23.3 图像生成:扩散模型完整理论
在上一节中,我们看到了文本如何驱动图像生成的整体流程。现在,是时候深入这台"造梦机器"的核心引擎了——扩散模型(Diffusion Model)。扩散模型是过去五年图像生成领域最重要的技术突破,从 2020 年 DDPM 的复兴到 Stable Diffusion 的工业级落地,再到 Sora 背后的 DiT 架构和 Flux 系列采用的 Flow Matching 方案,几乎所有前沿的视觉生成系统都建立在扩散模型的理论基础之上。
图 23-9:开源图像生成模型发展全景图。从 2022 年 Stable Diffusion 1.5 的 U-Net 架构,到 2024 年 SD3/Flux 全面转向 DiT 与 Flow Matching,图像生成技术在短短三年内经历了范式级跃迁。
本节将从 DDPM 的正向加噪与逆向去噪出发,逐步揭示三种预测目标的数学等价性、得分匹配与 SDE 的"上帝视角"、采样加速的工程技巧、条件控制与 CFG 的引导机制、潜空间扩散的降维奇迹、骨干网络从 U-Net 到 DiT 的架构演进,最后展望流匹配与一致性模型等前沿方向。
23.3.1 DDPM 核心:从噪声中重建世界
为什么需要扩散模型?
所有的生成式 AI,本质上都在做一件事:从数据分布
在扩散模型之前,GAN(对抗生成网络)是图像生成的主流方案,但它面临训练不稳定和模式坍塌两大顽疾。2020 年,Ho et al. 发表的 DDPM(Denoising Diffusion Probabilistic Models)证明了一个优雅的替代思路:不试图一步到位地从噪声生成图像,而是将过程拆解为上千个极其微小的去噪步骤,每一步都只需解决一个简单的"去掉一点噪声"的问题。
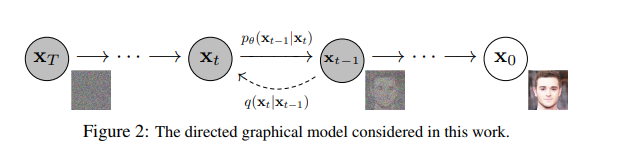
图 23-10:DDPM 的有向图模型(来源:Ho et al., 2020)。上方虚线箭头为正向加噪过程
正向过程:逐步加噪的马尔可夫链
正向过程是一个人为定义的、无需学习的马尔可夫链。给定一张干净的图片
即:
其中
重参数化技巧:闭式跳跃 [必读]
如果要生成第 1000 步的噪声图
其中
这个公式的工程意义极大:训练时可以随机抽取任意时间步
推导提示 [选读]: 将式 (23.2) 递归展开,利用"两个独立正态之和仍为正态"的性质(
),可以证明 ,从而得到式 (23.3)。
逆向过程:学习去噪
逆向过程是模型真正需要学习的。因为正向每一步加的噪声极小,数学上可以证明,真实的逆向单步转移同样近似为高斯分布:
其中方差
DDPM 损失函数:从 ELBO 到 MSE [必读]
为什么训练扩散模型的损失函数如此简洁?让我们追溯其推导路径。
DDPM 的训练目标源自变分推断的 ELBO(Evidence Lower Bound)。我们希望最大化数据的对数似然
经过仔细的条件分解,ELBO 可以拆成三部分:(a) 重建项
关键洞察: 在线性高斯马尔可夫链中,虽然
经过层层化简(将均值用
训练流程可以概括为四步:(1) 从数据集中采样一张干净图片
下面是完整的训练与采样的伪代码实现:
import torch
import torch.nn as nn
class DDPMTrainer:
def __init__(self, model, T=1000, beta_start=1e-4, beta_end=0.02):
self.model = model # 噪声预测网络 epsilon_theta
self.T = T
# 线性 beta 调度
betas = torch.linspace(beta_start, beta_end, T)
alphas = 1.0 - betas
alpha_bar = torch.cumprod(alphas, dim=0) # 累乘: bar{alpha}_t
self.register_buffers(betas, alphas, alpha_bar)
def train_step(self, x0):
"""DDPM 训练的单步:对应式 (23.3) 和 (23.6)"""
B = x0.shape[0]
# (1) 随机采样时间步
t = torch.randint(0, self.T, (B,), device=x0.device)
# (2) 采样随机噪声
epsilon = torch.randn_like(x0)
# (3) 一步到位加噪: x_t = sqrt(bar_alpha_t) * x0 + sqrt(1 - bar_alpha_t) * epsilon
sqrt_alpha_bar = self.alpha_bar[t].sqrt().view(B, 1, 1, 1)
sqrt_one_minus = (1 - self.alpha_bar[t]).sqrt().view(B, 1, 1, 1)
x_t = sqrt_alpha_bar * x0 + sqrt_one_minus * epsilon
# (4) 预测噪声并计算 MSE 损失
epsilon_pred = self.model(x_t, t)
loss = nn.functional.mse_loss(epsilon_pred, epsilon)
return loss
@torch.no_grad()
def sample(self, shape):
"""DDPM 逆向采样:从纯噪声逐步去噪"""
x = torch.randn(shape) # x_T ~ N(0, I)
for t in reversed(range(self.T)):
t_batch = torch.full((shape[0],), t, dtype=torch.long)
epsilon_pred = self.model(x, t_batch)
# 式 (23.5): 计算均值
alpha_t = self.alphas[t]
beta_t = self.betas[t]
alpha_bar_t = self.alpha_bar[t]
mu = (1 / alpha_t.sqrt()) * (x - beta_t / (1 - alpha_bar_t).sqrt() * epsilon_pred)
