19.5 模型压缩与量化
一个拥有 70B 参数的大语言模型,以 FP16 存储需要约 140 GB 显存——这远远超出了单张消费级 GPU 的容量。即便是工业级推理集群,如此巨大的模型也意味着高昂的带宽开销和缓慢的推理速度。模型压缩(Model Compression)正是为了解决这一矛盾而生的一系列技术的总称,其核心目标是:在尽量保持模型能力的前提下,减少模型的存储体积和计算开销,使大模型能够在更广泛的硬件上高效运行。
本节聚焦三种最主要的压缩手段:量化(Quantization)、知识蒸馏(Knowledge Distillation)和剪枝(Pruning)。其中量化是当前大模型部署中应用最广、效果最立竿见影的技术,我们将用最多的篇幅展开讨论。
19.5.1 为什么需要量化
大模型推理的性能瓶颈往往不在计算,而在内存带宽。以自回归生成为例,每生成一个 Token 都需要从显存中读取全部模型参数,而 GPU 的内存带宽(如 A100 的 2 TB/s)相比其计算能力(如 312 TFLOPS)是更稀缺的资源。量化通过将参数从高精度(FP32/FP16)转换为低精度(INT8/INT4/FP8),直接减小每次读取的数据量,从而缓解带宽瓶颈、提升推理速度。
下表总结了主要的数值格式及其特点:
| 格式 | 总位数 | 结构 | 相对 FP32 内存占用 | 典型用途 |
|---|---|---|---|---|
| FP32 | 32 | S(1) E(8) M(23) | 1x(基准) | 训练基准 |
| BF16/FP16 | 16 | S(1) E(8) M(7) / S(1) E(5) M(10) | 50% | 混合精度训练与推理 |
| FP8 | 8 | E4M3 / E5M2 | 25% | H100 等新硬件的推理加速 |
| INT8 | 8 | S(1) V(7) | 25% | 最常用的推理量化格式 |
| INT4 | 4 | S(1) V(3) | 12.5% | 极致压缩,需高级量化算法 |
表 19-1:常见数值格式对比。
量化的基本过程可以用一个线性映射来描述。对于对称量化(Absmax),将浮点值
其中
量化的精度取决于量化粒度——为多少个参数共享一组缩放因子。粒度从粗到细排列为:
- 逐张量(per-tensor):整个权重矩阵共享一个
,最简单但精度最低 - 逐通道/逐行(per-channel / per-row):每行或每列一个
,平衡精度与开销 - 逐组(group-wise):每
个参数一组(如 ),精度更高但存储开销增加
19.5.2 量化方法谱系
根据量化发生的时机和对象,主流方法可以分为三大类。
训练后量化(Post-Training Quantization, PTQ)。 在模型训练完成后,无需重新训练即可完成量化。PTQ 是部署中最常用的路径,因为它不需要访问原始训练数据,只需少量校准数据甚至无需数据。PTQ 又可细分为:
- 权重量化(Weight-only Quantization):仅量化权重,激活值在推理时仍以 FP16 计算。代表方法有 GPTQ、AWQ。这条路线实现简单、精度损失可控,但由于激活值未被压缩,加速效果有限。
