14.4 高级蒸馏方法
在前面的章节中,我们介绍了黑盒蒸馏(基于教师输出文本的 SFT)和白盒蒸馏(基于正向 KL 散度对齐教师 logits)。这两种方法虽然广泛使用,但都存在一个共同的根本性问题:训练-推理分布不匹配(Distribution Mismatch)。标准蒸馏中,学生模型在训练时看到的序列来自教师模型或训练集的固定分布,但在推理时必须基于自身生成的 token 继续生成——这种差距会导致错误累积,即暴露偏差(Exposure Bias)。
本节将深入讨论两种针对性的解决方案:GKD(Generalized Knowledge Distillation,广义知识蒸馏) 通过在策略数据(On-policy Data)上训练来弥合分布差距;MiniLLM 则通过反向 KL 散度(Reverse KLD)防止学生模型在教师分布的低概率区域浪费容量。这两种方法代表了蒸馏损失函数设计的两个不同方向,理解它们的原理将帮助读者在实践中做出更明智的选择。
14.4.1 分布不匹配问题
在标准的白盒蒸馏中,训练数据的来源通常是固定数据集或教师模型生成的序列。设教师模型的分布为
问题的根源在于:训练时学生看到的上文来自
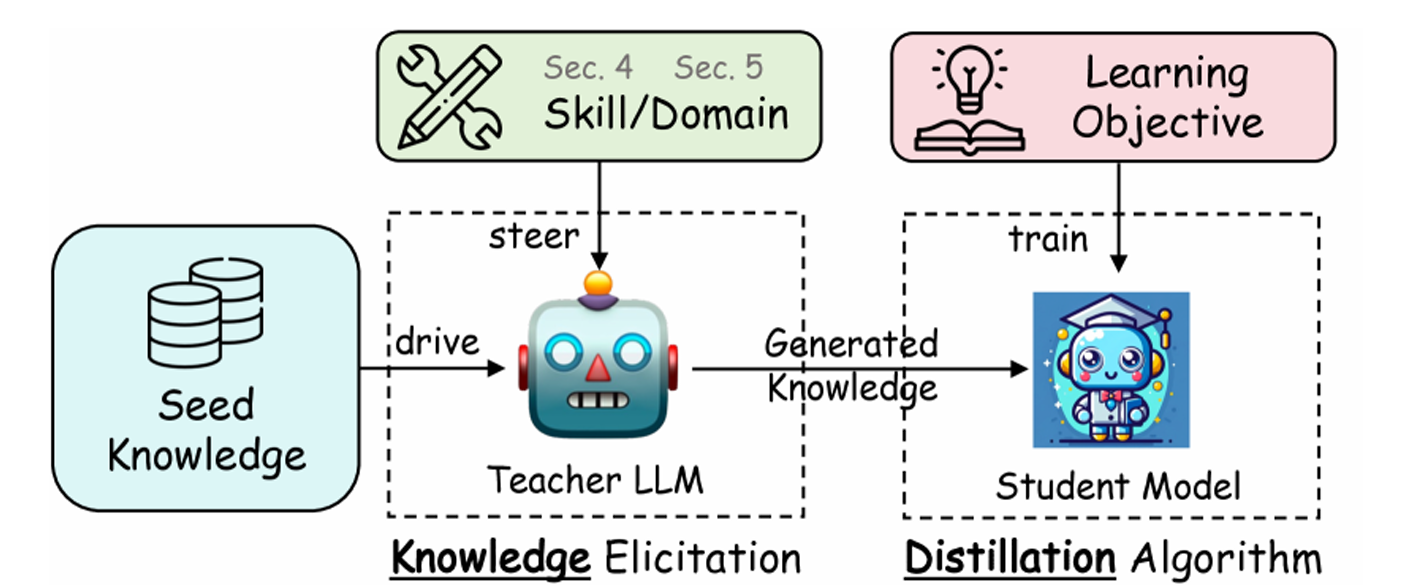
图 14-5:知识蒸馏的四阶段流程——在标准蒸馏中,学生训练使用教师提供的序列(Off-policy),而推理时必须使用自身的输出(On-policy),这种分布差距导致暴露偏差。
用一个简单的类比来理解:这就好比一个学生在考试前只做了标准答案的模拟题(Off-policy 训练),但从未做过自己写的答案的纠错练习(On-policy 训练)。当考试时写出一步有偏差的推导后,后续推理会越走越偏,因为在训练中从未遇到过这种"从错误出发"的情境。
这一问题在开放式文本生成(如对话、推理、创作)中尤为严重,因为序列越长,累积的分布偏移就越大。GKD 和 MiniLLM 分别从数据来源和损失函数方向两个角度提出了系统性的解决方案。
14.4.2 GKD:广义知识蒸馏
GKD(Generalized Knowledge Distillation) 由 Agarwal 等人在论文《On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes》中提出。其核心思想可以归纳为两点:
- On-policy 训练:让学生模型自己生成输出序列,然后在这些自生成序列上计算教师的反馈损失,从而直接在学生的分布上学习
- 广义 Jensen-Shannon 散度(Generalized JSD):用参数
在正向 KL 和反向 KL 之间平滑插值,提供了一个统一的损失函数框架
On-policy 数据为什么重要? 在传统蒸馏中,学生在固定数据上学到了"如果上文是 X,下一个 token 应该像教师那样输出 Y"。但如果学生推理时生成了 X'(而非 X),它就进入了训练中未见过的区域。GKD 的解决方案是:让学生先生成完整序列,然后让教师在学生序列上提供 token 级的概率反馈。这样学生不仅学到了"正确的上文该怎么续写",还学到了"如果写错了该如何修正"。
广义 JSD 损失函数。 GKD 定义了一个参数化的散度度量,将正向 KL 和反向 KL 统一到同一个框架中。给定教师的 token 级概率分布
其中
| 行为 | 等价损失 | |
|---|---|---|
| 退化为正向 KL 散度 | ||
| 退化为反向 KL 散度 | ||
| 标准 Jensen-Shannon 散度 | 对称的分布距离度量 |
这种参数化的好处在于:不同任务可能适合不同的损失方向。分类和短文本任务中,正向 KL(
:完全使用固定数据集的序列(Off-policy),退化为标准蒸馏 :完全使用学生自己生成的序列(On-policy) :以概率 使用学生生成数据,以概率 使用固定数据
论文实验表明,较高的
以下代码展示了 GKD 中广义 JSD 损失的完整实现:
import torch
import torch.nn.functional as F
def generalized_jsd_loss(student_logits, teacher_logits, labels=None,
beta=0.5, temperature=1.0):
"""
计算广义 Jensen-Shannon 散度损失。
Args:
student_logits: 学生模型输出, shape [batch, seq_len, vocab_size]
teacher_logits: 教师模型输出, shape [batch, seq_len, vocab_size]
labels: 标签, shape [batch, seq_len], -100 表示忽略位置
