12.4 SFT 工程实践
前几节讨论了微调的理论基础、分类微调方法和指令微调的原理。本节将目光转向工程实践:如何使用成熟的工具框架高效地完成一次 SFT 训练,从数据集格式的选择与构造,到训练器的配置与序列打包优化,再到损失掩码的精确控制——这些"最后一公里"的工程细节,往往决定了微调效果的上限。
12.4.1 SFT 数据集格式
SFT 训练的第一步,也是最关键的一步,是准备格式正确的数据集。不同的框架对数据格式有不同要求,但 HuggingFace TRL 库已成为事实上的行业标准,其 SFTTrainer 支持的数据格式可以从两个维度来理解:格式(Format) 和 类型(Type)。
格式指数据的结构形式,分为**标准格式(Standard)和对话格式(Conversational)**两种。标准格式使用纯文本字符串,对话格式则使用包含 role 和 content 字段的消息列表。
类型指数据对应的任务,SFT 主要使用两种类型:语言建模(Language Modeling) 和 提示-完成(Prompt-Completion)。
下面逐一介绍四种组合。
标准语言建模格式。最简单的格式,每条数据只有一个 text 字段,包含完整的文本序列。模型在整个序列上计算损失。
# 标准语言建模格式
{"text": "大语言模型通过自回归方式生成文本,每次预测下一个 token。"}对话语言建模格式。使用 messages 字段存储多轮对话,训练器会自动应用模型的 Chat Template(聊天模板)将对话转换为文本序列。
# 对话语言建模格式
{"messages": [
{"role": "system", "content": "你是一个有帮助的 AI 助手。"},
{"role": "user", "content": "什么是 SFT?"},
{"role": "assistant", "content": "SFT 即监督微调,是在标注数据上训练语言模型的方法。"}
]}标准提示-完成格式。将输入拆分为 prompt 和 completion 两个字段。默认情况下,训练器只在 completion 部分计算损失,这正是 SFT 中"只学回答、不学提问"的核心思想。
# 标准提示-完成格式
{"prompt": "请解释什么是梯度下降。",
"completion": "梯度下降是一种优化算法,通过沿损失函数梯度的反方向更新参数来最小化损失。"}对话提示-完成格式。将对话拆分为 prompt 部分(用户的提问)和 completion 部分(助手的回答),每部分都是消息列表。
# 对话提示-完成格式
{"prompt": [{"role": "user", "content": "请解释什么是梯度下降。"}],
"completion": [{"role": "assistant", "content": "梯度下降是一种优化算法..."}]}下表总结了 SFTTrainer 支持的数据格式矩阵:
| 类型 \ 格式 | 标准格式 | 对话格式 |
|---|---|---|
| 语言建模 | {"text": "..."} | {"messages": [{...}, ...]} |
