5.3 解码策略
语言模型在每个时间步输出词表上的 logits 向量,如何从这个向量中选出下一个 token,就是**解码策略(decoding strategy)**要解决的问题。不同策略在确定性与多样性之间做出不同取舍,直接影响生成文本的质量与风格。本节依次介绍贪心解码、温度缩放、Top-k 采样和 Top-p(核)采样,并给出每种策略的数学定义与 PyTorch 实现。
5.3.1 贪心解码
贪心解码是最简单的策略:每一步选取概率最大的 token。
数学定义。 设模型在第
由于
PyTorch 实现:
import torch
@torch.inference_mode()
def greedy_decode(model, token_ids, max_new_tokens, eos_token_id=None):
"""贪心解码:每步选取 logits 最大的 token。"""
for _ in range(max_new_tokens):
logits = model(token_ids)[:, -1, :] # (batch, vocab_size)
next_token = torch.argmax(logits, dim=-1, keepdim=True) # (batch, 1)
if eos_token_id is not None and (next_token == eos_token_id).all():
break
token_ids = torch.cat([token_ids, next_token], dim=1)
return token_ids贪心解码完全确定——相同输入永远产生相同输出。它的主要缺陷是局部最优不等于全局最优:每步选最大概率的 token,并不保证整个序列的联合概率最大。例如,"我喜欢吃饭"在每步都是局部最优,但"我喜欢学习"的联合概率可能更高。Beam Search 通过同时保留多条候选序列来缓解这一问题,但计算开销也相应增加。
5.3.2 温度缩放
温度缩放(temperature scaling)通过一个正标量
数学定义。 将 logits 除以温度后再做 softmax:
然后从该分布中随机采样:
直觉理解。 温度
:除以一个接近零的数使 logits 之间的差异被无限放大。softmax 后概率几乎全部集中在最大 logit 对应的 token 上,退化为贪心解码。分布变得极其"尖锐"。 :所有 logits 除以极大的数后趋近于零,softmax 输出接近均匀分布 。每个 token 被选中的概率几乎相等,输出变成随机噪声。