beta: JSD 插值系数, 0=正向KL, 1=反向KL, 0.5=标准JSD
temperature: 温度缩放参数
Returns:
标量损失值
"""
# 温度缩放
student_logits = student_logits / temperature
teacher_logits = teacher_logits / temperature
# 计算对数概率
student_log_probs = F.log_softmax(student_logits, dim=-1)
teacher_log_probs = F.log_softmax(teacher_logits, dim=-1)
if beta == 0:
# 退化为正向 KL: D_KL(teacher || student)
jsd = F.kl_div(student_log_probs, teacher_log_probs,
reduction="none", log_target=True)
elif beta == 1:
# 退化为反向 KL: D_KL(student || teacher)
jsd = F.kl_div(teacher_log_probs, student_log_probs,
reduction="none", log_target=True)
else:
# 计算混合分布的对数概率: M = beta * p_T + (1-beta) * p_S
beta_t = torch.tensor(beta, dtype=student_log_probs.dtype,
device=student_log_probs.device)
mixture_log_probs = torch.logsumexp(
torch.stack([
student_log_probs + torch.log1p(-beta_t), # log((1-beta)*p_S)
teacher_log_probs + torch.log(beta_t) # log(beta*p_T)
]),
dim=0,
)
# 广义 JSD = beta * KL(p_T || M) + (1-beta) * KL(p_S || M)
kl_teacher = F.kl_div(mixture_log_probs, teacher_log_probs,
reduction="none", log_target=True)
kl_student = F.kl_div(mixture_log_probs, student_log_probs,
reduction="none", log_target=True)
jsd = beta * kl_teacher + (1 - beta) * kl_student
# 应用标签掩码
if labels is not None:
mask = labels != -100
jsd = jsd[mask]
return jsd.sum() / mask.sum()
else:
return jsd.sum() / jsd.size(0)代码解读要点:
- 混合分布
的计算在对数空间中完成( torch.logsumexp),避免了直接指数运算的数值溢出问题 - 当
或 时,直接退化为标准 KL 散度,无需计算混合分布 log_target=True表示F.kl_div的第二个参数是对数概率,这在数值上比传递概率更稳定
14.4.3 GKD 的 On-policy 训练流程
理解了损失函数后,我们来看 GKD 完整的训练步骤。每个训练步骤的流程如下:
- 数据选择:以概率
决定使用学生自生成数据还是固定数据集。如果选择 on-policy,先用学生模型对当前 batch 的提示生成完整回答 - 教师反馈:无论数据来源如何,都用教师模型在选定的序列上进行前向传播,获取 token 级的概率分布
- 损失计算:用广义 JSD 损失比较学生和教师在每个 token 位置上的分布差异
- 参数更新:反向传播更新学生模型
以下代码展示了一个简化的 GKD 训练步骤:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import random
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
def gkd_training_step(student_model, teacher_model, batch, tokenizer,
lmbda=0.5, beta=0.5, temperature=0.9):
"""
GKD 的单步训练逻辑。
Args:
student_model: 学生模型(训练中)
