23.4 视频生成与理解
视频是人类感知世界最自然的媒介之一。与静态图像相比,视频多了一个时间维度——它不仅包含"场景中有什么",还记录了"事物如何变化"。这一维度的增加为模型理解和生成带来了根本性挑战:如何在空间特征之上高效建模帧间运动关系?如何在生成连续画面时保持时空一致性?
本节将沿着"传统视频分析 → 多模态 LLM 视频理解 → 文本到视频生成"的技术脉络展开,从双流网络到 SORA,串联起视频领域从理解到生成的完整技术图景。如何利用好视频数据、做好视频理解与生成,可能是通向更强人工智能的必经之路——视频包含了世界运行的因果信息,而这些信息在静态图像和纯文本中是缺失的。
视频理解为生成提供语义基础,而生成技术的进步反过来又推动我们重新审视"理解"本身的含义——如果一个模型能够生成物理上合理的视频,那它在某种意义上已经"理解"了物理世界。这两条看似独立的技术路线正在加速融合。
23.4.1 传统视频理解:从手工特征到深度学习
视频理解(Video Understanding)旨在让计算机"看懂"视频内容——不仅识别物体和场景,还能理解动态关系、时序逻辑和行为意图。简单来说,人类看一段视频能轻松知道"谁在什么地方、做了什么、为什么这么做、接下来可能发生什么",而视频理解的目标就是让机器具备同样的综合解析能力。
手工特征时代。在深度学习兴起之前,研究者依赖手工设计的特征提取器来处理视频。其中较为常用的技术包括:
- SIFT(Scale-Invariant Feature Transform,尺度不变特征变换):由 David Lowe 于 1999 年提出,能够从图像中提取对旋转、尺度变化、亮度变化具有不变性的特征点。在视频目标跟踪中,通过逐帧匹配 SIFT 特征点实现稳定追踪。
- SURF(Speeded-Up Robust Features,加速稳健特征):2006 年由 Herbert Bay 等人提出,使用 Hessian 矩阵和积分图像加速计算,速度显著优于 SIFT,常用于视频监控中的运动检测。
- HOG(Histogram of Oriented Gradients,方向梯度直方图):通过局部梯度方向统计描述形状和边缘信息,在行人检测和行为识别中应用广泛。通过分析目标在不同时间段内的梯度变化,可用于识别奔跑、跳跃、打斗等行为模式。
这些方法虽然奠定了视频分析的基础,但存在明显的局限性:对复杂场景(快速运动、遮挡、光照剧变)的适应性差,特征设计依赖研究者的经验和先验知识,通用性和扩展性不足。更关键的是,手工特征方法需要大量人工调试,且不同任务往往需要重新设计特征组合——行人检测用 HOG,目标跟踪用 SIFT,很难有一套通用方案适应所有场景。随着视频数据量的爆发式增长和应用场景的日益多样化,手工特征的局限性愈发凸显,促使研究者转向能够自动学习特征的深度学习方法。
双流网络:深度学习视频理解的开山之作。2014 年,Simonyan 和 Zisserman 提出双流网络(Two-Stream Network, NeurIPS 2014),将深度学习引入视频理解领域。在此之前,也有研究者尝试将 CNN 用于视频,例如 DeepVideo(CVPR 2014)提出了包含 100 万个视频的 Sports-1M 数据集,但由于没有很好地利用运动信息,在 UCF-101 数据集上精度只有 65.4%,比最好的手工方法 IDT 差了近 20 个百分点。这让研究者认识到,运动信息对视频理解至关重要。
双流网络的核心思想是将视频分解为两个互补信息流:
- 空间流(Spatial Stream):输入单帧 RGB 图像,用 CNN(基本就是一个 AlexNet)提取场景和物体信息——相当于对每一帧做图像分类。
- 时间流(Temporal Stream):输入光流(Optical Flow)图的叠加。光流可以理解为视频中每个像素点在相邻帧之间的运动轨迹和速度。通常取
张光流图叠加(输入通道数 ),让网络从中学习运动信息。空间流和时间流的网络结构几乎一样,唯一区别在于输入不同。
两路网络分别独立训练后,通过两种方式融合预测:
- Late Fusion:两路 softmax 输出取加权平均,再做 argmax 得到最终分类。
- SVM 融合:将两路 softmax 分数作为特征,训练一个 SVM 分类器输出最终结果。
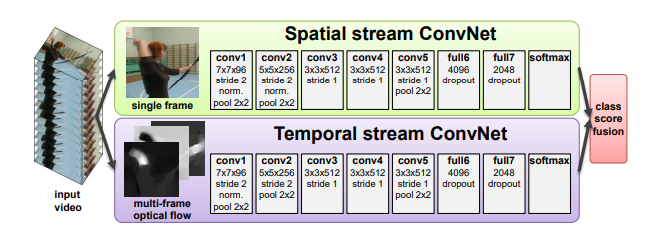
图 23-12:双流网络架构示意图(来源:Simonyan & Zisserman, 2014)。上路为空间流(单帧 RGB),下路为时间流(多帧光流叠加),两路独立提取特征后加权融合得到最终分类。
双流网络在 UCF-101 数据集上达到 88% 精度,追平了当时最好的手工方法。更重要的是,它揭示了一个深刻道理——正如亚马逊朱毅老师所评价的:"当你发现神经网络不能解决什么问题的时候,有可能仅仅靠魔改模型或改目标函数是没办法很好解决的。不如给模型提供先验信息,它学不到的我们帮它学。"光流就是对运动信息的显式编码,这一思路也可以看作多模态学习的先例——RGB 图像和光流本质上就是不同的"模态"。
