24.5 世界模型与物理 AI
在前面几节中,我们看到大模型如何赋能自动驾驶、具身智能和数字人等物理世界应用。这些应用有一个共同的瓶颈:训练数据的获取极其昂贵且危险——自动驾驶需要数百万公里的路测数据,机器人需要在真实环境中反复试错。能否构建一个物理世界的"数字孪生",让 AI 在虚拟环境中安全地学习物理规律?这就是世界基础模型(World Foundation Model, WFM)试图回答的核心问题。
2025 年 1 月,NVIDIA 在 CES 大会上正式发布了 Cosmos 平台——一个面向物理 AI 开发者的世界基础模型开发平台。黄仁勋将其定位为未来"三台计算机"架构中的关键一环:DGX 用于训练 AI,AGX 用于部署 AI,而 Omniverse + Cosmos 则用于模拟物理世界。本节将以 Cosmos 为核心案例,系统讲解世界模型的定义、技术架构与应用前景。
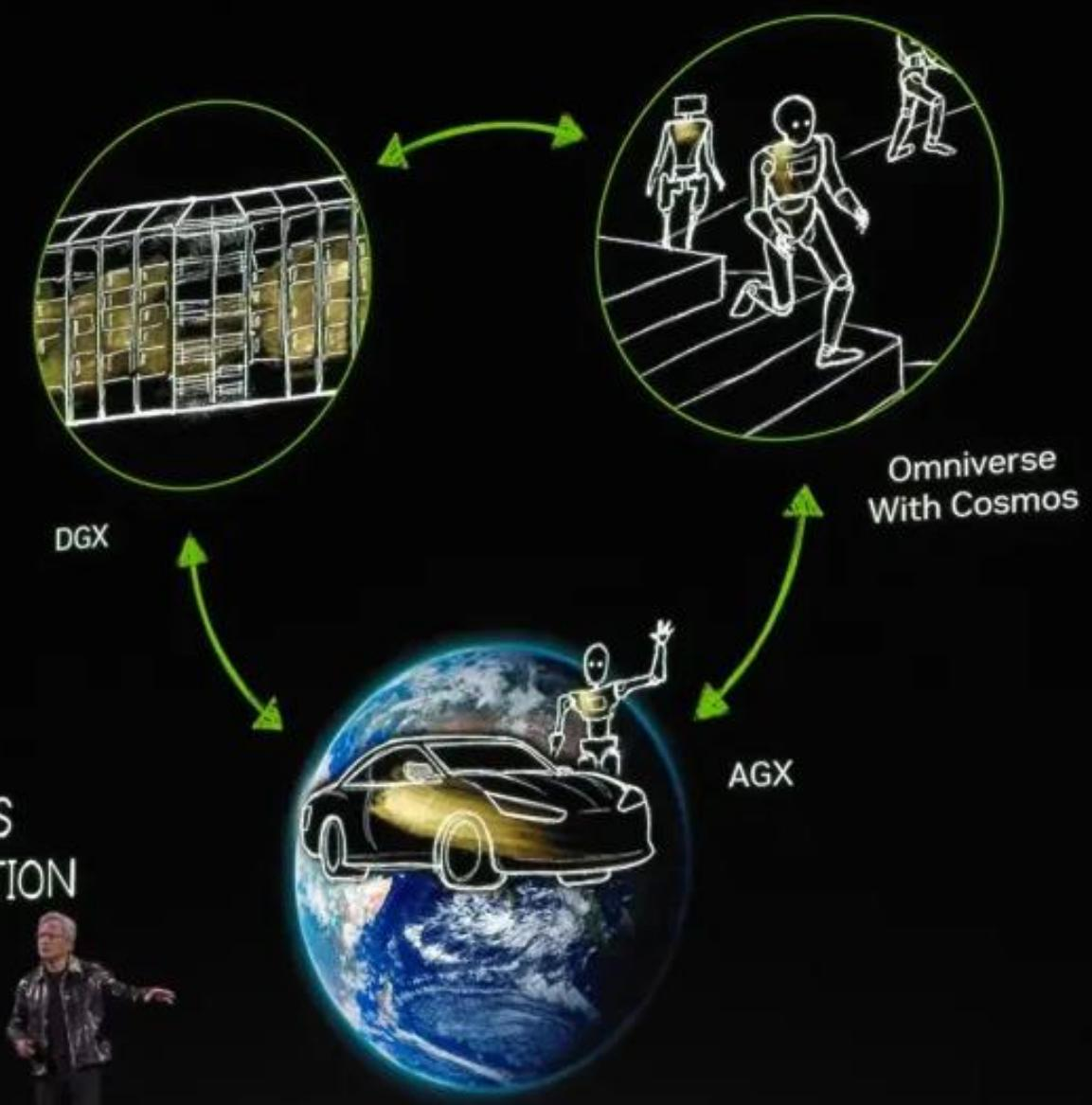
图 24-17:NVIDIA 的"三台计算机"愿景。DGX 集群用于 AI 模型训练,Omniverse 与 Cosmos 结合构建物理世界的数字孪生,AGX 芯片将训练好的 AI 部署到自动驾驶汽车和机器人等物理实体上。三者形成闭环,驱动物理 AI 的持续进化。
24.5.1 什么是世界模型
从强化学习到基础模型
"世界模型"(World Model)并非新概念。其起源可追溯至 20 世纪 90 年代 Juergen Schmidhuber 实验室的强化学习研究:智能体(Agent)在与环境交互时,会构建一个内部表示来模拟环境的动态规律——给定当前状态和执行的动作,预测环境的下一个状态。2018 年 Ha 和 Schmidhuber 发表了使用 RNN 建模世界模型的经典论文,正式奠定了这一研究方向的范式。
进入 2024 年,世界模型的概念因三大里程碑事件重新引爆:
| 时间 | 事件 | 核心思路 |
|---|---|---|
| 2024.02 | OpenAI 发布 Sora | 自回归生成式:通过 Diffusion Transformer 从文本生成长视频 |
| 2024.02 | Google 发布 Genie | 交互式环境生成:从视频中学习潜在动作,创建可交互虚拟世界 |
| 2024.02-03 | Meta 发布 V-JEPA | 联合嵌入预测:在隐空间学习视频表征,不直接生成像素 |
