21.10 Deep Research 系统
在前面的章节中,我们已经建立了从 Agentic RL(§21.9)到工具增强推理(§21.5)的完整技术栈。但这些技术最终要汇聚到一个应用场景中才能展现出全部威力——Deep Research(DR)系统。DR 将大语言模型置于端到端的研究工作流中,使其能够自主分解复杂问题、通过工具获取证据、管理长程记忆,并最终综合出带引用的结构化报告。它不是简单的"检索增强生成",而是一个完整的自主研究智能体。
本节的学习目标如下:(1)理解 DR 的三阶段演进路线图及其与传统 RAG 的本质区别;(2)掌握 DR 系统的四大核心组件——查询规划、信息获取、记忆管理、答案生成——的设计原理与权衡;(3)跟踪框架从 ReAct 到多 Agent 协作的技术演进;(4)理解奖励设计从单结果信号到多 Agent 信用分配的演进;(5)深入 REDSearcher 的完整训练方案;(6)了解主流评测基准的设计思路。
21.10.1 什么是 Deep Research:从 RAG 到自主研究
Deep Research 不是 RAG 的升级版,而是一种不同的范式。 要理解这个区别,我们先回顾传统 RAG 的工作方式:用户提问,系统检索一组相关文档,将文档拼接到 Prompt 中,模型一次性生成回答。整个过程是单轮、固定管道、被动检索的。
DR 则完全不同。它将 LLM 作为一个自主智能体,赋予其端到端的研究工作流:迭代式规划子问题、主动选择工具获取证据、在长程交互中管理记忆状态、最终将验证过的洞察综合为连贯的长文本报告。如图所示,整个系统形成一个闭环工作流,支持多轮迭代推理。
从系统设计的角度看,DR 的核心创新在于将"研究"这个本质上需要多轮试错的过程形式化为一个可优化的 MDP——Agent 在每一步观察当前的证据状态,决定下一步行动(搜索、浏览、提取、综合),并根据最终产出的质量获得奖励信号。
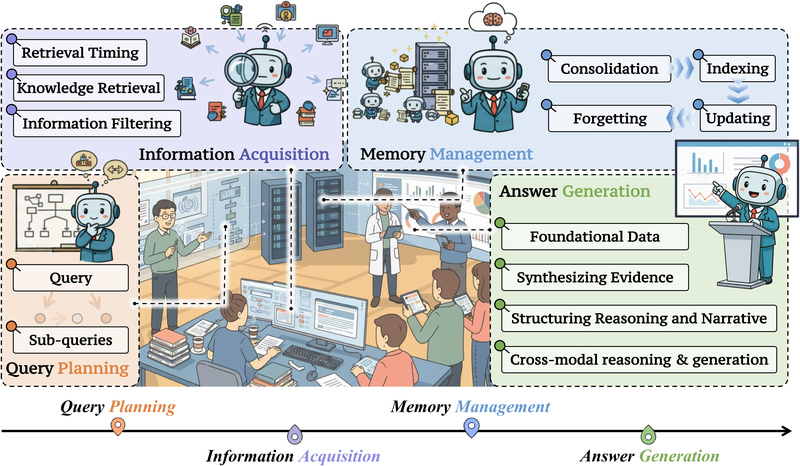
图 21-10a:DR 系统架构。从用户查询出发,依次经过查询规划(分解复杂问题)、信息获取(工具调用与过滤)、记忆管理(中间发现的整合与索引)和答案生成(冲突解决与结构化输出)。四个组件形成闭环,支持迭代式推理。来源:Shi et al. (2025)
三个维度的本质差异将 DR 与 RAG 彻底区分开来:
灵活的工具交互。RAG 局限于预索引语料库上的静态检索循环;DR 支持多步骤、工具增强的动态交互——搜索引擎、Web 浏览器、代码执行器、学术检索 API 都是可用工具,Agent 根据当前推理状态自主决定调用什么工具。
长程规划与自主工作流。复杂的研究问题不可能通过一次检索解决。DR 通过闭环控制和多轮推理实现自主工作流——协调多个子任务、管理不断增长的上下文、迭代优化中间结果。这要求系统具备 §21.9 中讨论的完整 Agentic RL 能力。
可验证的开放式输出。DR 引入引用追溯机制,将自然语言输出与有据可查的证据对齐。每一条声明都应当有明确的来源链接,使人类读者能够验证和追溯。
用一个具体例子来感受这种差别。假设用户问:"对比 Flash Attention 和 Ring Attention 在超长序列场景下的性能表现和适用条件。"
传统 RAG 会检索几篇相关论文的片段,拼进 Prompt 让模型一次性回答——但它无法处理两种方法在不同硬件配置下的交叉对比,也不会主动去搜索最新的基准测试数据。DR 系统则会:(1)将问题分解为"Flash Attention 的核心机制与性能数据"、"Ring Attention 的设计目标与适用场景"、"两者在超长序列上的对比实验"等子问题;(2)为每个子问题选择合适的检索工具(学术搜索引擎找论文、代码仓库找实现细节);(3)在获取第一轮证据后发现需要补充硬件配置信息,自主发起第二轮检索;(4)将所有证据整合为带引用的结构化对比报告。
21.10.2 三阶段演进路线图
Shi et al. (2025) 将 DR 视为一条能力轨迹,三个阶段捕捉了系统能力的渐进扩展。理解这个路线图有助于我们定位当前技术所处的位置,以及前沿研究正在攻克的方向。
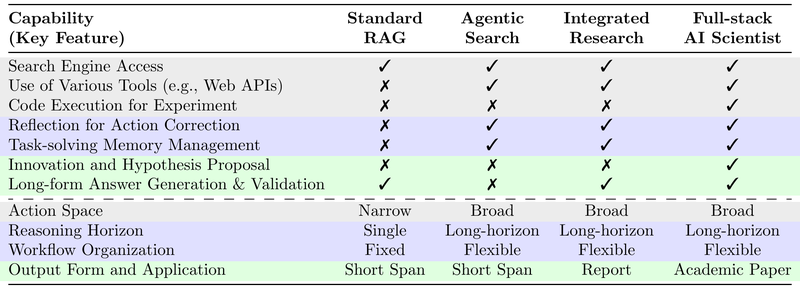
图 21-10b:从标准 RAG 到 DR 三阶段的能力对比。从左到右,动作空间从窄到宽,推理视野从单次到长程,工作流从固定到灵活,输出形式从短跨度答案到学术论文。来源:Shi et al. (2025)
Phase I:Agentic Search(智能搜索)——聚焦精确证据获取。系统通过查询改写和分解提高召回率,检索并重排候选文档,产出简洁的带引用答案。典型场景包括开放域问答和多跳问答。评估指标侧重检索 recall@k 和答案精确匹配(EM/F1)。
这个阶段的核心挑战是何时检索和检索什么——盲目检索不仅浪费计算资源,低质量文档还会误导模型。从技术实现看,Phase I 的系统通常仍采用固定或半固定的检索管道,Agent 的自主性体现在查询改写和结果筛选上,而非完整的工作流控制。
Phase II:Integrated Research(集成研究)——超越孤立事实,产出整合异构证据的连贯结构化报告。研究循环变为显式迭代:规划子问题、从多种原始内容(HTML、表格、图表)中检索和提取关键证据、最终综合为叙事性报告。评估转向细粒度事实性、引用验证、结构连贯性和关键点覆盖。
