13.1 LoRA 原理
当模型参数从数十亿增长到数千亿,全参数微调(Full Fine-Tuning)的代价变得令人望而却步——不仅需要存储完整的模型参数副本,还要为每个参数维护梯度和优化器状态(Adam 的一阶矩与二阶矩通常是参数量的 4 倍以上)。一个自然的疑问由此产生:微调真的需要更新所有参数吗?
研究表明,尽管预训练模型的参数空间维度极高,但模型在适应特定下游任务时,权重的变化实际上位于一个**极低的内在维度(Low Intrinsic Dimension)**空间中。换言之,微调所需的"有效自由度"远小于参数总数。**LoRA(Low-Rank Adaptation)**正是基于这一洞察,通过低秩矩阵分解来近似权重更新,以极少的可训练参数达到接近甚至媲美全参数微调的效果。
本节将从数学原理出发,详细剖析 LoRA 的核心机制,并从零实现一个完整的 LoRA 层,随后介绍其主流变体 QLoRA、AdaLoRA 和 DoRA。
13.1.1 低秩分解的数学基础
在 Transformer 架构中,线性层无处不在。注意力机制中的
其中
LoRA 的核心假设是:
其中
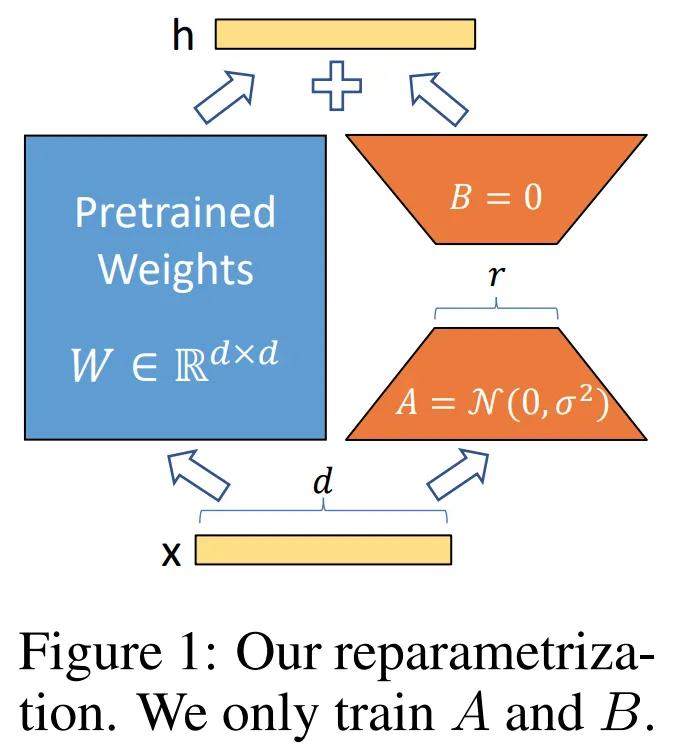
图 13-1:LoRA 的重参数化结构。左侧的预训练权重
这里的
参数量对比。 全参数微调需要更新
以 Llama-7B 的注意力层为例,
13.1.2 初始化策略与训练机制
LoRA 的初始化策略看似简单,实则经过精心设计:
- 矩阵
:使用高斯随机初始化(Kaiming 或标准正态分布) - 矩阵
:初始化为全零矩阵
这一设计的目的是确保训练起始时
为什么不能两者都初始化为零? 如果
为什么零初始化的是
训练流程。 LoRA 的训练过程非常直观:
- 冻结:将预训练模型的所有参数设为不可训练(
requires_grad = False) - 注入:在目标线性层旁并联 LoRA 模块
- 训练:仅优化
和 的参数,复用原有的训练数据和流程 - 合并:训练结束后,将
加回 ,部署时无额外开销
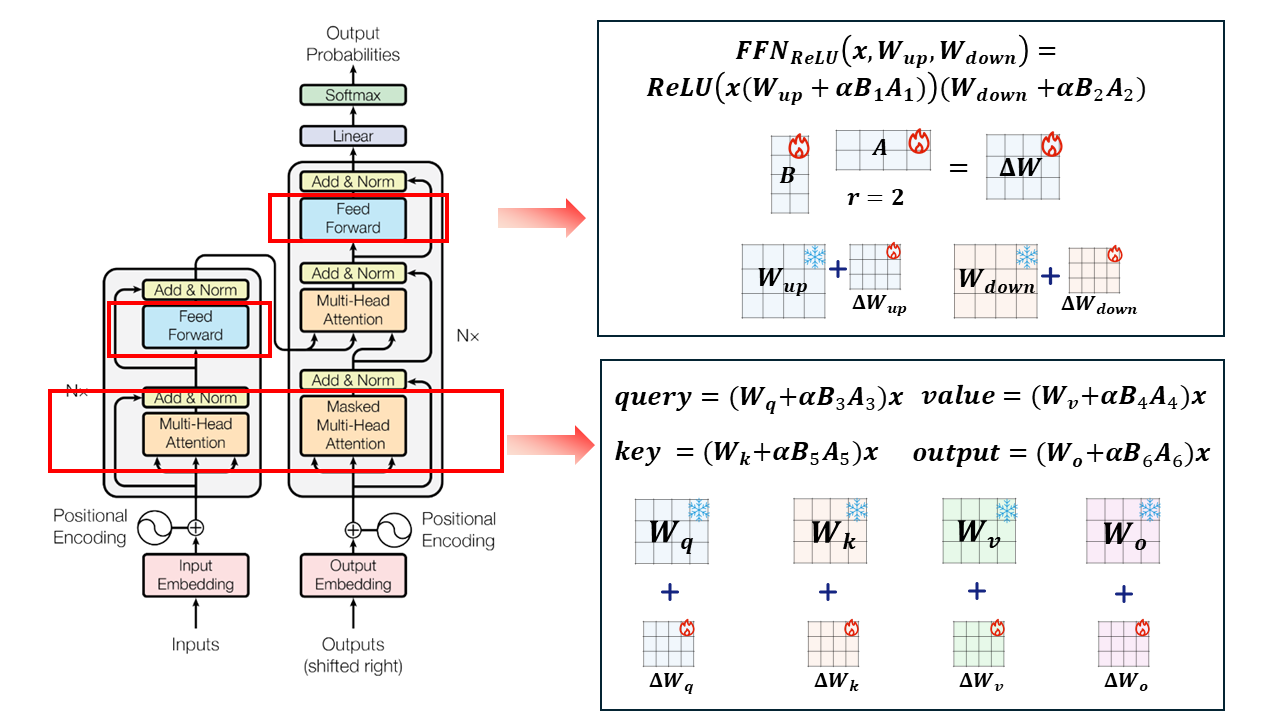
图 13-2:LoRA 在 Transformer 中的适配位置。注意力层的
零推理延迟。 这是 LoRA 相对于 Adapter Tuning 和 Prefix Tuning 的关键优势。Adapter 在模型中串联插入额外层,增加推理延迟;Prefix Tuning 占用宝贵的上下文窗口。而 LoRA 的旁路结构允许在推理前将低秩矩阵合并回原始权重:
部署后的模型结构与原始模型完全一致,不存在任何额外的推理开销。更进一步,不同任务可以共享同一个基模型,通过切换不同的
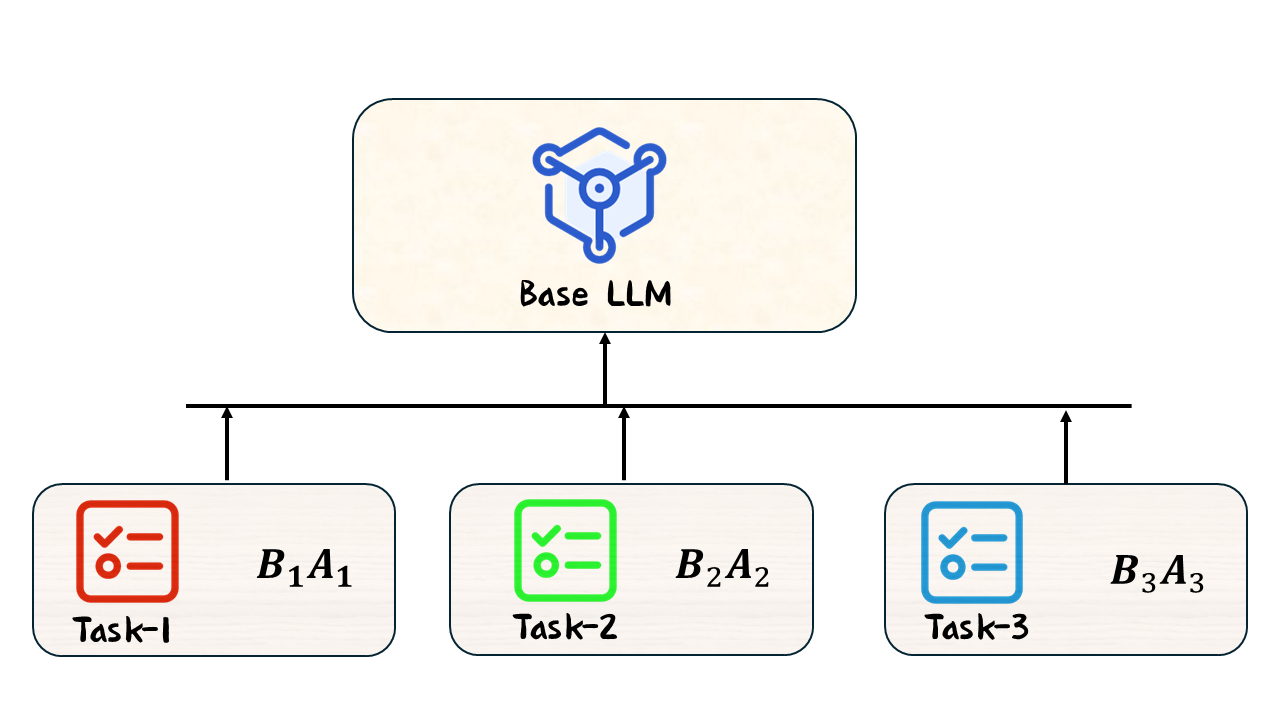
图 13-3:LoRA 的模块化特性。同一个基模型可搭配多组针对不同任务微调的 LoRA 矩阵,实现即插即用的任务切换。
13.1.3 从零实现 LoRA
下面用 PyTorch 从零实现一个完整的 LoRA 层,并展示如何将其注入到现有模型中。
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
"""LoRA 低秩适配层"""
def __init__(self, in_features: int, out_features: int,
rank: int = 8, alpha: float = 16.0):
super().__init__()
self.rank = rank
self.alpha = alpha
self.scaling = alpha / rank # 缩放因子
# 矩阵 A:高斯初始化,将输入投影到低秩空间
self.A = nn.Linear(in_features, rank, bias=False)
nn.init.kaiming_uniform_(self.A.weight)
# 矩阵 B:零初始化,将低秩空间映射回输出维度
self.B = nn.Linear(rank, out_features, bias=False)
nn.init.zeros_(self.B.weight)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# B(A(x)) * scaling
return self.B(self.A(x)) * self.scaling
class LinearWithLoRA(nn.Module):
"""将 LoRA 注入到标准线性层"""
def __init__(self, linear: nn.Linear, rank: int = 8, alpha: float = 16.0):
super().__init__()
self.linear = linear # 冻结的原始线性层
self.lora = LoRALayer(
