16.6 RL 训练工程稳定性
强化学习(Reinforcement Learning, RL)对齐阶段与监督微调(SFT)有着本质区别:SFT 的目标函数明确、梯度信号稳定,而 RL 训练中策略在"采样-评估-更新"的闭环中不断演化,任何环节出现偏差都会被放大并最终导致训练崩溃。大规模 RL 训练的工程稳定性问题可以归结为两个层面——系统层面的训练-推理不匹配和算法层面的信号质量退化。本节将系统地剖析这些问题的成因,并介绍业界行之有效的工程解决方案。
16.6.1 训练-推理不匹配
在 RL 训练中,模型需要频繁地在"推理模式"(生成样本)和"训练模式"(计算梯度并更新参数)之间切换。这两种模式使用不同的计算框架、不同的精度策略,有时甚至运行在不同的硬件节点上。当两者之间存在系统性偏差时,采样策略与实际更新策略不再是同一个策略,RL 算法的理论基础便被破坏,训练稳定性随之崩塌。
这种不匹配主要表现在三个方面。
(1)MoE 路由漂移。 混合专家模型(MoE)的每次前向传播只激活部分专家网络(Expert),由路由器(Router)根据输入动态决定激活哪些专家。问题在于:当策略更新改变了路由器的参数后,同一个输入可能被分配给完全不同的专家组合。这意味着在"旧策略"下采样的数据,其对数概率是由专家 A 和 B 计算的;而"新策略"下计算同一输入的对数概率时,路由器可能将其发送给了专家 C 和 D。新旧策略之间的差异不仅是参数微调带来的渐变,更是专家切换带来的突变——概率比(Ratio)剧烈震荡,GRPO 等 on-policy 算法极易崩溃。
解决方案是 Routing Replay(路由重放):在计算 RL 损失时,强制使用采样阶段记录的路由决策(即哪些专家被激活),而非让更新后的路由器重新做决策。这相当于在策略更新时"冻结"路由路径,确保新旧策略计算概率时使用相同的专家组合,从而消除路由切换引入的突变噪声。
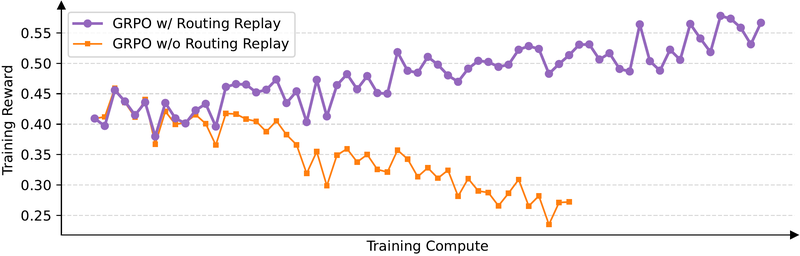
图 16-10:Routing Replay 的效果对比。没有 Routing Replay 的 GRPO(橙色)在 MoE 模型上训练奖励持续衰减,最终崩溃;启用 Routing Replay 后(紫色),训练曲线恢复平稳上升。
(2)推理引擎精度差异。 为了加速采样,工业界普遍使用 vLLM 等高性能推理引擎进行大规模并行生成。这些引擎为了追求吞吐量,会使用 INT8/FP8 量化、投机解码(Speculative Decoding)、甚至改变 CUDA 算子的计算顺序。然而训练端(FSDP/Megatron 等框架)为保证梯度计算的数值稳定性,通常使用 FP32 主权重(Master Weights)。
这种精度差异看似微小,却会在概率空间中引发系统性偏差:同一个 Token 在推理引擎和训练框架中计算出的对数概率
应对策略包括:在推理引擎中使用与训练端一致的精度(如 BF16),或者在计算概率比时对两端的对数概率做统一的精度对齐(如在训练端也用推理引擎重新计算
(3)多轮 Agent 编解码不一致。 在 Agent 场景中,模型需要与外部环境进行多轮交互(如调用工具、读取返回结果、继续推理)。每一轮的 prompt 拼接方式、特殊 Token 的处理、截断策略都可能在推理端和训练端存在细微差异。例如,推理端的 Tokenizer 可能对工具返回结果中的特殊字符做了特殊处理,而训练端在重新编码同一段对话历史时,得到了不同的 Token 序列。这种编解码不一致同样会导致概率空间的系统性偏移。
工程准则: 在大规模 RL 训练中,应定期对比推理端和训练端在同一输入上计算的