这是当前大多数商业 DR 产品(如 OpenAI Deep Research、Anthropic Deep Research)所处的阶段。Phase II 与 Phase I 的根本区别在于输出形态的跃迁——从短跨度答案(一句话或一段话)到万字级别的长文本报告,这对记忆管理和答案生成组件提出了全新要求。
Phase III:Full-stack AI Scientist(全栈 AI 科学家)——DR 智能体不仅聚合证据,还要生成假设、设计实验验证、批评现有观点、提出新视角。这意味着系统需要从信息消费者升级为知识创造者。应用包括论文审稿、科学发现和实验自动化。
这个阶段仍处于早期探索,核心难点在于如何区分"生成性新颖"(创造性重组已有知识)和"推导性新颖"(逻辑推出的真正新结论),以及如何防止"看似创新实则幻觉"。当前的前沿尝试包括 AI Scientist(自动生成研究 idea 并编写代码验证)和 PaperBench(评估 AI 复现论文的能力),但距离真正的自主科学发现仍有相当距离。
核心洞察:三个阶段之间不是替代关系,而是累积关系——Phase II 需要 Phase I 的精确检索能力作为基础,Phase III 需要 Phase II 的综合报告能力作为基础。跳级尝试(如直接在没有可靠检索的模型上做科学发现)通常会导致严重的幻觉问题。
21.10.3 四大核心组件
DR 系统的架构可以分解为四个正交但相互耦合的组件。理解它们各自的设计空间和权衡,是构建或评估 DR 系统的基础。
组件一:查询规划(Query Planning)
查询规划负责将用户的复杂问题分解为可执行的子查询序列。这个组件的设计直接决定了系统的推理深度和效率。
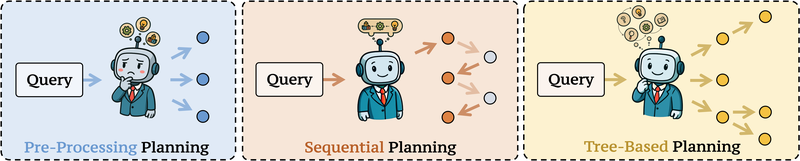
图 21-10c:三种查询规划策略对比。(a) 并行规划——一次性分解为独立子查询;(b) 顺序规划——多轮迭代逐步分解;(c) 树状规划——组织为树/DAG 结构。来源:Shi et al. (2025)
并行规划将查询一次性分解为多个独立子查询,同时处理。代表性工作包括 Least-to-Most Prompting(引导模型将复杂任务分解为有序的简单子查询)和 CoVE(生成多个独立子问题并行验证事实性)。并行规划的优势是高效,但它隐式假设子查询之间相互独立——当子问题之间存在逻辑依赖时(如"X 的导师是谁?"的答案决定了下一个子问题"这位导师在哪所大学任职?"),并行规划会产生错误。
顺序规划通过多轮迭代逐步分解问题,每一轮基于上一轮的输出。代表性工作包括 Search-R1(将搜索增强推理建模为多轮交互)和 R1-Searcher(在一个动作中发出多个查询以覆盖更广的检索空间)。顺序规划擅长处理逻辑依赖,但计算成本高,且可能产生累积误差——早期的错误分解会传播到后续所有步骤。
树状规划结合两者的优势,将子查询组织为树或有向无环图(DAG)。RAG-Star 利用蒙特卡洛树搜索(MCTS)和 UCT 引导迭代分解;DeepRAG 通过二叉树探索决定参数化推理 vs. 检索推理。树状规划在效率和依赖处理之间取得平衡,但训练稳健的树状模块极具挑战性。
设计权衡:并行 → 高效但忽略依赖;顺序 → 处理依赖强但成本高且可能累积误差;树状 → 平衡但训练难度大。实践中,多数先进系统采用混合策略——先顺序分解顶层子问题,再并行处理各子问题内的原子查询。
组件二:信息获取(Information Acquisition)
信息获取涉及三个关键子问题:选什么工具、何时检索和如何过滤。
工具选择方面,DR 系统通常配备三类检索工具:
- 词汇检索:BM25、SPLADE 等基于精确词匹配的方法,计算效率高,适合精确术语查找
- 语义检索:将查询和文档编码到连续向量空间,捕捉超越精确匹配的语义相似性
- 商业搜索引擎:Google、Bing 等,提供实时信息访问和跨源验证能力
高级系统如 WebDancer 还支持网页浏览、DOM 解析等操作,WebSailor-V2 进一步增加了多模态检索能力,显著扩展了可用动作空间。
检索时机是一个关键挑战。检索的演进路径可以概括为:固定检索(每一步都检索)→ 动态触发检索(ReAct 风格,模型决定何时检索)→ 基于 RL 的检索策略学习(Search-R1,模型通过强化学习自动学习最优检索时机)。盲目检索的代价不仅是计算资源浪费——低质量文档可能主动误导模型的推理方向。
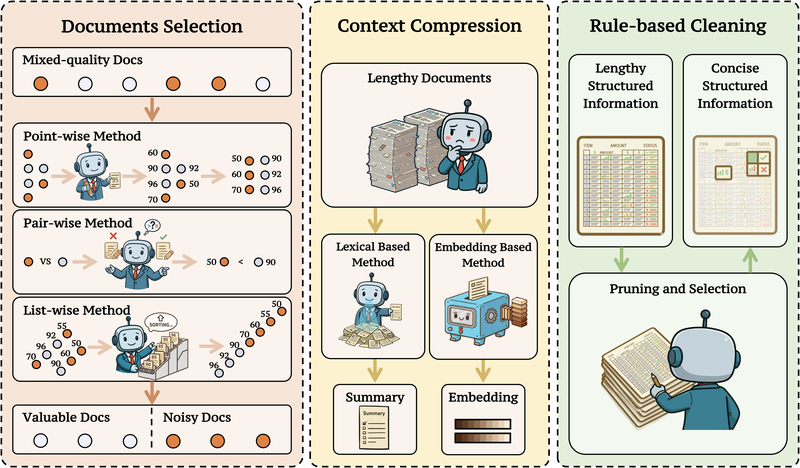
图 21-10d:信息过滤的三种范式。(a) 文档选择——逐点/逐对/列表式排序;(b) 内容压缩——词汇级摘要或嵌入级压缩;(c) 规则清洗——移除 CSS/JS 噪声、提取核心表格。来源:Shi et al. (2025)
信息过滤分为三类:
- 文档选择:从候选集中选出最相关的文档。方法从逐点评分(如 BGE 嵌入模型独立评估每篇文档的相关性)到逐对排序(如 PRP 成对比较)再到列表式全局排序(如 RankGPT 全局重排、Rank-R1 基于 GRPO 训练排序策略)
- 内容压缩:将长文档压缩为摘要或固定长度嵌入。词汇级方法如 RECOMP 生成文本摘要,嵌入级方法如 xRAG 将文档极致压缩为单个 token 的嵌入向量
