21.7 Agent 记忆系统
"Memory is the diary that we all carry about with us." —— Oscar Wilde
在上一节中,我们从"当下"的视角讨论了如何在有限的上下文窗口中精确管理信息。但一个真正智能的 Agent 不仅要处理好"此刻"的上下文,更需要具备跨越时间的记忆能力——它要记住用户的偏好、从过去的失败中学习、在重复任务中复用已有经验。如果说上下文工程(21.6 节)关注的是"现在给模型看什么",那么记忆系统关注的是"Agent 知道什么、经历过什么,以及这些知识如何演变"。
本节将系统讲解以下内容:(1)记忆系统的形式化框架与生命周期模型;(2)三种记忆形式——Token 级记忆、参数化记忆、潜在记忆;(3)三种记忆功能——事实记忆、经验记忆、工作记忆;(4)记忆的生命周期:形成、演化与检索;(5)Plan Caching 作为经验记忆的工程实例;(6)Agent 记忆与 RAG、Context Engineering 的边界辨析。
21.7.1 为什么 Agent 需要记忆
考虑一个日常场景:你使用一个编码助手连续工作三天,第一天你告诉它"我们项目用 4 空格缩进",第二天你让它修复一个数据库连接 bug,它尝试了三种方案后才找到根因是连接池超时配置。到了第三天,如果这个助手忘记了你的缩进偏好,又对类似的数据库问题从头排查,你会觉得它毫无进步。
这正是记忆系统要解决的问题。更形式化地说,在 21.1 节的 POMDP 框架中,Agent 的策略定义为:
其中
记忆状态
- 任务内信息(intra-task):当前会话中累积的中间结果、工具调用历史、推理轨迹;
- 跨任务信息(cross-task):用户偏好、历史任务的经验教训、可复用的技能模板。
这种区分暗示了一个关键洞察:传统的"短期记忆 vs 长期记忆"二分法过于粗糙。一条信息是否被"短期"还是"长期"地保持,取决于记忆系统的形成、演化和检索操作的时间依赖模式,而非某个独立的"短期记忆模块"或"长期记忆模块"。这一观点来自 Xu 等人(2025)的综述 "Memory in the Age of AI Agents",该工作提出了"形式(Forms)—功能(Functions)—动态(Dynamics)"的三维分析框架,为碎片化的 Agent 记忆研究提供了统一视角。
21.7.2 记忆的三种形式
Agent 的记忆"存放在哪里"?根据存储载体的不同,记忆可以分为三种形式:Token 级记忆(显式的离散文本/结构)、参数化记忆(编码在模型权重中)、潜在记忆(隐藏在中间表示如 KV Cache 中)。
Token 级记忆(Token-level Memory)
这是最直观的记忆形式:将信息存储为显式的、可读的离散单元——自然语言文本片段、JSON 条目、表格行等。这些单元可以被单独访问、修改和删除,是当前大多数 Agent 系统的主流选择。
根据这些单元之间的组织结构,Token 级记忆可以进一步细分为三种拓扑:
(1)扁平记忆(Flat Memory)——一维无结构集合。记忆单元之间没有显式的拓扑关系,类似一个"片段袋"(bag of snippets)。每条记忆可能是一段对话摘要、一个用户偏好条目、一条行为轨迹。
# 扁平记忆的典型实现
class FlatMemory:
"""最简单的记忆存储:列表 + 向量检索"""
def __init__(self, embedding_fn, max_entries=1000):
self.entries = [] # 记忆条目列表
self.embeddings = [] # 对应的向量表示
self.embedding_fn = embedding_fn
self.max_entries = max_entries
def add(self, content: str, metadata: dict = None):
"""写入一条新记忆"""
if len(self.entries) >= self.max_entries:
