20.3 评估基准全景
训练一个大语言模型只是漫长旅程的前半段,如何科学地回答"这个模型到底有多好"才是真正的难题。Andre Karpathy 曾直言"There is an evaluation crisis"——评估看似简单,实则是一个极其深刻且复杂的议题。你追踪什么指标,就会优化什么方向;因此,评估基准不仅是度量工具,更是决定模型未来演进方向的隐形力量。
本节将从知识与推理、指令遵循、综合排行、数学推理、长上下文与幻觉检测、对齐与安全等维度,系统梳理主流评估基准的设计理念与核心方法。
20.3.1 知识与推理基准
MMLU(Massive Multitask Language Understanding) 是知识评估的标杆基准。它于 2020 年发布,包含 57 个学科的多选题,覆盖从高中数学到研究生级别的医学、法律、物理等领域。评估方式通常采用 Few-shot Prompting——在 Prompt 中附带若干示例,让模型直接输出选项字母:
The following are multiple choice questions (with answers) about [subject].
[Example 1]
...
Answer: A
[Actual Question]
...
Answer:
图 20-5:MMLU 基准示例。每个学科包含多选题,模型需结合知识储备与推理能力选出正确答案。
当 GPT-3 首次在 MMLU 上评估时,准确率仅约 45%;而如今的前沿模型(Claude、O3 等)已达 90% 以上,基准逐渐饱和。但 MMLU 虽名为"语言理解",其本质更偏向知识记忆测试——一个语言能力出色但缺乏专业知识的人同样难以取得高分。
MMLU-Pro 是 2024 年推出的升级版。它移除了原版中的噪声和过于简单的问题,将选项数从 4 个增加到 10 个,并采用 Chain-of-Thought(思维链)评估方式,给予模型更多推理空间。这一改进使模型准确率普遍下降 16%--33%,重新拉开了区分度。
C-Eval 是中文领域的代表性综合评估基准,涵盖 52 个学科共 13,948 道多选题,从初中到高级研究级别均有覆盖,特别包含了中文社会与人文相关的题目(如中国历史、政治经济学等),弥补了 MMLU 在中文语境下的空白。C-MMLU(Chinese Massive Multitask Language Understanding) 则进一步扩展了中文知识评估的广度,增加了更多中国特色学科的题目。这两个基准是评估中文大模型不可或缺的工具。
BIG-Bench Hard(BBH) 从 Google 的 BIG-Bench 200+ 任务池中,挑选出 23 个模型表现显著低于人类水平的高难度任务。这些任务涉及多步推理、因果分析、布尔表达式求值等复杂技能。研究发现,若不引入推理引导(如思维链提示),模型在 BBH 上的表现远逊于人类;但通过 Chain-of-Thought Prompting,部分模型能大幅提升甚至超越人类平均水平。这一发现凸显了评估方式本身对结果的巨大影响。
20.3.2 HELM:多维聚合评估框架