- 规则清洗:去除网页中的 CSS/JS 噪声(HtmlRAG)、提取核心表格信息(TableRAG)等预处理操作
组件三:记忆管理(Memory Management)
记忆管理是 DR 与简单 RAG 的根本区别。 在多轮长程交互中,Agent 必须在不断膨胀的上下文中保持一致性和适应性。这要求系统具备记忆整合、索引、更新和遗忘四种能力。
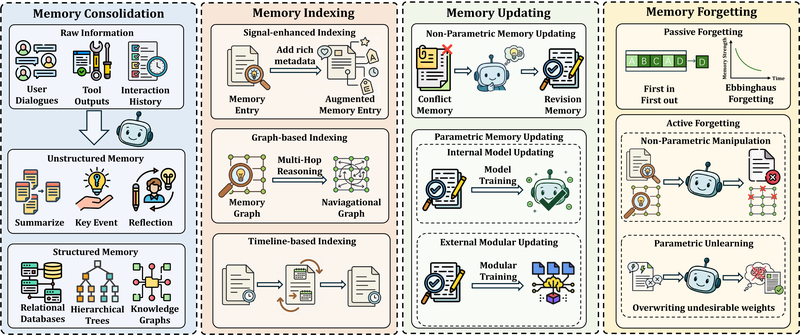
图 21-10e:记忆管理的四个核心操作。(1) 记忆整合——将短期信息转化为持久表示;(2) 记忆索引——构建高效检索路径;(3) 记忆更新——修正已存储知识;(4) 记忆遗忘——移除过时内容。来源:Shi et al. (2025)
记忆整合将短期交互信息转化为持久表示。非结构化方法(如 MemoryBank 的日常摘要、Generative Agents 的反思机制)简单但缺乏精确检索能力;结构化方法(如 HippoRAG 的知识图谱、AriGraph 的记忆图)支持精确的实体关系查询和多跳推理。
记忆索引为存储的记忆构建高效检索路径。三种范式各有侧重:信号增强索引(添加情感、时间等辅助元数据)、图索引(利用图结构支持多跳推理)、时间线索引(按时间/因果序列组织记忆)。
记忆更新分为非参数化(对外部存储执行显式的 ADD/UPDATE/MERGE 操作)和参数化(通过训练修改模型权重)两种。非参数化更新灵活但增加存储开销;参数化更新永久但风险高——错误的权重修改可能"遗忘"其他有用知识。
记忆遗忘是容易被忽视但至关重要的能力。被动遗忘(如 MemGPT 的 FIFO 队列、MemoryBank 的艾宾浩斯遗忘曲线)自动淘汰旧信息;主动遗忘(如 Mem0 的 DELETE 命令)允许精确移除特定记忆。在上下文窗口有限的现实约束下,选择性遗忘是保持系统效率的必要手段。
实践提示:记忆管理的设计需要在"记得越多越好"和"上下文预算有限"之间做出权衡。一个有效的经验法则是:对事实性信息使用结构化记忆(知识图谱),对推理过程使用周期性摘要压缩。
组件四:答案生成(Answer Generation)
答案生成是 DR 系统的最终综合环节,面临两个核心挑战:证据冲突解决和长文本连贯性维护。
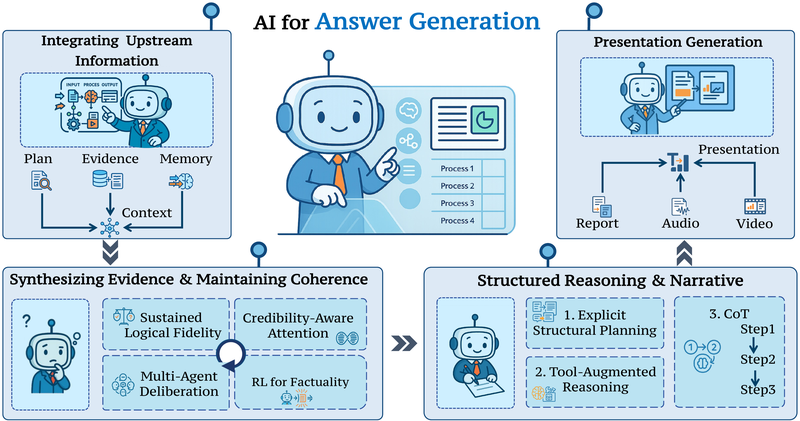
图 21-10f:答案生成的四个递进阶段。(1) 上游信息整合——汇聚子查询、证据和记忆;(2) 证据综合与连贯性——冲突解决与长文本结构化;(3) 推理结构化——从 Chain-of-Thought 到 DAG 大纲;(4) 展示生成——文本/可视化/多模态输出。来源:Shi et al. (2025)
冲突解决是最棘手的问题。当多个来源对同一事实给出矛盾证据时,系统必须做出判断。三种主要方法各有优劣:
- 可信度感知注意力:按来源权威性加权,简单高效,但可能偏向权威来源的错误信息
- 多智能体审议:MADAM-RAG 模拟专家委员会讨论,多个 Agent 分别阅读不同来源后进行"辩论",开销大但更鲁棒
- 基于 RL 的事实性训练:RioRAG 在奖励函数中显式编码事实一致性,需要额外训练但泛化性好
长文本连贯性的核心发现来自 LongWriter:模型能够产出的最大连贯长度与 SFT 训练样本长度成正比,即
值得一提的是,当前商业 DR 系统的答案生成通常依赖精心设计的工作流提示工程(Workflow Prompting)。以 Anthropic Deep Research 为代表,其编排器会分析查询的语义类型和难度,确定研究策略并动态分配 Agent 数量(从简单事实查询的 1-2 个到多视角分析的 10+ 个)。每个子任务被编码为结构化提示,指定目标、输出模式、引用策略和回退动作。工作者 Agent 并发运行后,编排器监控覆盖度、解决冲突,最终通过程序化链接将声明与来源关联,确保事实接地和透明引用。
21.10.4 框架演进:从 ReAct 到多 Agent 协作
理解了四大组件之后,我们来看 DR 系统的框架如何演进。这条技术路线清晰地展示了从简单到复杂、从单体到分布式的发展轨迹。
起点:ReAct 单 Agent 范式。 最早的 DR 方法基于 ReAct 风格的单 Agent 设计——模型在统一的决策序列中同时执行推理、查询、信息读取和回答生成。这里分化出两条路线:
Search-R1 / R1-Searcher 路线,强调在 LLM 原生推理能力上的延伸。Search-R1 的每一次动作都是一个查询:模型在
<think>...</think>中进行内部推理,遇到知识空缺时用<search>query</search>触发检索,将结果插入上下文后继续思考。R1-Searcher 在此基础上允许一次发出多个查询,并行探索不同检索方向。WebDancer / WebSailor-V2 路线,强调 Agent 行为的规范化。WebDancer 将 ReAct 规范化为标准的工具调用模式——用
<tool_call>标签 + 工具名称 + 参数发起调用,用<tool_response>接收结果。这种结构化使得 Agent 行为更模块化,便于策略学习与扩展。WebSailor-V2 则在动作空间上更为丰富:Agent 不仅可以发起搜索,还支持访问网页、解析 DOM、执行复杂页面操作等多种工具行为,使单模型能够处理更真实的 Web 环境。