# 淘汰最旧且未被频繁访问的条目
self._evict()
entry = {
"content": content,
"metadata": metadata or {},
"timestamp": time.time(),
"access_count": 0
}
self.entries.append(entry)
self.embeddings.append(self.embedding_fn(content))
def retrieve(self, query: str, top_k: int = 5) -> list:
"""基于语义相似度检索最相关的记忆"""
query_emb = self.embedding_fn(query)
scores = [cosine_similarity(query_emb, emb)
for emb in self.embeddings]
top_indices = sorted(range(len(scores)),
key=lambda i: scores[i],
reverse=True)[:top_k]
for i in top_indices:
self.entries[i]["access_count"] += 1
return [self.entries[i] for i in top_indices]扁平记忆的优势是简单、可扩展,适合快速原型开发。但它的瓶颈也很明显:检索质量完全依赖于 embedding 模型的语义匹配能力,无法表达条目之间的因果关系或层级结构。当记忆规模增大时,语义召回的噪音会显著增加。
(2)平面记忆(Planar Memory)——二维拓扑结构。在单一层级内引入显式的关联关系,典型形态包括:
- 知识图谱:以实体为节点、关系为边,支持多跳推理。例如存储"用户 Alice —偏好→ 4 空格缩进"、"项目 X —使用→ PostgreSQL"这样的三元组。
- 动态对话树:将多轮对话组织为树结构,每个分支代表一个话题线索。
- 表格:以结构化行列存储状态信息,如任务清单、工具调用结果汇总。
平面记忆的核心价值是从"存储"迈向"组织"——通过显式的关联关系,Agent 可以沿着关系路径进行结构化检索,而不仅仅依赖语义相似度。
(3)分层记忆(Hierarchical Memory)——三维立体结构。将信息组织在多个抽象层级中,层级之间通过链接互联。典型的结构是一个"金字塔":
- 底层:原始观察和交互记录(raw observations)
- 中层:事件摘要和经验总结(summaries & lessons)
- 顶层:高级模式和策略规则(patterns & policies)
这种结构的灵感直接来自 Park 等人(2023)的 Generative Agents 工作:Agent 首先记录原始观察("看到 John 在公园画画"),然后通过反思(Reflection)生成更高层的洞察("John 是一个热爱艺术的人"),进而影响后续的行为决策。
┌───────────────────────────────────┐
│ 策略层 (Policies) │ "遇到数据库超时,优先检查连接池配置"
├───────────────────────────────────┤
│ 摘要层 (Summaries) │ "任务 #42:PostgreSQL 连接池超时导致服务不可用"
├───────────────────────────────────┤
│ 事实层 (Raw Facts) │ "2025-03-20 14:32 工具返回 ConnectionTimeout..."
└───────────────────────────────────┘分层记忆的优势在于多粒度检索:面对"如何修复数据库问题"这样的高层查询,Agent 可以先在策略层匹配,获得通用指导;面对"上次超时的具体错误码"这样的细节查询,则深入事实层检索。其代价是结构维护复杂度高——需要设计合理的抽象规则、层间链接方式和信息流向。
参数化记忆(Parametric Memory)
