19.3 批处理与调度
上一节介绍了 KV Cache 和注意力加速如何从算子层面提升推理效率。然而,当数百乃至数千个用户请求并发涌入推理服务时,如何将这些请求高效地组织成批次送入 GPU 计算,就成了系统层面最关键的调度问题。本节从最朴素的静态批处理出发,依次介绍连续批处理(Continuous Batching)、Prefill-Decode 分离架构(PD 分离) 以及分块预填充(Chunked Prefill),帮助读者建立一套完整的推理调度思维。
19.3.1 从静态批处理到连续批处理
静态批处理的困境。 最直观的做法是将若干请求凑成一个固定大小的批次,统一做 Prefill 然后统一做 Decode。这种静态批处理(Static Batching) 有一个致命问题:批内各请求的生成长度往往差异悬殊——有的请求生成 10 个 Token 就结束了,有的可能要生成 500 个。整个批次必须等待最慢的请求完成,先完成的请求只能空等,GPU 利用率急剧下降。
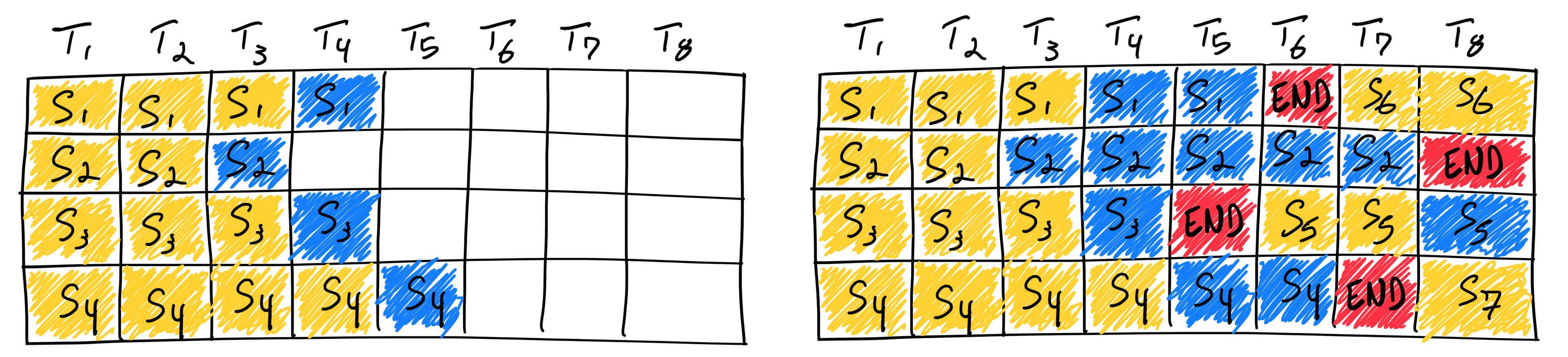
图 19-5:静态批处理(左)与连续批处理(右)对比。黄色为 Prefill 阶段,蓝色为 Decode 阶段,红色标记请求完成。连续批处理允许已完成的请求立即被新请求替换。
迭代级调度的思想。 2022 年 OSDI 上发表的 Orca 论文首次提出了迭代级调度(Iteration-Level Scheduling):不再以"请求"为调度单位,而是以每一个 Decode 迭代(即每生成一个 Token)为调度时机。每次迭代结束后,调度器检查哪些请求已经完成,将其移出批次并立即插入等待队列中的新请求。用数学语言描述,第
这样,GPU 几乎不会出现"空转"的情况——像一个永不停歇的流水席,客人吃完就离席,新客人立即坐下。这就是连续批处理(Continuous Batching) 的核心。
Selective Batching。 Orca 在实现迭代级调度时还提出了一个重要洞察:Transformer 中不同算子对批处理的适应性不同。线性层(Linear)和归一化层(LayerNorm)是逐 Token 的运算,可以直接将不同请求的 Token 拼在一起做大批次计算;而自注意力(Self-Attention)是序列级运算,每个请求的 KV Cache 长度不同,无法简单拼接。因此 Orca 采用选择性批处理(Selective Batching)——对非注意力算子将所有请求的 Token 扁平合并,对注意力算子则拆分后独立执行。后来随着 FlashAttention 和 PagedAttention 等融合内核的出现,注意力层也能高效地批处理不同长度的请求,Selective Batching 的限制被大幅消解。
为什么混合 Prefill 和 Decode 是关键。 连续批处理的性能优势根源在于 Prefill 和 Decode 两个阶段的互补性:
- Prefill 是计算密集(Compute-Bound) 的:一次性并行处理整个输入序列,即使 Batch Size 为 1,GPU 算力也接近饱和。
- Decode 是访存密集(Memory-Bound) 的:每次只生成一个 Token,计算量极小,瓶颈在于从显存读取模型权重和 KV Cache。
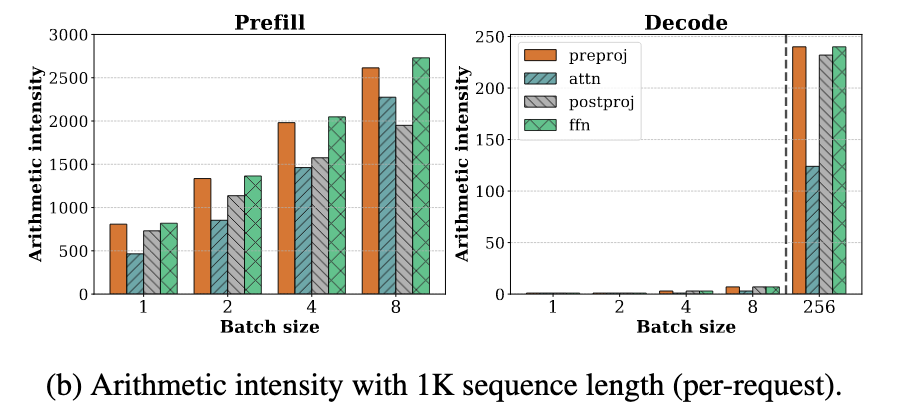
图 19-6:Prefill 与 Decode 阶段各算子的算术强度对比(序列长度 1K)。Decode 阶段在常规 Batch Size 下算术强度极低,大量 GPU 算力被浪费。