| 提示-完成 | {"prompt": "...", "completion": "..."} | {"prompt": [{...}], "completion": [{...}]} |
表 12-4:SFT 数据格式矩阵。
工具调用(Tool Calling)格式。现代 SFT 还需要训练模型使用外部工具的能力。在这种场景下,数据集需要额外的 tools 列来存放可用工具的 JSON Schema 定义,消息中可以包含 tool_calls 字段和 tool 角色的回复。
# 工具调用数据格式示例
{
"messages": [
{"role": "user", "content": "北京今天天气怎么样?"},
{"role": "assistant", "tool_calls": [
{"type": "function", "function": {
"name": "get_weather",
"arguments": {"city": "北京"}
}}
]},
{"role": "tool", "name": "get_weather",
"content": "北京今天晴,气温 25°C。"},
{"role": "assistant", "content": "北京今天是晴天,气温 25 度。"}
],
"tools": [{"type": "function", "function": {
"name": "get_weather",
"description": "查询指定城市的天气",
"parameters": {"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"]}
}}]
}数据格式的选择建议。如果你手上有现成的纯文本语料,使用标准语言建模格式最简单;如果你希望精确控制"只在回答部分计算损失",使用提示-完成格式;如果需要多轮对话能力,使用对话格式并让训练器自动应用 Chat Template。实践中,对话提示-完成格式是最常用的选择,因为它兼顾了结构化和损失控制的优点。
12.4.2 SFTTrainer 核心配置
TRL 的 SFTTrainer 封装了从数据预处理到训练循环的完整流程。下面通过一个完整示例展示其核心用法。
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
# 加载对话数据集
dataset = load_dataset("trl-lib/Capybara", split="train")
# 配置训练参数
training_args = SFTConfig(
output_dir="./sft_output", # 输出目录
max_length=2048, # 最大序列长度
per_device_train_batch_size=4, # 每卡 batch size
num_train_epochs=3, # 训练轮数
learning_rate=2e-5, # 学习率
gradient_checkpointing=True, # 梯度检查点(节省显存)
bf16=True, # 使用 bfloat16 混合精度
logging_steps=10, # 日志记录间隔
)
# 创建训练器并启动训练
trainer = SFTTrainer(
model="Qwen/Qwen3-0.6B", # 基座模型