# 添加噪声(最后一步 t=0 不加)
if t > 0:
noise = torch.randn_like(x)
sigma = beta_t.sqrt()
x = mu + sigma * noise
else:
x = mu
return x23.3.2 三种预测目标的等价性
在闭式公式
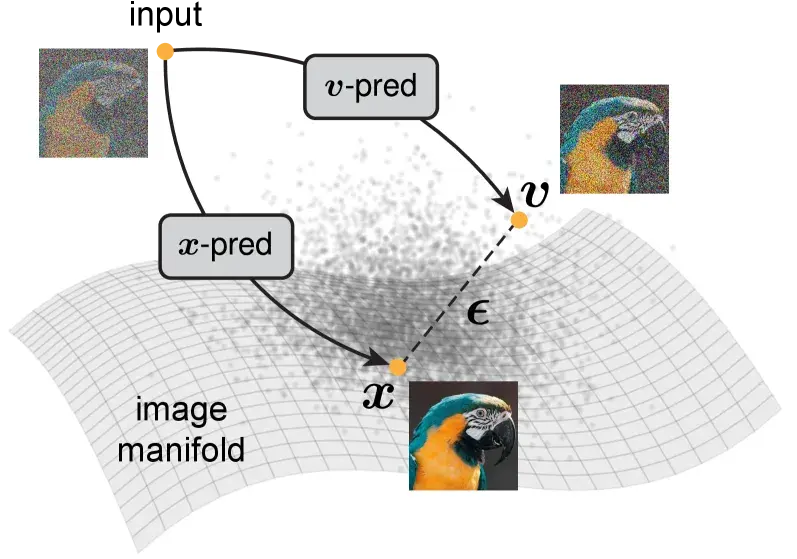
图 23-11:三种预测目标的几何直觉(来源:Salimans & Ho, 2022)。带噪输入位于噪声空间与图像流形之间,
这是 DDPM 的经典做法。网络输出
数值稳定性问题:在
网络直接输出
数值稳定性问题:在
Salimans & Ho (2022) 引入了一个巧妙的三角几何视角。注意到闭式公式中,
扩散过程就像一根指针在单位圆上从
核心优势:无论
关键洞察: 无论预测目标是
、 还是 ,骨干网络(U-Net 或 Transformer)的架构完全不需要改变。"语义不是写在网络结构里的,而是写在 Loss 里的。" 三种目标只是同一线性方程的不同"解读角度"。
下表总结了三种目标的特性:
| 预测目标 | 损失函数 | 代表模型 | ||
|---|---|---|---|---|
| 梯度退化 | 稳定 | DDPM, SD 1.x | ||
| 稳定 | 数值波动大 | DALL-E 2 | ||
| 稳定 | 稳定 | SD 2.x, Imagen |
23.3.3 得分匹配与 SDE 视角
前面的推导基于离散马尔可夫链和变分推断(ELBO)。本节将视角提升到连续时间,揭示扩散模型与得分匹配(Score Matching)、随机微分方程(SDE)之间的深刻联系。这一"上帝视角"由 Song et al. (2021) 的里程碑论文系统建立。
得分函数:只看坡度,不看海拔 [必读]
在能量模型
常数
得分(Score) 本质上是一个向量场:在数据空间的每个点上,它给出一个箭头,永远指向概率密度增加最快的方向。可以想象在地形图的每个位置放一个指南针,永远指向"下山"的方向。
核心联系:DDPM 中预测噪声
这意味着,训练一个
得分匹配的历史脉络 [选读]: 得分匹配最早由 Hyvarinen (2005) 提出,用于无需归一化常数的密度估计。Song & Ermon (2019) 将其与多尺度噪声扰动结合,提出了 NCSN(Noise Conditional Score Networks),即在不同噪声水平下联合训练得分估计器。DDPM 的
-prediction 可以被视为 NCSN 的一种特殊参数化形式。Song et al. (2021) 最终将 DDPM 和 NCSN 统一在 SDE 框架下,证明两者在数学上完全等价。
Langevin 动力学:从优化到采样 [选读]
如果单纯顺着得分(梯度)走,所有样本会被吸到局部最高概率的点上——这是"优化"而非"采样",会导致模式坍塌(Mode Collapse)。要实现真正的"生成/采样",必须引入精确的热噪声,即 Langevin 动力学:
一半是得分场的拉力(确定性),一半是高斯噪声的推力(随机性)。当步长