值,将两者的差异作为监控指标。当差异的绝对均值超过阈值(如 0.01)时,应发出告警并排查精度配置和编解码流程。
16.6.2 SFT 掩码规则
在 RL 训练的采样阶段,模型不可避免地会生成一些"垃圾输出"——格式错误的 JSON、导致系统崩溃的代码、或者根本无法解析的工具调用。如果这些错误输出未经处理就参与梯度回传,模型不仅无法从中学习到有用信息,反而会被错误模式污染。
正确的做法是对错误步骤施加 Loss Mask(损失掩码):
- 格式解析失败:模型输出的 JSON/XML 无法通过语法解析,该步骤的所有 Token 必须被 mask,不参与梯度计算
- 代码执行崩溃:模型生成的代码触发运行时异常(如内存溢出、无限循环超时),该轮交互的 loss 应被 mask
- 工具调用非法:模型调用了不存在的工具名称,或参数类型严重错误
核心原则是只让模型在正确的推理路径和合规的工具调用上进行反向传播。以下代码展示了一个实用的 SFT 掩码实现:
import torch
import json
from typing import List, Dict
def build_sft_loss_mask(
tokens: torch.Tensor, # (seq_len,) token IDs
step_boundaries: List[Dict], # 每步的起止位置和元信息
tokenizer,
) -> torch.Tensor:
"""为多步推理序列构建 SFT loss mask。
对每个推理步骤进行质量检查,只有通过检查的步骤
才允许参与梯度回传(mask=1),否则被屏蔽(mask=0)。
"""
mask = torch.zeros_like(tokens, dtype=torch.float32)
for step in step_boundaries:
start, end = step["start"], step["end"]
step_text = tokenizer.decode(tokens[start:end])
# 检查 1:JSON 格式是否可解析
if step.get("type") == "tool_call":
try:
parsed = json.loads(step_text)
# 检查 2:工具名是否在合法列表中
if parsed.get("tool") not in step.get("valid_tools", []):
continue # 非法工具调用,跳过(mask 保持 0)
except json.JSONDecodeError:
continue # JSON 解析失败,跳过
# 检查 3:代码执行结果是否正常
if step.get("type") == "code_exec":
if step.get("exec_status") in ("crash", "timeout", "oom"):
continue # 执行异常,跳过
# 通过所有检查,允许该步骤参与训练
mask[start:end] = 1.0
return mask
def masked_sft_loss(
logits: torch.Tensor, # (batch, seq_len, vocab_size)
labels: torch.Tensor, # (batch, seq_len)
loss_mask: torch.Tensor, # (batch, seq_len)
) -> torch.Tensor:
"""应用掩码的 SFT 交叉熵损失。"""
shift_logits = logits[:, :-1, :].contiguous()
