7.3 Gemma 3:高效混合注意力
前两节分别实现了 Llama 和 Qwen3,它们的注意力层在整个模型中采用统一的策略——要么全部是全局注意力(Full Attention),要么全部是分组查询注意力(GQA)。这种"一刀切"的设计虽然简洁,但在效率上存在浪费:并非每一层都需要关注完整的上下文历史,大量中间层的注意力权重高度集中在局部窗口内。Google 在 Gemma 3 中给出了一个极具工程启发性的回答:在同一个模型中混合使用滑动窗口注意力(SWA)和全局注意力,且以 5:1 的极端比例偏向局部注意力。这一设计使得仅有 270M 参数的轻量模型也能在推理效率和生成质量之间取得出色的平衡。
本节将以 Gemma 3 270M 为对象,剖析其混合注意力策略的设计理念,分析消融实验结果,并给出完整的 PyTorch 实现。
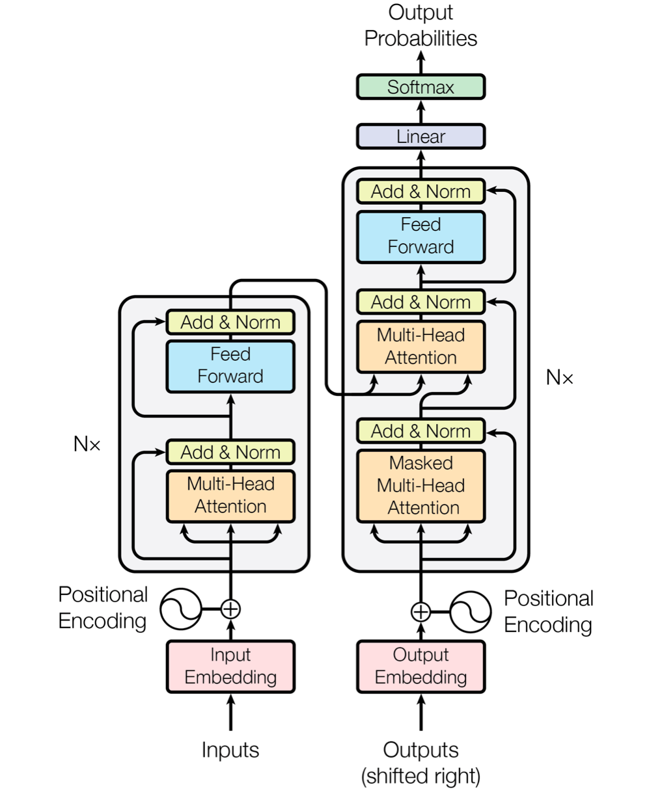
图 7-10:Gemma 3 270M 模型架构。以 5:1 的比例混合使用滑动窗口注意力和全局注意力,在效率和长距离建模间取得平衡。
7.3.1 架构总览:270M 参数的精巧布局
Gemma 3 270M 的完整配置如下:
| 超参数 | 值 | 说明 |
|---|---|---|
vocab_size | 262,144 | 词表大小(256K) |
emb_dim | 640 | 嵌入维度 |
n_layers | 18 | Transformer 层数 |
n_heads | 4 | 查询头数 |
n_kv_groups | 1 | KV 头数(即 Multi-Query Attention) |
head_dim | 256 | 每头维度(独立于 emb_dim / n_heads) |
hidden_dim | 2048 | FFN 中间维度 |
sliding_window | 512 | 滑动窗口大小 |
context_length | 32,768 | 最大上下文长度 |
rope_base | 1,000,000 | 全局注意力层的 RoPE 基频 |
rope_local_base | 10,000 | 滑动窗口层的 RoPE 基频 |
qk_norm | True | 启用 QK 归一化 |
query_pre_attn_scalar | 256 | 注意力缩放因子(替代默认的 |
表 7-3:Gemma 3 270M 模型配置。
几个值得关注的设计选择:
独立的 head_dim。 多数模型令 head_dim = emb_dim / n_heads,Gemma 3 则将 head_dim 设为独立超参数 256,远大于 emb_dim / n_heads = 160。这意味着查询投影的输出维度为
Multi-Query Attention(MQA)。 n_kv_groups = 1 表示所有 4 个查询头共享同一组 Key 和 Value,这是 GQA 的极端情况。MQA 将 KV 缓存压缩至最小,对于一个 270M 的轻量模型而言,这是合理的效率优先选择。
双 RoPE 基频。 滑动窗口层使用标准基频
权重绑定(Weight Tying)。 输入嵌入矩阵与输出投影头共享权重。对于词表大小为 262,144、嵌入维度为 640 的模型,嵌入矩阵占
7.3.2 5:1 混合注意力策略
Gemma 3 的 18 层 Transformer 按以下模式排列注意力类型:
层 0: sliding_attention
层 1: sliding_attention
层 2: sliding_attention
层 3: sliding_attention
层 4: sliding_attention
层 5: full_attention ← 每 6 层插入一个全局注意力
层 6: sliding_attention
层 7: sliding_attention
层 8: sliding_attention
层 9: sliding_attention
层 10: sliding_attention
层 11: full_attention
层 12: sliding_attention
层 13: sliding_attention
层 14: sliding_attention
层 15: sliding_attention
层 16: sliding_attention
层 17: full_attention18 层中有 15 层滑动窗口、3 层全局注意力,比例为 5:1。配合窗口大小仅 512 的激进设定,这意味着模型在绝大多数层中只关注当前 token 前后 512 个位置的局部上下文。
为什么 5:1 而不是 1:1? 这一比例背后的核心直觉是:大部分语言理解任务依赖局部上下文,只有少数场景需要全局信息。一个句子的语法结构、搭配关系、实体指代,绑定在几百个 token 的局部窗口内就能捕获。真正需要跨越数千 token 的远程依赖(如文档级主题跟踪、跨段落推理)相对稀少,用少量全局注意力层处理即可。Gemma 3 的消融实验(见 7.3.3 节)证实了这一直觉:将比例从 1:1 提高到 5:1,模型质量几乎不受影响,但推理效率大幅提升。
效率增益的来源。 滑动窗口注意力的计算复杂度为
相比 18 层全局注意力的