- 权重+激活量化(Weight-Activation Quantization):同时量化权重和激活值。代表方法有 LLM.int8()、SmoothQuant。这条路线压缩更彻底,但激活值的动态范围大、分布不规则,量化难度显著更高。SmoothQuant 的核心思想是在量化前通过逐通道缩放,将激活值中的量化难度"转移"到权重上——因为权重的分布通常比激活值更均匀,更容易量化。具体来说,它为每个通道引入一个缩放因子
,令 、 ,使得变换后的激活值和权重都更加"平坦",从而同时适合 INT8 量化。
量化感知训练(Quantization-Aware Training, QAT)。 在训练过程中模拟量化误差,让模型学会适应低精度表示。QAT 通常能获得比 PTQ 更好的精度,但需要完整的训练流程和数据,计算成本高。
量化感知微调(QLoRA)。 这是 QAT 思路在参数高效微调中的应用。§13.3 已详细介绍了 QLoRA 的原理:将预训练权重以 NF4 格式冻结存储,仅训练低秩 LoRA 适配器。从部署角度看,QLoRA 本身就完成了权重的 4-bit 量化,微调后的模型可以直接以量化形式部署推理。
19.5.3 INT8 量化:LLM.int8()
INT8 是目前应用最广泛的量化精度,其核心挑战在于如何处理大模型中的异常激活值(outlier features)。当模型参数规模超过约 6.7B 时,Transformer 所有层中都会涌现出数量极少(约 0.1%)但幅度极大(可达正常值 20 倍以上)的异常特征维度。这些异常值一旦参与量化,就会独占大部分量化区间,导致其余 99.9% 的正常值被压缩到极少数几个整数级别上,精度急剧崩溃。
LLM.int8() 提出了一种优雅的解决方案——混合精度分解(Mixed-precision Decomposition):将矩阵乘法拆分为两条路径,异常值走 FP16 高精度路径,正常值走 INT8 高效路径,最后将结果相加。
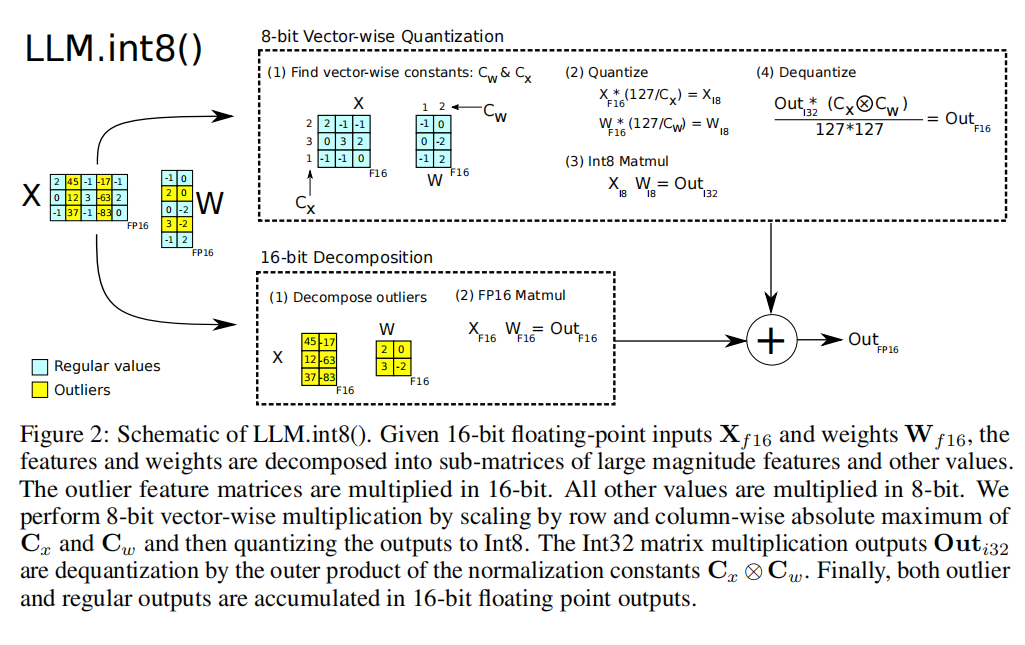
图 19-7:LLM.int8() 的混合精度分解流程。
具体步骤如下:
- 异常值检测与分离:设定幅度阈值
(默认 6.0),扫描输入激活矩阵 ,找出所有满足 的特征维度,归入异常值集合 。 - 向量级 INT8 量化:对正常值部分,为输入矩阵的每一行和权重矩阵的每一列分别计算独立的缩放因子,进行 INT8 量化:
- INT8 矩阵乘法:量化后的矩阵相乘,结果累加到 INT32 以防溢出。
- 反量化与合并:用缩放因子外积的倒数将 INT32 结果反量化为 FP16;同时将异常值部分以 FP16 执行标准矩阵乘法;最后将两部分结果相加得到最终输出。
在实际使用中,LLM.int8() 已被集成到 bitsandbytes 库中,只需一行代码即可启用:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