前向 SDE 与反向 SDE [选读]
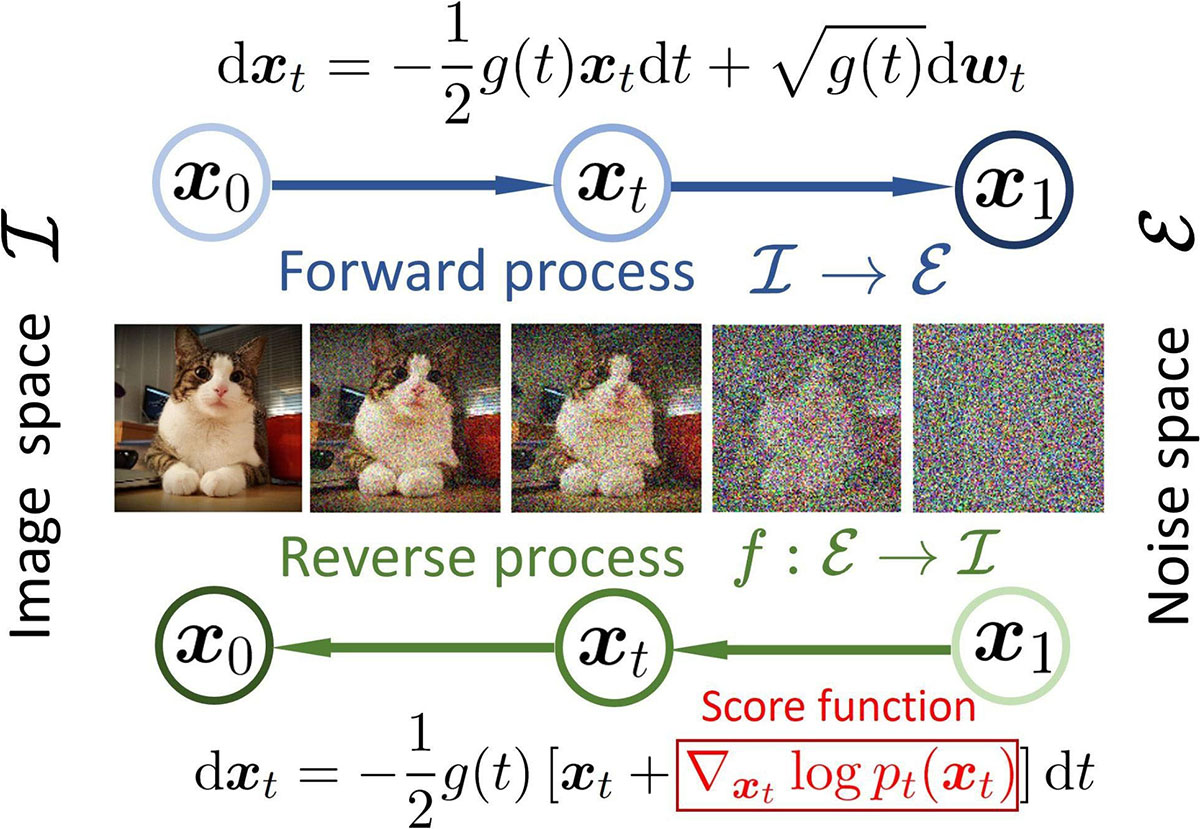
图 23-12:扩散模型的 SDE 视角(来源:Song et al., 2021)。上方为前向 SDE,将图像空间
在连续时间极限下(
其中
关键结论:只要我们学到了得分
概率流 ODE:确定性的平滑轨迹 [必读]
更震撼的是,Song et al. (2021) 证明了,对于每一条反向 SDE,都存在一条去掉了随机扰动项的概率流 ODE(Probability Flow ODE),两者在边际分布上完全等价:
两种轨迹的对比:
- SDE 轨迹:充满随机布朗运动,像在狂风中开车。容错率高,但必须步步为营,需要 1000 步才能走完(DDPM)。
- ODE 轨迹:没有随机项,是一条完全确定的平滑曲线。给定相同初始噪声,输出完全可复现。这为后续所有的**"加速采样算法"**奠定了理论基石。
23.3.4 采样加速:从千步到十步
理解了 SDE/ODE 视角后,一个核心认知浮出水面:采样器(Sampler)本质上就是微分方程的数值求解器。 DDPM 需要 1000 步采样,是因为它使用了最朴素的求解策略。减少步数会导致画面崩坏,根源在于三类误差的累积:
- 离散化误差:用折线拟合曲线,步长越大偏离越严重。
- 模型误差:神经网络预测的 Score 存在轻微偏差,大步长会加速偏差累积。
- 随机性误差(仅 SDE):步长变大导致单次注入的噪声方差暴增,系统极不稳定。
DDIM:关闭随机性
Song et al. (2021b) 提出的 DDIM(Denoising Diffusion Implicit Models)是第一个重要的加速方案。其核心思路是直接转向 ODE 视角,关闭随机项:
关闭随机项后,消除了"随机性误差",允许迈更大的步子。DDIM 将所需步数从 1000 步降至 50-100 步,实现 10-20 倍加速。更重要的是,给定相同初始噪声,DDIM 的轨迹是确定且可复现的——这为图像编辑和插值打开了大门。
DDIM 的语义插值 是确定性轨迹带来的一个附加能力:给定两张图像
DPM-Solver:高阶求解器
Lu et al. (2022) 提出的 DPM-Solver 将数值分析中的高阶方法引入扩散模型。直觉上:
- 一阶(Euler):只看脚下的斜率盲目前进,朴素但误差大——这就是 DDIM。
- 二阶(Heun)/ 多步法:先用 Euler 往前看一步,再用前方的斜率与当前的斜率做平均进行校正,利用历史轨迹进行高阶多项式拟合,大幅压缩所需步数。
DPM-Solver 在概率流 ODE 的半线性结构上进行精确解析求解,仅需 10-20 步即可生成高质量图像,成为 Stable Diffusion 的默认采样器之一。
Karras 时间步调度
时间
Karras 调度通过对
当
23.3.5 条件控制与 CFG
无条件的扩散模型只能随机生成图像。要让模型根据文本提示生成特定内容,需要将采样目标从
网络层面的条件注入
条件信息需要在网络架构中找到"入口"。现代扩散模型使用两种主要机制:
1. 特征调制(AdaGN):将条件信号(如时间步嵌入、类别嵌入)映射为一对向量
这相当于一个**"全局风格旋钮"**:
2. 交叉注意力(Cross-Attention):将文本条件 Token 化后,图像特征作为 Query,文本 Token 序列作为 Key/Value:
其中
CFG:无分类器引导 [必读]
无分类器引导(Classifier-Free Guidance, CFG)是现代扩散模型最核心的控制机制(Ho & Salimans, 2022)。
训练时:以一定概率(通常 10%)随机丢弃条件
推理时:在每一步同时计算两者,并进行线性外推:
几何直觉:有条件预测与无条件预测之差
:不使用引导,等价于标准条件生成。 :常用范围,图像质量与条件遵循度最佳。 过大(如 ):条件推力过强,扭曲流形,导致色彩过饱和、纹理粘连("塑料感")、画面崩坏。
三角权衡:
CFG 的得分函数解释 [挑战]: 从得分匹配视角,式 (23.20) 等价于对条件得分函数做外推。利用贝叶斯公式
,可以证明 CFG 实际上是在以 倍的强度增强似然项 的贡献: 。这与分类器引导(Classifier Guidance, Dhariwal & Nichol, 2021)在数学形式上完全等价,只是后者需要一个独立的分类器来提供 ,而 CFG 通过条件/无条件预测的差分隐式地实现了相同的效果——因此被称为"无分类器"引导。
负面提示词(Negative Prompt)
只需将公式 (23.20) 中的无条件预测
修正向量就变成了"既靠近正面描述,又远离负面描述"。例如,正面提示词为"高清写实照片",负面提示词为"模糊、低质量、卡通",推力方向就会同时追求清晰度并回避卡通风格。
23.3.6 潜空间扩散(Latent Diffusion / Stable Diffusion)
直接在
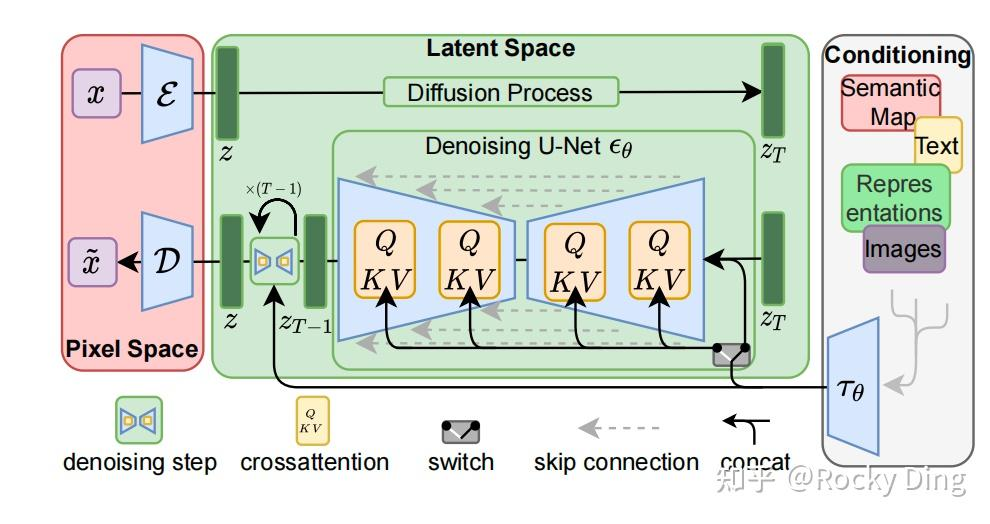
图 23-13:Latent Diffusion Model 架构(来源:Rombach et al., 2022)。左侧 VAE Encoder
VAE 压缩:降维打击
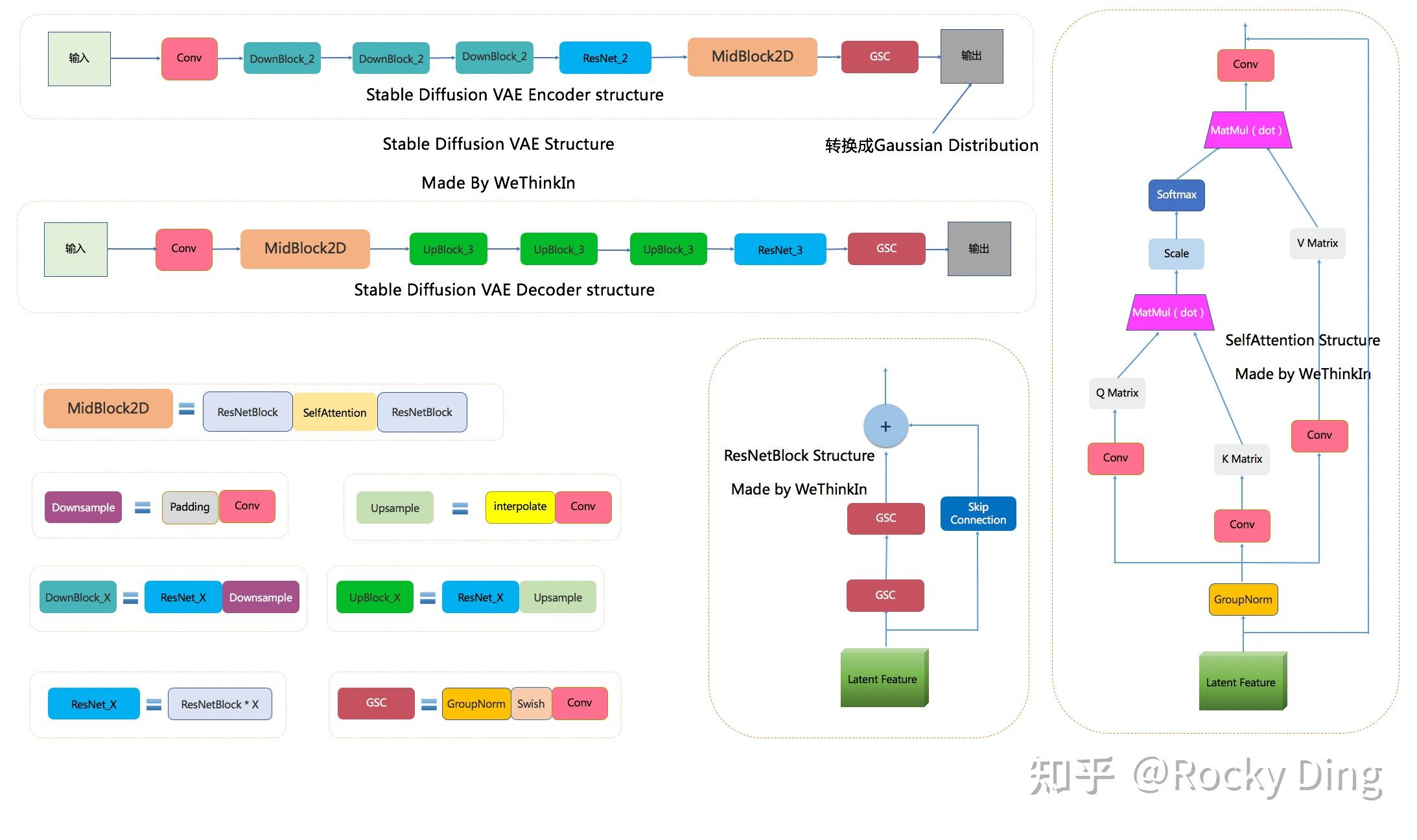
图 23-13b:Stable Diffusion 中 VAE 的详细结构。上方为 Encoder(多级 DownBlock 压缩),下方为 Decoder(多级 UpBlock 还原),中间包含 MidBlock 进行全局特征融合。
第一阶段,训练一个独立的 VAE(变分自编码器)作为"感知友好的压缩器":
- Encoder
:将 的像素图压缩到 的潜空间(SD 1.x 中 , )。一张 的图被压缩为 的 latent。具体而言,Encoder 由多级 DownBlock(每级包含 ResNet 块和下采样卷积)组成,最终输出均值 和标准差 ,通过重参数化 采样得到 latent。 - Decoder
:由对称的 UpBlock(ResNet 块 + 上采样插值 + 卷积)组成,将潜空间表示还原为像素图。
