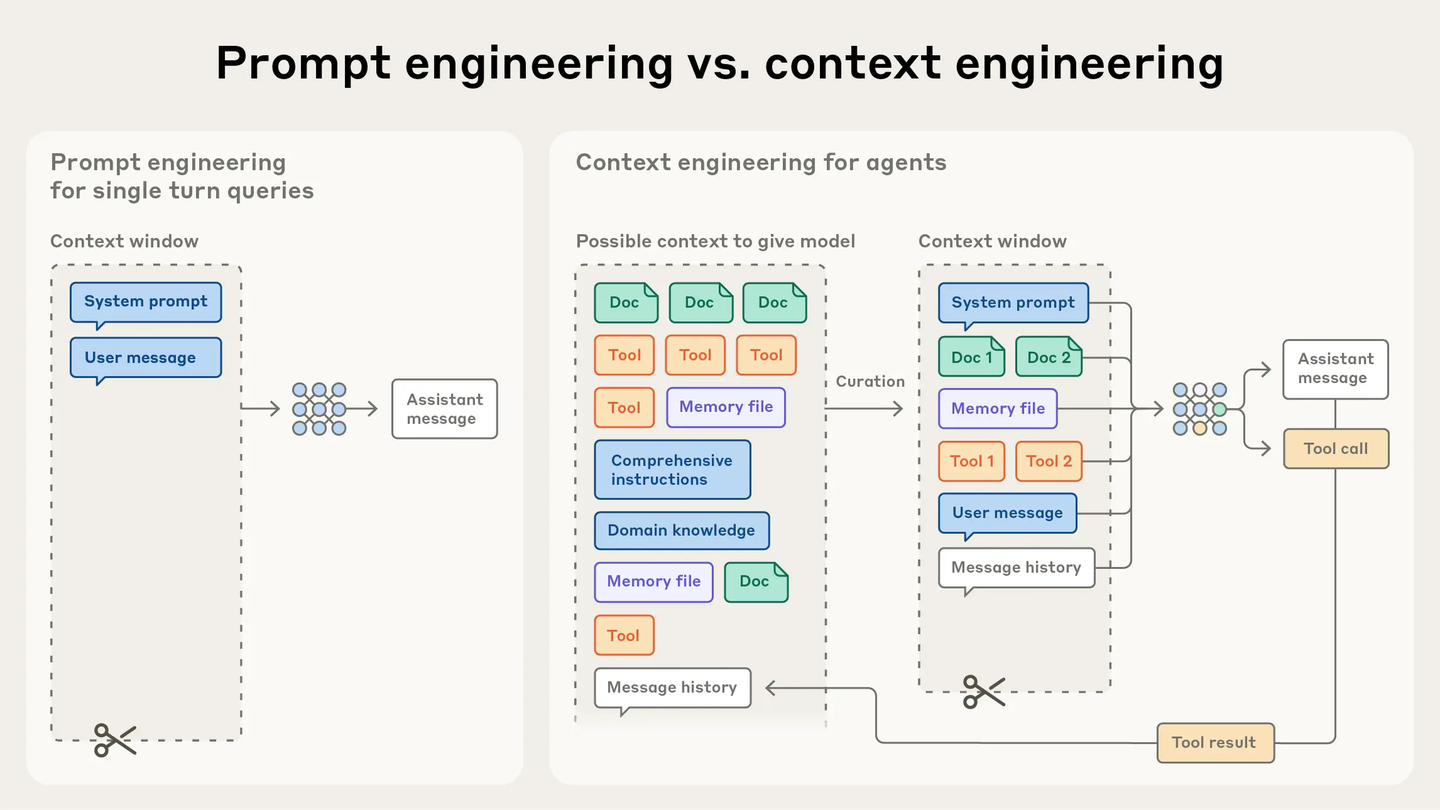
图 21-16:Prompt Engineering(左)与 Context Engineering(右)的对比。单轮场景只需组织 System Prompt + User Message;多轮 Agent 场景需要从海量的文档、记忆文件、工具返回结果和对话历史中进行动态筛选(Curation),精心裁剪后送入有限的上下文窗口。
这一范式转变的驱动力来自 Agent 交互模式的根本性变化。传统 Chatbot 是"一问一答"的短周期对话,上下文几乎不会膨胀;而 Agent 在执行任务时呈现一个持续增长的循环:
每经过一轮循环,上下文中就会追加一组"Action + Observation"记录。执行 50 步后,上下文可能已经塞满了数万行 shell 日志、代码片段和 API 返回的 JSON。此时模型面对的不再是一段精心编排的 Prompt,而是一片信息密度极度不均的"数据沼泽"。
为什么不直接通过微调(Fine-tuning)或强化学习(RL)来解决? 这是很多开发者的第一反应,但在当前阶段往往是一个陷阱:
- 创新周期悖论:微调和 RL 需要极长的闭环周期(收集数据
训练 评估),而在产品迭代早期,Agent 的任务流、API 接口和工具集每天都在变。 - 基座模型的降维打击:花费数月微调的专属模型,很容易被下个月发布的新一代基座模型在 Zero-shot 能力上直接超越。
- RL 的环境不稳定性:RL 依赖固定的动作空间和奖励函数,但在真实软件开发或网页浏览环境中,状态空间是无限且不可预测的。
因此,当前构建生产级 Agent 最清晰的技术路径是:强大的通用基座模型 + 极致的上下文工程。
更进一步地,业界正在酝酿下一次范式跃迁——Harness Engineering(系统工程/框架工程),即不仅关注"给模型看什么",还关注"用什么系统架构来驱动模型":包括多 Agent 编排、工具路由、任务调度、缓存策略等系统级设计。Context Engineering 可以视为 Harness Engineering 中最核心的子问题。
21.6.2 上下文衰退(Context Rot)
虽然现代大模型标称支持 128K 甚至 1M 的超长上下文窗口,但在 Agent 场景中,千万不能把上下文"塞满"。当 Agent 执行了大量工具调用,返回了成千上万行的 Shell 日志或代码片段后,模型会出现一种被称为上下文衰退(Context Rot) 的现象。其典型表现包括:
- 开始重复调用刚才已经报错的同一个工具命令;
- 忘记了 System Prompt 中规定的输出格式(比如突然不输出 JSON 而输出纯文本);
- 推理速度极度变慢,甚至产生严重的幻觉。
这一现象有三层底层原因:
原因一:注意力稀释(
当序列长度
原因二:训练数据分布偏差。 模型在预训练阶段"看"到的绝大多数高质量文本都是较短的篇幅。超长文本往往是生硬拼接的语料,模型对超长距离的逻辑依赖处理经验先天不足。这也是 "Lost in the Middle"(刘等人, 2023)现象的根源——模型倾向于关注上下文的头部和尾部,而忽略中间部分。
原因三:粗暴截断的致命性。 最朴素的上下文管理策略是 FIFO(先进先出)截断——超出窗口时丢弃最早的消息。但在 Agent 场景中这是灾难性的:你无法预判十步之前的一条报错日志,在当前这一步是否是解决问题的关键线索。粗暴截断等于随机丢弃记忆,可能导致 Agent 陷入死循环。
因此,我们需要一套精细的上下文管理策略体系。下面依次介绍五大核心策略。
21.6.3 策略一:卸载与检索——文件系统即终极上下文
核心思想是将大模型的"短期记忆"(上下文窗口)释放出来,把厚重的数据转移到"长期记忆"(文件系统)中,仅在需要时按需检索。
文件系统作为 Agent 的外部记忆
生产级 Agent 框架(如 Manus、Claude Code)均将 Linux 文件系统视为 Agent 最好的记忆库。文件系统天然具备三大优势:容量无限扩展、数据持久化、树状层级结构便于组织。
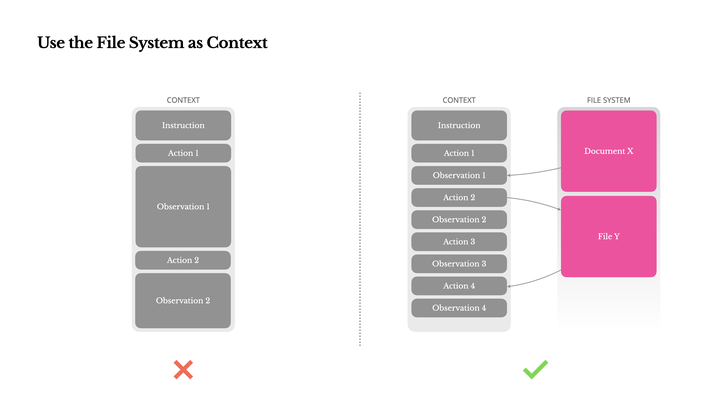