teacher_model: 教师模型(冻结参数)
batch: 包含 input_ids, attention_mask, labels, prompts 的字典
tokenizer: 分词器
lmbda: On-policy 数据使用概率
beta: JSD 插值系数
temperature: 生成和损失计算的温度
"""
# 步骤 1: 以概率 lmbda 使用学生自生成数据
if random.random() <= lmbda:
# 让学生模型基于提示生成新序列
gen_config = GenerationConfig(
max_new_tokens=128, temperature=temperature,
do_sample=True, pad_token_id=tokenizer.pad_token_id,
)
with torch.no_grad():
student_model.eval()
generated = student_model.generate(
input_ids=batch["prompts"],
generation_config=gen_config,
)
student_model.train()
# 更新 batch 为学生自生成的序列
batch["input_ids"] = generated
batch["attention_mask"] = (generated != tokenizer.pad_token_id).long()
batch["labels"] = generated.clone()
batch["labels"][generated == tokenizer.pad_token_id] = -100
# 步骤 2: 教师前向(无梯度)
teacher_model.eval()
with torch.no_grad():
teacher_outputs = teacher_model(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
)
# 步骤 3: 学生前向
student_outputs = student_model(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
)
# 只在回答部分计算损失(去掉提示部分的 logits)
prompt_len = batch["prompts"].shape[1]
student_logits = student_outputs.logits[:, prompt_len - 1:-1, :]
teacher_logits = teacher_outputs.logits[:, prompt_len - 1:-1, :]
shifted_labels = batch["labels"][:, prompt_len:]
# 步骤 4: 计算广义 JSD 损失
loss = generalized_jsd_loss(
student_logits=student_logits,
teacher_logits=teacher_logits,
labels=shifted_labels,
beta=beta,
temperature=temperature,
)
return loss关键设计决策:
- 在 on-policy 生成时,学生模型临时切换到
eval()模式以使用正常的采样策略,生成完毕后切回train()模式 - 教师模型始终在
eval()模式下运行,且使用torch.no_grad()节省显存 - 损失只在回答部分计算,通过 shifted_labels 中的 -100 掩码实现
14.4.4 使用 TRL 库实现 GKD
在实际项目中,可以直接使用 Hugging Face TRL 库的 GKDTrainer 来完成 GKD 训练,无需从零实现上述逻辑。以下是一个完整的使用示例:
from datasets import Dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl.experimental.gkd import GKDConfig, GKDTrainer
# 加载教师和学生模型
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
student_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
teacher_model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-1.5B-Instruct")
