5.6 小模型 Scaling 实践
大规模语言模型的 Scaling Law(Kaplan et al., 2020)指出,模型性能主要由参数量、训练数据量和训练计算量三者共同决定,而架构细节的影响几乎可以忽略。然而,当参数预算降至数亿甚至数千万量级时,这一结论不再完全成立——架构设计的每一个选择都会对最终效果产生显著影响。本节围绕小模型场景下的 Scaling 实践,讨论两个核心问题:如何分配深度与宽度,以及如何设定具体的参数配置。
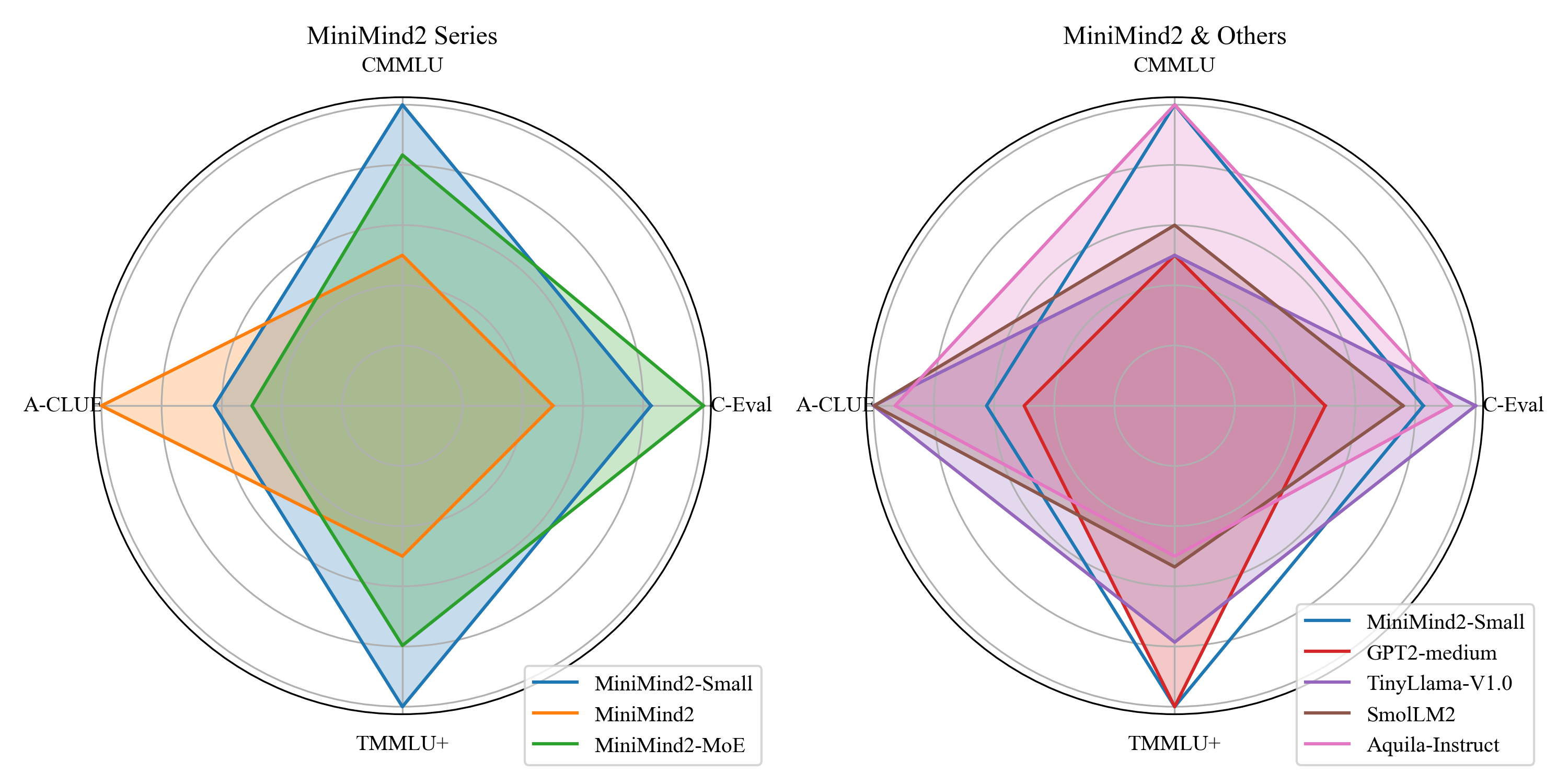
图 5-21:不同参数量小模型在多项基准任务上的性能雷达图对比。更深的模型(相同参数量)在多数任务上表现更优。
5.6.1 「深而窄」vs「矮胖」:深度与宽度的取舍
Transformer 模型的参数规模几乎只取决于两个超参数:隐藏层维度
大、 小:得到一个「矮胖」模型,每一层的表征能力强,但层数少、抽象层次有限。 小、 大:得到一个「深而窄」模型,层数多、能逐层构建更深的抽象表示,但每一层可用的维度较窄。
传统 Scaling Law 对二者并无明确偏好,但 MobileLLM(Liu et al., 2024)在 125M 和 350M 量级上的系统实验揭示了一个重要发现:在小模型中,深度比宽度更重要。具体而言,当参数量固定在 125M 时,30~42 层的「狭长」模型在常识推理、问答、阅读理解等 8 项基准上均显著优于 12 层左右的「矮胖」模型。这意味着,在小参数预算下,增加层数所带来的多层次抽象能力,比增加单层宽度所带来的表征丰富度更具性价比。
然而,「深而窄」的「窄」存在下限。实践经验表明:
当
时,词嵌入维度过低导致的表征坍塌问题非常明显。在采用多头注意力时,每个注意力头分到的维度 过小,注意力机制无法有效区分不同的语义模式。此时增加层数也难以弥补这一底层瓶颈。 当
时,词嵌入具备了足够的表征能力,此时适当增加层数能带来稳定的效果提升。 当
时,继续增加宽度的边际收益递减,而增加层数的优先级更高——即在同样的参数增量下,多加几层比拓宽维度更能带来「性价比」更高的效果增益。
综合来看,512 是小模型
5.6.2 小模型参数配置经验
以开源项目 MiniMind 为例,该项目从零训练了多个参数量级的小型语言模型(26M~145M),其架构遵循 Llama 风格(RMSNorm + RoPE + SwiGLU),并提供了 Dense 和 MoE 两种变体。下表展示了不同型号的完整参数配置:
| 模型 | 总参数量 | 词表大小 | KV Heads | Q Heads | FFN 中间维度 | 备注 | |||
|---|---|---|---|---|---|---|---|---|---|
| MiniMind2-Small | 26M | 6400 | 512 | 8 | 2 | 8 | 64 | ~1365 | 极小体积基线 |
| MiniMind2 | 104M | 6400 | 768 | 16 | 2 | 8 | 96 | 2048 | 主力 Dense 模型 |
| MiniMind2-MoE | 145M | 6400 | 640 | 8 | 2 | 8 | 80 | ~1365 | 1 共享 + 4 路由专家 |
注:FFN 中间维度按
(向上对齐到 64 的倍数)自动计算,以适配 GPU 并行粒度。
从这张表中可以提炼出若干配置经验:
1. 词表大小与「头重脚轻」问题
在大模型中,Embedding 层参数占总参数的比例微乎其微(例如 Llama-3 的 128K 词表仅占总参数的约 3%)。但在小模型中,情况截然不同:若采用 Qwen2 的 15 万词表,仅 Embedding 层就需要
这一策略的代价是分词粒度较粗、编码效率低于 Qwen2 或 ChatGLM 等中文友好型分词器,但在极小参数预算下,保持编码层与计算层的参数比例平衡远比分词效率更重要。
2. GQA(分组查询注意力)的应用
MiniMind2 系列统一采用 2 个 KV Heads、8 个 Q Heads 的 GQA 配置(每 4 个 Query Head 共享 1 组 KV)。相比 MiniMind-V1 的 MHA(每个 Query Head 独立拥有 KV),GQA 在几乎不损失效果的前提下显著降低了 KV Cache 的显存占用,对推理部署非常友好。在小模型中,GQA 还起到了正则化的作用——共享 KV 参数减少了过拟合风险。
3. 权重绑定(Weight Tying)
MiniMind 采用了 Embedding 层与输出投影层(LM Head)共享权重的策略。对于
4. FFN 中间维度的自动计算
MiniMind 沿用了 Llama 风格的 SwiGLU FFN,其中间维度按
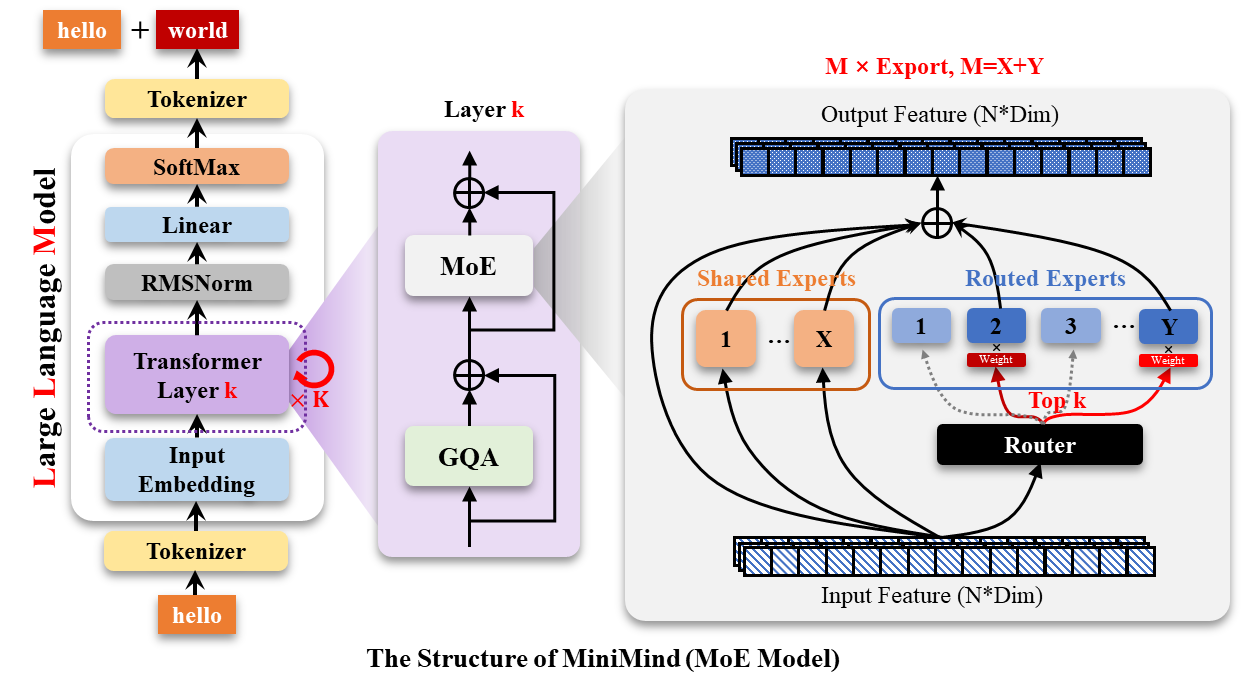
图 5-22:MoE 架构在小模型中的应用。共享专家处理通用特征,路由专家处理特定子任务,实现以较低推理成本获得更大模型容量。