实际使用中,
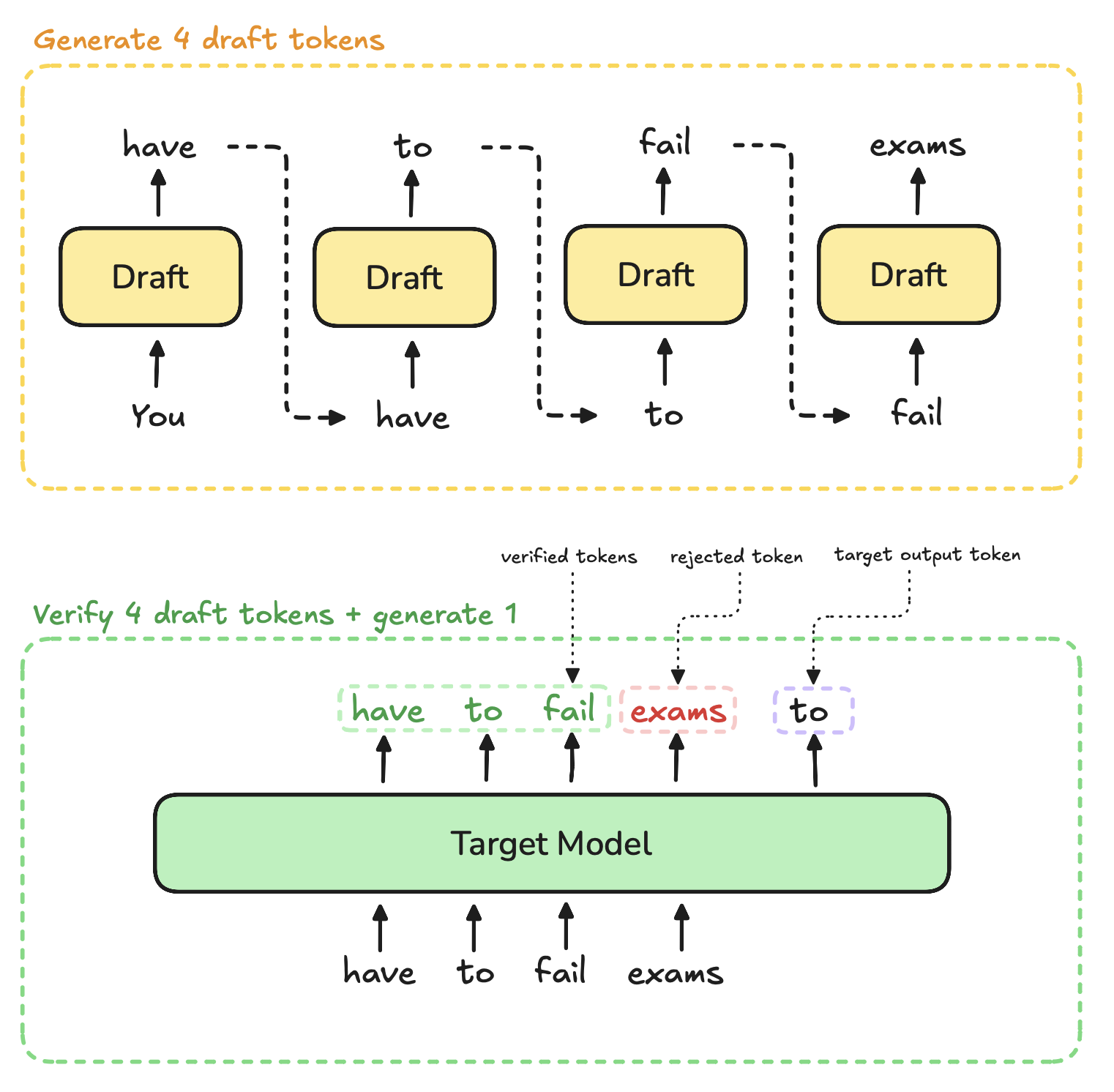
图 5-9:温度参数对概率分布的影响。T < 1 使分布更集中(更确定),T > 1 使分布更均匀(更随机),T = 1 保持原始分布不变。
PyTorch 实现:
def scale_logits_by_temperature(logits, temperature):
"""将 logits 除以温度参数。temperature 必须为正数。"""
if temperature <= 0:
raise ValueError("Temperature must be positive")
return logits / temperature
@torch.inference_mode()
def generate_with_temperature(model, token_ids, max_new_tokens,
temperature=1.0, eos_token_id=None):
"""基于温度缩放的随机采样解码。"""
for _ in range(max_new_tokens):
logits = model(token_ids)[:, -1, :]
if temperature == 0: # 退化为贪心
next_token = torch.argmax(logits, dim=-1, keepdim=True)
else:
scaled = scale_logits_by_temperature(logits, temperature)
probs = torch.softmax(scaled, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
if eos_token_id is not None and (next_token == eos_token_id).all():
break
token_ids = torch.cat([token_ids, next_token], dim=1)
return token_ids温度缩放虽然能调节随机性,但并不能阻止模型偶尔采样到概率极低的"长尾" token,从而产生不连贯的文本。接下来的 Top-k 和 Top-p 采样正是为了解决这一问题。
5.3.3 Top-k 采样
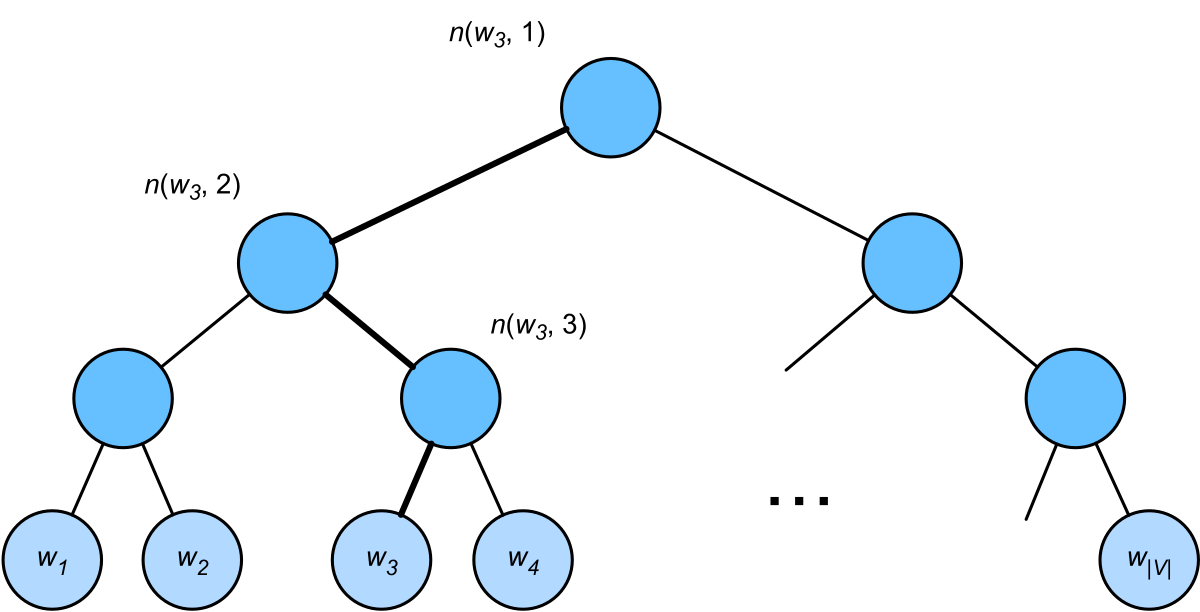