VAE 的训练结合了像素级重建损失(L1 或 L2)、感知损失(利用预训练 VGG 网络的中间特征计算)和对抗损失(引入 PatchGAN 判别器),以保证重建图像在高频细节上的真实感。
扩散模型只在这个低维潜空间里做加噪去噪,计算维度从
完整的 LDM 推理流程 可以概括为三步:(1) 从标准高斯分布采样 latent 噪声
三次损耗分析:VAE 是画质天花板
为什么 Stable Diffusion 画不好细小的文字?远景人脸容易崩坏?根源在于三重信息瓶颈:
- 编码损耗:VAE Encoder 压缩时,高频细节(文字边缘、细纹理)被强行丢弃。
下采样意味着原图中 的像素块被压缩为一个标量。 - 扩散损耗:扩散模型在潜空间中带有平滑归纳偏置,进一步模糊高频信息。
- 解码损耗:VAE Decoder 解码时,发现信息缺失,会根据训练偏好进行"统计性脑补"——这就是为什么 SD 有时会产生"外星文"或"塑料感"面孔。
结论:VAE 决定了画质的绝对天花板。 这也是为什么 Stable Diffusion 每一代的重大更新都伴随着 VAE 的升级(SD 1.x 用 KL-VAE,SDXL 改进了 VAE 训练策略,SD3 进一步提升了 latent 通道数)。
23.3.7 骨干网络演进:U-Net → DiT → MMDiT
扩散模型的理论框架(加噪、去噪、损失函数)与骨干网络的选择是正交的——你可以用任何能够处理图像并接受时间步条件的网络来做噪声预测。但网络架构的选择对性能有决定性影响。
U-Net:频率分工的先验专家
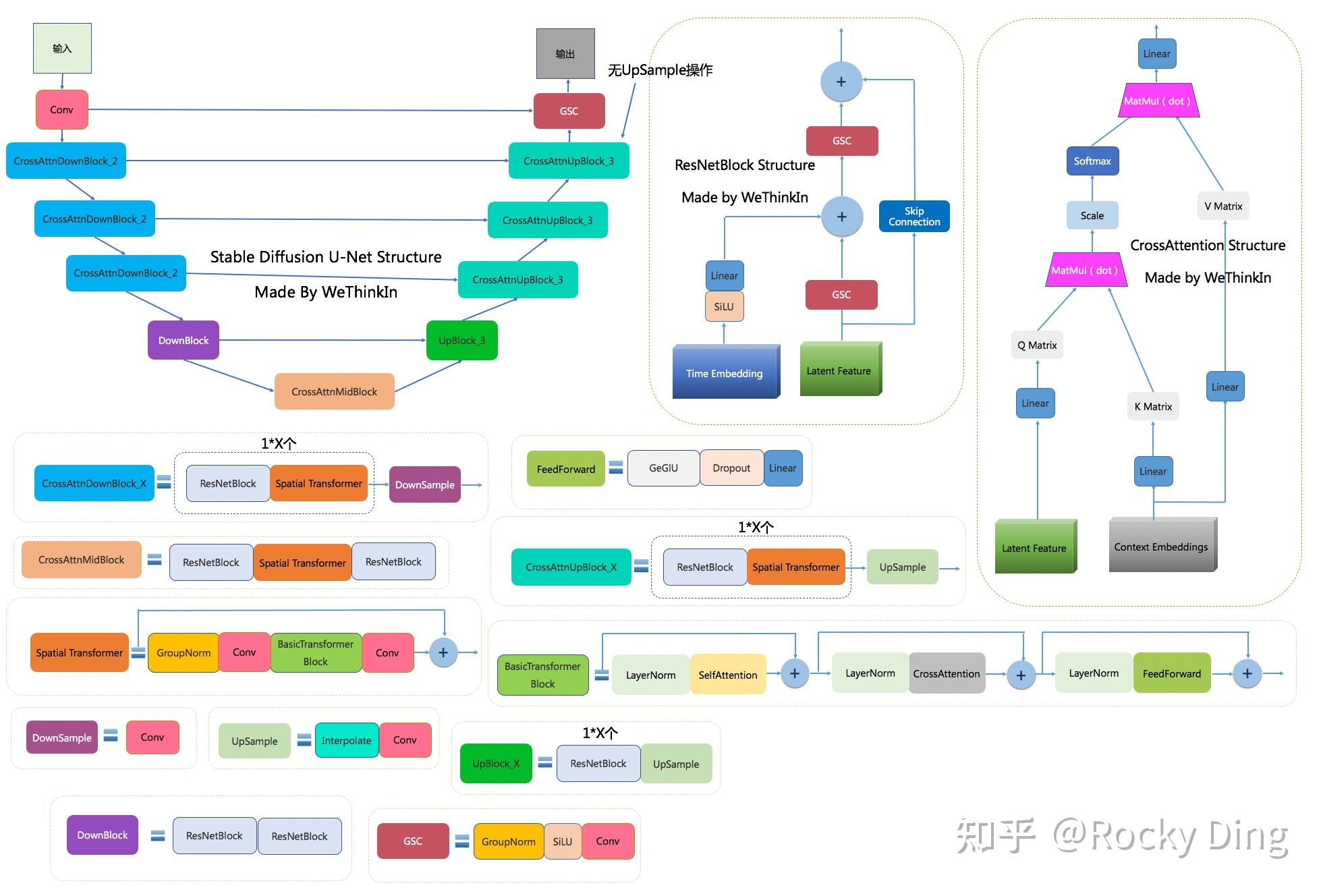
图 23-14:Stable Diffusion 中 U-Net 的详细架构。左侧为下采样路径(捕获全局低频轮廓),右侧为上采样路径(恢复高频细节),中间通过跳跃连接传递多尺度特征。每个阶段包含 ResNet 块、交叉注意力块(注入文本条件)和时间步嵌入。
U-Net 最初为医学图像分割设计(Ronneberger et al., 2015),其 U 形编码器-解码器结构天然适合扩散模型:
- 下采样路径:通过卷积和池化逐步缩小特征图,捕获全局低频轮廓。
- 上采样路径:逐步放大特征图,恢复局部高频细节。
- 跳跃连接(Skip Connection):将下采样各层的特征直接传递给对应的上采样层,实现多尺度特征融合。
这种结构等效实现了完美的**"频率分工"**:低分辨率层负责全局构图,高分辨率层负责细节纹理。U-Net 自带极强的图像局部相关性先验,在中小规模数据和算力下表现出色。
DiT:剥离先验,拥抱 Scaling Laws
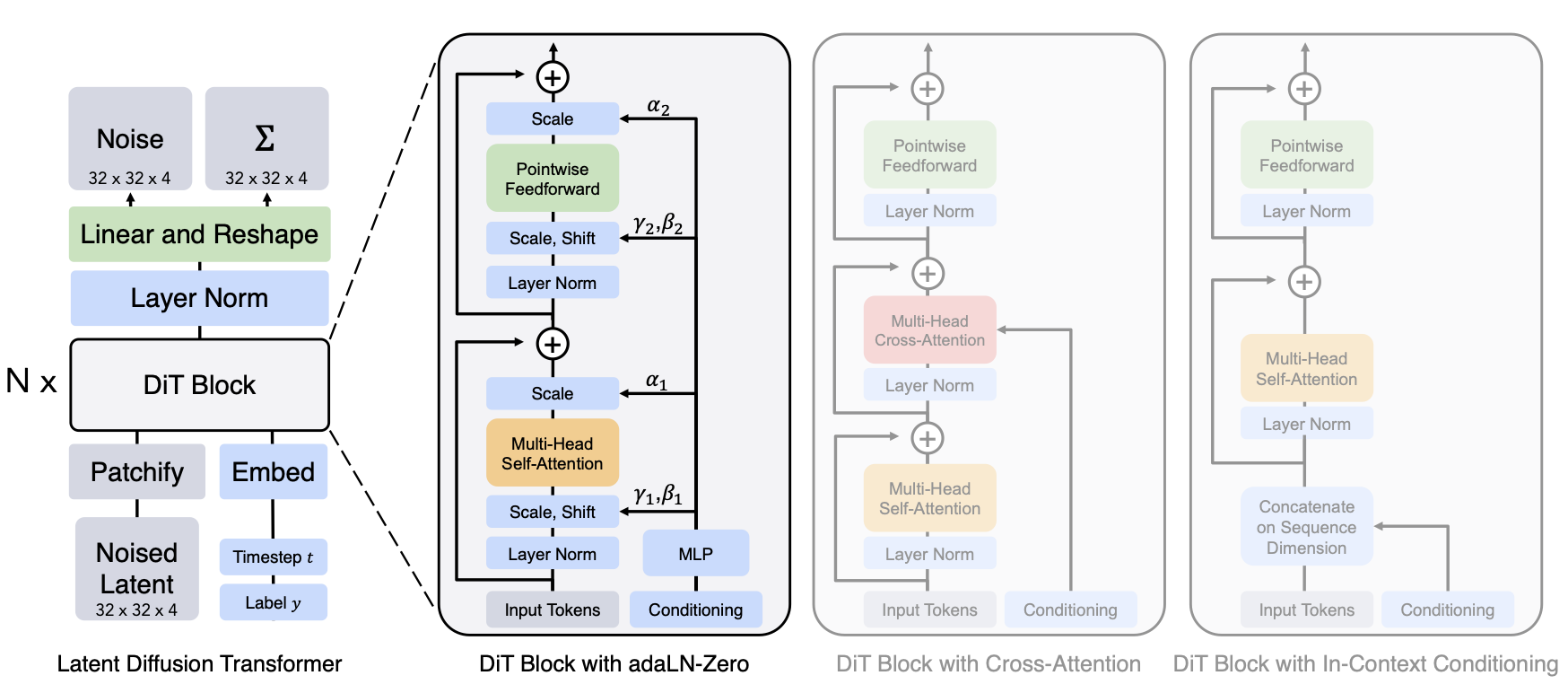
图 23-15:DiT(Diffusion Transformer)架构(来源:Peebles & Xie, 2023)。左侧为整体流程:将噪声 latent 切成 patch 并展平为序列,输入标准 Transformer。右侧展示了不同的条件注入方案,其中 adaLN-Zero 效果最优。
Peebles & Xie (2023) 提出了 DiT(Diffusion Transformer),核心思路是:像 LLM 处理文本一样处理图像。