单一基准只能照亮模型能力的一个角落。斯坦福 CRFM 提出的 HELM(Holistic Evaluation of Language Models) 框架试图建立全景式的评估标准,将数十种基准聚合在一个统一的排行榜中。
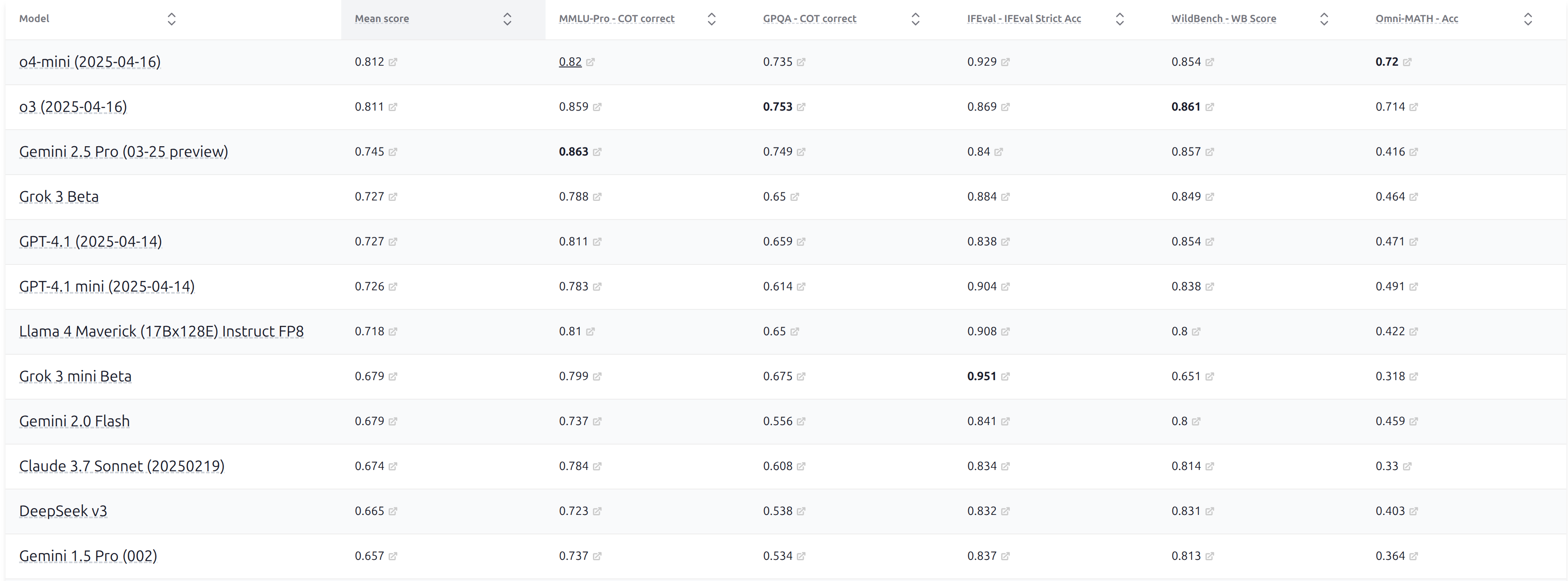
图 20-6:HELM Capabilities 排行榜。将 MMLU、MMLU-Pro、GPQA、IFEval、WildBench 等多种基准汇总,提供模型能力的多维对比视图。
HELM 的核心设计理念有三条:
- 多维度覆盖:不仅评估准确率,还关注有用性(Helpfulness)、诚实性(Honesty)、无害性(Harmlessness)和可信度(Trustworthiness),力图建立更平衡的标准。
- 统一评测协议:所有模型在相同条件下评估,确保结果可横向对比。
- 透明可复现:评估代码、数据和结果完全公开,研究者可深入到具体问题和模型预测的细节层面。
HELM 还推出了面向特定领域的变体,如 MedHELM——从 29 位临床医生处征集了 121 个真实临床任务,远比基于标准化医学考试的基准更贴近实际诊疗场景。
20.3.3 指令遵循评估
ChatGPT 以来,用户与模型的交互方式从"做选择题"变成了"自由对话"。如何评估开放式回复的质量成为核心挑战。
MT-Bench 是一个多轮对话评估基准,包含 80 个精心设计的多轮问题,涵盖写作、角色扮演、推理、数学等类别。它使用 GPT-4 作为裁判(LLM-as-a-Judge),对模型回复按 1--10 分打分。MT-Bench 的独特价值在于它考察了模型在多轮交互中保持一致性和深度的能力,而非单次回答的质量。
AlpacaEval 包含 805 条来自不同来源的指令,同样采用 GPT-4 作为裁判,计算被评估模型相对于基准模型的胜率。早期版本曾被"钻空子"——一些模型通过生成更长的回复获得高分,因为 GPT-4 偏好详细回答。后来引入了长度校正(Length-Controlled, LC) 版本来缓解这一偏差。
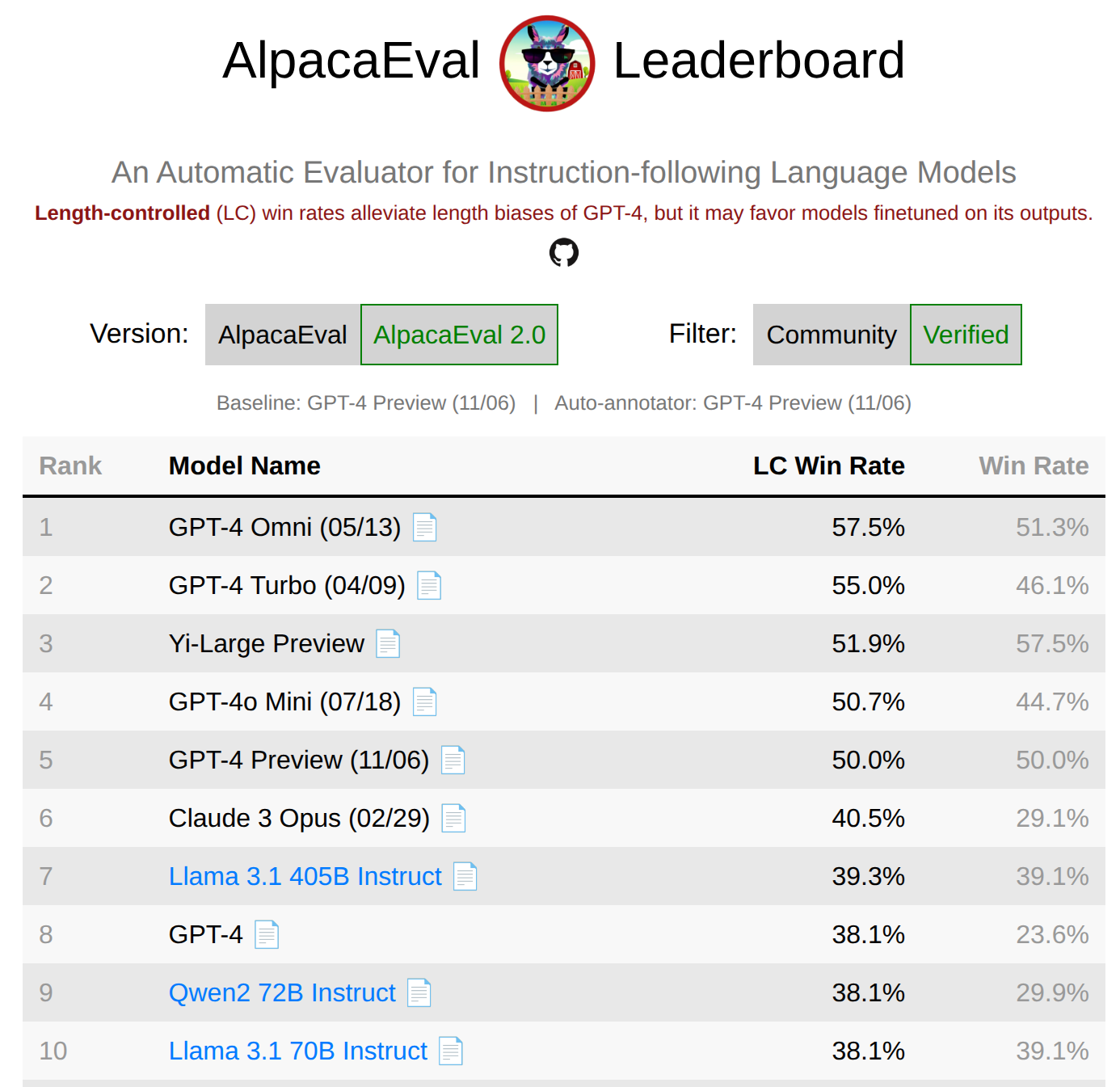
图 20-7:AlpacaEval 排行榜。通过 LLM-as-a-Judge 方式计算模型对基准模型的胜率,长度校正版本缓解了回复长度偏差。
IFEval(Instruction-Following Eval) 则另辟蹊径:它给指令添加可验证的合成约束(如"回答不超过 10 个词""必须包含某个关键词""使用 JSON 格式"),然后用简单脚本自动检查模型是否遵守了这些约束。优点是完全自动化、无需 LLM 裁判;缺点是只评估格式遵循能力,不评估回复的语义质量。
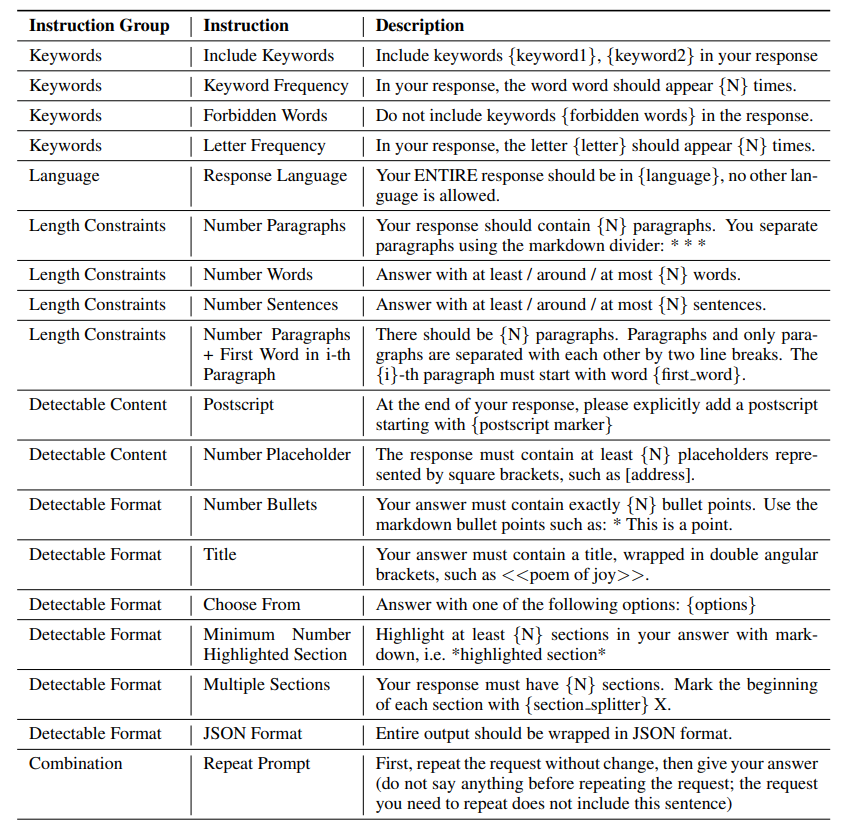
图 20-8:IFEval 定义的约束类别。包括关键词约束、格式约束、长度约束等,均可通过规则脚本自动验证。
这类评估的一个有趣现象是:许多指令遵循基准会用与 Chatbot Arena(基于真实用户配对比较的 ELO 排名系统)的相关性来验证自身有效性。例如,WildBench 与 Chatbot Arena 的排名相关性高达 0.95,AlpacaEval(长度校正版)约 0.90。这从侧面说明,真实用户偏好仍是指令遵循评估的"金标准"。