图 5-10:Softmax 温度缩放的数学原理。温度参数 T 作用于 logits 后再取 Softmax,T<1 使分布更尖锐(高确信度),T>1 使分布更平坦(高随机性)。
Top-k 采样将候选 token 限制为概率最高的
数学定义。 设
然后对
由于
PyTorch 实现:
def top_k_filter(logits, k):
"""保留 logits 中前 k 大的值,其余置为 -inf。"""
if k is None or k <= 0:
return logits
top_values, _ = torch.topk(logits, k, dim=-1)
min_top_value = top_values[:, -1].unsqueeze(-1) # 第 k 大的值
return torch.where(logits >= min_top_value, logits,
torch.full_like(logits, float('-inf')))
@torch.inference_mode()
def generate_with_top_k(model, token_ids, max_new_tokens,
temperature=1.0, k=50, eos_token_id=None):
"""Top-k 采样解码,可与温度缩放联合使用。"""
for _ in range(max_new_tokens):
logits = model(token_ids)[:, -1, :]
# 先做 Top-k 过滤,再做温度缩放
logits = top_k_filter(logits, k)
if temperature > 0:
logits = scale_logits_by_temperature(logits, temperature)
probs = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
if eos_token_id is not None and (next_token == eos_token_id).all():
break
token_ids = torch.cat([token_ids, next_token], dim=1)
return token_idsTop-k 的缺点在于
5.3.4 Top-p(核)采样
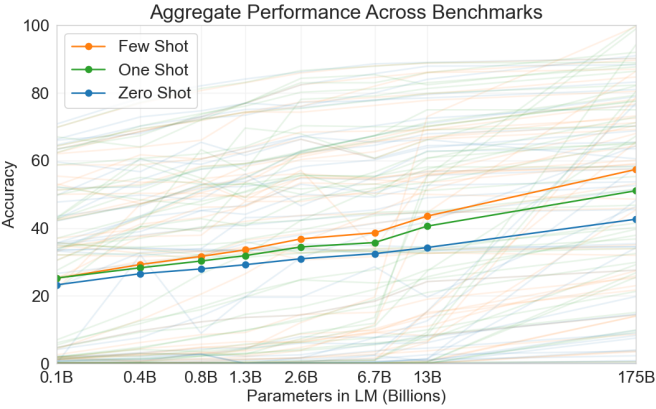
图 5-11:不同采样策略下模型输出的多样性。从贪心解码到 Top-k、Top-p,采样范围逐步扩大,生成文本的多样性和创造性也随之增加。