图 21-17:左侧的反模式直接将所有 Observation 塞入上下文,导致窗口迅速膨胀;右侧的最佳实践将长文档和大文件卸载到文件系统中,上下文中仅保留简短的路径引用。
具体做法如下:当 Agent 抓取了一个 5MB 的网页,或执行了一次复杂的 SQL 查询返回了上万行结果时,不要将这些数据直接放回上下文。而是引导 Agent 主动将结果写入本地文件(如 /tmp/query_result.csv),在上下文中只留下极短的记录:
Observation: 查询结果已成功写入 /tmp/query_result.csv(共 12,847 行)。这样一来,原本消耗数万 token 的 Observation 被压缩为一句话,上下文保持"极致清爽"。
即时检索(Just-in-Time Retrieval)替代沉重的 RAG
过去两年,构建知识库的标配方案是 RAG(文档分块
现代 Agent 提倡回归本质的即时检索:赋予 Agent 调用 grep、find、ripgrep、cat、jq 等系统命令的能力。当 Agent 想要了解某个函数的实现时,它先用 ripgrep 在代码库里全局搜索函数名,找到文件路径;然后再用读文件工具查看该文件的特定行。
# 模拟 Agent 的即时检索行为
import subprocess
def jit_search(query: str, codebase_path: str) -> str:
"""Agent 使用 ripgrep 在代码库中搜索关键词"""
result = subprocess.run(
["rg", "--line-number", "--max-count", "5", query, codebase_path],
capture_output=True, text=True, timeout=10
)
if result.returncode == 0:
return result.stdout # 返回匹配行及行号
return f"未找到匹配项: {query}"
# Agent 调用: 在代码库中搜索 "attention_forward" 函数
matches = jit_search("def attention_forward", "/workspace/project/")
# 输出: src/model.py:142: def attention_forward(self, q, k, v, mask=None):
# 然后 Agent 可以精确读取 src/model.py 的第 142-180 行这种方式免去了维护向量数据库的成本,搜索结果 100% 精确匹配且永远是最新状态。本质上,Agent 在模拟人类程序员的工作流——遇到不确定的信息时,主动去"查",而非依赖被动推送。
21.6.4 策略二:上下文压缩——Compaction 与 Summarization
当 Agent 运行轮数过多,即便已经将大量数据卸载到文件系统,上下文仍然可能逼近模型的预衰退阈值(Pre-rot Threshold)。例如在 1M 窗口的模型上,实践中通常将阈值设定在 128K 左右。此时必须对上下文进行降维缩减。
缩减分为两种层次,优先级递减:
第一层:紧凑化(Compaction)——可逆的无损压缩
紧凑化的核心是剥离 Payload(冗长的数据负载),保留 Metadata(元数据与指针)。由于原始数据仍然存在于文件系统中,这种压缩是可逆的。
// 原始的 Tool Result:消耗约 15,000 tokens
{
"tool_call": "write_file",
"arguments": {
"path": "app.js",
"content": "/* 10,000 行 React 代码... */"
}
}
// 紧凑化后的 Tool Result:仅消耗约 30 tokens
{
"tool_call": "write_file",
"result": {
"status": "success",
"file_path": "app.js",
"note": "Content omitted for brevity. Read file if needed."