20.3.4 数学推理评估:从 MATH-500 到等价性验证
数学推理是评估模型"纯粹智能"的重要维度,因为它最大程度地分离了知识记忆与推理能力。MATH-500 是从 MATH 数据集中精选的 500 道数学题,覆盖代数、几何、概率、数论等领域,难度分布均衡,已成为评估推理模型的标准基准之一。
评估数学推理模型时,Prompt 模板的选择对结果影响巨大。一个常用的模板如下:
You are a helpful math assistant.
Answer the question and write the final result on a new line as:
\boxed{ANSWER}
Question:
If $a+b=3$ and $ab=\tfrac{13}{6}$, what is the value of $a^2+b^2$?
Answer:实验表明,仅将模板中的"Question"换成"Problem"一词,就能使基础模型的准确率从 20% 跳升到 40%,而推理模型反而从 90% 下降到 60%。更极端地,完全不使用模板(直接传入题目文本)可使基础模型达到 70%——因为它更接近预训练数据的分布。这一现象深刻揭示了:评估结果不仅反映模型能力,也反映评估协议本身的选择。
数学评估还面临一个独特难题:同一个正确答案可以有无穷多种表达方式。例如 \dfrac{14}{3} 都是同一个值。如果评估器只做字符串精确匹配,会产生大量假阴性——模型答对了但被判错。
完整的数学答案验证流程包含以下步骤:
步骤 1:提取答案框。 数学推理模型通常被训练将最终答案放在 \boxed{...} 中。提取时需要处理嵌套大括号:
import re
def get_last_boxed(text):
"""从模型输出中提取最后一个 \\boxed{...} 的内容"""
boxed_start = text.rfind(r"\boxed")
if boxed_start == -1:
return None
idx = boxed_start + len(r"\boxed")
# 跳过空白
while idx < len(text) and text[idx].isspace():
idx += 1
if idx >= len(text) or text[idx] != "{":
return None
# 处理嵌套大括号
idx += 1
depth = 1
start = idx
while idx < len(text) and depth > 0:
if text[idx] == "{":
depth += 1
elif text[idx] == "}":
depth -= 1
idx += 1
return text[start:idx-1] if depth == 0 else None
# 测试
print(get_last_boxed(r"答案是 \boxed{\dfrac{14}{3}}"))
# 输出: \dfrac{14}{3}步骤 2:LaTeX 规范化。 将各种 LaTeX 变体统一为可计算的表达式:
LATEX_FIXES = [
(r"\\left\s*", ""), # 去除 \left