三者分别代表了通往世界模型的三条技术路线:生成式(像 Sora 一样直接产出视频帧)、交互式(像 Genie 一样支持动作控制)、和表征式(像 JEPA 一样学习抽象的隐空间预测)。但 Sora 在发布时自称"世界模拟器"(World Simulator),但 Yann LeCun 对此提出了尖锐批评——他认为仅仅生成视觉上逼真的视频并不意味着模型理解了物理世界,因为生成的视频中经常出现违反基本物理常识的错误(如蚂蚁被渲染成有 8 条腿)。这场论争凸显了一个根本问题:视频生成能力
世界模型的形式化定义
NVIDIA Cosmos 论文给出了一个简洁而通用的形式化定义。设
即根据历史观测和当前扰动,预测下一时刻的世界状态。

图 24-18:世界基础模型的形式化定义。模型
这一定义的精妙之处在于将"扰动"抽象化:在自动驾驶场景中,
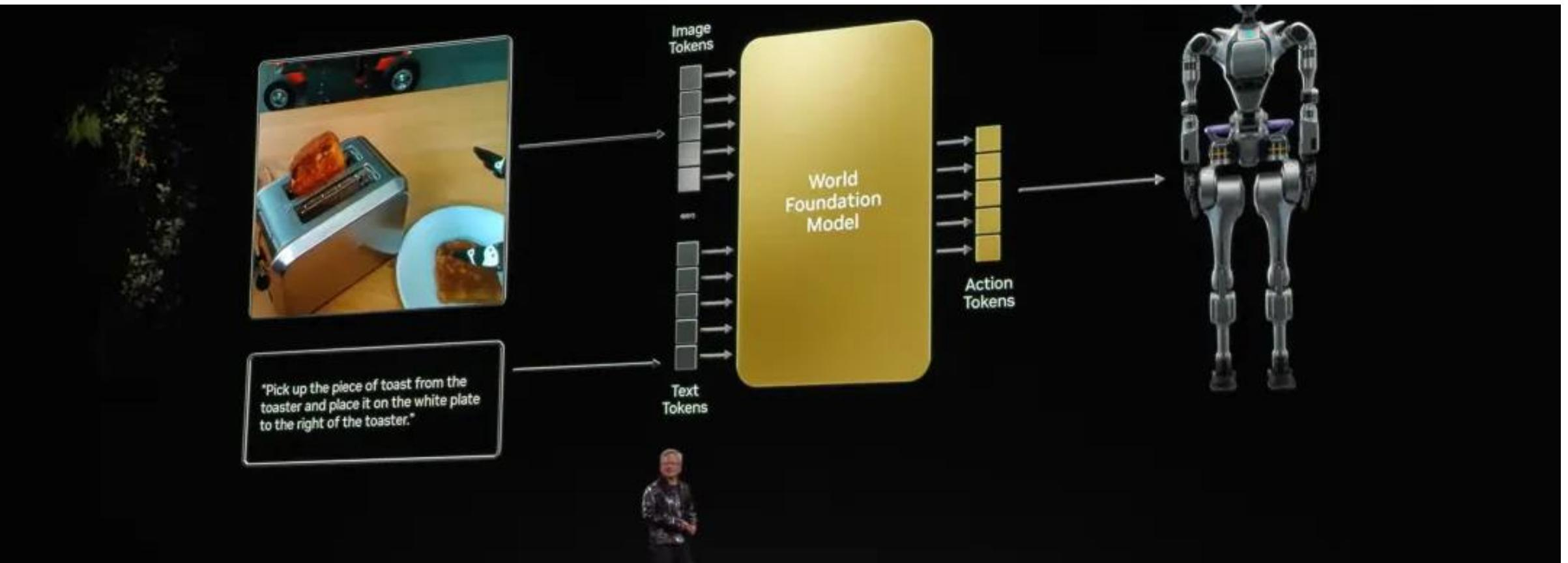
图 24-19:世界基础模型的概念流程。视觉观测被编码为图像 token,任务指令被编码为文本 token,共同输入 WFM 后,模型输出动作 token 来驱动物理实体执行操作。
世界模型对物理 AI 的五大价值
为什么物理 AI 如此需要世界模型?Cosmos 论文总结了五个关键用途:
- 策略评估(Policy Evaluation):不必将机器人部署到真实世界,而是让策略模型在 WFM 构建的虚拟世界中运行,快速筛除不合格的策略;
- 策略初始化(Policy Initialization):WFM 学到了世界的动态模式,可以作为策略模型的良好初始化,缓解物理 AI 的数据稀缺问题;
- 策略训练(Policy Training):WFM 配合奖励模型,可以在强化学习框架中充当物理世界的代理环境,让智能体在虚拟世界中安全试错;
- 规划与模型预测控制(Planning / MPC):WFM 模拟不同动作序列带来的未来状态,结合代价函数选出最优动作序列;
- 合成数据生成(Synthetic Data Generation):WFM 可以大规模生成训练数据,尤其适用于从仿真到真实(Sim2Real)的迁移场景。
24.5.2 Cosmos 平台架构
NVIDIA Cosmos 并非单一模型,而是一个完整的平台(Platform),包含从数据到模型到安全的全栈组件。
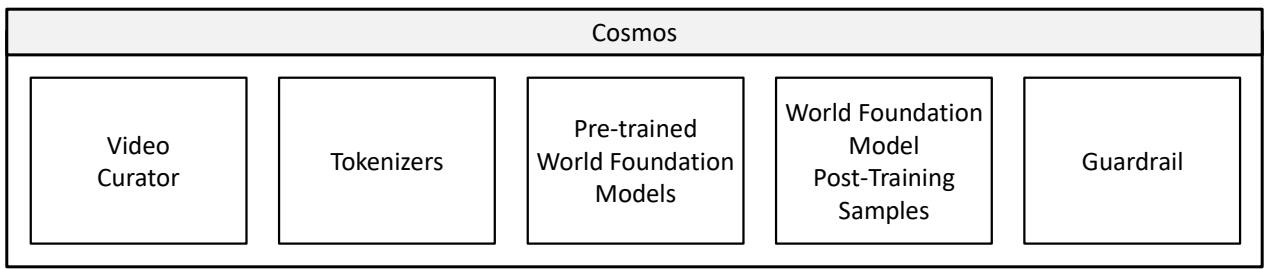
图 24-20:Cosmos 世界基础模型平台的组成。从左到右依次为:视频数据管理器(Video Curator)、视频分词器(Tokenizers)、预训练世界基础模型(Pre-trained WFMs)、后训练样例(Post-Training Samples)、安全护栏(Guardrail)。
平台采用预训练-后训练(Pre-training-and-Post-training)的范式,与大语言模型的训练策略异曲同工:先用大规模多样化视频数据训练通用的世界基础模型(通才),再用目标物理 AI 场景的专有数据进行微调,得到面向特定任务的专用模型(专才)。