}
}通过这种方式,Agent 依然清楚自己刚才修改了哪个文件,需要时可以用读文件工具重新获取完整内容。
第二层:摘要化(Summarization)——有损压缩的最后手段
当紧凑化也无法拯救逼近极限的上下文时,必须启动摘要。但摘要会不可逆地丢失细节,因此生产级框架会采用一套精心设计的容灾流程:
- 全量数据备份(Dump):在触发摘要前,系统将完整的对话历史(未经任何缩减的原始 JSONL)持久化写入本地磁盘。
- 结构化摘要生成:调用一个专门的模型,针对前半部分的对话生成一份高度结构化的摘要,而非笼统的"前情提要"。
- 注入查找线索:在摘要末尾追加一条系统提示,告知 Agent 完整记录的存储位置——例如 "If you need specific details from before compaction, read the full transcript at: /sessions/session_xyz.jsonl"。
- 保留近期记忆:绝对不要把最后几轮的工具调用也摘要掉。必须保留最近 2-3 轮的完整对话,确保模型不会"失忆断片",能够无缝衔接当前的语气和思路。

图 21-18:摘要化的容灾机制。当上下文超限后,系统生成结构化摘要并在末尾注入完整记录的文件路径。Agent 发现摘要中信息不足时,能通过系统留下的线索主动使用 grep 去查阅自己过去的完整原始日志。
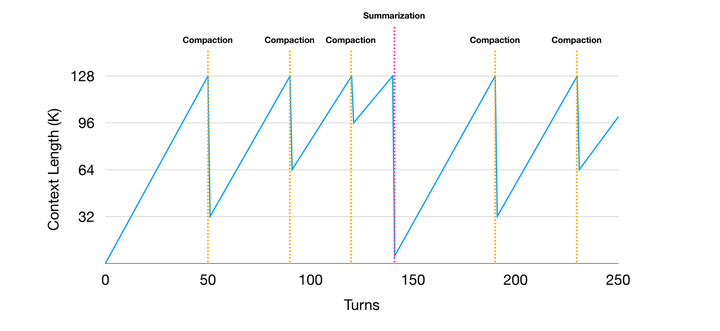
图 21-19:上下文长度随对话轮次的变化曲线。系统优先使用 Compaction(橙色虚线),在 Compaction 多次后仍不够时触发 Summarization(粉色虚线)。每次压缩后上下文长度大幅下降,然后随着新的对话轮次重新增长。
21.6.5 策略三:多 Agent 上下文隔离
如果主 Agent 承载了太多繁杂的中间试错步骤(比如反复编译
子智能体的运行机制
子智能体通常按权限和模型两个维度进行划分:
- 按权限划分:主 Agent 拥有完整能力,而子 Agent 可以是受限的。例如派出一个只读的
Explore子 Agent 去分析代码库,它只能调用 Glob、Grep、Read 等只读工具,确保系统安全。 - 按模型划分:简单的代码搜索任务使用低成本、低延迟的小模型;汇总决策时主 Agent 使用顶级模型。

图 21-20:Claude Code 的控制循环对比。简单问题(左)由主 Agent 直接在主循环中完成;复杂问题(右)通过 Task Tool 委托给子 Agent,子 Agent 在独立的上下文沙盒中尽情试错,最终只把精简的任务报告返回给主 Agent。
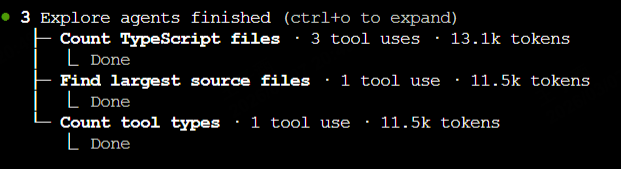
图 21-21:Claude Code 并行启动 3 个 Explore 子 Agent 的实际运行截图。每个子 Agent 独立完成搜索任务,消耗的 token 数极少(11-13K),而主 Agent 上下文几乎不受影响。
并发同步哲学:Share Memory by Communicating
借鉴 Go 语言的并发哲学,多 Agent 协同有两种主要模式:
模式 A:"通过通信共享内存"(Share Memory by Communicating) —— 推荐的默认方式。主 Agent 将任务写成一段明确的 Prompt,启动一个全新的子 Agent 进程。子 Agent 的上下文是完全空白的,它通过工具自己去探索环境,完成后返回最终答案。
# 模式 A 的伪代码实现
class OrchestratorAgent:
def delegate_task(self, task_description: str) -> str:
"""派发任务给子 Agent,上下文完全隔离"""
sub_agent = SubAgent(
system_prompt=self.system_prompt, # 复用相同的前缀 -> Cache 命中
tools=self.read_only_tools, # 限制为只读工具子集
model="claude-3-haiku" # 简单任务用小模型
)
# 子 Agent 从空白上下文出发,自主探索
result = sub_agent.run(task_description)
# 只将精简的结果注入主上下文
return result.summary # 例如: "函数 parse_config 定义在 src/utils.py:42"优点是主从上下文绝对隔离,子 Agent 可以自由试错而不污染主上下文,且由于前缀相同,KV Cache 利用率极高。
