21.5 GRPO + Agent(环境接口层)
在 RLVR(Reinforcement Learning with Verifiable Rewards)的经典范式中,模型生成一个完整回答,获得一个奖励信号,然后更新参数——整个过程干净、简单,本质上是一个 in-context bandit 问题。但当我们将训练场景从"解一道数学题"拓展到"在真实环境中执行多步操作"时,一切都变了。模型不再只是"给出答案",而是要在不断变化的环境中 持续决策:观察环境反馈、调用工具、修正策略、为最终结果负责。这种从静态数据集到动态环境交互的跃迁,是 GRPO 从推理训练走向 Agent 训练的核心挑战。

图 21-5a:RLVR 与 Agentic RL 的关系。RLVR 是单步的"给答案拿奖励",而 Agentic RL 要求模型在多步交互中持续决策。算法、基础设施和环境/数据三者之间的协同决定了训练成败。
本节的定位是 桥梁:一端连接 GRPO 的数学定义(已在 §16.3 完整推导),另一端通向完整的 Agentic RL 训练系统(将在 §21.9 深入展开)。本节聚焦的问题是——环境接口层:当 Agent 需要与真实环境交互时,如何设计标准化的环境 API?如何让环境产生的奖励回传到 GRPO 的训练循环中?如何处理动态交互带来的长尾延迟和噪声信号?
21.5.1 从静态数据集到动态环境:为什么需要环境接口
在 §16.3 的 GRPO 训练流程中,奖励的产生非常直接:模型生成若干条回答,每条回答通过一个 验证函数(如检查数学结果是否正确)获得奖励
但 Agent 场景打破了这一假设。考虑一个终端操作任务"在 Linux 服务器上配置 Nginx 反向代理":
- Agent 需要先检查系统环境(
cat /etc/os-release) - 根据操作系统选择安装命令(
apt install nginx或yum install nginx) - 编辑配置文件(
vi /etc/nginx/nginx.conf) - 重启服务(
systemctl restart nginx) - 验证配置是否生效(
curl localhost)
每一步都会 改变环境状态,下一步的最优动作取决于上一步的执行结果。奖励不是从模型的一次性输出中计算的,而是从模型与环境的 多轮交互轨迹 的最终结果中获得。这就要求训练框架具备与环境交互的能力——而环境接口正是承载这一能力的关键组件。
将 RLVR 与 Agent 训练的关键差异梳理如下:
| 维度 | RLVR(静态奖励) | Agent 训练(环境驱动奖励) |
|---|---|---|
| 交互步数 | 单步(一次生成) | 多步(持续交互) |
| 奖励来源 | 验证函数直接判定 | 环境状态反馈 |
| 状态空间 | 无(输入固定) | 动态变化 |
| 动作空间 | 完整文本 | 工具调用 / 命令序列 |
| 时间开销 | 均匀(生成时间相近) | 长尾分布(有的任务几秒,有的几十分钟) |
| 失败模式 | 答案错误 | 环境崩溃、工具超时、无效循环 |
这张对比表揭示了一个核心事实:Agent 训练中的 GRPO 不仅需要一个新的奖励计算方式,更需要一整套环境管理基础设施。
21.5.2 OpenEnv:Gymnasium 风格的环境框架
为了标准化 Agent 与环境的交互接口,Meta 的 PyTorch 团队推出了 OpenEnv 框架。如果你熟悉经典 RL 中的 Gymnasium(原 OpenAI Gym),那么 OpenEnv 就是它在 LLM Agent 世界的对应物——提供 reset() 和 step() 两个核心 API,让任何环境都能以统一的方式被 Agent 调用。
