8.4 DeepSeek 架构创新(仅架构层面)
前两节分别从通用视角梳理了 MoE 架构的演进史(8.1 节)和长上下文技术栈(8.3 节)。本节将焦点收窄到一个具体的模型族——DeepSeek 系列,以架构设计为唯一切入角度,系统解析它在注意力机制、MoE 路由策略和多 token 预测三个维度上的原创贡献。这些创新并非零散的技巧堆砌,而是遵循一条清晰的主线:在保持甚至提升模型表达能力的前提下,极限压缩推理阶段的访存瓶颈和通信开销。
我们将从 DeepSeek-V2 首次亮相的 Multi-Head Latent Attention(MLA)出发,完整推导其低秩压缩、矩阵吸收与解耦 RoPE 三阶段设计;然后进入 DeepSeek-V3 的 671B MoE 架构,分析 Sigmoid 路由、序列级负载均衡和 Multi-Token Prediction(MTP)的联合设计;最后讨论 FlashMLA 和 DeepEP 两项配套系统优化的架构动机。
8.4.1 [必读] MLA:多头潜在注意力的完整推导
Multi-Head Latent Attention(MLA)是 DeepSeek-V2 的核心架构创新,也是 DeepSeek-V3 继续沿用的注意力机制。它的设计动机只有一个:在不损失模型表达能力的前提下,将 KV Cache 压缩到极限。
问题背景:KV Cache 的访存瓶颈
在标准多头注意力(MHA)中,设模型隐层维度为
MQA(Multi-Query Attention)让全部头共享一对 KV,缓存降至
MLA 的出发点是:放弃结构化约束,改用一般性的线性低秩压缩,在同等缓存开销下获得更强的表达能力。
数学基础:低秩近似的最优性
MLA 的第一个理论依据是矩阵的低秩近似。从数学角度看,GQA 本质上是一种特殊的、结构化的低秩近似——同组内的 KV 被强制置为相等。如果放宽这种结构化约束,采用一般的线性变换,能在同等参数/缓存量下提供更优的表达能力。
根据奇异值分解(SVD)和 Eckart-Young-Mirsky 定理,对于任意矩阵
基于此定理,MLA 引入了隐状态(Latent vector)
Phase 1:低秩联合压缩
MLA 不再直接生成高维的多头 KV,而是将输入
其中
其中
此时的矛盾:如果推理时需要从
这一矛盾的解决,依赖于 MLA 最精妙的代数技巧——矩阵吸收。
Phase 2:矩阵吸收(核心恒等变换)
考虑第
将
注意到
在推理阶段,可以离线预计算
此时 Attention Score 变为:
同理处理 Value 聚合:第
阶段性结论:通过矩阵吸收,推理时只需缓存
Phase 3:解耦 RoPE
上述恒等变换在引入旋转位置编码(RoPE)时会失效。RoPE 是依赖于绝对位置
问题:位置相关的动态矩阵
MLA 的解决方案是解耦策略:将 Query 和 Key 拆分为"内容部分"和"位置部分",分别处理。
新增一个专用于承载 RoPE 的维度
Query 的组成:
- 内容部分:
(从 Query 压缩隐变量 生成,不含 RoPE) - 位置部分:
(所有头共享,带有 RoPE)
Key 的组成:
- 内容部分:
(不含 RoPE) - 位置部分:
(所有头共享,带有 RoPE)
执行点积后,Attention Score 自然分解为两项:
- 内容项完全不包含 RoPE,遵循 Phase 2 的矩阵吸收,推理时只需缓存
