24.2 具身智能
在前一节中,我们看到大模型如何赋能自动驾驶这一特定领域的具身系统。本节将视野拓展到更广泛的具身智能(Embodied Intelligence)——一种使机器人能够像人类一样感知物理环境、自主决策并执行动作的高级机器智能形式。如果说语言模型是在"文字世界"中推理,那么具身智能就是要让 AI 走出虚拟空间,在真实的三维物理世界中"用身体思考"。
本节将从四个层次展开:首先厘清具身智能的定义与核心架构,理解"感知-决策-执行"三位一体的基本范式;然后逐一深入感知、决策和执行三个技术模块,看大模型如何为每个环节带来质变;接着对比业界两条主流技术路线——分层决策与端到端模型;最后讨论具身智能的产业生态与落地挑战。
24.2.1 什么是具身智能
从符号 AI 到具身认知
传统 AI 研究长期遵循"符号主义"范式——在抽象的数学空间中处理知识表示和逻辑推理,与物理世界没有直接交互。1980 年代,MIT 的 Rodney Brooks 提出了著名的"无表示智能"(Intelligence Without Representation)理论,认为真正的智能必须具有身体(embodiment),通过与物理环境的持续交互来涌现。这一思想后来被哲学家和认知科学家发展为"具身认知"(Embodied Cognition)理论,其核心主张是:认知不仅仅发生在大脑中,身体的结构、感官的能力、以及与环境的交互方式都深刻地塑造着智能的形成。
在大模型时代,这一理念获得了新的技术内涵。具身智能可以形式化地定义为:
具身智能 = 感知输入(视觉/触觉/力觉)+ 算法决策(大模型)+ 物理执行(机械反馈)
一个具身智能系统由两个核心部分组成:本体(Embodiment)——在物理世界中执行感知和动作的实体(如机器人硬件);智能体(Agent)——运行在本体之上的软件系统,负责感知理解、任务规划和行为控制。
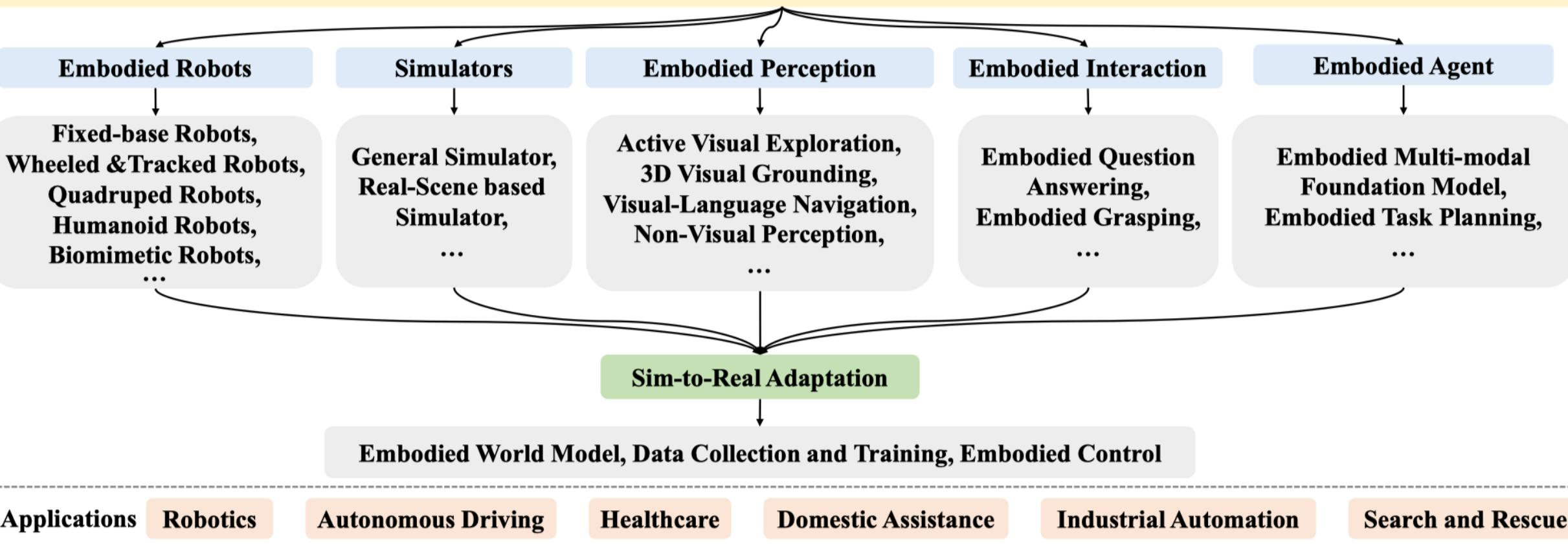
图 24-4:具身智能研究的知识全景(来源:Embodied AI survey)。顶层涵盖五大研究方向:具身机器人(Embodied Robots)、仿真器(Simulators)、具身感知(Embodied Perception)、具身交互(Embodied Interaction)、具身智体(Embodied Agent)。中间层是 Sim-to-Real 适配,包括世界模型、数据采集与控制。底层是应用领域:机器人、自动驾驶、医疗、家政、工业自动化和搜救等。