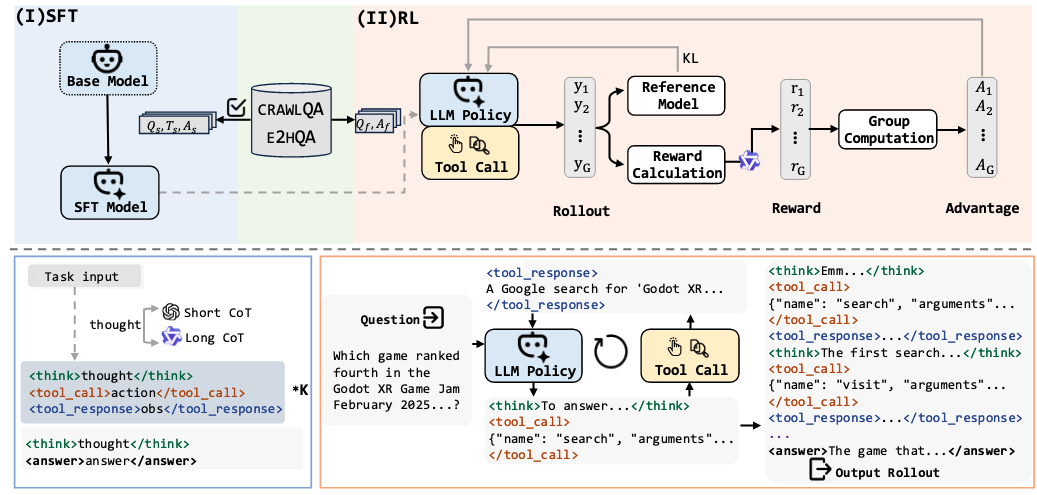
图 21-10g:WebDancer 架构。将 ReAct 单 Agent 范式规范化为标准工具调用模式,支持搜索、浏览、信息提取等多种结构化工具操作。来源:Wu et al. (2025)
瓶颈与转折。 单 Agent 范式在简单任务上表现良好,但随着任务复杂度增加,两个问题变得不可回避:长链任务中的记忆过载(上下文窗口被工具返回的大量文本填满,模型开始"遗忘"早期获取的关键证据)和推理轨迹过长带来的训练不稳定(数十轮交互的累积误差使 RL 训练信号极度稀疏,且超长轨迹中"有效动作"与"无效动作"的比例严重失衡)。这两个问题的根源是同一个:所有能力集中在一个策略中学习,当任务复杂度超过单一策略的承载能力时,系统性能急剧下降。
关键过渡:ReSum 的双模型协作。 ReSum 引入了一个独立训练的摘要模型(ReSumTool),对不断膨胀的交互历史进行周期性压缩,将系统状态浓缩为紧凑的"reasoning state"。具体而言,每当交互历史超过预设阈值时,摘要模型被触发,将当前所有的 Thought-Action-Observation 记录压缩为一段结构化摘要,保留关键发现和待验证假设,丢弃冗余的工具返回原文。从框架结构看,ReSum 已从传统 ReAct 范式转向主 Agent + 摘要器的双模型协作——搜索决策和长期记忆管理被解耦。其中,摘要模型在主 Agent 训练之前通过监督数据单独完成训练,强化学习阶段仅优化主模型参数。
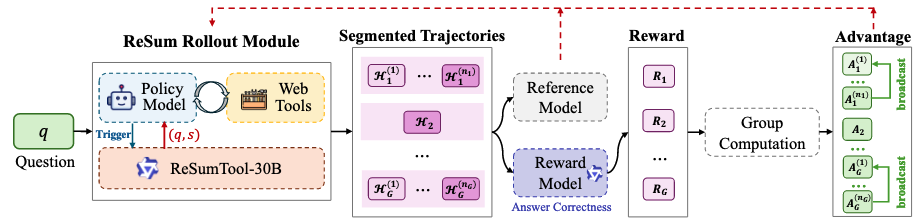
图 21-10h:ReSum 架构。主 Agent 负责搜索与决策,摘要器负责周期性压缩交互历史,缓解长程搜索中的上下文膨胀。来源:Wu et al. (2025)
多 Agent 协作。 MMOA-RAG 和 C-3PO 将分工推进到更彻底的多 Agent 架构。MMOA-RAG 构建了由 Retriever、Selector、Generator 三个协作 Agent 组成的系统,各 Agent 通过结构化状态通信,并在训练阶段实现协同优化。C-3PO 则通过蒙特卡洛方法在长序列搜索路径中进行信用分配——对每一次搜索、点击或判断动作进行轨迹采样,计算其对最终结果的贡献度。
最新形态:WebResearcher 的长程研究工作流。 WebResearcher 将 DR 建模为多阶段、长时序的迭代过程,通过主研究者 Agent(负责高层决策和报告演化)、上下文管理器(管理长程记忆)和并行探索器(执行具体搜索任务)的协作,生成 evolving report。
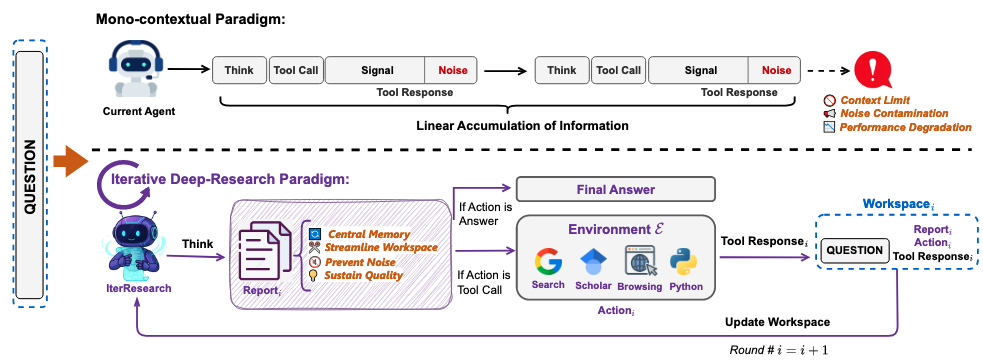
图 21-10i:WebResearcher 架构。主研究者 Agent、上下文管理器和并行探索器协作,支持长 horizon 的多步骤研究任务。来源:Qiao et al. (2025)
下表总结了框架演进的关键里程碑:
| 阶段 | 代表框架 | 核心特征 | 局限 |
|---|---|---|---|
| 单 Agent ReAct | Search-R1, WebDancer | 统一决策序列,结构简单 | 记忆过载,长链不稳定 |
| 双模型协作 | ReSum | 主 Agent + 摘要器解耦 | 摘要模型需单独训练 |
| 多 Agent 协作 | MMOA-RAG, C-3PO | 角色分工,协同优化 | 信用分配复杂 |
| 长程研究工作流 | WebResearcher | 并行探索 + 报告演化 | 训练数据构建成本高 |
21.10.5 奖励设计演进:从单结果奖励到多 Agent 信用分配
框架的演进驱动了奖励设计的同步进化。在 Agentic RL 中(§21.9),奖励信号的密度和精度直接决定了训练效果。DR 任务的多步骤、多角色特性使得传统的单结果奖励变得力不从心。
第一代:单结果奖励(Outcome Reward)。 Search-R1 首次将 RL 引入 DR 任务,以最终答案的正确性作为唯一奖励信号。模型完成整个搜索-推理-回答循环后,根据答案准确性更新策略。这种设计简单直接,但在长链任务中信号极度稀疏——模型无法知道是哪一步检索、哪一次推理判断导致了最终的成功或失败。
第二代:阶段化奖励(Stage Reward)。 R1-Searcher 引入阶段化奖励,将检索行为与推理结果分开评估,使模型在"是否发起检索"和"检索了什么信息"上获得独立反馈。这改善了长链推理的训练效率,但仍然是对单个 Agent 内部不同步骤的粗粒度区分。
第三代:多 Agent 信用分配(Multi-Agent Credit Assignment)。 MMOA-RAG 为多 Agent 系统中的每个角色设计独立奖励——Retriever 基于检索质量获得奖励,Selector 基于文档选择精度获得奖励,Generator 基于答案正确性获得奖励。这种设计使每个 Agent 能够针对自己的角色进行优化。
C-3PO 则采用更精细的蒙特卡洛信用分配。系统对每一次搜索、点击或判断动作进行轨迹采样,通过蒙特卡洛方法估计每个动作对最终结果的贡献度,从而实现动作级别的信用分配。