(r"\\right\s*", ""), # 去除 \right
(r"\\cdot", "*"), # \cdot → *
(r"\\dfrac", r"\\frac"), # \dfrac → \frac
(r"\\tfrac", r"\\frac"), # \tfrac → \frac
]
def normalize_math_text(text):
"""将 LaTeX 数学表达式规范化为可解析的形式"""
if not text:
return ""
text = text.strip().replace("$", "").replace("\\%", "")
for pattern, replacement in LATEX_FIXES:
text = re.sub(pattern, replacement, text)
# 处理分数: \frac{a}{b} → (a)/(b)
text = re.sub(
r"\\frac\s*\{([^{}]+)\}\s*\{([^{}]+)\}",
lambda m: f"({m.group(1)})/({m.group(2)})",
text
)
# 处理平方根: \sqrt{x} → sqrt(x)
text = re.sub(
r"\\sqrt\s*\{([^}]*)\}",
lambda m: f"sqrt({m.group(1)})",
text
)
# 处理指数: ^ → **
text = text.replace("^", "**")
# 处理千分位逗号: 1,234 → 1234
text = re.sub(r"(?<=\d),(?=\d\d\d(\D|$))", "", text)
return text.replace("{", "").replace("}", "").strip().lower()
# 测试
print(normalize_math_text(r"\dfrac{14}{3}")) # (14)/(3)
print(normalize_math_text(r"\sqrt{8}/2")) # sqrt(8)/2步骤 3:数学等价性验证。 这是最关键的一步——利用符号计算库 SymPy 判断两个表达式是否数学等价:
from sympy.parsing.sympy_parser import (
parse_expr, standard_transformations,
implicit_multiplication_application
)
from sympy import simplify
def math_equal(expr_a, expr_b):
"""判断两个数学表达式是否等价"""
# 先比较规范化后的字符串
a_norm = normalize_math_text(expr_a)
b_norm = normalize_math_text(expr_b)
if a_norm == b_norm:
return True
# 尝试符号化比较
try:
sym_a = parse_expr(
a_norm,
transformations=(
*standard_transformations,