# 准备训练数据(ChatML 格式)
train_dataset = Dataset.from_dict({
"messages": [
[
{"role": "user", "content": "什么是知识蒸馏?"},
{"role": "assistant", "content": "知识蒸馏是一种模型压缩技术..."},
]
] * 1000 # 实际应使用真实数据
})
# 配置 GKD 训练参数
training_args = GKDConfig(
output_dir="gkd-distilled-model",
per_device_train_batch_size=2,
num_train_epochs=3,
learning_rate=5e-5,
# GKD 特有参数
lmbda=0.5, # 50% 概率使用学生自生成数据
beta=0.5, # 使用标准 JSD(正向 KL 和反向 KL 的对称混合)
temperature=0.9, # 生成和损失计算的温度
max_new_tokens=128,
seq_kd=False, # 不使用序列级蒸馏
)
# 创建 Trainer 并开始训练
trainer = GKDTrainer(
model=student_model,
teacher_model=teacher_model,
args=training_args,
processing_class=tokenizer,
train_dataset=train_dataset,
)
trainer.train()GKDConfig 关键参数说明:
| 参数 | 默认值 | 含义 |
|---|---|---|
lmbda | 0.5 | On-policy 数据比例,0=纯 off-policy,1=纯 on-policy |
beta | 0.5 | JSD 插值系数,0=正向 KL,1=反向 KL |
temperature | 0.9 | 同时用于生成采样和损失计算的温度 |
max_new_tokens | 128 | On-policy 生成时的最大 token 数 |
seq_kd | False | 是否使用序列级蒸馏(教师生成序列作为目标) |
disable_dropout | True | 是否关闭学生模型的 Dropout |
当 seq_kd=True 且 lmbda=0 时,GKD 退化为序列级蒸馏——教师先生成完整序列,然后学生在教师序列上接收 token 级的 JSD 反馈。这可以看作是黑盒蒸馏(SFT)和白盒蒸馏(KL 对齐)的中间形态。
14.4.5 MiniLLM:反向 KL 散度蒸馏
MiniLLM 由 Gu 等人在论文《Knowledge Distillation of Large Language Models》中提出,它从损失函数的方向性入手来解决蒸馏质量问题。MiniLLM 的核心洞察是:在开放式文本生成任务中,标准的正向 KL 散度
正向 KL vs 反向 KL 的直觉。 想象教师的输出分布是一座有多个山峰的地形图——有几个主要的高峰(高概率的优质回答)和大量的低矮丘陵(低概率的边缘回答):
- 正向 KL(Mode-covering):要求学生的分布必须覆盖教师所有的山峰和丘陵。学生被迫在低概率区域分配概率质量,导致高概率区域的精度下降
- 反向 KL(Mode-seeking):允许学生只聚焦教师最高的几个山峰,忽略低矮的丘陵。学生在主要模式上的拟合更精确,但可能丢失多样性
MiniLLM 选择反向 KL 散度
注意,这里的期望是在学生分布

图 14-6:MiniLLM 蒸馏算法流程——学生从自身分布采样序列,计算反向 KL 散度作为优化目标,结合单步分解和长度归一化策略提升训练稳定性。
为什么反向 KL 需要策略梯度? 与正向 KL 不同,反向 KL 的梯度需要从学生分布采样(因为期望在
14.4.6 MiniLLM 的三项稳定训练策略
直接用策略梯度优化反向 KL 会面临高方差、奖励作弊和长度偏差等问题。MiniLLM 引入了三项关键的稳定化技术:
1. 单步分解(Single-step Decomposition)。 将多步序列的反向 KL 分解为逐 token 的精确期望计算,而非使用整个序列的蒙特卡洛估计。这大幅降低了梯度估计的方差。具体来说,每一步的 KL 散度可以在给定上文的条件下精确计算(对整个词表求和),无需采样。对应的损失项为:
2. 教师混合采样(Teacher-mixed Sampling)。 如果学生模型只在自身生成的(可能低质量的)序列上训练,可能会出现"奖励作弊"——学生找到一些教师分布中也很低概率但奖励恰好较高的退化序列。为缓解这一问题,MiniLLM 在学生采样的序列中混入教师生成的序列,确保训练数据覆盖高质量区域。