Top-p 采样(也称核采样,nucleus sampling)不固定候选数量,而是取累积概率刚好超过阈值
数学定义。 将所有 token 按概率降序排列为
即累积概率首次达到
当模型确信度高时,也许只需 2–3 个 token 即可覆盖
PyTorch 实现:
def top_p_filter(probs, top_p):
"""对概率分布应用 Top-p 过滤并重归一化。"""
if top_p is None or top_p >= 1.0:
return probs
# 按概率降序排列
sorted_probs, sorted_idx = torch.sort(probs, dim=-1, descending=True)
# 计算累积概率
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
# 保留累积概率(不含当前 token)< top_p 的 token
# 这样恰好包含使累积概率首次超过 top_p 的那个 token
prefix_mask = (cumulative_probs - sorted_probs) < top_p
prefix_mask[:, 0] = True # 至少保留概率最大的 token
# 置零被过滤的 token
kept_sorted = torch.where(prefix_mask, sorted_probs,
torch.zeros_like(sorted_probs))
# 恢复原始词表顺序
filtered = torch.zeros_like(probs).scatter(-1, sorted_idx, kept_sorted)
# 重归一化
return filtered / filtered.sum(dim=-1, keepdim=True).clamp(min=1e-12)
@torch.inference_mode()
def generate_with_top_p(model, token_ids, max_new_tokens,
temperature=1.0, top_p=0.9, eos_token_id=None):
"""Top-p 核采样解码,可与温度缩放联合使用。"""
for _ in range(max_new_tokens):
logits = model(token_ids)[:, -1, :]
# 温度缩放
if temperature > 0:
logits = scale_logits_by_temperature(logits, temperature)
# logits → 概率 → Top-p 过滤
probs = torch.softmax(logits, dim=-1)
probs = top_p_filter(probs, top_p)
next_token = torch.multinomial(probs, num_samples=1)
if eos_token_id is not None and (next_token == eos_token_id).all():
break
token_ids = torch.cat([token_ids, next_token], dim=1)
return token_ids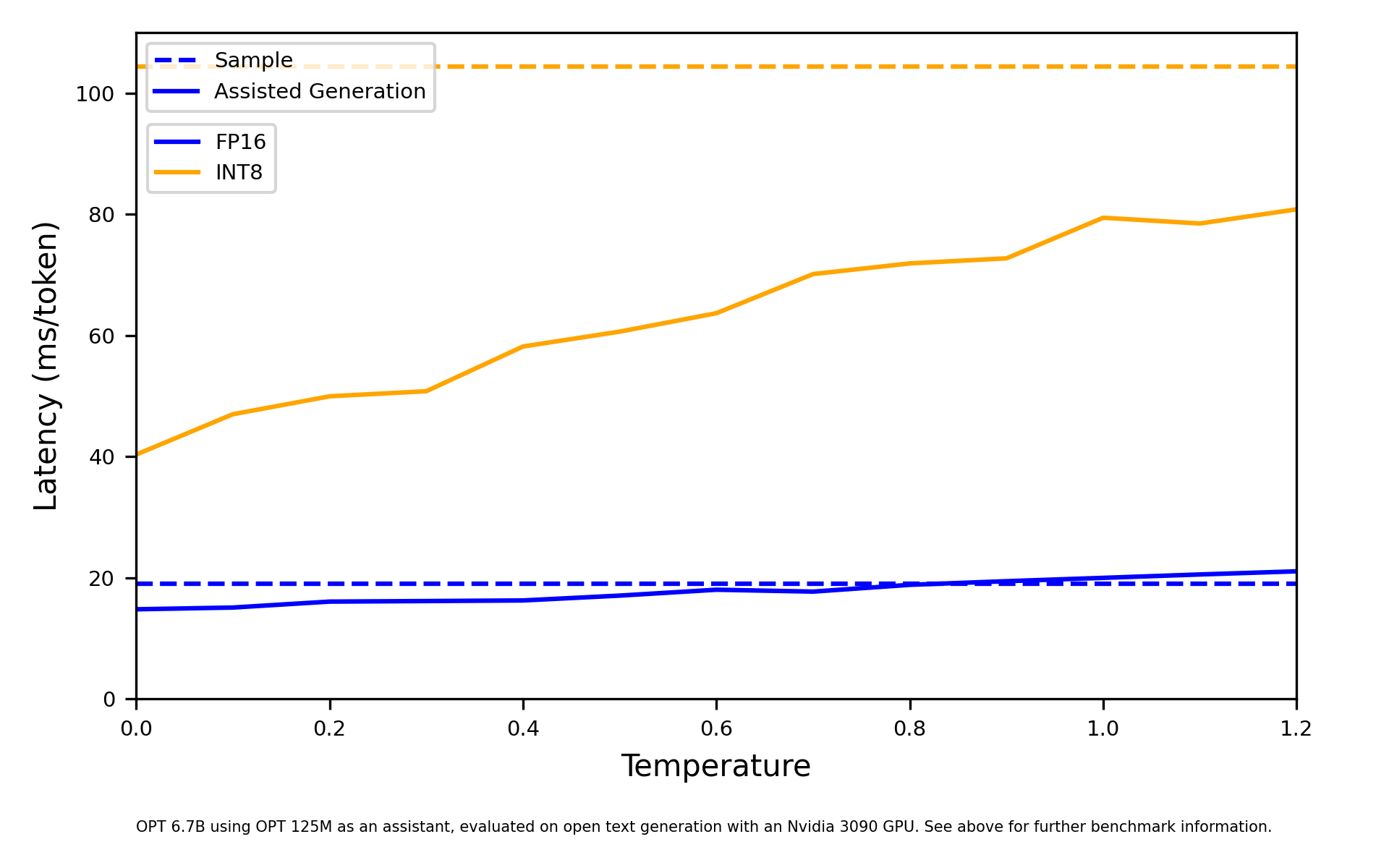
图 5-12:解码策略对比。贪心解码输出确定但缺乏多样性,Top-k 和 Top-p 采样在确定性与创造性之间取得不同平衡。
5.3.5 策略对比与总结
下表汇总了四种解码策略的核心特征:
| 策略 | 随机性 | 候选集大小 | 典型用途 |
|---|---|---|---|
| 贪心解码 | 无 | 1 | 事实问答、代码生成等需要确定性输出的场景 |
| 温度缩放 | 可调 | 全词表 | 作为基础手段,几乎总与 Top-k/Top-p 联合使用 |
| Top-k 采样 | 有 | 固定 | 简单有效,适合对多样性要求适中的场景 |
| Top-p 采样 | 有 | 动态(自适应) | 自动适配模型确信度,是当前主流推理服务的默认选项 |
实践中的常见组合。 主流推理框架(如 vLLM、HuggingFace TGI)通常同时启用温度缩放与 Top-p 采样。一组常见的默认参数是
执行顺序。 当多种策略联合使用时,典型流程为:
先在 logits 空间做 Top-k 截断(因为 Top-k 只看相对大小,与缩放无关),再做温度缩放和 softmax 转概率,最后做 Top-p 过滤并采样。
本节小结
- 贪心解码简单高效,但局部最优不等于全局最优,输出缺乏多样性。
- 温度
控制分布锐度—— 使分布更尖锐(更确定), 使分布更平坦(更随机)。 - Top-k 固定候选数量,实现简单但不够灵活。
- Top-p 根据累积概率动态确定候选集大小,能更好地适配模型在不同位置的确信度差异。
- 解码策略不改变模型参数,仅作用于推理阶段的采样过程,是一种零成本的输出调优手段。