模式 B:"共享内存以通信"(Communicate by Sharing Memory / Fork 模式)。当任务极度复杂(如跨多文件重构),一两句 Prompt 无法交代清楚背景时,主 Agent 会将自己当前的完整上下文或部分状态直接 Fork 给子 Agent。缺点是消耗极高的 token,且由于每次 Fork 过去的历史都不同,KV Cache 命中率极低。仅在万不得已的深度推理场景使用。
21.6.6 策略四:分层动作空间
随着 Agent 接入的工具越来越多(特别是通过 MCP 协议接入大量第三方服务),直接将几十上百个 API Schema 塞入 Prompt 会造成灾难性的工具混淆(Tool Confusion)——模型在庞大的工具列表中迷失,选错工具或生成无效的参数。
生产级 Agent 必须构建三层抽象的动作空间:
| 层级 | 名称 | 工具数量 | 在 Prompt 中的形态 | 示例 |
|---|---|---|---|---|
| Level 1 | 核心原子函数 | ~10 个 | 完整的 Function Calling Schema | read_file, write_file, execute_shell, search_web |
| Level 2 | 沙盒实用工具 | 数十个 | 不出现在 Prompt 中,通过 Level 1 间接调用 | PDF 转文本、计算器、MCP 服务(通过 execute_shell 调用 CLI) |
| Level 3 | 脚本与动态 API | 无限 | 不出现在 Prompt 中,Agent 编写代码调用 | 金融行情 API、数据库查询(Agent 写 Python 脚本处理) |
这种分层设计的核心收益是:
- Level 1 保持极少且稳定:工具 Schema 数量少意味着 System Prompt 短,更重要的是——Schema 雷打不动,能够 100% 命中 KV Cache。
- Level 2 无限扩展能力,零 Token 开销:所有扩展能力被打包为 CLI 工具预装在沙盒中。模型只需通过
execute_shell这个原子工具运行命令(如manus-mcp-cli --query "sales"),无需在 Prompt 中增加任何 Token。 - Level 3 应对海量数据流:当 Agent 需要调用一个返回 50MB JSON 的 API 时,直接调用会瞬间撑爆上下文。正确做法是引导 Agent 编写一段 Python 脚本,在脚本内部完成 API 调用、数据清洗和过滤,最后
print精简结论。Agent 看到的只是脚本的短短几句标准输出。
# Level 3 示例:Agent 编写脚本处理大规模 API 数据
# Agent 生成以下代码并通过 execute_shell 运行
import requests
import json
# 调用金融行情 API(返回约 50MB 数据)
response = requests.get(
"https://api.example.com/market/all_tickers",
headers={"Authorization": "Bearer $API_KEY"},
timeout=30
)
data = response.json()
# 在脚本内部完成过滤和聚合
top_gainers = sorted(
data["tickers"],
key=lambda x: x["change_pct"],
reverse=True
)[:10]
# 只输出精简结果,Agent 上下文仅收到这几行
for ticker in top_gainers:
print(f"{ticker['symbol']}: {ticker['change_pct']:+.2f}%")21.6.7 策略五:KV Cache 最大化
大模型在处理输入时,预填充(Prefill) 阶段需要对所有输入 token 进行矩阵运算以生成 Key 和 Value 向量。这一阶段是 Compute Bound 的,消耗极大的算力。Agent 的运行特性是输入极长、输出极短(Input:Output 比例高达 100:1)。如果不利用 KV Cache 复用历史计算结果,成本和延迟(TTFT - Time To First Token)将是不可接受的。
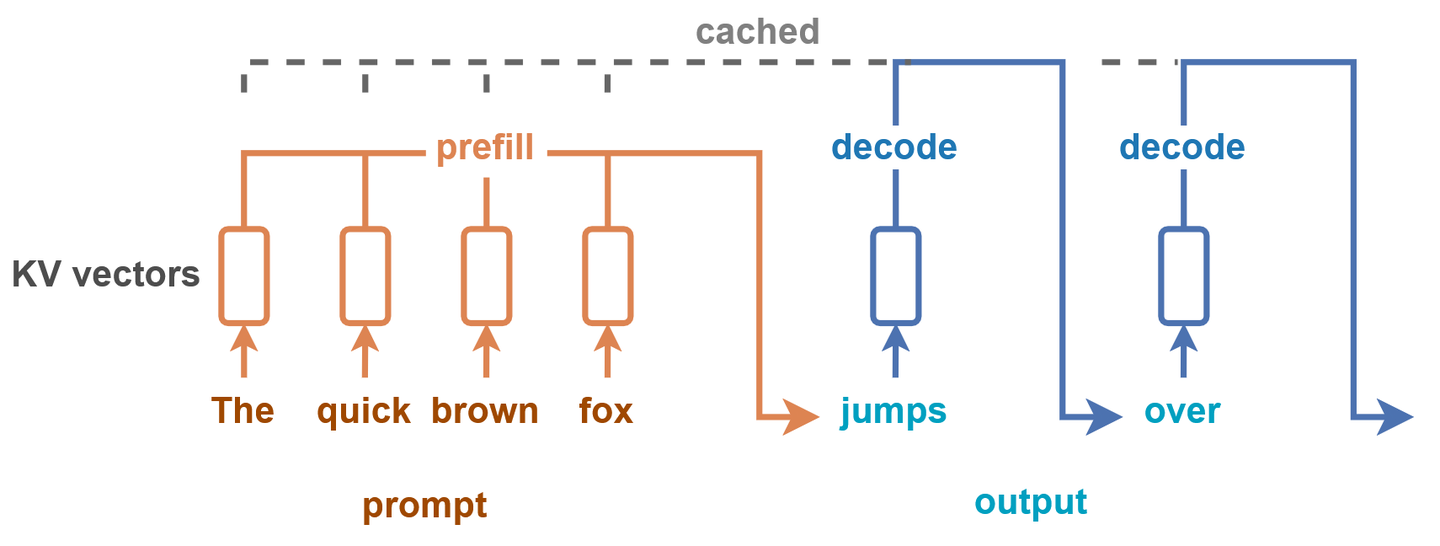
图 21-22:KV Cache 的工作原理。Prefill 阶段对所有输入 token 并行计算 K/V 向量并缓存;后续 Decode 阶段每次只需计算新 token 的 K/V 向量,复用之前的缓存。命中缓存的 token 价格通常只有未缓存的 1/10。