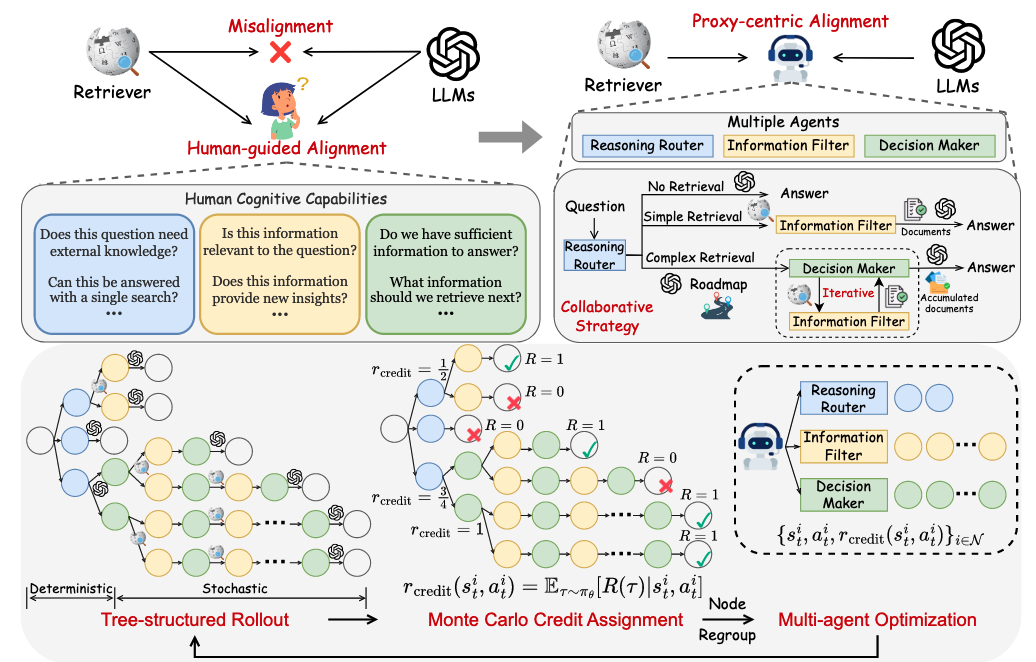
图 21-10j:C-3PO 架构。通过蒙特卡洛方法在长序列搜索路径中对每个动作进行信用分配,实现比结果奖励更精细的优化信号。来源:Chen et al. (2025)
前沿:GiGPO 的双层信用分配。 GiGPO(Group-in-Group Policy Optimization)提出了两级信用分配机制:宏观层评估整个 episode 的相对优势(类似 GRPO 的组内归一化),微观层基于锚点状态对每一步决策进行优势估计。该方法无需外部 Critic 网络,可直接融入 GRPO 框架。
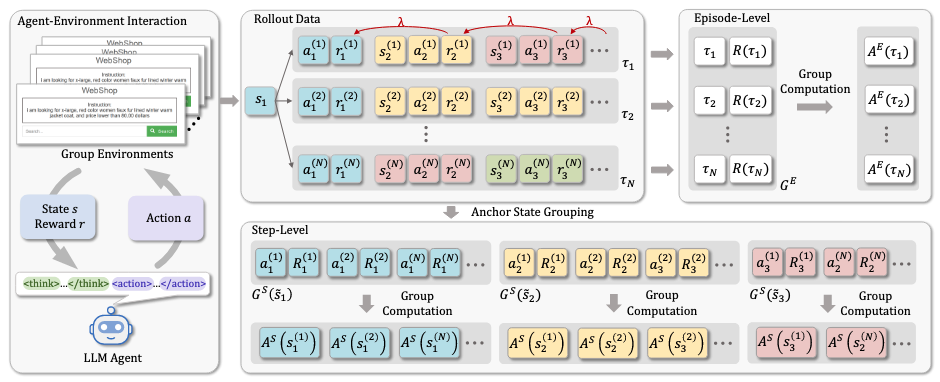
图 21-10k:GiGPO 的双层信用分配。外层为 episode 级别的相对优势(组间比较),内层为步骤级别的微观优势(基于锚点状态的逐步估计)。来源:Feng et al. (2025)
形式化地,GiGPO 的微观优势估计可以表示为:
其中
下表总结了奖励设计的演进:
| 范式 | 代表工作 | 奖励粒度 | 优势 | 局限 |
|---|---|---|---|---|
| 单结果奖励 | Search-R1 | Episode 级 | 简单、无需额外设计 | 长链信号稀疏 |
| 阶段化奖励 | R1-Searcher | 步骤级 | 改善长链训练效率 | 仍为粗粒度 |
| 角色独立奖励 | MMOA-RAG | Agent 级 | 各角色针对性优化 | 角色间协调困难 |
| 蒙特卡洛信用分配 | C-3PO | 动作级 | 精细信用分配 | 采样开销大 |
| 双层信用分配 | GiGPO | Episode + 步骤 | 无需 Critic,融入 GRPO | 锚点选取需设计 |
21.10.6 REDSearcher:开源 DR Agent 的完整训练方案
前面几节介绍的框架和奖励设计更多是概念层面的。REDSearcher(Chu et al., 2025)提供了一个从预训练模型到可部署 DR Agent 的完整、可复现的训练路径,并在多个基准上以 30B-A3B(30B 总参数、3B 激活参数)的 MoE 模型达到了与 GPT-5、Claude-4.5 等闭源系统可比的性能。
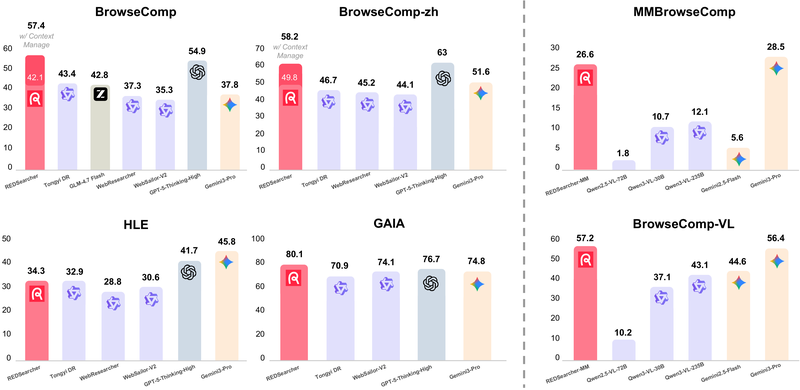
图 21-10l:REDSearcher 在六个基准测试上的性能对比。30B-A3B 规模的 REDSearcher 在 GAIA 上达到 80.1,超过 GPT-5-Thinking-High(76.7)。来源:Chu et al. (2025)
Treewidth 驱动的任务合成
REDSearcher 的第一个核心贡献是回答了一个基础问题:如何刻画深度搜索问题的复杂度? 答案是两个正交维度。
拓扑逻辑复杂度:Treewidth。 借鉴算法和数据库理论中的经典洞察——图结构问题的计算难度取决于底层图的 treewidth(树宽)。直觉上,treewidth 衡量了满足耦合约束所需的"工作记忆"大小。给定查询的逻辑结构图
其中
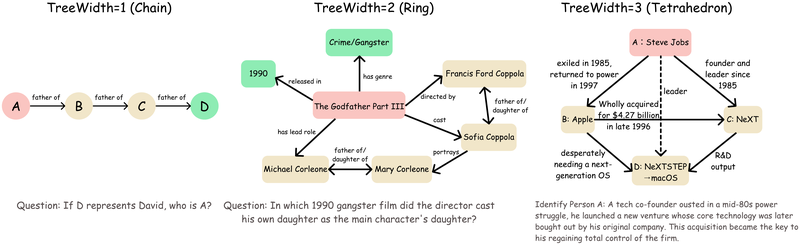
图 21-10m:三种代表性结构的 treewidth。左:链式推理(
信息源分散度:Minimum Source Dispersion(MSD)。 Treewidth 刻画了结构耦合,但不能完全决定搜索难度——因为单个综合文档可能包含多个关联事实,形成"快捷检索"。MSD 定义为完整覆盖所有推理节点所需的最少文档数:
当 treewidth 和 MSD 同时较高时,任务最能抵抗快捷检索,迫使 Agent 进行迭代规划和跨文档综合。
合成流程分为两个阶段。
QA 生成阶段:从种子实体出发,通过 Wikidata 结构化关系和网页超链接双通道构建知识图谱;LLM 驱动的 Graph Agent 进行拓扑增密(引入环路,将搜索从顺序检索转变为联合约束满足问题);从主图中采样多个子图和答案节点(One-Graph-Multi-Task 策略,答案节点按拓扑角色——深叶 vs. 高度枢纽——选取,实现样本量级的放大);最终通过 Tool-Injection 策略将静态实体转化为工具依赖约束(如地名转为路线约束、人名转为引用数约束、命名实体转为视觉线索),使工具调用成为推理轨迹的固有前提。
验证阶段:五级递进过滤——LLM 无工具求解(过滤太简单的样本)→ 搜索可检索性检查 → 幻觉/一致性检查 → Agent rollout 验证 → 答案唯一性检查。从低成本到高成本逐级递进,有效控制验证开销。
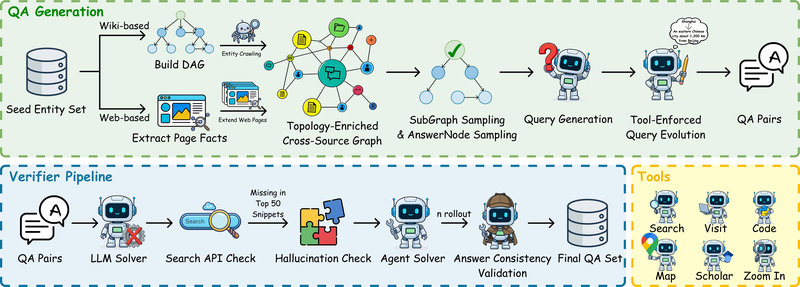
图 21-10n:REDSearcher 的双约束任务合成流程。上半部分为 QA 生成(从种子实体到工具依赖查询),下半部分为五阶段验证。来源:Chu et al. (2025)
四阶段训练流水线
REDSearcher 的训练方案包含 Mid-Training(两阶段)和 Post-Training(SFT + RL)共四个阶段。

图 21-10o:REDSearcher 完整训练流水线。Mid-Training Stage I(32K 上下文,~90B tokens)→ Stage II(128K 上下文,~10B tokens)→ Agentic SFT → Agentic RL。来源:Chu et al. (2025)
