24.6 模型范式演进框架
从 2022 年 ChatGPT 横空出世到 2025 年,大模型领域经历了多轮范式级别的跃迁。如果说前面几节讲的是大模型在各个垂直领域的落地(自动驾驶、具身智能、推荐系统、AI 终端、世界模型),那么本节要退后一步,从方法论和部署形态的角度审视大模型技术本身的演进脉络。我们将沿四条主线展开:推理模型范式如何让"慢思考"成为新的 Scaling 维度;多模态生成范式如何从"理解"跨越到"创造";工具调用范式如何将大模型从对话助手升级为自主执行的 Agent;部署形态如何从闭源 API 向开源权重乃至端侧推理全面铺开。
24.6.1 推理模型范式
从"快系统"到"慢系统"
早期大模型(如 GPT-3、GPT-4)的推理模式可类比于心理学中的系统 1 思维(System 1)——给定一个问题,模型在一次前向传播中直接生成答案,速度快但对复杂推理任务容易出错。2024 年 9 月,OpenAI 发布的 o1 模型标志着一个范式转折:模型在输出最终答案之前,先在内部生成一段长长的思维链(Chain-of-Thought, CoT),逐步推导、反思、纠错,最后才给出结论。这种"先想清楚再回答"的模式被称为推理时计算(Inference-Time Compute)或系统 2 思维(System 2),其核心思想是:在推理阶段投入更多计算资源,可以显著提升模型在数学、编程和科学推理等困难任务上的表现。
从技术实现看,o1 的训练融合了两项关键技术:
- 大规模强化学习(RL):以 CoT 过程的最终答案正确性作为奖励信号,通过 RL 训练模型学会"如何思考"——包括何时拆分子问题、何时回溯检查、何时切换策略。不同于 ChatGPT 使用的 RLHF(基于人类偏好的奖励),o1 的奖励信号来自客观的正确性判定(数学题有标准答案、代码有测试用例),这使得 RL 可以在无需人工标注的情况下大规模运行。
- 思维链蒸馏:将 RL 产生的高质量 CoT 数据用于监督微调,使模型在推理时自然地展开内部推理过程,而不需要用户手动设计 few-shot CoT 提示。
OpenAI 公布的评测数据展示了这种范式的威力:
| 基准测试 | GPT-4o | o1-preview | o1 | 说明 |
|---|---|---|---|---|
| AIME 2024(数学竞赛) | 13.4% | 56.7% | 83.3% | 美国数学邀请赛准确率 |
| Codeforces(编程竞赛) | 第 11 百分位 | 第 62 百分位 | 第 89 百分位 | 编程竞赛排名百分位 |
| GPQA Diamond(博士级科学问答) | 56.1% | 78.3% | 78.0% | 人类专家水平为 69.7% |
这些数字揭示了一个重要信息:o1 在专业推理任务上的提升并非线性的"小幅改进",而是跨越了一个数量级——从"基本不会做竞赛题"到"接近竞赛选手水平"。
推理时间缩放定律
传统的 Scaling Law 关注的是训练时计算——增加模型参数量和训练数据量可以持续提升性能。推理模型开辟了第二条缩放维度:推理时计算。给同一个模型更多的"思考时间"(即允许生成更长的 CoT),其准确率会持续提升。这意味着即使模型参数量固定,也可以通过增加推理预算来"解锁"更强的能力。
这一思想可以用以下框架理解:
其中
过程奖励模型(PRM)
推理模型的一个关键技术组件是过程奖励模型(Process Reward Model, PRM)。与传统的结果奖励模型(Outcome Reward Model, ORM)只在最终答案处给出奖励不同,PRM 对推理过程中的每一步都给出评分。直觉上,PRM 就像一个数学老师——不只看学生最终答案对不对,还检查每一步推导是否正确。
PRM 的引入带来了两个好处:第一,它提供了更密集的训练信号,解决了 RL 中稀疏奖励的问题;第二,它可以在推理时实现最佳优先搜索(Best-of-N Search)——生成多条推理路径,用 PRM 评估每条路径的每一步质量,选择综合得分最高的路径作为最终输出。
