21.2 编码智能体
编写代码是当今大语言模型最成功的应用之一。从最初的自动补全几行代码,到独立完成一个 GitHub Issue,再到端到端地开发整个项目,编码智能体(Coding Agent)的能力边界正在以惊人的速度扩展。如果说上一节介绍的通用智能体框架描绘了"感知-推理-行动-记忆"的抽象骨架,那么编码智能体就是这一骨架在软件工程领域最成熟的肉身。
本节将建立一个系统的分类框架,从 IDE 内代理、CLI 代理 到 Repo 级代理 三个层次解剖编码智能体的架构与工作流。我们还会深入讨论编码智能体的四项核心能力——任务规划、代码搜索、文件编辑和 Shell 执行——以及 SWE-Bench 等评估基准。学完本节后,读者应能清楚回答三个问题:当前的编码智能体能做什么、不能做什么、以及它们正在往哪个方向演进。
21.2.1 从自动补全到端到端开发:编码智能体的演进
编码智能体的发展可以被概括为三个阶段,每个阶段都代表着能力边界的一次跃迁:
第一阶段:补全几行代码。 以 GitHub Copilot(2021 年发布)为代表。模型根据光标位置的上下文预测接下来的几行代码。这本质上是一个条件语言模型的自回归生成任务——输入是当前文件的前缀,输出是续写的代码片段。用户的角色是持续的审核者和决策者,模型只负责"打字加速"。
第二阶段:完成一个任务或 Issue。 以 Cursor Agent 模式和 Claude Code 为代表。模型不再只是补全代码,而是接受一个自然语言描述的任务(如"给这个 API 加上分页功能"),然后自主规划步骤、搜索相关代码、编辑多个文件、运行测试并修复错误。用户的角色从逐行审核转变为任务委派和结果验证。
第三阶段:端到端的完整开发流程。 以 Devin、OpenAI Codex(云端沙箱版)和 SWE-Agent 为代表。模型接手从需求理解到代码提交的全流程——读 Issue、制定计划、克隆仓库、编写代码、运行测试、提交 Pull Request。人类的角色进一步后退为架构设计者和最终审核者。
这一演进趋势的背后有两个驱动力:基础模型能力的提升(更长的上下文窗口、更强的指令遵循和推理能力)和智能体工程的进步(更好的工具集成、上下文管理和反馈闭环设计)。两者缺一不可——一个再聪明的模型,如果没有文件读写和 Shell 执行的工具链,也无法真正"编程";反过来,一个再精巧的工作流,如果底层模型连 Python 语法都搞不清楚,也注定不会成功。
21.2.2 分类框架:三层编码智能体
我们按照运行环境和自主程度将编码智能体分为三类。
IDE 内代理:Cursor 与 GitHub Copilot
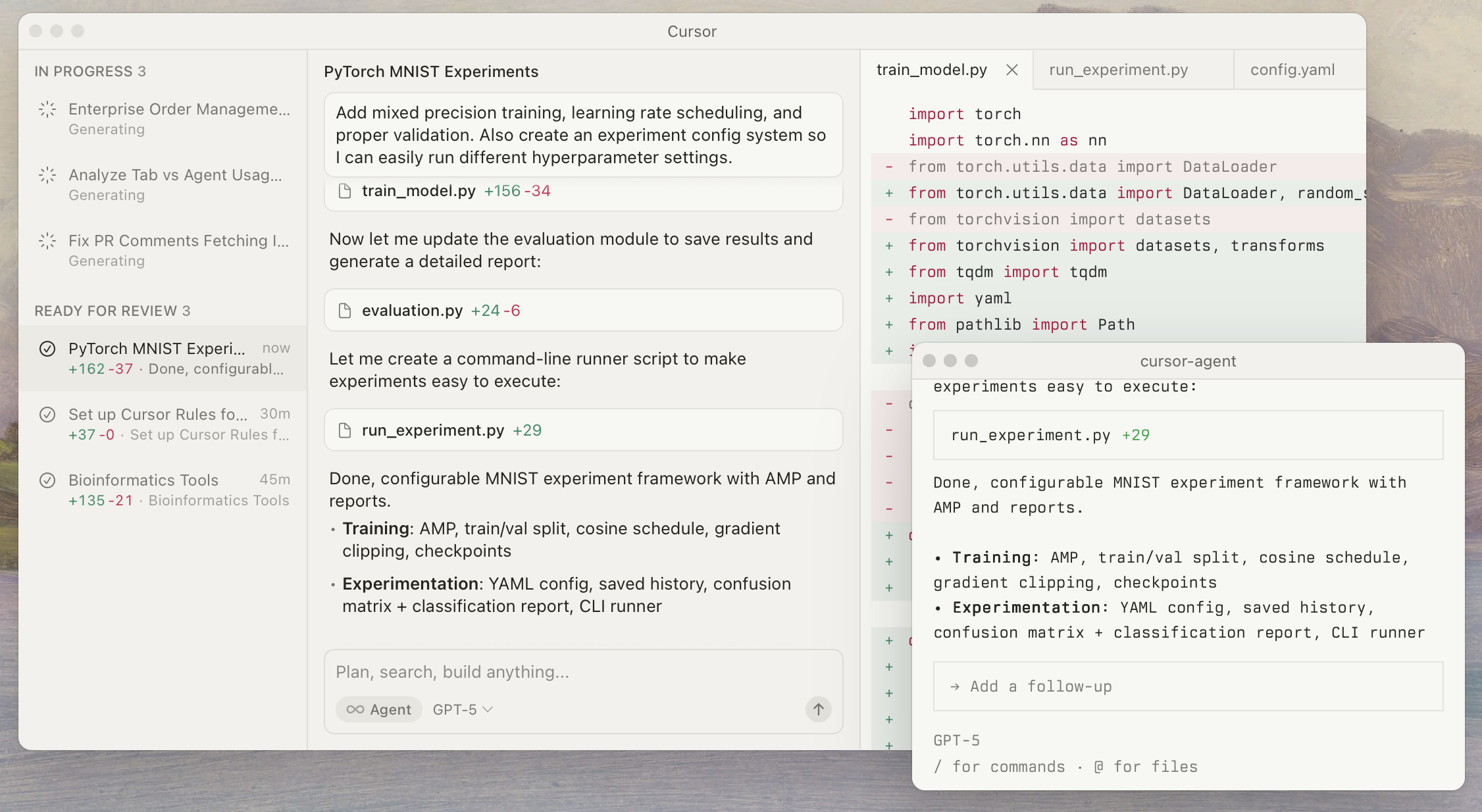
图 21-1:Cursor 的 Agent 模式界面。左侧面板展示正在进行和等待审查的任务列表,中间是代码编辑区,右下角是 Agent 的对话面板。
IDE 内代理直接嵌入开发者的集成开发环境中运行。以 Cursor 为例,它在 VS Code 的基础上深度集成了 AI 能力,形成了三种递进的交互模式:
- Tab 补全模式: 在你打字时实时预测接下来的代码,按 Tab 键接受。这是最轻量的交互,延迟通常在 200–500 毫秒以内。
- Inline Edit(行内编辑): 选中一段代码后用自然语言描述修改意图,模型直接在原位生成 diff(差异补丁)。
- Agent 模式: 输入一个高层任务描述,Agent 自主搜索项目代码、编辑多个文件、在终端执行命令,直到任务完成。

图 21-2:Cursor 由四位 MIT 本科辍学生于 2023 年创立,公司估值在两年内已接近 300 亿美元,成为 AI 编程领域商业化最成功的案例。
GitHub Copilot 则走了另一条路径:它不重新造一个 IDE,而是以插件形式嵌入多种编辑器(VS Code、JetBrains、Neovim 等)。Copilot 从最初的纯补全工具逐步进化,先后添加了 Copilot Chat(对话式交互)和 Copilot Workspace(多文件任务模式)。
IDE 内代理的核心优势在于低摩擦——开发者不需要离开编辑器就能使用 AI,上下文自然就是当前打开的文件和项目。但它们的能力天花板也很明显:受限于 IDE 进程的沙箱环境,通常无法执行需要网络访问、长时间运行或复杂环境配置的任务。
CLI 代理:Claude Code 与 Codex CLI
图 21-3:Claude Code 是第一个基于命令行的编码智能体工具,用户在终端中以自然语言描述任务,Agent 自主探索代码库、编辑文件并执行 Shell 命令。
CLI 代理运行在终端(命令行界面)中,以对话方式接受任务并直接操控文件系统和 Shell。与 IDE 内代理相比,CLI 代理拥有更大的自由度——它可以执行任意 Shell 命令、操作任意目录、调用任意 CLI 工具。
以 Claude Code 为例,它的典型工作流如下:
- 用户在终端中输入自然语言任务描述;
- Agent 使用内置工具搜索代码库(Grep/Glob)、读取文件、理解项目结构;
- Agent 制定执行计划,逐步编辑代码文件;
- Agent 运行测试或构建命令验证修改的正确性;
- 如果测试失败,Agent 读取错误日志并自主修复,形成闭环。
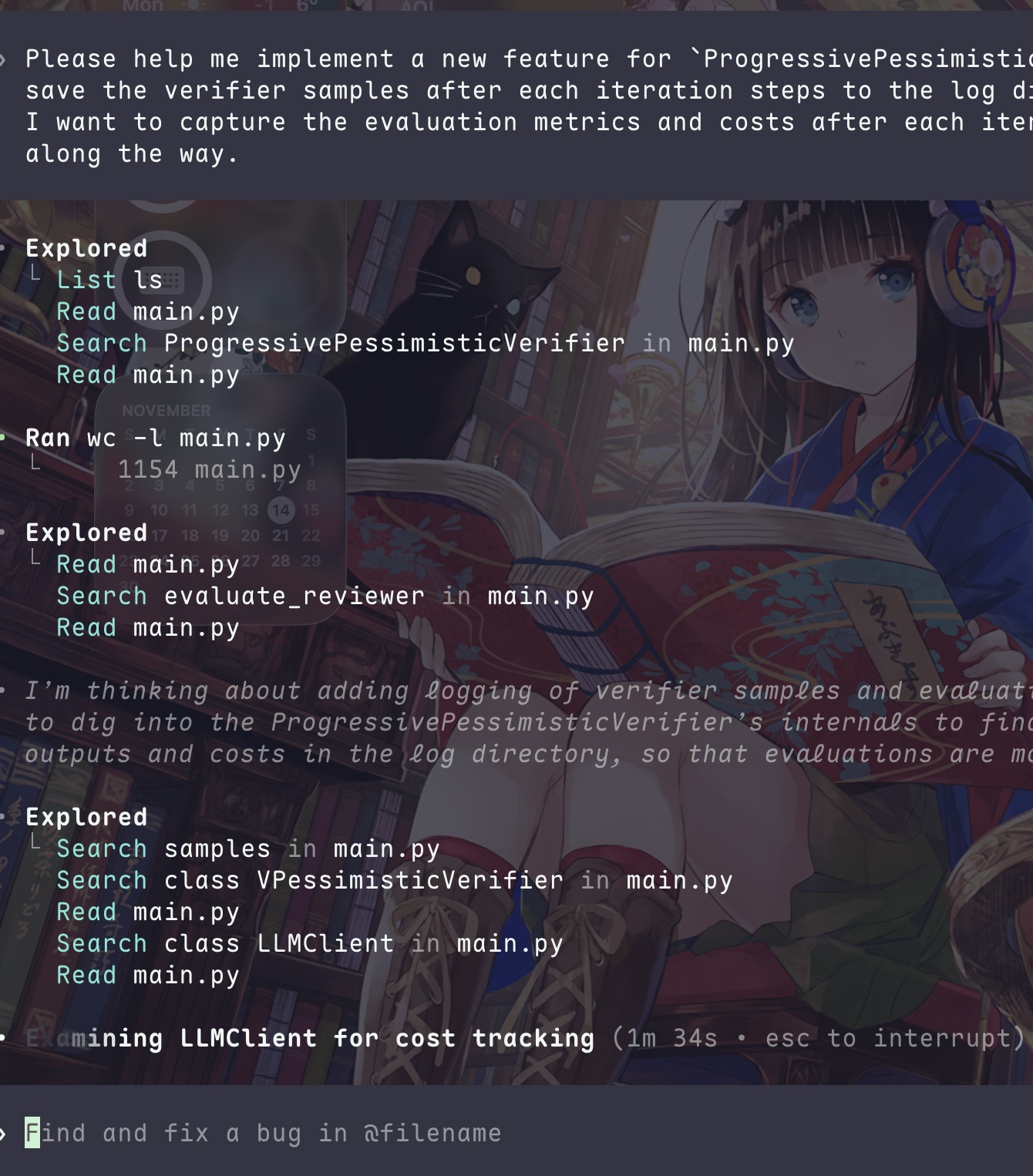
图 21-4:OpenAI Codex 的工作界面。Agent 接到用户请求后,依次执行文件探索、代码搜索、阅读理解、规划和编辑等步骤,整个过程在云端沙箱中自主完成。
OpenAI Codex(云端版)进一步将 CLI 代理的理念推向极端:它为每个任务启动一个独立的云端沙箱,Agent 在其中拥有完整的 Linux 环境、可以安装依赖、运行服务。任务完成后将结果(代码变更、测试结果)同步回本地。这种架构的好处是完全隔离——Agent 的操作不会意外破坏本地环境;代价是引入了网络延迟和计算成本。
图 21-5:Codex 完成任务后产出代码变更和更新文档,Agent 的推理过程、编辑操作和执行计划在界面中透明可见。
CLI 代理的架构可以用一段简洁的伪代码来概括:
# 编码智能体的核心循环(简化伪代码)
def coding_agent_loop(task: str, tools: dict):
