1.5 混合精度训练
训练一个大语言模型,最直观的瓶颈是显存。以 7B 参数的模型为例,若所有参数、梯度和优化器状态均以 FP32 存储,仅静态显存就需要约 112 GB——这远超单张消费级 GPU 的容量。然而,深度学习的计算并不总是需要 32 位浮点数的全部精度。混合精度训练(Mixed Precision Training)正是基于这一洞察:在训练流程的不同阶段使用不同精度的浮点格式,在不牺牲模型收敛质量的前提下,大幅降低显存占用并加速计算。
这一技术由 NVIDIA 在 2017 年提出(Micikevicius et al., 2018),如今已成为大模型训练的标准实践。要理解混合精度训练为何有效、又为何需要精心设计,首先需要理解不同浮点格式的数值特性。
1.5.1 浮点数的表示:FP32、FP16、BF16 与 FP8
计算机中的浮点数遵循 IEEE 754 标准,由三部分组成:符号位(Sign)决定正负,指数位(Exponent)决定数值的动态范围——即能表示的最大值与最小值之间的跨度,尾数位(Mantissa/Fraction)决定数值精度——即相邻两个可表示数之间的间距。一个浮点数的值可以写为:
其中偏置值
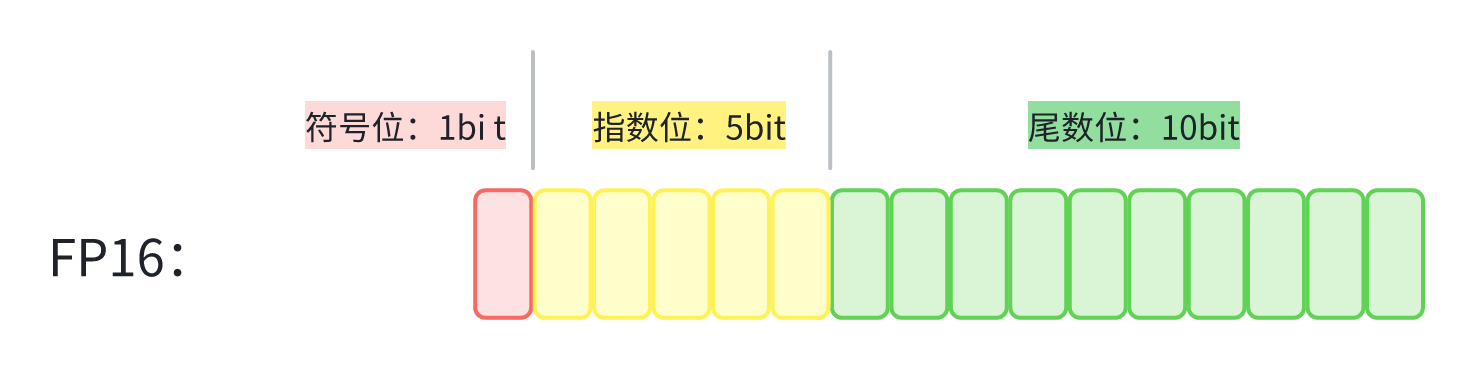
图 1-10:FP16 的位分配结构。1 位符号位(粉色)、5 位指数位(黄色)、10 位尾数位(绿色),共 16 位。不同浮点格式的本质区别在于指数位与尾数位之间的"预算分配"。
下表对比了训练中常见的几种浮点格式:
| 格式 | 总位数 | 符号位 | 指数位 | 尾数位 | 每参数字节 | 动态范围 | 典型用途 |
|---|---|---|---|---|---|---|---|
| FP32 | 32 | 1 | 8 | 23 | 4 | 优化器状态、主权重 | |
| FP16 | 16 | 1 | 5 | 10 | 2 | 早期混合精度计算 | |
| BF16 | 16 | 1 | 8 | 7 | 2 | 现代大模型训练主流 | |
| FP8 E4M3 | 8 | 1 | 4 | 3 | 1 | 前向传播、权重存储 | |
| FP8 E5M2 | 8 | 1 | 5 | 2 | 1 | 反向传播、梯度计算 |
这张表格揭示了浮点格式设计的核心权衡:指数位越多,动态范围越大;尾数位越多,数值精度越高。总位数固定时,两者此消彼长。
FP32 是传统的"黄金标准",8 位指数和 23 位尾数兼顾了范围与精度,但每个参数占 4 字节,显存和带宽开销巨大。FP16 将位宽减半,计算速度在 Tensor Core 上大幅提升,但只有 5 位指数,动态范围仅到 65504——对于大模型训练中梯度和激活值动辄出现的极端数值而言,这个范围远远不够。
BF16(Brain Floating Point)是 Google Brain 团队针对深度学习场景设计的格式。它的关键洞察是:深度学习对动态范围的需求远大于对精度的需求。因此 BF16 保留了与 FP32 相同的 8 位指数(相同的动态范围),代价是将尾数位从 23 位削减到 7 位。实践证明,这种精度损失对训练收敛的影响微乎其微,但避免了 FP16 频繁溢出的致命问题。BF16 已成为当代大模型训练事实上的标准计算精度。