Mid-Training Stage I:原子能力训练(32K 上下文,~90B tokens)。聚焦两个核心原子能力:
(1)Intent-anchored Grounding(意图锚定提取)——在嘈杂的网页环境中根据当前推理意图准确识别缺失信息。训练方法是反向 QA 合成 + 干扰项:给定中心实体及其文档,提取事实片段,合成查询意图,在输入中混入无关干扰文档,训练模型在噪声中精确提取目标信息。
(2)Hierarchical Planning(层次规划)——将复杂问题区分为具体目标(有明确查询意图,需获取特定信息)和模糊目标(需通过查询缩小不确定性以确定具体目标),利用知识图谱的拓扑结构沿信息流方向展平,再由 LLM 生成对应的规划数据。
Mid-Training Stage II:复合交互训练(128K 上下文,~10B tokens)。解决预训练模型缺乏环境反馈经验的问题:
(1)Agentic Tool Use——用 LLM 模拟生成工具集(包含描述、接口签名、调用链),合成查询并模拟环境反馈,构建完整 ReAct 循环数据。关键设计是不调用任何外部服务,全部由 LLM 模拟——这使得数据生成成本极低且完全可控。
(2)Long-Horizon Interaction——长程场景下 LLM 模拟环境不可行(成本和一致性问题),因此构建基于 Wikipedia 和 Web Crawl Dumps 的本地模拟搜索环境,支持 search 和 visit 操作,在模拟环境中使用合成的复杂查询生成长程交互轨迹。
核心设计思想:将"原子技能"和"复合交互"分离——Stage I 用廉价合成数据大规模训练基础能力(90B tokens),Stage II 在有环境反馈的场景中训练复合行为(10B tokens),成本比例约 9:1。这种分离使得下游 SFT/RL 的初始探索成功率大幅提升。
Post-Training SFT:使用 5 个真实环境工具(Google Search、Jina 网页访问、代码沙箱、Google Scholar、Google Maps)生成高质量轨迹。标准 next-token prediction loss,mask 环境观测部分不参与梯度更新——这一设计至关重要,因为环境返回的文本(搜索结果、网页内容)不是模型应该学习生成的,对其计算梯度会引入噪声信号。三重过滤策略保证数据质量:仅保留答案正确的轨迹、过滤含大量失败动作的样本、每个问题仅保留一条轨迹(避免对特定问题过拟合)。
Post-Training RL:使用 GRPO 算法,核心目标函数为:
其中优势函数通过组内相对归一化计算
关键工程细节:构建包含数千万文档的功能等价模拟环境,三个设计原则保证其有效性——接口一致性(API 与真实搜索 API 保持一致)、证据完备性(包含所有必要证据)、环境噪声(大规模干扰文档模拟真实搜索的信噪比)。实现 URL 混淆流水线防止模型学习 Wikipedia URL 模式偏见——如果模型记住了"Wikipedia 的 URL 格式通常包含答案实体",它就会绕过搜索直接构造 URL,学到的是捷径而非真正的搜索策略。RL 训练采用基于 Slime 的异步 rollout 工作流,两级负载均衡策略(同一 rollout 内保持推理引擎亲和性以最大化 prefix cache 复用,跨引擎采用 round-robin + 最少访问调度)保证训练效率。
关键实验发现
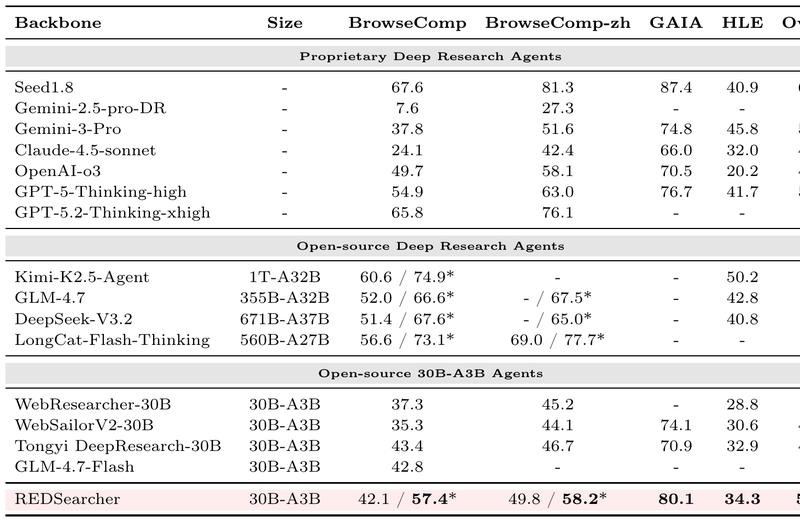
图 21-10p:REDSearcher 文本搜索主要结果。Overall 得分 51.6,超越同规模开源模型和多个闭源系统。来源:Chu et al. (2025)
三个最具启示性的实验发现:
Mid-Training 的逐阶段增益。 消融实验显示平均性能从 Base 的 42.81 稳步提升到 Stage II 后的 47.39(+4.58)。其中 Stage I Grounding 为 BrowseComp 带来 +1.87 的提升(增强噪声环境中的信息提取);Stage I Planning 为 GAIA 带来 +4.13(从 76.70 到 80.83,确认层次规划对复杂推理的关键作用);Stage II Agentic 训练带来的 BrowseComp-ZH +8.91 是最大单项增益,说明真实动作-反馈循环和 128K 上下文对深度搜索的目标一致性至关重要。这些数据支持了"先原子后复合"的分阶段设计决策。
RL 使 Agent 变得更高效。 一个反直觉的发现:RL 训练期间 rollout 长度逐渐下降(平均工具调用从 100.6 降至 90.1),但奖励保持稳定或继续提升。这说明模型通过 RL 学会了更高效的搜索策略,减少了冗余工具调用。
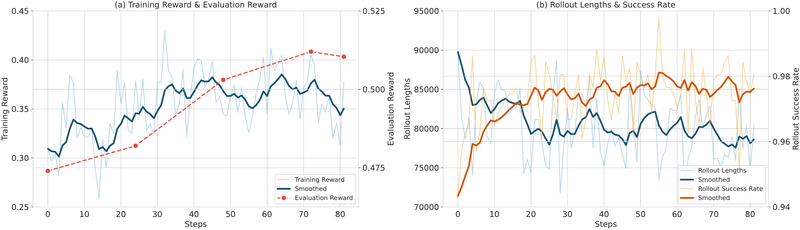
图 21-10q:RL 训练曲线。(a) 训练奖励和评估奖励持续提升;(b) rollout 长度随训练逐渐下降,说明模型学会了更高效的搜索策略。来源:Chu et al. (2025)