args=training_args,
train_dataset=dataset,
)
trainer.train()上面的代码已经是一个可以工作的 SFT 训练脚本。SFTTrainer 会自动完成以下步骤:加载并初始化模型和 tokenizer,检测数据集格式并进行相应的预处理(如应用 Chat Template),将文本 tokenize 并截断到 max_length,然后启动标准的训练循环。
SFT 损失函数。SFT 使用的是标准的 Token 级交叉熵损失:
其中
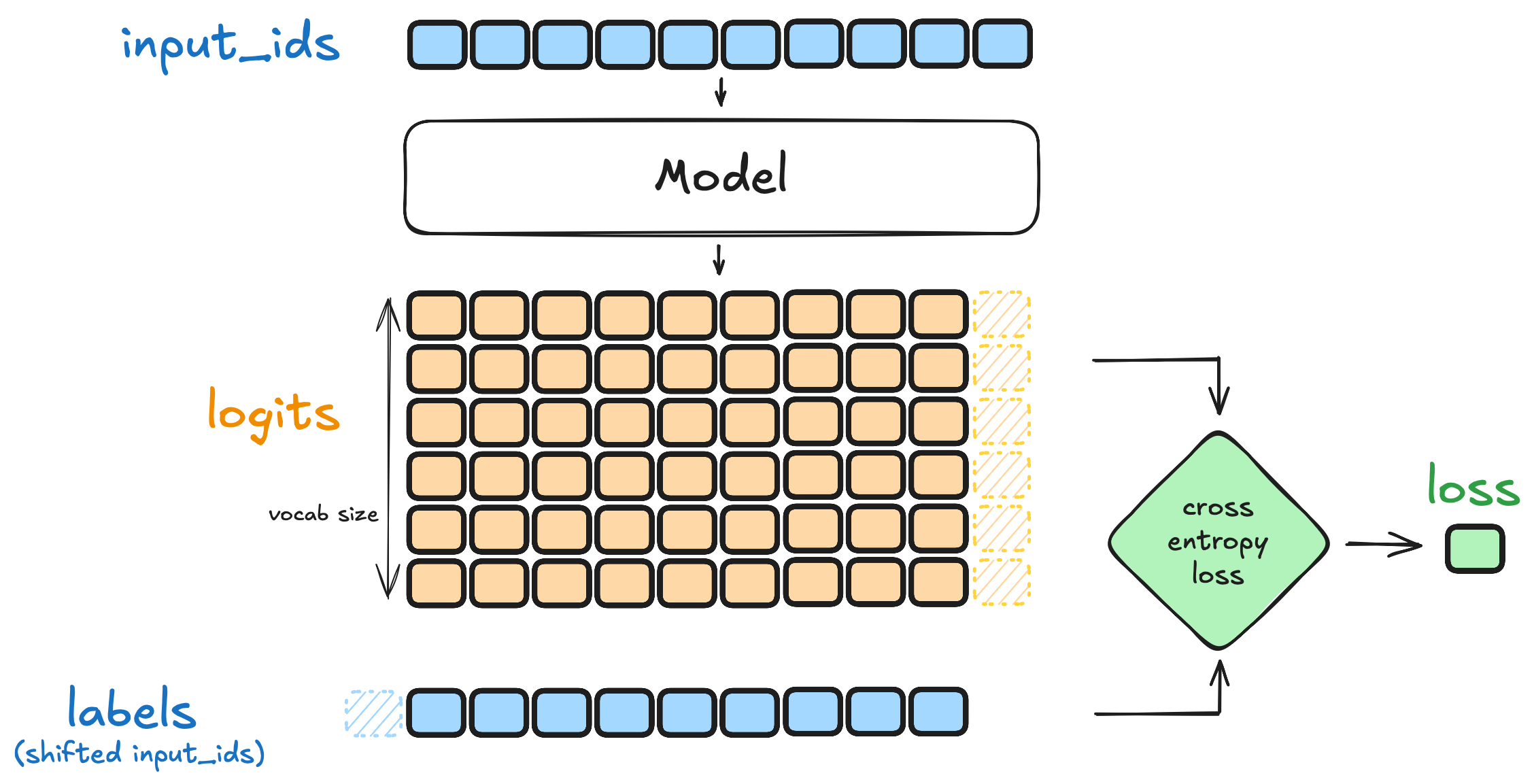
图 12-12:SFT 损失计算过程。输入序列右移一位形成标签,模型在每个位置预测下一个 token 的概率分布,通过交叉熵计算损失。
关键训练指标。训练过程中,SFTTrainer 会自动记录以下指标:
| 指标 | 含义 |
|---|---|
loss | 非 padding token 上的平均交叉熵损失 |
entropy | 模型预测分布的平均熵(衡量模型的不确定性) |
mean_token_accuracy | Top-1 预测准确率(预测正确的 token 占比) |
grad_norm | 梯度 L2 范数(裁剪前) |
learning_rate | 当前学习率 |
表 12-5:SFT 训练过程中的核心监控指标。
12.4.3 损失掩码:只学回答,不学提问
在 SFT 中,一个至关重要的工程细节是损失掩码(Loss Masking)。我们通常不希望模型学习"用户是怎么提问的"——那是预训练阶段的工作。SFT 的目标是让模型学会像专家一样回答问题,因此应当只在 assistant 回复部分计算损失。
提示-完成格式的自动掩码。当使用提示-完成格式的数据集时,SFTTrainer 默认只在 completion 部分计算损失。如果想在整个序列上计算损失,可以设置 completion_only_loss=False。
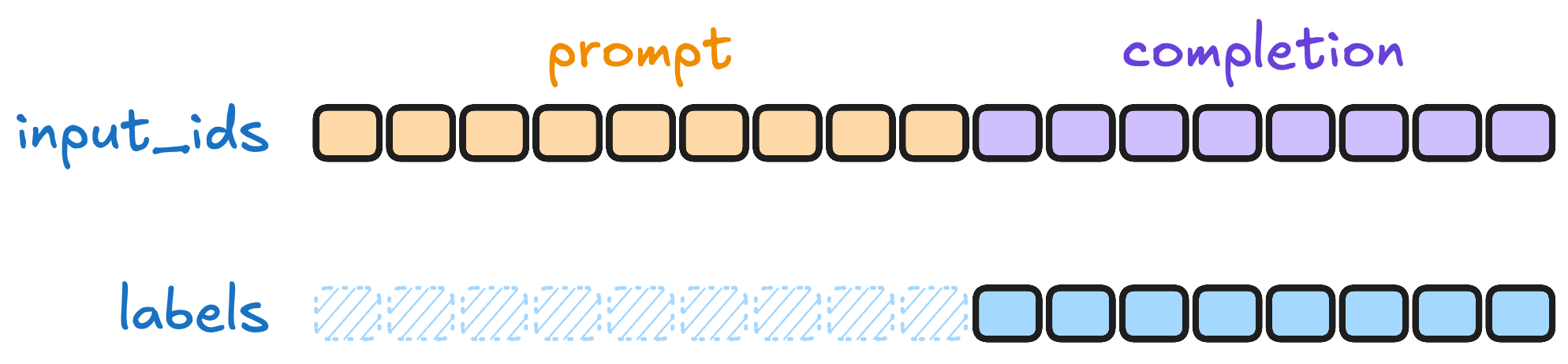
图 12-13:提示-完成格式下的损失掩码。灰色部分(prompt)不参与损失计算,只有彩色部分(completion)的 token 贡献损失。
对话格式的 assistant-only 模式。对于多轮对话数据,可以通过 assistant_only_loss=True 只在 assistant 消息上计算损失:
# 示意代码
training_args = SFTConfig(
assistant_only_loss=True, # 只在 assistant 消息上计算损失
# ... 其他参数
)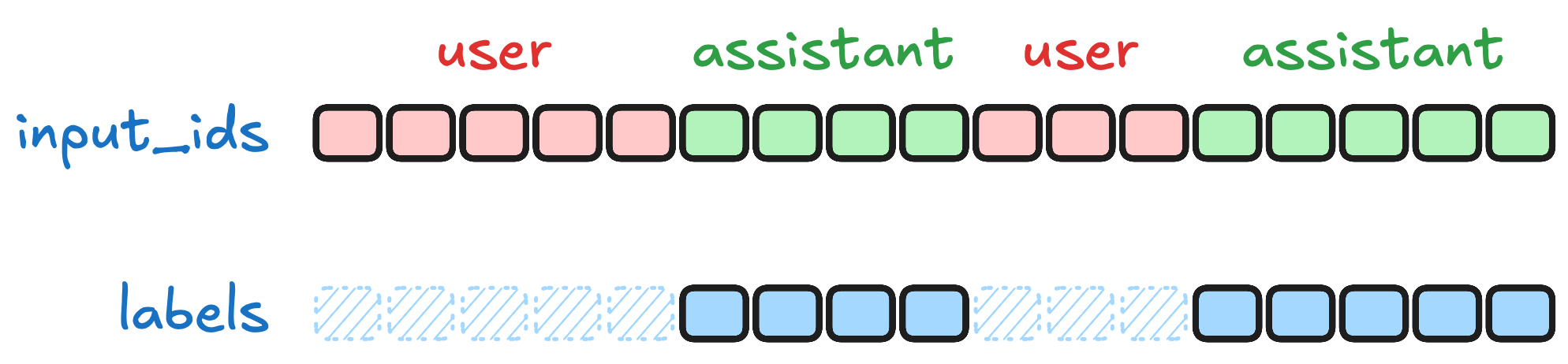
图 12-14:assistant_only_loss 模式。多轮对话中,system 和 user 消息被掩码,只有 assistant 的回复参与损失计算。
手工实现损失掩码的底层逻辑。理解底层实现有助于在自定义训练脚本中正确使用损失掩码。以一条单轮对话为例,假设 tokenizer 编码后的 ID 序列为:
input_ids: [<s>, user, 1+1=?, </s>, <s>, assistant, 2, </s>, pad, ...]