在连续批处理中,系统可以用 Decode 阶段闲置的算力来处理新请求的 Prefill。Prefill 搭载在 Decode 未被充分利用的计算资源上,同时 Decode 和 Prefill 共享一次模型权重读取——GPU 的计算单元和内存带宽都得到更充分的利用。
下面用一个简化的 Python 模拟来展示连续批处理的核心逻辑:
from collections import deque
from dataclasses import dataclass, field
@dataclass
class Request:
req_id: int
prompt_len: int # 输入 Token 数
max_gen_len: int # 最大生成 Token 数
generated: int = 0 # 已生成 Token 数
phase: str = "prefill" # 当前阶段: "prefill" 或 "decode"
@property
def is_done(self) -> bool:
return self.generated >= self.max_gen_len
class ContinuousBatchingScheduler:
"""连续批处理调度器的简化模拟"""
def __init__(self, max_batch_size: int = 8):
self.waiting: deque[Request] = deque()
self.running: list[Request] = []
self.max_batch = max_batch_size
self.completed: list[int] = []
def add_request(self, req: Request):
self.waiting.append(req)
def step(self) -> list[Request]:
"""执行一次迭代级调度"""
# 1. 移除已完成的请求
still_running = []
for r in self.running:
if r.is_done:
self.completed.append(r.req_id)
else:
still_running.append(r)
self.running = still_running
# 2. 从等待队列补入新请求
while self.waiting and len(self.running) < self.max_batch:
self.running.append(self.waiting.popleft())
# 3. 对当前批次中的每个请求执行一步
for r in self.running:
if r.phase == "prefill":
# Prefill 阶段一次处理完, 生成第一个 Token
r.generated = 1
r.phase = "decode"
else:
# Decode 阶段每步生成一个 Token
r.generated += 1
return self.running
# --- 运行示例 ---
scheduler = ContinuousBatchingScheduler(max_batch_size=3)
requests = [
Request(1, prompt_len=128, max_gen_len=5),
Request(2, prompt_len=64, max_gen_len=8),
Request(3, prompt_len=256, max_gen_len=3),
Request(4, prompt_len=32, max_gen_len=6),
Request(5, prompt_len=100, max_gen_len=4),
]
