附录E:聊天界面实现
在第 25 章中,我们学习了如何将训练好的模型部署为 API 服务。但对于大多数用户而言,与大模型最自然的交互方式不是发送 HTTP 请求,而是像 ChatGPT 那样在浏览器中进行实时对话。本附录将从零开始实现一个完整的 ChatGPT 风格聊天界面,涵盖后端 API、流式输出、前端界面和多轮对话管理四个核心模块。
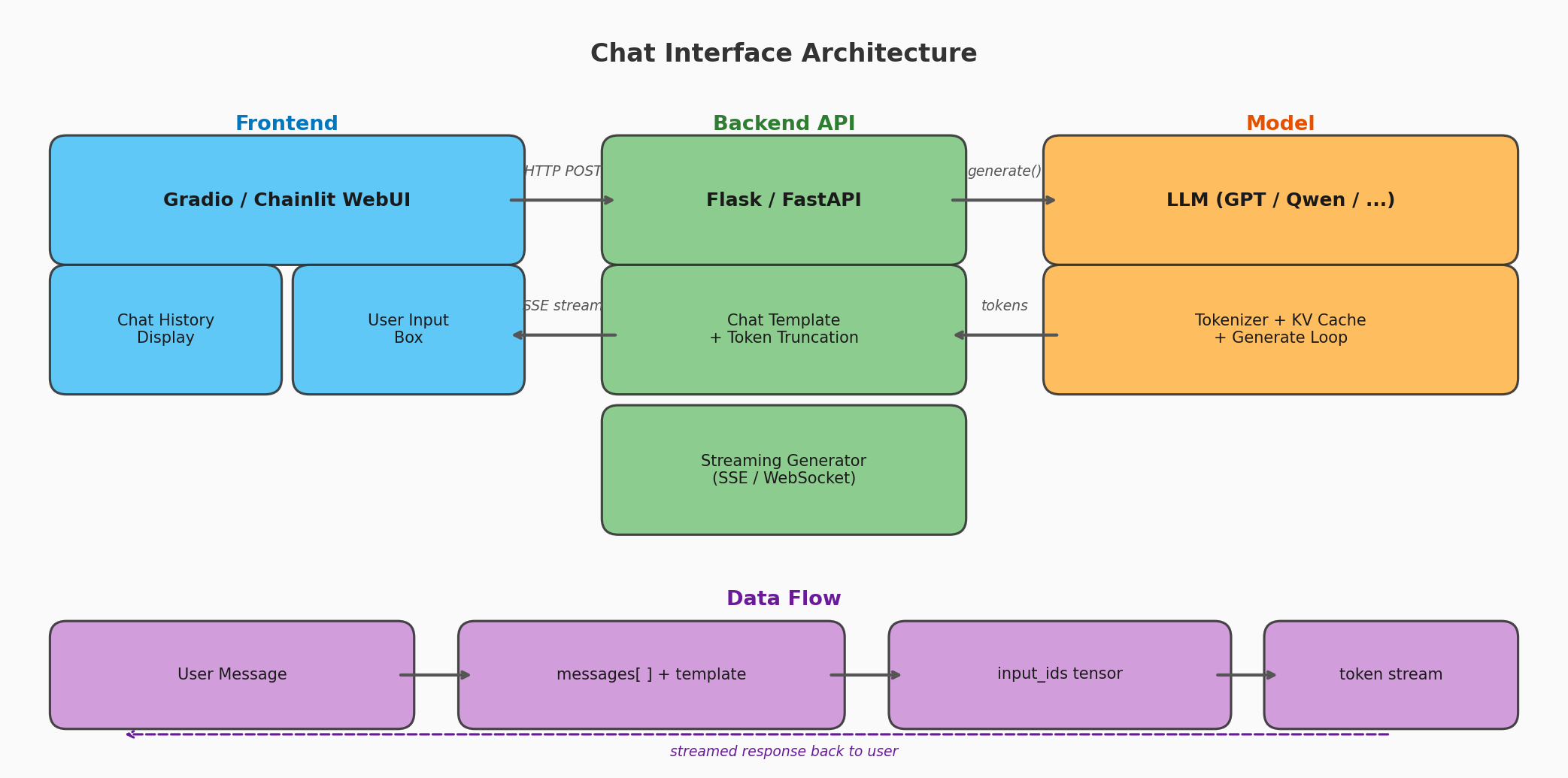
上图展示了聊天系统的三层架构。前端(Gradio 或 Chainlit)呈现对话界面并接收用户输入;后端 API(Flask 或 FastAPI)管理对话历史、拼装提示词模板、调度模型推理并以流式方式返回结果;模型层执行实际的 token 生成。三者通过 HTTP 请求和 Server-Sent Events(SSE)协议串联:用户消息 → 历史拼装 → 模型推理 → 流式返回 → 界面实时显示。
E.1 对话模板与提示词拼装
大语言模型本身只看到一段连续的文本,它并不天然理解"谁是用户、谁是助手"。Chat Template(对话模板)的作用就是将结构化的消息列表转换为模型能理解的纯文本格式。目前最常用的模板是 ChatML 格式,Qwen、Llama 3 等模型均采用这一标准:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant每条消息被 <|im_start|> 和 <|im_end|> 标记包裹,最后追加一个空的 assistant 标头,告诉模型"现在轮到你说了"。实现函数如下:
def build_chat_prompt(messages):
"""
将消息列表转换为 ChatML 格式的提示词。
messages: [{"role": "system"|"user"|"assistant", "content": str}, ...]
"""
parts = []
for msg in messages:
parts.append(f"<|im_start|>{msg['role']}\n{msg['content']}<|im_end|>\n")
# 追加 assistant 标头,引导模型开始生成
parts.append("<|im_start|>assistant\n")
return "".join(parts)对于支持 apply_chat_template 方法的分词器(如 Qwen、Llama 3),可以直接调用 tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) 来生成格式正确的提示词。手动实现有助于理解底层机制,也便于适配自定义模型。
提示:如果使用的模型(如 GPT-2)在预训练时没有见过 ChatML 标记,对话模板的效果会打折扣。此时可退化为简单拼接——将所有消息文本用换行符连接即可。
E.2 流式输出(Streaming)实现
流式输出是现代聊天界面的标配——助手的回复逐字逐句出现,而非等待全部生成完毕。技术原理是 Server-Sent Events(SSE):服务端在长连接中持续推送 JSON 数据片段,每个片段包含新生成的 token。
实现的关键挑战在于 model.generate() 是阻塞调用。解决方案是在子线程中运行生成,通过线程安全的队列逐 token 传递给主线程。Transformers 的 TextIteratorStreamer 类封装了这一模式:
from threading import Thread
from transformers import TextIteratorStreamer
def generate_stream(prompt_text, tokenizer, model, device,
max_new_tokens=512, temperature=0.7, top_p=0.9):
"""
流式生成器:子线程运行 model.generate,
通过 TextIteratorStreamer 逐 token 产出文本。
