6.4 SWA(滑动窗口注意力)
标准自注意力是一种全局注意力机制——序列中的每个 token 都可以访问所有其他 token。这种全局视野赋予了模型强大的长距离建模能力,但代价同样巨大:KV 缓存的大小与上下文长度成正比,当序列长度从 4K 拉长到 32K 甚至 128K 时,KV 缓存会迅速吞噬 GPU 显存。滑动窗口注意力(Sliding Window Attention, SWA)提供了一种直接的解决思路:限制每个 token 的注意力范围为一个固定大小的局部窗口,从而将 KV 缓存从随上下文长度线性增长变为固定大小。SWA 最早由 Beltagy 等人在 2020 年的 Longformer 论文中提出,此后在 Mistral、Gemma 2/3 等主流模型中得到广泛应用,证明了局部注意力在实际大语言模型中的可行性。
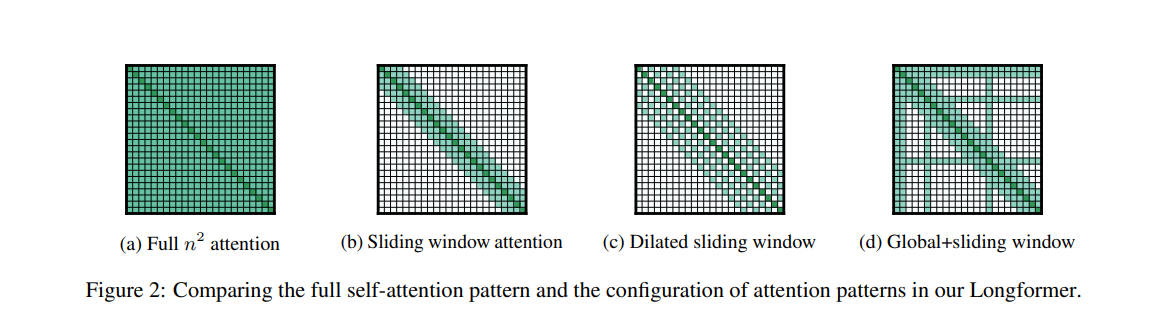
图 6-13:滑动窗口注意力(SWA)模式。每个 token 只关注固定大小窗口内的局部上下文,将 KV 缓存从线性增长变为固定大小。
6.4.1 局部窗口注意力的核心思想
在标准因果注意力中,位置
这一限制基于一个经验性假设:在自然语言中,大部分有意义的依赖关系都集中在局部上下文中。一个 token 的语义主要由其附近的词决定,真正需要跨越数千个 token 的远程依赖虽然存在,但频率较低。SWA 正是利用了这一统计特性——用有限的窗口覆盖绝大多数有效依赖,换取显著的内存节省。
从 KV 缓存的角度看,SWA 的效果非常直观:每一层只需缓存最近
6.4.2 SWA 掩码的实现
SWA 的核心在于构造正确的注意力掩码。在标准因果注意力中,掩码确保每个 query 只能关注它之前(含自身)的 key。SWA 在此基础上增加了一个下界约束:不仅要求 key 的位置不超过 query 的位置(因果性),还要求 key 的位置不低于 query 位置减去窗口大小(局部性)。
以下是一个简洁的 SWA 掩码构造方式:
import torch
def create_swa_mask(seq_len, window_size):
"""构造滑动窗口因果注意力掩码。
Args:
seq_len: 序列长度
window_size: 滑动窗口大小 W
Returns:
布尔掩码,True 表示该位置应被屏蔽(设为 -inf)
"""
q_pos = torch.arange(seq_len).unsqueeze(1) # (seq_len, 1)
k_pos = torch.arange(seq_len).unsqueeze(0) # (1, seq_len)
diff = q_pos - k_pos
# 屏蔽条件:key 在 query 之后(因果性)或距离超出窗口(局部性)
mask = (diff < 0) | (diff >= window_size)
return mask对于 seq_len=6, window_size=3,生成的掩码矩阵如下(0 表示可见,1 表示屏蔽):
k0 k1 k2 k3 k4 k5
q0 [ 0 1 1 1 1 1 ]
q1 [ 0 0 1 1 1 1 ]
q2 [ 0 0 0 1 1 1 ]
q3 [ 1 0 0 0 1 1 ]
q4 [ 1 1 0 0 0 1 ]
q5 [ 1 1 1 0 0 0 ]与标准因果掩码的关键差异在于左下角的 1:q3 无法看到 k0,q4 无法看到 k0 和 k1,以此类推。每个 query 最多只能看到最近 3 个位置的 key。
在实际的 Transformer 实现中,SWA 掩码通过 masked_fill_ 将被屏蔽位置的注意力分数设为
attn_scores = queries @ keys.transpose(-2, -1)
mask = create_swa_mask(num_tokens, window_size).to(queries.device)