for r in requests:
scheduler.add_request(r)
step = 0
while scheduler.running or scheduler.waiting:
batch = scheduler.step()
if not batch:
break
ids = [(r.req_id, r.phase, r.generated) for r in batch]
print(f"Step {step}: batch={ids}")
step += 1
print(f"完成顺序: {scheduler.completed}")运行后可以观察到:请求 3 只需要生成 3 个 Token,会先于请求 2 完成并退出批次,空出的位置立即被请求 4 填入——这就是连续批处理的"流水席"效果。
连续批处理的性能收益。 实测数据表明,在 LLaMA-13B 模型、A100 GPU 上,vLLM 凭借连续批处理 + PagedAttention 的组合,吞吐量比 HuggingFace 原生推理高出 14–24 倍,比 TGI 高出 2.2–2.5 倍。这一巨大差距的根源正是调度策略——GPU 不再因为等待慢请求而空转,每个迭代步都在处理有意义的计算。
19.3.2 Prefill-Decode 分离架构
连续批处理虽然大幅提升了 GPU 利用率,但它在同一张 GPU 上混合执行 Prefill 和 Decode,这带来了一个新的矛盾。
Prefill-first 的干扰问题。 在 vLLM 早期版本中,调度策略采用 Prefill-first:当新请求到达时,立即执行其 Prefill。由于 Prefill 是计算密集操作(长 prompt 可能需要数百毫秒),正在 Decode 的请求被迫暂停——虽然 Decode 每步只需几毫秒,但它必须等 Prefill 完成才能继续。这导致了已在生成中的请求的 Token 间延迟(TPOT) 出现剧烈抖动。
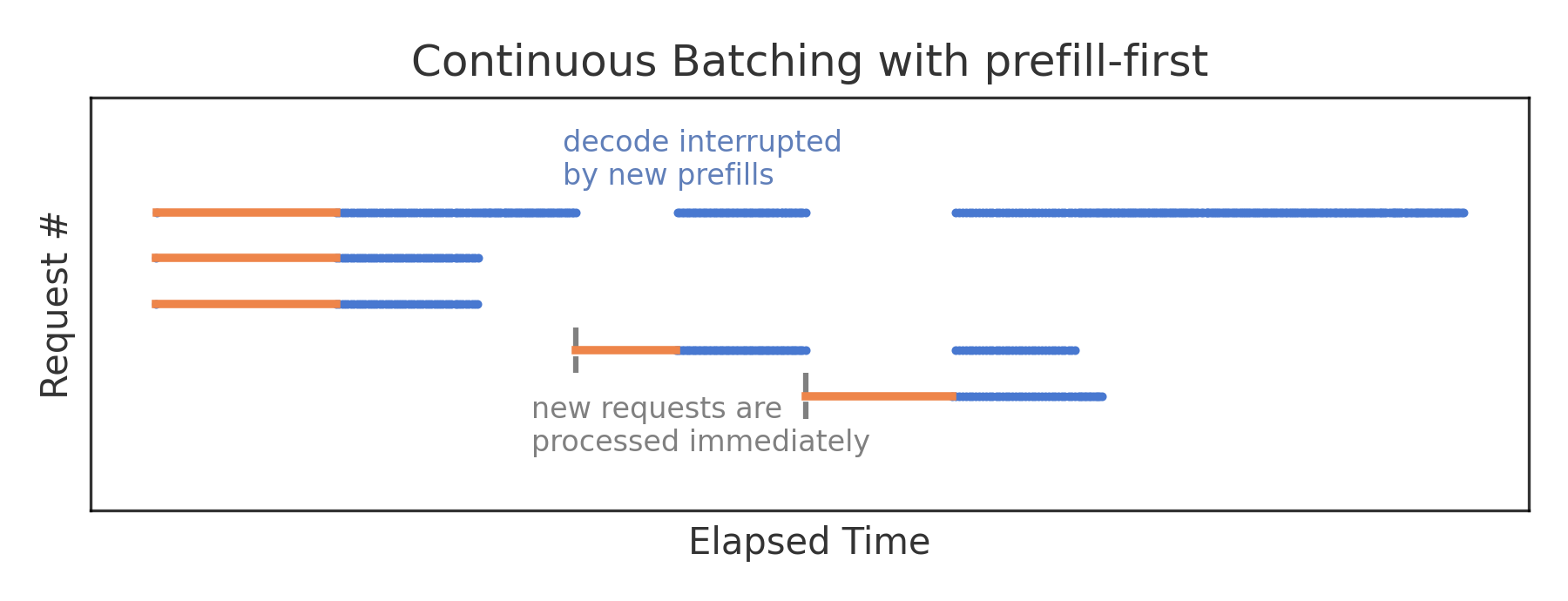
图 19-7:Prefill-first 调度的干扰效应。橙色为 Prefill 阶段,蓝色为 Decode 阶段。新请求的 Prefill 会打断已有请求的 Decode 流程,造成输出卡顿。
分离的核心思想。 既然 Prefill 和 Decode 对硬件的需求截然不同——Prefill 需要强大的计算能力,Decode 需要高内存带宽——最彻底的解决方案是将它们部署在物理分离的 GPU 集群上:
- Prefill Worker(P 节点):专门处理输入 prompt 的并行计算,生成完整的 KV Cache。
- Decode Worker(D 节点):接收 P 节点传来的 KV Cache,负责逐 Token 的自回归生成。
这就是 PD 分离(Prefill-Decode Disaggregation) 架构。
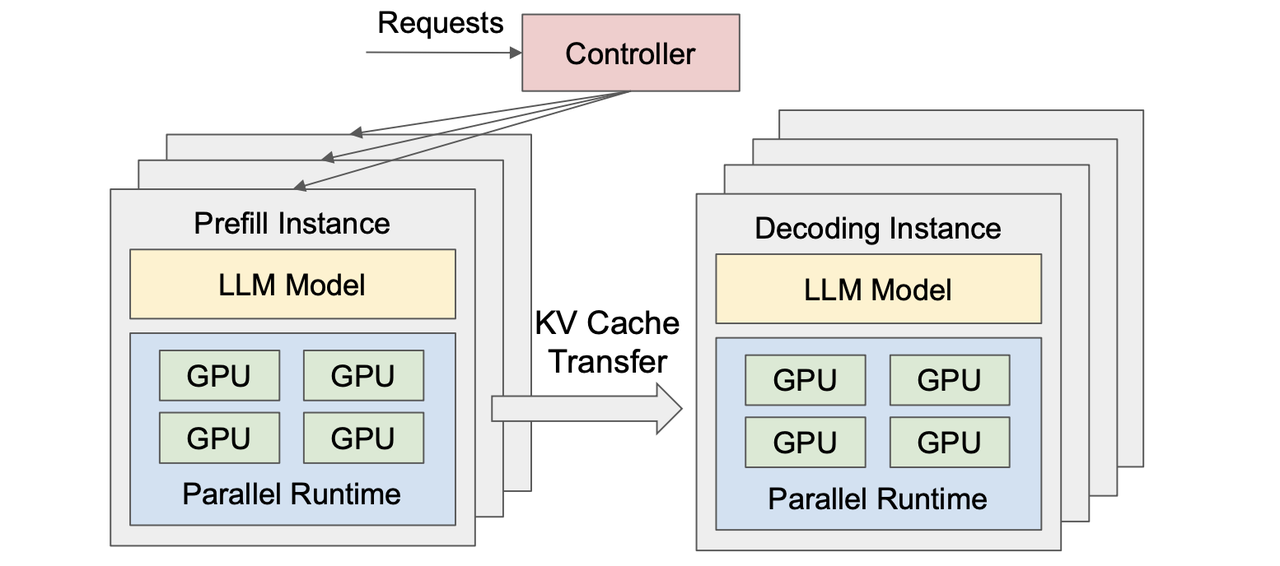
图 19-8:PD 分离架构。Controller 负责请求路由,Prefill 和 Decode 运行在独立的 GPU 实例上,通过 KV Cache 传输连接。
PD 分离的核心优势在于两个阶段不再相互干扰:
| 对比维度 | 混合部署 | PD 分离 |
|---|---|---|
| 资源竞争 | Prefill 和 Decode 抢占同一 GPU | 各自独占专用资源 |
| TTFT(首 Token 延迟) | 需等待 Decode 批次空出位置 | P 节点专注 Prefill,响应更快 |
| TPOT(Token 间延迟) | 被新请求的 Prefill 打断 | D 节点不受 Prefill 干扰 |