"""
编码智能体的基本执行循环。
接受一个自然语言任务描述,通过工具调用-反馈循环完成任务。
"""
messages = [{"role": "user", "content": task}]
while True:
# 1. 调用大语言模型,获取下一步动作
response = llm_call(messages)
# 2. 如果模型认为任务完成,退出循环
if response.is_final_answer:
return response.content
# 3. 解析模型输出的工具调用
tool_name = response.tool_call.name # 如 "read_file", "edit_file", "bash"
tool_args = response.tool_call.arguments # 如 {"path": "src/main.py"}
# 4. 执行工具并获取结果
result = tools[tool_name](**tool_args)
# 5. 将结果反馈给模型,进入下一轮
messages.append({"role": "assistant", "content": response.raw})
messages.append({"role": "tool", "content": str(result)})这个循环看似简单,但有效的编码智能体在这个骨架之上叠加了大量的工程优化:上下文窗口管理、工具结果压缩、错误重试策略、子任务委派等。
Repo 级代理:Devin 与 SWE-Agent
Repo 级代理是自主程度最高的编码智能体。它们接受一个 GitHub Issue 或高层需求描述作为输入,端到端地完成从代码理解到提交 Pull Request 的全流程,中间几乎不需要人类介入。
Devin(Cognition Labs, 2024)是第一个引发广泛关注的 Repo 级代理。它提供了一个完整的虚拟开发环境——包含浏览器、代码编辑器、终端——并能在这些工具之间自如切换。Devin 在发布时声称在 SWE-Bench 上取得了 13.86% 的 Issue 解决率(后续修正为更保守的数字),引发了"AI 是否将取代程序员"的大讨论。
SWE-Agent(Princeton, 2024)则走了一条更学术化的路径。它是一个开源框架,专注于研究如何设计智能体与代码仓库的交互界面(Agent-Computer Interface, ACI)。SWE-Agent 的核心洞察是:交互界面的设计对智能体性能的影响,不亚于底层模型的选择。 例如,将文件浏览从"一次显示整个文件"改为"每次显示一个窗口(约 100 行),支持上下滚动和搜索",就能显著提升 Agent 在复杂代码库中的导航成功率。
Repo 级代理的典型工作流包含以下阶段:
| 阶段 | 具体动作 | 典型工具 |
|---|---|---|
| 需求理解 | 读取 Issue 描述,理解期望行为和复现步骤 | GitHub API |
| 代码定位 | 在仓库中找到相关文件和函数 | Grep, 语义搜索, AST 分析 |