5. MoE 的参数效率
MiniMind2-MoE 采用 1 个共享专家 + 4 个路由专家的 DeepSeek 风格 MoE 架构。虽然总参数量达到 145M,但每个 Token 实际激活的参数量远小于此(仅共享专家 + Top-K 路由专家被激活)。这使得 MoE 模型在推理时的计算成本接近于 Dense 小模型,却拥有更大的模型容量。对于算力受限但希望提升效果的场景,MoE 是值得考虑的架构选择。
5.6.3 配置建议速查
结合 MobileLLM 的研究结论与 MiniMind 的实践经验,可以给出以下面向不同参数预算的配置建议:
| 参数预算 | 推荐 | 推荐 | 词表策略 | 注意力机制 | 关键注意事项 |
|---|---|---|---|---|---|
| < 50M | 512 | 8~12 | 精简词表(< 10K) | GQA | 必须启用权重绑定;词表越小越好 |
| 50M~200M | 640~768 | 12~20 | 精简词表(< 20K) | GQA | 优先加深层数;可考虑 MoE |
| 200M~500M | 768~1024 | 20~30 | 中等词表(< 50K) | GQA | 深度优先原则仍然适用 |
| > 500M | 1024~2048 | 24~48 | 标准词表 | GQA / MHA | 逐步过渡到标准 Scaling Law |
注意,上表为经验性建议而非严格公式。实际配置应根据具体任务、训练数据量和硬件条件进行调整,但「深度优先、词表精简、启用权重绑定」三条原则在小模型场景下具有较高的普适性。
5.6.4 小结
小模型的 Scaling 实践与大模型存在本质差异。经典 Scaling Law 假设架构影响可忽略,但在参数预算降至数亿以下时,架构选择——尤其是深度与宽度的分配——对性能有决定性影响。核心经验可归纳为三点:
深度优先:在
的前提下,优先增加层数。30 层以上的「狭长」模型在多项任务上持续优于同参数量的「矮胖」模型。 守住宽度下限:
是实践中的安全下限。低于此值时,注意力头维度不足导致的表征坍塌无法通过增加深度弥补。 全局参数效率:在小模型中,Embedding 层、LM Head 等「非核心」组件的参数占比远高于大模型。通过精简词表、权重绑定、GQA 等手段压缩这些组件的参数开销,将有限的参数预算集中于 Transformer 核心层,是小模型获得最优性价比的关键策略。