3. 长度归一化(Length Normalization)。 反向 KL 是在整个序列上累加的,这使得模型倾向于生成短序列(短序列的总 KL 值更小)。长度归一化通过对每个位置的 advantage 按折扣后的有效长度做除法,消除了这种长度偏差:
其中
以下代码展示了 MiniLLM 中 advantage 计算和单步分解损失的核心实现:
import torch
import torch.nn.functional as F
def compute_rkl_advantage(student_log_probs_on_labels,
teacher_log_probs_on_labels,
mask, gamma=0.0, length_normalization=True):
"""
计算反向 KL 的 advantage(优势值)。
Args:
student_log_probs_on_labels: 学生在标签上的对数概率 [batch, seq_len]
teacher_log_probs_on_labels: 教师在标签上的对数概率 [batch, seq_len]
mask: 有效位置掩码 [batch, seq_len]
gamma: 折扣因子, 0 表示不使用时序折扣
length_normalization: 是否进行长度归一化
Returns:
advantages: [batch, seq_len]
"""
mask = mask.float()
response_length = student_log_probs_on_labels.size(1)
# 即时奖励 = 教师对数概率 - 学生对数概率
rewards = (teacher_log_probs_on_labels - student_log_probs_on_labels) * mask
if gamma > 0.0:
# 构造折扣因子序列 [gamma^0, gamma^1, ..., gamma^(T-1)]
gamma_pow = torch.pow(gamma, torch.arange(
response_length, device=rewards.device
))
# 加权奖励
advantages = rewards * gamma_pow
# 从后向前累积求和(等价于计算折扣回报)
advantages = advantages.flip(1).cumsum(dim=1).flip(1)
if length_normalization:
# 计算有效折扣长度
safe_mask = torch.where(mask < 0.5, 1e-4, mask)
lengths = safe_mask * gamma_pow
lengths = lengths.flip(1).cumsum(dim=1).flip(1)
advantages = advantages / lengths
else:
advantages = rewards
return advantages
def single_step_decomposition_loss(student_log_probs, teacher_log_probs, mask):
"""
单步分解的反向 KL 损失。
在每个位置精确计算分布级 KL,而非仅使用 token 级采样。
Args:
student_log_probs: 学生的全分布对数概率 [batch, seq_len, vocab_size]
teacher_log_probs: 教师的全分布对数概率 [batch, seq_len, vocab_size]
mask: 有效位置掩码 [batch, seq_len]
"""
# 反向 KL: KL(p_S || p_T) = sum p_S * (log p_S - log p_T)
kl = F.kl_div(
teacher_log_probs, student_log_probs,
reduction="none", log_target=True
) # [batch, seq_len, vocab_size] -> sum over vocab -> [batch, seq_len]
if mask is not None:
kl = kl[mask]
return kl.sum() / mask.sum()
return kl.mean()14.4.7 MiniLLM 实验效果
MiniLLM 在多个模型族和参数规模上进行了系统评估,结果清晰地展示了反向 KL 蒸馏相比标准正向 KL 蒸馏的优势。
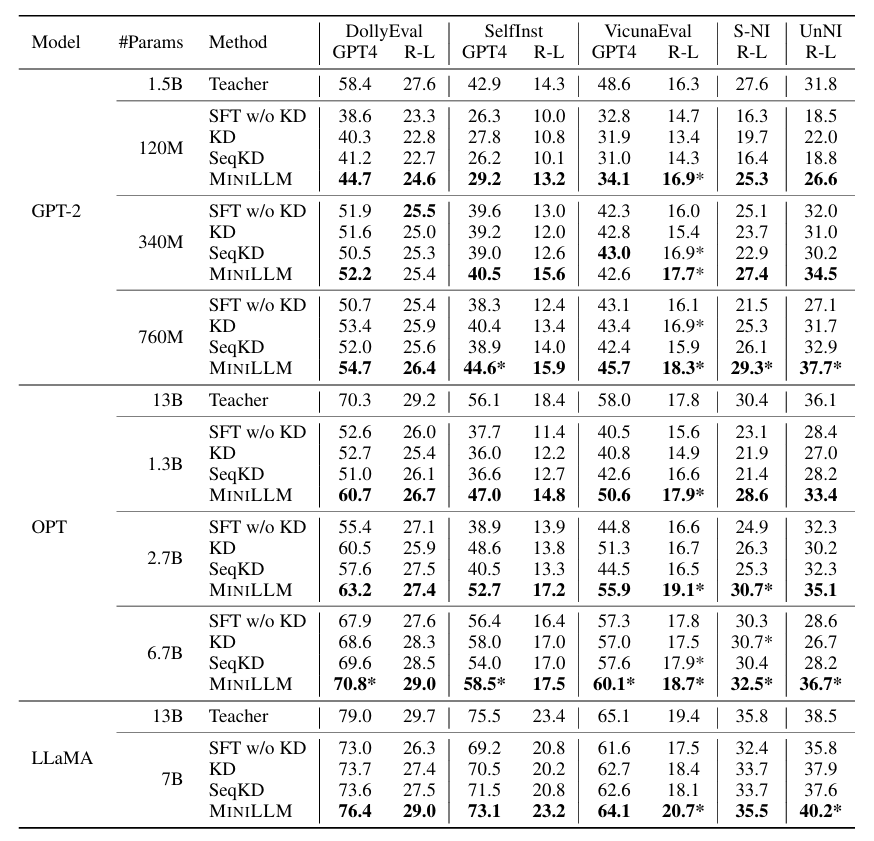