DeepSeek-R1:开源推理模型的里程碑
2025 年 1 月,DeepSeek 团队发布了 DeepSeek-R1,在多项推理基准上达到了与 o1 相当的水平,并且完全开源了模型权重。DeepSeek-R1 的技术路线揭示了一个重要发现:纯 RL 训练就能让模型涌现出 CoT 推理能力。
DeepSeek-R1 的训练分为两个阶段:
- 第一阶段(纯 RL):从 DeepSeek-V3 基座模型出发,仅使用基于规则的奖励(如数学题的答案正确性、代码的测试用例通过率),通过 GRPO(Group Relative Policy Optimization)算法进行大规模 RL 训练。研究者发现,模型在 RL 过程中自发涌现出了自我验证(self-verification)、反思(reflection)和纠错(self-correction)等高级推理行为——这些行为并非通过示例教授,而是模型为了获得更高奖励而自主发展出来的策略。
- 第二阶段(蒸馏 + SFT):将第一阶段产生的高质量 CoT 数据用于监督微调,提升模型输出的可读性和格式规范性。这一阶段同时也修复了纯 RL 模型在语言混杂、格式混乱等方面的问题。
此外,DeepSeek 还发布了一系列蒸馏模型(如 DeepSeek-R1-Distill-Qwen-32B、Distill-Qwen-14B 等),证明了推理能力可以从大模型向小模型迁移——即使是 14B 参数的蒸馏模型,在数学推理上也超过了直接用 RL 训练的同规模模型。这为端侧设备上运行推理模型开辟了可行路径。
从 o1 到 o3/o4-mini:持续进化
OpenAI 在 o1 之后持续迭代:2025 年初发布了 o3 和 o4-mini,进一步提升了推理效率和准确率。o3 在 ARC-AGI 基准上取得了突破性表现,o4-mini 则在保持推理能力的同时大幅降低了推理成本。这条路线的核心演进方向是:
| 阶段 | 代表模型 | 核心技术 | 关键特征 |
|---|---|---|---|
| CoT 提示 | GPT-4 + few-shot CoT | 手工设计提示模板 | 提升有限,依赖 prompt 工程 |
| 训练时 CoT | o1 / R1 | RL + CoT 蒸馏 | 模型学会自主推理,性能跨量级提升 |
| 验证器驱动 | o1-pro / o3 | 过程奖励模型(PRM) | 每步推理都获得反馈,减少错误传播 |
| 推理效率优化 | o4-mini / R1-Distill | 蒸馏 + 自适应推理预算 | 小模型也能做复杂推理,成本可控 |
24.6.2 多模态生成范式
从"看懂"到"创造"
早期的多模态大模型(如 GPT-4V、LLaVA)主要解决理解问题——给一张图片,模型能描述内容、回答问题。2024 年起,多模态范式发生了根本性跃迁:大模型不仅要"看懂",还要能"创造"。这一转变沿三条技术路线展开。
路线一:统一理解与生成
2024 年 5 月发布的 GPT-4o("o"代表 omni,即"全能")是这条路线的里程碑。GPT-4o 的核心创新是将文本、视觉和音频三种模态统一在一个端到端模型中训练和推理,而非像前代模型那样通过 Whisper(语音识别)+ GPT-4(文本理解)+ TTS(语音合成)的级联管线拼接。
从 GPT-4o 技术报告披露的组织结构可以看到,该项目涉及超过 400 名研究人员,分为语言大模型项目(16 个小组、220+ 人,负责长文本、预训练、数据飞轮、Tokenizer 等)和多模态大模型项目(20 个小组、106+ 人,负责语音预训练、视觉感知与生成、编解码等)。这种规模的投入表明,真正的端到端多模态模型在工程复杂度上远超单一模态的 LLM。
统一架构带来了两个关键优势:
- 延迟大幅降低:级联管线中每个模块都会引入延迟,GPT-4o 的端到端架构使语音响应时间降至 320 毫秒,接近人类对话的自然延迟。
- 跨模态语义一致:模型能直接感知语音中的情感、语调、背景噪音等信息,而非仅依赖转录后的文本。这意味着当用户用焦虑的语气提问时,模型不仅理解文字内容,还能感受到情绪状态。
在开源社区,DeepSeek 发布的 Janus 系列代表了另一种统一思路:通过解耦的视觉编码器同时支持理解和生成。Janus 使用一个理解编码器(SigLIP)处理视觉理解任务,一个生成编码器(VQ tokenizer)处理图像生成任务,二者共享同一个 LLM 主干网络。这种设计避免了"理解需要高维语义表征、生成需要低维空间表征"之间的矛盾,因为两个编码器各自为其任务优化表征空间,只在 LLM 层面进行融合。
路线二:视频与 3D 生成
2024 年 2 月,OpenAI 发布 Sora 技术报告,宣告了视频生成领域的范式转换。Sora 的技术架构可以简洁表述为:
理解这个公式需要把握四个组件的角色分工:
- VAE Encoder:将原始视频压缩为低维潜空间表示(Spacetime Patches),大幅降低后续处理的计算量。
- Diffusion Transformer(DiT):在潜空间中执行条件去噪生成。与传统扩散模型使用 U-Net 作为主干不同,Sora 使用 Transformer 架构,使得模型可以像 LLM 一样随参数量增长持续提升。
- VAE Decoder:将 DiT 生成的潜空间表示还原为像素级视频数据。
- CLIP + DALL-E 3:将文本条件注入生成过程,并使用 GPT-4 进行提示词扩充——将用户简短的提示词自动丰富为详细的场景描述。
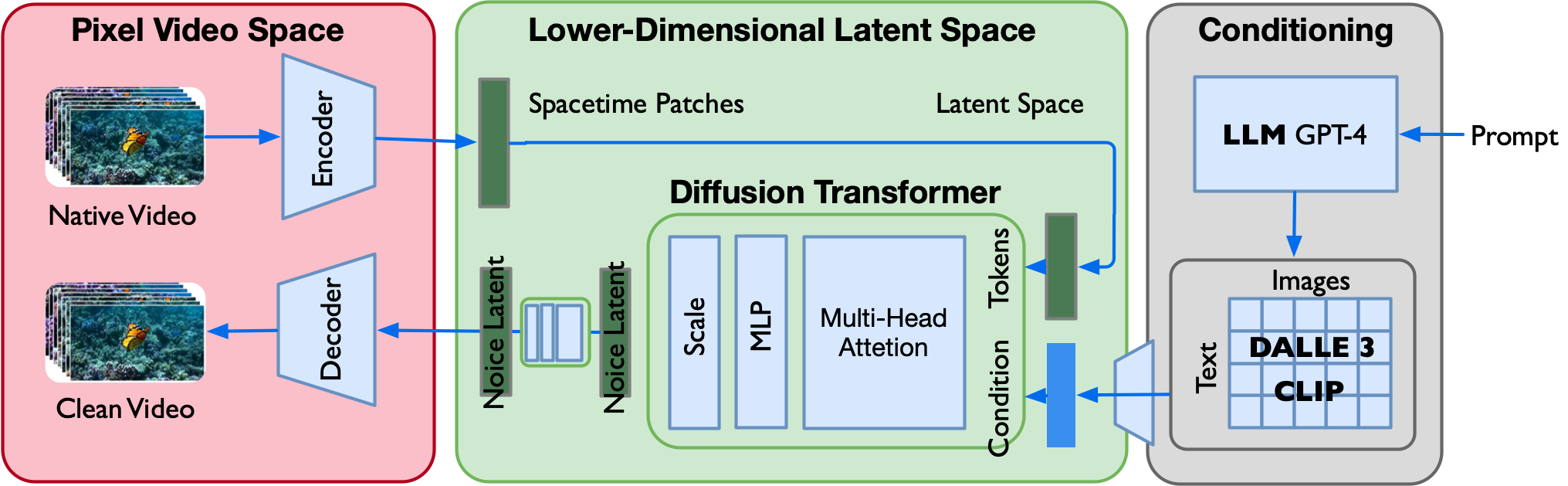
图 24-27:Sora 的技术架构。原始视频经 VAE 编码器压缩为 Spacetime Patches,Diffusion Transformer(DiT)在潜空间进行条件去噪生成,文本条件通过 CLIP 和 DALL-E 3 注入,最终 VAE 解码器将潜空间表示还原为像素级视频。
Sora 的几项核心设计选择值得深入理解:
- 原生分辨率/时长训练:不裁剪、不缩放原始视频,直接以原生尺寸和时长训练。这使得模型学到了更好的构图和尺寸感知能力。
- DiT 取代 U-Net:传统的 Stable Diffusion 系列使用 U-Net 作为去噪主干,其结构固定导致模型规模受限。DiT 通过将去噪过程转化为 Transformer 的序列处理任务,打通了视频生成的 Scaling 路线。
- Re-captioning 数据工程:训练数据中的原始视频标注通常质量不高。Sora 使用 DALL-E 3 和 GPT-4 对视频进行详细的文本再标注,构建高质量的 Text-Video 配对数据集。
从 Sora 到后续的 Runway Gen-3、Kling(可灵)等产品,视频生成已经从"生成几秒钟模糊片段"进化到"生成数十秒高保真视频"。但正如 24.5 节讨论的那样,视频生成能力并不等于物理理解能力——生成的视频中仍然频繁出现违反物理常识的错误(如物体穿模、液体反重力流动等),这是当前视频生成模型最大的局限。
路线三:从理解到全模态
2024-2025 年间,多模态模型的演进方向从"多模态理解"走向"全模态统一"(Any-to-Any),即一个模型同时处理文本、图像、音频、视频的输入和输出。这条路线的关键里程碑包括:
| 时间 | 模型 | 能力范围 | 核心架构创新 |
|---|---|---|---|
| 2024.05 | GPT-4o | 文本+图像+音频 理解与生成 | 端到端多模态统一训练 |
| 2024.12 | Gemini 2.0 | 文本+图像+音频+视频 | 原生多模态 + 工具调用 |