具身机器人的形态谱系
具身智能的"身体"可以有多种形态,不同形态适配不同的任务场景:
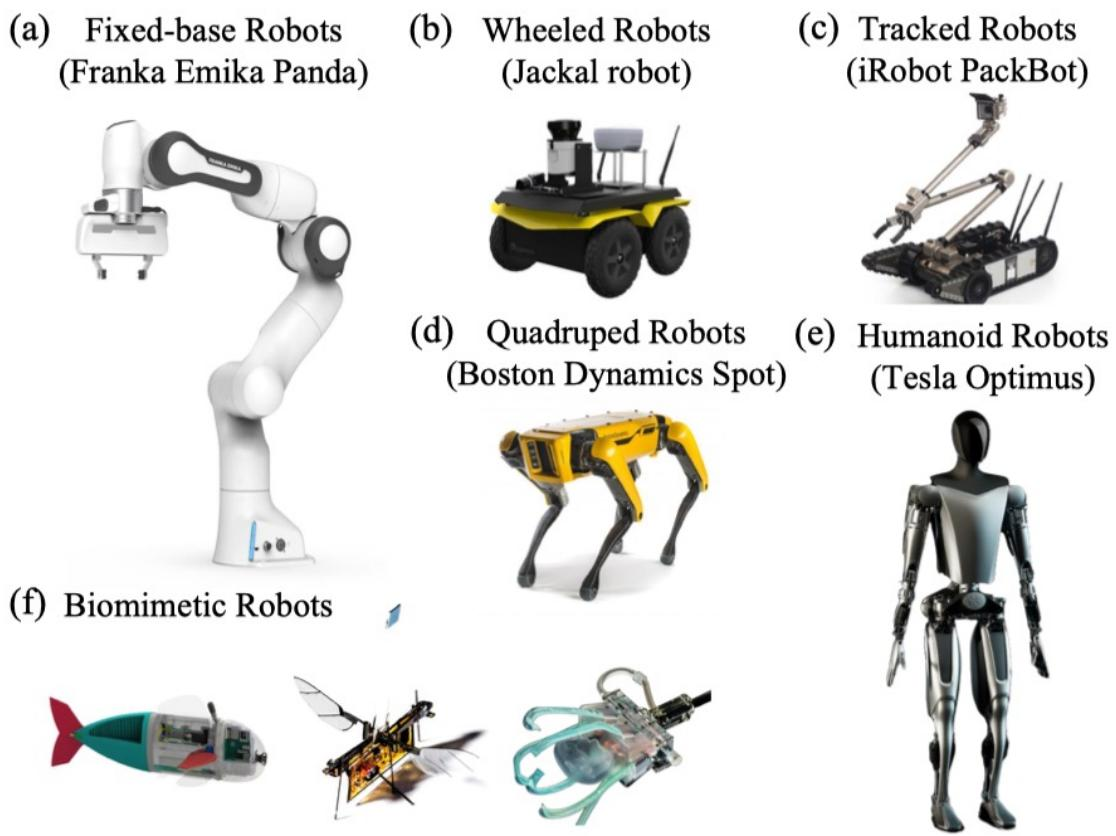
图 24-5:具身机器人的六大形态分类。(a) 固定基座型(Franka Emika Panda 机械臂);(b) 轮式机器人(Jackal);(c) 履带机器人(iRobot PackBot);(d) 四足机器人(Boston Dynamics Spot);(e) 人形机器人(Tesla Optimus);(f) 仿生机器人(机器鱼、飞行昆虫等)。
| 形态 | 代表产品 | 典型应用 | 核心优势 |
|---|---|---|---|
| 固定基座型(机械臂) | Franka Emika Panda | 实验室自动化、工业装配 | 精度高、重复性好 |
| 轮式机器人 | Jackal、Amazon Scout | 物流、仓储、安防巡检 | 机动性强、能耗低 |
| 履带机器人 | iRobot PackBot | 排爆、灾难救援、农业 | 越野能力强 |
| 四足机器人 | Boston Dynamics Spot、宇树 | 地形探测、巡检、军事 | 地形适应性好、稳定性强 |
| 人形机器人 | Tesla Optimus、Figure 02 | 家政服务、工厂协作 | 与人类环境天然兼容 |
| 仿生机器人 | 机器鱼、机器昆虫 | 水下探测、微型监测 | 环境融入度高 |
在所有形态中,人形机器人(Humanoid Robot)是当前具身智能研究和产业投入的焦点。其核心逻辑在于:人类社会的基础设施(门、楼梯、工具、家具)都是为人体尺度设计的,人形机器人可以直接复用这些环境而无需改造;更重要的是,海量的人类动作视频数据可以直接用于训练,大幅降低了数据采集成本。
24.2.2 感知-决策-执行:具身智能的核心闭环
具身智能系统的运作可以抽象为一个持续循环的三阶段闭环:感知(Perception)获取环境信息,决策(Decision)制定行动方案,执行(Action)在物理世界中实施动作,执行结果又反馈回感知模块,形成闭环。
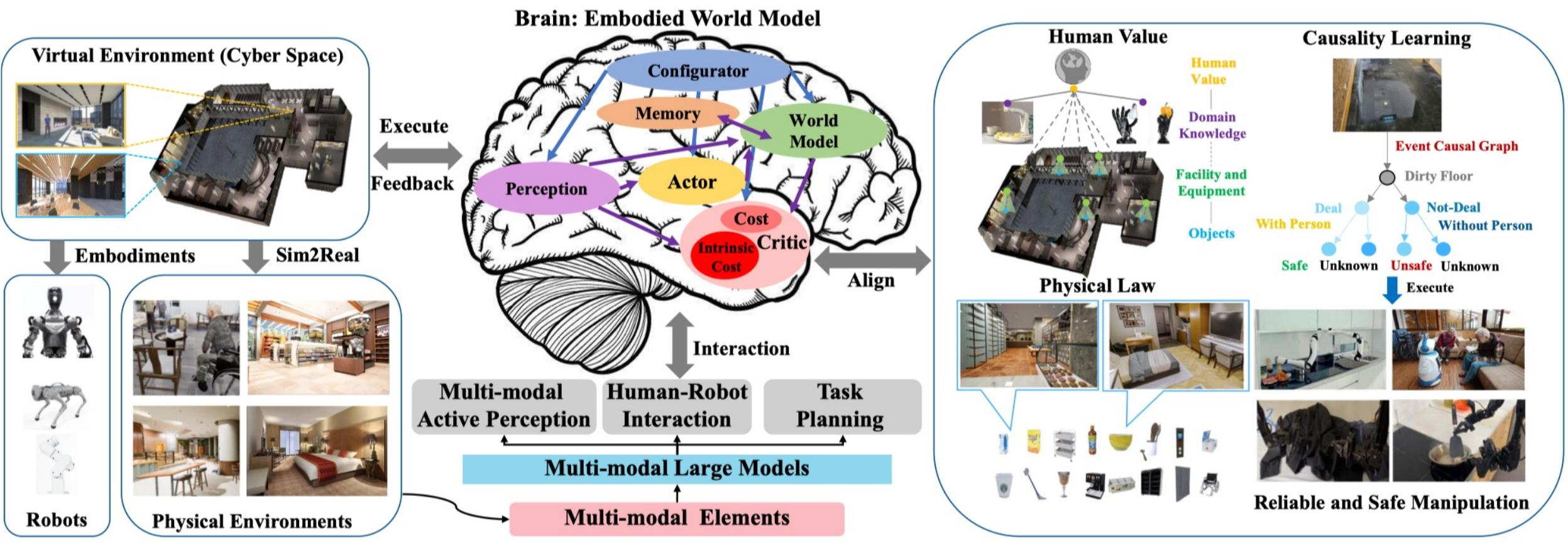
