23.2 VLM 工程实现:以 MiniMind-V 为例
上一节从理论和架构层面介绍了 CLIP、BLIP、Janus 等代表性 VLM。然而,当我们真正要动手实现一个视觉-语言模型时,许多看似简单的概念——"图像 patch 作为 token 插入序列"、"投影层对齐维度"、"两阶段训练"——都会变成一系列具体的工程问题:占位符 token 应该放在序列的什么位置?投影层的输入输出维度如何确定?训练时哪些参数应该冻结、哪些应该更新?
本节以 MiniMind-V 这一极简 VLM 实现为蓝本,用完整的代码和维度追踪,逐步拆解一个 VLM 从图像编码到损失计算的全流程。MiniMind-V 的设计思路直接继承了 LLaVA(Liu et al., 2023)的范式:冻结预训练视觉编码器(CLIP ViT),通过一个轻量投影层将图像特征映射到 LLM 的嵌入空间,然后用占位符机制将图像 token 无缝插入文本序列。这也是当前大多数开源 VLM 的通用架构模板。
23.2.1 整体架构:从 LLM 到 VLM 只差一个投影层
MiniMind-V 的核心思想可以用一句话概括:将图像特征伪装成"特殊的词向量",插入文本序列中,让原本只能处理文本的 LLM "看懂"图片。
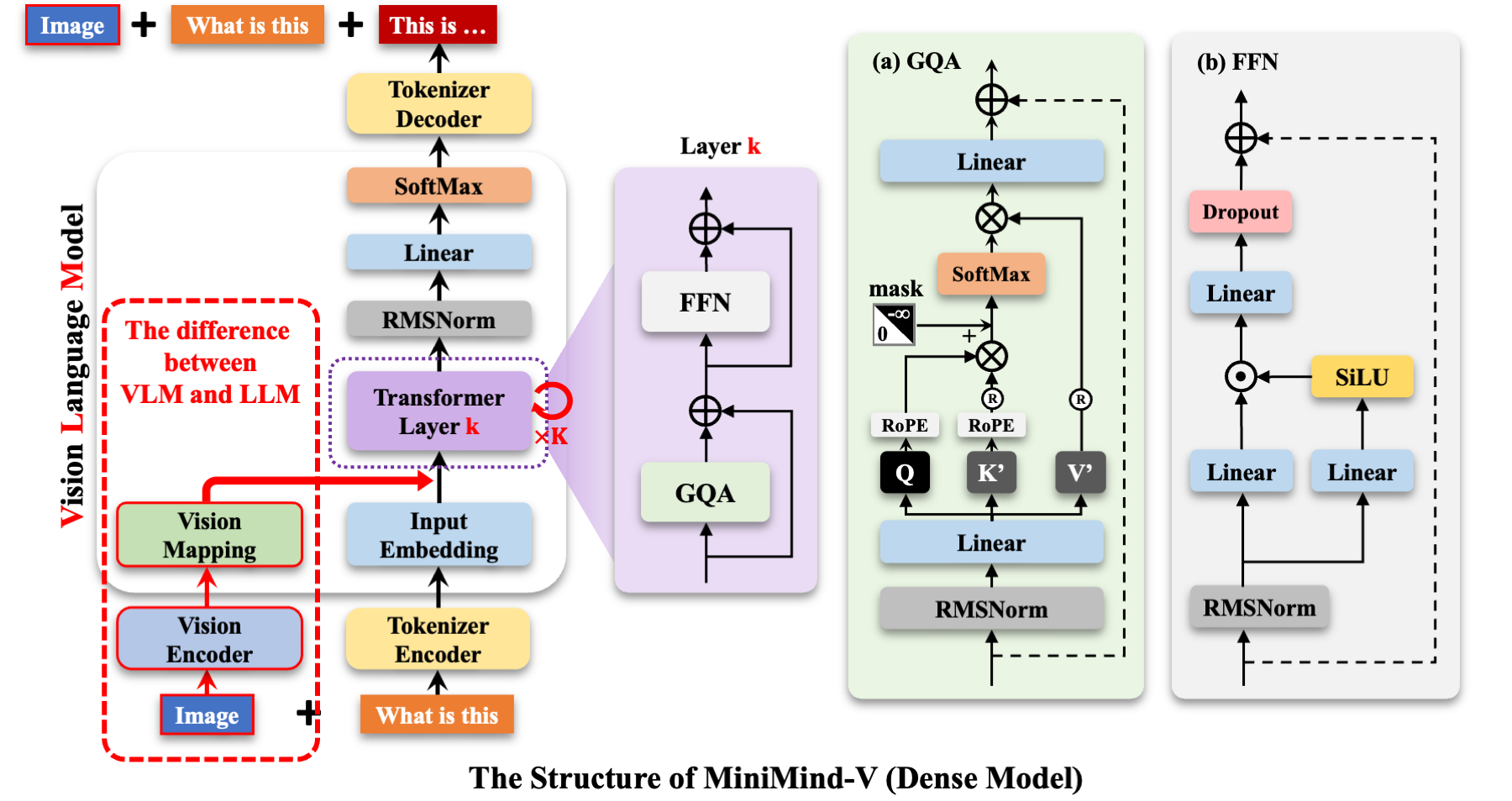
图 23-8:MiniMind-V(Dense 版本)的整体架构。左侧红色虚线框标出了 VLM 相比纯文本 LLM 的增量部分:底部增加了 Vision Encoder(CLIP ViT)和 Vision Mapping(投影层)。图像经编码和投影后,以 token 的形式插入输入序列,与文本 token 一起送入标准的 Transformer 层进行处理。右侧展示了每个 Transformer 层的内部结构:GQA(Grouped Query Attention)注意力机制和 FFN 前馈网络。
这个架构由三个核心模块组成:
- 视觉编码器(Vision Encoder):使用预训练的 CLIP ViT-Base,将输入图像编码为一组 patch 特征向量。整个训练过程中该模块完全冻结,不参与梯度更新
- 投影层(Vision Projection):一个简单的线性层
Linear(768, 512),将 CLIP 输出的 768 维特征投影到 LLM 的 512 维嵌入空间。这是 VLM 相比纯文本 LLM 唯一新增的可学习模块 - 语言模型(LLM):标准的 Transformer 解码器(与 MiniMind 的纯文本版本完全相同),接收混合了图像和文本的 token 序列,执行自回归生成
MiniMind-V 同样支持 MoE(Mixture of Experts)变体——此时 Transformer 层内部的 FFN 被替换为 MoE 路由结构,但 VLM 的图像处理流程完全不变。
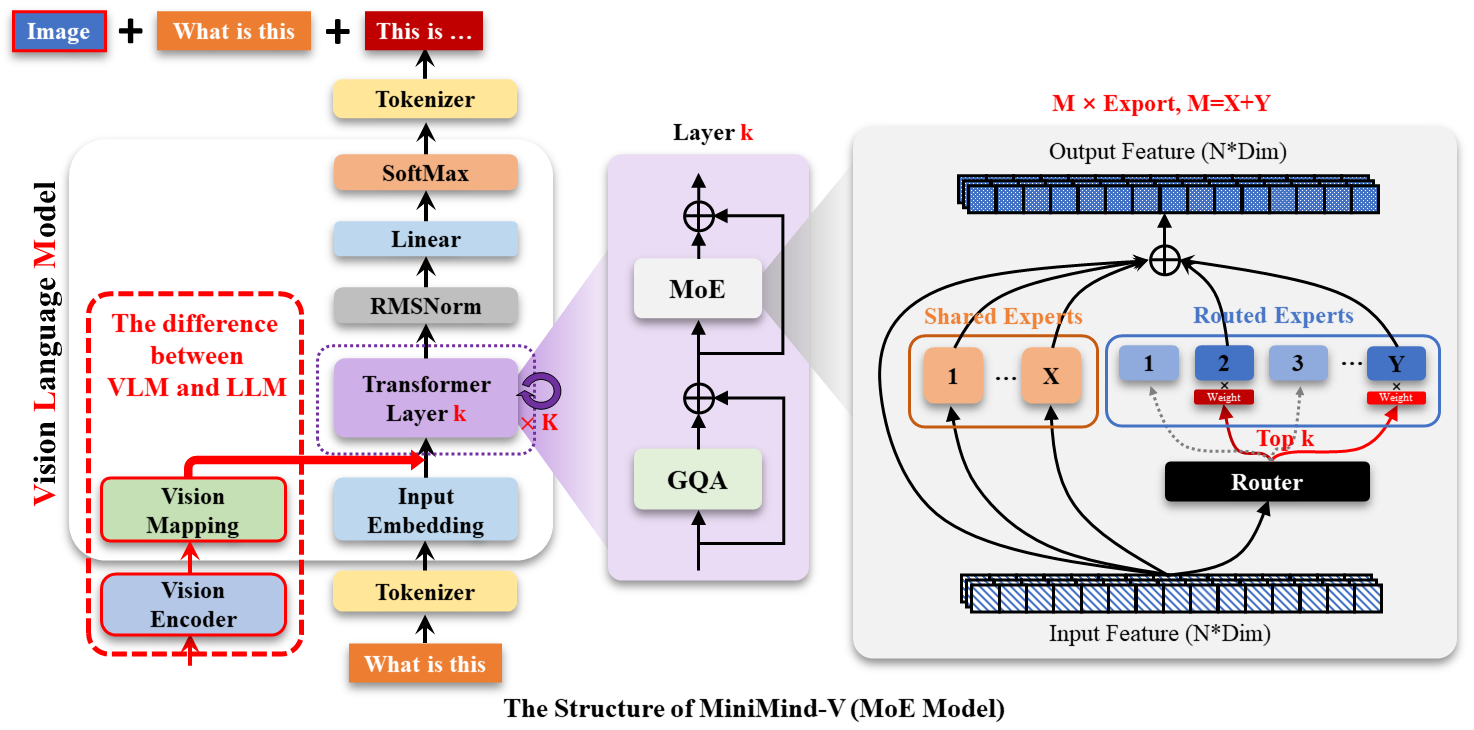