| 2025.01 | Janus-Pro | 图像理解 + 图像生成 | 解耦编码器 + 共享 LLM |
| 2025.03 | GPT-4o 原生图像生成 | 高质量文本驱动图像生成 | 自回归原生图像生成(非 DALL-E) |
值得关注的是,2025 年 3 月 GPT-4o 更新的原生图像生成能力标志着一个重要转变:图像不再由独立的扩散模型(如 DALL-E 3)生成,而是由 LLM 本身在自回归解码过程中直接产出。这意味着语言模型和图像生成模型的边界正在消失。
24.6.3 工具调用范式
从对话到行动
大模型最初的交互形式是纯文本对话:用户提问,模型回答。但现实世界中的许多任务(搜索信息、编辑文件、执行代码、操作数据库)无法仅通过生成文本来完成。工具调用(Tool Use / Function Calling)赋予大模型"动手"的能力,是从"对话助手"到"自主 Agent"的关键跳板。
第一阶段:结构化函数调用
2023 年 6 月,OpenAI 为 GPT-3.5/4 API 正式推出 Function Calling 功能。模型不再只是返回自然语言文本,而是可以输出结构化的 JSON 格式函数调用请求,由外部系统执行后将结果返回给模型。以下是一个典型的调用流程示例:
import json
# 1. 定义可用工具的描述(传给模型的元信息)
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "查询指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "城市名称"},
"date": {"type": "string", "description": "日期,格式 YYYY-MM-DD"}
},
"required": ["location"]
}
}
}]
# 2. 模型决定调用工具,输出结构化 JSON(而非自然语言)
model_output = {
"function": "get_weather",
"arguments": {"location": "北京", "date": "2025-03-24"}
}
# 3. 外部系统执行函数
result = get_weather(**model_output["arguments"])
# result = {"temperature": 15, "condition": "晴", "wind": "北风3级"}
# 4. 将执行结果返回给模型,模型据此生成最终回答
# "北京今天天气晴朗,气温15°C,北风3级,适合户外活动。"这一机制的关键在于:模型学会了何时该调用工具(而非凭记忆直接回答)以及如何构造参数(输出符合 JSON Schema 的结构化数据)。训练方法通常包括在 SFT 数据中加入大量工具调用示例,让模型学会在合适的时机输出特定格式的调用指令。
第二阶段:Agent 自主规划
Function Calling 解决了"单步工具调用"的问题,但复杂任务往往需要多步规划:分析任务需求、拆解子任务、按序调用多个工具、处理中间失败、整合最终结果。这就是 AI Agent 范式的核心。
Agent 的基本架构可以抽象为四个组件:
其中 LLM 负责理解任务、制定计划和生成工具调用指令;工具集包括搜索引擎、代码执行器、文件系统、浏览器等;记忆模块存储历史交互和中间结果(包括短期的工作记忆和长期的向量数据库);规划模块协调整个执行流程。
2024 年最具影响力的 Agent 框架是 ReAct(Reasoning + Acting),它将推理和行动交织在一个循环中:
Thought: 用户要求分析某公司近5年的营收趋势。
我需要先搜索该公司的财务数据。
Action: search("某公司 2020-2024 年度营收")
Observation: [搜索结果: 2020年100亿, 2021年120亿, ...]