。 - 位置项包含 RoPE,但
在所有头之间共享,只需额外缓存一个 维向量。
最终的 KV Cache:每个 token 仅需缓存
缩放因子的修正:由于 Query 和 Key 是内容部分与位置部分的拼接,Attention Score 的缩放因子相应调整为
Query 的低秩压缩(训练优化)
为减少训练时的激活值显存占用,MLA 对 Query 也进行了类似的低秩处理。引入 Query 压缩隐变量
各头的 Query 内容部分通过升维矩阵恢复:
MLA 的数值效果
以 DeepSeek-V2 的参数配置为例:
| 参数 | 值 |
|---|---|
| 隐藏层维度 | 5120 |
| 注意力头数 | 128 |
| 每头维度 | 128 |
| KV 压缩维度 | 512 |
| RoPE 维度 | 64 |
| 方案 | 每 token 缓存量 | 压缩比 |
|---|---|---|
| 标准 MHA | 1x | |
| GQA(8 组) | 16x | |
| MQA | 128x | |
| MLA | 57x |
表 8-6:不同注意力机制的 KV Cache 对比。MLA 的压缩比介于 GQA 与 MQA 之间,但消融实验表明 MLA 的模型性能甚至优于 MHA——同时获得了高压缩比和强表达能力。
训练 vs 推理的计算模式差异:训练阶段不执行矩阵吸收,显式计算出所有的
8.4.2 DeepSeek-V2 的 MoE 设计:细粒度专家首次规模化
DeepSeek-V2(236B 总参数 / 21B 激活参数)在注意力层使用 MLA,在 FFN 层使用 DeepSeekMoE。其 MoE 配置为 2 个共享专家 + 160 个路由专家,每次激活 6 个路由专家。
共享专家 + 细粒度专家的规模化验证。 DeepSeek-V2 是 DeepSeek MoE V1 所提出的"共享专家 + 细粒度切分"范式首次在百亿参数级别得到验证的模型。消融实验表明:(1) 提取共享专家后路由专家的专精度显著提升——禁用同比例最高权重专家时 DeepSeekMoE 的性能下降比 GShard 更剧烈,说明专家之间的知识冗余更低;(2) 从 16 专家选 2 到 64 专家选 8(保持总参数和激活参数不变),模型在多个基准上持续提升。
设备感知路由。 V2 面临的新挑战是:160 个路由专家分布在大量 GPU 上,一个 token 被路由到的 6 个专家可能分散在多个设备上,导致 All-to-All 通信开销急剧增加。V2 引入 Top-M 设备路由——先计算各设备上所有专家分数的汇总,选出总分最高的
通信均衡损失。 除了专家负载均衡,V2 还引入了设备间的通信均衡损失
这一损失项鼓励模型将 token 和路由权重均匀分布到不同设备上,不仅平衡计算负载,还平衡设备间的数据传输量——这是超大规模 MoE 训练中容易被忽视但至关重要的工程约束。
8.4.3 DeepSeek-V3:671B MoE 的全面升级
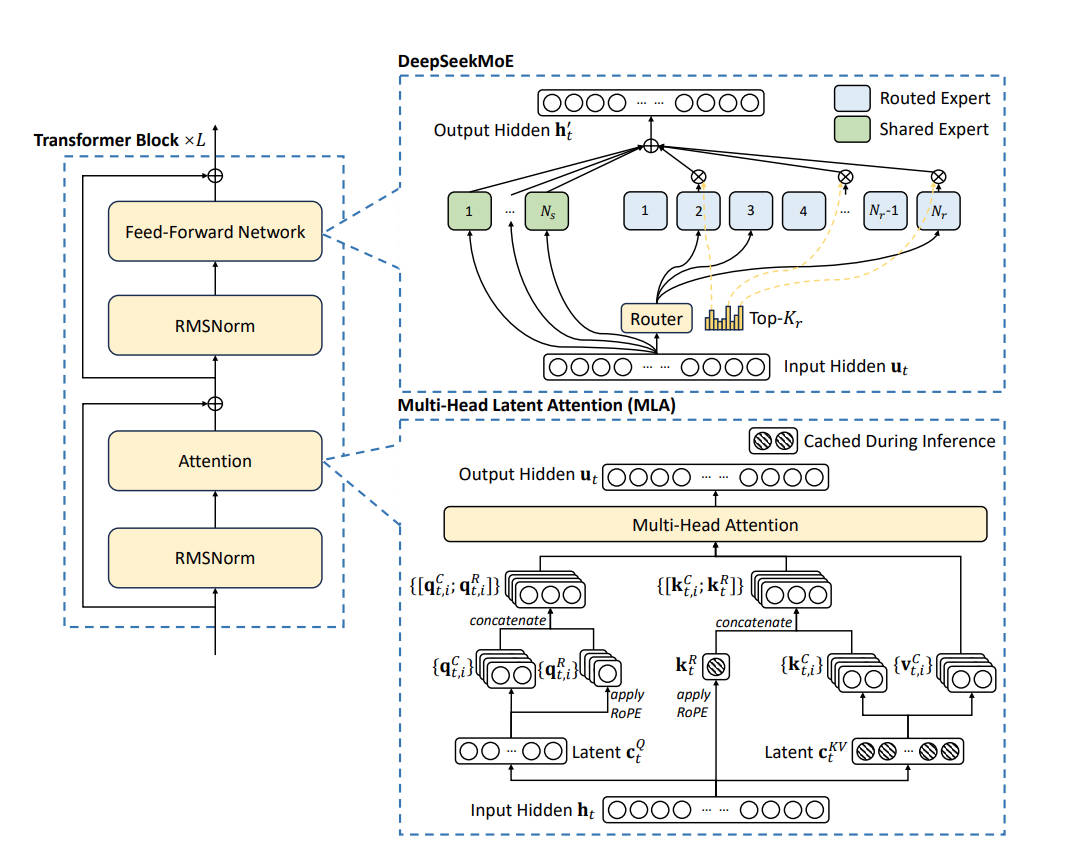
图 8-9:DeepSeek V3 整体架构。左侧为 Transformer Block 的堆叠结构(RMSNorm + Attention + FFN),右上为 DeepSeekMoE 层(共享专家