图 23-9:MiniMind-V(MoE 版本)的整体架构。与图 23-8 的唯一区别是 FFN 模块被替换为 MoE 路由结构(右侧):输入特征经 Router 分配到不同 Expert,各 Expert 独立处理后加权合并。VLM 的视觉编码和投影流程与 Dense 版本完全一致。
为什么用简单的线性投影而非复杂的 Q-Former? LLaVA 的实验表明,在有充足的对齐数据时,一个简单的线性投影层(甚至两层 MLP)就足以实现良好的跨模态对齐。Q-Former 的优势主要体现在训练数据受限或需要极端压缩视觉 token 数量的场景。对于学习和原型开发而言,线性投影是最直观且最容易调试的方案。
23.2.2 图像编码与特征投影:把图片变成"词向量"
让我们用一个具体的例子,逐步追踪图像从像素到 token 的完整变换过程。
场景设定:假设输入一张 224×224 的 RGB 图像,CLIP ViT-Base 的 patch size 为 16,LLM 的隐藏维度为 512。
第一步:CLIP 编码
CLIP ViT 将图像切分为 [CLS] token,编码器输出 197 个 768 维向量:
import torch
from transformers import CLIPVisionModel, CLIPImageProcessor
class VisionEncoder:
"""视觉编码器:封装 CLIP ViT 的图像编码流程。"""
def __init__(self, model_name="openai/clip-vit-base-patch16"):
self.processor = CLIPImageProcessor.from_pretrained(model_name)
self.model = CLIPVisionModel.from_pretrained(model_name)
# 冻结所有参数——视觉编码器在 VLM 训练中不更新
for param in self.model.parameters():
param.requires_grad = False
def encode(self, images):
"""
将图像编码为 patch 特征序列。
Args:
images: PIL Image 或 Tensor, 经 processor 预处理后
shape: (batch, channels=3, height=224, width=224)
Returns:
patch_features: (batch, 196, 768)
"""
with torch.no_grad():
outputs = self.model(pixel_values=images)
# outputs.last_hidden_state: (batch, 197, 768)
# 去掉 [CLS] token,只保留 196 个 patch 特征
patch_features = outputs.last_hidden_state[:, 1:, :]