"""
inputs = tokenizer(
prompt_text, return_tensors="pt", truncation=True, max_length=1024
).to(device)
# TextIteratorStreamer 内部维护队列,generate 每产出一个 token 就放入
streamer = TextIteratorStreamer(
tokenizer, skip_prompt=True, skip_special_tokens=True
)
gen_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": max_new_tokens,
"do_sample": True,
"temperature": temperature,
"top_p": top_p,
"streamer": streamer,
}
thread = Thread(target=model.generate, kwargs=gen_kwargs)
thread.start()
# 主线程从 streamer 逐块读取
for text_chunk in streamer:
if text_chunk:
yield text_chunk
thread.join()TextIteratorStreamer 继承自 TextStreamer,在 on_finalized_text 回调中将解码后的文本片段放入内部队列。主线程通过迭代器协议逐块取出,形成生成器。skip_prompt=True 确保只输出新生成的内容。
将流式生成器接入 Flask SSE 端点的方式如下:
import json
from flask import Flask, request, Response, jsonify
app = Flask(__name__)
@app.route("/chat/stream", methods=["POST"])
def chat_stream():
"""流式聊天端点:以 SSE 格式逐 token 返回。"""
data = request.get_json()
messages = data.get("messages", [])
prompt = build_chat_prompt(messages)
def event_stream():
for chunk in generate_stream(prompt, tokenizer, model, DEVICE):
payload = json.dumps({"content": chunk}, ensure_ascii=False)
yield f"data: {payload}\n\n"
yield "data: [DONE]\n\n"
return Response(
event_stream(), mimetype="text/event-stream",
headers={"Cache-Control": "no-cache", "X-Accel-Buffering": "no"}
)X-Accel-Buffering: no 告诉 Nginx 等反向代理不要缓冲响应,确保 SSE 事件立即送达客户端。
E.3 Gradio 聊天界面(完整可运行)
Gradio 是 Python 社区中最流行的 ML 演示框架,其 ChatInterface 组件可以用很少的代码搭建完整的聊天 UI。下面给出一个单文件完整实现,集成了模型加载、流式生成、多轮历史管理和参数调节:
# chat_app.py — 完整的 ChatGPT 风格聊天应用
import torch
import gradio as gr
from threading import Thread
from transformers import (
AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer,
)