表 14-3:MiniLLM 与基线方法在指令遵循任务上的对比。GPT4 为 GPT-4 的平均偏好评分,R-L 为 Rouge-L 分数。MiniLLM 在多个规模和模型族下均显著优于标准 KD 和 SeqKD 方法。
关键实验发现:
- 生成质量显著提升:在 Rouge-L 和 GPT-4 偏好评估中,MiniLLM 一致优于标准 KD(正向 KL)和 SeqKD(序列级蒸馏),且在部分规模下学生模型的表现甚至超越了教师模型
- 暴露偏差有效缓解:在长文本生成场景下,MiniLLM 的累积超额错误(ExAccErr)显著低于标准 KD,且在超过 150 token 后误差停止累积
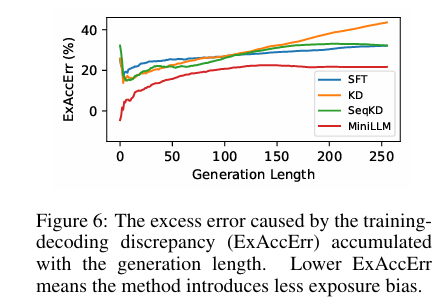
图 14-7:训练-解码差异导致的累积超额错误随生成长度的变化。MiniLLM(反向 KL)的误差增长远慢于标准 KD(正向 KL),在长序列中优势尤为明显。
- 多样性未受损:反向 KL 的 mode-seeking 特性并未导致明显的模式坍缩。Distinct-4 指标(衡量生成多样性)显示,MiniLLM 与基线方法相近,说明学生既保持了生成质量也维持了基本的多样性
- 概率校准更优:在 SST2 和 BoolQ 数据集上,MiniLLM 的预期校准误差(ECE)显著低于基线,准确率也更高
14.4.8 使用 TRL 库实现 MiniLLM
TRL 库同样提供了 MiniLLMTrainer,它基于 GRPO 框架实现了 MiniLLM 的训练逻辑。以下是一个使用示例:
from datasets import load_dataset
from trl.experimental.minillm import MiniLLMConfig, MiniLLMTrainer
# 加载数据集(需要包含 "prompt" 列)
dataset = load_dataset("trl-lib/tldr", split="train")
# 配置 MiniLLM 训练
training_args = MiniLLMConfig(
output_dir="minillm-distilled",
per_device_train_batch_size=2,
num_train_epochs=3,
learning_rate=5e-6,
# MiniLLM 特有参数
rkl_advantage=True, # 使用反向 KL advantage
single_step_decomposition=True, # 启用单步分解降低方差
kd_temperature=1.0, # 蒸馏温度
gamma=0.0, # 折扣因子(0=不折扣)
length_normalization=True, # 启用长度归一化
num_generations=1, # 每个提示生成 1 个序列
)
# 创建 Trainer
trainer = MiniLLMTrainer(
model="Qwen/Qwen3-0.6B",
teacher_model="Qwen/Qwen3-1.7B",
args=training_args,
train_dataset=dataset,
)
trainer.train()MiniLLMConfig 关键参数说明:
| 参数 | 默认值 | 含义 |
|---|---|---|
rkl_advantage | True | 是否使用反向 KL advantage 增强奖励 |
single_step_decomposition | True | 是否使用单步分解损失(降低方差) |
kd_temperature | 1.0 | 蒸馏温度 |
gamma | 0.0 | advantage 的时序折扣因子 |
length_normalization | True | 是否对 advantage 做长度归一化 |
MiniLLM 与 GKD 的关系。 MiniLLMTrainer 的文档指出,当设置 rkl_advantage=False 且 single_step_decomposition=True 时,MiniLLM 的损失退化为 GKD 在
14.4.9 GKD 与 MiniLLM 的对比
两种方法从不同角度解决蒸馏中的核心问题,下表给出了系统性的对比:
| 维度 | GKD | MiniLLM |
|---|---|---|
| 核心思想 | On-policy 训练 + 灵活的散度度量 | 反向 KL 防止低概率过度估计 |
| 损失函数 | 广义 JSD( | 反向 KL + 策略梯度 advantage |
| 数据来源 | 天然 on-policy(从 | |
| 训练框架 | 基于 SFTTrainer | 基于 GRPOTrainer(RL 框架) |