return patch_features # (batch, 196, 768)维度变化:(1, 3, 224, 224) → CLIP ViT → (1, 197, 768) → 去掉 [CLS] → (1, 196, 768)
第二步:线性投影
196 个 768 维的 CLIP 特征需要映射到 LLM 的 512 维空间。投影层就是一个简单的线性变换:
import torch.nn as nn
class VisionProjection(nn.Module):
"""投影层:将视觉编码器的输出维度对齐到 LLM 的嵌入维度。"""
def __init__(self, vision_dim=768, llm_dim=512):
super().__init__()
self.proj = nn.Linear(vision_dim, llm_dim)
def forward(self, vision_features):
"""
Args:
vision_features: (batch, num_patches=196, vision_dim=768)
Returns:
projected: (batch, num_patches=196, llm_dim=512)
"""
return self.proj(vision_features)维度变化:(1, 196, 768) → Linear(768, 512) → (1, 196, 512)
经过这一步,每个图像 patch 都变成了一个 512 维的向量——与 LLM 的文本词向量维度完全一致。从 LLM 的视角来看,这 196 个向量和普通的文本 token 嵌入没有任何区别。
维度对齐的硬性约束:CLIP 输出的 patch 数量(196)必须与后续占位符 token 的数量严格匹配。如果使用不同分辨率的图像或不同 patch size 的 ViT,这个数字会改变(例如 384×384 图像 + patch16 →
个 patch),占位符序列长度也必须相应调整。
23.2.3 占位符机制:在文本中为图片"预留座位"
现在我们有了 196 个图像 token 向量,但 LLM 的输入是一个 token ID 序列——如何将这些连续向量"插入"离散的文本序列中?MiniMind-V 采用了一种简洁的占位符替换(Placeholder Substitution)策略。
核心思路:在文本分词阶段,用 196 个特殊的占位符 token(例如 ID 为 34 的 @ 符号)在序列中标记图片的位置。模型的 forward 方法在获取文本 embedding 之后、送入 Transformer 层之前,将占位符位置的 embedding 替换为真正的图像特征向量。
完整的数据流可以分为三步:
Step 1:构造包含占位符的输入序列
# 假设文本为 "看这张图 [IMAGE] 是一只猫"
# 分词后:[...文本ID..., 34, 34, ...(共196个), ...文本ID...]
# 其中 34 是占位符 token 的 ID
# 示例序列:
# 前缀文本 "看这张图" → 20 个 token
# 图片占位符 @@...@@ → 196 个 token (全部为 ID=34)
# 后缀文本 "是一只猫" → 10 个 token
# 总长 seq_len = 226
input_ids = torch.tensor([[
*text_prefix_ids, # 20 个文本 token
*([34] * 196), # 196 个占位符
*text_suffix_ids # 10 个文本 token
]]) # shape: (1, 226)Step 2:获取文本 embedding 并替换占位符
def fuse_vision_into_text(input_ids, text_embeddings, vision_proj,
placeholder_id=34, num_patches=196):
"""
在文本 embedding 序列中找到占位符位置,替换为图像特征。
Args:
input_ids: (batch, seq_len) — 包含占位符的 token ID 序列
text_embeddings: (batch, seq_len, hidden_dim) — 文本 embedding
vision_proj: (batch, num_patches, hidden_dim) — 投影后的图像特征
placeholder_id: 占位符 token 的 ID
num_patches: 每张图对应的 patch 数量
Returns:
fused_embeddings: (batch, seq_len, hidden_dim) — 融合后的 embedding
"""
batch_size = input_ids.size(0)
fused = text_embeddings.clone()
for i in range(batch_size):
# 在 input_ids 中滑动窗口,找到连续 num_patches 个占位符的起始位置
ids = input_ids[i].tolist()
start = find_placeholder_start(ids, placeholder_id, num_patches)
if start is not None:
# 核心操作:"狸猫换太子"
# 将占位符位置的 embedding 替换为真正的图像特征
fused[i, start:start + num_patches, :] = vision_proj[i]
return fused
def find_placeholder_start(ids, placeholder_id, length):
"""滑动窗口查找连续占位符的起始索引。"""
for j in range(len(ids) - length + 1):
if all(ids[j + k] == placeholder_id for k in range(length)):
return j
return NoneStep 3:送入 Transformer 处理
替换完成后,fused_embeddings 的形状仍然是 (1, 226, 512)——维度没有变化,但中间 196 个位置的数据已经从"无意义的占位符向量"变成了"富含视觉语义的图像特征"。随后,这个混合序列直接送入标准 Transformer 层,Self-Attention 机制会让文本 token(如"是一只猫")自然地关注到前面的图像 token,从而实现图文理解。
以下是完整的 VLM 前向传播流程:
class MiniMindVLM(nn.Module):
"""极简视觉-语言模型的前向传播逻辑(简化示意)。"""
def __init__(self, llm, vision_encoder, vision_proj,
placeholder_id=34, num_patches=196):