FP8 是 NVIDIA H100 引入的前沿格式,追求极致的计算效率。它包含两种变体:E4M3 侧重精度,适合前向传播中的权重和激活值;E5M2 侧重动态范围,适合反向传播中的梯度计算。DeepSeek-V3 等前沿模型已在训练中大规模采用 FP8 混合精度方案。
1.5.2 三类数值问题:上溢、下溢与舍入误差
低精度格式的好处很明显——显存减半、计算加速——但它也引入了三类必须正视的数值风险。
上溢(Overflow) 发生在计算结果超出格式可表示的最大值时。超出的数值会被截断为
import torch
large_value = torch.tensor(65504.0) * 2 # 131008,超出 FP16 范围
print(large_value.to(torch.float16)) # 输出: inf(上溢)
print(large_value.to(torch.bfloat16)) # 输出: 131072.0(正常表示,有精度损失)BF16 拥有与 FP32 相同的指数位,因此几乎不会发生上溢——这是它优于 FP16 的最核心理由。
下溢(Underflow) 是上溢的镜像:当数值过于接近零、小于格式能表示的最小正数时,它会被截断为零。对深度学习而言,下溢的危害比上溢更隐蔽。训练中的梯度值通常在
舍入误差(Rounding Error) 则更为微妙。低精度格式的尾数位较少,意味着相邻两个可表示数之间的间距更大。当一个真实值落在两个可表示数之间时,只能被四舍五入到最近的可表示数。单次舍入的误差虽然微小,但训练是一个成千上万步迭代累加的过程。如果每步更新量
三类问题的严重程度与格式的关系可总结如下:
| 数值问题 | FP32 | FP16 | BF16 | 根本原因 |
|---|---|---|---|---|
| 上溢 | 极罕见 | 高危 | 极罕见 | FP16 指数位仅 5 位,最大值仅 65504 |
| 下溢 | 极罕见 | 高危 | 极罕见 | FP16 最小正数 |
| 舍入误差 | 极小 | 中等 | 中等偏高 | BF16 尾数仅 7 位,精度约 0.8% |
这张表格清晰地说明了为什么单纯地将所有计算切换到低精度是行不通的:FP16 在范围上不安全,BF16 在精度上不充分。混合精度训练的核心思想就是让不同阶段各取所长——计算密集的前向/反向传播用低精度加速,对精度敏感的参数更新用高精度保护。
1.5.3 混合精度训练的完整机制
标准的混合精度训练流程包含三个关键机制,它们协同工作以解决上述数值问题。
机制一:FP32 主权重备份(Master Weights)。 模型参数的"主副本"始终以 FP32 存储。每次前向传播前,主权重被临时转换(cast)为低精度副本(BF16 或 FP16)用于计算;前向和反向传播完成后,计算出的梯度被转换回 FP32,用于更新 FP32 主权重。
为什么必须维护这份 FP32 副本?考虑一个典型场景:权重值
这就是精度累加(Precision Accumulation)的核心原理:微小的梯度更新在低精度下会被逐一丢弃,但在高精度下可以被忠实地逐步积累。数千步之后,FP32 主权重的变化量足够大,转换到 BF16 后也能体现出来。