| 方案规划 | 制定修改计划(改哪些文件、怎么改) | 推理能力 |
| 代码编辑 | 按计划修改代码 | 文件编辑工具 |
| 验证测试 | 运行现有测试,确认修改不破坏已有功能 | Shell 执行 |
| 错误修复 | 如果测试失败,读取错误信息并迭代修复 | 反馈闭环 |
| 提交结果 | 生成 commit message,提交 PR | Git 命令 |
Repo 级代理面临的最大挑战是长期一致性:在跨越数十个工具调用和数万 Token 的上下文后,如何保持对任务目标的准确记忆和对已做修改的正确追踪。这也是上下文工程(Context Engineering)如此重要的原因——我们将在 21.6 节专门讨论这一话题。
21.2.3 编码智能体的四项核心能力
不论属于哪一类,所有编码智能体都围绕四项核心能力构建。
能力一:任务规划(Task Planning)。 面对一个复杂需求,Agent 需要将其分解为可执行的子步骤。优秀的规划能力意味着 Agent 能识别任务之间的依赖关系,确定正确的执行顺序,并在遇到阻碍时灵活调整计划。例如,面对"给 API 加分页功能"这个任务,Agent 应能规划出:(1) 查找 API 路由定义,(2) 理解当前查询逻辑,(3) 修改查询加入 offset/limit 参数,(4) 更新响应格式,(5) 添加测试用例,(6) 更新 API 文档。
能力二:代码搜索(Code Search)。 在一个可能包含数千个文件的代码库中,精准定位与任务相关的代码是成功的前提。编码智能体通常组合使用多种搜索策略:
# 编码智能体常用的搜索策略组合
def multi_strategy_search(query: str, codebase_root: str) -> list[str]:
"""
组合多种搜索策略定位相关代码。
实际的编码智能体会在这些策略之间动态选择。
"""
results = []
# 策略1: 文件名模式匹配(快速缩小范围)
# 例如搜索 "pagination" 相关文件
glob_matches = glob_search(codebase_root, f"**/*{query}*")
results.extend(glob_matches)
# 策略2: 全文关键词搜索(精确定位引用)
grep_matches = grep_search(codebase_root, query)
results.extend(grep_matches)
# 策略3: 语义搜索(理解意图而非匹配字面量)
# 基于嵌入向量的相似度检索
semantic_matches = embedding_search(query, codebase_index)
results.extend(semantic_matches)
# 去重并按相关性排序
return rank_and_deduplicate(results)能力三:文件编辑(File Editing)。 编码智能体需要精确地修改代码文件,而不是每次都重写整个文件。主流的做法是生成差异补丁(diff)——模型输出需要替换的旧文本和新文本,由工具负责定位和替换。这种方式比"重写整个文件"高效得多,且不会意外覆盖无关代码。