工具增益 vs. 参数记忆的解耦。 REDSearcher 在无工具模式下得分最低,启用工具后大幅提升。这看似是劣势,实则是优势——它表明模型的搜索能力是真实习得的,而非依赖预训练阶段记住的知识。相反,部分基线在无工具模式下仍有较高准确率,可能反映了基准集的数据泄露或更广泛的预训练覆盖。tool-enabled 增益比最终准确率更能反映深度搜索能力的真实水平。
21.10.7 数据构建:从简单 QA 到多步骤研究轨迹
DR 系统的训练需要高质量的多步骤交互轨迹,但这类数据极其稀缺。本节梳理数据构建的三种主要范式。

图 21-10r:三种数据合成范式。(i) 强到弱蒸馏——从强大 LLM 蒸馏正确轨迹;(ii) 多智能体蒸馏——利用多角色系统生成多样化轨迹;(iii) 迭代自进化——模型在自身数据上迭代微调。来源:Shi et al. (2025)
强到弱蒸馏是最直接的方法。WebDancer 提出了两类互补的数据生成策略:CRAWLQA(从真实网站递归抓取子页面,记录完整浏览轨迹,再由 LLM 生成 QA 对)强调网页操作能力;E2HQA(Easy-to-Hard QA,从简单问题逐步生成更复杂的多跳问题)强调多步推理能力。
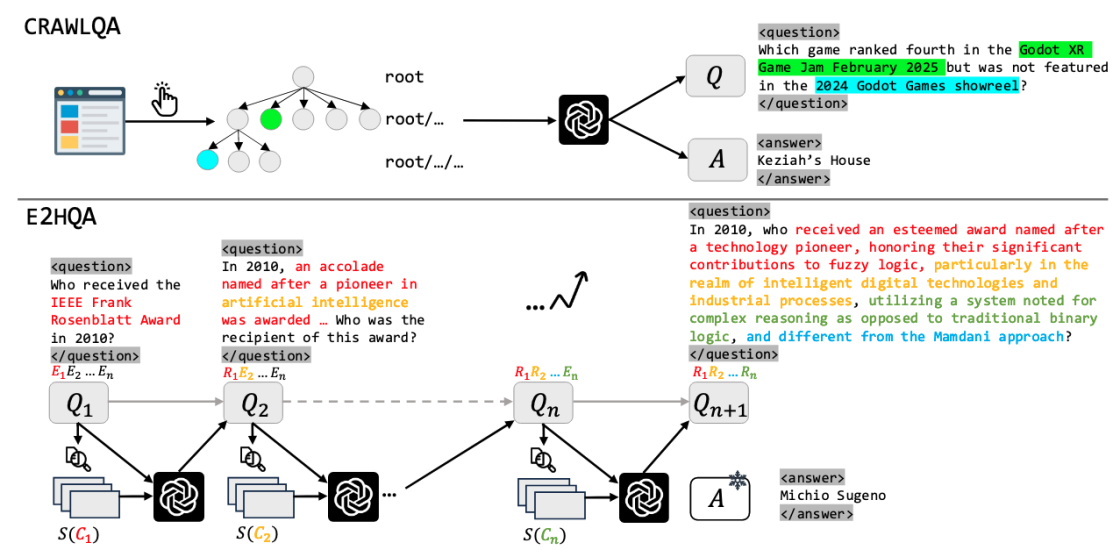
图 21-10s:WebDancer 的两类数据生成流程。CRAWLQA 基于真实网站浏览轨迹,E2HQA 通过难度递进生成多跳问题。来源:Wu et al. (2025)
多智能体蒸馏利用由规划器、查询改写器、验证器等组成的多 Agent 系统生成更多样化的训练轨迹。MaskSearch 通过这种方式生成了 58K 验证轨迹,Chain-of-Agents 经四阶段过滤产出 16,433 条高质量轨迹。多智能体蒸馏产出的轨迹更长、更多样,但管道设计复杂、推理成本高。WebSailor-V2 采用了一种独特的数据增强策略:将网页内容组织为密集互联的知识图(节点间有循环和多路径依赖,而非简单树状结构),并对网页信息进行遮掩和扰动(随机隐藏或修改部分信息),构造"高不确定性任务"。这迫使模型学会反复确认信息、迭代搜索,在信息不完整或有干扰的情况下仍能生成合理推理结果。
迭代自进化的核心优势是无需外部模型或人工标注即可扩展训练。WebResearcher 采用三阶段数据引擎:从多学科文档中提取信息块并生成种子 QA 对 → 通过工具增强 Agent 迭代升级问题和答案(增加认知复杂度)→ 通过 Judge 和 Scorer 筛选验证。但自进化面临分布漂移、奖励黑客和自强化错误等风险。
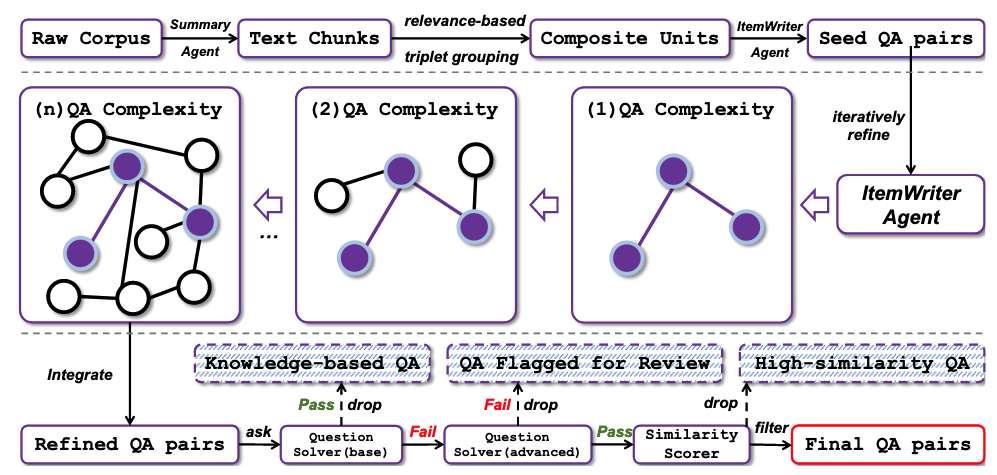
图 21-10t:WebResearcher 的三阶段数据引擎。种子生成 → 工具增强迭代升级 → 多 Agent 筛选验证。来源:Qiao et al. (2025)
数据质量 vs. 数据量的权衡:REDSearcher 的经验表明,500 条人工标注中 85% 通过逻辑一致性验证,DeepSeek-V3.2 在标准 Agent 设定下只能解决约 40% 的合成任务——这意味着合成数据的难度校准至关重要。太简单的数据无法推动能力提升,太难的数据则导致 RL 探索成功率过低、训练信号消失。
21.10.8 评测基准
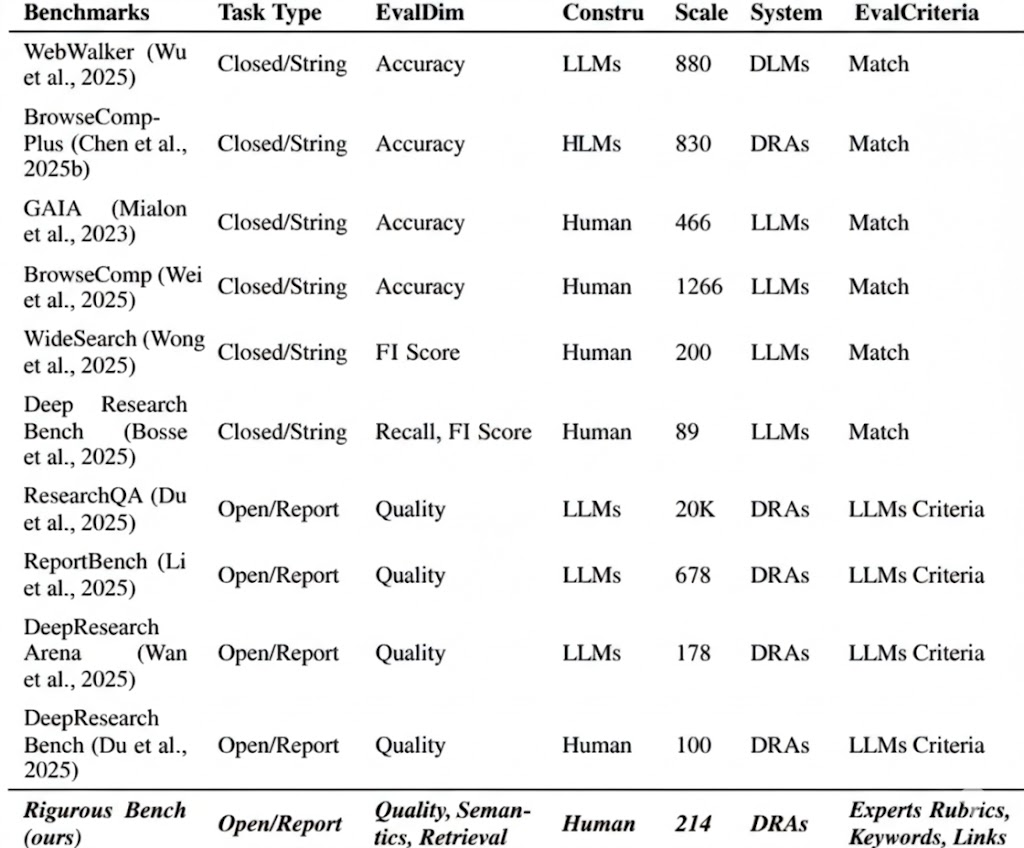
图 21-10u:DR 评测基准全景。来源:综合整理
DR 系统的评测沿三个维度展开,每个维度都有独特的挑战。
智能搜索评测从查询复杂度和交互环境两个子维度演进。查询复杂度从单跳 QA(NQ, TriviaQA)→ 多跳推理(HotpotQA, MuSiQue)→ 深度探索(GPQA 研究生级问题、GAIA 多步推理、HLE 全学科基准)。交互环境从静态语料库 → 实时网络(BrowseComp 要求持续导航定位难找信息)→ 多模态环境(MMInA)。其中 BrowseComp 值得特别关注——它的任务设计要求 Agent 在真实网络中持续导航、定位那些"难以通过简单关键词搜索找到"的信息,这使得单次检索几乎不可能成功,真正考验了 Agent 的长程搜索和迭代规划能力。
AI for Research 评测是 Phase III 的前沿评估方向。PaperBench 评估 AI 复现论文的能力;Scientist-Bench 涵盖 16 个领域的科研任务;DeepReview-Bench 包含 1,200 篇 ICLR 2024-2025 投稿,评估 AI 的同行评审能力。这些基准的共同挑战是评估标准本身的主观性——"创新性"和"科学贡献"难以用自动化指标精确衡量。
综合报告评测是 Phase II 的核心评估场景,主要基准包括:
| 基准 | 规模 | 核心特色 | 评估维度 |
|---|---|---|---|
| Deep Research Bench | 89 任务 | RetroSearch 冻结网页快照,解决评估可重复性 | 事实准确、信息保持 |
| DeepResearch Bench | 100 任务 | 来自真实用户查询(中英双语) | 报告质量、来源准确性 |
| ReportBench | 基于 arXiv | 根据专家综述反向生成问题 | 文献检索精确率/召回率 |
| DR Arena | 研讨会语料 | MAHTG 系统自动提取科研任务 | 关键点对齐、自适应清单 |