load_in_8bit=True, # 启用 LLM.int8() 量化
device_map="auto",
)
# 模型显存占用从约 14 GB 降至约 7 GB19.5.4 INT4 量化:GPTQ 与 AWQ
INT4 只有 16 个可能的取值(-8 到 7),表示能力极为有限。直接使用简单的线性量化会导致模型性能严重下降。因此,INT4 量化方法需要更精巧的算法来最小化量化误差。
GPTQ 的核心思想来源于经典的最优脑量化(Optimal Brain Quantization, OBQ)框架,但将其从逐权重的贪心更新改进为逐列批量处理,大幅提升了效率。其基本流程是:
- 使用少量校准数据(如 128 条样本)收集每一层的输入激活值
- 对权重矩阵逐列量化:将当前列量化为 INT4 后,利用 Hessian 矩阵的信息计算量化误差,并将误差补偿到尚未量化的列上
- 这种"量化-补偿"的迭代过程使得最终的总体量化误差远小于独立量化每列的误差
GPTQ 的量化误差补偿公式为:
其中
AWQ(Activation-aware Weight Quantization) 采用了一个更简洁的洞察:权重的重要性不是均匀的,那些对应于激活值幅度较大的通道的权重更加重要。AWQ 通过在激活值统计的基础上为每个通道计算一个缩放因子,在量化前先放大重要通道的权重,使其在量化后能保留更多精度:
其中
从工程角度看,AWQ 相比 GPTQ 的一个重要优势是对不同提示和任务的泛化性更好。GPTQ 的误差补偿依赖于校准数据的具体分布,如果校准数据与实际使用场景差异较大,可能导致量化精度不理想。而 AWQ 的缩放因子仅基于激活值的统计特征(通道级绝对值最大值),对具体输入内容的依赖更弱。
Group Quantization(分组量化) 是 INT4 方法中普遍采用的技术:将权重矩阵的每一行按固定大小(如 128 个元素)分组,每组使用独立的缩放因子和零点。分组越小,量化精度越高,但额外的元数据存储也越多。GPTQ 和 AWQ 通常默认使用 group_size=128 的分组量化。
下面的示例展示了使用 AutoGPTQ 进行 4-bit 量化的典型流程:
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 配置 GPTQ 量化参数
gptq_config = GPTQConfig(
bits=4, # 4-bit 量化
group_size=128, # 每 128 个权重一组
dataset="c4", # 校准数据集
desc_act=True, # 按激活值排序量化顺序
)
# 加载并量化模型
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=gptq_config,
device_map="auto",
)
# 7B 模型从约 14 GB 压缩至约 4 GB19.5.5 FP8 量化
FP8 是近年来随 NVIDIA H100/B200 等新硬件普及而兴起的量化格式。与 INT8 不同,FP8 保留了浮点数的指数-尾数结构,因此天然具备更好的动态范围适应能力。FP8 有两种主要变体:
- E4M3(4 位指数 + 3 位尾数):精度较高,动态范围适中,适合前向传播中的权重和激活值
- E5M2(5 位指数 + 2 位尾数):动态范围更大但精度较低,适合反向传播中的梯度
在推理场景中,FP8 的优势在于:它无需像 INT8 那样处理异常值问题(浮点格式本身能表示大范围的数值),且硬件原生支持 FP8 的 Tensor Core 运算,无需额外的量化/反量化开销。在 H100 上,FP8 推理吞吐量约为 FP16 的 2 倍,且精度损失通常可以忽略不计。
FP8 量化通常采用延迟缩放(Delayed Scaling)策略:不在量化时即时计算缩放因子,而是维护一个滑动窗口,记录过去若干步的激活值最大值(amax history),据此估计下一步的缩放因子。这种方式避免了每次都扫描整个张量来计算 amax 的开销,在保持量化精度的同时提升了吞吐量。
在主流推理框架中,TensorRT-LLM 和 vLLM 均已内置 FP8 支持。典型用法是在模型加载时指定 dtype="fp8",框架会自动完成权重的 FP8 转换和推理时的精度管理。对于训练场景,NVIDIA 的 Transformer Engine 库提供了透明的 FP8 混合精度训练支持,前向传播使用 E4M3,反向传播使用 E5M2,主权重仍以 BF16/FP32 保存。
19.5.6 量化方法谱系总览
下表横向对比了主流量化方法的关键特征:
| 方法 | 精度 | 量化对象 | 是否需要校准数据 | 关键技术 | 典型工具 |
|---|---|---|---|---|---|
| LLM.int8() | W8A8 | 权重 + 激活 | 否 | 混合精度分解 | bitsandbytes |
| SmoothQuant | W8A8 | 权重 + 激活 | 少量 | 逐通道缩放迁移 | SmoothQuant |
| GPTQ | W4A16 | 仅权重 | 少量 | Hessian 误差补偿 | AutoGPTQ |
| AWQ | W4A16 | 仅权重 | 少量 | 激活感知缩放 | AutoAWQ |
| FP8 | W8A8 | 权重 + 激活 | 否 | 硬件原生浮点 | TensorRT-LLM |
| QLoRA | W4 (NF4) | 仅权重 | 训练数据 | NF4 + 双重量化 + LoRA | bitsandbytes + PEFT |
| FlatQuant | W4A4 | 权重 + 激活 | 少量 | Kronecker 仿射变换 | — |
表 19-2:主流量化方法对比。QLoRA 属于量化感知微调,与其他 PTQ 方法定位不同。
以一个 7B 参数模型为例,各量化方案的显存占用大致如下:
| 量化方案 | 每参数字节数 | 模型显存占用 | 相对 FP16 |
|---|---|---|---|
| FP16(基准) | 2 B | ~14 GB | 1.0x |