Thought: 数据已获取,接下来需要绘制趋势图并分析。
Action: execute_code("import matplotlib; ...")
Observation: [图表已生成]
Thought: 图表显示营收持续增长但增速放缓,需要总结分析。
Action: 生成最终分析报告这种"思考-行动-观察"的循环使得 Agent 能够动态调整策略:如果某个工具调用失败,Agent 可以尝试替代方案;如果中间结果不符合预期,Agent 可以回溯重新规划。
第三阶段:环境交互与自主执行
2024-2025 年,Agent 范式进一步进化,从"在沙盒中调用 API"走向"在真实环境中自主执行"。代表性产品包括:
- Claude Code(Anthropic,2025):一个命令行 AI Agent,能够在开发者的本地环境中直接读写文件、执行 shell 命令、运行测试、操作 Git。它不是简单地建议代码修改,而是直接执行修改并验证结果。开发者只需用自然语言描述目标(如"给这个函数加上错误处理并写测试"),Claude Code 会自动分析代码库、编写修改、运行测试、检查结果。
- Manus(2025):一个通用任务 Agent,能够操作浏览器、编写和执行代码、管理文件,完成从"帮我调研某个主题并整理成报告"到"帮我部署一个网站"等端到端任务。
- OpenAI Operator / Computer Use(2025):通过截图理解 + 鼠标键盘操作的方式,Agent 直接操控浏览器界面(点击、滚动、输入),像人类一样完成网页上的复杂操作。这种方式的优势是不依赖任何 API——只要应用有图形界面,Agent 就能使用。
下表梳理了工具调用范式的三个演进阶段:
| 阶段 | 时间 | 核心能力 | 代表案例 | 人类角色 |
|---|---|---|---|---|
| 函数调用 | 2023 | 单步结构化调用 | GPT Function Calling | 用户触发每次调用 |
| Agent 规划 | 2024 | 多步任务分解与执行 | AutoGPT、MetaGPT、ReAct | 用户设定目标,Agent 自主执行 |
| 环境交互 | 2025 | 直接操控真实环境 | Claude Code、Manus、Operator | 用户只需审查最终结果 |
这条演进路线的核心趋势是人类参与度递减:从"每一步都要人来触发"到"设定目标后全程自动",人类的角色从"操作者"逐渐转变为"监督者"。与此同时,安全性和可控性成为越来越核心的设计约束——Agent 具备在真实环境中执行操作的能力后,误操作的代价也相应增大,因此确认机制、权限控制和操作审计变得不可或缺。
24.6.4 部署形态演进
从"黑箱 API"到"手机端运行"
大模型的部署形态决定了谁能使用它、在什么场景下使用、以及如何控制成本和隐私。2023 年至 2025 年间,部署形态经历了三个标志性阶段。
阶段一:闭源 API 主导(2023)
2023 年上半年,市场上性能最强的大模型(GPT-4、Claude、Gemini)全部以闭源 API 形式提供服务。开发者通过 HTTP 请求调用模型,按 token 计费,无法看到模型权重,也无法自行部署。这种模式的优势是使用门槛低、无需自建 GPU 集群,但缺点同样明显:
- 数据隐私风险:所有输入都发送到第三方服务器,对金融、医疗、政府等敏感领域来说难以接受。
- 成本不可控:高频调用场景下 token 计费迅速累积,一个日活百万的产品月度 API 账单可达数十万美元。
- 定制困难:无法针对特定领域微调,只能通过 few-shot 提示和 RAG 来适配业务需求。
阶段二:开源权重爆发(2024)
2023 年 7 月 Meta 发布 Llama 2 开启了开源大模型的大门,但真正的分水岭是 2024 年 7 月的 Llama 3.1。Llama 3.1 发布了 8B、70B 和 405B 三个版本,其中 405B 版本(约 820GB 权重)在 MMLU、HumanEval、MATH 等多项基准上与 GPT-4o 不相上下,首次实现了开源模型与最强闭源模型的性能对齐。