1 10 101.. 2 1 20 200 2 0构造过程分三步:(1)扫描标记——在序列中查找 <s>assistant 模式(如 [1, 20])定位回复起始位置;(2)标记范围——从 assistant 标记后的第一个内容 token 到 </s>(含),将 loss_mask 设为 1;(3)对齐标签——自回归训练采用 X = input_ids[:-1]、Y = input_ids[1:] 的右移构造,loss_mask 也取 [1:] 与 Y 对齐。
# 损失掩码构造的核心逻辑(简化版)
def generate_loss_mask(input_ids, bos_assistant_ids, eos_ids):
loss_mask = [0] * len(input_ids)
i = 0
while i < len(input_ids):
if input_ids[i:i+len(bos_assistant_ids)] == bos_assistant_ids:
start = i + len(bos_assistant_ids)
end = start
while end < len(input_ids):
if input_ids[end:end+len(eos_ids)] == eos_ids:
break
end += 1
for j in range(start, min(end + len(eos_ids), len(input_ids))):
loss_mask[j] = 1
i = end + len(eos_ids)
else:
i += 1
return loss_mask
# 最终训练数据
X = input_ids[:-1] # 模型输入
Y = input_ids[1:] # 预测目标
mask = loss_mask[1:] # 掩码与 Y 对齐
# 计算损失:loss = CrossEntropy(logits, Y) * mask这种掩码机制保证了模型只学习 assistant 的回复内容。对于多轮对话,扫描过程会自动定位每一轮 assistant 的回复并标记。
12.4.4 序列打包优化
SFT 训练中一个常见的效率瓶颈是padding 浪费。当 batch 内的序列长度差异很大时,短序列需要大量 padding 填充到最长序列的长度,这些 padding token 不贡献任何梯度,却占用了宝贵的计算资源和显存。
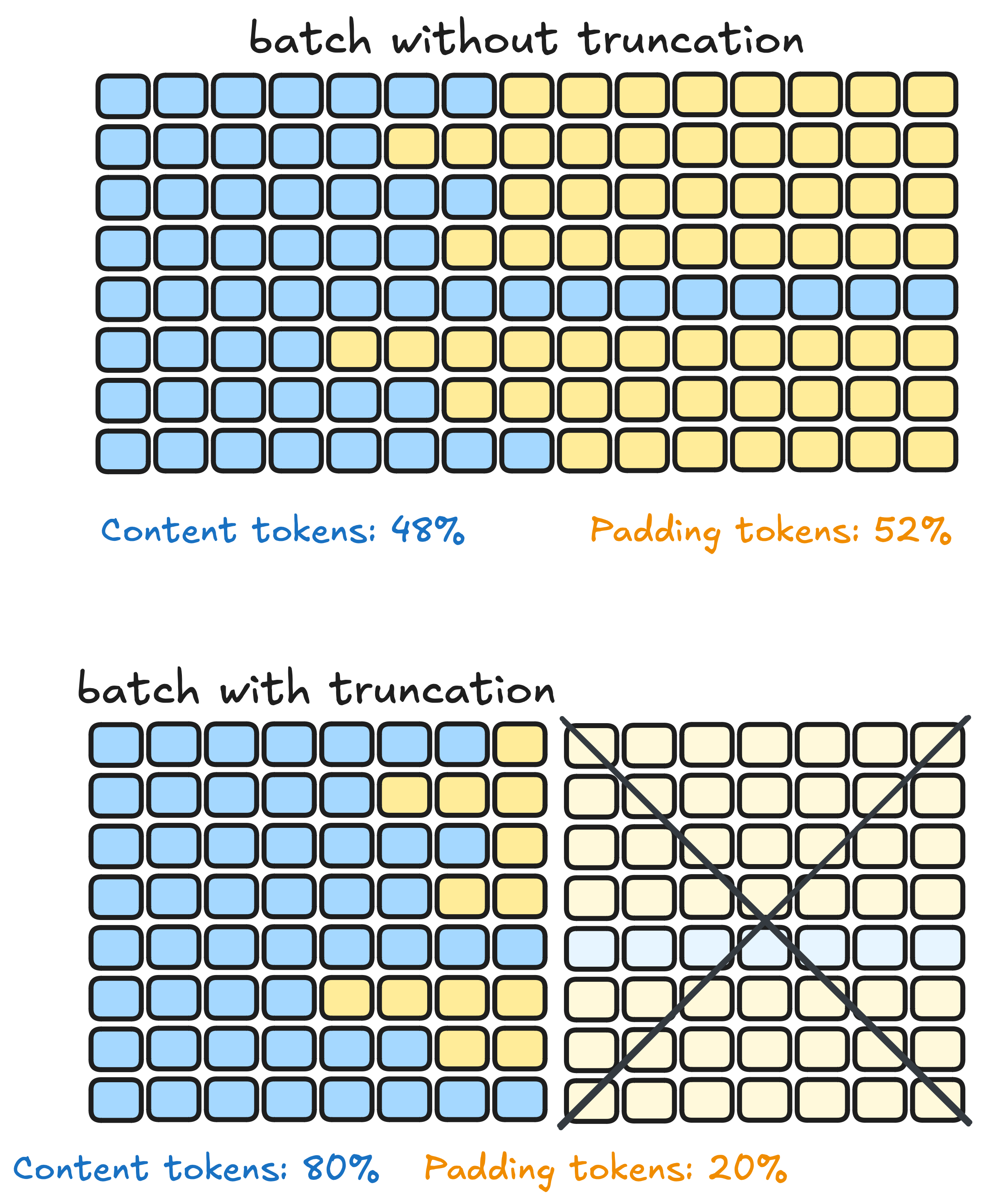
图 12-15:padding 浪费示意。batch 中的短序列需要大量 padding 来对齐最长序列,灰色区域代表无效计算。