shift_labels = labels[:, 1:].contiguous()
shift_mask = loss_mask[:, 1:].contiguous()
# 逐 token 计算交叉熵
loss_per_token = torch.nn.functional.cross_entropy(
shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1),
reduction="none",
).view(shift_labels.shape)
# 应用掩码:只对合法步骤计算损失
masked_loss = (loss_per_token * shift_mask).sum()
num_valid = shift_mask.sum().clamp(min=1.0)
return masked_loss / num_valid这段代码的关键设计在于逐步骤检查:不是简单地根据最终奖励决定整条序列的 mask,而是对序列中的每个推理步骤独立判断其质量。一条包含 5 个推理步骤的序列,可能前 3 步格式正确、第 4 步 JSON 解析失败、第 5 步工具调用非法——此时只有前 3 步参与梯度计算,最大化了有效训练信号的利用率。
16.6.3 中间步骤奖励
标准的 RL 奖励设计通常只在序列末尾给出一个终端奖励(Terminal Reward):答案正确得 1 分,错误得 0 分。这种稀疏奖励在短序列任务上尚可工作,但在长推理链场景下会导致严重的信用分配问题(Credit Assignment Problem)——模型无法知道是哪一步推理做对了、哪一步走偏了。
中间步骤奖励(Intermediate Step Reward) 的核心思想是:对正确推理链的关键中间步骤给予额外的奖励加成(Bonus),让模型获得更密集的学习信号。典型的多步奖励分配方案如下表所示:
| 奖励维度 | 权重 | 判定标准 |
|---|---|---|
| 工具选择正确性 | 0.5 | 与 Ground Truth 的工具名完全匹配 |
| 参数正确性 | 0.2 | 工具参数的键值对与 GT 一致 |
| 推理链质量 | 0.2 | Thought 中包含逻辑连词("首先"、"然后"、"因为") |
| 规划完整性 | 0.1 | Plan 字段覆盖了后续所有必要步骤 |
表 16-5:多步 Agent 任务的奖励分配方案。
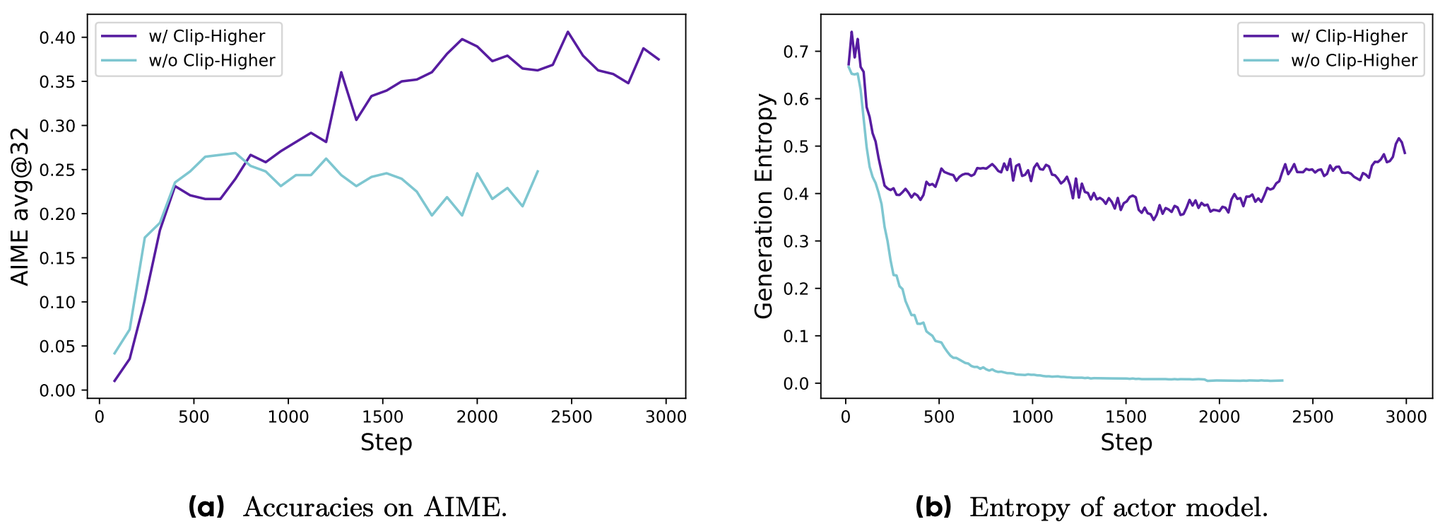
图 16-11:Clip-Higher(非对称裁剪)对训练稳定性的影响。左图:使用 Clip-Higher(紫色)的模型准确率持续上升,而不使用(蓝色)的模型在早期就停滞不前。右图:不使用 Clip-Higher 时策略熵迅速坍缩至零(模型退化为"复读机"),而 Clip-Higher 有效维持了健康的探索水平。
奖励函数设计中有两个容易被忽略的关键细节:
分数上限必须可达 1.0。 如果各项奖励相加的理论最大值只有 0.8,那么模型的所有完美表现都无法获得满分,组内归一化后的优势值分辨率会大幅下降。务必确保当模型输出完全正确时,总奖励恰好为 1.0。
定向负向惩罚。 通过分析错误日志,如果发现模型在不确定时反复滥用某个特定工具(如过度调用 check_status),应在奖励函数中对该行为施加强惩罚(如 -0.3)。针对具体错误模式的定向惩罚,远比泛化的算法调整更加高效。
多奖励解耦归一化(GDPO)。 当奖励函数包含多个维度(如正确性、格式规范性、安全性)时,还需要警惕奖励坍缩(Reward Collapse)问题。标准做法是将各维度奖励加权求和后做组内归一化,但这会抹平不同维度之间的优先级差异。例如,一个"正确性极高但格式略差"的回答和一个"正确性为零但格式完美"的回答,在求和归一化后可能获得几乎相同的优势值。