| 硬件异构优化 | 无法针对性优化 | 可为 P/D 选用不同硬件规格 |
表 19-2:混合部署与 PD 分离的对比。
通信协议:NCCL 与 NIXL。 PD 分离的关键挑战在于 KV Cache 的跨设备传输。KV Cache 的体积可能非常大(一个 70B 参数模型在 4K 序列长度下,单请求的 KV Cache 可达数百 MB),因此需要高效的通信协议:
- NCCL(NVIDIA Collective Communication Library):NVIDIA 官方的 GPU 间高性能通信库,适用于 P 和 D 节点位于同一集群内的场景。通过 NVLink 或 InfiniBand 等高速互连,NCCL 的
Send/Recv原语可以实现低延迟的 KV Cache 传输。 - NIXL(NVIDIA Interconnect eXtension Layer):NVIDIA 推出的新一代跨节点通信层,可以理解为"面向推理系统的远程 NCCL"。当 P 节点和 D 节点分布在不同数据中心或不同网段时,NIXL 提供了统一的抽象接口,支持 RDMA、GPU Direct 等多种传输后端,专门针对 PD 分离场景下的远程 KV Cache 传输进行了优化。
两者的定位关系可以这样理解:NCCL 负责同集群内的高速互联,NIXL 在此之上提供跨节点的远程扩展能力。
vLLM 中的 PD 分离实现。 vLLM 的 PD 分离架构由三个核心组件构成:
- Proxy API Server:接收用户请求,充当路由和协调者。
- vLLM Prefill:P 节点执行 Prefill 操作,生成 KV Cache,并将其传输给 D 节点。
- vLLM Decode:D 节点执行
drop_select操作——获取 P 节点传来的 KV Cache 并跳过 Prefill,直接进入 Decode 阶段开始逐 Token 生成。
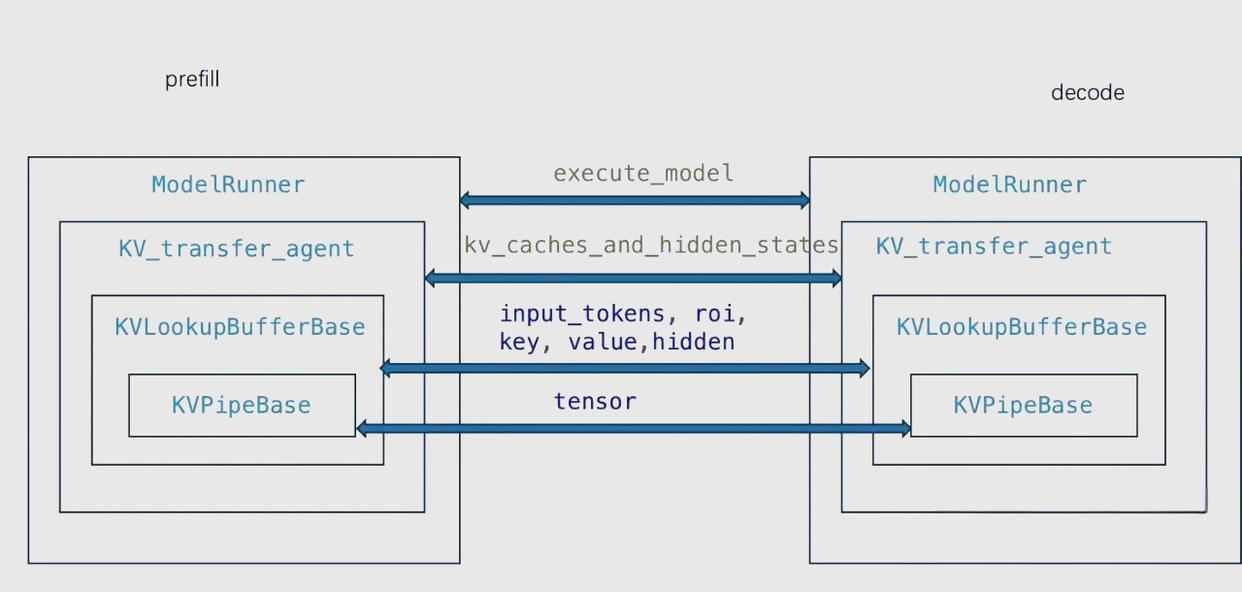
图 19-9:vLLM PD 分离的内部数据流。Prefill 端和 Decode 端各自拥有 ModelRunner,通过 KV_transfer_agent 和 KVPipeBase 完成 KV Cache 的跨设备传输。
请求的完整生命周期是:用户请求 → Proxy 转发到 P 节点 → P 节点做 Prefill 并传 KV Cache 给 D 节点 → D 节点做 Decode 逐 Token 输出 → Proxy 将 Token 流式返回用户。注意 P 节点只负责生成 KV Cache,所有 Token 输出都来自 D 节点。
PD 分离还有两种工程实现模式:
- Pooling 模式:P 节点将 KV Cache 发送到一个共享存储池(如 LMCache、Mooncake),D 节点从池中拉取。实现简单,但需要两次传输。
- P2P 模式:P 节点直接将 KV Cache 点对点发送给指定的 D 节点。只需一次传输,延迟更低,但需要路由协调逻辑。
下面用一个简化的 Python 模拟来展示 PD 分离的核心流程:
import time
from dataclasses import dataclass, field
@dataclass
class KVCache:
"""模拟 KV Cache 数据"""
req_id: int
num_layers: int
seq_len: int
size_mb: float = 0.0
def __post_init__(self):