图 24-6:具身智体的典型架构(来源:Embodied AI survey)。中央的"大脑"包含世界模型(World Model)、记忆(Memory)、配置器(Configurator)、行动器(Actor)和评估器(Critic)。左侧是虚拟环境(仿真)和物理环境中的机器人本体,通过执行-反馈回路与大脑交互。下方是多模态大模型提供的基础能力:主动感知、人机交互、任务规划。
具身感知:从被动观察到主动探索
传统计算机视觉的感知是"被动"的——给定一张静态图片,模型对其进行分类或检测。具身感知则有根本性的不同:智体必须在三维物理环境中移动、主动选择观察角度,并在动态变化的场景中持续更新对环境的理解。
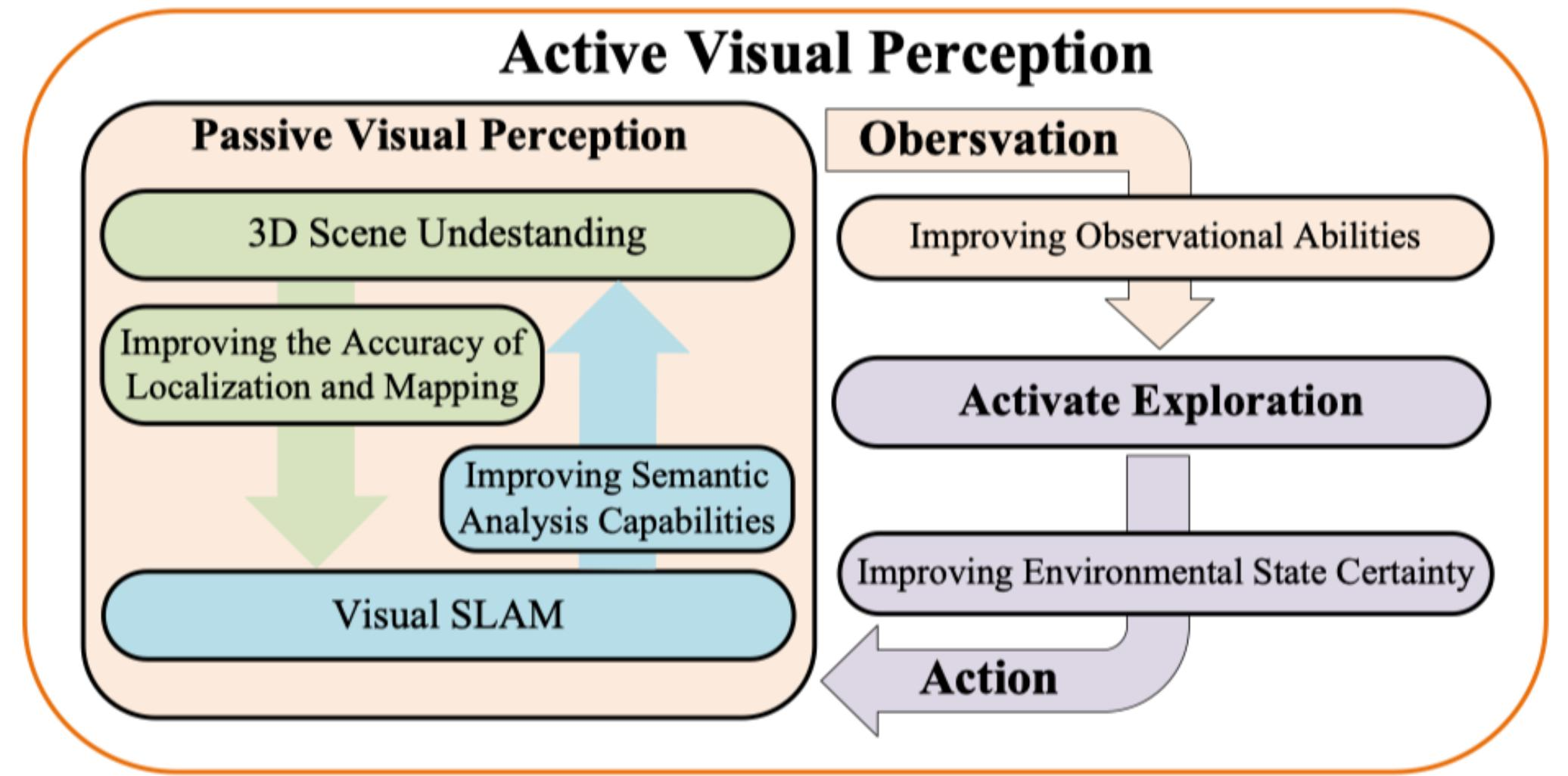
图 24-7:具身感知的两种模式。左侧为被动视觉感知,包括 Visual SLAM(视觉同步定位与建图)和 3D 场景理解,两者互相促进。右侧为主动视觉感知,智体通过"观察→激活探索→行动→改善环境确定性"的闭环不断丰富对环境的认知。
具身感知的关键技术包括:
- 视觉 SLAM(Visual Simultaneous Localization and Mapping):智体在移动过程中同时构建环境三维地图并定位自身位置。这是自主导航的基础能力。
- 3D 场景理解(3D Scene Understanding):不仅要识别物体"是什么",还要理解物体的空间位置、朝向和相互关系。3D Visual Grounding 技术让智体能够根据语言描述(如"桌子上红色的杯子")精确定位目标物体。
- 视觉-语言导航(Visual-Language Navigation, VLN):智体根据自然语言指令(如"沿走廊走到尽头,左转进入卧室")在未知环境中导航。这要求模型同时具备视觉感知、语言理解和空间推理能力。
- 多模态融合感知:将视觉、深度(RGB-D)、触觉、力觉、IMU 等多种传感器信息进行融合,构建更鲁棒的环境表征。
具身决策:大模型充当"大脑"
决策是具身智能的核心环节,也是大模型带来最大变革的领域。具身决策需要将抽象的高层目标(如"帮我从抽屉里拿薯片")分解为一系列可执行的子任务:
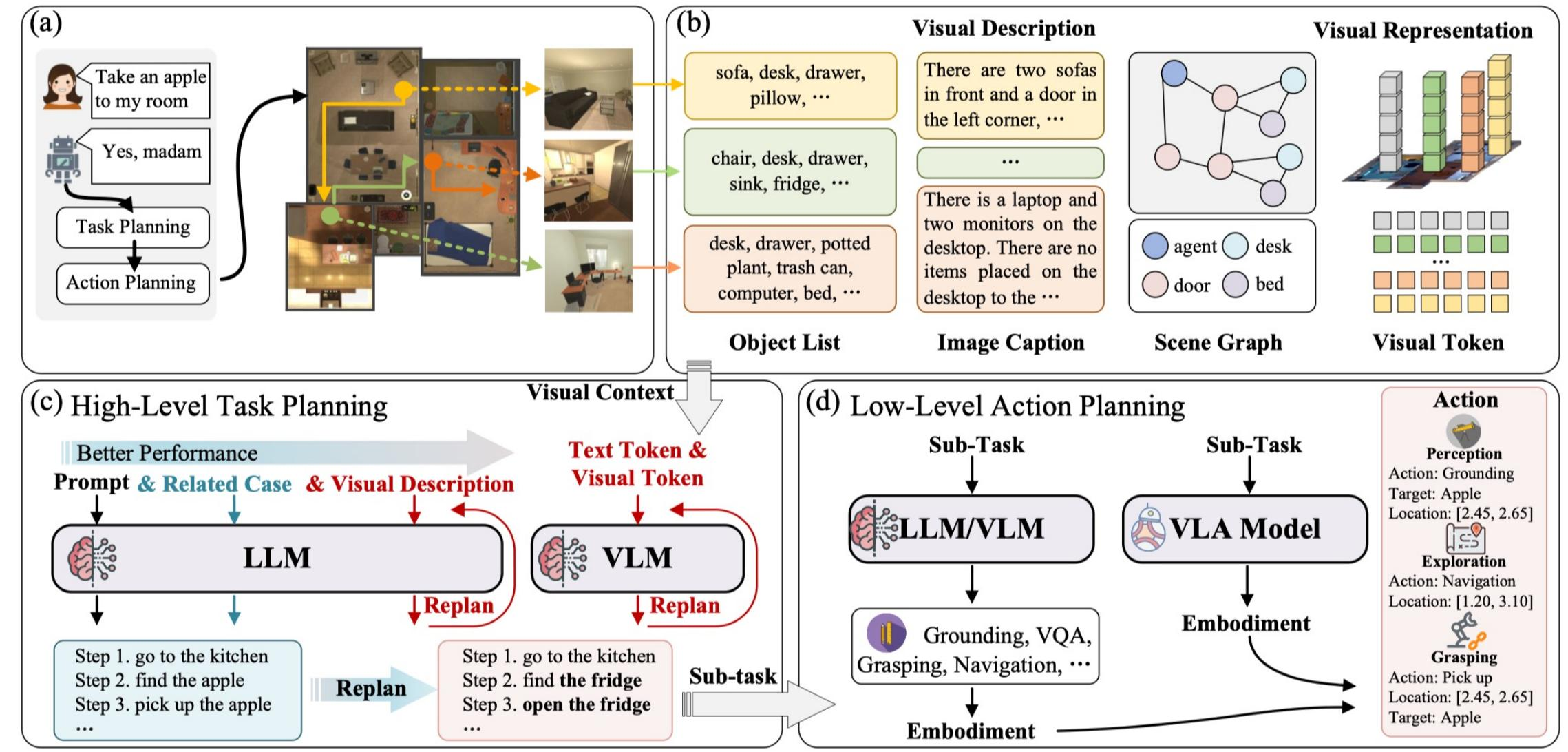