GDPO(Group reward-Decoupled normalization Policy Optimization,分组奖励解耦归一化)的核心思想是先对每个奖励维度独立做组内归一化,再加权求和:
其中
16.6.4 GAR:开放式任务的组内锦标赛奖励
上述奖励设计适用于有明确正确答案的任务(数学题、代码测试)。然而对于开放式任务——创意写作、对话、摘要生成——不存在标准答案,绝对评分的噪声极大:同一篇文章,不同评价者可能给出从 3 分到 8 分的差异。
GAR(Group Arena Reward,组内竞技场奖励) 采用了一种巧妙的替代方案:不给单个回答打绝对分,而是将同一个 Prompt 下模型生成的多个回答放入"竞技场"中进行两两比较(Pairwise Comparison),以相对排名代替绝对分数。
GAR 的工作流程如下:
- 对同一个 Prompt,策略模型采样
个回答 - 对所有
个回答对,使用评判模型(Judge Model)进行两两比较,判定胜负 - 根据每个回答的胜率计算其在组内的排名分数,作为该回答的奖励信号
import numpy as np
from itertools import combinations
from typing import List, Callable
def compute_gar_rewards(
responses: List[str],
prompt: str,
judge_fn: Callable[[str, str, str], float],
) -> np.ndarray:
"""计算 Group Arena Reward (GAR)。
Args:
responses: 同一 prompt 下的 G 个生成回答
prompt: 原始提示
judge_fn: 评判函数,输入 (prompt, resp_a, resp_b),
返回 resp_a 的胜率(0~1,0.5 表示平局)
Returns:
每个回答的归一化 GAR 分数,范围 [0, 1]
"""
n = len(responses)
win_scores = np.zeros(n)
# 循环赛:所有回答两两比较
for i, j in combinations(range(n), 2):
# judge_fn 返回 response_i 的胜率
win_prob_i = judge_fn(prompt, responses[i], responses[j])
win_scores[i] += win_prob_i
win_scores[j] += (1.0 - win_prob_i)
# 归一化到 [0, 1]
total_matches = n - 1 # 每个选手参加 n-1 场比赛
normalized = win_scores / total_matches
return normalized
# 使用示例
def mock_judge(prompt: str, a: str, b: str) -> float:
"""模拟评判函数(实际使用时替换为 LLM Judge)。"""
# 简单示例:更长的回答更可能获胜
return 0.6 if len(a) > len(b) else 0.4
responses = [
"这是一篇关于量子计算的优秀综述...",
"量子计算是一个重要领域...",
"本文深入探讨了量子计算的核心原理...",
"量子计算利用量子力学原理进行信息处理...",