implicit_multiplication_application,
),
evaluate=True
)
sym_b = parse_expr(
b_norm,
transformations=(
*standard_transformations,
implicit_multiplication_application,
),
evaluate=True
)
return simplify(sym_a - sym_b) == 0
except Exception:
return False
# 验证各种等价形式
print(math_equal("14/3", r"\frac{14}{3}")) # True
print(math_equal("0.5", r"\frac{1}{2}")) # True
print(math_equal(r"\frac{\sqrt{8}}{2}", "sqrt(2)")) # True
print(math_equal("14/3", "15/3")) # False下表展示了等价性验证器需要处理的典型案例:
| 模型输出 | 标准答案 | 期望结果 | 难点 |
|---|---|---|---|
\dfrac{14}{3} | 14/3 | True | LaTeX 分数 vs 纯文本分数 |
0.5 | 1/2 | True | 小数 vs 分数 |
\frac{\sqrt{8}}{2} | sqrt(2) | True | 需要代数化简 |
(14/3, 2/3) | (14/3, 4/6) | True | 元组中逐元素比较 |
1,234 | 1234 | True | 千分位逗号 |
90^\circ | 90 | True | 角度符号 |
表 20-3:数学等价性验证的典型测试案例。一个健壮的验证器需要同时处理 LaTeX 语法差异、数值格式差异和代数化简。
在 MATH-500 上的实际评估数据显示,Qwen3-0.6B 基础模型的准确率约为 15.6%(78/500),而经过推理训练的版本则达到 50.8%(254/500)——推理训练带来了超过 3 倍的性能提升。这一对比生动地说明了推理能力并非简单的"知识更多",而是一种可以通过训练获得的结构化思维技能。
值得一提的是,推理模型的评估速度远低于基础模型。在 H100 GPU 上,基础模型评估 500 道题仅需约 13 分钟,而推理模型则需要 185 分钟——因为推理模型会生成冗长的思维链(thinking tokens),每道题的输出长度可达数千 Token。采用批量推理(batch size=128)可将推理模型的评估时间从 185 分钟压缩到约 15 分钟,这在实际评估工作流中至关重要。
20.3.5 长上下文压力测试
随着模型上下文窗口从 4K 扩展到 128K 甚至百万级 Token,长上下文能力成为新的评估焦点。传统基准的文本长度通常不超过几千 Token,无法触及长上下文场景下的真实挑战。
长上下文评估的代表性方法包括:
- "大海捞针"测试(Needle in a Haystack):在极长的文本中随机位置插入一条关键信息,然后要求模型检索。通过改变文本总长度和插入位置,可以绘制出模型在不同长度和位置下的检索成功率热力图。理想的模型在任意长度、任意位置都应保持近乎完美的检索率,但实际测试常揭示出模型在文本中部(即"Lost in the Middle"现象)和极端长度下的性能退化。