# ============ 配置区(修改这里即可切换模型)============
MODEL_NAME = "gpt2" # HuggingFace 模型名或本地路径
MAX_NEW_TOKENS = 512 # 最大生成 token 数
CONTEXT_LENGTH = 1024 # 模型上下文窗口长度
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# ======================================================
# 模型加载(全局只执行一次)
print(f"[INFO] 正在加载模型 {MODEL_NAME}...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME).to(DEVICE)
model.eval()
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
print(f"[INFO] 模型已加载到 {DEVICE},"
f"参数量: {sum(p.numel() for p in model.parameters())/1e6:.1f}M")
def build_prompt(messages):
"""将消息列表转换为 ChatML 格式文本。"""
parts = []
for m in messages:
parts.append(f"<|im_start|>{m['role']}\n{m['content']}<|im_end|>\n")
parts.append("<|im_start|>assistant\n")
return "".join(parts)
def trim_history(history, system_prompt, max_tokens):
"""
滑动窗口历史管理:保留 system prompt + 尽可能多的最近对话轮次,
使总 token 数不超过 max_tokens。
"""
messages = [{"role": "system", "content": system_prompt}]
sys_len = len(tokenizer.encode(
build_prompt(messages), add_special_tokens=False
))
budget = max_tokens - sys_len
# 从最新轮次向前保留
kept_pairs = []
total = 0
for user_msg, bot_msg in reversed(history):
pair_text = user_msg + (bot_msg or "")
pair_len = len(tokenizer.encode(pair_text, add_special_tokens=False))
if total + pair_len > budget:
break
kept_pairs.insert(0, (user_msg, bot_msg))
total += pair_len
for user_msg, bot_msg in kept_pairs:
messages.append({"role": "user", "content": user_msg})
if bot_msg:
messages.append({"role": "assistant", "content": bot_msg})
return messages
def respond(message, history, system_prompt, temperature,
top_p, max_tokens):
"""Gradio ChatInterface 的回调:流式生成,每 yield 更新界面。"""
# 历史截断 + 拼装提示词
token_budget = CONTEXT_LENGTH - int(max_tokens)
messages = trim_history(history, system_prompt, token_budget)