Llama 3.1 的技术要点包括:
- 训练数据:超过 15 万亿 token 预训练数据,数据混合比为 50% 常识知识、25% 数学与推理、17% 代码、8% 多语言。微调数据包括公开指令数据集和超过 2500 万个综合生成的示例。
- 后训练流程:采用 SFT + 拒绝采样(Rejection Sampling)+ DPO 三阶段对齐。这里的关键设计决策是使用 DPO 而非 RLHF 的 PPO 算法——因为 PPO 的训练稳定性不确定且制约 AI 集群规模扩展 Scaling Law。奖励模型(RM)的角色也不同于 ChatGPT:在 Llama 3.1 中,RM 用于对模型生成的多个回答进行质量排序并筛选最优作为 SFT 数据,而非像 PPO 流程那样直接参与在线 RL 训练。
- 蒸馏范式:405B 模型作为"教师"蒸馏出 70B 和 8B 版本,实现"先大后小"的能力迁移。这种方法比从头训练小模型更高效,因为大模型已经"学会"了如何回答,小模型只需模仿。
与此同时,Google 的 Gemma 系列和阿里的 Qwen 系列也在推动开源生态。以 Gemma 为例,它专门面向桌面和笔记本端运行设计,采用 Decoder-only Transformer 架构:
| 特征 | Gemma 2B | Gemma 7B |
|---|---|---|
| 参数量 | 约 25 亿 | 约 85 亿 |
| 隐藏维度 | 2048 | 3072 |
| 层数 | 18 | 28 |
| 注意力机制 | MQA(1 个 KV head) | MHA(16 个 KV head) |
| 激活函数 | GeGLU | GeGLU |
| 归一化 | RMS Norm(前后各一次) | RMS Norm(前后各一次) |
| 位置编码 | RoPE | RoPE |
| 词表大小 | 256,128 | 256,128 |
| 上下文长度 | 8192 token | 8192 token |
Gemma 7B 在 MMLU 上达到 64.3,超过 Llama 2 7B(45.3)和 13B(54.8),也超过 Mistral 7B(62.5)。但 Gemma 采用的是"开放模型"(Open Model)而非传统意义上的"开源"(Open Source)——免费获取权重但使用条款有限制,不遵循常规开源协议。这一微妙区别在整个开源大模型生态中普遍存在:Llama 系列同样有类似的使用条款限制。
到 2025 年,开源模型的阵营进一步壮大,并呈现出MoE 架构主导的趋势:
| 模型 | 发布方 | 总参数量 | 激活参数量 | 关键特征 |
|---|---|---|---|---|
| Qwen3 | 阿里 | 235B | 22B | 推理、代码、多语言全面对标 GPT-4o |
| DeepSeek-V3 | DeepSeek | 671B | 37B | 训练成本仅 557 万美元 |
| Llama 4 Scout | Meta | 109B | 17B | 1000 万+ token 上下文 |
| Llama 4 Maverick | Meta | 400B | 17B | 128 专家的大规模 MoE |
这些模型共同证明了一个趋势:开源模型在性能上已经不再是闭源模型的"低配替代品",而是在多个维度上实现了对齐甚至超越。
阶段三:端侧部署(2024-2025)
随着量化技术(INT4/INT8/GPTQ/AWQ)和专用硬件(Apple Neural Engine、Qualcomm Hexagon NPU)的成熟,大模型开始走向手机、PC 和 IoT 设备:
- Apple Intelligence(2024):在 iPhone/Mac 上本地运行约 3B 参数的模型,处理文本摘要、智能回复、图像理解等任务,隐私敏感数据不出设备。复杂请求则通过 Private Cloud Compute 路由到苹果自建的云端服务器。
- Gemma 2B / Phi-3-mini:专门设计用于在消费级硬件上运行的小模型,2B 参数配合 4-bit 量化后仅需约 1.5GB 内存,一台普通笔记本就能流畅推理。