super().__init__()
self.llm = llm
self.vision_encoder = vision_encoder
self.vision_proj = vision_proj
self.placeholder_id = placeholder_id
self.num_patches = num_patches
def forward(self, input_ids, pixel_values=None):
"""
Args:
input_ids: (batch, seq_len) — 包含占位符的 token 序列
pixel_values: (batch, 1, 3, 224, 224) — 预处理后的图像
Returns:
logits: (batch, seq_len, vocab_size)
"""
# Step 1: 文本 embedding
hidden_states = self.llm.embed_tokens(input_ids)
# shape: (batch, seq_len, 512)
# Step 2: 图像编码 + 投影 + 融合
if pixel_values is not None:
# CLIP 编码:(batch, 1, 3, 224, 224) → (batch, 196, 768)
img_features = self.vision_encoder.encode(
pixel_values.squeeze(1)
)
# 投影:(batch, 196, 768) → (batch, 196, 512)
img_embeds = self.vision_proj(img_features)
# 替换占位符
hidden_states = fuse_vision_into_text(
input_ids, hidden_states, img_embeds,
self.placeholder_id, self.num_patches
)
# Step 3: Transformer 前向传播
for layer in self.llm.layers:
hidden_states = layer(hidden_states)
# Step 4: LM Head 输出
logits = self.llm.lm_head(hidden_states)
return logits # (batch, seq_len, vocab_size)整个流程的维度变化总结如下:
| 阶段 | 数据 | 维度 |
|---|---|---|
| 输入图像 | pixel_values | (1, 1, 3, 224, 224) |
| CLIP 编码 | last_hidden_state[:, 1:, :] | (1, 196, 768) |
| 线性投影 | vision_proj(·) | (1, 196, 512) |
| 文本 embedding | embed_tokens(input_ids) | (1, 226, 512) |
| 占位符替换 | fused_embeddings | (1, 226, 512) — 中间 196 个被替换 |
| Transformer 输出 | hidden_states | (1, 226, 512) |
| LM Head | logits | (1, 226, vocab_size) |
23.2.4 两阶段训练:先配眼镜,再训大脑
VLM 的训练通常分为两个阶段,每个阶段有不同的参数冻结策略和训练目标。这一范式最早由 LLaVA 提出,MiniMind-V 忠实地复现了这一设计。
阶段一:Alignment Pretrain(特征对齐预训练)
目标是训练投影层,让它学会将 CLIP 的视觉特征"翻译"成 LLM 能理解的嵌入表示。此阶段的类比是"配眼镜"——LLM 的"大脑"已经具备语言理解能力(来自预训练),我们只需要给它配一副合适的"眼镜"(投影层),让它看清图像特征。
参数冻结策略:
| 模块 | 状态 | 原因 |
|---|---|---|
| Vision Encoder (CLIP) | 冻结 | 已有优秀的视觉表示能力,无需调整 |