linear.in_features, linear.out_features,
rank=rank, alpha=alpha
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 原始输出 + LoRA 旁路输出
return self.linear(x) + self.lora(x)
def merge_weights(self):
"""将 LoRA 权重合并到原始权重中(部署时调用)"""
with torch.no_grad():
# W_deploy = W_0 + scaling * B @ A
self.linear.weight += (
self.lora.scaling
* self.lora.B.weight @ self.lora.A.weight
)
self.lora = None # 释放 LoRA 参数将 LoRA 注入模型并计算参数量。 下面展示如何遍历模型、注入 LoRA,以及对比微调前后的参数量变化:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def apply_lora(model: nn.Module, rank: int = 8, alpha: float = 16.0):
"""将 LoRA 注入模型中所有线性层"""
for name, module in model.named_children():
if isinstance(module, nn.Linear):
# 冻结原始权重
module.weight.requires_grad = False
if module.bias is not None:
module.bias.requires_grad = False
# 替换为带 LoRA 的线性层
setattr(model, name, LinearWithLoRA(module, rank, alpha))
else:
# 递归处理子模块
apply_lora(module, rank, alpha)
# --- 使用示例 ---
class SimpleLLM(nn.Module):
"""简化的 Transformer 层,用于演示"""
def __init__(self, d_model: int = 4096):
super().__init__()
self.q_proj = nn.Linear(d_model, d_model, bias=False)