| INT8 (W8A8) | 1 B | ~7 GB | 0.5x |
| FP8 (W8A8) | 1 B | ~7 GB | 0.5x |
| INT4 (W4A16, group=128) | ~0.56 B | ~4 GB | 0.28x |
| INT4 + 双重量化 (NF4) | ~0.52 B | ~3.6 GB | 0.26x |
表 19-3:7B 模型在不同量化方案下的显存占用估算。INT4 方案的实际占用略高于理论值 0.5 B/param,因为需要存储分组缩放因子。
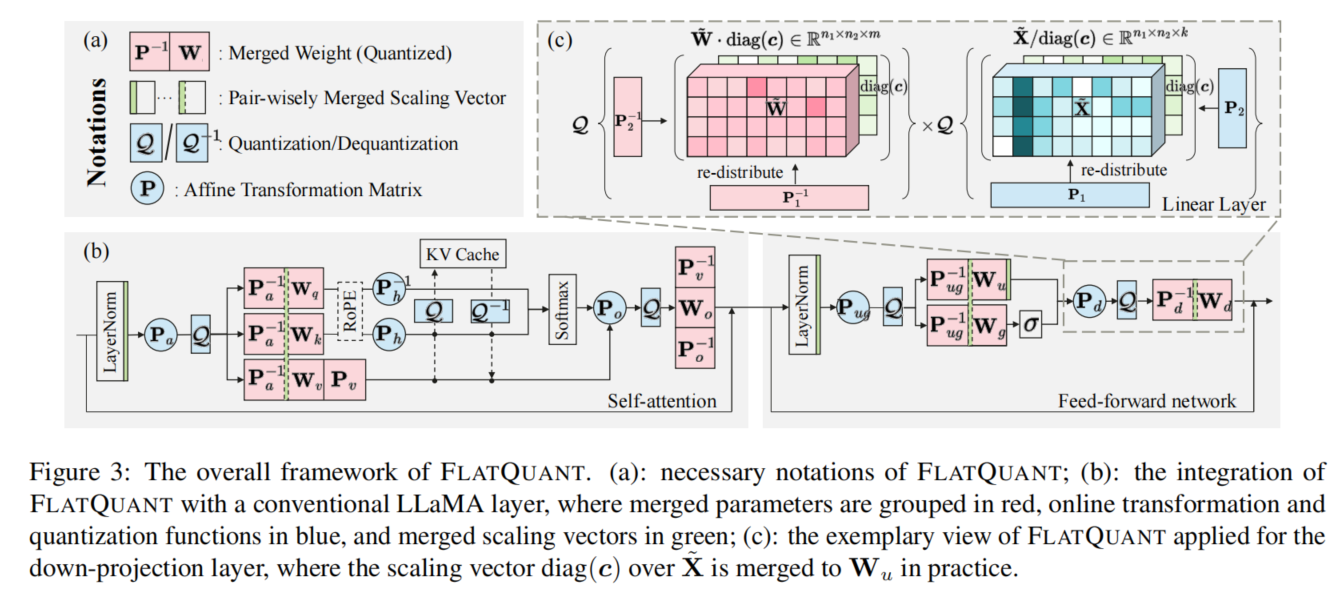
图 19-8:FlatQuant 的整体框架。通过可学习的仿射变换将权重和激活值分布重塑为更平坦的形态,提升 INT4 量化的精度。
19.5.7 知识蒸馏在部署中的角色
知识蒸馏(Knowledge Distillation, KD)在第 14 章已有详细讨论。在部署场景中,蒸馏扮演着与量化互补的角色:量化是在同一个模型上减少数值精度,而蒸馏是用一个更小的模型来替代原模型。
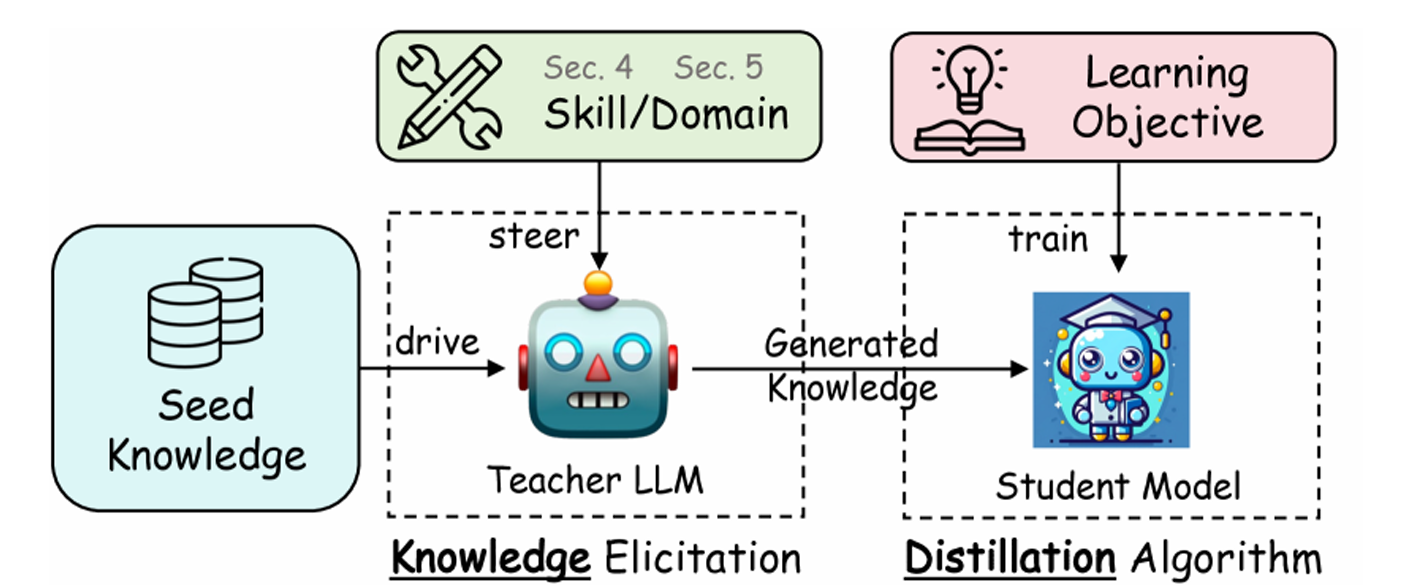
图 19-9:蒸馏在大模型部署中的典型流程。教师模型生成知识,学生模型学习后用于推理。
部署导向的蒸馏有几种常见模式:
- 离线蒸馏:教师模型在大量数据上生成输出(logits 或生成文本),学生模型通过最小化与教师输出的 KL 散度来学习。DeepSeek-R1 的技术报告中就展示了如何将 671B 的大模型蒸馏到 1.5B-70B 的多个规模。
- 在线蒸馏:教师和学生同时在线运行,学生在每个训练步实时获取教师的输出作为指导。精度更高但计算成本也更高。
- 自蒸馏(Self-distillation):模型蒸馏自身——用模型的强能力(如思维链推理)生成训练数据,再用这些数据微调同一个模型或其轻量版本。
蒸馏训练的总损失通常结合软标签损失(KL 散度)和硬标签损失(交叉熵):
其中
在实践中,蒸馏和量化经常联合使用:先将大模型蒸馏为小模型,再对小模型进行 INT4/INT8 量化,实现双重压缩。例如,将 70B 模型蒸馏到 7B,再以 INT4 量化,最终模型仅需约 4 GB 显存,即可在单张消费级 GPU 上运行。
19.5.8 模型剪枝
剪枝(Pruning)通过移除模型中"不重要"的参数或结构来减少模型大小和计算量。根据移除的粒度,剪枝分为两大类。
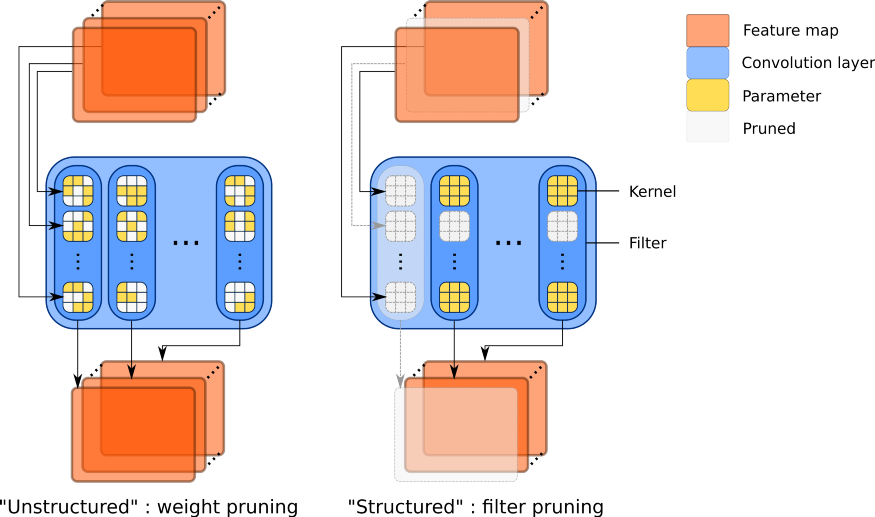
图 19-10:非结构化剪枝(左)与结构化剪枝(右)的示意对比。
非结构化剪枝(Unstructured Pruning)。 将权重矩阵中绝对值较小的元素直接置零,不改变矩阵的形状。例如,将 50% 的权重置零后,权重矩阵变成了稀疏矩阵。非结构化剪枝在理论上可以达到很高的稀疏度(如 90%)而仅有微小的精度损失,但问题在于:通用硬件(GPU)对稀疏矩阵的加速支持有限。除非使用专门的稀疏计算库或硬件(如 NVIDIA 的 2:4 稀疏模式),否则稀疏矩阵的实际运行速度并不比稠密矩阵快多少。