从显存角度看,维护 FP32 主权重确实增加了开销。以 Adam 优化器为例,每个参数的显存占用如下:
| 存储项 | 精度 | 每参数字节 |
|---|---|---|
| 模型参数(计算用) | BF16 | 2 |
| 梯度 | BF16 | 2 |
| FP32 主权重(Master Weights) | FP32 | 4 |
| Adam 一阶动量 | FP32 | 4 |
| Adam 二阶动量 | FP32 | 4 |
| 合计 | — | 16 |
对比纯 FP32 训练的
机制二:损失缩放(Loss Scaling)。 这是专门为 FP16 设计的保护机制。FP16 的动态范围有限,训练中大量梯度值会下溢为零。损失缩放的思路非常直观:在反向传播开始前,将损失值乘以一个大的缩放因子
PyTorch 通过 GradScaler 实现了动态损失缩放,它根据训练过程的实际情况自动调整缩放因子:
import torch
from torch.cuda.amp import autocast, GradScaler
model = MyModel().cuda()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
scaler = GradScaler() # 初始 scale = 2^16 = 65536
for data, target in dataloader:
optimizer.zero_grad()
# autocast 自动为不同操作选择合适的精度
with autocast(dtype=torch.float16):
output = model(data)
loss = loss_fn(output, target)
# scale(loss) 将损失放大 S 倍后执行反向传播
scaler.scale(loss).backward()
# step() 内部:(1) 将梯度除以 S;(2) 检查是否有 inf/NaN;
# (3) 若无异常则调用 optimizer.step(),否则跳过本步更新
scaler.step(optimizer)
# 动态调整缩放因子:若连续多步无 inf/NaN,则增大 S;
# 若出现 inf/NaN,则减小 S
scaler.update()GradScaler 的工作逻辑可以概括为四步循环:(1)用当前缩放因子
对于 BF16 训练,通常不需要损失缩放。 BF16 拥有与 FP32 相同的 8 位指数,动态范围足以覆盖训练中出现的梯度值,下溢问题大大缓解。这是 BF16 相对于 FP16 的又一重要优势——不仅训练更稳定,代码也更简洁。2024 年以来的主流实践是:
# BF16 混合精度:无需 GradScaler
scaler = GradScaler(enabled=(dtype == 'float16')) # 仅 FP16 时启用
with autocast(dtype=torch.bfloat16):