与 Token 级记忆的"外显"不同,参数化记忆将信息编码到模型的参数中,通过前向传播隐式访问。根据参数的位置,可分为两类:
内部参数记忆:直接修改基础模型的权重。例如,通过在特定领域数据上继续预训练(continual pre-training),让模型"记住"金融术语或医学知识。优点是推理时零额外开销;缺点是更新代价高昂,且面临灾难性遗忘(catastrophic forgetting) 的风险——学习新知识时可能覆盖旧知识。
外部参数记忆:将记忆存储在可插拔的附加参数模块中,如 LoRA 适配器、轻量级 MLP 模块等。这些模块可以按需加载:
其中
外部参数记忆的典型代表包括:
- K-Adapter:为不同类型的知识训练独立的适配器模块
- WISE:使用知识分片(knowledge sharding)将不同时期的知识存储在不同参数子空间
- Retroformer:引入辅助 LLM 模块,专门负责从历史经验中提取反馈信号
潜在记忆(Latent Memory)
潜在记忆介于 Token 级和参数化记忆之间:信息存储在模型的中间表示中——KV Cache、隐藏状态激活、潜在嵌入——而非显式文本或模型权重。根据操作方式的不同,分为三个子类:
生成型(Generate):由专门的模块将输入信息压缩为高密度的潜在表示,供后续推理使用。例如 Gist Token 技术将冗长的 System Prompt 压缩为少量"要旨 Token",保留核心语义的同时大幅减少上下文占用。更高级的方案如 Titans(Google, 2025)引入了可微的长期记忆模块,能够在推理过程中动态写入和读取潜在记忆。
复用型(Reuse):直接复用已有的 KV Cache 作为记忆条目。例如 Memorizing Transformers 在注意力计算时,除了关注当前序列的 KV 对,还会检索外部存储的历史 KV 对:
其中
变换型(Transform):对现有的 KV Cache 进行压缩、修剪或重组,在保持信息密度的同时减少存储开销。典型方法包括:
- H2O(Heavy-Hitter Oracle):识别注意力分数累积最高的 Key-Value 对("Heavy Hitter"),仅保留这些高频访问的条目
- SnapKV:通过观察注意力模式,自动选择最关键的 KV 对进行保留
- PyramidKV:在不同注意力头上分配不同的 KV 预算,低注意力头保留更少的 KV 对
下表总结了三种记忆形式的对比:
| 维度 | Token 级记忆 | 参数化记忆 | 潜在记忆 |
|---|---|---|---|
| 存储载体 | 显式文本/结构 | 模型权重/适配器 | KV Cache/隐藏状态 |
| 可解释性 | 高(人类可读) | 低(统计编码) | 低(数值向量) |
| 更新方式 | 增删改查 | 训练/微调 | 前向计算/压缩 |
| 推理开销 | 检索 + 注入上下文 | 无(已在权重中) | 注意力扩展 |
| 持久性 | 外部存储,易持久化 | 模型文件持久化 | 会话结束即丢失 |
| 适用场景 | 对话历史、用户画像 | 领域知识、技能内化 | 长上下文处理 |
21.7.3 记忆的三种功能
"形式"回答的是"记忆存在哪",而"功能"回答的是"记忆用来做什么"。Agent 记忆可以按功能划分为三大支柱:事实记忆、经验记忆和工作记忆。它们并非孤立运作,而是形成一个动态循环。
事实记忆(Factual Memory)
事实记忆是 Agent 的声明性知识库——存储关于"世界是什么样的"的显式事实。它进一步分为两个子类:
用户事实记忆:维护与用户交互一致性所需的事实信息。
- 身份与偏好:用户的名字、编程语言偏好、代码风格要求(如"4 空格缩进")
- 历史承诺:Agent 做出的承诺和已确认的决定(如"已同意使用 PostgreSQL 而非 MySQL")
- 任务状态:已完成的步骤、待解决的问题、已确认的中间结果
环境事实记忆:维护与外部环境一致性所需的事实信息。