能力四:Shell 执行(Shell Execution)。 代码写完了不等于任务完成——必须运行才能知道对不对。Shell 执行能力使 Agent 能够运行测试、安装依赖、启动服务、查看日志,形成"编辑-运行-反馈-修复"的闭环。这个闭环的重要性怎么强调都不过分:没有执行反馈的 Agent,本质上仍是一个"盲写"的代码生成器。
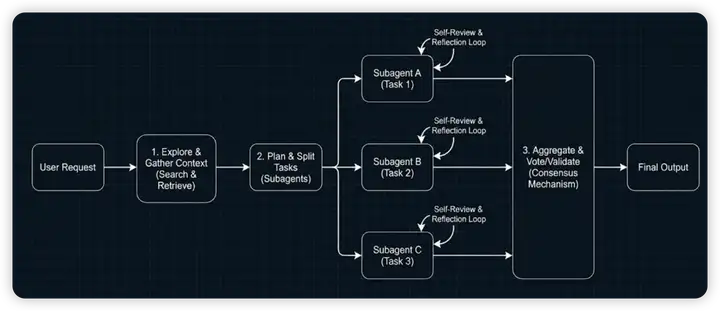
图 21-6:编码智能体的完整工作流。用户请求首先经过探索和上下文收集,然后被拆分为子任务,各子任务由独立的 Subagent 并行执行(每个 Subagent 包含自审查和反思循环),最终通过聚合和投票机制得到可靠输出。
21.2.4 实践经验:让编码智能体更可靠
在实际使用编码智能体时,经验丰富的开发者总结出了一系列让 Agent 更可靠的工程实践。
先探索,后规划(Explore before Plan)。 直接让 Agent 动手写代码,它很可能会基于预训练知识"凭空编造"不存在的 API 或函数。更好的做法是要求 Agent 先花时间探索代码库——阅读目录结构、搜索关键函数、理解现有设计模式——再基于收集到的信息制定计划。这个原则的本质是用真实上下文替换模型的先验知识,从而降低幻觉率。
子任务隔离与上下文管理。 过长的上下文会让模型"注意力涣散"——早期的指令被忘记、信息被混淆、幻觉增加。有效的对策是使用 Subagent(子智能体) 隔离上下文:将大任务拆分为小的子任务,每个子任务由独立的 Subagent 处理,只传回压缩后的结果。例如,让一个 Subagent 专门负责"爬取并总结文档",另一个负责"运行测试并报告失败项",主 Agent 只需要处理精炼后的信息。
自审查与反思(Self-Review & Reflection)。 让 Agent 在完成编码后进行自我审查,可以捕获一部分低级错误。更进一步,可以启用冗余并行——让多个 Agent 独立完成同一任务,然后通过投票或交叉审查选出最优结果。
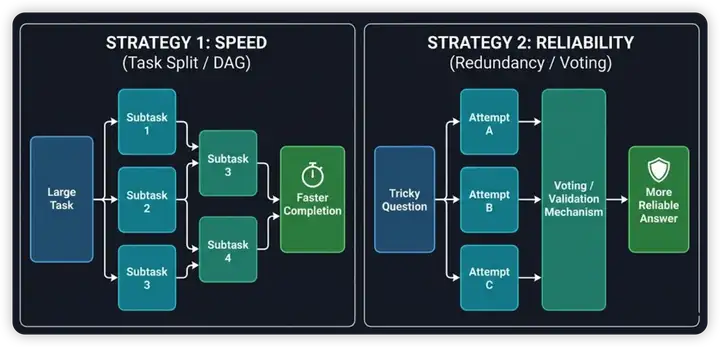
图 21-7:编码智能体的两种并行策略。左:任务拆分(Task Split),将大任务分解为子任务并行执行以加速完成。右:冗余并行(Redundancy),对同一问题多次独立求解,通过投票/验证机制提升可靠性。
强制验证闭环。 Agent 天生偏好"给出一个看起来合理的答案然后停止"。在没有外部约束的情况下,它会跳过测试直接宣布任务完成。因此,需要在系统层面强制要求 Agent 在提交结果前必须运行测试,测试不通过不允许退出。这就是所谓的**驾驭工程(Harness Engineering)**的核心理念:你越想让 AI 获得更高的自主性,就越要把规矩定死。
以下是一个实现强制验证闭环的示例:
# 强制验证闭环的实现模式
def coding_agent_with_verification(task: str, max_retries: int = 3):
"""