双流网络之后,涌现了一系列改进工作:融入 LSTM 提升长视频理解的 Two-Stream+LSTM(CVPR 2015),改进融合方式的 Early Fusion(CVPR 2016),将长视频拆分再合并特征的 TSN(ECCV 2016)等。不过,双流网络有一个致命瓶颈:光流的计算代价极高。光流提取耗时长(准备训练数据需要花费大量时间预先抽取光流)、存储量大(光流的密集表示导致存储空间远超原始视频帧),无论训练还是推理都难以做到实时。值得一提的是,尽管光流成本高昂,但在提升效果方面它始终是一个很好的特征——即使在后来的 3D CNN 和 Video Transformer 时代,加入光流仍然可以继续提高性能。不过,研究者们还是开始寻找能直接从视频中学习运动信息、而不需要显式计算光流的替代方案。
3D CNN 与 I3D:告别光流依赖。既然视频比图像多了时间维度,一个自然的想法是把 2D 卷积升级为 3D 卷积,让网络直接在时空维度上学习。早期的 C3D(ICCV 2015)实现了这一想法,但效果仍有差距(UCF-101 上 82.3%)。
真正让 3D CNN 大放异彩的是 Carreira 和 Zisserman (2017) 提出的 I3D(Inflated 3D ConvNet, CVPR 2017)。I3D 的核心贡献包括:
Inflated 策略:将成熟的 2D 网络(如 Inception-V1)直接"膨胀"到 3D——
卷积核变成 ,2D 池化变成 3D 池化,整体架构保持不变。这样可以直接复用 CV 领域成熟的 2D 网络结构(VGG、ResNet 等),无需从零设计 3D 架构或进行大量消融实验(甚至到 2022 年的 Video Swin Transformer 仍在做类似的 Inflate 操作,将 2D Swin Transformer 膨胀到 3D)。 Bootstrapping 初始化:2D 预训练参数如何迁移到 3D 网络?I3D 的做法是:将 2D 滤波器权重沿时间维度复制
次,并除以 进行归一化。这样当输入是将同一帧复制多次形成的"伪视频"时,3D 网络的输出与原始 2D 网络完全一致。这使得即使是很深的 3D 模型也不需要大量视频数据从头训练——直接用 2D 预训练参数初始化即可。 Kinetics 数据集:I3D 作者认为图像处理之所以发展得好,一个重要原因是 ImageNet 这样足够大的数据集提供了预训练基础,但当时视频领域没有与之匹配的数据集。因此他们发布了 Kinetics-400:400 个类别、每类超过 400 个视频、每段来自独一无二的 YouTube 视频、精准截取 10 秒段落、难度适中、标注精确。Kinetics 为视频理解提供了类似 ImageNet 的预训练生态,后续扩展到 Kinetics-600 和 Kinetics-700。
架构设计细节:I3D 基于 Inflated Inception-V1,池化层在时间维度上的处理值得注意——前几个池化层不在时间维度下采样(如
池化变为 ,stride 从 变为 ),仅在后几个阶段进行时间下采样。这是因为输入视频通常只有 2 秒左右(64 帧),过早的时间下采样会丢失宝贵的时序信息。后来的研究也验证了这一设计选择——2D 扩展到 3D 时,池化层的时间维度最好不要过早下采样。
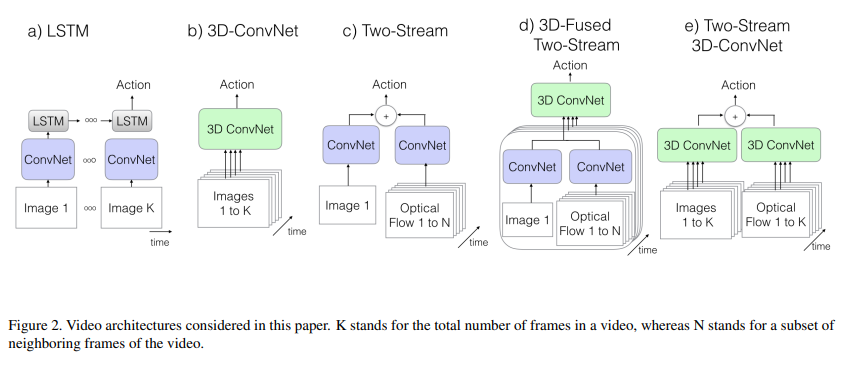
图 23-13:I3D 论文中五种视频理解架构的对比(来源:Carreira & Zisserman, 2017)。从左到右分别是 CNN+LSTM、纯 3D CNN、双流网络、3D 融合双流网络、以及 I3D(双流 3D ConvNet)。I3D 在 UCF-101 上达到 98%,HMDB-51 上达到 80%,基本"刷爆"了这两个经典数据集。
I3D 的网络结构以及 Kinetics 数据集给视频理解带来了两条清晰的技术路线:如果缺少好的训练数据,可以用 ImageNet 预训练模型 Inflate 到 3D,复用已有参数(Inflating + Bootstrapping);如果想从头训练 3D 网络,可以用 Kinetics 数据集做预训练,不再依赖 ImageNet。
I3D 之后,3D CNN 统治了 2017–2020 年的视频理解领域,涌现出一系列重要改进:
- R(2+1)D(CVPR 2018):将 3D 卷积拆分为 2D 空间卷积 + 1D 时间卷积,既降低了过拟合风险,又提高了训练稳定性。这一"分解"思想在后来的 Video Transformer 时代仍被广泛使用。
- Non-local Networks(CVPR 2018):将自注意力机制引入 3D CNN,使模型能够直接建模感受野之外的长程依赖。用 ResNet 实现的 I3D + Non-local 成为后续工作的标准基线。
- SlowFast(ICCV 2019):舍弃光流,改用两个网络分别以低帧率(Slow 路径,捕获静态语义)和高帧率(Fast 路径,捕获运动信息)处理视频,两路特征通过侧连接融合。
- X3D:使用 AutoML 搜索网络结构,参数量极小而效果极好,基本封顶了 3D CNN 的性能上限,研究者们开始寻求其他出路。
然而,3D CNN 存在三个根本性问题限制了视频理解的进一步发展:
- 强归纳偏置:卷积的局部连接性和平移不变性在小数据集上有利,但数据集够大时会限制模型表达能力。
- 全局感知不足:卷积核专门设计用于捕捉局部时空信息,即使堆叠多层扩大感受野,仍难以建模长程依赖。
- 计算资源瓶颈:应用于高清长视频时,训练深度 3D CNN 极其消耗计算资源。