- 资源状态:数据库连接信息、API 可用性、文件系统布局
- 协作方事实:在多 Agent 系统中,记录其他 Agent 的能力和当前状态
事实记忆的三个关键属性是连贯性(recall and integrate relevant interaction history)、一致性(avoid contradictions across sessions)和适应性(personalize based on stored profiles)。
# 事实记忆的实用模式:结构化用户画像
class UserProfile:
"""维护用户偏好的持久化事实记忆"""
def __init__(self):
self.facts = {} # key -> {"value": ..., "confidence": ..., "source": ...}
def update(self, key: str, value, source: str = "explicit"):
"""
更新事实。显式声明 > 行为推断 > 默认值
"""
existing = self.facts.get(key)
priority = {"explicit": 3, "inferred": 2, "default": 1}
if existing is None or priority.get(source, 0) >= priority.get(
existing["source"], 0
):
self.facts[key] = {
"value": value,
"confidence": 1.0 if source == "explicit" else 0.7,
"source": source,
"updated_at": time.time()
}
def get(self, key: str, default=None):
entry = self.facts.get(key)
return entry["value"] if entry else default
# 使用示例
profile = UserProfile()
profile.update("indent_style", "4 spaces", source="explicit") # 用户明确说了
profile.update("language", "Python", source="inferred") # 从代码推断经验记忆(Experiential Memory)
如果事实记忆回答的是"世界是什么样的",那么经验记忆回答的是"Agent 如何改进"。它存储从过去的轨迹、失败和成功中提炼出的程序性和策略性知识,主要服务于两个目标:
技能学习(Skill Acquisition):Agent 将成功完成任务的执行轨迹抽象为可复用的"技能模板"。例如,一个编码 Agent 在多次处理"数据库连接超时"问题后,可以将解决方案提炼为一个通用模板:
技能:诊断数据库连接超时
触发条件:错误信息包含 "ConnectionTimeout" 或 "connection pool exhausted"
步骤:
1. 检查连接池配置(max_connections, idle_timeout)
2. 查看当前活跃连接数(SHOW PROCESSLIST)
3. 检查网络延迟(ping 数据库主机)
4. 根据诊断结果调整配置或修复代码策略优化(Policy Refinement):Agent 从失败中学习"什么不该做"。Reflexion(Shinn 等人, 2023)框架是这一方向的代表:Agent 在任务失败后,用 LLM 对失败轨迹进行反思,生成自然语言形式的"教训",存入经验记忆,下次遇到类似任务时作为上下文注入。
工作记忆(Working Memory)
工作记忆是 Agent 的容量有限的暂存器,用于管理当前任务的活跃上下文。在认知科学中,人类的工作记忆容量约为"7 ± 2"个组块(Miller, 1956);类比到 LLM Agent,工作记忆的容量约束就是上下文窗口大小。