NVIDIA Ampere 及后续架构支持 2:4 结构化稀疏(N:M sparsity)模式:在每 4 个连续元素中必须恰好有 2 个为零。这是一种介于非结构化和完全结构化之间的折中方案——稀疏模式足够规则以利用专用硬件加速(Sparse Tensor Core 可实现约 2 倍加速),同时灵活性也足以保持较好的精度。
SparseGPT 是非结构化剪枝在大模型上的代表工作。它借鉴了 GPTQ 的思路,在剪枝某个权重后,利用 Hessian 信息补偿剩余权重,使得层输出的变化最小化。SparseGPT 可以在无需重新训练的情况下,将大模型剪枝到 50-60% 的稀疏度(包括 2:4 模式),且精度损失很小。其核心公式与 GPTQ 一脉相承——将剪枝视为一种特殊的"量化"(量化到 0),然后用误差补偿来最小化输出偏差。
结构化剪枝(Structured Pruning)。 以更粗的粒度移除——整个注意力头、整个 FFN 神经元、甚至整个 Transformer 层。移除后模型的形状(维度)实际改变了,因此可以直接用标准的稠密矩阵运算加速,无需特殊硬件支持。但结构化剪枝的难度在于,移除一个完整的结构单元通常会导致更大的精度损失,需要配合微调来恢复性能。
LLM-Pruner 是结构化剪枝的代表方法。它分三步工作:(1) 通过梯度信息识别哪些结构单元(如注意力头、FFN 中间维度)对模型输出的贡献最小;(2) 移除这些单元;(3) 用 LoRA 进行少量微调恢复精度。
在大模型部署的实际选择中,剪枝的使用频率远低于量化。原因在于:量化可以在几乎不损失精度的前提下直接压缩 2-4 倍,且不改变模型结构,部署简单;而剪枝要达到类似的压缩比通常需要额外的微调过程,且在通用硬件上的加速效果有限。不过,剪枝与量化并不矛盾——可以先剪枝减少模型规模,再量化进一步压缩,两者是正交的优化维度。
稀疏性与量化的联合优化正在成为研究热点。例如,SparseGPT + GPTQ 的组合可以同时实现 50% 稀疏度和 4-bit 量化,使模型的有效存储量压缩到原来的约 1/8。在支持 2:4 稀疏 Tensor Core 的硬件上,这种组合可以实现约 4 倍的推理加速。
19.5.9 实践指南:如何选择压缩策略
面对一个需要部署的大模型,工程师通常按以下优先级选择压缩方案:
首选 INT8 量化:精度损失极小,部署简单,几乎适用于所有场景。使用 bitsandbytes 的
load_in_8bit=True或推理框架(如 vLLM、TensorRT-LLM)的内置 INT8 支持即可。显存紧张时选 INT4:当 INT8 仍然放不下时,使用 GPTQ 或 AWQ 进行 4-bit 权重量化。GPTQ 量化耗时较长但精度略好;AWQ 量化速度快,且在不同模型上的鲁棒性更强。两者在 llama.cpp、vLLM、TensorRT-LLM 等主流推理框架中均有良好支持。
H100/B200 硬件优先选 FP8:新一代 GPU 原生支持 FP8 计算,精度接近 FP16 且吞吐量翻倍,是最"无痛"的量化选择。