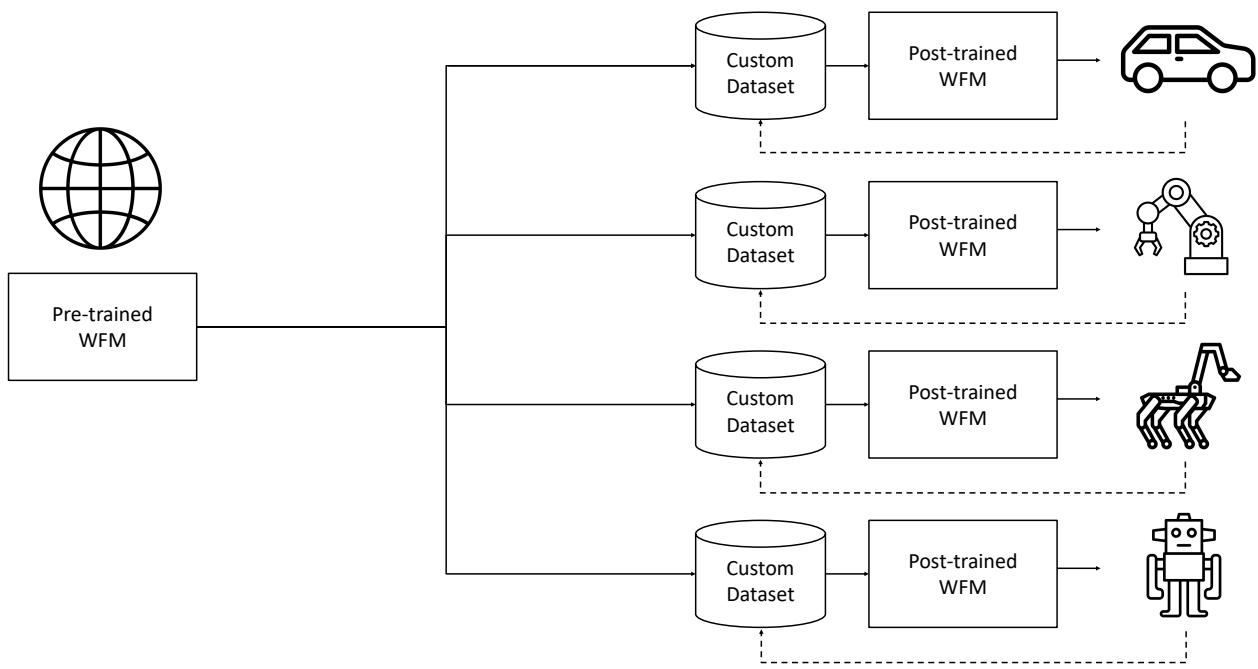
图 24-21:Cosmos 的预训练-后训练范式。左侧的预训练 WFM 是在大规模多样化视频上训练的通才模型;右侧通过各领域的定制数据集微调,分别得到面向自动驾驶、机械臂、四足机器人、人形机器人等不同物理 AI 场景的专用 WFM。虚线表示数据闭环。
视频数据管理:从 2000 万小时到 1 亿条精选片段
高质量的训练数据决定了模型的上限。Cosmos 设计了一套五阶段视频数据管理流水线,从约 2000 万小时、720p~4K 的原始视频中提取出约

图 24-22:Cosmos 视频数据管理流水线。原始视频先通过镜头检测分割为无场景切换的片段(Split),再经过运动过滤、画质过滤、文字叠加过滤和视频类型过滤(Filtering),然后使用 VLM 生成文字标注(Annotation),接着进行语义去重(Dedup),最后按分辨率和宽高比分片(Sharding)供训练使用。
流水线的设计有几个值得关注的工程细节:
- 镜头检测:采用 TransNetV2 端到端神经网络而非基于颜色直方图的传统方法(如 PySceneDetect),在复杂剪辑过渡场景下 F1 分数提升约 10 个百分点;
- GPU 加速转码:利用 NVIDIA L40S 的硬件编解码加速器(NVDEC/NVENC),用 PyNvideoCodec 替代 ffmpeg,转码吞吐量提升约 6.5 倍;
- 视频标注:使用 130 亿参数的 VILA 模型为每个片段生成描述,配合 FP8 量化的 TensorRT-LLM 推理引擎,吞吐量达到基线 PyTorch 的约 10 倍;
- 语义去重:基于 InternVideo2 特征的 SemDeDup 方法,移除约 30% 的冗余数据。
训练数据覆盖九大类目,刻意偏向与物理 AI 相关的内容:
| 类目 | 占比 | 说明 |
|---|---|---|
| 自然动态 | 20% | 流水、风吹草动、火焰等自然物理现象 |
| 手部运动与物体操作 | 16% | 抓取、放置、组装等精细操作 |
| 空间感知与导航 | 16% | 室内外导航、空间理解 |
| 驾驶场景 | 11% | 各种交通环境下的驾驶视频 |
| 人体运动与活动 | 10% | 行走、跑步、体育运动等 |
| 第一人称视角 | 8% | 头戴式摄像头拍摄的主观视角 |
| 动态相机运动 | 8% | 平移、缩放、旋转等摄影技法 |
| 合成渲染 | 4% | 游戏引擎/仿真器渲染的场景 |
| 其他 | 7% | — |