DeepSeek-V3(671B 总参数 / 37B 激活参数)在 V2 的基础上进行了四项关键架构改进:Sigmoid 路由、序列级负载均衡损失、Loss-Free 负载均衡和 Multi-Token Prediction。注意力层继续沿用 MLA,参数规模扩大但核心机制不变。
Sigmoid 路由替代 Softmax
V2 的路由层使用 Softmax 将专家分数归一化为概率分布,然后取 Top-k。V3 将其改为 Sigmoid:
Top-k 选出后再对被选中的
这一改动的理论依据来自 MoE 的几何直观(8.1.2 节):路由器输出的物理意义是专家的"模长"而非"概率"。Softmax 的归一化约束迫使专家之间零和竞争——一个专家的分数上升必然伴随其他专家的下降,这种零和博弈容易导致"赢家通吃"式的路由塌缩。Sigmoid 将每个专家的分数独立映射到
V3 的完整 MoE 前向流程:
- 输入
经过共享专家 (所有 token 强制通过),得到基础输出 ; - 路由器计算各路由专家的分数:
, ; - 选出分数最大的 8 个专家位置,对选中的分数做归一化得到门控值
; - 8 个被选中的路由专家分别计算,输出按
加权求和得到 ; - 最终输出
(含残差连接)。
序列级负载均衡损失
V3 在 Loss-Free 偏置项(8.1.3 节已详述)的基础上,新增了一个轻量级的序列级辅助损失。其形式与传统的 batch 级辅助损失完全相同:
区别在于
动机:Loss-Free 的偏置项在 batch 级别调整,足以保证跨序列的全局均衡。但在实际部署中,如果某一时刻大量用户同时提问某一类话题(如数学推理),同一序列内部可能出现极端的路由偏斜——某几个擅长数学的专家被该序列中的所有 token 集中调用。序列级辅助损失以极小的权重(不干扰主任务)兜底这种局部异常,增强推理时的鲁棒性。
8.4.4 [选读] Multi-Token Prediction(MTP)
Multi-Token Prediction 是 DeepSeek-V3 在架构层面最具特色的创新之一。它的目标是:在训练时为骨干网络提供更丰富的监督信号,在推理时提供推测解码的加速能力。
传统 MTP 的架构
在 DeepSeek-V3 之前,多 token 预测的典型实现方式(如 Meta 的研究)是:将骨干网络最后一层 Transformer Block 提出,作为预测下一个 token 的主头;额外增加若干预测头,每个头包含一个独立的 Transformer Block 和一个分类头,分别从第
这种设计的问题在于:跨多步的预测头看不到自己前面几个 token 的信息。例如第 4 个预测头需要在不知道前 3 个未来 token 的情况下直接预测第 4 个 token,难度极大,不利于训练收敛。
DeepSeek 的改进:级联信息传递
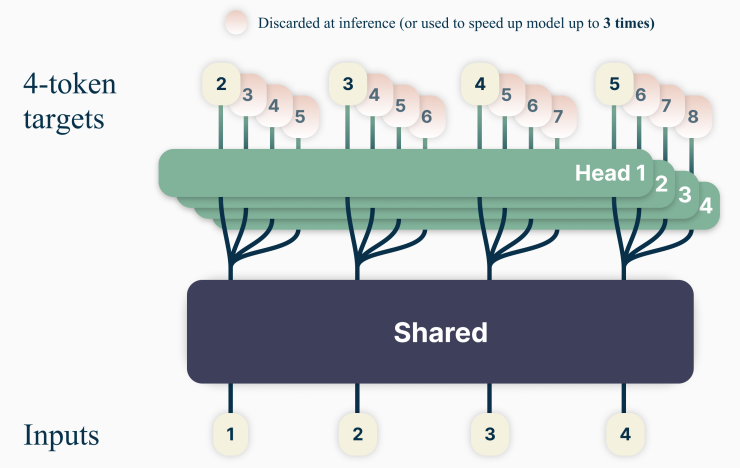
图 8-2:DeepSeek MTP 架构。主模型(左侧)预测
DeepSeek-V3 对 MTP 架构做了关键改进——为每个预测头注入"前序 token"的信息:
- 主模型:
层 Transformer Block,输出第 层隐状态 ,经分类头预测 。 - MTP 头
( )的输入由两部分构成: - 来自上一级的隐状态(主模型或前一个 MTP 头的输出),提供"能预测