这些问题共同为 Transformer 的入场埋下了伏笔——直到 ViT(ICLR 2021)的出现,视频理解终于迎来了转机。
Video Transformer 时代。2021 年,随着 ViT(ICLR 2021)在图像领域的成功,研究者开始将 Transformer 迁移到视频理解。TimeSformer(Bertasius et al., ICML 2021)是这方面最早的代表性工作之一。
Transformer 相比 CNN 有三大优势:(1)归纳偏置更少,大数据下模型表达能力更强;(2)自注意力机制可以直接捕捉任意距离的时空依赖;(3)训练和推理效率更高,相同计算资源下可以训练更强的网络。但直接计算视频所有帧所有 patch 的联合自注意力(即 Joint Space-Time Attention)计算量极大,显存基本塞不下。
TimeSformer 系统探索了五种注意力拆分方案:
| 方案 | 策略 | 特点 |
|---|---|---|
| Space Attention (S) | 仅计算单帧内 patch 间注意力 | 类似 ViT 基线,完全忽略时间信息 |
| Joint Space-Time (ST) | 所有帧所有 patch 联合计算 | 理论最优但显存基本不可行 |
| Divided Space-Time (T+S) | 先时间注意力再空间注意力 | 效果最佳,复杂度可控 |
| Sparse Local-Global (L+G) | 先局部注意力再全局稀疏 | 类似 Swin Transformer 思路 |
| Axial (T+W+H) | 分别沿时间/宽度/高度轴 | 三次拆分,进一步降低复杂度 |
以 Divided Space-Time (T+S) 为例具体说明:假设视频有
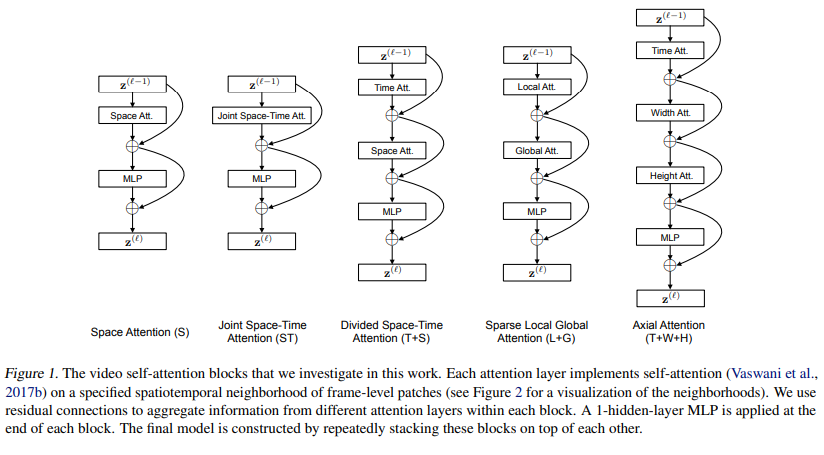
图 23-14:TimeSformer 五种时空注意力方案的架构示意图(来源:Bertasius et al., 2021)。实验表明 Divided Space-Time Attention (T+S) 在精度与效率间取得最佳平衡。在 Kinetics-400 上,T+S 方案效果最好;需要注意的是,纯空间注意力在偏静态的 K-400 上表现尚可,但在需要强时序建模的 Something-Something-V2 上急剧下降。
TimeSformer 之后,Video Transformer 迅速迭代:
- ViViT(ICCV 2021):通过时空管采样(Tubelet Embedding)提取视频标记,采用编码器分解策略平衡效率与性能。
- MViT(ICCV 2021):引入多尺度特征和 Longformer 式稀疏注意力。
- Video Swin Transformer(CVPR 2022):加入时间窗口移位机制,增强长时依赖捕捉能力。
这些工作共同确立了 Transformer 在视频理解领域的主导地位。
TimeSformer 还有一个重要贡献值得强调:它的可扩展性使得模型可以在长达数分钟的视频片段上训练(当时的 3D CNN 最多只能处理几秒),为 AI 系统理解更复杂的人类行为做下了铺垫。不过,Transformer 也有其局限——作者团队的消融实验显示,TimeSformer 在数据较少时表现不佳,需要非常大的数据量才能达到媲美 CNN 的效果(这与 ViT 的结论一致)。此外,模型本身的庞大使其难以在算力较小的设备上部署,时至今日这仍是 Video Transformer 的普遍问题。
深度学习视频理解总结。回顾从双流网络到 Video Transformer 的演进脉络,每一代模型都在解决前一代的核心瓶颈:双流网络引入光流弥补 CNN 对运动信息的感知不足;I3D 通过 Inflate 策略让 3D CNN 实用化;TimeSformer 用拆分注意力突破 CNN 的全局感知局限。
深度学习模型的核心优势在于能够自动学习更具判别性的特征,避免了手工特征依赖人工设计的局限性,对复杂场景和多样化内容的适应性显著增强。通过在大规模数据集上训练,模型的泛化能力大幅提升。然而,这些模型也存在共性挑战:
- 数据瓶颈:深度学习模型通常需要大量标注数据,而获取高质量的标注视频数据成本极高——构建视频行为分析数据集需要专业人员逐帧标注行为类别,耗时且容易出错。
- 计算瓶颈:模型的计算复杂度高,尤其是处理高清长视频时对硬件要求苛刻,在资源受限的边缘设备(如智能摄像头)上部署面临巨大挑战。
- 可解释性不足:模型内部的决策过程难以理解,在自动驾驶、安防监控等对安全性要求高的场景中可能带来潜在风险。
这些挑战也为多模态大模型的介入提供了契机——利用 LLM 的语义理解能力弥补纯视觉模型在深层理解上的不足,通过大规模预训练减少对特定任务标注数据的依赖。
23.4.2 多模态大模型视频理解
随着大语言模型能力的不断增强,研究者自然地思考:能否让 LLM"看懂"视频?与 TimeSformer 这类专用模型通过分类头直接输出类别不同,多模态大模型通过将视频特征对齐到文本语义空间,利用 LLM 强大的推理能力实现语义级理解——不仅能做视频分类,还能回答"视频中人物为何打开冰箱"这类深层语义问题。
通用架构范式。当前主流的视频理解大模型基本遵循统一的三段式架构:
视觉编码器(通常基于 ViT)将视频帧编码为视觉 token,跨模态连接器将其对齐到文本 token 的语义空间,最后由 LLM 进行自回归解码。这一范式之所以以文本模态为核心,有几个深层原因:
- 文字是人类对世界语义最精准的结构化编码,具备天然的语义锚点特性——文字"狗"可直接锚定概念,而图像中的"狗"需要通过像素组合间接表达。
- 文字的离散化序列结构天然适配 Transformer,降低了多模态融合的结构适配难度。
- 文本数据规模和预训练模型生态远超其他模态,LLM 经过海量文本预训练已具备强大的语义理解和推理能力,多模态模型可以直接复用。
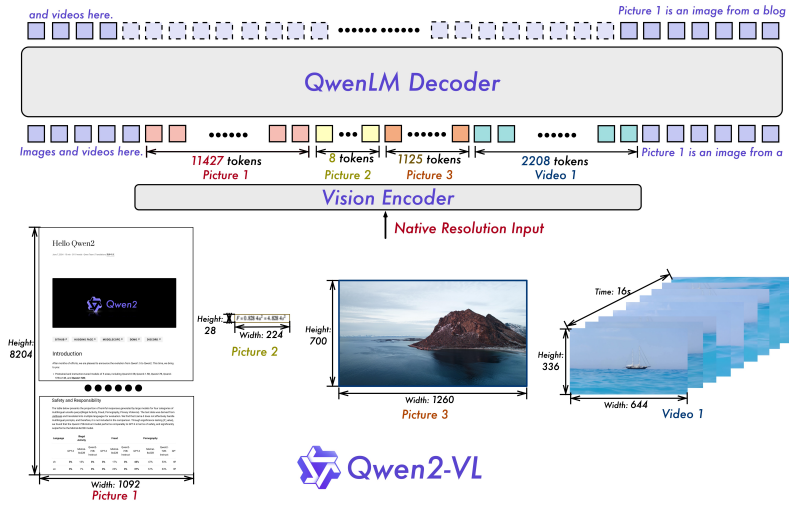
图 23-15:Qwen2-VL 的多模态架构(来源:Wang et al., 2024)。图像和视频经 Vision Encoder 编码为向量后,与文本 token 共同输入 LLM Decoder 进行 next token prediction。输入可以是图文混合或视频文字混合。
代表性模型与核心创新。以 Qwen 系列为例,可以清晰看到视频理解能力的快速演进:
Qwen2-VL 是该系列首个加入视频训练数据的版本。它采用混合训练方案(同时整合图像与视频数据),对视频每秒采样两帧,并使用两层 3D 卷积处理视频输入,在不增加序列长度的同时处理更多的视频帧。为保持一致性,图片被视为两个相同的帧处理。为平衡长视频处理的计算需求与整体训练效率,动态调整每个视频帧的分辨率,将单个视频的 token 总数限制为 16384 个,可处理超过 20 分钟的视频。
架构上的关键创新是 M-RoPE(Multi-dimensional Rotary Position Embedding)——将旋转位置嵌入分解为时间、高度、宽度三个组件。具体的分配规则如下:
- 文本输入:三个组件采用相同的位置 ID,使 M-RoPE 等效于标准 1D-RoPE。
- 图像输入:每个视觉 token 的时间 ID 保持不变,高度与宽度组件根据 token 在图像中的空间位置分配独立 ID。
- 视频输入:被视为帧序列,每帧的时间 ID 递增,高度与宽度组件遵循与图像相同的分配方式。
- 多模态混合输入:各模态的位置编号通过将前一模态的最大位置 ID 递增 1 来初始化。
这一设计不仅增强了位置信息的建模能力,还降低了图像与视频的位置 ID 值,使模型在推理时能够外推至更长的序列。Qwen2-VL 在 MVBench、PerceptionTest 和 EgoSchema 三项测试中均取得最佳表现。
Qwen2.5-VL 做了进一步优化:将 M-RoPE 的时间组件与绝对时间对齐——利用时间 ID 间隔编码真实时间关系,使模型能学习不同帧率视频间的一致时间映射。为增强鲁棒性,训练时动态采样帧率使分布更均匀。对超过半小时的视频,通过合成管道整合多帧字幕构建长视频数据集。该版本支持数小时级视频理解。
Qwen3-VL 引入两项架构升级:(1)MRoPE-Interleave 将时间
其他代表性工作各有侧重:
- Seed1.5-VL(字节跳动):采用动态帧分辨率采样(Dynamic Frame-Resolution Sampling),在时间和空间维度联合优化。时间维度上根据任务需求动态调整帧率(默认 1fps,需详细时序信息的任务升至 2fps,视频计数/运动跟踪任务升至 5fps),并在每帧前添加时间戳 token(如
[1.5 second])强化时序感知。空间维度上在每段视频最大 81920 token 预算内,通过六级预定义分辨率(640/512/384/256/160/128)动态分配每帧 token 数。对超长视频,若最低分辨率仍超编码长度,则通过均匀采样减少总帧数以保留关键时序信息。 - InternVL3.5(上海 AI 实验室):三大核心技术创新。一是视觉-语言解耦部署(DvD)——将视觉编码器和 LLM 分布在独立 GPU 服务器上,通过 TCP/RDMA 单向传输视觉特征,构建"视觉处理-特征传输-语言解码"异步三级流水线,高分辨率(1344px)下提速约 2 倍。二是视觉分辨率路由器(ViR)——通过二元分类器动态判断每帧 patch 的压缩必要性(计算高/低分辨率输出的 KL 散度),对静态背景帧采用 1/16 高压缩率,对动态运动帧保留 1/4 压缩率,减少 50% 视觉 token 同时保持 99% 以上性能。三是级联强化学习——通过"离线 MPO 预热 + 在线 GSPO 优化"两阶段,提升视频逻辑推理能力(LongVideoBench 推理分数提升 6.5%)。
视频理解中的思考模型。随着 OpenAI o1 和 DeepSeek-R1 在推理领域取得的突破,一些研究者开始将推理模型应用于视频理解。上文提到的 Qwen3-VL 就有 Thinking 版本;InternVL 团队推出的 Video-Chat-R1.5 通过迭代感知(ITP)机制和基于 GRPO 的强化学习优化"时空线索选择策略";字节与清华联合推出的 Video-SALMONN2 提出多轮直接偏好优化(MrDPO),通过搭配联合奖励来提升视频字幕质量。不过,当前思考模型在视频理解中的应用仍处于早期阶段——它们主要是在文字回答中加入了思考格式,与纯文字思考模型的区别还不够本质。真正将"视觉思考"(而非仅仅"关于视觉内容的文本思考")融入模型,仍是一个开放的研究方向。