attn_scores.masked_fill_(mask, -torch.inf)
attn_weights = torch.softmax(attn_scores / (head_dim ** 0.5), dim=-1)当结合 KV 缓存进行自回归生成时,实现需要更加精细:缓存中只保留最近
6.4.3 混合策略:局部与全局的平衡
纯 SWA 模型虽然内存高效,但完全放弃全局注意力会导致模型无法捕捉远距离依赖。例如,在长文档问答中,答案线索可能出现在数千个 token 之前;在代码生成中,函数调用可能引用文件开头的定义。因此,实际部署中通常采用混合策略——在模型的多个层中交替使用 SWA 和全局注意力。
Gemma 2 的 1:1 策略。 Gemma 2 使用 SWA 层与全局注意力层 1:1 交替排列,即每隔一层使用 SWA,另一层使用全局注意力。SWA 窗口大小为 4096 tokens。这种对称设计确保模型中有一半的层能够访问完整上下文,为远距离依赖提供了充分的建模通道。
Gemma 3 的 5:1 策略。 Gemma 3 将效率优化推向更激进的方向:每 5 层 SWA 之后才跟 1 层全局注意力,SWA 窗口大小进一步缩减至 1024 tokens。以 32 层模型为例,按 5:1 比例分配,会产生 27 层 SWA 和 5 层全局注意力。Gemma 3 技术报告中的消融实验表明,这种激进配置对模型质量的影响微乎其微——大量的建模工作可以在局部窗口中完成,少量全局层足以传递远程信息。
这一设计理念可以理解为一种信息分层传递机制:SWA 层负责精细的局部语义建模(如短语结构、句法关系),全局层则负责在更宏观的尺度上整合信息(如篇章结构、跨段落引用)。信息通过残差连接在层间传递,即使某一层只有局部视野,其输出中也间接包含了前序全局层聚合的远程信息。因此,全局层的数量不需要很多——它们更像是"信息中继站",而非每一层都需要的标配。
在实现层面,混合策略的分配逻辑十分简洁。给定 SWA:Full 比例
def assign_attention_type(layer_index, swa_count, full_count):
"""判断第 layer_index 层应使用 SWA 还是全局注意力。
Args:
layer_index: 层索引(从 0 开始)
swa_count: 比例中的 SWA 层数(如 5:1 中的 5)
full_count: 比例中的全局层数(如 5:1 中的 1)
Returns:
True 表示使用 SWA,False 表示使用全局注意力
"""
group_size = swa_count + full_count
position_in_group = layer_index % group_size
return position_in_group < swa_count对于 32 层模型、5:1 比例,层 0-4 使用 SWA,层 5 使用全局注意力,层 6-10 使用 SWA,层 11 使用全局注意力,以此类推。
图 6-14:全局注意力与滑动窗口注意力的混合模式。不同层使用不同的注意力范围,实现计算效率与长距离建模能力的平衡。
6.4.4 KV 缓存内存对比
SWA 对 KV 缓存的压缩效果可以精确量化。延续 §6.2 中的 KV 缓存公式:
SWA 层将公式中的
其中
以下使用一组典型的中大规模模型参数进行对比:
模型配置: emb_dim=4096,n_heads=32,n_layers=32,context_length=32768,batch_size=1,dtype=bf16(2 字节/元素),head_dim=128,sliding_window_size=1024,GQA 分组数
| 配置 | KV 头数 | SWA 层 / 全局层 | KV 缓存大小 | 相对 MHA 比例 |
|---|---|---|---|---|
| MHA(全局) | 32 | 0 / 32 | 17.18 GB | 1.00x |