的语义特征"; 本身的 Embedding,提供"前序 token 的身份信息"(训练时已知所有 token)。
- 来自上一级的隐状态(主模型或前一个 MTP 头的输出),提供"能预测
- 两部分分别做 RMSNorm 后逐 token 拼接(特征维度翻倍),经线性层映射回原始维度,再通过一个 Transformer Block 和共享分类头预测
。
损失函数:每个 MTP 头贡献一个交叉熵损失,所有 MTP 头的损失取平均后乘以权重
DeepSeek-V3 使用
MTP 的推理加速:推测解码
MTP 在推理时可作为推测解码(Speculative Decoding)的草稿模型使用。其流程为:
- 并行预测:给定输入序列,主头和
个 MTP 头并行输出 个候选 token。主头输出最可信,后续头的可信度递减。 - 批量验证:将
个不确定的候选 token 构造成一个 batch,让主头逐个验证。由于 GPU 擅长并行计算,这一步的耗时近似于单次生成。 - 接受最长正确序列:从主头验证结果中找到最长的连续匹配前缀。若 MTP 头预测的某个 token 错误,则采用主头在该位置给出的修正结果。
加速效果与局限性:在理想情况下,一轮"预测 + 验证"可以生成
8.4.5 DualPipe:流水线并行的通信隐藏
DeepSeek-V3 在训练系统层面提出了 DualPipe 流水线并行策略。虽然这严格来说属于系统优化而非模型架构,但它的设计动机与 MoE 架构的通信特性紧密耦合,因此简要介绍其架构关联。
MoE 模型的训练面临一个特殊挑战:All-to-All 通信。在专家并行中,每个 token 需要被路由到可能分布在不同设备上的专家,这要求在前向和反向传播中各执行一次 All-to-All 通信。传统流水线并行中,气泡(Pipeline Bubble)已经是效率损失的主要来源;MoE 的 All-to-All 通信进一步加剧了这一问题。
DualPipe 的核心思想是:将流水线的前向和反向微批次(microbatch)交错调度,使得一个微批次的计算阶段恰好与另一个微批次的通信阶段重叠。具体而言,它将每个 Transformer 层的计算拆分为注意力阶段(计算密集、无跨设备通信)和 MoE 阶段(计算密集 + All-to-All 通信),然后在两个微批次之间交错执行这两个阶段,使得通信被计算完全掩盖。这种设计使 DeepSeek-V3 在 2048 个 H800 GPU 上训练时,流水线气泡率控制在极低水平。
8.4.6 FlashMLA 与 DeepEP:配套系统优化的架构动机
MLA 和 MoE 架构的创新在算法层面已经完备,但如果底层算子和通信库不做相应优化,理论上的效率提升无法兑现为实际的推理加速。DeepSeek 团队开源了两个配套组件:FlashMLA 和 DeepEP。
FlashMLA
FlashMLA 是专门为 MLA 设计的 GPU kernel,其架构动机源于 MLA 推理时的独特计算模式。
经过矩阵吸收后,MLA 在推理阶段退化为等效的 MQA——所有头共享一份缓存
FlashMLA 的核心优化包括:(1) 针对 MLA 的非对称 Q/K/V 维度重新设计分块大小和 SRAM 布局;(2) 利用 MLA 推理时所有头共享 KV Cache 的特性,在块加载调度上消除冗余的 KV 读取;(3) 与 PagedAttention 结合,支持变长序列的高效批处理。