核心 API 设计
OpenEnv 遵循 Gymnasium 的经典接口设计,但将状态和动作从数值向量扩展为文本和结构化数据:
# Gymnasium 经典接口(回顾)
env = gym.make("CartPole-v1")
obs, info = env.reset() # 重置环境,获取初始观测
obs, reward, done, truncated, info = env.step(action) # 执行动作,获取奖励
# OpenEnv 的 LLM Agent 接口(同构设计)
from echo_env import EchoEnv, EchoAction
env = EchoEnv(base_url="http://0.0.0.0:8001")
result = env.reset() # 重置环境,获取初始观测(文本)
result = env.step(EchoAction(message="hello")) # 执行动作,获取奖励
# result.observation → 环境返回的文本观测
# result.reward → 本步奖励(float)
# result.done → 是否终止(bool)这种同构设计的直接好处是:所有为 Gymnasium 生态编写的训练逻辑——rollout 循环、奖励收集、轨迹存储——只需做最小修改就能适配 LLM Agent 的训练场景。
三种部署方式
OpenEnv 支持三种灵活的环境部署模式,适应不同的开发和训练需求:
# 方式一:从 Hugging Face Hub 加载(推荐,自动启动 Docker 容器)
env = EchoEnv.from_hub("openenv/echo-env")
# 方式二:连接远程 HF Space
env = EchoEnv(base_url="https://openenv-echo-env.hf.space")
# 方式三:本地启动(适合开发调试)
# 终端运行:python -m uvicorn echo_env.src.envs.echo_env.server.app:app --port 8001
env = EchoEnv(base_url="http://0.0.0.0:8001")环境目录
OpenEnv 提供了一个不断扩展的环境目录(Environment Catalog),包括:
- EchoEnv:最简单的环境,根据输出文本长度给奖励,适合教学和快速验证
- TextArena:文本游戏环境集合(Wordle、Tic-Tac-Toe、Snake 等),训练模型的推理和策略能力
- 自定义环境:开发者可以构建并推送自己的环境到 Hub,供社区复用
这种"环境即服务"的设计理念,使得环境的开发、分发和复用变得极为便捷,也为大规模 Agent 训练提供了标准化基础。
21.5.3 环境驱动奖励:接入 GRPO 训练循环
理解了环境接口之后,核心问题变为:如何将环境产生的奖励无缝接入 GRPO 的训练循环? TRL 框架通过 rollout_func 机制提供了一个优雅的解决方案。
rollout_func 的设计哲学
在标准的 GRPO 训练中,GRPOTrainer 负责生成 completion、计算奖励、更新策略。但当 Agent 需要与环境交互时,生成和奖励计算这两步必须嵌入到环境循环中。rollout_func 允许用户 完全接管 rollout 过程,只要返回约定格式的字典即可:
def rollout_func(
prompts: list[str],
trainer: GRPOTrainer,
) -> dict[str, list]:
"""
自定义 rollout 函数签名。
返回字典必须包含:
- prompt_ids: 每条 prompt 的 token ID 列表
- completion_ids: 每条 completion 的 token ID 列表
- logprobs: 每个 token 的对数概率
额外字段会自动透传到奖励函数的 **kwargs 中
"""
pass关键设计点:返回字典中除三个必需字段外的 任何额外字段,都会被自动转发到奖励函数的 **kwargs 参数中。这意味着环境产生的奖励信号可以直接"穿透" rollout 传递给奖励函数,无需修改 GRPOTrainer 的任何内部逻辑。
最小完整示例:Echo 环境
下面展示一个完整的、可运行的 GRPO + 环境训练代码。Echo 环境根据输出文本长度给予奖励,鼓励模型生成更长的输出:
from datasets import Dataset
from echo_env import EchoEnv, EchoAction
from trl import GRPOConfig, GRPOTrainer
from trl.experimental.openenv import generate_rollout_completions
# 1. 创建环境客户端
client = EchoEnv.from_hub("openenv/echo-env")
# 2. 定义 rollout 函数:生成 + 环境交互
def rollout_func(prompts: list[str], trainer: GRPOTrainer):
# 生成 completions(自动复用 trainer 的采样配置)
outputs = generate_rollout_completions(trainer, prompts)
tokenizer = trainer.processing_class
completions_text = [
tokenizer.decode(out["completion_ids"], skip_special_tokens=True)
for out in outputs
]
# 与环境交互,收集奖励
client.reset()
env_rewards = []
for msg in completions_text:
env_result = client.step(EchoAction(message=msg))
env_rewards.append(env_result.reward)
# 返回标准字段 + 额外的环境奖励
return {
"prompt_ids": [out["prompt_ids"] for out in outputs],
"completion_ids": [out["completion_ids"] for out in outputs],
"logprobs": [out["logprobs"] for out in outputs],
"env_reward": env_rewards, # 额外字段,自动透传
}
# 3. 定义奖励函数:从 kwargs 中提取环境奖励
def reward_from_env(completions, **kwargs):
env_rewards = kwargs.get("env_reward", [])