- Qualcomm AI Hub / MediaTek APU:芯片厂商直接在 SoC 中集成 NPU 加速单元,将大模型推理速度提升数倍。
端侧部署的核心价值在于隐私和延迟:数据不离开设备,响应时间不受网络延迟影响,且推理的边际成本近乎为零(电量消耗忽略不计)。但端侧模型的参数量(通常 1B-7B)决定了其能力上限远低于云端大模型,因此 2025 年的主流方案是云-端协同:简单任务(文本摘要、格式转换、快速问答)在本地处理,复杂任务(长文档分析、代码生成、多步推理)上传到云端大模型。
下表总结了三种部署形态的核心差异:
| 维度 | 闭源 API | 开源权重 | 端侧部署 |
|---|---|---|---|
| 代表案例 | GPT-4o、Claude 3.5 | Llama 3、Qwen3、DeepSeek-V3 | Gemma 2B、Phi-3-mini |
| 参数规模 | 数千亿(不公开) | 8B-671B | 1B-7B |
| 使用门槛 | 最低(HTTP 调用) | 中等(需 GPU 服务器) | 较低(消费级设备) |
| 数据隐私 | 低(数据发送到第三方) | 高(自行部署) | 最高(数据不出设备) |
| 定制能力 | 受限(仅 few-shot/RAG) | 强(全参微调/LoRA) | 有限(量化约束) |
| 推理成本 | 按 token 计费 | 一次性硬件投入 | 近乎零边际成本 |
| 离线可用 | 否 | 是(本地部署后) | 是 |
24.6.5 四条主线的交汇与展望
上述四条范式演进路线并非彼此独立,而是在多个交汇点上相互增强,形成了一个立体的技术演进网络。
推理 + Agent:推理模型的 CoT 能力天然适配 Agent 场景。一个能深度推理的 Agent 可以在复杂任务中制定更合理的计划、预判工具调用的后果、发现并修正中间步骤的错误。2025 年的 Claude Code 和 OpenAI 的 Deep Research 已经展示了"推理 Agent"的初步形态——这些产品在解决复杂编程任务或深度调研任务时,会在内部展开长达数千 token 的推理过程,远超简单的指令跟随。
多模态 + Agent:当 Agent 具备视觉理解和生成能力后,其可操作的环境从"命令行 + API"扩展到"图形界面 + 物理世界"。Computer Use 类 Agent 通过"截取屏幕 -> 理解界面元素 -> 执行点击/输入操作"的循环,能够使用任何具有图形界面的软件,无需该软件提供 API。这极大地扩展了 Agent 的适用范围。
开源 + 端侧:开源权重是端侧部署的前提——只有拿到模型权重,才能进行量化压缩并部署到本地设备。Llama 3/Gemma/Qwen 系列同时发布了多种规模的模型,从 405B 的云端版本到 2B 的端侧版本,覆盖了完整的部署光谱。
推理 + 开源:DeepSeek-R1 的开源证明了推理模型不必是闭源专属。通过蒸馏技术,推理能力可以迁移到 14B 甚至 7B 的小模型中,使得端侧设备也具备一定的"深度思考"能力。
推理 + 多模态:2025 年出现的多模态推理模型(如支持图像输入的 o3)预示着下一个融合方向——模型不仅能对文本问题进行深度推理,还能对视觉信息进行逐步分析。例如,面对一张复杂的数学证明手写稿,模型可以先识别符号,再逐步验证每一步推导的正确性。
站在 2025 年的时间节点回望,大模型的范式演进呈现出一个清晰的趋势:模型能力的边界在持续扩展(从文本到多模态,从理解到生成,从对话到行动,从简单推理到深度思考),而使用门槛在持续降低(从闭源 API 到开源权重,从云端集群到手机端运行)。这两个方向的交汇,正在将大模型从"科技公司的核心资产"转变为"人人可用的基础设施"。
本节以"范式演进框架"的视角梳理了推理模型、多模态生成、工具调用和部署形态四条主线的技术脉络与典型案例。理解这些范式的核心差异与演进逻辑,有助于读者在面对快速变化的大模型领域时,把握技术发展的主旋律,而非迷失在层出不穷的模型名称和跑分数字中。