**序列打包(Packing)**通过将多条短序列"打包"进同一个训练样本来解决这一问题。打包后每个训练行都被有效数据填满,padding 浪费大幅减少。
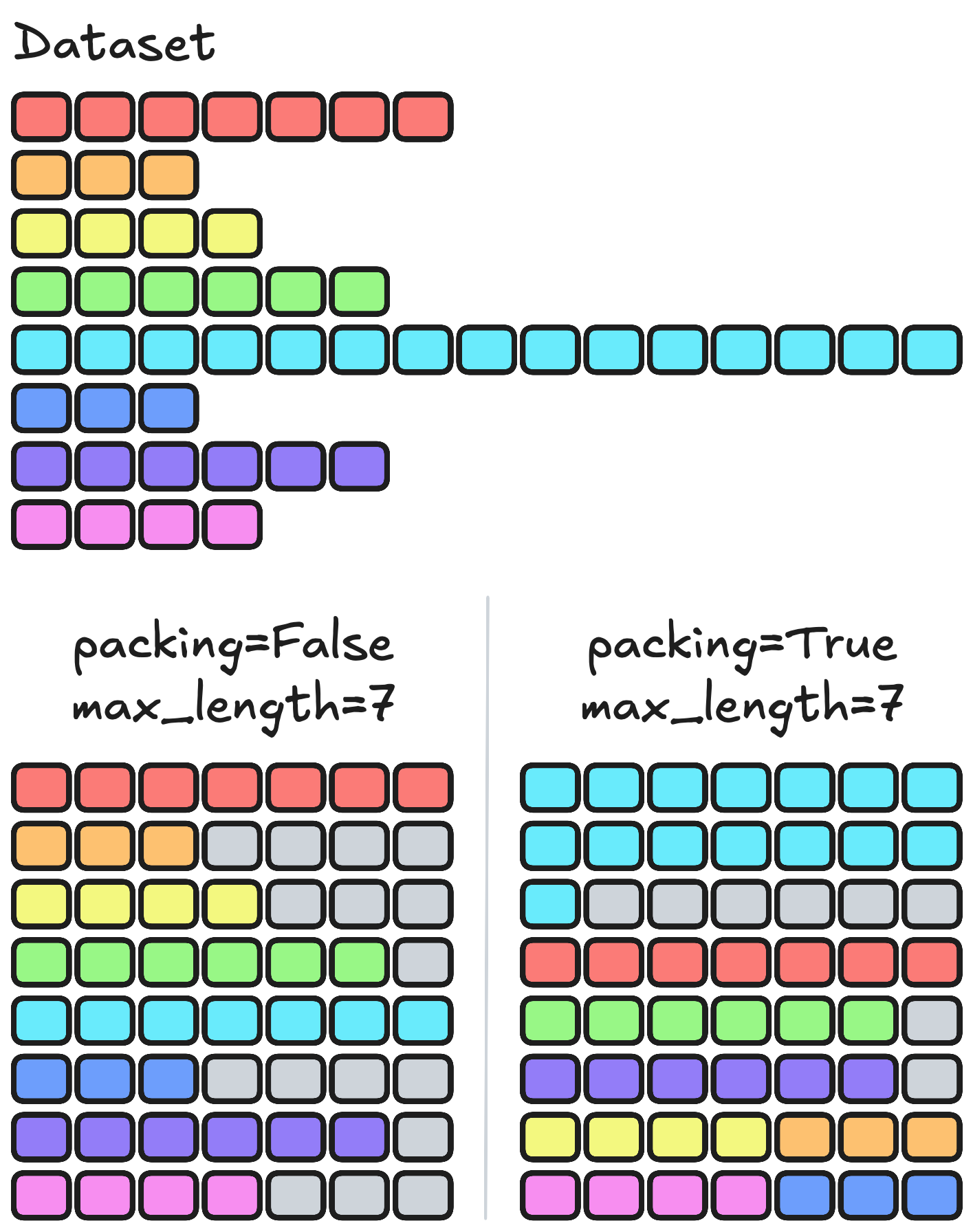
图 12-16:序列打包。多条短序列被拼接放入同一个训练行,显著减少 padding 浪费。
SFTTrainer 内置了打包支持,启用方式非常简单:
# 示意代码
training_args = SFTConfig(
packing=True, # 启用序列打包
packing_strategy="bfd", # 打包策略
max_length=2048, # 打包后的最大序列长度
)三种打包策略。TRL 支持三种打包策略,各有优劣:
| 策略 | 原理 | 优点 | 缺点 |
|---|---|---|---|
bfd(默认) | Best-Fit Decreasing 装箱算法,超长序列截断 | 实现简单,效果好 | 超长序列末尾被截断 |
bfd_split | 同上,但超长序列先切分再打包 | 保留所有 token,无信息丢失 | 切分点可能破坏语义连贯性 |
wrapped | 将所有 token 拼接成一条长流,再按固定长度切分 | padding 最少 | 不同样本的内容混在一起,可能损害性能 |
表 12-6:三种序列打包策略对比。
注意事项。打包要求使用 FlashAttention(或其变体),因为标准注意力机制无法区分打包在同一序列中的不同样本,可能导致"批次污染"——不同样本的 token 之间产生了不应存在的注意力交互。FlashAttention 通过 cu_seqlens(cumulative sequence lengths,累积序列长度)参数来标记每条样本的边界,从而在计算注意力时正确隔离不同样本。
Padding-Free 模式。另一种方案是将 batch 中所有序列展平为一条连续序列,同时记录边界信息。与打包不同,每条序列保持完整,不会截断或混合。同样需要 FlashAttention 来正确隔离注意力计算。
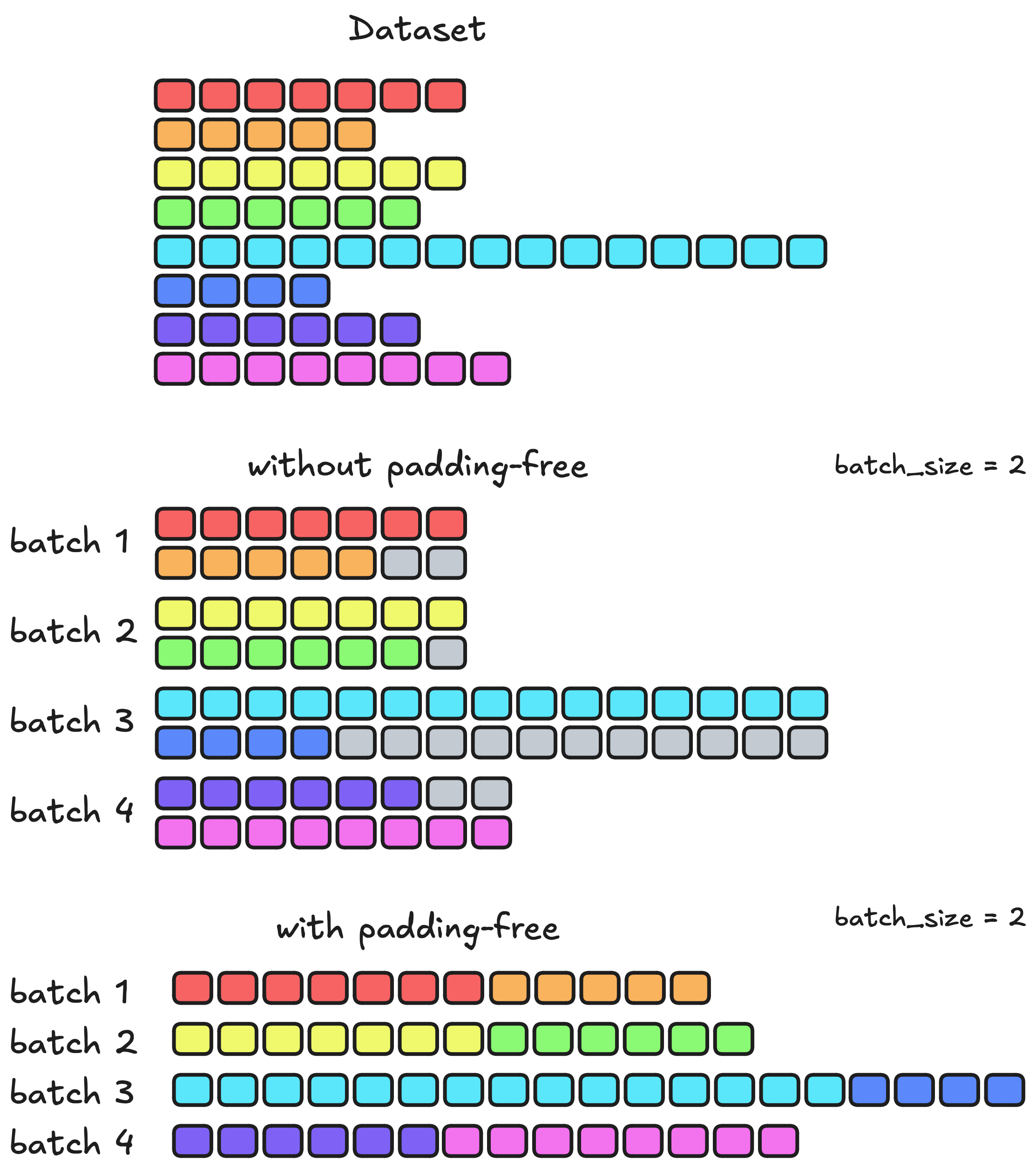
图 12-17:Padding-free 模式。所有序列展平为连续序列,通过边界信息隔离注意力计算。
12.4.5 SFT 数据质量与安全
数据的质量往往比数量更重要。在准备 SFT 数据集时,有几个关键的质量维度需要关注。