messages.append({"role": "user", "content": message})
prompt_text = build_prompt(messages)
# 编码
inputs = tokenizer(
prompt_text, return_tensors="pt",
truncation=True, max_length=CONTEXT_LENGTH
).to(DEVICE)
# 流式生成
streamer = TextIteratorStreamer(
tokenizer, skip_prompt=True, skip_special_tokens=True
)
gen_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": int(max_tokens),
"do_sample": True,
"temperature": max(float(temperature), 0.01),
"top_p": float(top_p),
"streamer": streamer,
}
thread = Thread(target=model.generate, kwargs=gen_kwargs)
thread.start()
partial = ""
for chunk in streamer:
partial += chunk
yield partial
thread.join()
# 构建 Gradio 界面
demo = gr.ChatInterface(
fn=respond,
title="LLM Chat Interface",
description="支持流式输出、多轮对话、参数实时调节。",
additional_inputs=[
gr.Textbox(value="You are a helpful assistant.",
label="System Prompt", lines=2),
gr.Slider(0.1, 2.0, value=0.7, step=0.1, label="Temperature"),
gr.Slider(0.1, 1.0, value=0.9, step=0.05, label="Top-p"),
gr.Slider(64, 2048, value=512, step=64, label="Max New Tokens"),
],
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=7860)运行方式:
pip install gradio transformers torch
python chat_app.py打开 http://localhost:7860 即可开始对话。ChatInterface 自动处理了对话历史渲染、清空会话等功能。additional_inputs 在界面底部生成滑块,让用户实时调整生成参数。respond 函数是一个 Python generator——每次 yield 时 Gradio 用产出的文本更新助手回复气泡,形成流式效果。
修改 MODEL_NAME 即可切换模型——例如改为 "Qwen/Qwen2.5-0.5B-Instruct" 使用 Qwen 模型,改为本地路径则加载自训练模型。
E.4 Chainlit 聊天界面
Chainlit 是另一个优秀的聊天 UI 框架,提供更接近 ChatGPT 原生体验的界面风格。其编程模型基于事件装饰器:@chainlit.on_chat_start 处理会话初始化,@chainlit.on_message 处理每条用户消息,流式输出通过 Message.stream_token() 实现。
# chat_chainlit.py — Chainlit 聊天界面
import torch
import chainlit
from transformers import AutoModelForCausalLM, AutoTokenizer