self.k_proj = nn.Linear(d_model, d_model, bias=False)
self.v_proj = nn.Linear(d_model, d_model, bias=False)
self.o_proj = nn.Linear(d_model, d_model, bias=False)
def forward(self, x):
q, k, v = self.q_proj(x), self.k_proj(x), self.v_proj(x)
return self.o_proj(v) # 简化,仅演示结构
model = SimpleLLM(d_model=4096)
# 注入前的参数量
total_before = sum(p.numel() for p in model.parameters())
print(f"注入前总参数量: {total_before:,}") # 67,108,864
# 注入 LoRA(rank=8)
apply_lora(model, rank=8, alpha=16.0)
# 注入后的参数量统计
total_params = sum(p.numel() for p in model.parameters())
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
frozen = total_params - trainable
print(f"注入后总参数量: {total_params:,}")
print(f"可训练参数量 (LoRA): {trainable:,}") # 262,144
print(f"冻结参数量: {frozen:,}") # 67,108,864
print(f"LoRA 参数占比: {trainable/frozen*100:.2f}%") # 0.39%输出如下,清晰展示了 LoRA 的极致参数效率:
注入前总参数量: 67,108,864
注入后总参数量: 67,371,008
可训练参数量 (LoRA): 262,144
冻结参数量: 67,108,864
LoRA 参数占比: 0.39%仅用不到原始参数量 0.4% 的可训练参数,LoRA 就能让模型适应新任务。
13.1.4 秩的选择与实践经验
秩
![]()
图 13-4:LoRA 在不同秩下的实验结果。即使
实践中,秩的选择通常遵循以下经验法则:
| 场景 | 推荐秩 | 说明 |
|---|---|---|
| 简单分类/情感分析 | 1 -- 8 | 任务简单,低秩即可捕捉关键特征 |
| 通用 SFT | 16 -- 64 | 适应指令跟随等中等复杂度任务 |
| 大规模 SFT(追求匹敌全参数微调) | 128 -- 256 | 高容量适配,配合 target_modules="all-linear" |
| 强化学习(GRPO/PPO) | 1 -- 32 | 策略梯度每轮提取信息量有限,低秩足够 |
缩放因子
目标模块的选择。 研究表明,将 LoRA 应用到所有线性层(而非仅注意力层的 target_modules="all-linear" 一键实现全线性层注入:
from peft import LoraConfig
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear", # 注入所有线性层
)13.1.5 LoRA 变体:QLoRA、AdaLoRA 与 DoRA
LoRA 的简洁设计为后续一系列变体奠定了基础。每一种变体都针对 LoRA 的某个局限性进行了改进。
QLoRA:量化 + LoRA。 标准 LoRA 虽然减少了可训练参数量,但基模型本身仍以 16 位精度加载,占用大量显存。QLoRA 的核心思想是将基模型权重量化到 4 位精度,再在其上叠加 16 位的 LoRA 适配器。
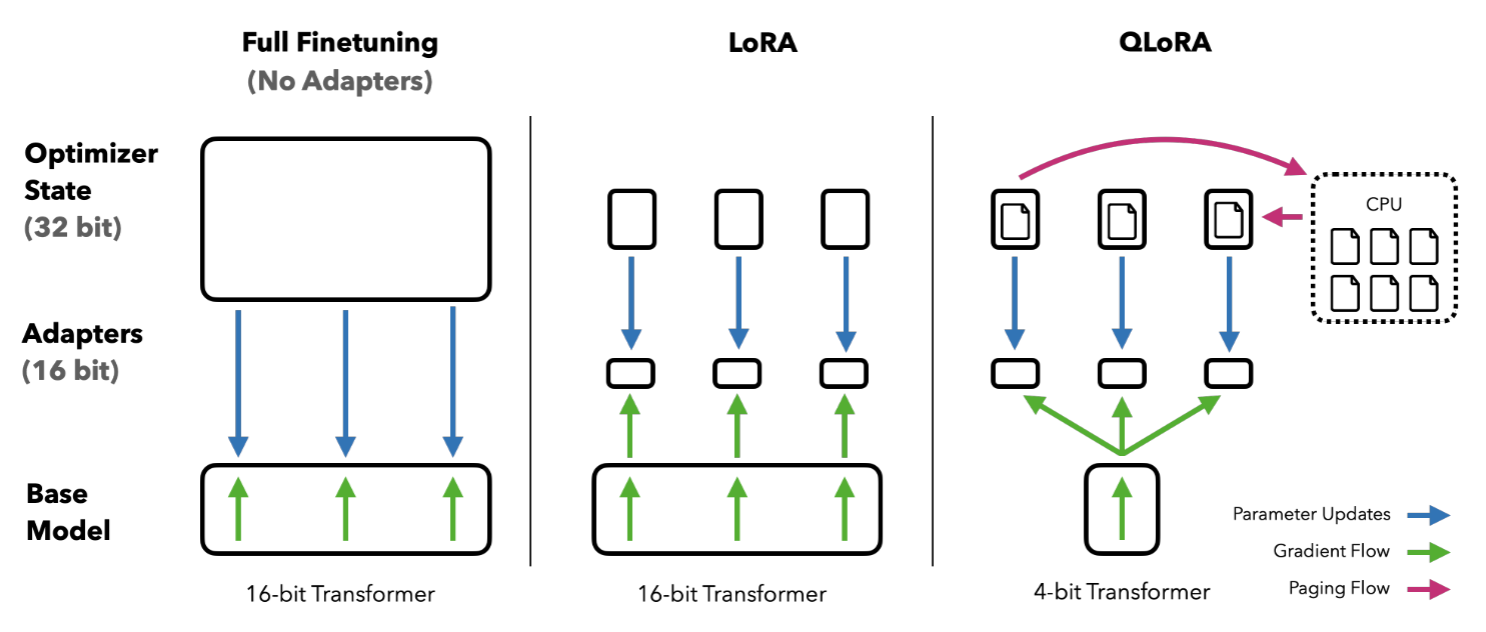
图 13-5:Full Finetuning、LoRA 与 QLoRA 的显存分配对比。QLoRA 将基模型压缩至 4-bit,优化器状态可分页到 CPU,显存占用大幅降低。
QLoRA 引入了三项关键技术:
- NF4 量化(4-bit NormalFloat):利用预训练权重近似服从正态分布的特性,采用等概率分割(而非等步长分割)来设置量化刻度。在数据密集的零点附近量化点密集,在尾部则稀疏,实现了信息论意义上的最优表示。
- 双重量化(Double Quantization):对量化过程中产生的缩放因子再进行一次量化,将每参数平均位数从约 4.5 bit 进一步降低到约 4.1 bit。
- 分页优化器(Paged Optimizer):利用 NVIDIA 统一内存特性,将不在当前使用的优化器状态自动分页到 CPU,避免显存溢出。
QLoRA 成功地在单张 48GB GPU 上微调了 650 亿参数的模型,同时几乎保留了完整的 16 位微调性能。