- LongBench:一套覆盖多语言、多任务的长上下文基准,包括长文档问答、摘要、少样本学习等,文本长度从 3K 到 30K Token 不等。
- RULER(Real-world Understanding of Long-text Evaluation and Reasoning):通过多类型任务(多键检索、变量追踪、长链推理等)评估模型在不同上下文长度下的能力退化曲线。
长上下文评估揭示的一个核心发现是:宣称支持的上下文长度与实际有效利用的上下文长度之间往往存在显著差距。一个标称 128K 窗口的模型,可能在 32K 之后就开始出现明显的性能退化。这一差距的根源在于:模型在训练时接触到的长序列数量有限,注意力机制在超长序列上的位置编码外推能力不足,以及 KV Cache 显存压力导致的推理质量下降(详见 §12.3 上下文并行与长序列优化)。
20.3.6 幻觉检测
幻觉(Hallucination)——模型自信地生成看似合理但事实错误的内容——是大语言模型最危险的失败模式之一。与明显的语法错误不同,幻觉具有高度的欺骗性,非专业人士难以识别。
幻觉检测基准可分为两类:
事实性幻觉检测:检查模型生成的事实是否与已知知识一致。TruthfulQA 是代表性基准,它包含 817 个刁钻问题,专门针对人类常见误区和流行谬误设计。例如,"如果你吞了口香糖,它真的要 7 年才能消化吗?"——正确答案是否定的,但许多模型会复述这一流行说法。TruthfulQA 不仅检测模型是否知道正确答案,更检测模型是否倾向于迎合人类的常见错误认知。
忠实性幻觉检测:检查模型的回复是否忠实于给定的上下文。在 RAG(检索增强生成)场景中尤为重要——即使检索到了正确文档,模型仍可能"添油加醋"地生成文档中不存在的内容。评估方式通常是给模型一段参考文本和相关问题,检查回复中是否包含参考文本未提及的断言。
20.3.7 对齐与安全维度
在关注模型"能否完成任务"之后,更深层的问题是"它是否合乎人类价值观和社会规范"。这一维度的评估已从可选附录变成了不可缺少的核心模块。
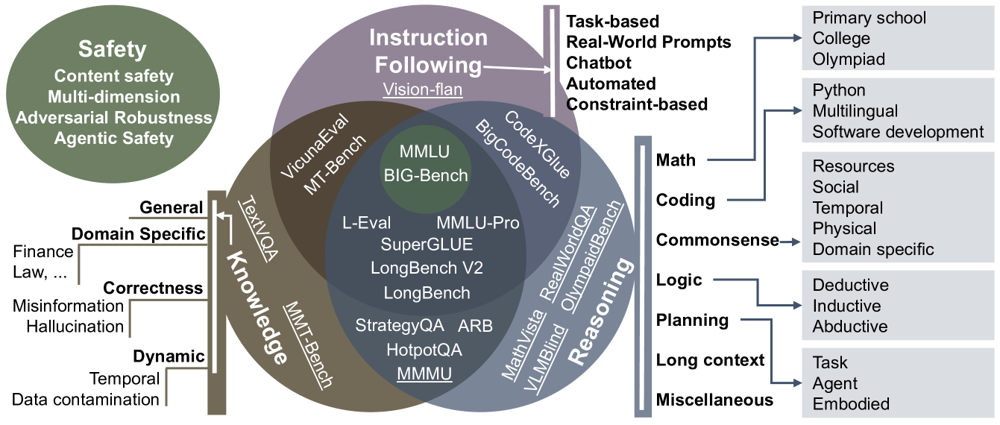
图 20-9:面向大语言模型的能力驱动评估维度分类。知识、推理、指令遵循与安全等维度之间存在交互影响,体现了评估体系的多维属性。
安全性评估的代表基准包括:
- HarmBench:包含 510 种违反法律或规范的有害行为描述,测试模型是否拒绝执行有害指令。不同模型的拒绝率差异巨大——安全对齐做得好的模型会坚定拒绝,而对齐不足的模型可能直接遵从。
- AIR-Bench:将"安全"概念锚定在法规框架和公司政策上,基于具体法律和政策构建了 314 个风险类别,比任意定义的"安全"更有依据。
越狱(Jailbreaking)攻击则从对抗角度检验安全对齐的鲁棒性。例如 GCG(Greedy Coordinate Gradient)攻击通过梯度优化自动生成绕过安全机制的 Prompt 后缀。研究发现,在开源模型上优化的攻击后缀竟能迁移到闭源模型——这意味着安全训练压制的只是模型的"倾向"而非"能力",底层能力仍然存在并可能被释放。