带强制验证的编码智能体循环。
Agent 必须通过测试才能声明任务完成。
"""
# 阶段1: 探索代码库,收集上下文
context = explore_codebase(task)
# 阶段2: 基于上下文制定计划
plan = make_plan(task, context)
# 阶段3: 执行计划
for step in plan:
execute_step(step)
# 阶段4: 强制验证(不可跳过)
for attempt in range(max_retries):
test_result = run_tests()
if test_result.all_passed:
return "任务完成,所有测试通过"
# 测试失败:读取错误日志,要求 Agent 修复
error_log = test_result.error_output
fix_plan = analyze_and_fix(error_log, attempt_number=attempt)
execute_step(fix_plan)
return "达到最大重试次数,需要人工介入"21.2.5 驾驭工程:编码智能体的控制论
当编码智能体的能力足够强大,能够自主编写数十万行代码时,一个新的工程挑战浮现出来:如何确保 Agent 产出的代码不会偏离设计意图? 这就是**驾驭工程(Harness Engineering)**要解决的问题。
驾驭工程的演进脉络清晰地映射了 AI 工程范式的三代发展:
| 代际 | 范式 | 核心问题 | 交互模式 |
|---|---|---|---|
| 第一代 | Prompt Engineering | 怎么跟 AI 说话 | 一问一答 |
| 第二代 | Context Engineering | 怎么给 AI 喂信息 | 给背景资料,AI 生成 |
| 第三代 | Harness Engineering | 怎么构建 AI 的自治环境 | 人造环境,AI 在里面跑 |
驾驭工程的五大核心组件包括:
1. 渐进式知识披露(Progressive Disclosure)。 不要把所有规范塞进一个巨大的配置文件——Agent 的注意力有限,"一切都重要等于一切都不重要"。正确的做法是建立一个层次化的文档目录,Agent 启动时只加载顶层地图,随后按需加载具体规范。
2. 机械化的架构约束。 将代码风格和架构规范编码为自动化的 Linter 规则和 CI 检查。关键的一点是,当规则被违反时,报错信息中必须包含修复指令——这样 Agent 遇到错误就能自动修正,而不是陷入反复试错。
3. 机器可读的可观测性。 传统的日志和监控面板是给人看的,但 Agent 需要的是结构化的、可程序化查询的反馈。为 Agent 提供独立沙箱环境、日志查询接口,甚至浏览器自动化能力(截图比对 UI 渲染结果),是让 Agent 从"盲写"走向"闭环验证"的关键基础设施。
4. 死循环检测与强制打断。 Agent 容易陷入对同一个文件反复修改却无法修好的死循环。系统应监控同一文件的编辑次数,一旦超过阈值,强制注入打断提示:"你已经尝试多次但未成功,请退后一步重新审视问题。"