| 实现复杂度 | 较低(只需额外的生成步骤) | 较高(需要策略梯度 + advantage 估计) |
| 训练成本 | 中等(on-policy 生成增加开销) | 较高(RL 训练通常更慢) |
| 适用场景 | 通用蒸馏,灵活调节 | 开放式长文本生成 |
| 与 RL 的结合 | 可无缝集成 RLHF | 本身即 RL 框架 |
选择建议:
- 如果目标是通用蒸馏(分类、短文本生成、指令遵循),推荐从 GKD 开始,
(标准 JSD)是一个稳健的起点 - 如果目标是开放式长文本生成(对话、创作、推理),且愿意承担更高的训练成本,MiniLLM 的反向 KL 能带来更好的生成质量
- 如果训练资源有限,GKD 的
lmbda=0(纯 off-policy)配置与标准白盒蒸馏成本相当,但通过 JSD 损失仍可获得一定改进 - 两者都可以与 RLHF 结合——GKD 的论文明确指出其设计兼容 RL 微调
14.4.10 正向 KL 与反向 KL 的代码对比
为了加深理解,以下代码并排展示了正向 KL 和反向 KL 蒸馏损失的计算方式及其行为差异:
import torch
import torch.nn.functional as F
def compare_kl_directions(teacher_logits, student_logits, temperature=4.0):
"""
对比正向 KL 和反向 KL 在同一组 logits 上的行为。
"""
T = temperature
teacher_probs = F.softmax(teacher_logits / T, dim=-1)
student_probs = F.softmax(student_logits / T, dim=-1)
teacher_log_probs = F.log_softmax(teacher_logits / T, dim=-1)
student_log_probs = F.log_softmax(student_logits / T, dim=-1)
# 正向 KL: D_KL(p_teacher || p_student)
# 学生被迫覆盖教师的所有模式(mode-covering)
forward_kl = F.kl_div(student_log_probs, teacher_probs,
reduction="batchmean") * (T ** 2)
# 反向 KL: D_KL(p_student || p_teacher)
# 学生只聚焦教师的高概率模式(mode-seeking)
reverse_kl = F.kl_div(teacher_log_probs, student_probs,
reduction="batchmean") * (T ** 2)
return forward_kl, reverse_kl
# 模拟场景:教师有多个模式,学生容量有限
torch.manual_seed(42)
# 教师分布:两个明显的模式(位置 0 和位置 3 概率较高)
teacher_logits = torch.tensor([[5.0, 1.0, 0.5, 4.5, 0.1, -1.0, -2.0, -3.0]])
# 学生初始分布:较为均匀
student_logits = torch.tensor([[2.0, 1.5, 1.0, 0.5, 0.3, 0.1, -0.5, -1.0]])
fwd_kl, rev_kl = compare_kl_directions(teacher_logits, student_logits)
print(f"正向 KL (mode-covering): {fwd_kl.item():.4f}")
print(f"反向 KL (mode-seeking): {rev_kl.item():.4f}")
# 正向 KL 对低概率区域的偏差更敏感
# 反向 KL 对高概率区域的偏差更敏感14.4.11 小结
本节介绍了两种针对标准蒸馏局限性的高级方法。GKD 通过 on-policy 训练解决了分布不匹配问题,并用广义 JSD 提供了正向 KL 到反向 KL 之间的连续调节能力。MiniLLM 则从损失函数的方向性出发,用反向 KL 避免学生在教师的低概率长尾区域浪费容量,并通过单步分解、教师混合采样、长度归一化三项技术确保训练稳定。两者的共同启示是:蒸馏的效果不仅取决于数据质量(第 14.1 节的核心观点),也取决于训练时学生"看到的是什么数据"(on-policy vs off-policy)以及"优化的是哪个方向的差距"(正向 KL vs 反向 KL)。在实践中,TRL 库的 GKDTrainer 和 MiniLLMTrainer 提供了开箱即用的实现,读者可以根据任务特点和资源约束选择合适的方案。