图 24-8:具身决策的两层规划架构。(a) 任务接收与规划:用户指令经任务规划后分解为步骤序列。(b) 视觉描述与表示:场景信息被转化为物体列表、图像描述、场景图和视觉 token 等多种表示。(c) 高层任务规划:LLM/VLM 接收文本和视觉信息,生成可重规划的子任务序列。(d) 低层行动规划:VLA 模型将子任务转化为具体的感知-导航-抓取动作。
决策模块的核心能力可以分为两层:
高层任务规划(High-Level Task Planning):将用户的自然语言指令分解为有序的子任务序列。例如,"帮我从抽屉里拿薯片"可以分解为:(1) 走到抽屉旁;(2) 打开抽屉;(3) 识别薯片位置;(4) 抓取薯片;(5) 关上抽屉;(6) 把薯片递给用户。大模型凭借强大的常识推理和指令理解能力,可以处理开放域的复杂任务分解。
低层行动规划(Low-Level Action Planning):将每个子任务转化为机器人关节层面的具体动作序列(如末端执行器的位姿轨迹、关节角度序列等)。这一层通常需要结合视觉感知信息,输出精确的运动控制指令。
具身执行:从数字指令到物理动作
执行模块负责将决策层的指令转化为实际的物理运动。核心挑战包括:
- 运动控制:协调机器人多关节的运动,实现平稳、精确的动作执行。对于人形机器人,全身运动控制(Whole-Body Control)需要同时考虑平衡维持、碰撞避免和任务完成。
- 灵巧操作:精细的物体操作(如拧瓶盖、折衣服、使用工具)对灵巧手的硬件设计和控制算法都提出了极高要求。
- 具身抓取(Embodied Grasping):根据语言指令执行目标定位和抓取,需要将语义理解、场景感知和鲁棒的抓取规划无缝衔接。大模型(LLM/VLM)的引入使智体能够理解模糊指令(如"帮我拿那个能喝水的东西"),并根据场景推断具体目标。
以下代码展示了一个简化的具身智能感知-决策-执行闭环:
from dataclasses import dataclass
@dataclass
class Observation:
"""智体从环境中获取的多模态观测。"""
rgb_image: list # 相机图像 (H, W, 3)
depth_map: list # 深度图 (H, W)
joint_positions: list # 当前关节角度
force_torque: list # 末端力/力矩传感器读数