# 简化估算: 每层 2(K+V) * seq_len * hidden_dim * dtype_bytes
self.size_mb = self.num_layers * 2 * self.seq_len * 4096 * 2 / 1e6
class PrefillWorker:
"""P 节点: 专注于 Prefill 计算"""
def __init__(self, num_layers: int = 32):
self.num_layers = num_layers
def process(self, req_id: int, prompt_len: int) -> KVCache:
# 模拟 Prefill 计算 (耗时与 prompt 长度正相关)
compute_time = prompt_len * 0.001 # 简化为线性
time.sleep(compute_time * 0.01) # 缩放以加速演示
return KVCache(req_id, self.num_layers, prompt_len)
class DecodeWorker:
"""D 节点: 专注于逐 Token 生成"""
def generate(self, kv: KVCache, max_tokens: int) -> list[int]:
tokens = []
for i in range(max_tokens):
# 模拟 Decode 一步 (访存密集, 耗时稳定)
tokens.append(hash((kv.req_id, i)) % 50000)
kv.seq_len += 1
return tokens
class PDDisaggregatedSystem:
"""PD 分离推理系统模拟"""
def __init__(self):
self.prefill = PrefillWorker(num_layers=32)
self.decode = DecodeWorker()
def serve(self, req_id: int, prompt_len: int, gen_len: int):
# 阶段 1: P 节点执行 Prefill
kv = self.prefill.process(req_id, prompt_len)
print(f" [P] req={req_id}: Prefill 完成, "
f"KV Cache={kv.size_mb:.1f}MB")
# 阶段 2: KV Cache 传输 (NCCL/NIXL)
transfer_time = kv.size_mb * 0.001 # 模拟传输延迟
print(f" [T] req={req_id}: KV Cache 传输中 "
f"({kv.size_mb:.1f}MB)")
# 阶段 3: D 节点执行 Decode
tokens = self.decode.generate(kv, gen_len)
print(f" [D] req={req_id}: Decode 完成, "
f"生成 {len(tokens)} tokens")
# --- 运行示例 ---
system = PDDisaggregatedSystem()
for rid, plen, glen in [(1, 512, 50), (2, 128, 200), (3, 2048, 30)]:
print(f"处理请求 {rid} (prompt={plen}, gen={glen}):")
system.serve(rid, plen, glen)这段代码清晰地展示了 PD 分离的三阶段流程:Prefill → KV Cache 传输 → Decode。在真实的生产系统中,多个请求可以在 P 节点和 D 节点上分别流水线式并行处理——当 P 节点在处理请求 2 的 Prefill 时,D 节点可以同时在做请求 1 的 Decode,两个阶段的硬件利用率都能得到最大化。