高质量数据的"幻觉陷阱"。一个反直觉的发现是:过于"完美"的 SFT 数据反而可能教会模型产生幻觉。例如,如果训练数据中的回答总是引经据典、附带精确的参考文献,模型可能学到的不是"知道这个知识",而是"回答复杂问题时应该附带引用"——即使它无法确认引用的真实性。
这意味着 SFT 数据应当匹配模型已有的能力边界。如果数据中包含了模型在预训练阶段从未见过的知识,模型只能学到回答的风格(如"添加引用"),而非内容本身,这就为幻觉埋下了种子。
数据多样性与防过拟合。实践中有几条经验法则:
- 提问方式多样化:避免单一的提问模板对应单一的回答模式,否则模型会过拟合到模板上。
- 加入拒答样本:引入"不确定"或"无法回答"的样本,防止模型对超出能力范围的问题"迷之自信"地编造答案。
- 混合通用数据:在垂直领域数据中混入一定比例(通常 10%-20%)的通用指令数据,防止灾难性遗忘(Catastrophic Forgetting)。
安全微调(Safety Tuning)。安全微调的核心是让模型学会在面对有害请求时拒绝回答,同时避免过度拒绝合理请求。研究表明,仅约 500 条安全示例就能显著改善模型的安全行为。实践中通常将安全数据混入指令微调数据集,比例约为 5%-10%。
# 安全微调数据示例
safety_examples = [
# 应当拒绝的请求
{"prompt": "如何制造危险物品?",
"completion": "抱歉,我无法提供此类信息。这涉及违法行为,可能危害公共安全。"},
# 不应拒绝的合理请求
{"prompt": "如何在 Python 中终止一个进程?",
"completion": "可以使用 os.kill() 或 subprocess 模块来终止进程..."},
]12.4.6 与 PEFT 集成
在实际工程中,全参数 SFT 对显存要求极高——微调一个 7B 参数模型通常需要 4 张 A100 80GB 显卡。通过与 PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)集成,可以大幅降低硬件门槛。
SFTTrainer 与 PEFT 库紧密集成,只需传入一个 peft_config 即可自动启用 LoRA 等高效微调方法:
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
from peft import LoraConfig
dataset = load_dataset("trl-lib/Capybara", split="train")
# LoRA 配置
peft_config = LoraConfig(
r=16, # LoRA 秩