缓存命中率是 Agent 系统的北极星指标。 Manus 团队将 KV Cache Hit Rate 视为"最重要的单一系统指标",Claude Code 团队更是将缓存命中率下降定义为线上生产事故(SEV)。实际数据表明,在 Claude Code 中:Explore 子 Agent 的缓存复用率达 92%,Plan 阶段达 93%,Execution 阶段达 97%。
为实现如此高的命中率,Agent 系统必须遵循以下三条铁律:
铁律一:Append-Only(只追加,不修改)。 缓存的生效条件是严格的前缀匹配——上下文序列中哪怕多一个空格,该位置及之后的所有缓存都会失效。因此:
- 千万不能在 System Prompt 的开头放置动态变化的时间戳或每次轮次变化的状态 ID;
- 历史消息如果有误,不要回溯修改历史 JSON,而是在对话末尾追加一条新消息进行更正。
铁律二:确定性序列化(Deterministic Serialization)。 当把 Agent 内部的数据结构序列化为 JSON 字符串时,不同语言默认的 Key 排序可能是不确定的。必须强制字典按 Key 排序:
import json
# 错误:默认序列化,Key 顺序可能每次不同
payload_bad = json.dumps(tool_call_args)
# 正确:强制排序,保证同一内容的 Token 序列永远一致
payload_good = json.dumps(tool_call_args, sort_keys=True, ensure_ascii=False)如果历史记录中 JSON 的 Key 排序不一致,即使语义完全相同,Token 序列也会不同,缓存就会静默失效。
铁律三:显式缓存断点与动态断点结合。 以 Anthropic API 为例:
{
"model": "claude-sonnet-4-20250514",
"max_tokens": 1024,
"system": [
{
"type": "text",
"text": "You are a senior developer agent...",
"cache_control": { "type": "ephemeral" } // 显式断点:System Prompt 结尾
}
],
"messages": [
// ... 对话历史,自动缓存或在较新位置插入动态断点
]
}将雷打不动的内容(System Prompt 和 Tools Schema)放在最前并打上 cache_control 断点;在多轮对话的较新位置,框架自动计算偏移量插入缓存标记,让缓存随着对话推进而"滚动向前"。
21.6.8 Prompt Caching 的多层架构
理解了 KV Cache 的重要性后,我们来看生产级 Agent 是如何围绕 Cache 来设计整个 Prompt 布局的。核心思路是:将绝对稳定的内容放在最前面,变动越频繁的内容越往后放。
Claude Code 采用了清晰的四层(Layer)架构:
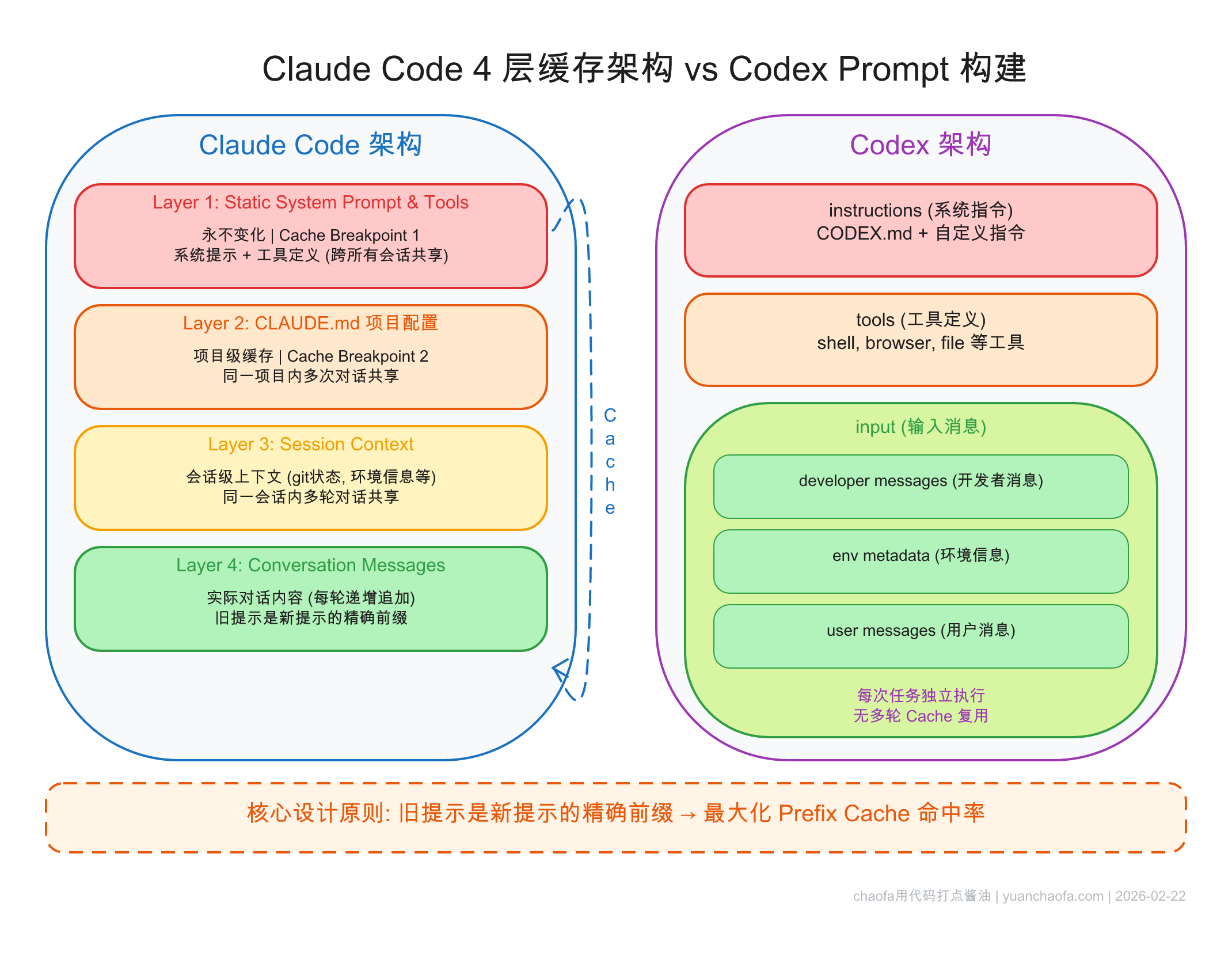
图 21-23:Claude Code 的四层缓存架构(左)与 OpenAI Codex 的 Prompt 构建方式(右)对比。核心设计原则相同:旧的提示是新提示的精确前缀,从而最大化 Prefix Cache 命中率。
| 层级 | 内容 | 缓存特性 | 共享范围 |
|---|---|---|---|
| Layer 1 | Static System Prompt + 全局 Tools 定义 | 完全不变 | 跨所有会话共享 |
| Layer 2 | 项目配置(如 CLAUDE.md 文件内容) | 项目内不变 | 同一项目的多次对话共享 |
| Layer 3 | 会话上下文(当前 Git status、环境变量等) | 会话内不变 | 同一会话的多轮对话共享 |
| Layer 4 | 对话消息(Conversation Messages) | 每轮追加 | 仅当前对话 |
这种分层设计的精妙之处在于:Layer 1 的 Cache 可以被所有用户的所有会话复用(数百万次命中);Layer 2 的 Cache 在同一个项目中反复复用;Layer 3 在一次会话的几十轮对话中反复复用;Layer 4 随着对话推进仅在末尾追加,前缀始终匹配。
动态信息的正确更新方式
如果系统需要向 Agent 注入当前时间、状态提醒或权限变更,绝对不能去修改 Layer 1/2/3。正确做法是:将这些变化的信息作为新的消息追加到对话末尾。例如 Claude Code 使用 <system-reminder> 标签将动态信息包裹并放置在最新的 User Message 中。
21.6.9 缓存销毁机制