工作记忆的核心挑战是信息的进出管理:
- 进:从事实记忆和经验记忆中检索相关条目,注入上下文
- 出:当上下文逼近容量上限时,通过压缩、摘要或淘汰策略释放空间
- 组织:在有限空间内合理安排信息的优先级和布局
这与 21.6 节讨论的上下文工程高度相关——上下文工程的技术手段(Compaction、Summarization、分层动作空间)正是工作记忆管理的具体实现。
三类记忆的协同循环:在一次完整的任务执行中,三类记忆形成如下认知循环:
工作记忆(当前推理)
↑ 检索 ↓ 编码
事实记忆 ←──→ 经验记忆
↑ ↓
└── 反思与策略提炼 ──────┘Agent 在工作记忆中进行即时推理和决策,同时从事实记忆中召回相关上下文、从经验记忆中获取技能和策略指导。任务完成后,新的事实和经验被编码回长期记忆,供未来任务使用。
21.7.4 记忆生命周期:形成、演化与检索
理解了记忆的"形式"和"功能"之后,我们需要关注记忆的动态过程——信息如何被创建、如何随时间变化、如何在需要时被找回。这三个阶段构成了记忆的完整生命周期。
记忆形成(Formation)
记忆形成是指 Agent 将交互过程中产生的信息性产物(informative artifacts)
"选择性"是关键词。并非所有交互都值得记忆——一条冗余的日志输出、一个已知的确认信息,记住它们只会增加噪音。形成算子
- 过滤:判断哪些信息值得保留。例如,仅保存包含新事实或错误信号的工具输出,忽略常规的成功确认。
- 抽象:将原始信息转化为更紧凑的形式。例如,将 500 行的 debug 日志摘要为"PostgreSQL 连接池默认 max_connections=10,生产负载需要至少 50"。
记忆演化(Evolution)
新形成的记忆候选需要与已有记忆库进行整合,这一过程可能涉及:
- 冲突解决:新记忆与旧记忆矛盾时(如用户更改了偏好),需要决定保留哪个版本
- 冗余消除:合并语义重复的条目
- 结构重组:在分层记忆中,将具体事实抽象为更高层的规则
- 遗忘:丢弃长期未被访问、相关性低的条目
演化机制决定了记忆的质量上限。一个只写不改的记忆系统会迅速被噪音淹没;一个积极演化的记忆系统能够保持高信噪比,但也增加了维护的计算成本。
记忆检索(Retrieval)
在做出决策时,Agent 需要从记忆库中检索相关信息:
检索算子
| 策略 | 机制 | 适用场景 |
|---|---|---|
| 语义检索 | 通过 embedding 相似度匹配 | 扁平记忆中的通用查询 |
| 时序检索 | 按时间戳排序,优先返回近期记忆 | 工作记忆中的会话上下文 |
| 图遍历 | 沿知识图谱的关系边多跳搜索 | 平面记忆中的结构化推理 |
| 层级下钻 | 先匹配高层策略,再按需展开细节 | 分层记忆中的多粒度查询 |
| 混合检索 | 结合语义 + 时序 + 重要性权重的加权融合 | 复杂场景下的综合检索 |
一个设计良好的检索策略应该在召回率(不遗漏关键信息)和精确率(不注入无关噪音)之间取得平衡。21.6 节中提到的"Lost in the Middle"效应提醒我们:即使成功检索到了相关记忆,如果放在上下文的中间位置,模型也可能忽略它。因此,检索后的排列策略(将最重要的信息放在上下文的头部或尾部)同样关键。
短期记忆与长期记忆的统一理解
传统分类将记忆简单二分为"短期"和"长期"。但在上述生命周期框架下,这种区分被更优雅地解释为时间依赖模式的不同:
- 短期现象:记忆在形成后快速被检索和使用,随后在演化过程中被丢弃。例如,一次工具调用的中间结果,在当前推理步骤中使用后即可释放。
- 长期现象:记忆在形成后经过多次演化(抽象、整合、强化),在较长时间跨度内被反复检索。例如,用户的编程偏好会在每次会话中被检索并使用。
这意味着我们不需要设计独立的短期和长期记忆模块。同一个记忆系统通过不同的演化策略和检索模式,自然呈现出短期和长期的行为特征。
21.7.5 Plan Caching:经验记忆的工程实践