视频模型作为零样本学习者。一个值得关注的前沿方向是视频生成模型的"涌现理解能力"。Yang 等人 (2025) 对 Google 的 Veo 3 模型进行了系统性测试,涵盖感知(边缘检测、分割)、建模(物理动力学、刚体/软体模拟)、操纵(背景移除、风格迁移)和推理(图遍历、BFS 搜索、序列补全、数字排序)四个层级共 62 项定性任务和 7 项定量任务,均以零样本方式执行。
结果表明,视频生成模型能以零样本方式处理多样化的视觉任务,展现出被称为"帧链"(Chain-of-Frames)的分步推理能力。这揭示了视频模型与视觉语言模型推理方式的根本区别:
- 视觉语言模型的推理是分析性的:通过文本指令生成一系列关键静态图像,过程由外部语言逻辑驱动,侧重状态的逻辑转换。
- 视频模型的推理是模拟性的:直接生成时空连续、物理合理的视频流来演绎事件全过程,依赖内化的因果和物理规律,侧重对动态过程本身的仿真。
尽管 Veo 3 在许多专项任务上仍不及专用模型,但其能力的快速提升令人印象深刻:5×5 迷宫求解的 pass@10 成功率从 Veo 2 的 14% 跃升至 78%。研究者指出,模型表现是其能力的下界,因其高度依赖提示工程。这预示着视频生成模型有可能演变为新一代通用视觉基础模型。
23.4.3 文本到视频生成(T2V)
文本到视频生成(Text-to-Video Generation, T2V)是指从自然语言描述出发,生成连续、自然、符合物理规律的视频序列。与图像生成相比,T2V 不仅需要保证单帧质量,还必须维持帧间的时空一致性——物体运动轨迹要连贯、光影变化要合理、场景切换要自然。
在 §23.3 中,我们已详细介绍了扩散模型的基本原理:通过前向过程逐步向数据添加噪声,再训练神经网络学习逆过程从噪声中恢复数据。T2V 正是在这一基础上,将扩散过程从二维图像扩展到三维时空体积。2024 年以前,视频生成研究者主要通过 GAN 生成视频、通过 AnimateDiff 控制 Stable Diffusion 生成连续图像合成视频等方法,效果一般,并没有引起广泛关注。2024 年初的 SORA 彻底改变了这一局面。
SORA:视频生成的范式转折。2024 年 2 月,OpenAI 发布的 SORA 以端到端的高保真视频生成效果震动了整个 AI 领域。SORA 最大支持 60 秒视频生成,支持短视频前后扩展保持连续性,还支持基于视频+文本的编辑功能。虽然 SORA 是闭源模型,技术报告没有公布完整细节,但从已知信息中可以还原其核心技术框架。
SORA 的架构可以概括为:
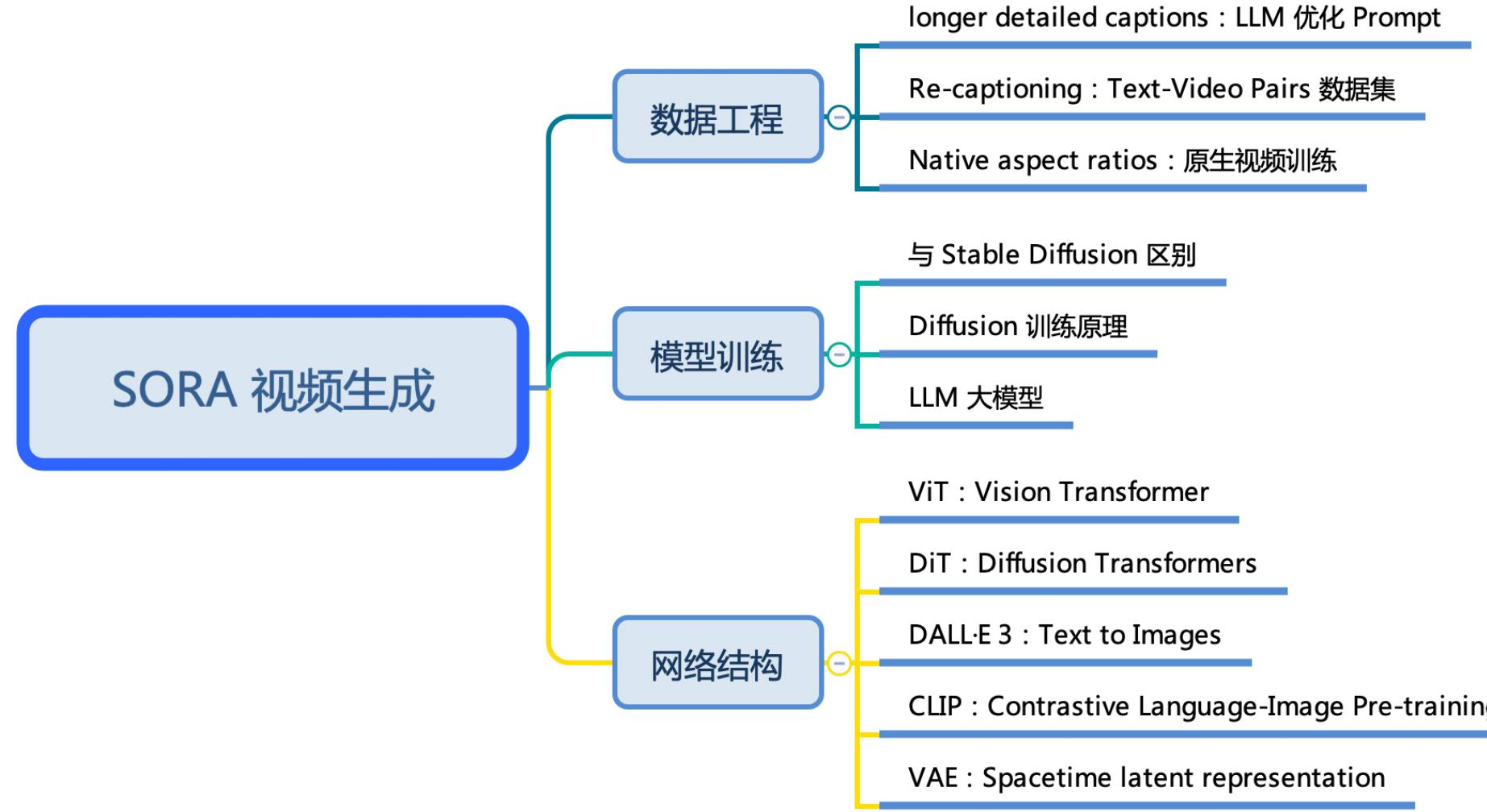
图 23-16:SORA 技术架构全景(来源:ZOMI 讲座)。SORA 的核心技术分为三大支柱:数据工程(Re-captioning、LLM 优化 Prompt、原生视频训练)、模型训练(Diffusion + Scaling Law)、网络结构(ViT + DiT + DALL-E 3 + CLIP + VAE)。
SORA 的训练流程可分为四个步骤:
- 文本条件构建:使用 DALL-E 3 中的 CLIP 模型建立文本-图像语义关联。CLIP 接受约 4 亿对 <图片-文字> 数据训练,学习给定文本与图像之间的关联。图像及文本通过各自编码器映射到
维共享空间,训练目标是最大化正确匹配对的余弦相似度(详见 §23.1)。同时利用 GPT-4 将用户简短提示扩充为包含丰富细节的长文本描述。 - 视频编码:将原始视频切分为时空 Patches(Spacetime Patches),通过 VAE 编码器压缩为低维潜空间表示。这一步是关键创新——与传统方法对视频进行固定裁剪或缩放不同,Spacetime Patches 的灵活性使模型可以直接处理不同尺寸、时长和分辨率的视频。借鉴了 NaViT(Dehghani et al., 2023)的 "Patch n' Pack" 思想,不同宽高比和分辨率的视频都可以统一表示。
- 扩散生成:以 Diffusion Transformer(DiT)为主干网络,在潜空间中完成从文本语义到视频语义的映射。回顾 §23.3 的内容,传统 Stable Diffusion 使用 U-Net 作为去噪主干,但 U-Net 的结构固定性限制了模型规模的进一步扩大。DiT(Peebles & Xie, 2023)成功用 Transformer 替代 U-Net,打开了 Scaling 的天花板。具体而言,DiT 首先将每个 patch 的潜空间表示转换为 token 序列,应用标准的 ViT Patch Embedding 和 Position Embedding,然后通过多层 Transformer Block 处理。DiT 还需要处理时间步长
、类别标签、文本语义等条件信息,其中效果最好的条件注入方式是 adaLN-Zero:通过自适应层归一化(Adaptive Layer Normalization)将条件信息编码为 scale 和 shift 参数 ,调制每一层的归一化输出,并将残差连接的缩放因子 初始化为零,确保训练初期 DiT Block 等效于恒等映射。 - 视频解码:DiT 输出的潜空间表示通过 VAE 解码器恢复为像素级视频数据。
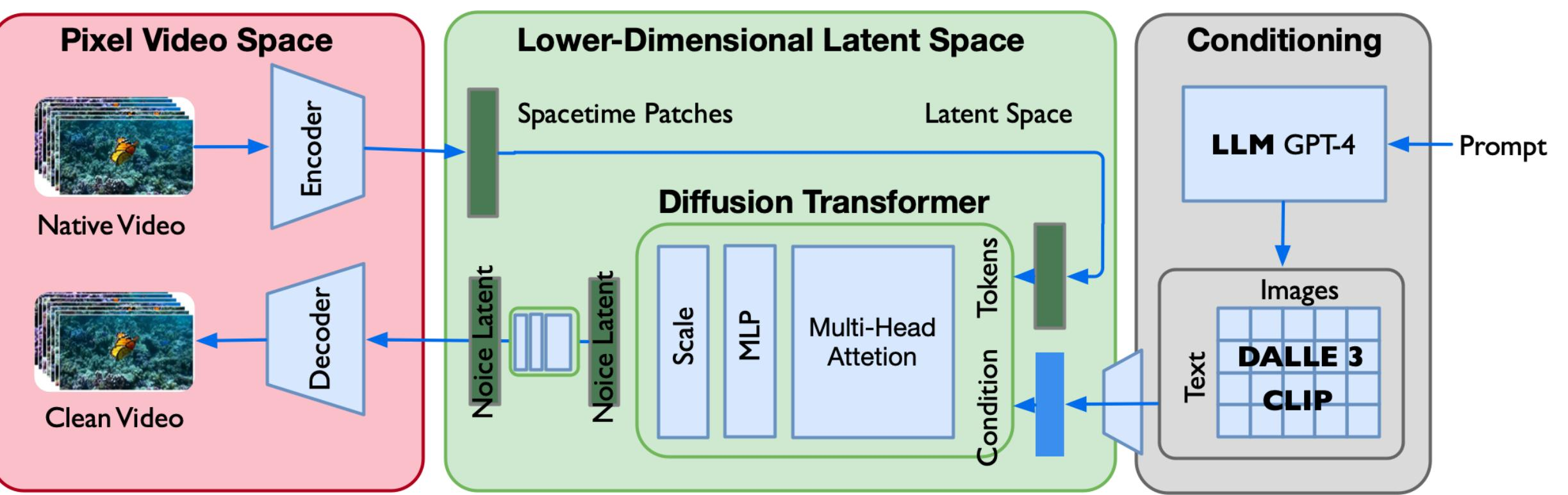