19.3.3 分块预填充(Chunked Prefill)
PD 分离虽然彻底解决了 Prefill 与 Decode 的干扰问题,但它需要额外的硬件资源和复杂的跨设备通信。有没有一种方法,在单 GPU 上也能缓解 Prefill 对 Decode 的干扰?答案是分块预填充(Chunked Prefill)。
核心思想。 不再一次性处理整个长 prompt,而是将其切分为固定大小的小块(例如 256 或 512 个 Token),每个调度周期只处理一个块。这样,在相邻两个 Prefill 块之间,调度器可以插入 Decode 迭代步,保证正在生成 Token 的请求不会被长时间阻塞。
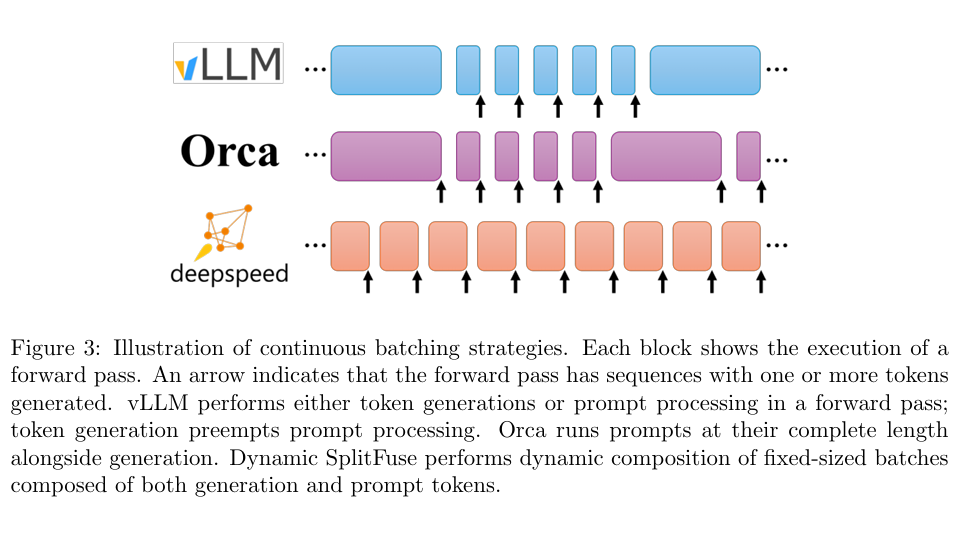
图 19-10:三种连续批处理策略对比。顶部 vLLM 采用 Prefill-first,中间 Orca 将完整 prompt 与生成混合执行,底部 DeepSpeed-FastGen 采用 DynamicSplitFuse 将 prompt 切块后与 Decode 融合,保持每次前向传播的 Token 数量稳定。
DeepSpeed-FastGen 将这一思想发展为 DynamicSplitFuse 策略,它包含两个互补的操作:
- Split(拆):将长 prompt 拆分为多个小块,分布在多次前向传播中逐步处理。只在最后一个块处理完时才开始生成 Token。
- Fuse(合):将多个短 prompt 合并在一起,与正在进行的 Decode Token 一起填满本次前向传播的 Token 预算。
其理论依据来自一个简洁的凸性分析。设
这意味着将
Chunked Prefill 在工程上的效果非常显著。以 vLLM 为例,启用 enable_chunked_prefill=True 后,调度器可以配置以下参数来精细控制行为:
| 参数 | 含义 |
|---|---|
max_num_partial_prefills | 允许同时进行的分块 Prefill 数量 |
max_long_partial_prefills | 长 prompt 的最大并发分块数 |
long_prefill_token_threshold | 判定"长 prompt"的 Token 数阈值 |
max_num_batched_tokens | 每次前向传播的最大 Token 预算 |
通过合理设置这些参数,可以在不同的业务场景下取得 TTFT 与 TPOT 的平衡:交互型服务适当增大并发分块数以降低首 Token 延迟;离线批处理任务则减小分块数以最大化吞吐。
下面用代码模拟 Chunked Prefill 的调度逻辑,展示长 prompt 如何被切块并与 Decode 交错执行:
from collections import deque
from dataclasses import dataclass
@dataclass
class ChunkedRequest:
req_id: int
total_prompt: int # 总 prompt Token 数
prefilled: int = 0 # 已 Prefill 的 Token 数
generated: int = 0 # 已生成的 Token 数
max_gen_len: int = 10 # 最大生成长度
@property
def needs_prefill(self) -> bool:
return self.prefilled < self.total_prompt
@property