return [float(r) for r in env_rewards] if env_rewards else [0.0] * len(completions)
# 4. 组装训练器
dataset = Dataset.from_dict({
"prompt": ["Echo environment interaction prompt:"] * 64
})
trainer = GRPOTrainer(
model="Qwen/Qwen2.5-0.5B-Instruct",
reward_funcs=reward_from_env,
train_dataset=dataset,
rollout_func=rollout_func,
args=GRPOConfig(
use_vllm=True,
vllm_mode="colocate",
num_train_epochs=1,
num_generations=8,
max_completion_length=2048,
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
),
)
trainer.train()这段代码的数据流可以概括为五步闭环:
注意这里 GRPO 的核心数学没有任何改变——组内相对优势、裁剪比率、KL 约束等全部复用 §16.3 的定义。改变的只是 奖励的来源:从静态验证函数变成了动态环境反馈。
21.5.4 多步交互环境:以 Wordle 为例的深度集成
Echo 环境是单步交互——模型生成一次回复,环境返回一个奖励。但真正的 Agent 场景往往是 多步 的。TextArena 的 Wordle 猜词游戏展示了多步环境交互如何与 GRPO 集成。
Wordle 的 MDP 建模
- 状态空间:当前的字母反馈矩阵(哪些字母位置正确/存在/不存在)
- 动作空间:一个五字母英文单词
- 奖励:猜对得 1.0,猜错得 0.0(极其稀疏)
- 终止条件:猜对或达到 6 次猜测上限
多步 rollout 的实现模式
在多步场景中,rollout_func 不再是"生成一次 + 拿一次奖励",而是一个完整的 episode 循环:
def rollout_once(trainer, env, tokenizer, system_prompt, max_turns):
result = env.reset()
observation = result.observation
prompt_ids, completion_ids, logprobs = [], [], []
green_scores, yellow_scores, repetition_scores = [], [], []
guess_counts = {}
for turn in range(max_turns):
if result.done:
break
# 构造当前步的 prompt(含历史交互)
user_prompt = make_user_prompt(observation)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
prompt_text = tokenizer.apply_chat_template(
messages, add_generation_prompt=True, tokenize=False
)
# 模型生成猜测
rollout_out = generate_rollout_completions(trainer, [prompt_text])[0]