# ============ 配置区 ============
MODEL_NAME = "gpt2"
MAX_NEW_TOKENS = 512
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# ================================
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME).to(DEVICE)
model.eval()
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
EOS_IDS = {tokenizer.eos_token_id}
def build_prompt_from_history(history):
"""将对话历史拼装为 ChatML 格式。"""
parts = []
for m in history:
parts.append(f"<|im_start|>{m['role']}\n{m['content']}<|im_end|>\n")
parts.append("<|im_start|>assistant\n")
return "".join(parts)
def trim_input(input_ids, context_length, max_new_tokens):
"""左截断:保留最近的 token,确保有空间生成新 token。"""
keep_len = max(1, context_length - max_new_tokens)
if input_ids.shape[1] > keep_len:
input_ids = input_ids[:, -keep_len:]
return input_ids
@chainlit.on_chat_start
async def on_start():
"""会话开始时初始化对话历史。"""
chainlit.user_session.set("history", [
{"role": "system", "content": "You are a helpful assistant."}
])
@chainlit.on_message
async def on_message(message: chainlit.Message):
"""处理用户消息:生成回复并流式返回。"""
history = chainlit.user_session.get("history")
history.append({"role": "user", "content": message.content})
# 拼装提示词并编码
prompt = build_prompt_from_history(history)
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(DEVICE)
input_ids = trim_input(input_ids, context_length=1024,
max_new_tokens=MAX_NEW_TOKENS)
# 创建空消息,后续流式填充
out_msg = chainlit.Message(content="")
await out_msg.send()
# 逐 token 生成
generated_text = ""
with torch.no_grad():
for _ in range(MAX_NEW_TOKENS):
outputs = model(input_ids)
next_token_id = torch.argmax(outputs.logits[:, -1, :], dim=-1)
if next_token_id.item() in EOS_IDS:
break
piece = tokenizer.decode(next_token_id.tolist(),
skip_special_tokens=True)
generated_text += piece