图 23-17:SORA 模型结构示意图(来源:ZOMI 讲座)。左侧为像素视频空间(Pixel Video Space),原始视频经编码器压缩、经解码器恢复;中间为低维潜空间(Lower-Dimensional Latent Space),Spacetime Patches 经 Diffusion Transformer 去噪;右侧为条件信息(Conditioning),用户 Prompt 经 GPT-4 扩充后通过 DALL-E 3/CLIP 编码为语义条件注入。
SORA 的技术突破可以从三个维度理解:
- Scaling Law 在视频生成中的验证。从 GPT-1 到 GPT-3,参数量从 1 亿增长到 1750 亿带来了质的飞跃。SORA 表明同样的规律适用于视频生成——模型规模的增大能有效解决视频的一致性和连续性问题。用 Transformer 替代 U-Net 主干正是为了打开模型规模的天花板。
- 数据工程的关键作用。使用 DALL-E 3 进行视频文本标注(Re-captioning),利用 GPT-4 扩充用户提示词,保持原始宽高比(Native Aspect Ratios)进行训练——高质量的文本描述和原生格式的视频数据对最终效果至关重要。
- 统一的表示方式。将视频统一为 Spacetime Patches 在低维潜空间中操作,使得模型可以处理各种输入格式(不同尺寸、分辨率、时长),并天然支持视频前后扩展、视频+文本编辑等灵活功能。
不过,SORA 仍存在明显局限:物理交互的细节有时会失真(如玻璃破碎效果不真实、水流模拟异常),雪地脚印等痕迹无法正确生成,说明模型尚未完全内化物理世界的规律。另外,SORA 的模型参数量估计在
从产业视角看,SORA 的意义远超技术本身。它从底层改变了内容生产方式,60 秒高保真视频生成意味着广告、短视频、影视辅助等行业的创作效率将发生质变。同时,多模态大模型训练及应用普及对算力消耗将继续增长——视频生成的推理算力比 Stable Diffusion 要大 2–3 个数量级,需要结合专用的 AI 训练/推理集群。
23.4.4 T2V 代表性开源模型
SORA 之后,多个开源和半开源模型迅速跟进,部分甚至在特定指标上达到或超越了 SORA 的水平。以下介绍两个最具代表性的工作,它们公布了较为详细的技术报告,可以帮助我们了解当前主流文生视频模型的完整技术栈。
HunyuanVideo。腾讯混元实验室推出的 130 亿参数开源视频生成基础模型,采用统一的图像-视频生成架构,支持文生视频、图生视频及视频编辑等功能。
在数据层面,HunyuanVideo 的预训练数据涵盖人、动物、风景、车辆、建筑等 8 大类场景,包含 8700 万条视频-文本对及数十亿图像-文本对,分为 5 组视频数据和 2 组图像数据,每组针对不同训练阶段定制。数据经过多重筛选流程:
- PySceneDetect 分割单镜头,拉普拉斯算子筛选清晰帧
- 内部模型去除水印和敏感信息
- 设置最小时长、空间质量、宽高比合规性、构图、颜色、曝光等多重阈值
- 自研 VLM 生成 JSON 格式结构化字幕,训练支持 14 种运动类型的运镜分类器
SFT 阶段构建了约 100 万个人工标注高质量样本,聚焦视觉吸引力强、运动细节复杂的视频,经过自动化过滤 + 人工审查双重校验。
架构层面,HunyuanVideo 的核心创新包括:
- 因果 3D VAE:通过时间 4 倍、空间 8 倍、通道 16 倍的三级压缩,将原始视频数据量降低 512 倍,同时保留运动轨迹连续性。
- 双流-单流 Transformer:前 12 层独立处理视频与文本 token(避免模态干扰),后 20 层通过跨层注意力(CLA)实现深度融合,文本-视频对齐精度提升 18.7%。
- MLLM 文本编码:采用 Decoder-only 架构的多模态大语言模型替代传统 CLIP+T5 组合,具备零样本学习、因果注意力适配和细粒度语义解析三大优势,文本对齐度达 61.8%。
- 3D RoPE:将旋转位置编码扩展至时间
、高度 、宽度 三个维度,支持多分辨率、多宽高比、不同时长的生成。
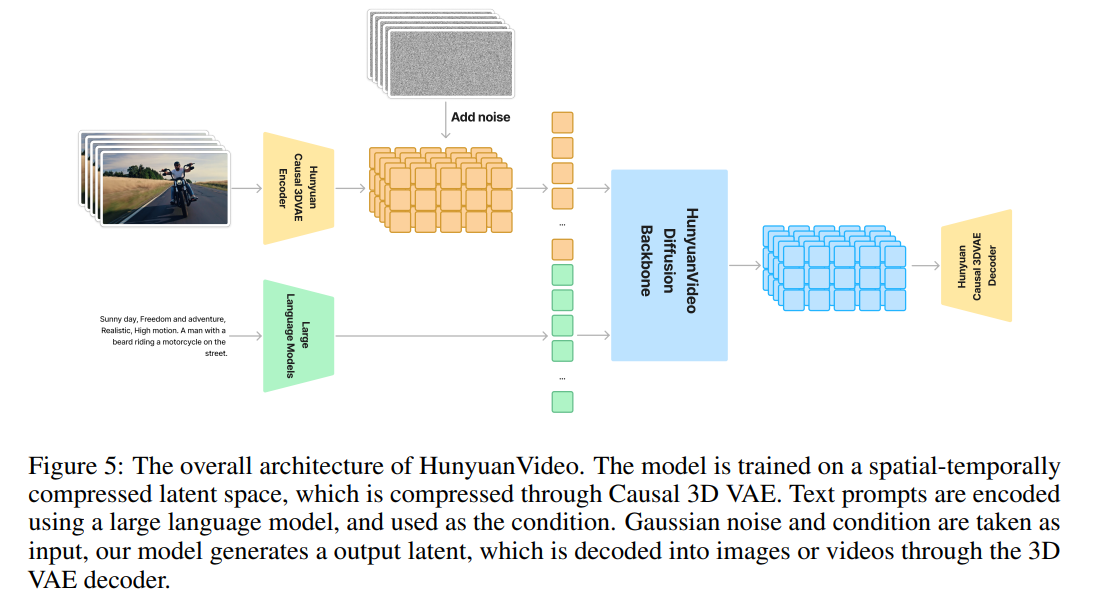
图 23-18:HunyuanVideo 整体架构(来源:Tencent, 2024)。视频经 Causal 3D VAE 压缩至潜空间,文本经 LLM 编码为条件,HunyuanVideo Diffusion Backbone(双流-单流 Transformer)在潜空间完成去噪,最终由 Causal 3D VAE Decoder 解码为视频。
训练策略是 HunyuanVideo 的另一核心。整体采用渐进式课程学习,分三个阶段逐步提升难度:
| 阶段 | 内容 | 目标 |
|---|---|---|
| 图像预训练 Phase 1 | 256px 低分辨率图像 | 学习低频视觉概念 |
| 图像预训练 Phase 2 | 512px 混合宽高比图像 | 学习多分辨率适应 |
| 视频-图像联合训练 | 低分辨率短视频 → 长视频 → 高分辨率长视频 | 时空建模能力递进提升 |
训练过程中动态调整批次大小优化 GPU 利用率,图像数据补充视频数据的稀缺性,避免灾难性遗忘。推理端结合 3D 并行训练、KV 缓存和投机解码技术,130 亿参数模型可在单张 32GB GPU 上运行,推理速度提升 2.3 倍。