prompt_ids.extend(rollout_out["prompt_ids"])
completion_ids.extend(rollout_out["completion_ids"])
logprobs.extend(rollout_out["logprobs"])
# 提取猜测并执行环境步进
guess = extract_guess(rollout_out)
result = env.step(TextArenaAction(message=guess))
observation = result.observation
# 收集中间信号
feedback = extract_wordle_feedback(observation)
green_scores.append(count_greens(feedback) / 5.0)
yellow_scores.append(count_yellows(feedback) / 5.0)
repetition_scores.append(compute_repetition_penalty(guess, guess_counts))
return {
"prompt_ids": prompt_ids,
"completion_ids": completion_ids,
"logprobs": logprobs,
"correct_reward": float(result.reward or 0.0),
"green_reward": green_scores[-1] if green_scores else 0.0,
"yellow_reward": yellow_scores[-1] if yellow_scores else 0.0,
"repetition_reward": repetition_scores[-1] if repetition_scores else 0.0,
}复合奖励设计
Wordle 的环境奖励极其稀疏——只有最终猜对才给 1.0,否则全为 0.0。单靠这个信号,模型几乎无法学习。解决方案是设计 多维复合奖励,通过中间信号引导学习:
# 四路奖励函数,分别提取不同维度的信号
reward_funcs = [
reward_correct, # 最终是否猜对 (0.0 / 1.0)
reward_greens, # 绿色字母密度(位置正确的比例)
reward_yellows, # 黄色字母密度(字母存在但位置不对的比例)
reward_repetition, # 重复猜测惩罚(鼓励探索新组合)
]这种复合奖励的设计思路具有普遍性:在任何环境奖励稀疏的 Agent 场景中,都可以从环境的中间反馈中提取 辅助信号 来加速学习。这些辅助奖励不改变最终的优化目标(猜对词),但为 GRPO 的组内对比提供了更丰富的区分度——即使所有 completion 都没猜对,green 和 yellow 的多少也能区分"差一点猜对"和"完全瞎猜"。
21.5.5 环境状态表示与动作空间设计
在真实的 Agent 训练中,环境接口的设计远不止 reset() 和 step() 两个 API。如何表示环境状态、如何定义动作空间,直接决定了模型能否有效学习。
环境状态的结构化表示
对于 LLM Agent,环境状态通常被编码为 自然语言文本,而非传统 RL 中的数值向量。但这并不意味着可以随意拼接。ROLL 团队在实践中总结了两种环境管理模式:
- Roll-Managed 模式:训练框架负责上下文管理和轨迹构建,灵活但可能与真实 Agent 行为存在偏差
- CLI-Native 模式:直接在真实 Agent 框架上训练,上下文由 Agent 框架维护,保证训练与部署的一致性
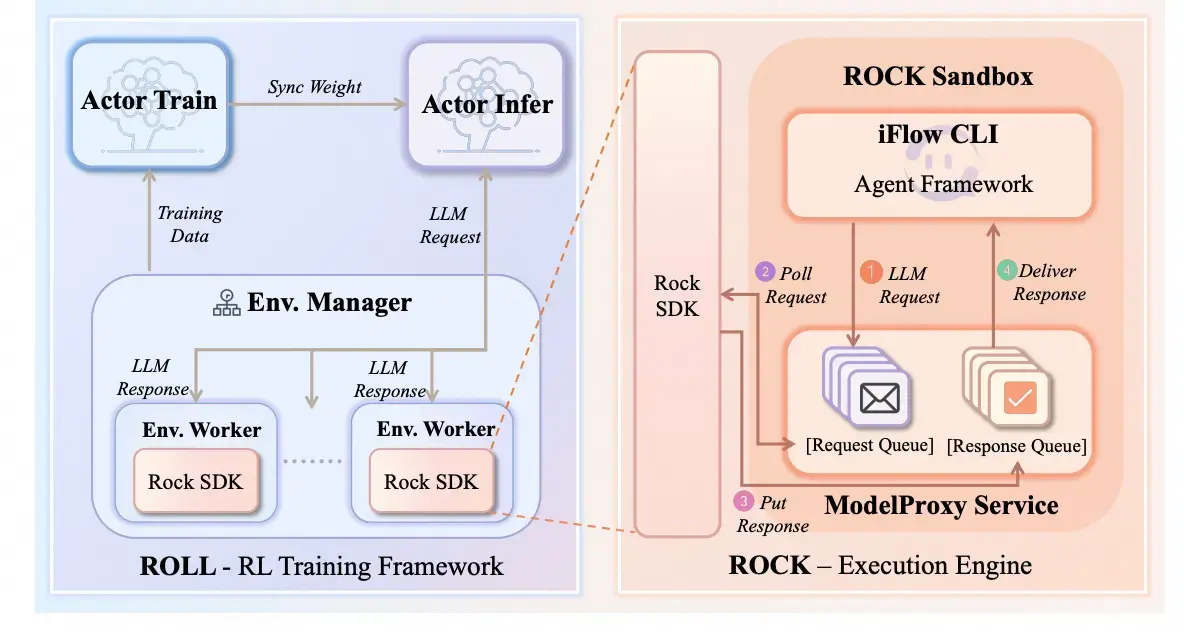
图 21-5b:ROLL(训练框架)与 ROCK(沙箱执行引擎)的协作架构。左侧 ROLL 负责 RL 训练循环(Actor Train/Infer、环境管理),右侧 ROCK 负责沙箱生命周期管理和 Agent 框架执行。ModelProxy Service 提供异步消息队列,实现两端的非阻塞通信。
这两种模式的选择涉及一个根本性的权衡:灵活性 vs 一致性。Roll-Managed 模式允许在训练时引入丰富的 prompt 模板和交互机制来提升鲁棒性,但训练时的 prompt 构造方式与真实部署可能不同,导致能力迁移损失。CLI-Native 模式确保模型在训练时看到的输入分布与部署时完全一致,但牺牲了训练侧的定制灵活性。
动作空间的层级化设计
传统 RL 的动作空间是离散的(如上下左右)或连续的(如力矩大小),维度固定。但 LLM Agent 的动作空间是 自然语言生成——理论上无限大。实践中,通过 工具调用格式 对动作空间进行结构化约束:
# 动作空间通过工具定义进行结构化
tools = [
{"name": "bash", "params": {"command": "string"}},
{"name": "read_file", "params": {"path": "string"}},
{"name": "write_file", "params": {"path": "string", "content": "string"}},
{"name": "search", "params": {"query": "string", "directory": "string"}},
]
# 模型的"动作"是选择一个工具并填充参数
# 例如:{"tool": "bash", "params": {"command": "ls -la /etc/nginx/"}}这种设计将无限的文本生成空间收敛为"选择工具 + 填充参数"的结构化决策,大幅降低了策略搜索的难度。
环境增强:防止过拟合
一个容易被忽视但至关重要的设计是 环境多样性。如果 Agent 总是在完全相同的初始环境中训练,它会学会依赖特定的软件版本、镜像源配置或预安装依赖,而无法泛化到真实场景。

图 21-5c:环境增强(Environment Augmentation)的四种场景。理想化环境(A)中 Agent 可以直接执行;但真实场景中可能遇到镜像源不可用(B)、依赖缺失(C)或配置错误(D)。通过有意扰动环境初始状态,迫使 Agent 学会"行动前先检查"。
ROLL 团队在实践中发现,故意引入环境扰动——如移除预装依赖、切换到不可用的镜像源——相当于一种 数据增强,能显著提升 Agent 的泛化能力和鲁棒性。
21.5.6 环境交互的工程挑战
将 GRPO 从静态奖励扩展到环境驱动奖励,最大的工程挑战不在算法层面,而在 基础设施层面。这里介绍三个核心问题及其解决方案。
长尾延迟问题
Agent 与环境的交互时间具有显著的 长尾分布:大多数 rollout 在几秒内完成,但少数 rollout 因为环境编译慢、网络延迟、或 Agent 陷入无效循环而耗时极长。在同步批量训练中,这些长尾任务会成为 拖尾瓶颈(straggler bottleneck),导致整个 batch 等待最慢的那个 rollout,GPU 利用率急剧下降。