24.5.3 视频分词器
大语言模型需要文本分词器(Tokenizer)将自然语言转换为 token 序列,世界基础模型同样需要视频分词器将高维视频数据压缩为紧凑的 token 表示。视频分词器是连接原始像素世界与模型潜在空间的桥梁。
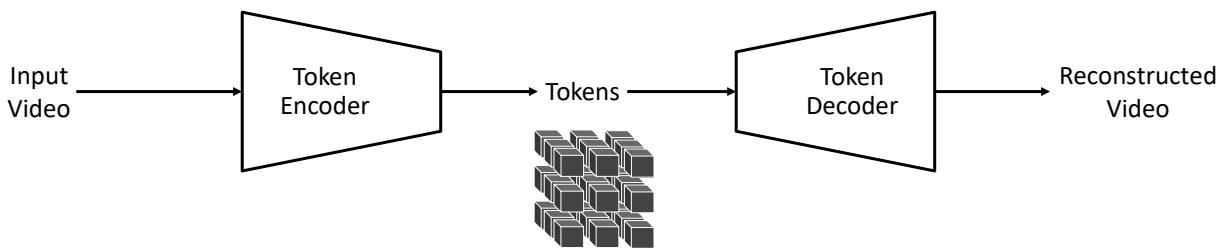
图 24-23:视频分词管线。输入视频通过编码器压缩为远比原始视频紧凑的 token 表示,解码器从 token 重建原始视频。分词器训练的目标是让 token 尽可能保留原始视频的视觉信息。
连续分词器 vs. 离散分词器
Cosmos 提供两类视频分词器:
- 连续分词器(Continuous Tokenizer, CV):将视频编码为连续的浮点向量,类似于 Stable Diffusion 中的 VAE 潜在表示。适用于扩散模型,因为扩散过程需要在连续空间中进行加噪/去噪。
- 离散分词器(Discrete Tokenizer, DV):将视频编码为离散的整数索引,类似于 VQ-VAE 的量化码本。适用于自回归模型,因为自回归模型通过交叉熵损失预测下一个离散 token。
两类分词器都采用了因果设计(Causal Design)——当前帧的 token 计算不依赖未来帧的信息。这一设计有两个优势:一是训练时可以联合使用图片和视频数据(单帧图片可视为长度为 1 的"视频"),丰富模型对视觉多样性的学习;二是部署时与因果物理世界自然对齐——物理 AI 无法"预见未来"。
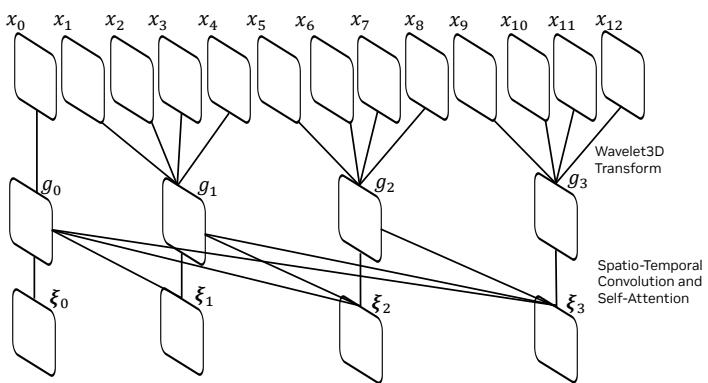
图 24-24:因果视频分词器编码器架构。输入视频帧
Cosmos 分词器的关键创新在于引入了 Wavelet3D 变换作为时空下采样方式,替代了传统的步进卷积(Strided Convolution)。小波变换将信号分解为低频近似和高频细节分量,在下采样时保留了更丰富的纹理和边缘信息,有效缓解了视频压缩中常见的模糊问题。
编码器-解码器的整体架构基于注意力机制:编码器通过多层 Wavelet3D 下采样和时空自注意力模块逐步压缩视频;解码器则通过对称的上采样和自注意力逐步恢复视频。训练时采用对抗损失(GAN Loss)、感知损失(Perceptual Loss)和重建损失(L1/L2)的组合,在压缩率和视觉质量之间取得平衡。
性能方面,Cosmos 分词器在图像和视频的编解码速度上相比已有方案(如 OpenSora 的 CausalVideoVAE)快 2 到 12 倍,同时保持了最小的模型参数量。下表对比了两类分词器的关键参数:
| 分词器 | 压缩比 (TxHxW) | token 类型 | 适配模型 | 典型用途 |