| Vision Projection | 可训练 | 唯一需要学习的模块 |
| LLM | 冻结 | 保护已有的语言能力不被破坏 |
def init_vlm_for_pretrain(model):
"""阶段一初始化:只训练投影层。"""
# 冻结所有参数
for param in model.parameters():
param.requires_grad = False
# 解冻投影层
for param in model.vision_proj.parameters():
param.requires_grad = True
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
total = sum(p.numel() for p in model.parameters())
print(f"可训练参数:{trainable:,} / 总参数:{total:,} "
f"({100 * trainable / total:.2f}%)")训练数据通常是大规模的图像-描述对(Image-Caption pairs)。训练目标是标准的 next-token prediction:给定图像和部分文本,预测下一个文本 token。
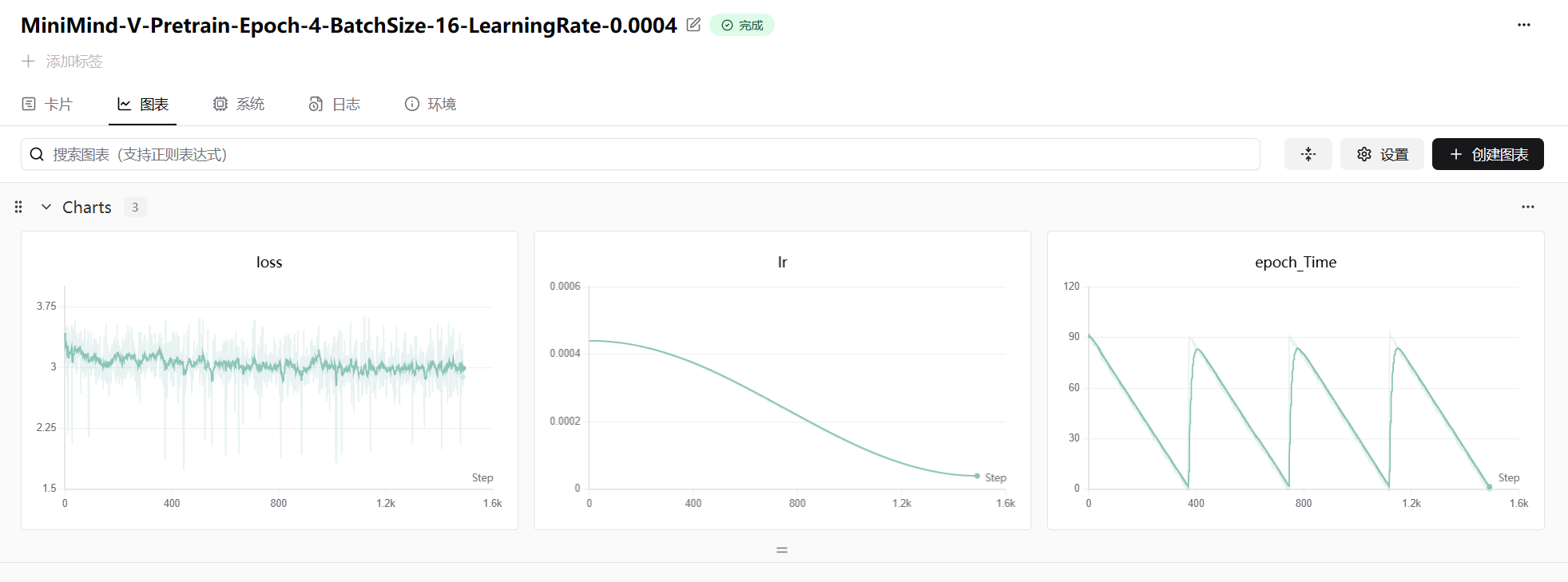
图 23-10:MiniMind-V 阶段一(Alignment Pretrain)的训练曲线。左图:训练 loss 从约 3.75 逐步收敛至 2.5 附近。中图:学习率 0.0004 采用余弦衰减策略。右图:每个 epoch 的训练时间。此阶段 BatchSize=16,训练 4 个 Epoch。
阶段二:SFT(指令微调)
阶段一完成后,投影层已经建立了跨模态的特征映射。阶段二的目标是解冻 LLM,让整个模型端到端地学习视觉对话能力——不仅要看清图片,还要能根据图片内容回答复杂问题。
参数冻结策略:
| 模块 | 状态 | 原因 |
|---|---|---|
| Vision Encoder (CLIP) | 冻结 | 始终不动 |
| Vision Projection | 可训练 | 继续微调对齐 |
| LLM | 可训练 | 学习根据视觉信息生成回答 |
def init_vlm_for_sft(model, pretrain_vlm_path):
"""阶段二初始化:加载阶段一权重,解冻 LLM。"""
# 加载阶段一训练好的权重(不包含 vision_encoder)
weights = torch.load(pretrain_vlm_path, map_location="cpu")
model.load_state_dict(weights, strict=False) # strict=False:跳过缺失的 CLIP 参数
# 冻结视觉编码器
for param in model.vision_encoder.parameters():
param.requires_grad = False
# LLM 和投影层均可训练(默认 requires_grad=True)
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"可训练参数:{trainable:,}")注意 strict=False 的使用:阶段一保存权重时,通常会剔除冻结的 CLIP 参数以节省存储空间(CLIP ViT-Base 约 350MB)。加载时,strict=False 允许 PyTorch 跳过权重字典中缺失的 CLIP 参数,只加载 LLM 和投影层的权重。CLIP 模块则从原始预训练权重重新初始化。
def save_vlm_checkpoint(model, path):
"""保存 VLM 权重时剔除冻结的视觉编码器,节省存储空间。"""
state_dict = model.state_dict()
# 过滤掉 vision_encoder 的参数
clean_state_dict = {
key: value for key, value in state_dict.items()
if not key.startswith("vision_encoder.")