在 1533 条多样化指令的专业盲测中(60 名资深视觉工程师参与),HunyuanVideo 综合得分 41.3%,全面超越 Runway Gen-3、Luma 1.6 等主流闭源模型。核心指标:运动质量 66.5%(较 Luma 1.6 提升 22.3 个百分点),文本对齐度 61.8%,视觉质量 95.7%,物理合理性 72.3 分。支持 480P–720P 分辨率、最长 129 帧视频生成。HunyuanVideo 以 Apache 2.0 协议开源(允许商业使用),成为首个比肩闭源模型的开源视频生成基础设施。
MovieGen。Meta 于 2024 年 10 月发布的多模态媒体生成模型系列,包含两大子模型:MovieGen Video(300 亿参数,负责文本到图像/视频生成,支持 16 秒 16FPS 视频)和 MovieGen Audio(130 亿参数,负责视频+文本到音频生成,支持 48kHz 高质量音频)。
MovieGen 的数据策略同样精细:约 1 亿视频-文本对和 10 亿图像-文本对用于预训练,原始视频时长 4 秒至 2 分钟,通过视觉过滤(清晰度、无敏感信息)、动作过滤(剔除低动作幅度内容)、内容过滤(去重、多样性采样)三阶段处理。此外训练了支持 16 类运镜(如变焦、平移)的运镜分类器,为模型学习电影级镜头语言提供标注。
核心技术亮点包括:
- 时间自编码器(TAE):基于图像 VAE 参数膨胀为 3D 结构,采用 2+1D 轻量化设计(2D 空间卷积 + 1D 时间卷积、2D 注意力 + 1D 时间注意力),在时间/空间维度各下采样 8 倍,通道数设为 16 以平衡效果与效率。TAE 通过联合图像和视频训练,使同一个编码器可以同时处理静态图像和动态视频。
- Flow Matching 生成框架:替代传统 DDPM 噪声调度,通过学习从噪声到目标数据的"速度预测"生成样本(参见 §23.3 中 Flow Matching 的介绍),训练效率更高,天然支持零终端信噪比,时空连续性也更好。MovieGen 借鉴了 Llama 3 的 Transformer 结构进行优化,最大上下文长度达 73K 视频 token。
- 多文本编码器:联合 UL2(全局语义)、ByT5(字符级局部理解)和 Long-prompt MetaCLIP(跨模态对齐)三个编码器,三者互补以实现从全局语义到局部字符的精准文本理解。
- 效率优化:因子化可学习位置编码(适配任意宽高比和时长)、时间平铺(切片编码 + 重叠融合,支持长视频处理)、线性-二次时间步长调度(50 步采样等效于传统 1000 步的效果)。
- 个性化与编辑能力:MovieGen 还支持个性化视频生成(保留人物 ID 特征)和指令级视频编辑,后者创新地采用无监督数据训练方案,规避了大规模监督编辑数据缺失的问题。
MovieGen 支持 1080P 高清输出和可变宽高比。在人工评价中,MovieGen 相比 Runway Gen-3 的整体质量净胜率为 35.02%,相比 LumaLabs 为 60.58%,与 OpenAI SORA 基本持平(8.23%,在 2σ 区间内)。细分来看,MovieGen 在文本对齐(17.72% vs SORA)和运动完整性(8.86%)上有优势,但在 Kling 1.5 面前整体质量仅持平(3.87%)。
两者的比较与启示。对比 HunyuanVideo 和 MovieGen,可以总结出当前 T2V 模型的几个共性技术趋势:
- 3D VAE 压缩是标配:无论是 HunyuanVideo 的因果 3D VAE 还是 MovieGen 的 TAE,都采用时空联合压缩将视频映射到低维潜空间,大幅降低后续扩散/流匹配模型的计算压力。
- 文本编码器越来越强:从 CLIP 到 CLIP+T5 组合,再到 MLLM 或多编码器联合,文本理解的精准度直接决定生成视频与描述的一致性。
- 位置编码的三维扩展:3D RoPE 和因子化可学习位置编码都在解决同一个问题——如何在时间、高度、宽度三个维度上灵活编码位置信息,以支持可变分辨率和时长。
- 数据质量优于数据规模:两者的数据策略都强调多阶段筛选和高质量 SFT 数据,"海量预训练打基础 + 高质量 SFT 提质感"已成为业界共识。
- 渐进式训练:从低分辨率到高分辨率、从短视频到长视频的渐进课程学习,在稳定训练的同时逐步提升生成质量。
23.4.5 视频生成的挑战与展望
视频生成技术已从"短低清"阶段迈入"长高清"阶段,但仍面临多个核心挑战:
物理一致性。当前模型在复杂物理交互场景(如多人快速互动、流体模拟、碰撞与破碎)中仍会出现细节失真。模型学到的更多是统计层面的视觉规律,而非真正理解底层物理定律。如何让模型内化因果关系和物理约束,是从"生成好看的视频"到"模拟真实世界"的关键跨越。
长视频生成。主流模型的生成时长普遍在 5–16 秒(HunyuanVideo 最长 129 帧约 5 秒,MovieGen 支持 16 秒),距离分钟级甚至更长的视频仍有较大差距。长视频生成面临三重挑战:(1)计算资源随帧数近似线性甚至超线性增长;(2)需要跨片段维持时空一致性——人物外观不变、场景逻辑连贯、运动趋势延续;(3)长程叙事的语义连贯性——视频内容需要遵循某种"故事线"而非简单地拼接短片段。一些工作(如 WAN-S2V 的 Frame Pack 模块和 HunyuanVideo-Avatar 的 Time-aware Position Shift Fusion)通过对早期运动帧施加更高压缩比或分段生成+重叠融合来延长可处理序列,但从根本上解决这一问题仍需架构层面的创新。