|---|---|---|---|---|
| CV8x8x8 | 8x8x8 | 连续向量 | 扩散模型 | 高质量视频生成 |
| DV8x16x16 | 8x16x16 | 离散整数 | 自回归模型 | 高效实时预测 |
24.5.4 两种世界基础模型
Cosmos 探索了两种可扩展的深度学习范式来构建预训练 WFM:扩散模型和自回归模型。二者都将困难的视频生成问题分解为一系列更易解决的子问题。所有模型在 10000 块 NVIDIA H100 GPU 组成的集群上训练,历时约三个月。
| 模型族 | 基础模型 | 衍生模型 | 辅助模块 |
|---|---|---|---|
| 扩散模型 | 7B Text2World, 7B Video2World | 14B Text2World, 14B Video2World | Prompt Upsampler |
| 自回归模型 | 4B, 12B | 5B Video2World, 13B Video2World | Diffusion Decoder |
扩散 WFM
扩散 WFM 采用 Transformer 架构,将视频生成分解为逐步去噪过程。预训练分两阶段:
- Text2World:从文本提示生成视频,让模型学习文本到视觉世界的映射;
- Video2World:以过去的视频帧和文本提示为条件,预测未来视频帧——这才是"世界模型"的核心能力。
架构上,扩散 WFM 基于 DiT(Diffusion Transformer),使用连续分词器 CV8x8x8(时间、高度、宽度各压缩 8 倍)将视频映射到连续 token 空间,然后在该空间中执行扩散去噪。文本条件通过 T5 编码器提取特征后,经交叉注意力注入 DiT 的每一层。对于 Video2World 任务,模型将过去的视频帧编码为条件 token,与噪声视频 token 一起送入去噪网络。此外,Cosmos 还训练了一个基于 LLM 的 Prompt Upsampler——将用户的简短文本提示扩展为详细描述,从而改善扩散模型的生成质量。
自回归 WFM
自回归 WFM 将视频生成建模为下一 token 预测任务,与 GPT 系列语言模型的范式完全一致。预训练同样分两阶段:
- 纯视频预测:给定过去的视频 token,自回归地预测未来视频 token;
- 文本条件 Video2World:加入文本提示,实现可控的世界状态预测。
自回归 WFM 使用离散分词器 DV8x16x16(时间压缩 8 倍、空间各压缩 16 倍),将视频量化为整数 token 后,用标准的交叉熵损失训练。在模型规模实验中,12B 模型相比 4B 模型生成了运动更自然、细节更清晰的视频,体现了 Scaling Law 在视频世界模型领域的有效性。