}
torch.save(clean_state_dict, path)
print(f"已保存(不含 Vision Encoder):{path}")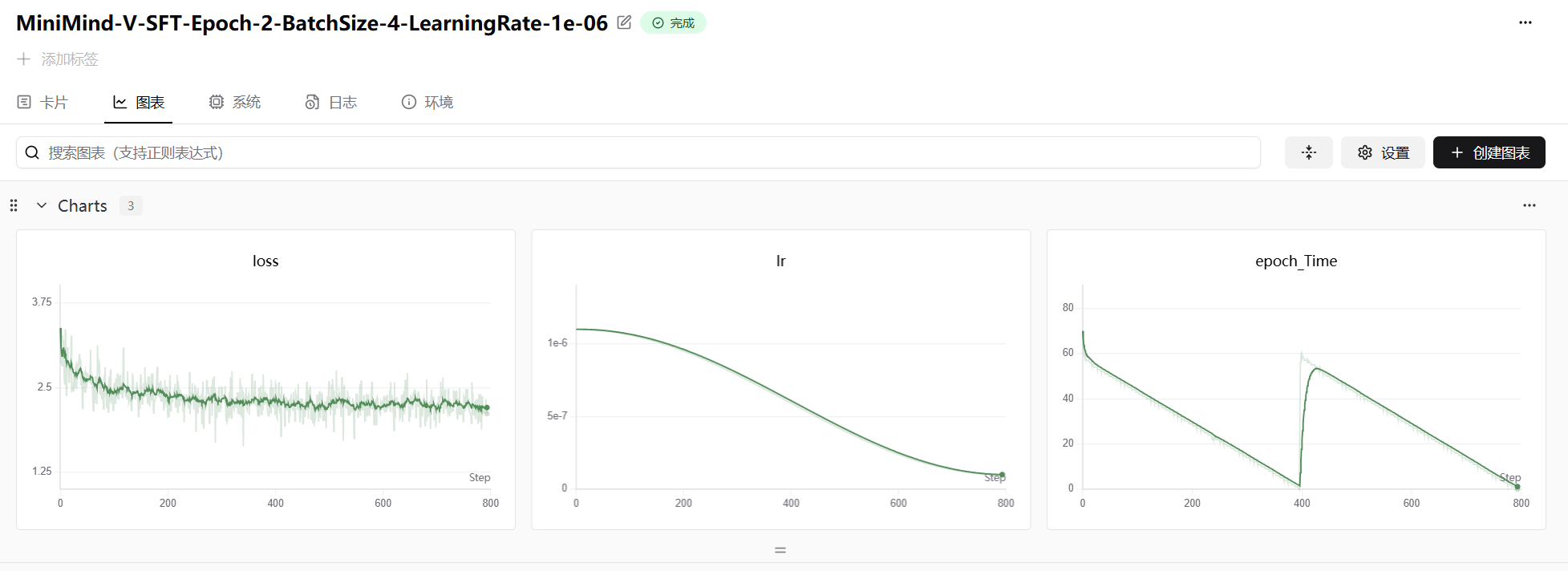
图 23-11:MiniMind-V 阶段二(SFT)的训练曲线。左图:训练 loss 从约 3.5 收敛至 2.0 附近,下降幅度比阶段一更大。中图:学习率仅为 1e-6(远低于阶段一的 4e-4),因为此时 LLM 已解冻,需要极小的学习率避免灾难性遗忘。右图:每个 epoch 的训练时间。此阶段 BatchSize=4,训练 2 个 Epoch。
阶段二的学习率(1e-6)比阶段一(4e-4)低了近 400 倍,这是一个值得关注的工程细节。原因在于:阶段二解冻了 LLM 的全部参数,如果学习率过大,模型会迅速"遗忘"预训练阶段学到的语言能力(即灾难性遗忘,Catastrophic Forgetting)。极低的学习率确保 LLM 在保持语言能力的前提下,缓慢地适应视觉输入。
23.2.5 训练循环:损失计算与工程细节
VLM 的训练循环与标准 LLM 基本一致——使用自回归交叉熵损失和混合精度训练。但有几个 VLM 特有的工程细节值得注意。
损失计算与 Loss Mask
训练数据中的每条样本包含三个部分:提问(Prompt)、图像占位符、回答(Response)。损失只计算在回答部分的 token 上——提问和图像占位符不参与损失计算。这通过一个 loss_mask 向量实现:
def compute_vlm_loss(logits, targets, loss_mask):
"""
VLM 训练损失计算:仅对回答部分计算交叉熵。
Args:
logits: (batch, seq_len, vocab_size) — 模型输出
targets: (batch, seq_len) — 目标 token ID
loss_mask: (batch, seq_len) — 1 表示需要计算 loss,0 表示忽略
Returns:
loss: 标量
"""
loss_fn = torch.nn.CrossEntropyLoss(reduction="none")
# 展平计算
# (batch * seq_len, vocab_size) vs (batch * seq_len,)
token_losses = loss_fn(
logits.view(-1, logits.size(-1)),
targets.view(-1)
).view(targets.size()) # 恢复为 (batch, seq_len)
# 应用 mask:只保留回答部分的 loss
masked_loss = (token_losses * loss_mask).sum() / loss_mask.sum()
return masked_loss完整训练循环
def train_epoch(model, loader, optimizer, scaler, device,
accumulation_steps=1):
"""MiniMind-V 的单 epoch 训练循环。"""
model.train()
for step, (input_ids, targets, loss_mask, pixel_values) in enumerate(loader):
# 数据搬运到 GPU
input_ids = input_ids.to(device) # (B, L)
targets = targets.to(device) # (B, L)
loss_mask = loss_mask.to(device) # (B, L)
pixel_values = pixel_values.to(device) # (B, 1, 3, 224, 224)
# 前向传播(混合精度)
with torch.cuda.amp.autocast():
logits = model(input_ids, pixel_values=pixel_values)
loss = compute_vlm_loss(logits, targets, loss_mask)
loss = loss / accumulation_steps
# 反向传播
scaler.scale(loss).backward()