需要极致压缩时考虑蒸馏+量化:先蒸馏出更小的模型,再对小模型量化。这种方案的压缩比最高,但需要额外的训练资源。
剪枝作为补充手段:在特定场景下(如边缘设备部署、定制化硬件),结构化剪枝可以作为量化的补充。
关于 llama.cpp 与 GGUF 格式。 在端侧和 CPU 推理场景中,llama.cpp 是最流行的推理引擎之一。它使用 GGUF(GPT-Generated Unified Format)格式存储量化模型,支持从 Q2_K 到 Q8_0 的多种量化级别。以"Q4_K_M"为例,Q 表示量化,4 表示主体精度为 4-bit,K 表示使用 k-quant(分组量化),M 表示中等质量。在 Hugging Face 上可以直接找到社区预量化的 GGUF 模型,下载后即可用 llama.cpp 的 llama-server 或 ollama 等工具直接运行。
下面的代码展示了一个典型的"从加载到量化推理"的完整流程:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 方案 1:INT8 量化(最简单)
model_int8 = AutoModelForCausalLM.from_pretrained(
model_id, load_in_8bit=True, device_map="auto"
)
# 方案 2:INT4 量化(更激进)
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # NF4 量化(正态分布感知)
bnb_4bit_use_double_quant=True, # 双重量化,进一步压缩
bnb_4bit_compute_dtype=torch.float16, # 计算时反量化为 FP16
)
model_int4 = AutoModelForCausalLM.from_pretrained(
model_id, quantization_config=bnb_config, device_map="auto"
)
# 推理
inputs = tokenizer("大模型量化的核心目标是", return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model_int4.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))小结
模型压缩是大模型从实验室走向生产环境的关键桥梁。量化是当前最成熟、最实用的压缩技术——INT8 量化几乎零精度损失地将模型体积减半,INT4 量化在分组量化和误差补偿(GPTQ/AWQ)的帮助下可以将模型压缩到原来的四分之一,FP8 则在新硬件上提供了精度与速度的最佳平衡。知识蒸馏通过"以大教小"实现更激进的模型缩减,与量化联合使用可以达到数十倍的压缩比。剪枝提供了另一个正交的压缩维度,尤其是结构化剪枝在定制化部署中有独特价值。在实际工程中,这三种技术往往不是非此即彼的选择,而是可以灵活组合的工具箱。