推理效率方面,自回归模型引入了 Medusa 多头推测解码——在 Transformer 最后一层之上添加多个并行预测头,每个头独立预测未来的一个 token,再通过验证机制确认正确的预测。这一技术在 8 块 H100 GPU 上实现了 320x512 分辨率下每秒 10 帧的实时视频生成,达到了交互式应用的基本速度要求。
两种范式各有优劣,可以用下表概括:
| 维度 | 扩散 WFM | 自回归 WFM |
|---|---|---|
| 生成范式 | 逐步去噪(并行) | 逐 token 预测(串行) |
| token 类型 | 连续向量 | 离散整数 |
| 视觉质量 | 更高(连续空间保真度好) | 较低(离散量化损失) |
| 推理速度 | 较慢(需多步去噪) | 较快(单步预测) |
| 可控性 | 通过交叉注意力注入条件 | 通过 token 序列拼接条件 |
| 与 LLM 统一 | 架构不同,难统一 | 范式一致,易统一 |
扩散解码器:取长补短
离散分词器的激进压缩(16x16 空间压缩)不可避免地带来模糊和伪影。Cosmos 提出了一个巧妙的解决方案——扩散解码器(Diffusion Decoder):将自回归模型输出的离散 token 作为条件输入,通过微调后的扩散模型进行"超分辨率"式的解码,恢复出清晰的视频帧。
具体而言,训练时对每个视频同时计算两套 token:离散分词器 DV8x16x16 产出的离散 token(作为条件输入),和连续分词器 CV8x8x8 产出的连续 token(作为去噪目标)。离散 token 经嵌入层映射为 16 维向量后,在空间维度上 2 倍上采样以匹配连续 token 的尺寸,然后沿通道维度与噪声连续 token 拼接,送入扩散去噪器训练。推理时,自回归模型输出的离散 token 经过上述条件化扩散过程解码为连续 token,再由连续分词器的解码器恢复出 RGB 视频。这一设计让自回归模型兼获了离散建模的效率和扩散解码的视觉质量。
24.5.5 物理对齐评估
世界模型最终需要的不只是生成"好看"的视频,更要生成物理正确的视频。Cosmos 论文从两个维度评估预训练 WFM 的物理可信度。
3D 一致性
好的世界模型生成的视频应当对应一个几何合理的三维世界。Cosmos 使用两组指标来度量:
- 几何一致性:计算生成视频中关键点匹配的 Sampson 误差,以及 SfM(Structure from Motion)相机位姿估计的成功率。Cosmos 扩散 WFM 的位姿估计成功率达到 62.6%~68.4%,接近真实视频的 56.4%(对比基线 VideoLDM 仅 4.4%);