生成效率与部署成本。训练 SORA 级别的模型需要数千张高端 GPU(MovieGen 的训练最高使用 6144 张 H100),推理端的算力需求也比图像生成高 2–3 个数量级。如何通过架构优化(如时空稀疏注意力、动态分辨率路由)和系统优化(如 PD 分离、投机解码、模型量化)降低成本,直接决定了视频生成的商业化前景。
可控性。用户不仅需要"生成一段好看的视频",更需要精确控制镜头运动(推拉摇移)、角色动作(跑步、转身、微笑)、场景切换(淡入淡出、硬切)等细节。当前的文本条件控制粒度仍然有限——用户很难仅通过一段文字描述精确指定每一秒的画面内容。音频驱动视频生成(如腾讯的 HunyuanVideo-Avatar、阿里的 WAN-S2V)通过"文本控制全局 + 音频控制细节"的协同方式取得了进展,MovieGen 训练运镜分类器标注 16 类镜头运动也是一种尝试。但实现"导演级"的细粒度可控生成——让用户像使用专业视频编辑软件一样精确控制每个镜头——仍是产品化的核心需求。
伦理风险。高质量视频生成技术不可避免地带来深度伪造(Deepfake)的风险。当生成的视频逼真到普通人无法区分真伪时,虚假信息、身份冒用、舆论操纵等问题将变得更加严峻。如何在技术创新与伦理规范之间找到平衡——建立可靠的视频溯源机制(如数字水印、内容来源认证)、内容真伪检测方法和法规框架——是全行业必须面对的课题。
AI 基础设施挑战。视频生成不像 LLM 已经统一了训练范式,视频大模型的训练场景变化快速。对 AI 编译器的挑战尤其大——需要提供如 CUDA 般灵活的编程体系并拓展应用生态。同时,视频处理中大量的图像/视频预处理(传统在 CPU 上完成)正在向 GPU 迁移(如 NVIDIA DALI),这对整个 AI 基础设施栈都提出了新的要求。
音频驱动视频生成。除了文本驱动外,音频驱动的视频生成也是重要方向。腾讯的 HunyuanVideo-Avatar 基于 MM-DiT 架构,通过角色图像注入模块(保持身份一致性)、音频情感模块 AEM(对齐音频情感与面部表情)和面部感知音频适配器 FAA(实现多角色独立驱动)三大创新,在音画同步和身份保持上均达到领先水平。阿里的 WAN-S2V 则首次将音频驱动从"单角色语音"扩展到"复杂影视场景",通过文本-音频协同(文本控全局、音频控细节)实现细腻角色互动与动态镜头。这些工作预示着"多模态协同驱动"将成为视频生成的重要范式。
展望未来,视频理解与生成正走向深度融合。一方面,视频理解模型为生成提供语义条件和质量评估;另一方面,生成模型展现出的"帧链"推理能力暗示,视频生成本身可能成为一种新的推理方式——通过在心智中"播放"视频来模拟和预测世界的演变。
从更大的视角看,视频生成模型可能是通向世界模型(World Model)的关键路径之一。SORA 技术报告的标题"Video Generation Models as World Simulators"正反映了这一雄心——当一个模型能够准确地生成视频来描述世界的运行方式时,它在某种意义上已经"理解"了世界。NVIDIA 的 Cosmos 世界基础模型系列也在朝着同一方向探索,试图构建能够理解和模拟物理世界的通用视频模型。
未来发展可能聚焦三个方向:一是高效长视频处理,通过动态分辨率路由、稀疏化注意力等技术,在有限计算资源下支持小时级视频的连贯理解和生成;二是细粒度时空对齐,强化帧级内容与时间戳的精准绑定,提升事件定位、动作追踪等任务的精度;三是跨模态推理深化,结合强化学习等方法增强模型对视频中因果关系、意图预测等复杂语义的解析能力。此外,多源数据融合(视频与音频、字幕的协同建模)和低资源场景适配也是重要方向。随着技术迭代,多模态大模型有望从被动理解向主动推理演进。
本节小结。本节梳理了视频技术从理解到生成的完整脉络:
- 视频理解经历了从手工特征(SIFT/HOG)到双流网络(光流作为运动先验)、3D CNN(I3D 的 Inflate + Bootstrapping)、Video Transformer(TimeSformer 的拆分时空注意力)的技术演进,每一代都在解决前一代的核心瓶颈。
- 多模态大模型视频理解通过"视觉编码器 + LLM"的统一范式实现了语义级深度理解。M-RoPE 及其迭代升级(绝对时间对齐、Interleave 策略)使模型能处理从秒级到小时级的视频。动态帧分辨率采样、视觉 token 压缩等技术在效率与性能间取得了平衡。
- 视频生成以扩散模型为基础,通过 Spacetime Patches + DiT 架构和 Scaling Law 的驱动,在 SORA 之后迎来爆发式发展。HunyuanVideo 和 MovieGen 等工作通过因果 3D VAE 压缩、Flow Matching、渐进式课程学习等技术栈推动了开源生态建设。
- 理解与生成的融合是未来最值得期待的方向。生成模型展现出的"帧链"推理能力表明,视频生成可能成为一种全新的推理范式。能够真正"理解"物理世界的视频模型,也必然能够"生成"符合物理规律的视频,反之亦然——这正是通向世界模型的关键路径。