| DR Bench II | 132 任务 | 源自专家级调查报告 | 信息召回、分析深度、表达呈现 |
| MMDeepResearch-Bench | 140 任务 | 21 个领域的图文包 | 写作质量(FLAE)、引用忠实(TRACE)、文图一致(MOSAIC) |
几个值得注意的评测洞察:
信息保持是当前瓶颈。 Deep Research Bench 的失败模式分析揭示,Agent 的主要失败原因是遗忘上下文信息,其次是重复调用相同工具和产生幻觉。这直接印证了记忆管理组件的关键重要性。
写作质量与引用准确度的权衡。 MMDeepResearch-Bench 发现,写作质量高的模型不一定在引用准确度或视觉对齐上表现好——两者之间存在系统性权衡。这意味着评测 DR 系统需要多维度指标的联合评估,单一指标(如报告流畅度)会严重高估系统能力。
可重复性挑战。 真实网页内容随时间变化,导致评估结果不可重复。Deep Research Bench 的 RetroSearch 方案(冻结并存储网页快照)提供了一种解决思路,但快照本身会过时,如何平衡时效性和可重复性仍是开放问题。DR Bench II 提出了另一种思路——基于专家级调查报告构建任务和评分标准,将研究能力细分为信息召回、分析深度和表达呈现三个维度,通过二元评分细则(每个细则对应一个不可分割的事实或推理要求)降低评估主观性。
LLM-as-Judge 的可靠性。 大多数 DR 评测依赖 LLM 作为自动评审,但这引入了系统性偏见风险。DR Arena 通过将评审过程分为"准则制定"和"实际打分"两个独立阶段来缓解这一问题,并通过人类专家校准验证评审一致性(皮尔逊相关系数)。DeepResearch Bench 则同时检验了 LLM 评分与人类评分的一致性。即便如此,LLM 评审可能偏好更长的回复、特定的写作风格或与自身相似的系统,这些偏见在当前评测体系中尚未被完全解决。
21.10.9 挑战与展望
DR 系统正处于 Phase I 向 Phase II 的大规模过渡期,Phase III 仍处于早期探索。以下几个挑战将定义这个领域未来两到三年的研究方向。
训练稳定性。 多轮 RL 训练常出现奖励下降、无效响应和熵崩溃。两个已知的具体问题是:空轮次(SimpleTIR 识别并过滤不推进任务的碎片化输出,切断有害反馈循环)和回声陷阱(StarPO-S 发现策略快速同质化、放弃探索后不断重复保守输出,使用不确定性轨迹过滤保持探索)。更根本的方向是设计保留探索能力的冷启动方法,避免 SFT 导致的早期熵崩溃。具体而言,如果 SFT 阶段只示范了一种"标准"的搜索工作流,模型的策略分布就集中在这条路径上,后续 RL 几乎无法发现更优的替代策略。DAPO 和 MiniMax 的 Continual Pretraining 等方法试图通过在训练早期就植入多样的 Agent 行为模式来缓解这一问题。此外,多轮 GRPO 的奖励方差通常比单轮任务大得多,设计更平滑的多轮奖励函数是另一个重要方向。
记忆进化。 从被动知识缓冲转向动态预测性用户模型(预见需求、主动获取信息)、从扁平向量存储转向知识图谱等结构化表示(支持双时态建模和连续流式处理)、将记忆管理建模为 RL 决策问题(同时优化"搜索什么"和"记住什么")。REDSearcher 的 Discard-all 策略虽然简单有效(BrowseComp +15.3),但在证据高度分散或搜索路径不可重复的场景中代价极高。将上下文管理建模为可训练动作(而非硬编码规则)是一个尚未被充分探索的方向。
评估瓶颈。 现有基准在三个方面存在系统性不足:逻辑评估(现有基准局限于符号逻辑谜题或短句蕴含,无法评估长文本中的论证一致性,需要设计多粒度——句子/段落/文档级——的连贯性评估框架)、新颖性与幻觉的边界(看似原创的输出可能嵌入不可验证的声明,需区分生成性新颖和推导性新颖并结合验证机制)、LLM-as-Judge 的偏见(可能偏好更长的回复或与自身相似的系统,需通过人类校准和去偏训练缓解)。
模拟与真实环境的分布偏移。 REDSearcher 展示了模拟环境在加速 RL 训练上的巨大价值,但真实网络中的动态内容更新、反爬机制、搜索引擎排序漂移等现象是模拟环境无法覆盖的。更深层的问题是:URL 混淆虽然防止了模式偏见,但模拟环境中文档的语言分布、主题覆盖和噪声类型仍然由 Wikipedia + Web Crawl 决定——这与真实搜索的长尾分布存在系统性差异。量化这种 sim-to-real gap,并设计自动校准机制(如从少量真实交互中估计分布偏移并调整模拟环境参数),是使模拟训练从"可用"走向"可靠"的关键一步。
本节总结。 Deep Research 代表了 LLM 从"会回答问题"到"会做研究"的范式跃迁。这个系统由四大核心组件(查询规划、信息获取、记忆管理、答案生成)构成闭环工作流,框架从 ReAct 单 Agent 演进到多 Agent 协作,奖励设计从单结果信号走向双层信用分配,训练数据从简单 QA 升级为多步骤研究轨迹。REDSearcher 以 Treewidth 驱动的任务合成和四阶段训练流水线,证明了 30B-A3B 规模的开源模型可以匹配甚至超越百B级闭源系统。当前的核心瓶颈在于训练稳定性、记忆进化和评估体系——这些问题的解决将决定 DR 能否从 Phase II 的集成研究迈向 Phase III 的全栈 AI 科学家。