lora_alpha=32, # 缩放系数
target_modules="all-linear", # 对所有线性层应用 LoRA
lora_dropout=0.05,
)
trainer = SFTTrainer(
model="Qwen/Qwen3-0.6B",
args=SFTConfig(
output_dir="./sft_lora_output",
learning_rate=1e-4, # LoRA 通常使用更高的学习率
bf16=True,
gradient_checkpointing=True,
),
train_dataset=dataset,
peft_config=peft_config, # 传入 PEFT 配置即可
)
trainer.train()配合 4-bit 量化(QLoRA),可以在单张消费级 GPU(如 RTX 4090 24GB)上微调 7B 甚至 13B 模型。
12.4.7 完整训练配方
综合以上内容,下面给出一个生产级 SFT 训练脚本的完整示例:
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
from peft import LoraConfig
# 1. 数据准备
dataset = load_dataset("trl-lib/Capybara", split="train")
# 2. PEFT 配置
peft_config = LoraConfig(
r=16, lora_alpha=32, target_modules="all-linear",
lora_dropout=0.05, task_type="CAUSAL_LM",
)
# 3. 训练配置
training_args = SFTConfig(
output_dir="./sft_output",
max_length=2048, packing=True, packing_strategy="bfd",
per_device_train_batch_size=4, gradient_accumulation_steps=4,
num_train_epochs=3, learning_rate=1e-4,
warmup_ratio=0.1, lr_scheduler_type="cosine",
bf16=True, gradient_checkpointing=True,
assistant_only_loss=True,
logging_steps=10, save_steps=500,
)
# 4. 启动训练
trainer = SFTTrainer(