- 视图合成一致性:在生成视频上训练 3D 高斯溅射模型,评估合成新视角的 PSNR/SSIM/LPIPS。Cosmos 模型的 PSNR 达到 30~33 dB,显著优于 VideoLDM 的 26.23 dB。
物理规律对齐
Cosmos 团队使用 NVIDIA PhysX 和 Isaac Sim 物理仿真引擎生成了 800 个受控测试视频,覆盖八类物理场景:
- 自由落体——重力与碰撞
- 斜面滚动——重力与转动惯量
- U 型轨道——势能与动能转换
- 稳定堆叠——力的平衡
- 不稳定堆叠——重力与碰撞
- 多米诺骨牌——动量传递
- 跷跷板——力矩与转动惯性
- 陀螺仪——角动量与进动
评估时,将仿真渲染的前几帧作为条件输入 WFM,让模型"推演"后续帧,再与物理仿真的真值对比。结果表明:提供更多条件帧(9 帧 vs. 1 帧)能显著改善物理预测准确度(扩散 WFM 的目标 IoU 从 0.332 提升到 0.592);但所有模型在复杂物理场景中仍存在明显失败案例,如物体凭空出现/消失、形状变形、违反重力等。
客观评价:当前 WFM 在受控的刚体物理场景下已经表现出了一定的物理直觉,但离真正"理解"物理定律还有很大差距。正如 Cosmos 论文所坦承的,"所有 WFM 在物理对齐上都面临同样的挑战,需要更好的数据管理和模型设计"。
24.5.6 后训练:从通才到专才
预训练 WFM 是物理世界的"通才",但实际部署需要面向特定任务的"专才"。Cosmos 展示了三类后训练场景。
相机控制:可导航的 3D 世界
通过在模型中注入 Plucker 坐标编码的相机位姿信息,用户可以用"摇杆"控制虚拟相机在生成的 3D 世界中自由漫游——前进、后退、左转、右转。量化评估显示,Cosmos 相机控制模型的 FID 为 14.30(对比基线 CamCo 的 57.49),位姿估计成功率高达 82.0%(对比 CamCo 的 43.0%)。

图 24-25:Cosmos 相机控制后训练模型的生成结果。给定相同的初始图像和相机轨迹,不同随机种子生成了视觉多样化但 3D 结构一致的虚拟世界。上下两组分别对应两个不同的场景。
机器人操作:指令驱动与动作驱动
Cosmos 在两种机器人任务上进行了后训练:
- 指令驱动:输入当前画面和自然语言指令(如"将面包从烤面包机取出放到盘子上"),预测机器人执行该指令的未来视频。训练数据来自 1X Technologies 的 EVE 人形机器人,约 200 小时自我中心视角视频;
- 动作驱动:输入当前画面和 7 维动作向量
,预测执行该动作后的下一帧。通过自回归执行一系列动作,即可生成整个操作过程的视频。