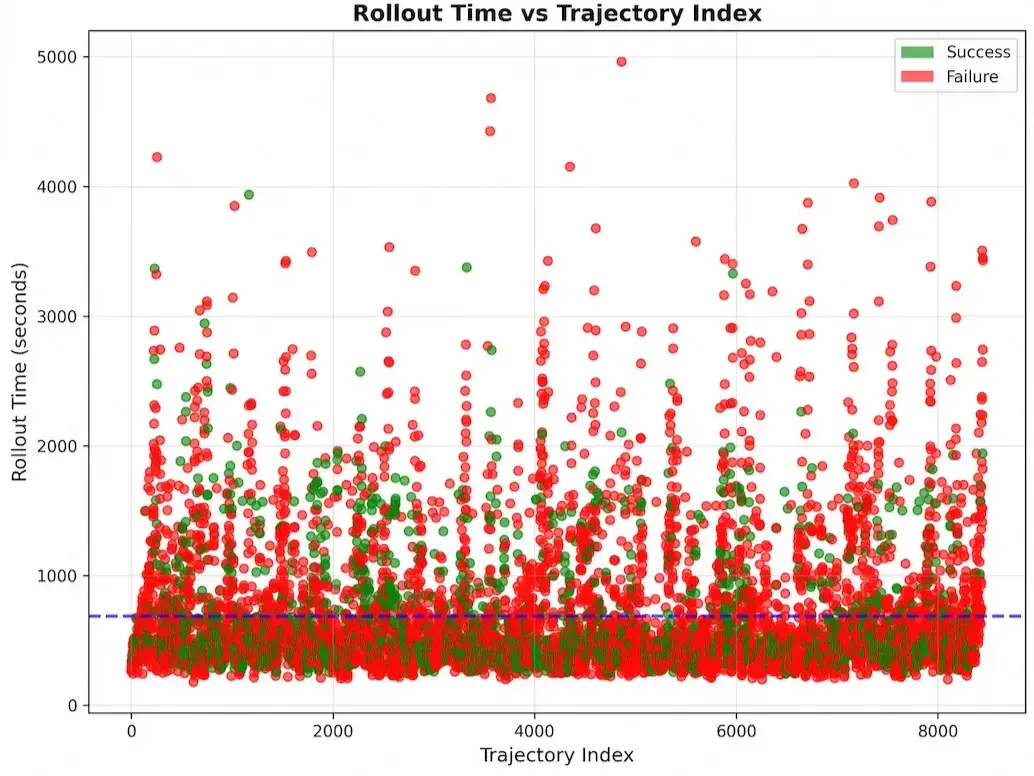
图 21-5d:Rollout 时间 vs 轨迹索引。绿色点为成功轨迹,红色点为失败轨迹。大多数轨迹在 1000 秒内完成,但存在大量超过 3000 秒的长尾样本,这些样本在同步训练中会导致严重的 GPU 空转。
同步 vs 异步 rollout 调度
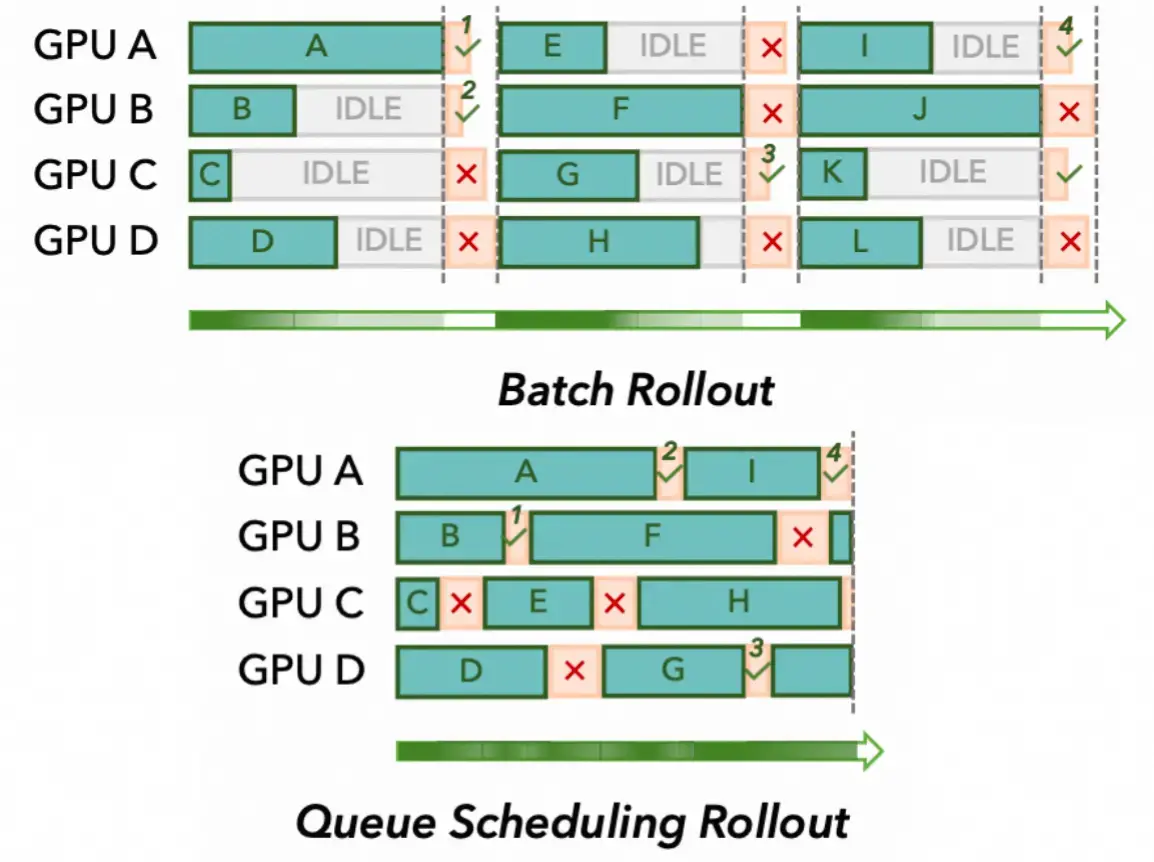
图 21-5e:两种 rollout 调度策略对比。上方的 Batch Rollout 中,GPU 必须等待最慢的任务完成才能开始下一批(大量 IDLE);下方的 Queue Scheduling Rollout 中,每个 GPU 完成一个任务后立即领取下一个,消除了等待时间。
异步训练管线的核心思想是将 rollout 的三个阶段——LLM 生成、环境交互、奖励计算——完全解耦,使其可以独立调度:
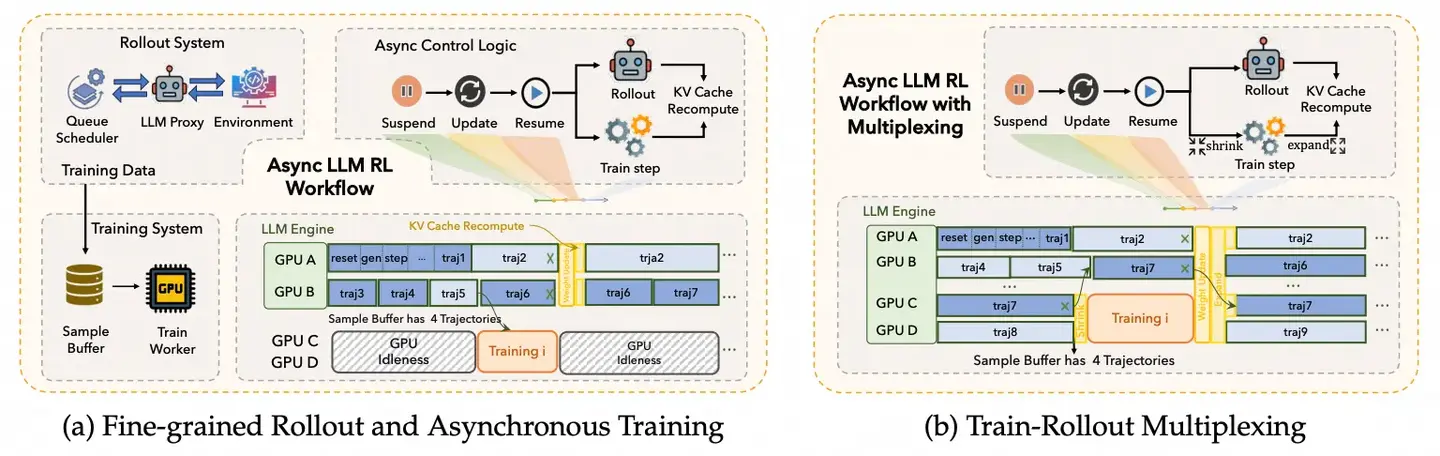
图 21-5f:异步 LLM RL 训练架构。(a)细粒度异步 rollout:LLM 推理、环境交互和训练各自独立运行在不同 GPU 上,通过样本缓冲区异步交换数据;(b)Train-Rollout 复用:在同一组 GPU 上通过时间分片交替执行推理和训练,进一步提升利用率。
vLLM 的两种执行模式
TRL 框架为环境训练提供了两种 vLLM 部署方式,对应不同的资源和规模需求:
# 模式一:Colocate(共址模式,1 GPU)
# vLLM 与训练运行在同一进程中,适合快速实验
args = GRPOConfig(
use_vllm=True,
vllm_mode="colocate",
)
# 模式二:Server(服务模式,2+ GPU)
# vLLM 作为独立推理服务器运行,可多 GPU 并行
# 启动:CUDA_VISIBLE_DEVICES=0,1 trl vllm-serve --model Qwen/Qwen3-1.7B --tensor-parallel-size 2
args = GRPOConfig(
use_vllm=True,
vllm_mode="server",
vllm_server_base_url="http://localhost:8000",
)Server 模式的优势在于 解耦推理与训练:推理服务器可以被多个训练进程共享,可以使用不同型号的 GPU(如用 A100 做推理、H100 做训练),并且支持水平扩展。
噪声信号的 Mask & Filter
在真实环境中训练 Agent,不可避免地会遇到各种 非模型原因的失败:沙箱启动失败、网络超时、工具调用异常等。如果将这些噪声信号直接纳入策略更新,会严重干扰学习。
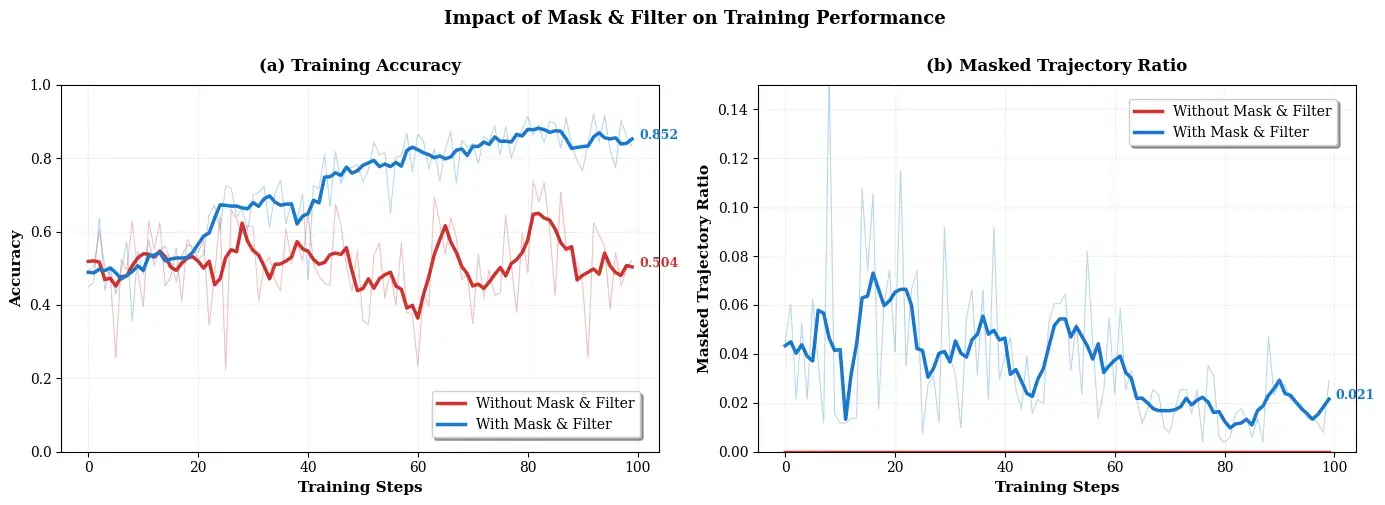
图 21-5g:Mask & Filter 策略的效果。不使用该策略时(红色),训练准确率波动大且收敛到较低水平(约 0.704);使用后(蓝色),训练更稳定且收敛到更高水平(约 0.832)。右图显示被 mask 的轨迹比例随训练推进逐渐降低。
实践中的处理策略分为两级:
# 第一级:不可恢复错误 → Mask(保留占位但零梯度)
if failure_type in {"env_init_failed", "sandbox_unavailable"}:
placeholder = create_placeholder_rollout()