前面的讨论较为抽象,现在让我们看一个将经验记忆成功应用于降本增效的具体案例——Agentic Plan Caching(Nagaraju 等人, 2025)。
问题背景
LLM-based Agent 的服务成本居高不下,核心原因在于每次任务都需要大模型从头进行复杂的规划推理。现有的两种缓存方案各有局限:
- 上下文缓存(Context Caching):利用 KV Cache 复用前缀相同的请求。但它要求输入文本近乎精确匹配,在 Agent 场景中命中率极低。
- 语义缓存(Semantic Caching):存储"输入-输出"对,对语义相似的新输入直接返回缓存的输出。但在数据依赖型任务中,表面相似的查询可能需要完全不同的处理流程(例如"FY2019 的营运资金"和"FY2020 的营运资金"语义几乎相同,但需要查阅不同的财报数据),导致高假阳性率。
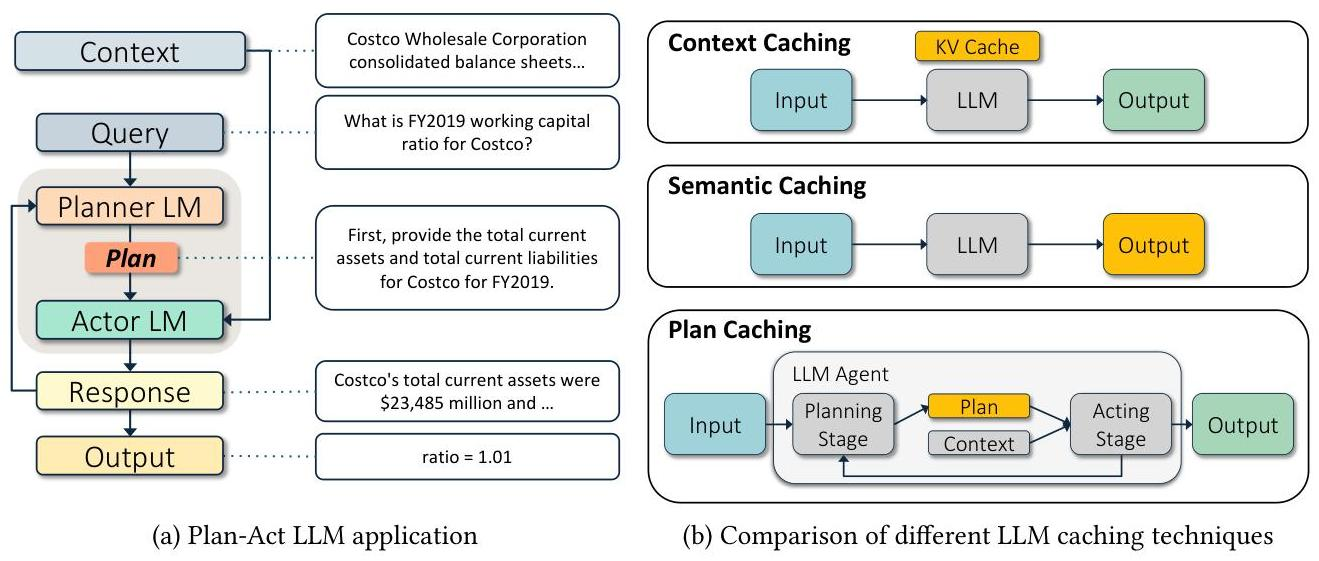
图 21-17:传统 Plan-Act 架构中 Planner LM 和 Actor LM 的分工(左),以及三种缓存策略的对比(右)。Context Caching 依赖 KV Cache 前缀匹配,Semantic Caching 存储输入-输出对,而 Plan Caching 缓存可复用的规划模板。
核心设计
Plan Caching 的核心洞察是:缓存的不是具体的问答对,而是可复用的"规划模板"。完整的工作流程包含三个阶段:
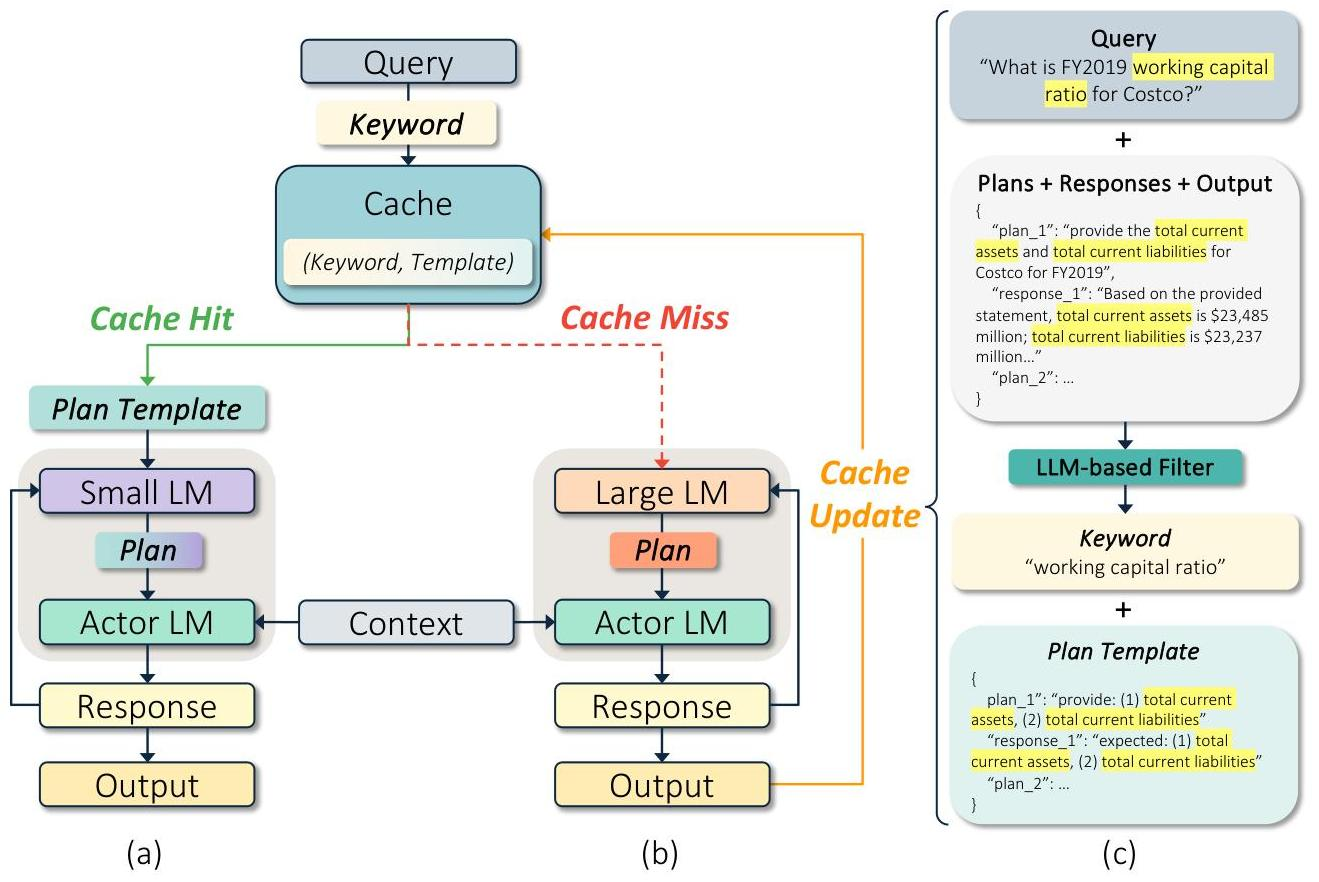
图 21-18:Plan Caching 工作流。(a) Cache Hit:用小模型将模板适配到当前上下文;(b) Cache Miss:用大模型生成新规划,执行后将规划模板存入缓存;(c) 关键词提取与模板生成的示例。
阶段一:关键词提取。 收到新请求后,系统首先用一个轻量级模型(或基于规则的提取器)从任务描述中提取任务关键词——捕获任务类型的核心特征,同时剥离具体的数据值。例如,从"What is FY2020 working capital ratio for Costco?"中提取关键词"working capital ratio"。
阶段二:缓存查找。 用提取的关键词在缓存中搜索匹配的规划模板:
- Cache Hit:找到匹配的模板后,交给一个小型、低成本的 Planner 模型负责适配——将模板中的占位符替换为当前任务的具体参数,生成可执行的规划。
- Cache Miss:没有匹配时,调用大型、高成本的模型从头生成规划。执行完成后,通过一个 LLM-based Filter 将执行流程提炼为规划模板,连同关键词一起存入缓存。
阶段三:执行。 无论规划来源如何,最终都交给 Actor LM 按照规划逐步执行并生成输出。
# Plan Caching 的核心逻辑(简化示意)
class PlanCache:
def __init__(self, large_planner, small_planner, keyword_extractor):
self.cache = {} # keyword -> plan_template
self.large_planner = large_planner
self.small_planner = small_planner
self.keyword_extractor = keyword_extractor
def get_plan(self, query: str, context: str) -> str:
# Step 1: 提取任务关键词
keyword = self.keyword_extractor(query)
# Step 2: 缓存查找
if keyword in self.cache:
# Cache Hit: 小模型适配模板
template = self.cache[keyword]
plan = self.small_planner.adapt(template, query, context)
else:
# Cache Miss: 大模型从头生成
plan = self.large_planner.generate(query, context)
# 执行后提炼模板并缓存
template = self._distill_template(plan, query)
self.cache[keyword] = template
return plan
def _distill_template(self, execution_trace: str, query: str) -> str:
"""将具体执行轨迹提炼为通用规划模板"""
prompt = (
f"Given the execution trace:\n{execution_trace}\n"
f"Distill a reusable plan template by replacing "
f"specific data values with placeholders."
)
return self.large_planner.generate(prompt)关键实验结果
在 FinanceBench(金融文档推理)和 TabMWP(表格数学推理)两个数据密集型任务上,Plan Caching 取得了令人瞩目的效果:
- 成本降低 46.62%:Cache Hit 时使用小模型适配而非大模型重新规划,显著节约推理费用
- 维持 96.67% 的最优准确率:与无缓存的大模型基线相比,准确率几乎不受影响
- 额外开销极低:关键词提取和模板生成仅占总成本的 1.04%
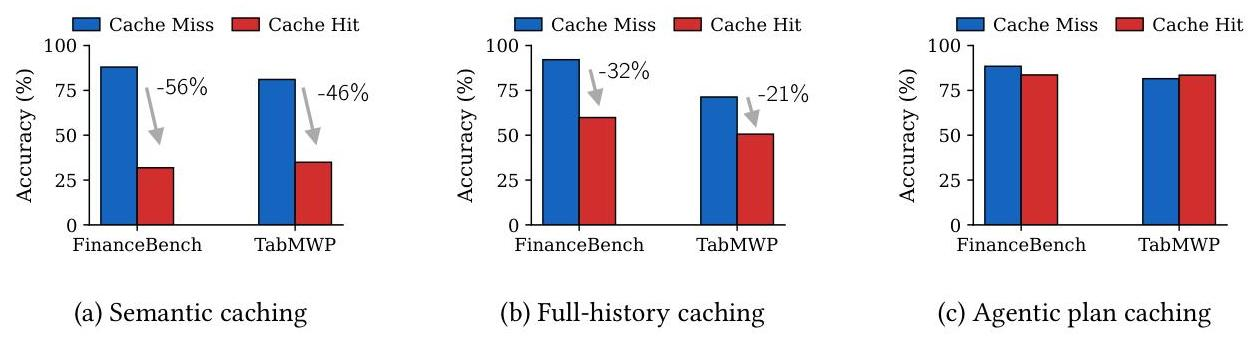
图 21-19:三种缓存策略在 Cache Hit 与 Cache Miss 时的准确率对比。Semantic Caching(左)在 Cache Hit 时准确率大幅下降(-56%/-46%),说明"成功"的缓存命中反而导致了更差的结果。Full-history Caching(中)同样出现性能衰减。唯有 Agentic Plan Caching(右)在 Cache Hit 和 Cache Miss 时保持了稳定一致的准确率。
这一结果验证了 Plan Caching 的核心设计哲学:规划模板比输入-输出对更具泛化性。因为规划模板只编码"做什么步骤",而将"用什么数据"留给适配阶段动态填入,从而避免了语义缓存中"形似而神不似"的误匹配问题。
21.7.6 Agent 记忆 vs RAG vs Context Engineering
在实际开发中,"记忆"、"RAG"、"上下文工程"这三个概念经常被混淆使用。它们确实在技术实现上有大量重叠,但在设计哲学上存在本质差异。
技术重叠
三者共享许多技术构建块:
- 向量索引 + 语义搜索:Agent 记忆用它检索历史经验,RAG 用它检索外部文档,Context Engineering 用它筛选上下文内容
- 信息压缩:Agent 记忆中的记忆演化需要压缩冗余,Context Engineering 的 Compaction 策略同样压缩上下文,RAG 的摘要检索也涉及信息浓缩
- 结构化存储:知识图谱既是 Agent 平面记忆的载体,也是 Graph RAG 的数据结构
核心差异
但三者的设计目标截然不同:
| 维度 | Agent 记忆 | RAG | Context Engineering |
|---|---|---|---|
| 核心问题 | Agent 如何持续学习和自我演化? | 如何让 LLM 访问外部知识? | 如何在有限窗口内最大化决策信息密度? |
| 数据来源 | Agent 自身的交互历史和经验 | 外部静态或半静态知识库 | 一切可注入上下文的信息 |
| 持久性 | 跨任务持久、自演化 | 通常为只读或低频更新 | 会话级,任务结束即丢弃 |
| 自演化 | 记忆主动形成、整合、遗忘 | 知识库被动更新 | 不涉及 |
| 典型技术 | 反思、技能提炼、Plan Caching | 文档切分、向量检索、重排序 | Compaction、Summarization、KV Cache 管理 |