@dataclass
class Action:
"""智体输出的动作指令。"""
target_joint_positions: list # 目标关节角度
gripper_command: float # 夹爪开合度 [0, 1]
class EmbodiedAgent:
"""具身智能 Agent 的最小闭环架构。"""
def __init__(self, perception_model, decision_model, controller):
self.perception = perception_model # 感知模块 (e.g., VLM)
self.decision = decision_model # 决策模块 (e.g., LLM)
self.controller = controller # 底层控制器
def perceive(self, obs: Observation) -> dict:
"""将原始传感器数据转化为语义理解。"""
scene_description = self.perception.describe_scene(
obs.rgb_image, obs.depth_map
)
object_locations = self.perception.detect_objects(
obs.rgb_image, obs.depth_map
)
return {
"scene": scene_description,
"objects": object_locations,
"robot_state": obs.joint_positions,
}
def decide(self, state: dict, instruction: str) -> list:
"""大模型将指令分解为子任务序列。"""
prompt = (
f"当前场景: {state['scene']}\n"
f"可见物体: {state['objects']}\n"
f"用户指令: {instruction}\n"
f"请将指令分解为可执行的子任务序列:"
)
subtasks = self.decision.generate(prompt)
return subtasks # e.g., ["navigate_to(drawer)", "open(drawer)", ...]