人工评估表明,在视觉质量、物理合理性、指令遵循和时间连贯性四个维度上,基于 Cosmos WFM 微调的模型均优于从头训练的 VideoLDM 基线。
自动驾驶:多视角世界生成
Cosmos 还展示了面向自动驾驶的多视角 WFM 后训练。模型可以同时生成多个摄像头视角的驾驶场景视频,并支持以行驶轨迹为条件进行控制。这为自动驾驶系统提供了大规模虚拟测试环境,显著降低路测成本。

图 24-26:Cosmos 生成的自动驾驶多视角场景。模型能够同时输出前方、侧方等多个摄像头视角的连贯驾驶视频,支持多种天气和光照条件。
24.5.7 世界模型的未来方向
世界模型是一个极具潜力但尚处早期的研究方向。基于 Cosmos 的实践和当前技术现状,有以下几个值得关注的发展方向:
物理对齐的深化。当前 WFM 本质上是从视频数据中学习统计规律,并未显式编码物理定律。将物理先验(如守恒律、牛顿运动方程)融入模型训练,或结合物理仿真引擎进行混合建模,是提升物理可信度的关键路径。
从视频到交互。Cosmos 当前的 WFM 主要在"预测未来视频帧"层面工作,尚未实现真正的实时双向交互。未来需要让 WFM 能在推理时实时响应智能体的动作输入,形成闭环控制回路。自回归模型在 8 块 H100 上已实现 10 FPS 的实时生成,为交互式应用提供了初步的速度基础。
多模态感知融合。当前 WFM 以视觉(RGB 视频)为主要输入,但物理世界包含深度、触觉、力觉、声音等丰富模态。将这些模态纳入世界模型的输入输出空间,将极大提升其对物理世界的建模能力。
评估标准的建立。如何系统评估一个世界模型的"物理理解"能力,目前还缺乏成熟的基准。Cosmos 提出的基于物理仿真的受控评估方法是一个有价值的起点,但需要扩展到更复杂的场景(如流体动力学、柔性体形变)和更精细的物理效应(如摩擦系数变化、多体碰撞链)。
数据规模与质量的持续提升。Cosmos 的实践表明,视频数据的质量(物理相关性、动态丰富性、多样性)对 WFM 性能的影响远大于简单的数据量增长。设计更精细的数据管理策略——如自动识别并富集物理信息密集的视频片段——是未来的重要工程方向。
本节小结。世界基础模型代表了物理 AI 领域的一个重要范式转变:不再让 AI 直接在危险且昂贵的真实环境中学习,而是先在物理世界的"数字孪生"中训练。NVIDIA Cosmos 平台通过开源的视频管理流水线、视频分词器和预训练世界基础模型,降低了这一方向的研发门槛。然而,从"能生成逼真视频"到"真正理解物理规律",世界模型仍有相当长的路要走。正如从 GPT-2 到 GPT-4 的跨越让语言模型从"像模像样"变为"实用工具",世界模型也需要在数据规模、模型架构和物理对齐三个维度上持续突破,才能真正成为物理 AI 的基础设施。