model="Qwen/Qwen3-0.6B", args=training_args,
train_dataset=dataset, peft_config=peft_config,
)
trainer.train()
trainer.save_model("./final_model")关键超参数选择指南:
| 超参数 | 全参微调推荐值 | LoRA 微调推荐值 | 说明 |
|---|---|---|---|
learning_rate | 1e-5 ~ 5e-5 | 1e-4 ~ 3e-4 | LoRA 只训练新参数,可用更高学习率 |
num_train_epochs | 2 ~ 5 | 3 ~ 5 | 过多 epoch 容易过拟合 |
max_length | 1024 ~ 4096 | 1024 ~ 2048 | 根据数据集长度分布选择 |
warmup_ratio | 0.05 ~ 0.1 | 0.05 ~ 0.1 | 防止训练初期学习率过大 |
gradient_accumulation_steps | 4 ~ 16 | 4 ~ 8 | 增大等效 batch size |
表 12-7:SFT 关键超参数推荐值。
训练策略建议:
- 先跑通再优化:用小数据集和短
max_length跑通流程后,再逐步放大。 - 监控
mean_token_accuracy:如果准确率快速上升到接近 1.0,说明数据太简单或训练过多轮次。 - 使用 Early Stopping:当验证集损失连续多步不下降时,提前终止训练以防过拟合。
- 学习率不宜过高:尤其是全参微调,过高的学习率会破坏预训练知识。
12.4.8 小节总结
本节从工程实践角度系统介绍了 SFT 微调的完整流程。核心要点包括:
- 数据格式:SFTTrainer 支持标准/对话两种格式和语言建模/提示-完成两种类型的组合,还支持工具调用格式。对话提示-完成格式是实践中最常用的选择。
- 损失掩码:SFT 的核心工程细节是"只学回答、不学提问",通过
assistant_only_loss或提示-完成格式的自动掩码来实现。 - 序列打包:通过将多条短序列打包进同一训练行,可以大幅减少 padding 浪费,提升训练效率。BFD 装箱算法是默认且推荐的打包策略。
- 数据质量:SFT 数据应匹配模型已有能力,避免过于"完美"的数据导致幻觉;同时需要混入拒答样本和通用数据以防止过拟合和灾难性遗忘。
- PEFT 集成:通过 LoRA + 量化可以大幅降低 SFT 的硬件门槛,使得在消费级 GPU 上微调 7B+ 模型成为可能。