def execute(self, subtask: str, state: dict) -> Action:
"""底层控制器将子任务转化为关节级动作。"""
trajectory = self.controller.plan_trajectory(
subtask, state["robot_state"], state["objects"]
)
return Action(
target_joint_positions=trajectory[0],
gripper_command=trajectory[1],
)
def run(self, instruction: str, env):
"""主循环:感知 → 决策 → 逐步执行。"""
obs = env.get_observation()
state = self.perceive(obs)
subtasks = self.decide(state, instruction)
for subtask in subtasks:
while not env.subtask_done(subtask):
obs = env.get_observation()
state = self.perceive(obs)
action = self.execute(subtask, state)
env.step(action)24.2.3 两条技术路线:分层决策 vs 端到端
当前业界具身智能的算法路径主要分为两条,分别以 OpenAI + Figure 合作的分层决策模型和 Google RT-2/PaLM-E 为代表的端到端模型为标杆。
路线一:分层决策模型(OpenAI + Figure)
分层决策的核心思想是将感知、决策和执行解耦为独立模块,每个模块各司其职、独立迭代。Figure 02 人形机器人的技术方案是这一路线的典型代表:
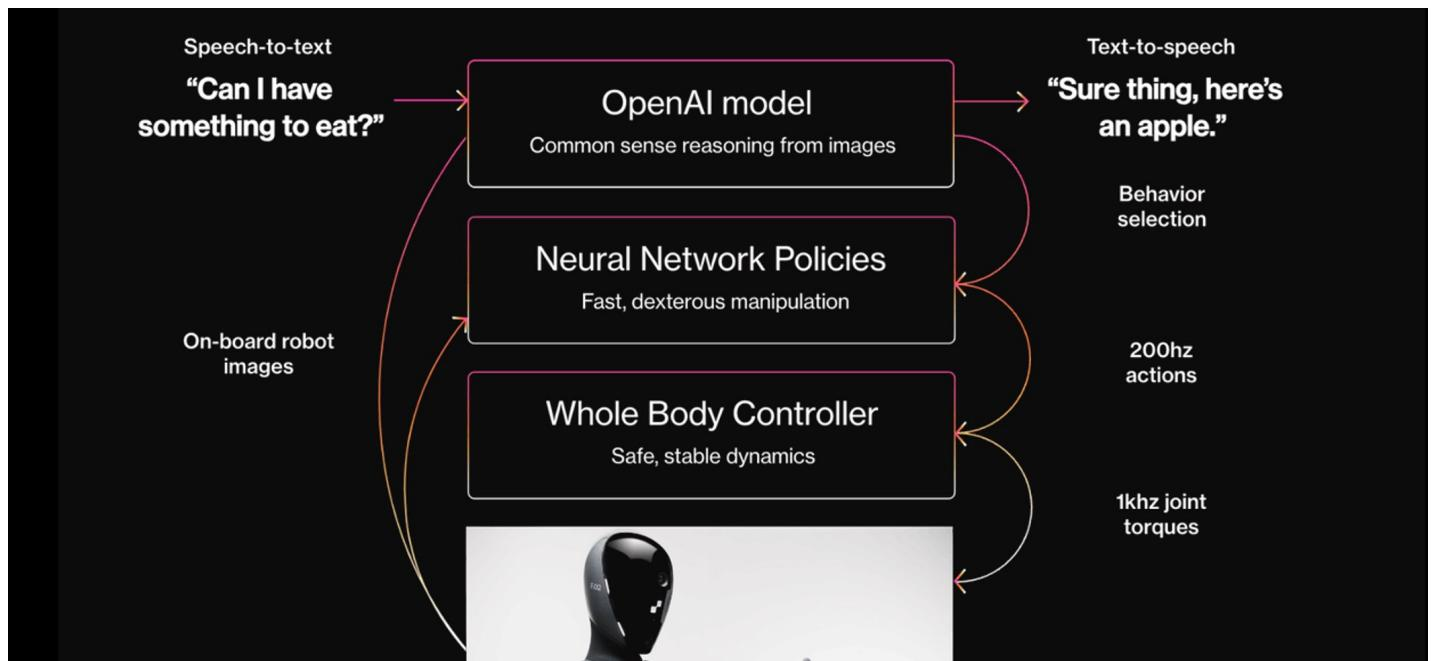
图 24-9:Figure 02 的分层决策架构。顶层:OpenAI 多模态大模型接收语音输入和机器人机载相机图像,进行常识推理并生成语言回复(如"Sure thing, here's an apple.")和行为选择指令。中层:Neural Network Policies 网络以 200Hz 频率生成灵巧操作动作序列。底层:Whole Body Controller 以 1kHz 频率输出安全、稳定的关节力矩。
这一架构的运作流程如下:
- High-Level Planner(多模态大模型):接收用户语音指令(经 Speech-to-Text 转换)和机载相机图像,理解用户意图并生成高层行为选择。大模型在这里充当"大脑",负责常识推理和语言交互。
- Low-Level Policy(神经网络策略):接收高层指令和视觉输入,生成 200Hz 的动作序列。这一层通常使用强化学习或模仿学习训练,擅长快速、精确的灵巧操作。
- Whole Body Controller(全身运动控制器):传统的机器人运动控制算法,以 1kHz 的频率输出关节力矩,保证机器人的动态平衡和运动安全。
分层架构的优点在于逻辑结构清晰、各层可独立调试和升级——大模型升级了推理能力不需要重训底层控制器,底层硬件更换也不影响上层决策。其缺点是层间信息传递存在损失,不同模块的融合和一致性是主要工程挑战。
路线二:端到端模型(Google PaLM-E / RT-2)
端到端路线的理想是用一个统一的大模型直接完成从感知输入到动作输出的全过程,减少中间模块带来的信息损失和工程复杂度。Google 在 2023 年发布的 PaLM-E(Driess et al., 2023)是这一路线的里程碑:

图 24-10:PaLM-E 的多任务架构(来源:Driess et al., 2023)。PaLM-E 将视觉 token(由 ViT 编码)和文本 token 一起输入 PaLM(562B)大语言模型,直接输出控制指令和语言回复。左侧展示了移动操作任务(Mobile Manipulation)、视觉问答、图像描述等多种能力;右上角展示了任务与运动规划、桌面操作任务。