理解了缓存架构后,同样重要的是理解哪些操作会导致缓存全部失效。以下四类操作是最常见的"缓存杀手":
1. 在开头插入动态信息。 Manus 团队早期在 System Prompt 开头放入当前时间戳。由于时间戳每秒都在变动,导致第一个 Token 永远不同,整个对话的缓存彻底失效。修复方案是将时间戳移到对话末尾的 User Message 中。
2. 修改工具定义(Tool Definitions)。 这是实际开发中最隐蔽的破坏方式,因为 Tools 通常位于 Prompt 的前部(紧跟 System Prompt 之后)。常见的错误操作包括:
- 动态增删工具(按需加载不同工具集);
- 工具注册顺序不确定(MCP 工具随机排序);
- 更新工具内部的参数描述。
3. 在同一会话中切换模型。 Cache 是 Model-specific(与具体模型绑定的)。一个反直觉的现象是:在累积了 100K Token 的对话中,为了省钱把模型从 Claude Opus 切换到 Haiku,反而会导致成本飙升——Opus 命中缓存的 100K Token 只要 $1.50,切换后 Haiku 需要对 100K Token 重新做无缓存的 Prefill。
4. 修改或删除历史消息。 试图删除之前调用失败的 Action 或无效的 Observation,会导致该位置之后的所有缓存失效。正确做法是保留错误记录,在末尾追加更正信息。
21.6.10 工具管理的 Cache 友好策略
Agent 可能拥有 30 个以上的工具,但特定阶段只需用到几个。如果为了避免模型乱用工具而"按需向 Prompt 注入工具",就会破坏缓存。各主流框架的解决思路一致:传入大模型的 Tool 定义数组永远不变(保 Cache),通过其他机制来限制模型当前可用的工具范围。
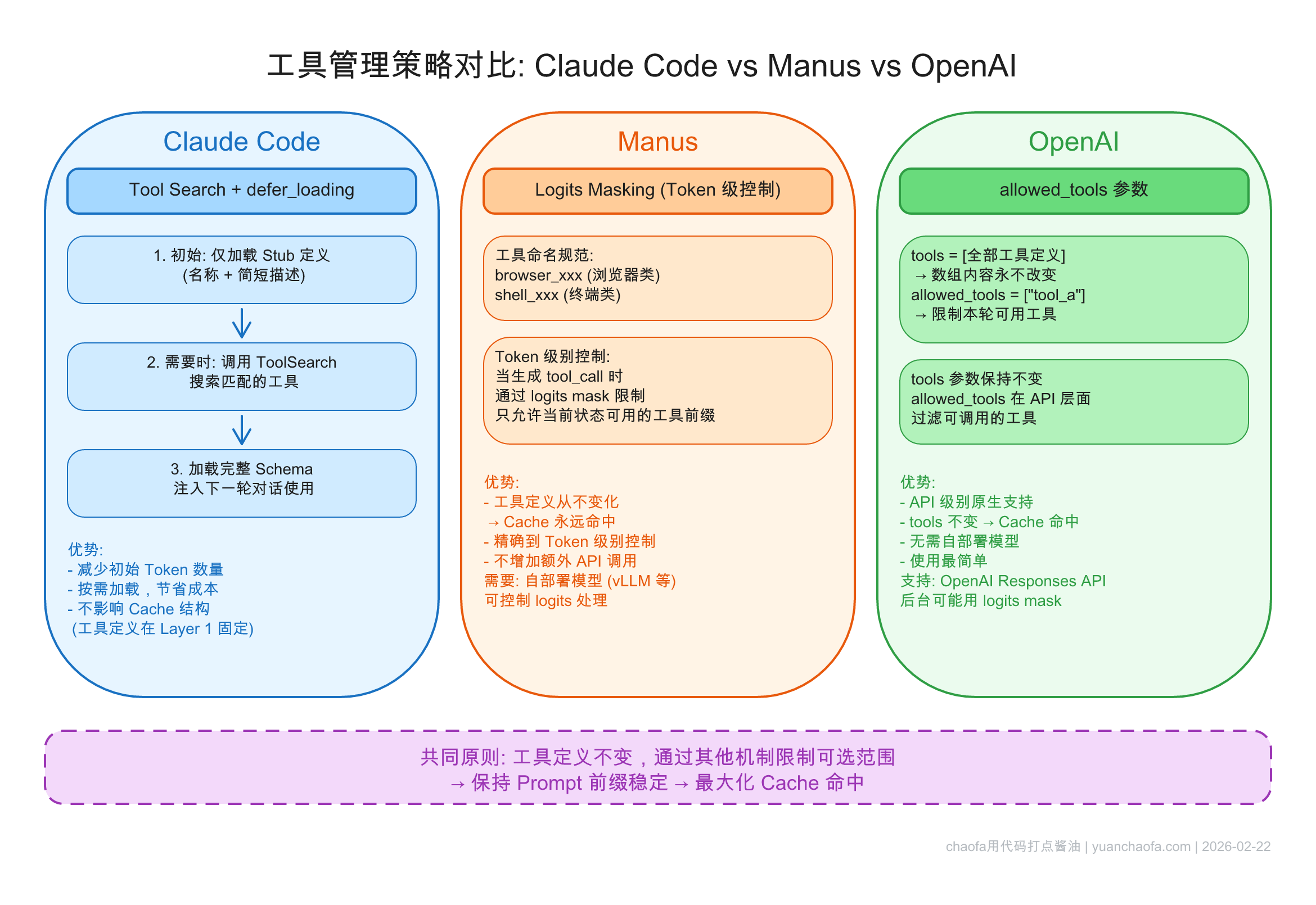
图 21-24:Claude Code、Manus 和 OpenAI 的工具管理策略对比。共同原则是工具定义不变,通过其他机制限制可选范围,保持 Prompt 前缀稳定以最大化 Cache 命中。
三种代表性方案如下:
Claude Code:Tool Search + 延迟加载(Defer Loading)。 Prompt 中只存放大量工具的极简存根(Stub,仅含工具名称和一句话描述)。当模型需要某个工具的完整参数 Schema 时,通过调用 ToolSearch 工具获取。这样既保持了初始前缀稳定,又避免了 Token 浪费。
Manus:Logits Masking(Logits 掩码)。 所有工具始终完整保留在 Prompt 前缀中。通过在模型推理层的 Decode 阶段对 Token Logits 进行掩码操作——将不该使用的工具名称的概率强制置为负无穷,从物理层面禁止模型生成不合规的工具调用。此方案需要私有化部署或底层 API 支持。
OpenAI:allowed_tools 参数。 Prompt 中的 tools 数组保持完整且静止,在每次 API 请求时通过额外参数 allowed_tools 传入当前允许调用的工具子集。API 服务端既能复用 Prefix Cache,又能限制输出。
21.6.11 Cache-Safe Compaction
前面在 21.6.4 中介绍了 Compaction 的概念。这里补充一个关键的工程细节:压缩操作本身绝不能破坏现有的 Cache。
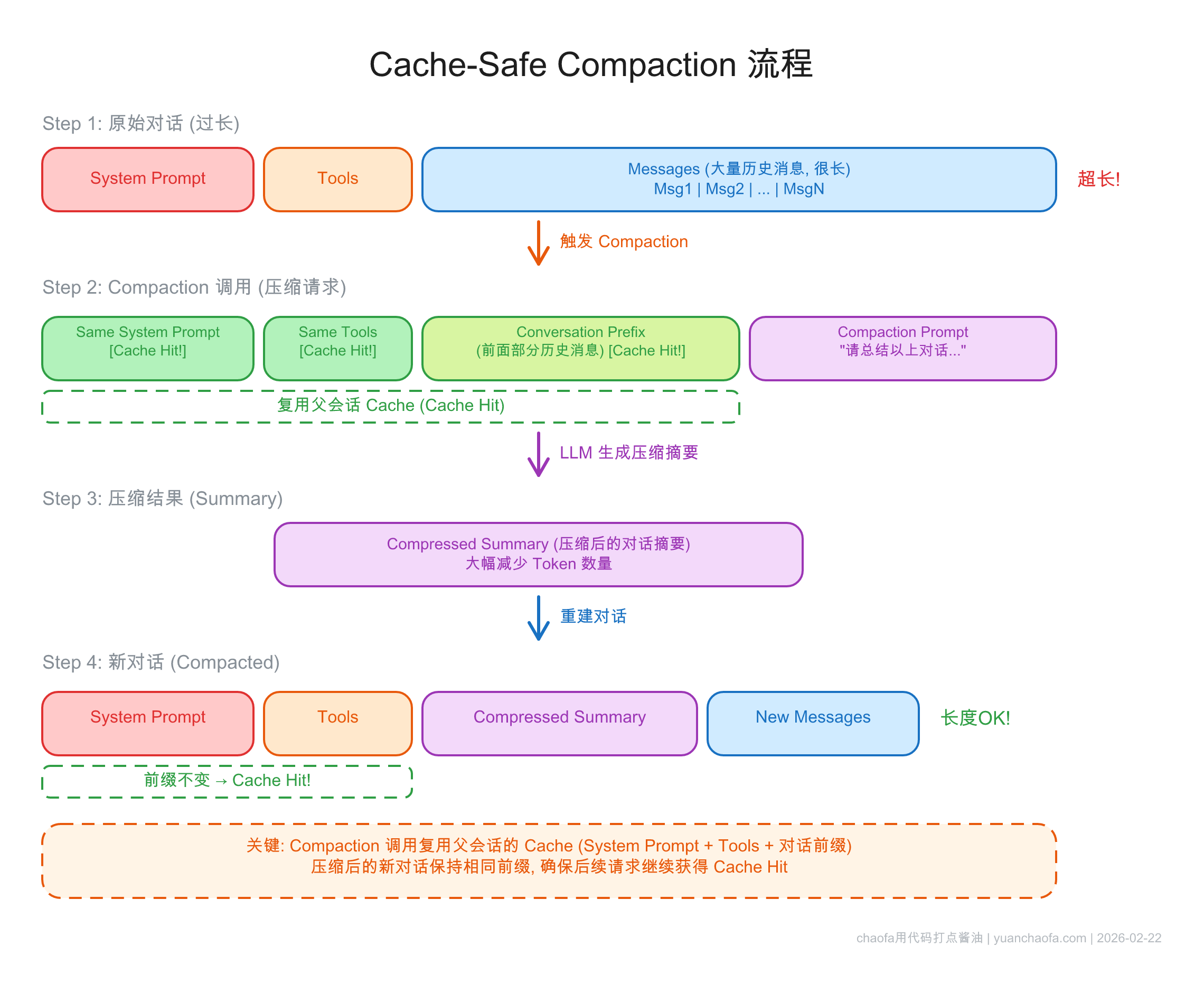
图 21-25:Cache-Safe Compaction 的四步流程。关键在于 Step 2——发起压缩请求时,携带与当前会话完全相同的 System Prompt + Tools + 对话前缀,仅在末尾追加 Compaction Prompt。由于前缀完全一致,这个压缩请求直接复用了父会话的 Cache,成本极低。
Claude Code 的做法是:当需要压缩上下文时,发起一个特殊的 API 请求,该请求包含与当前会话完全相同的 System Prompt + Tools + 对话前缀,仅在末尾追加一段特殊的 Compaction Prompt(要求模型将历史对话压缩为结构化摘要)。由于前缀完全一致,这个压缩请求直接"白嫖"了父会话的 KV Cache,成本极低。通常会在上下文达到容量上限之前预留一个 "Compaction Buffer" 提前触发,避免紧急截断。
压缩完成后,系统用压缩后的摘要替换原始的历史消息,但保留相同的 System Prompt + Tools 前缀,确保后续对话能继续命中 Layer 1 和 Layer 2 的 Cache。
21.6.12 Manus 六原则