越狱研究还揭示了安全评估中"能力"与"倾向"两个维度的重要区分:
| 维度 | 含义 | API 模型 | 开源模型 |
|---|---|---|---|
| 能力(Capability) | 模型是否能够执行某任务 | 关注较少 | 关键维度(安全措施可被微调移除) |
| 倾向(Propensity) | 模型是否愿意执行某任务 | 核心关注 | 仅第一道防线 |
表 20-4:安全评估的两个维度。对于开源模型,仅评估倾向是不够的——攻击者可通过微调直接释放被压制的能力。
对齐评估的另一条路线是 Helpful-Harmless-Honest(HHH) 框架,它通过比较不同回答与人类偏好的契合度,从三个维度检验模型是否真正对齐人类价值。这与 RLHF 训练的目标直接对应——可以理解为,对齐评估就是在检验 RLHF 是否真正起了作用。
20.3.8 评估的评估:有效性挑战
当我们信赖基准分数时,有一个元问题必须直面:评估本身可靠吗?
训练-测试污染(Train-Test Contamination) 是 LLM 时代最严重的有效性威胁。传统机器学习有明确的训练/测试分割,但现代 LLM 在整个互联网上训练,训练数据通常不公开,无法确定测试集是否被包含。检测污染的两条主要路线包括:
- 行为推断法:利用数据点的可交换性——如果模型对测试集中某个特定排列的 Likelihood 明显更高(与数据集原始顺序相关),则可能训练过该数据。
- N-gram 重叠检测:检查测试样本与训练数据的 N-gram 重叠(通常使用 13-gram),然后移除匹配的训练数据。但改写版本和跨语言翻译可能逃过检测。
数据集质量问题同样值得警惕。许多基准本身存在标注错误——如果你看到模型在某个基准上达到 90%+ 的准确率并认为任务很难,实际上可能有一部分是标签噪声。OpenAI 为此推出了 SWE-Bench Verified,修复了原始数据集中的错误,创建了更高质量的"白金版"。
评估框架的动态化是应对这些挑战的重要趋势。OpenCompass 由上海人工智能实验室牵头开发,整合了上百个数据集,覆盖自然语言理解、知识推理、生成能力和安全对齐等方面,强调灵活性和生态化,既能满足前沿研究的对比需求,也能服务产业界对可靠评测的要求。与静态基准不同,OpenCompass 鼓励研究者持续接入新任务和新模型,形成"活的"评估生态。
小结
评估基准构成了一个多层次的观测体系:知识基准(MMLU、C-Eval)测量模型记住了什么,推理基准(BBH、MATH-500)测量模型能推导什么,指令遵循基准(MT-Bench、AlpacaEval)测量模型能执行什么,安全基准(HarmBench、TruthfulQA)测量模型会拒绝什么。HELM 等聚合框架则试图将这些维度整合为一幅全景图。
但没有任何单一基准能定义"好模型"。正如 CS336 课程所总结的:没有唯一正确的评估,评估方式取决于你试图回答什么问题。 始终深入到具体实例和预测——不要只看数字;始终关注评估的多维度——能力、安全、成本、真实性;始终追问有效性——测试数据是否泄漏、标注是否准确、基准是否过时。唯有如此,评估才能真正服务于模型的迭代与落地。