- Patchify:将
的噪声 latent 切成 的 patch,展平为长度为 256 的序列。 - 位置编码:加入可学习的或正弦位置编码。
- 标准 Transformer:使用多头自注意力和前馈网络处理序列。
- 条件注入:通过 adaLN-Zero(Adaptive Layer Normalization with Zero-initialization)注入时间步和类别条件——将条件信号映射为
三组向量,分别控制 LayerNorm 的缩放、平移和残差门控。
DiT 的哲学是剥离 U-Net 的归纳偏置先验,用纯数据驱动的 Transformer 拥抱 Scaling Laws。实验表明,DiT-XL/2(约 6.75 亿参数)在 ImageNet 256×256 上以 FID=2.27 首次超越了所有 U-Net 基线。Sora 的视频生成引擎即基于 DiT 架构的扩展。
为什么 adaLN-Zero 是最优的条件注入方式? DiT 论文对比了四种条件注入策略:(1) In-Context(将条件 Token 拼入序列)、(2) Cross-Attention、(3) adaLN(自适应 LayerNorm)、(4) adaLN-Zero。最后一种在残差连接前引入了一个初始化为零的门控参数
MMDiT:双向语义对齐
Stable Diffusion 3(Esser et al., 2024)引入了 MMDiT(Multi-Modal DiT),对 DiT 做了关键升级:
- 传统做法:图像特征通过交叉注意力单向查询文本特征——信息流是"图→文"的单行道。
- MMDiT:将图像 Token 和文本 Token 拼接成一整条长序列,在同一个 Self-Attention 中做联合计算。信息在两个模态之间双向自由流动。
这带来了更强大的图文对齐能力。直觉上,传统的交叉注意力像是"翻译"——图像先理解自己,再去查阅文本字典。MMDiT 更像是"讨论"——图像和文本坐在同一张桌子上实时交流,双方都能根据对方的信息调整自己的表达。
三种架构的对比总结:
| 特性 | U-Net | DiT | MMDiT |
|---|---|---|---|
| 核心组件 | 卷积 + 跳跃连接 | Self-Attention + FFN | Joint Self-Attention |
| 归纳偏置 | 强(多尺度、局部性) | 弱(仅位置编码) | 弱 |
| 条件注入 | 交叉注意力 + AdaGN | adaLN-Zero | Joint Attention |
| Scaling Law | 有限(卷积瓶颈) | 强 | 强 |
| 代表模型 | SD 1.x/2.x/XL | Sora, FLUX | SD 3/3.5 |
23.3.8 前沿:流匹配、修正流与一致性模型
扩散模型的演进并没有停止。当我们站在"概率流演化"的上帝视角,新的大门就打开了。
流匹配(Flow Matching)[必读]
扩散模型用高斯噪声找路的轨迹是弯曲且随意的——前向过程的数学形式决定了 ODE 的速度场不会是直线。为什么不直接走直线?