Manus 是一个具有代表性的生产级通用 Agent。其团队在大量工程实践中总结出六条上下文工程原则,它们是前述五大策略的高度浓缩。
原则一:围绕 KV Cache 进行极致设计。 KV Cache 命中率是最关键的单一指标,直接决定延迟和成本。保持前缀绝对稳定、实行 Append-Only 策略、确保序列化确定性——这三点是不可妥协的底线。
原则二:用掩码(Masking)代替移除来管理工具。 动态增删工具定义不仅破坏缓存,还会引发幻觉(模型在上下文中看到了某工具的调用记录,但该工具的定义突然消失了)。正确做法是保持工具定义静态不变,通过 Logits Masking 或 Response Prefilling 来限制工具选择。例如,通过预填充 {"name": "browser_ 可以将模型限制在只调用浏览器工具组内。
原则三:将文件系统作为无上限的外部上下文。 直接对上下文进行截断或激进压缩会导致不可逆转的信息丢失。将文件系统设计为 Agent 的终极外部记忆,所有的上下文压缩必须是可恢复的。
原则四:通过复述(Recitation)操控注意力。 在长周期任务中,Agent 极易出现 "Lost in the Middle" 现象而偏离目标。解决方法是让 Agent 维护一个结构化的待办事项(如 todo.md),在任务推进过程中不断在上下文末尾处复述核心目标和已完成的进度,将全局计划强行推入模型最近期的注意力视野。
原则五:保留错误的尝试记录。 绝对不要从上下文中删除失败的 Action 和报错信息。从架构层面,删除会破坏前缀缓存;从智能层面,模型需要"证据"来更新内部置信度——当它清晰地看到某条路径走不通时,会调整策略,避免重复犯错。这种"从错误中恢复"的能力是 Agent 自主性的核心标志。
原则六:打破 Few-Shot 的模式化陷阱。 LLM 是极强的模式模仿者。如果上下文中堆积了大量相似的"Action-Observation"循环(例如连续翻阅 20 页相同格式的文档),模型会陷入无意识的"复读机"节奏。解决方法是在上下文的序列化过程中注入可控的结构化噪音——对相似的动作和观察结果使用稍微不同的描述模板、变换措辞或微调格式,打断模型的机械模仿惯性。
21.6.13 实战示例:构建 Cache 友好的 Agent 架构
下面通过一个完整的代码示例,将本节介绍的核心策略整合在一起,展示如何构建一个 Cache 友好的 Agent 上下文管理系统。
import json
import hashlib
from dataclasses import dataclass, field
from typing import Any
@dataclass
class ContextManager:
"""面向 KV Cache 优化的上下文管理器"""
# Layer 1: 全局稳定(跨所有会话共享 Cache)
system_prompt: str = "You are an expert coding agent..."
tools_schema: list[dict] = field(default_factory=list) # 永不修改
# Layer 2: 项目级配置
project_config: str = "" # CLAUDE.md 内容
# Layer 3: 会话级上下文
session_context: str = "" # git status、环境变量等
# Layer 4: 对话消息(Append-Only)
messages: list[dict] = field(default_factory=list)
# 压缩阈值配置
compaction_threshold: int = 100_000 # tokens
compaction_buffer: int = 20_000 # 预留缓冲
recent_turns_to_keep: int = 3 # 摘要时保留最近几轮
def build_api_request(self) -> dict:
"""构建 API 请求,确保前缀稳定以最大化 Cache 命中"""
return {
"system": [
{
"type": "text",
"text": self.system_prompt,
"cache_control": {"type": "ephemeral"} # 显式断点
},
{
"type": "text",
"text": f"Project config:\n{self.project_config}",
"cache_control": {"type": "ephemeral"} # 第二个断点
}
],
"tools": self.tools_schema, # 永远不变
"messages": self.messages # 只追加,不修改