]
rewards = compute_gar_rewards(responses, "请写一篇量子计算综述", mock_judge)
print(f"GAR 奖励分数: {rewards}")
# 示例输出: GAR 奖励分数: [0.60 0.33 0.73 0.33]GAR 的优势在于:相对比较的一致性远高于绝对评分。即使评判模型对文章质量的绝对判断不够准确,它在"A 比 B 好"这种相对判断上通常是可靠的。这种机制有效降低了主观评估中的噪声和方差,为开放域对齐提供了更稳定的奖励信号。
GAR 与 GRPO 的组内归一化机制天然契合:GRPO 本身就是对同一 Prompt 下的多个采样回答计算相对优势值,GAR 只是将"比较"这一步从数值奖励的减法运算替换为了 Judge Model 的语义比较,概念上完全一致。当 Group Size
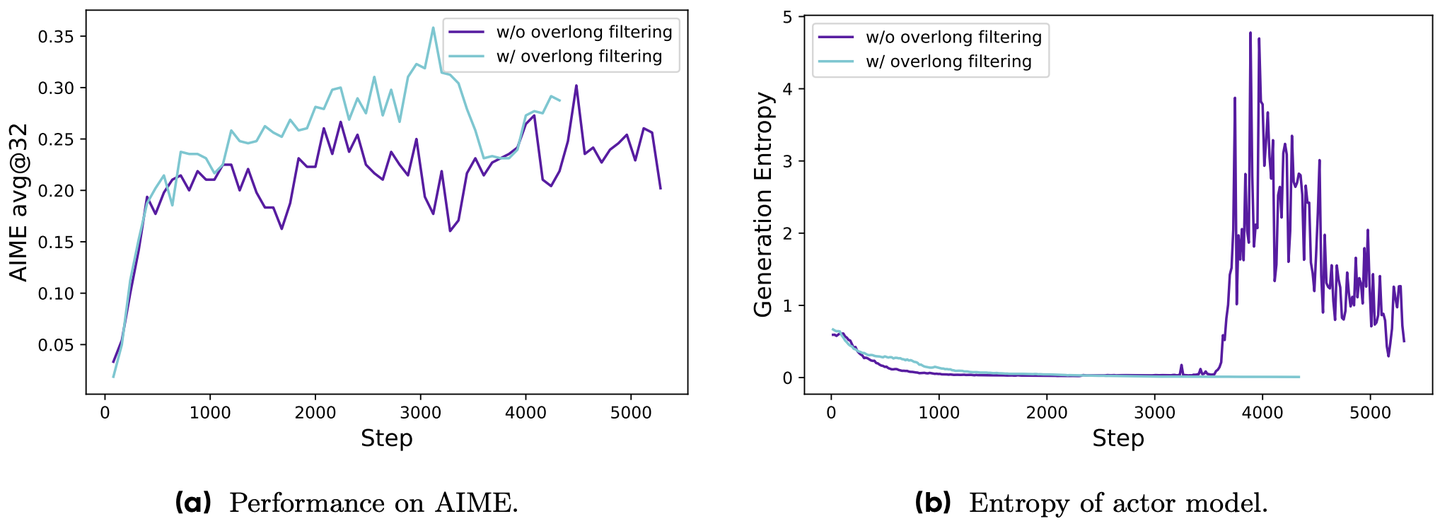
图 16-12:Overlong Filtering(过长过滤)对长序列推理任务的影响。左图显示启用过长过滤(蓝色)后准确率上升更平稳;右图中不使用过长过滤(紫色)的训练出现严重的熵震荡和爆炸,说明截断序列的噪声对策略更新具有显著破坏性。
16.6.5 训练监控指标体系
工程稳定性不仅依赖于算法设计,更依赖于实时监控和快速干预。以下四个核心指标构成了 RL 训练的"仪表盘":
| 监控指标 | 健康状态 | 异常信号与应对 |
|---|---|---|
| frac_reward_zero_std(零方差批次占比) | < 30% | > 50%:模型丧失学习信号,需引入虚拟样本注入或细化奖励函数 |
| reward/mean(平均奖励) | 平稳上升 | 卡在某个非满分阈值:检查奖励函数上限是否为 1.0 |
| grad_norm(梯度范数) | 持续稳定的非零值 | 持续逼近零:检查零方差现象或梯度冲突抵消 |
| completion_length(平均生成长度) | 平稳 | 极度接近 max_length:模型陷入循环,需加入过长惩罚 |
表 16-6:RL 训练核心监控指标及其诊断规则。
其中 frac_reward_zero_std 是最容易被忽视但最具诊断价值的指标。在 GRPO 等基于组内归一化的算法中,当一个 Group 内所有回答的奖励完全相同时(方差为零),优势函数
应对方案是虚拟样本注入(NGRPO):在计算优势值之前,向每个 Group 的奖励列表中注入一个虚拟满分样本(score = 1.0)。即使模型生成的 4 个回答全部得 0.8 分,加入虚拟 1.0 后,均值变为 0.84、标准差不再为零,原本得 0.8 的样本会获得负向优势值,模型因此得知"还有提升空间",梯度信号得以恢复。
16.6.6 小结
RL 训练的工程稳定性是一个多维度的系统工程问题。本节讨论的核心要点可以归纳为以下优先级:
- 消除训推不匹配:确保推理引擎和训练框架在精度、路由、编解码上保持一致,这是一切 RL 算法正常工作的前提
- 守好 SFT 掩码底线:错误的推理步骤绝不应参与梯度回传,否则相当于教模型犯错
- 密集化奖励信号:通过中间步骤奖励和定向惩罚,让模型获得更高分辨率的学习反馈
- 适配任务类型:有标准答案的任务用基于规则的可验证奖励,开放式任务用 GAR 锦标赛机制
- 建立监控体系:盯紧零方差批次占比、奖励曲线、梯度范数和生成长度四个核心指标
记住一条工程箴言:在 RL 训练中,关注 reward curve 而非 loss curve。Loss 在 RL 中不再是模型质量的可靠指标,奖励曲线的趋势才真正反映了策略的进化方向。