DeepEP
DeepEP(Deep Expert Parallelism)是专门为 MoE 模型设计的 All-to-All 通信库。其架构动机在于:DeepSeek-V3 拥有 256 个路由专家分布在多个节点上,每个 token 激活 8 个专家,每次前向传播都需要执行大规模的 token-to-expert 路由通信。标准的 NCCL All-to-All 操作在这种"高扇出、小消息"的通信模式下效率不佳。
DeepEP 通过以下策略优化 MoE 通信:(1) 将 All-to-All 操作分解为节点内和节点间两阶段,利用 NVLink 的高带宽处理节点内通信;(2) 支持计算与通信的流水线重叠,配合 DualPipe 的交错调度;(3) 针对推理场景提供低延迟模式,利用 RDMA 减少小消息的通信延迟。
FlashMLA 和 DeepEP 的共同启示:架构创新与系统优化必须协同设计。MLA 的矩阵吸收使推理退化为等效 MQA,但如果没有 FlashMLA 针对非标准维度的 kernel 优化,吞吐量提升会打折扣。MoE 的细粒度专家和 Sigmoid 路由使路由模式更灵活,但如果没有 DeepEP 对高扇出通信的专项优化,大规模部署会遭遇通信瓶颈。架构设计者必须在提出算法创新的同时,考虑其对底层计算和通信模式的影响——这也是 DeepSeek 团队的核心竞争力之一。
8.4.7 本节总结
DeepSeek 系列的架构创新可以从三个维度来理解:
| 维度 | DeepSeek-V2 | DeepSeek-V3 | 核心收益 |
|---|---|---|---|
| 注意力 | MLA 首次亮相:低秩压缩 + 矩阵吸收 + 解耦 RoPE | 沿用 MLA,扩大参数规模 | KV Cache 压缩约 57 倍,性能不降反升 |
| MoE | 共享 + 细粒度首次百亿级验证;设备感知路由 | Sigmoid 路由;Loss-Free + 序列级辅助损失 | 路由组合多样性 |
| 预测策略 | 标准 next-token prediction | Multi-Token Prediction(级联信息传递) | 训练信号增强,推理可选推测解码 |
表 8-7:DeepSeek 架构创新的三维度对比。
这些创新的内在逻辑一脉相承:MLA 通过低秩压缩和矩阵吸收将注意力层的访存瓶颈压缩到极限;细粒度 MoE 通过组合爆炸和 Sigmoid 路由最大化稀疏化的表达效率;MTP 通过级联信息传递为训练提供更密集的梯度信号。三者共同指向同一个目标——在固定的硬件预算下,榨取最大的模型能力。
从更宏观的视角看,DeepSeek 的架构哲学可以概括为"算法-系统协同设计":每一项算法创新(MLA、MoE 细粒度路由、MTP)都伴随着配套的系统优化(FlashMLA、DeepEP、DualPipe)。这种端到端的设计方法论,而非某一项单独的技术突破,才是 DeepSeek-V3 能够以 557 万美元训练成本达到 GPT-4o 级别性能的根本原因。
延伸阅读。 DeepSeek-R1 的强化学习训练方案(如何从 V3 基座模型出发训练推理能力)将在第 18 章详细展开;DeepSeek 的多模态扩展(Janus 系列)将在第 23 章讨论。