AdaLoRA:自适应秩分配。 标准 LoRA 为所有适配层分配相同的秩
- 热身阶段:以高于目标的初始预算开始训练,让模型充分探索参数空间
- 预算削减阶段:按三次函数平滑地降低预算至目标值,基于重要性评分剪枝不重要的分量
- 微调阶段:固定预算,继续标准训练至收敛
AdaLoRA 用与 LoRA 相同的参数量,在多个基准测试上实现了性能超越。
DoRA:权重分解适配。 DoRA 从全新的视角审视 LoRA 与全参数微调的差距。通过将权重矩阵分解为**量级(Magnitude)和方向(Direction)**两个分量,研究者发现了一个关键差异:
- 全参数微调中,量级变化与方向变化呈负相关——模型可以灵活地独立调整二者
- LoRA 中,二者呈强正相关——量级和方向被"捆绑"更新,限制了微调的灵活性

图 13-6:权重更新的量级变化
DoRA 的解决方案是将量级和方向的更新显式解耦:
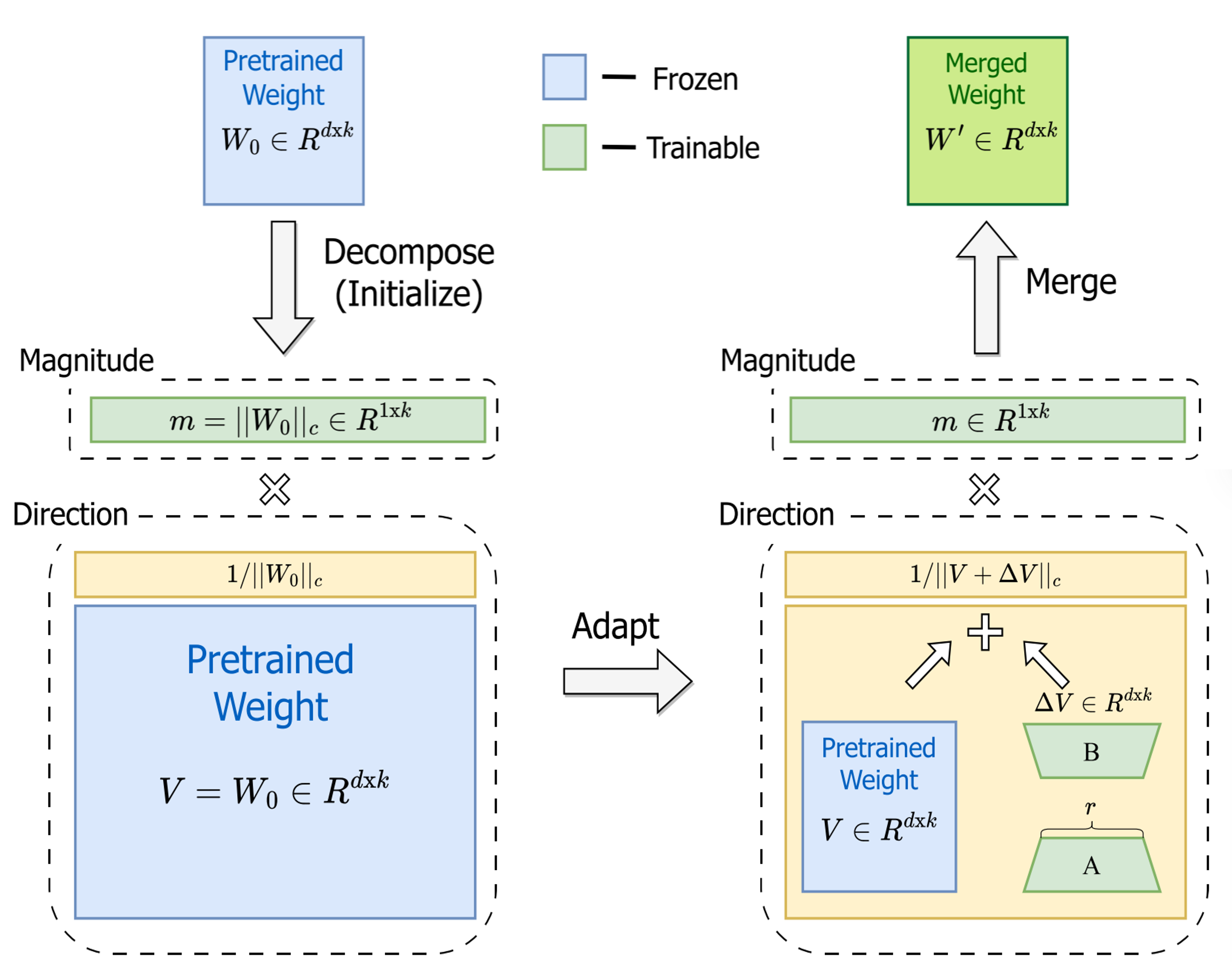
图 13-7:DoRA 的工作流程。预训练权重被分解为量级向量
通过这种设计,DoRA 让低秩适配具备了接近全参数微调的灵活性,在多个任务上显著缩小了与全参数微调的性能差距。
下表总结了各变体的核心特性:
| 方法 | 核心改进 | 适用场景 | 额外开销 |
|---|---|---|---|
| LoRA | 低秩分解 | 通用微调 | 无推理延迟 |
| QLoRA | 4-bit 量化基模型 + LoRA | 显存极度受限 | 量化/反量化计算 |
| AdaLoRA | SVD 参数化 + 自适应秩分配 | 参数预算紧张时的精细调控 | 重要性评分计算 |
| DoRA | 解耦量级与方向更新 | 追求接近全参数微调的性能 | 额外的归一化计算 |
本节小结
- LoRA 的核心思想是低秩分解:将权重更新
分解为两个小矩阵的乘积 ,仅训练这对矩阵,实现数百倍的参数压缩。 - 初始化策略至关重要:
高斯随机初始化、 全零初始化,确保训练起始时不破坏预训练表征。 - 缩放因子
控制 LoRA 旁路的贡献强度,秩 决定低秩矩阵的表达能力。 - LoRA 的零推理延迟特性(权重可合并)和模块化特性(多任务切换)使其成为大模型微调的事实标准。
- QLoRA 通过量化进一步降低显存门槛,AdaLoRA 实现自适应秩分配,DoRA 解耦量级与方向更新——各变体针对不同需求提供了精准的优化方案。