5. 防熵增机制。 AI 产出代码极快,但也会快速累积技术债务。可以设立专门的"文档园丁"Agent 和"技术债清理"Agent,以高频率、小粒度的方式持续维护代码质量。
21.2.6 评估基准:SWE-Bench 与同类
如何客观衡量编码智能体的能力?学术界和工业界围绕这一问题开发了一系列评估基准。
SWE-Bench(Princeton, 2024)是目前最具影响力的编码智能体基准。它从 12 个流行的 Python 开源仓库(如 Django、Flask、scikit-learn、sympy 等)中收集了 2294 个真实的 GitHub Issue,每个 Issue 配有人类开发者编写的修复补丁和相应的测试用例。Agent 的任务是:给定一个 Issue 描述和代码仓库的完整快照,生成一个能通过测试的修复补丁。
SWE-Bench 的评估指标简洁而有力:解决率(Resolve Rate)——在所有 Issue 中,Agent 成功生成了通过测试的补丁的比例。由于完整的 2294 个 Issue 中存在测试噪声(如测试本身有 bug),SWE-Bench 团队后来发布了人工校验过的子集 SWE-Bench Verified(500 个 Issue),提供更干净的评估信号。
截至 2025 年中,顶尖编码智能体在 SWE-Bench Verified 上的解决率已突破 70%,这意味着 Agent 能独立修复大多数中等难度的真实软件 Bug。但需要注意,SWE-Bench 衡量的是"修复已有 Bug"的能力,而非"从零开发新功能"——后者涉及更多设计决策,是当前基准尚未很好覆盖的领域。
除 SWE-Bench 外,还有以下值得关注的评估基准:
| 基准 | 侧重点 | 规模 | 特点 |
|---|---|---|---|
| SWE-Bench | Bug 修复 | 2294 Issue | 真实 GitHub Issue,Python 仓库 |
| SWE-Bench Verified | Bug 修复(已校验) | 500 Issue | 人工校验测试质量 |
| HumanEval | 函数级代码生成 | 164 题 | 经典基准,但已趋于饱和 |
| MBPP | 入门级编程 | 974 题 | 难度较低,主要测试基础能力 |
| LiveCodeBench | 竞赛编程 | 持续更新 | 使用发布后的竞赛题目防止数据泄露 |
| Aider Polyglot | 多语言代码编辑 | 多语言 | 测试多种编程语言的编辑能力 |
| Terminal-Bench | 系统管理 | 多场景 | 测试 Shell 命令和系统操作能力 |
值得思考的是,现有基准大多聚焦于短期、独立的编程任务。而编码智能体在实际使用中面临的挑战往往是长期项目中的跨文件、跨模块的复杂修改,这类场景的自动化评估仍是一个开放问题。
21.2.7 发展趋势与未来展望
编码智能体领域正处于快速演进之中。以下几个趋势值得密切关注。