def is_done(self) -> bool:
return (not self.needs_prefill
and self.generated >= self.max_gen_len)
class ChunkedPrefillScheduler:
"""分块预填充调度器"""
def __init__(self, token_budget: int = 512, chunk_size: int = 256):
self.token_budget = token_budget # 每步最大 Token 数
self.chunk_size = chunk_size # Prefill 块大小
self.waiting: deque[ChunkedRequest] = deque()
self.running: list[ChunkedRequest] = []
def add_request(self, req: ChunkedRequest):
self.waiting.append(req)
def step(self) -> dict:
"""一次调度迭代"""
budget = self.token_budget
decode_reqs, prefill_chunks = [], []
# 1. 优先安排 Decode (每个请求消耗 1 Token 预算)
active = [r for r in self.running if not r.is_done]
for r in active:
if not r.needs_prefill and budget >= 1:
decode_reqs.append(r)
r.generated += 1
budget -= 1
# 2. 用剩余预算做 Prefill 块
for r in list(active) + list(self.waiting):
if budget <= 0:
break
if r.needs_prefill:
remaining = r.total_prompt - r.prefilled
chunk = min(remaining, self.chunk_size, budget)
r.prefilled += chunk
budget -= chunk
prefill_chunks.append((r.req_id, chunk))
if r not in self.running:
self.waiting.remove(r)
self.running.append(r)
# 3. 清理已完成请求
self.running = [r for r in self.running if not r.is_done]
return {"decode": len(decode_reqs),
"prefill_chunks": prefill_chunks,
"budget_used": self.token_budget - budget}
# --- 运行示例 ---
scheduler = ChunkedPrefillScheduler(token_budget=512, chunk_size=256)
scheduler.add_request(ChunkedRequest(1, total_prompt=1024, max_gen_len=5))
scheduler.add_request(ChunkedRequest(2, total_prompt=128, max_gen_len=8))
for step in range(12):
info = scheduler.step()
if not info["budget_used"]:
break
print(f"Step {step}: decode={info['decode']}, "
f"prefill_chunks={info['prefill_chunks']}, "
f"budget_used={info['budget_used']}")运行这段代码可以观察到:请求 1 的 1024 Token prompt 被拆成了 4 个 256 Token 的块,分 4 步处理;而在每一步中,已经完成 Prefill 的请求 2 可以同时执行 Decode。这就是 Chunked Prefill 的"拆长补短"效果——长 prompt 不再独占整个前向传播,Decode 请求的 Token 间延迟保持稳定。
19.3.4 调度策略全景
不同的调度策略各有适用场景,下面的对比图展示了三种典型策略在时间线上的行为差异:
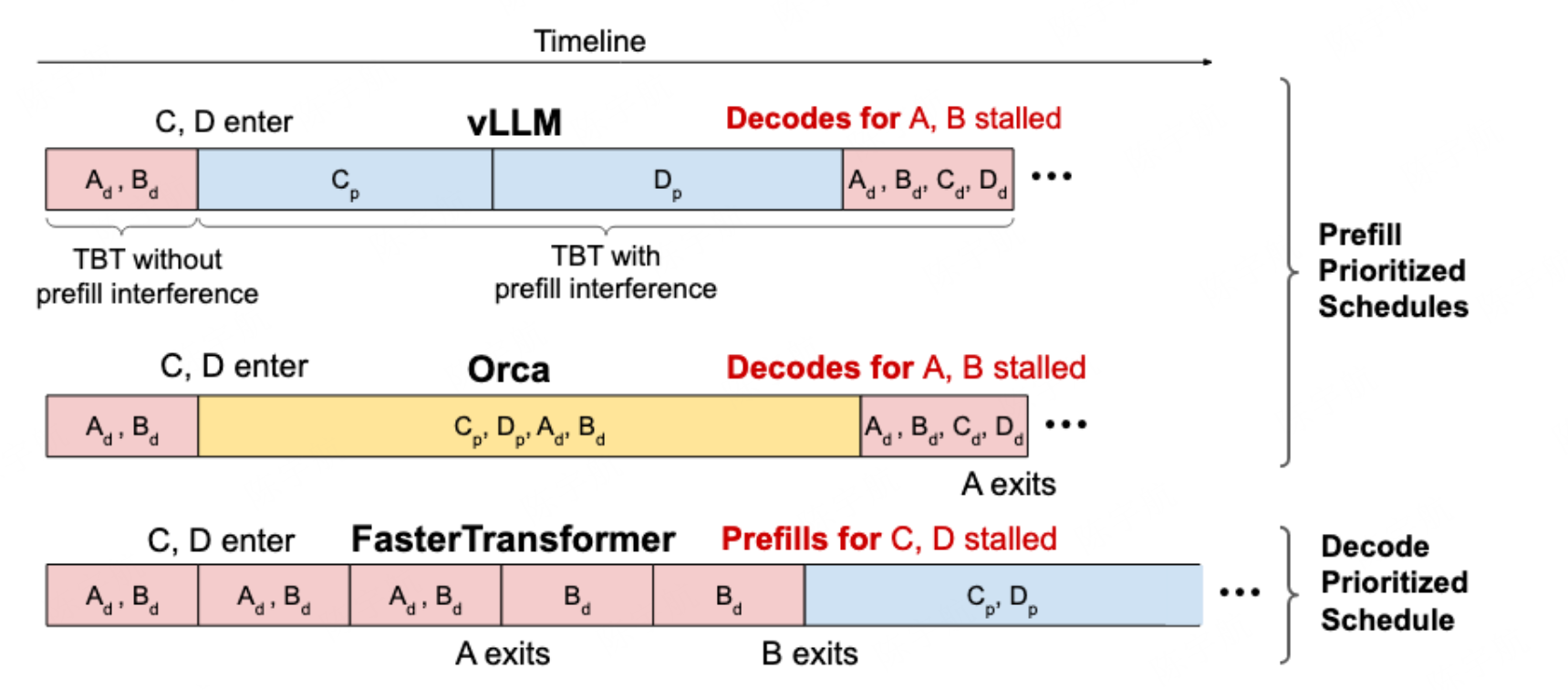
图 19-11:三种调度策略对比。上方 Prefill-Prioritized 策略导致 Decode 被阻塞;中间 Orca 混合调度;下方 Decode-Prioritized 策略保证了 Decode 的连续性但推迟了新请求的首 Token 生成。
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 静态批处理 | 实现最简单 | GPU 利用率低、尾延迟高 | 原型验证 |
| 连续批处理(Prefill-first) | 高吞吐、低 TTFT | Prefill 干扰 Decode、TPOT 抖动 | 吞吐优先的离线任务 |
| PD 分离 | 两阶段完全解耦、可异构部署 | 需额外硬件、KV Cache 传输开销 | 大规模生产部署 |
| 分块预填充 | 单 GPU 兼顾 TTFT 和 TPOT | 调参复杂、长 prompt 总时延略增 | 在线交互服务 |
表 19-3:主要调度策略对比。
在生产环境中,这些策略往往不是非此即彼的选择,而是分层组合使用的:
- 入口层:优先级队列区分请求类型(交互式 vs 批量任务),长请求分流到离线通道。
- 调度层:基于 Token 预算的 FCFS(先来先服务)调度,结合 Chunked Prefill 防止长 prompt 队首阻塞。对于多 GPU 集群,进一步采用 PD 分离实现阶段级负载均衡。
- 执行层:PagedAttention 管理 KV Cache 的物理显存,支持按需分配和回收,避免显存碎片。
- 资源管控层:当显存不足时触发抢占(Preemption)——将低优先级请求的 KV Cache 换出到 CPU(Swap)或直接丢弃后重算(Recompute),为高优先级请求腾出空间。
一个成熟的推理服务框架(如 vLLM、TensorRT-LLM、SGLang)通常同时支持多种策略,由运维人员根据业务指标(TTFT、TPOT、吞吐、尾延迟 P99 等)进行调优。
小结
本节沿着"为什么需要连续批处理 → 为什么需要 PD 分离 → 为什么需要 Chunked Prefill"的递进逻辑,介绍了推理系统中最核心的调度技术。连续批处理通过迭代级调度解决了静态批处理的等待浪费问题;PD 分离将 Prefill 和 Decode 部署在专用硬件上,借助 NCCL/NIXL 传输 KV Cache,彻底消除两阶段的资源竞争;分块预填充则在单 GPU 条件下通过拆分长 prompt 来缓解 Prefill 对 Decode 的干扰。这三项技术从不同层面回应了同一个核心矛盾——Prefill 的计算密集性与 Decode 的访存密集性之间的资源需求错配。理解这一矛盾,是设计高效推理服务的基础。