Lipman et al. (2023) 提出的 Flow Matching 抛弃了繁琐的马尔可夫链和 SDE 框架,直接定义一条从噪声到图像的线性插值轨迹:
此时的理想速度场是一个常数向量:
训练目标变得极其简单——让神经网络
与 DDPM 相比,Flow Matching 有三个显著优势:
- 数学简洁:无需
、 、 等繁琐的噪声调度。 - 轨迹更直:接近直线的轨迹意味着低阶 ODE 求解器(如简单的 Euler 法)就能高效采样。
- 步数更少:4-8 步即可生成高质量图像,远少于 DDPM 的 1000 步或 DDIM 的 50 步。
Stable Diffusion 3 和 Flux 系列均采用 Flow Matching 方案训练。
下面是 Flow Matching 训练的核心代码,对比 DDPM 可以看到简洁程度的飞跃:
import torch
import torch.nn as nn
class FlowMatchingTrainer:
def __init__(self, model):
self.model = model # 速度预测网络 v_theta
def train_step(self, x_data):
"""Flow Matching 训练的单步:对应式 (23.22)-(23.24)"""
B = x_data.shape[0]
# (1) 采样噪声和时间
x_noise = torch.randn_like(x_data)
t = torch.rand(B, 1, 1, 1, device=x_data.device) # t ~ U(0, 1)
# (2) 线性插值构造 x_t
x_t = (1 - t) * x_noise + t * x_data
# (3) 目标速度就是常数: x_data - x_noise
target_v = x_data - x_noise
# (4) 预测速度并计算 MSE 损失
v_pred = self.model(x_t, t.squeeze())
loss = nn.functional.mse_loss(v_pred, target_v)
return loss
@torch.no_grad()
def sample(self, shape, steps=8):
"""Flow Matching 采样:Euler 法求解 ODE"""
x = torch.randn(shape)
dt = 1.0 / steps
for i in range(steps):
t = torch.full((shape[0],), i * dt)
v = self.model(x, t)
x = x + v * dt # Euler 步进
return x注意 Flow Matching 的训练代码不需要
修正流(Rectified Flow)[选读]
虽然 Flow Matching 在微观上规定了直线轨迹,但因为
Liu et al. (2023) 提出了 Rectified Flow(修正流),通过一个"拉直"(Reflow)过程来解决这个问题:
- 第一轮训练:用随机配对的数据训练一个 Flow Matching 模型。
- 生成因果配对:用训练好的模型从一批噪声
出发,ODE 积分得到对应的图像 。现在 之间有了明确的因果关系。 - Reflow 重训:用这些因果配对数据重新训练模型。由于配对有了一一对应的确定性关系,宏观流形被强行拉直。
轨迹越直,ODE 求解器就可以用越大的步长。经过 Reflow 后,模型在 1-4 步即可生成高质量图像。
一致性模型(Consistency Models)[选读]
Song et al. (2023) 提出了比"拉直路线"更极端的方案——直接跳过积分过程。
一致性模型的核心约束是自一致性:同一条 ODE 轨迹上的任意两个点
训练时,通过惩罚同一轨迹上相邻时间点输出的不一致性来优化这个约束。一旦训练完成,无论输入哪个时间步的带噪图像,模型都能一步到位直接输出干净的
下表总结了从 DDPM 到一致性模型的采样效率演进:
| 方法 | 典型步数 | 核心思路 | 轨迹类型 |
|---|---|---|---|
| DDPM | 1000 | 反向 SDE(朴素 Euler) | 随机(含布朗运动) |
| DDIM | 50-100 | 概率流 ODE(一阶 Euler) | 确定性 |
| DPM-Solver | 10-20 | 高阶 ODE 求解器 | 确定性 |
| Flow Matching | 4-8 | 直线轨迹 + Euler | 确定性 |
| Rectified Flow | 1-4 | Reflow 拉直宏观流 | 确定性 |
| Consistency Model | 1 | 跳过积分,直接映射终点 | 单步映射 |
23.3.9 本节总结
本节系统地梳理了扩散模型的完整理论体系。我们从 DDPM 的正向加噪与逆向去噪出发,理解了重参数化技巧为何能让训练"一步到位";通过三种预测目标(
在工程层面,CFG 通过条件与无条件预测的线性外推实现了精确的文本控制;潜空间扩散(LDM / Stable Diffusion)通过 VAE 压缩将计算量降低了近两个数量级;骨干网络从 U-Net 的归纳偏置先验演进到 DiT / MMDiT 的纯 Scaling Law 驱动。在前沿方向,Flow Matching 用直线轨迹取代弯曲的扩散路径,Rectified Flow 通过 Reflow 进一步拉直宏观流形,一致性模型则直接跳过积分实现单步生成。
理解这些理论,不仅是使用扩散模型的基础,更是理解 Sora、Flux、SD3 等下一代视觉生成系统的必备知识。在下一节中,我们将看到如何将扩散模型的生成能力扩展到视频领域,以及多模态统一模型如何在单一架构中兼顾理解与生成。