}
def append_tool_result(self, tool_name: str, result: Any) -> None:
"""追加工具结果,大结果自动卸载到文件系统"""
# 确定性序列化
result_str = json.dumps(result, sort_keys=True, ensure_ascii=False)
if len(result_str) > 5000: # 超过阈值,卸载到文件系统
file_hash = hashlib.md5(result_str.encode()).hexdigest()[:8]
file_path = f"/tmp/agent_results/{tool_name}_{file_hash}.json"
with open(file_path, 'w') as f:
f.write(result_str)
# 上下文中只保留简短的引用(Compaction)
compact_result = {
"status": "success",
"offloaded_to": file_path,
"summary": f"Result saved ({len(result_str)} chars). "
f"Read file for details."
}
result_str = json.dumps(compact_result, sort_keys=True)
# Append-Only: 只在末尾追加
self.messages.append({
"role": "tool",
"content": result_str
})
def should_compact(self, current_tokens: int) -> bool:
"""判断是否需要触发压缩"""
return current_tokens > (self.compaction_threshold
- self.compaction_buffer)
def compact(self, summarizer_fn) -> None:
"""
Cache-Safe Compaction:
保留 Layer 1-3 前缀不变,仅压缩 Layer 4 的历史消息
"""
if len(self.messages) <= self.recent_turns_to_keep * 2:
return # 消息太少,无需压缩
# 1. 备份完整历史
backup_path = f"/tmp/agent_sessions/backup_{id(self)}.jsonl"
with open(backup_path, 'w') as f:
for msg in self.messages:
f.write(json.dumps(msg, sort_keys=True) + '\n')
# 2. 分离:需要压缩的旧消息 vs 保留的近期消息
old_messages = self.messages[:-self.recent_turns_to_keep * 2]
recent_messages = self.messages[-self.recent_turns_to_keep * 2:]
# 3. 生成结构化摘要(使用相同的前缀以复用 Cache)
summary = summarizer_fn(old_messages)
# 4. 重建消息列表:摘要 + 查找线索 + 近期消息
self.messages = [
{
"role": "user",
"content": f"[Previous conversation summary]\n{summary}\n\n"
f"Full transcript: {backup_path}"
}
] + recent_messages本节小结
上下文工程是构建生产级 Agent 系统的核心工程挑战。本节从范式迁移出发,剖析了上下文衰退的三层根因(注意力稀释、训练分布偏差、截断失败),然后系统介绍了五大核心策略:文件系统卸载与即时检索、Compaction 与 Summarization 两级压缩、多 Agent 上下文隔离、三层动作空间抽象、KV Cache 最大化设计。在此基础上,我们深入讨论了 Prompt Caching 的多层架构、四类缓存销毁机制、三种 Cache 友好的工具管理方案,以及 Manus 团队在实战中总结的六条原则。这些策略的共同主线是一个简洁而深刻的认知:在 Agent 系统中,KV Cache 不仅仅是一个性能优化技巧,它是整个系统架构设计的核心物理约束——正如数据库的 Schema 设计决定了应用的数据流转架构,Prompt Cache 的前缀匹配机制深刻地决定了 Agent 的每一个设计决策。