| GQA(全局) | 8 | 0 / 32 | 4.29 GB | 0.25x |
| MHA + SWA(5:1) | 32 | 27 / 5 | 3.14 GB | 0.18x |
| GQA + SWA(5:1) | 8 | 27 / 5 | 0.78 GB | 0.05x |
表 6-5:不同注意力配置下的 KV 缓存内存对比(emb_dim=4096, n_heads=32, n_layers=32, context_length=32768, sliding_window_size=1024, bf16)。
几个关键观察:
SWA 的压缩效果与 GQA 正交且可叠加。 MHA 的 17.18 GB 经过 SWA(5:1)降至 3.14 GB,经过 GQA(4 分组)降至 4.29 GB。两者叠加后仅 0.78 GB——不到原始 MHA 的 5%。这正是 Gemma 3 同时使用 GQA 和 SWA 的原因。
SWA 的压缩比随上下文长度增大而更加显著。 窗口大小
是固定的,因此 随着 增大而减小。在 32K 上下文下 SWA 层的缓存是全局层的 ;若上下文扩展到 128K,则变为 。这意味着 SWA 在长上下文场景中的收益远高于短上下文场景。 5:1 比例使全局层的 KV 缓存开销被大量 SWA 层"稀释"。 32 层中只有 5 层需要存储完整的 32K 序列,其余 27 层只需存储 1K 窗口。全局层虽然单层开销大,但数量少,因此对总量的贡献被有效控制。
6.4.5 KV 缓存计算推导
以 GQA + SWA(5:1)配置为例,展开具体的计算过程。
SWA 层的单层 KV 缓存(
全局层的单层 KV 缓存(
总 KV 缓存:
对比纯 MHA 的 17.18 GB,压缩率约为 95.4%。
6.4.6 SWA 的局限性与工程权衡
SWA 并非没有代价。以下是需要注意的几个方面:
窗口外信息的间接传递依赖层数。 虽然单层只能看到
个 token,但经过 层残差连接后,信息理论上可以传播 个 token 的距离。然而,这种间接传递的信息会随着层数增加而衰减,远不如直接注意力那样精确。对于需要精确远程引用的任务(如长文档中的精确事实回溯),纯 SWA 可能不足。 窗口大小的选择需要权衡。 窗口越小,内存节省越大,但局部上下文越受限。Gemma 3 选择 1024 tokens 的窗口——这大约覆盖 2-3 个自然段落,对于大多数局部语义理解任务已经足够。但对于代码补全等需要较长局部上下文的场景,可能需要更大的窗口。
混合比例的选择依赖任务分布。 5:1 比例在 Gemma 3 的通用评测中表现优异,但对于特别依赖长距离依赖的任务(如长文档摘要),可能需要更高比例的全局层。这是一个经验性的超参数,需要通过消融实验确定。
图 6-15:全局注意力与局部注意力模式对比。全局注意力覆盖全部上下文,滑动窗口仅覆盖局部,混合架构交替使用两种模式以兼顾效率和长距离依赖。
本节小结
本节介绍了滑动窗口注意力(SWA)的原理、实现与工程应用:
- 核心思想: 每个 token 仅关注固定大小的局部窗口(如 1024 tokens),将 KV 缓存从随序列长度线性增长变为固定大小,压缩比为
。 - 掩码实现: SWA 掩码在因果掩码的基础上增加窗口下界约束,通过
(diff < 0) | (diff >= W)同时编码因果性和局部性。 - 混合策略: 实际模型中 SWA 与全局注意力层交替使用。Gemma 2 采用 1:1 比例(窗口 4096),Gemma 3 采用更激进的 5:1 比例(窗口 1024),消融实验表明对模型质量影响极小。
- 与 GQA 叠加: SWA 和 GQA 的压缩效果正交,两者组合可将 KV 缓存从 17.18 GB 压缩至 0.78 GB(95.4% 的压缩率),这正是 Gemma 3 的实际配置。
- 设计理念: 少量全局层充当"信息中继站",大量 SWA 层负责高效的局部建模,信息通过残差连接在层间传递,以极低的内存代价实现接近全局注意力的建模能力。