趋势一:从"人驱动 AI"到"AI 驱动 AI"。 编码智能体已经开始被用于开发编码智能体本身。例如,Claude Code 的相当一部分代码就是由 Claude Code 自己编写的。这种自举(bootstrapping)趋势意味着编码智能体的改进速度可能呈现加速态势。
趋势二:多 Agent 协作。 单个 Agent 处理复杂项目时面临上下文窗口和注意力的瓶颈。越来越多的系统开始采用多 Agent 架构——一个 Architect Agent 负责需求分析和任务拆分,多个 Coding Agent 并行执行子任务,一个 Reviewer Agent 负责审查和质量把关。这种架构本质上是用"分治"策略对抗上下文长度的限制。
趋势三:基础模型与 Agent 的双向优化。 新一代基础模型(如 Claude 系列、GPT-4.1、Kimi K2 等)在训练时就越来越重视 Agentic 能力——更好的工具调用、更长的上下文、更强的指令遵循。模型和 Agent 框架之间呈现"双向奔赴"的态势:模型为 Agent 提供更强的"大脑",Agent 的需求反过来指引模型训练的优化方向。
趋势四:编程范式的转变——氛围编程(Vibe Coding)。 越来越多的开发者不再逐行编写代码,而是用自然语言描述意图,让 Agent 生成代码后再审查和调整。这种被称为"氛围编程"的工作方式正在重塑软件开发的日常实践。正如一位深度使用编码智能体的研究者所描述的:"时至今日,我的科研代码中已有 90% 以上由编码智能体编写。"
然而,我们也需要清醒地认识到编码智能体当前的局限性:
- 幻觉: Agent 可能自信地使用不存在的 API 或编造函数签名。
- 长期一致性: 在跨越数小时的长任务中,Agent 容易丢失早期的指令和上下文。
- 架构设计能力: 修复 Bug 和实现需求对 Agent 来说相对容易,但做出好的架构设计决策仍是显著的弱项。
- 业务理解: Agent 缺乏对业务领域的深层理解,容易在指令模糊时做出不当假设。
正如一位实践者形象的比喻:Agent 就像"一群不知疲倦、痴痴傻傻的实习生——它们打字飞快、从不抱怨加班,但你必须用足够清晰的指令和足够严格的检查机制来驾驭它们。"
本节小结
本节系统介绍了编码智能体的分类框架、核心能力、工程实践和评估基准。编码智能体按运行环境可分为三类:嵌入 IDE 的低摩擦代理(Cursor、Copilot)、运行在终端的高自由度 CLI 代理(Claude Code、Codex CLI),以及执行端到端开发流程的 Repo 级代理(Devin、SWE-Agent)。无论哪一类,其核心能力都围绕任务规划、代码搜索、文件编辑和 Shell 执行四个维度展开。在实践中,先探索后规划、子任务隔离、强制验证闭环等工程策略能显著提升 Agent 的可靠性。驾驭工程(Harness Engineering)作为 AI 工程的第三代范式,通过构建约束-反馈-控制系统来驯服编码智能体的自主行为。SWE-Bench 等基准为衡量 Agent 能力提供了客观标尺,顶尖 Agent 在其上的解决率已突破 70%。编码智能体正在从"辅助工具"走向"自主开发者",但在架构设计、业务理解和长期一致性方面仍存在显著差距——这也正是后续章节中上下文工程、记忆系统等主题的研究动机所在。