placeholder.response_mask[:] = 0 # 梯度归零
placeholder.advantages[:] = 0
placeholder.rewards[:] = 0
return placeholder
# 第二级:偶发可恢复错误 → Filter(直接丢弃,但控制总比例 ≤ 50%)
if transient_error and global_filter_ratio < 0.5:
return None # 丢弃该样本这里的设计原则很简单:对训练有害或无法提供有效学习信号的样本,都应该被移除。但 Filter 比例需要设置上限(如 50%),否则在环境大面积故障时可能没有足够的数据完成训练。
21.5.7 奖励函数设计:从结果奖励到多维信号
奖励函数的设计是 Agent 训练中最需要领域知识的环节。一个好的奖励函数需要平衡三个目标:信号密度(能区分好坏)、信号可靠性(不被 hack)和 与最终目标的对齐(不产生误导)。
纯结果奖励的困境
最朴素的奖励设计是纯结果奖励:任务完成得 1.0,失败得 0.0。但在复杂的 Agent 场景中,这种设计面临严重问题:
- 信号极其稀疏:模型在早期几乎没有成功的轨迹,导致 GRPO 的组内对比全是"0 vs 0",梯度退化为零
- 信用分配困难:一个 50 步的轨迹最终失败了,模型无法知道是第 3 步的命令选错了,还是第 47 步的参数写错了
- 伪阳性风险:模型可能找到绕过测试的捷径(如直接修改测试脚本),获得高奖励但学到错误行为
分层奖励设计实践
在 Wordle 示例中,我们已经看到了多维奖励的雏形。将这一思路推广到通用 Agent 场景,可以构建以下层级的奖励体系:
| 奖励层级 | 信号来源 | 示例 | 密度 |
|---|---|---|---|
| 结果奖励 | 最终测试/验证 | 任务是否完成 | 极稀疏 |
| 过程奖励 | 环境中间反馈 | 子步骤执行成功率 | 中等 |
| 行为奖励 | 动作模式分析 | 重复动作惩罚、并行工具调用奖励 | 密集 |
| 效率奖励 | 资源消耗度量 | token 消耗、执行时间、工具调用次数 | 密集 |
需要特别警惕的是,复杂的奖励规则设计不是可持续方案。手动给工具失败施加固定的
21.5.8 本节小结
本节搭建了从 GRPO 算法到 Agent 训练的桥梁——环境接口层。核心要点回顾:
范式跃迁:Agent 训练将 RLVR 的"单步 bandit"升级为"多步 MDP"。奖励不再来自静态验证函数,而是来自模型与环境的动态交互。GRPO 的数学核心(§16.3)不变,改变的是奖励的产生方式。
标准化接口:OpenEnv 提供 Gymnasium 风格的
reset()/step()API,使任何环境都能以统一方式被接入。TRL 的rollout_func机制通过 kwargs 透传,将环境奖励无缝接入 GRPO 训练循环。环境设计:状态表示采用结构化自然语言;动作空间通过工具定义进行约束;环境增强(扰动初始状态)是防止过拟合的重要手段。
工程挑战:长尾延迟需要异步调度;环境故障需要 Mask & Filter;奖励稀疏需要多维复合信号。这些工程问题的解决质量,往往比算法选择更直接地决定训练成败。
与后续章节的衔接:本节聚焦环境 API 形态与奖励回传接口,不涉及完整的 Agentic RL 训练系统设计。关于多步信用分配、Chunked MDP、异步训练管线的完整设计、以及训练稳定性的系统性解决方案,将在 §21.9(Agentic RL)中深入展开。