loss = model(input)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()机制三:算子级精度选择(Autocast)。 并非所有计算都适合用低精度执行。PyTorch 的 autocast 上下文管理器会根据算子类型自动选择精度:矩阵乘法、卷积等计算密集型操作使用低精度(BF16/FP16),因为 Tensor Core 的低精度吞吐量远高于 FP32;而归约操作(如 Softmax、LayerNorm、损失计算)则保持 FP32,因为这些操作对精度敏感且计算量相对较小。
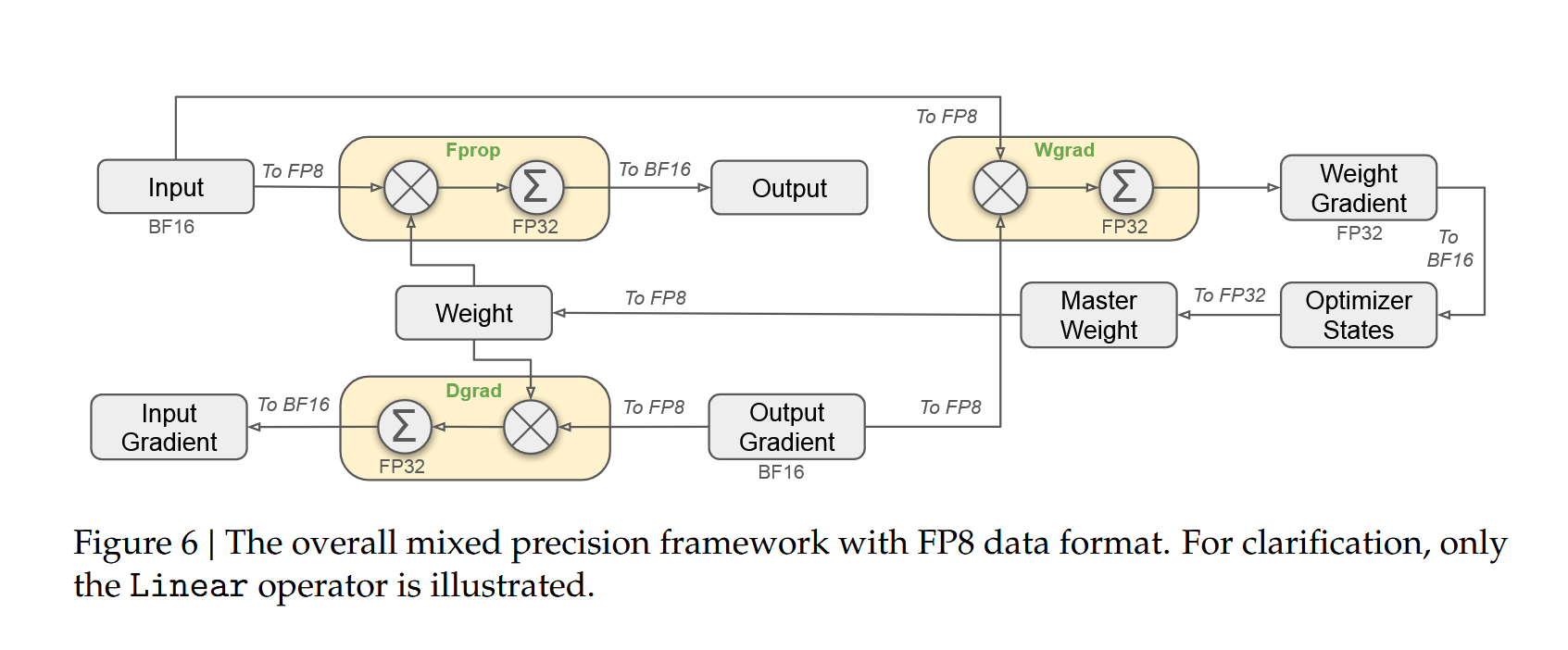
图 1-12:FP8 混合精度训练数据流。前向传播中权重和激活值以 FP8 格式进行矩阵乘法,累加在 FP32 下完成;反向传播中梯度计算遵循类似的精度分配策略。优化器始终在 FP32 下维护主权重。
1.5.4 从 BF16 到 FP8:前沿演进
图 1-11:FP8 混合精度训练的完整数据流(以线性层为例)。前向传播(Fprop)中,输入和权重转为 FP8 进行矩阵乘法,累加在 FP32 下完成,输出转为 BF16;反向传播中梯度计算(Dgrad/Wgrad)遵循类似流程;优化器在 FP32 下维护主权重和动量,更新后的权重再转回 FP8 参与下一轮前向传播。
随着模型规模突破千亿参数,FP8 格式正在成为新的训练标准。NVIDIA H100 的 FP8 Tensor Core 算力达到 BF16 的 2 倍(3958 TFLOPS vs. 1979 TFLOPS),同时每参数仅占 1 字节,通信带宽需求也相应降低。
FP8 训练的关键创新在于双格式策略:前向传播使用 E4M3(4 位指数 + 3 位尾数),以更高精度保护激活值;反向传播使用 E5M2(5 位指数 + 2 位尾数),以更大动态范围覆盖梯度的极端值。这种精细的格式分工,配合 Per-Tensor 动态缩放因子,使得 FP8 训练在收敛质量上能够逼近 BF16。DeepSeek-V3(671B 参数)的实践表明,FP8 混合精度相比 BF16 方案节省约 33% 显存,训练时长减少约 40%,而最终模型困惑度与 BF16 训练相当。
1.5.5 小结
混合精度训练的本质是一种精度预算的精细分配:在训练流程的每个环节,依据该环节对数值范围和精度的实际需求,选择"刚好够用"的浮点格式。前向和反向传播是计算密集型操作,对精度的容忍度较高,适合用 BF16 甚至 FP8 加速;参数更新是精度敏感型操作,微小的梯度必须被忠实累加,需要 FP32 保驾护航。损失缩放则作为安全网,在 FP16 场景下防止梯度下溢。
理解混合精度训练,有三个要点值得铭记:第一,动态范围比精度更重要——这是 BF16 胜过 FP16 的核心原因;第二,FP32 主权重不可省略——没有它,微小梯度的累加效应将完全丧失;第三,GradScaler 是 FP16 训练的必需品,但 BF16 训练可以不用——这使得 BF16 在工程上更加简洁可靠。随着 FP8 乃至更低精度格式的成熟,混合精度训练的精度分配将越来越精细,但其核心思想——让计算快的地方快,让精度高的地方高——始终不变。