一个有用的直觉类比是:
- RAG 像一座图书馆——Agent 去查阅外部资料,图书馆本身不因 Agent 的使用而改变
- Context Engineering 像一张书桌——决定当前时刻桌面上放哪些资料、怎么摆放
- Agent 记忆 像一本个人笔记——Agent 自己写的、持续更新的、越用越精炼的知识积累
Agentic RAG 是一个有趣的交叉地带:它让 Agent 主动控制检索的时机和策略("何时查、查什么、怎么查"),在行为模式上接近 Agent 记忆的检索阶段。但经典的 Agentic RAG 通常操作于外部任务特定数据库,而非 Agent 自身积累的经验库,因此仍不等同于完整的 Agent 记忆系统。
# 三者的交互关系示意
class AgentWithFullMemory:
"""集成记忆、RAG 和上下文工程的 Agent 架构"""
def __init__(self, llm, memory, rag_index, context_manager):
self.llm = llm
self.memory = memory # Agent 记忆(持久、自演化)
self.rag_index = rag_index # 外部知识库(静态/半静态)
self.context_manager = context_manager # 上下文工程
def act(self, observation: str, task: str) -> str:
# 1. 从 Agent 记忆中检索相关经验和事实
agent_memories = self.memory.retrieve(
query=observation + task, top_k=3
)
# 2. 从外部知识库检索参考资料(RAG)
external_docs = self.rag_index.search(
query=task, top_k=5
)
# 3. 上下文工程:在有限窗口内组装最优上下文
context = self.context_manager.assemble(
system_prompt=SYSTEM_PROMPT,
agent_memories=agent_memories,
external_docs=external_docs,
recent_history=self.context_manager.get_recent(k=10),
observation=observation,
budget=MAX_CONTEXT_TOKENS
)
# 4. 用组装好的上下文调用 LLM
action = self.llm.generate(context)
# 5. 将新的交互记录编码到 Agent 记忆(记忆形成)
self.memory.encode(observation, action, task)
return action本节小结
Agent 记忆系统是赋予智能体"跨时间认知能力"的核心组件。本节从形式化框架出发,首先介绍了三种记忆形式:Token 级记忆(扁平/平面/分层)提供人类可读的显式存储,参数化记忆(内部权重/外部适配器)将知识编码进模型参数,潜在记忆(生成/复用/变换 KV Cache)利用中间表示实现高效记忆。随后阐述了三种记忆功能:事实记忆维护世界状态的声明性知识,经验记忆通过技能学习和策略优化实现自我进化,工作记忆在有限容量内管理即时推理上下文。在生命周期维度,我们看到记忆经历"形成(选择性编码)→ 演化(整合、去噪、遗忘)→ 检索(多策略召回)"的完整循环,而传统的短期/长期记忆区分本质上是这一循环中不同时间依赖模式的自然涌现。Plan Caching 作为经验记忆的工程实例,展示了如何通过缓存可复用的规划模板在维持 96.67% 准确率的同时将服务成本降低 46.62%。最后,我们厘清了 Agent 记忆与 RAG、Context Engineering 的边界:三者共享技术构建块,但 Agent 记忆独有的持久性和自演化能力使其在本质上区别于静态的外部知识检索和会话级的上下文管理。