await out_msg.stream_token(piece)
input_ids = torch.cat(
[input_ids, next_token_id.unsqueeze(0)], dim=1
)
await out_msg.update()
history.append({"role": "assistant", "content": generated_text})
chainlit.user_session.set("history", history)运行命令:
pip install chainlit transformers torch
chainlit run chat_chainlit.py浏览器会自动打开 http://localhost:8000。Chainlit 与 Gradio 的核心差异在于编程模型:Gradio 是函数式的(传入消息,返回回复),Chainlit 是事件驱动的(装饰器注册回调)。Chainlit 通过 chainlit.user_session 存储每个用户的独立状态,天然支持多用户并发;对于需要复杂交互逻辑(文件上传、多步工作流等)的场景,事件模型更加灵活。
E.5 多轮对话管理
单轮对话只需将用户消息送入模型即可,但真正有用的聊天系统必须支持多轮对话——用户可以追问、引用之前的内容。这要求每次请求时将完整的对话历史作为上下文传给模型。
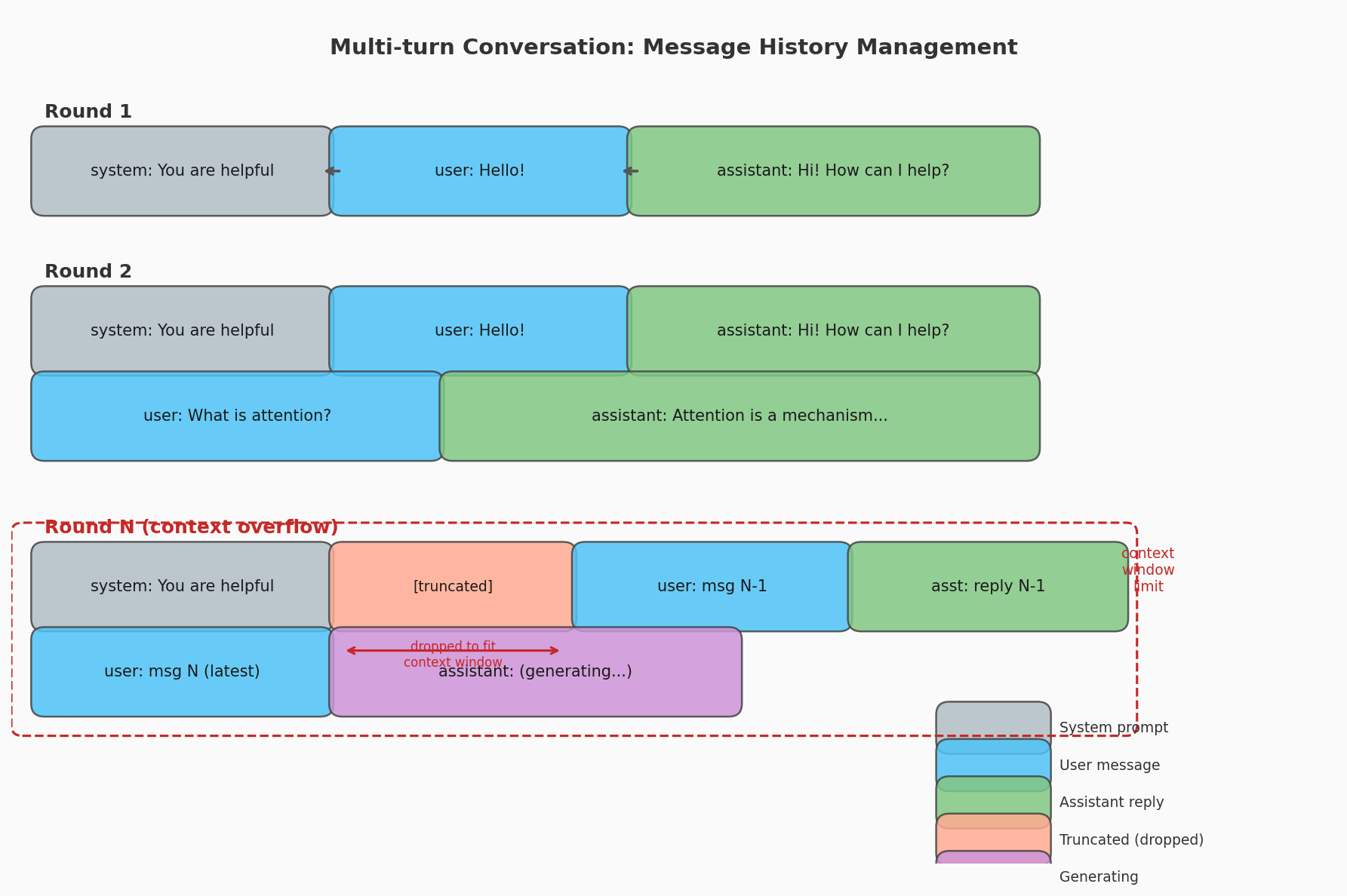
核心挑战是上下文窗口有限。模型的上下文长度(GPT-2 的 1024 token、Llama 3 的 8192 token)是固定的,而对话历史随轮数增长不断膨胀。超出窗口时必须截断。常见策略如下:
| 策略 | 方法 | 优点 | 缺点 |
|---|---|---|---|
| 左截断 | 保留最近 N 个 token | 实现最简单 | 可能切断消息边界 |
| 按轮截断 | 丢弃最早的对话轮次 | 保持消息完整性 | 粒度较粗 |
| 滑动窗口 | 保留 system prompt + 最近 K 轮 | 系统提示不丢失 | 中间信息丢失 |
滑动窗口是最常用的策略,因为 system prompt 包含角色设定和行为约束,丢失它会导致模型行为漂移。E.3 节的 trim_history 函数就采用了这一策略:始终保留 system prompt,从最新轮次向前累积,超出 token 预算时丢弃更早的轮次。E.4 节的 trim_input 函数则展示了更简单的 token 级左截断方式,适合快速原型验证。
两种截断方式的权衡很清晰:按轮截断(trim_history)保证每轮消息的完整性,但需要在应用层管理历史列表;token 级左截断(trim_input)实现最简单——只需一行切片操作——但可能从某条消息的中间切断,导致模型收到不完整的上下文。生产环境建议使用按轮截断。
E.6 扩展方向
本附录实现的聊天系统已具备核心功能,但距离生产级应用还有若干改进方向:
KV Cache 复用:当前实现每次生成都重新编码完整历史。可通过
past_key_values参数传入上一轮的 KV Cache,避免重复计算已见过的 token,显著提升多轮对话的响应速度。E.4 节 Chainlit 的逐 token 循环中已展示了这一思路的雏形。并发与异步:Flask 的同步模型在高并发时会成为瓶颈。可切换到 FastAPI + Uvicorn,利用异步 I/O 和多 worker 处理并发请求。更高性能需求可接入 vLLM 作为推理后端(见第 25 章 §25.4.5)。
会话持久化:当前对话历史存储在内存中,服务重启后丢失。可将对话记录序列化为 JSON 或存入 SQLite/Redis,实现跨会话的历史保留。
安全过滤与限流:生产环境需要对输入输出进行内容过滤,并通过 API Key 认证和请求频率限制保护服务。
本附录的代码可直接作为任意 HuggingFace 模型的聊天界面起点。通过修改配置区的 MODEL_NAME,即可为不同模型搭建端到端的对话系统。