PaLM-E 的关键设计思路:
- 统一输入:将机器人相机图像通过 ViT 编码为视觉 token,与任务指令的文本 token 混合输入一个超大规模语言模型(PaLM, 562B 参数)。
- 统一输出:模型直接输出文本形式的动作序列,如"1. Go to the drawers. 2. Open top drawer. 3. Pick the green rice chip bag.",再由底层执行器解析执行。
- 端到端微调:先在大规模互联网数据上预训练 VLM,再在机器人任务数据上微调,使模型同时具备常识推理和具身控制能力。
端到端方案的突出发现是在 PaLM-E 这样的超大规模模型中观察到了能力涌现(emergent capabilities)——当模型参数量足够大时,即使没有在特定机器人任务上训练,模型也能展现出零样本迁移到新任务的能力。这提示了一条与 Scaling Law 一致的技术路径:用足够大的数据和模型来"暴力"逼近通用具身智能。
两条路线的对比
| 维度 | 分层决策(Figure) | 端到端(PaLM-E / RT-2) |
|---|---|---|
| 架构特点 | 模块化,各层独立 | 统一模型,全流程端到端 |
| 误差传递 | 层间可能损失信息 | 理论上减少误差传递 |
| 工程实现难度 | 相对简单,逻辑清晰 | 需海量数据训练,推理资源消耗大 |
| 可解释性 | 各模块职责明确,易调试 | 黑箱程度高,难以定位故障 |
| 泛化能力 | 依赖各模块独立泛化 | 大模型涌现能力带来强泛化潜力 |
| 实时性 | 底层控制器可达 1kHz | 调用万亿参数模型的推理延迟高 |
| 代表性缺点 | 模块间融合一致性是难点 | 需海量机器人数据,资源消耗巨大 |
当前的工业实践中,分层架构仍然是主流选择——它在工程上更可控、更安全,各层可独立迭代。端到端方案的科研前景更具想象力,但距离大规模部署仍有相当距离。未来最有可能的方向是两条路线的融合:用端到端大模型处理高层感知和决策,用传统控制器保障底层执行的安全性和实时性。
24.2.4 仿真平台:Sim-to-Real 的桥梁
具身智能研究面临一个根本性困难:真实世界的数据采集既昂贵又缓慢。一个机器人在实验室中采集一条操作轨迹可能需要数分钟,而训练一个鲁棒的策略往往需要数百万条轨迹。仿真平台(Simulator)正是为解决这一瓶颈而生,它提供了一个虚拟的物理环境,允许智体在其中以极低成本进行大规模并行训练。
仿真平台主要分为两类:
通用物理仿真器(General Simulators):如 MuJoCo、Isaac Sim、PyBullet 等,提供通用的物理引擎,支持刚体动力学、接触力计算和传感器模拟。它们的优势在于计算效率高、API 标准化,适合算法开发和快速原型验证。例如,MuJoCo 以其高效的接触动力学计算成为强化学习领域的标准测试平台。
真实场景仿真器(Real-Scene Based Simulators):如 Habitat、AI2-THOR、iGibson 等,从真实世界扫描或利用 3D 游戏引擎(UE5、Unity)构建高度逼真的室内外场景。这些平台的优势在于视觉真实度极高,训练出的策略更容易迁移到真实世界。
仿真到现实的迁移(Sim-to-Real Transfer)是当前研究的核心挑战之一。仿真中训练的策略在迁移到真实机器人时,往往因为物理参数差异(摩擦系数、质量分布)、传感器噪声和动力学 gap 而性能大幅下降。主流的应对策略包括:域随机化(Domain Randomization,在仿真中随机扰动物理参数以增强鲁棒性)、域适应(Domain Adaptation,学习仿真与现实之间的映射)、以及数字孪生(Digital Twin,构建与现实高度匹配的仿真模型)。
24.2.5 产业生态与落地挑战
产业技术栈
具身智能的产业链是一个从底层硬件到上层软件的完整生态:
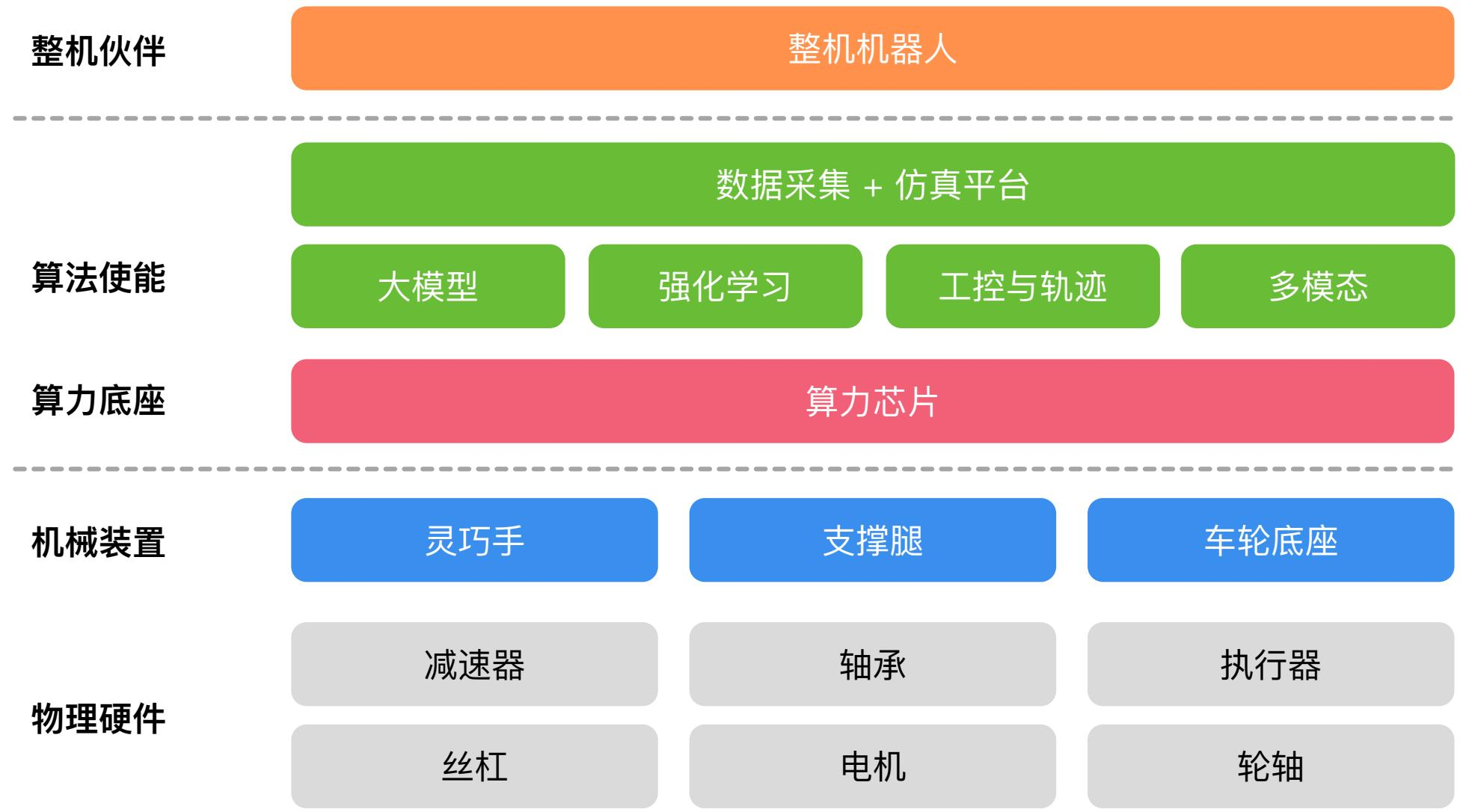
图 24-11:具身智能产业技术栈。从下到上:物理硬件层(减速器、轴承、执行器、丝杠、电机、轮轴)→ 机械装置层(灵巧手、支撑腿、车轮底座)→ 算力底座(算力芯片)→ 算法使能层(大模型、强化学习、工控与轨迹、多模态)→ 数据采集与仿真平台 → 整机伙伴。
这一技术栈揭示了具身智能与纯软件 AI 的根本差异:硬件是一切的基础。一家具身智能公司的核心竞争力不仅仅在算法层面,还需要在硬件设计、数据工程和系统集成上具备深厚积累。
人形机器人:为什么是"人形"?

图 24-12:人形机器人执行多样化任务的示例。左上:自主折叠衣物;右上:双机器人与人类协作交互;左下:高空跳跃展示动态平衡能力;右下:自主整理桌面物品。这些任务都受益于人形结构对人类环境的天然适配性。
人形机器人之所以成为焦点,有两个深层原因。第一,环境适配性:双足行走占地面积小,能适应楼梯、狭窄通道等为人类设计的环境;双臂双手的结构可以直接操作人类工具和物品。第二,数据可用性:互联网上存在海量的人类动作视频,人形机器人可以通过模仿学习直接利用这些数据进行训练——这是轮式或四足机器人无法享有的优势。
数据飞轮:具身智能公司的核心壁垒
无论选择哪条算法路线,都需要建立一套完整的数据收集-训练-部署-反馈闭环(即"数据飞轮"),这是当前具身智能公司最核心的竞争力。数据工程面临两大挑战:
- 硬件耦合性:采集到的操作数据与特定硬件深度绑定。一旦硬件规格修改(如更换电机型号或调整关节布局),已有数据可能无法直接复用,需要重新采集。跨硬件的算法迁移目前仍处于研究阶段。
- 数据工程复杂度:涉及数据采集(遥操作 / 自主采集)、清洗、标注、存储管理、与算法训练的闭环迭代,需要专业的数据工程团队。
产业落地路径:从垂直到通用
业界对具身智能的落地路径已经形成了相对清晰的共识:
- 短期(1-3 年):产品主要面向高校和科研机构,用于科研和教学。商业化以垂直场景为主——特定工业环节的机器人(如仓储分拣、特定装配线)会率先落地。
- 中期(3-5 年):垂直领域机器人的成本降低到商业可行水平,开始规模化部署。通用工业机器人逐步成熟。
- 长期(5-10 年以上):家用通用机器人进入市场。但这不仅需要技术突破(灵巧操作、安全性),还需要解决成本、伦理和法律问题(如机器人打碎贵重物品的责任归属)。
实际上,产业界存在两种派系。学术派团队技术相对领先(尤其在视觉算法和大模型算法层面),倾向于讲家用机器人的宏大愿景;产业派团队则更务实,将开源算法与自身硬件优势结合,集中在垂直场景落地。历史经验表明,真正的技术瓶颈不仅在大模型和强化学习算法,还在于执行层面——理想的末端执行器(灵巧手)、低成本的触觉传感器、以及可量产的制造工艺和供应链。
本节要点总结
- 具身智能是让 AI 从虚拟空间走向物理世界的关键范式,其核心架构是"感知-决策-执行"三位一体的闭环。本体(硬件)与智能体(软件)共同构成一个具身智能系统。
- 感知模块需要在三维动态环境中进行主动探索,关键技术包括视觉 SLAM、3D 场景理解和视觉-语言导航。决策模块分为高层任务规划和低层行动规划两层,大模型的引入使开放域指令理解和复杂任务分解成为可能。执行模块负责将数字指令转化为物理动作,灵巧操作和全身运动控制是核心挑战。
- 业界存在两条主流技术路线:以 Figure 为代表的分层决策架构(模块化、工程可控、当前主流)和以 PaLM-E 为代表的端到端模型(统一、高泛化潜力、资源消耗大)。两条路线的融合是未来趋势。
- 仿真平台是 Sim-to-Real 的关键桥梁,通用仿真器(MuJoCo、Isaac Sim)和真实场景仿真器(Habitat、AI2-THOR)各有侧重。域随机化、域适应等技术用于缩小仿真与现实的差距。
- 产业落地的核心壁垒在于硬件-数据-算法的三位一体闭环。人形机器人因环境适配性和数据可用性成为焦点形态。落地路径遵循"垂直场景先行、通用能力后至"的渐进逻辑,短期以科研客户为主,长期向家用通用机器人演进。