# 梯度累积 + 参数更新
if (step + 1) % accumulation_steps == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(
model.parameters(), max_norm=1.0
)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
# 显存清理(对小显存训练至关重要)
del input_ids, targets, loss_mask, pixel_values, logits, loss
torch.cuda.empty_cache()以下几个工程细节值得特别说明:
梯度裁剪
clip_grad_norm_(max_norm=1.0):Transformer 训练中的标准操作,防止某些 batch 产生的异常大梯度导致训练发散。对于 VLM 尤其重要,因为图像 token 和文本 token 的梯度量级可能差异较大混合精度训练
autocast+GradScaler:将前向传播中的大部分计算降低到 float16 精度,显著减少显存占用并加速训练。GradScaler负责在 float16 下防止梯度下溢(underflow)显式显存清理
del+empty_cache():在单卡 24GB 显存的场景下,每个 step 结束后手动释放大张量并清理 CUDA 缓存,可以有效避免显存碎片化导致的 OOM权重保存时剔除 CLIP:如前所述,保存 checkpoint 时过滤掉
vision_encoder前缀的参数,可以将权重文件体积减少约 350MB
23.2.6 从 MiniMind-V 到生产级 VLM:差距在哪里
MiniMind-V 提供了一个清晰完整的 VLM 实现框架,但与生产级 VLM(如 LLaVA-1.5、InternVL、Qwen-VL)相比,仍有几个维度的差距值得读者了解:
视觉编码器的选择。MiniMind-V 使用 CLIP ViT-Base(86M 参数,224×224 分辨率),而生产级 VLM 通常使用 SigLIP-SO400M 或 InternViT-6B 等更大的编码器,支持 384×384 甚至动态分辨率输入。更高的分辨率意味着更多的 patch token(例如 576 或 2880 个),对显存和计算的要求也相应增加。
投影层的复杂度。MiniMind-V 使用单个线性层,而 LLaVA-1.5 使用两层 MLP(带 GELU 激活),Qwen-VL 使用单层交叉注意力(类似简化的 Q-Former),InternVL 使用像素洗牌(Pixel Shuffle)降采样 + MLP。更复杂的投影层能更好地捕捉图像特征的局部结构。
多图和动态分辨率。MiniMind-V 只支持单张固定分辨率图像,而现代 VLM 普遍支持多图输入(图文交错对话)和动态分辨率(将高分辨率图像切片为多个子图,分别编码后拼接)。这需要更复杂的占位符管理和位置编码策略。
训练数据规模。MiniMind-V 的对齐数据仅包含约 3.4 万条图文对,而 LLaVA 使用 55.8 万条 CC3M 过滤数据进行 alignment,SFT 阶段使用 66.5 万条多任务指令数据。数据规模的差异是性能差距的主要来源之一。
尽管存在这些差距,MiniMind-V 的价值在于它完整地呈现了 VLM 的核心设计模式。读者理解了占位符替换、投影层对齐、两阶段训练这三个关键机制后,阅读 LLaVA、Qwen-VL 等复杂实现时会发现它们本质上遵循着完全相同的范式——区别只在于各个模块的规模和精细度。
本节要点总结
- VLM 的核心工程思想是将图像特征"伪装"成文本词向量:通过视觉编码器提取 patch 特征,经投影层对齐维度后,替换文本序列中的占位符 token,让 LLM 像处理文本一样处理图像。
- 占位符替换机制分为三步:分词时在文本中插入固定数量的占位符 token → embedding 层获取初始向量 → 用真正的图像特征替换占位符位置的向量。占位符数量必须与 patch 数量严格一致。
- 两阶段训练是 VLM 的标准范式:阶段一冻结 LLM 只训练投影层(高学习率,学习跨模态对齐);阶段二解冻 LLM 进行端到端微调(极低学习率,防止灾难性遗忘)。两阶段的学习率相差约两个数量级。
- 工程实践要点包括:保存权重时剔除冻结的 CLIP 参数以节省存储;使用
strict=False加载不完整的权重字典;用 loss mask 区分提问和回答部分的损失计算;通过梯度裁剪、混合精度训练和显式显存清理应对资源受限场景。