KV 缓存的节省同样显著。 滑动窗口层的 KV 缓存只需保留最近 512 个 token 的 Key/Value,而非完整序列。在 MQA(
7.3.3 消融实验分析
Gemma 3 技术报告中的消融实验揭示了两个关键发现:
发现一:5:1 混合对质量的影响极小。 在固定模型规模和训练数据的条件下,将全局注意力层的比例从 50%(1:1)降低到约 17%(5:1),模型在下游任务上的性能下降幅度可忽略不计。这说明绝大多数层学到的注意力模式本质上是局部的——即使给予全局视野,这些层的注意力权重也高度集中在局部窗口内。既然如此,不如直接限制其注意力范围,换取确定性的效率提升。
发现二:窗口大小可以激进地缩小。 Gemma 3 将滑动窗口从常见的 4096 缩小到 512,质量损失同样很小。这一发现更加激进:它意味着局部注意力层真正"有效"的感受野远小于通常假设。512 个 token 大约对应一个中等长度的段落,足以覆盖大部分局部依赖。
这两个消融结果共同指向一个结论:注意力资源的最优分配是高度不均匀的。与其让所有层以相同的方式处理全局上下文,不如将有限的"全局注意力预算"集中到少数几个关键层上,让其余层以极低成本处理局部模式。
7.3.4 TransformerBlock:按层类型分发掩码
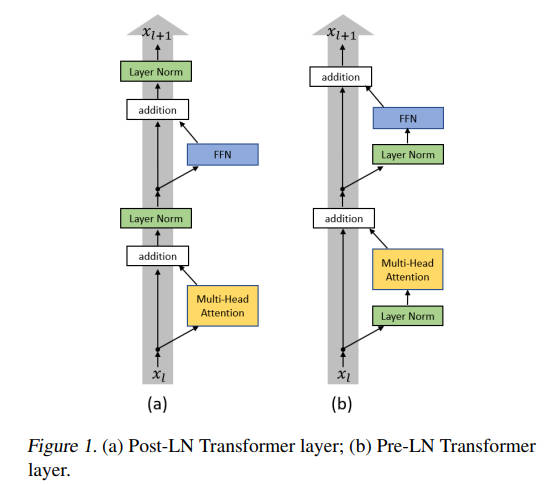
图 7-11:Pre-Norm 与 Post-Norm 归一化方案的对比。Gemma 3 采用 Pre-Norm + Post-Norm 的"三明治归一化",在注意力和 FFN 的输入输出端各放置一个 RMSNorm。
Gemma 3 的 TransformerBlock 需要根据自身的注意力类型选择不同的掩码和 RoPE 参数。以下是核心实现:
import torch
import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, cfg, attn_type):
super().__init__()
self.attn_type = attn_type # "sliding_attention" 或 "full_attention"
self.att = GroupedQueryAttention(
d_in=cfg["emb_dim"],
num_heads=cfg["n_heads"],
num_kv_groups=cfg["n_kv_groups"],
head_dim=cfg["head_dim"],
qk_norm=cfg["qk_norm"],
query_pre_attn_scalar=cfg["query_pre_attn_scalar"],
dtype=cfg["dtype"],
)
self.ff = FeedForward(cfg)
# Gemma 3 使用 4 个 RMSNorm:注意力前后各一个,FFN 前后各一个
self.input_layernorm = RMSNorm(cfg["emb_dim"])
self.post_attention_layernorm = RMSNorm(cfg["emb_dim"])
self.pre_feedforward_layernorm = RMSNorm(cfg["emb_dim"])
self.post_feedforward_layernorm = RMSNorm(cfg["emb_dim"])
def forward(self, x, mask_global, mask_local,
cos_global, sin_global, cos_local, sin_local):
# 根据注意力类型选择掩码和 RoPE
if self.attn_type == "sliding_attention":
mask, cos, sin = mask_local, cos_local, sin_local
else:
mask, cos, sin = mask_global, cos_global, sin_global
# Pre-Norm + Attention + Post-Norm + Residual
shortcut = x
x = self.input_layernorm(x)
x = self.att(x, mask, cos, sin)
x = self.post_attention_layernorm(x)
x = shortcut + x
# Pre-Norm + FFN + Post-Norm + Residual
shortcut = x
x = self.pre_feedforward_layernorm(x)
x = self.ff(x)
x = self.post_feedforward_layernorm(x)
x = shortcut + x
return x掩码分发逻辑。 模型在前向传播之前统一构造两种掩码——mask_global(标准因果掩码)和 mask_local(因果掩码 + 窗口限制),然后传入每一层。每层根据自己的 attn_type 选择对应的掩码和 RoPE 参数。这种设计避免了在每层内部重复构造掩码的开销。
四重 RMSNorm。 与 Llama(2 个 RMSNorm/层)不同,Gemma 3 在注意力和 FFN 的输出端各增加了一个 Post-Norm。这种 Pre-Norm + Post-Norm 的"三明治归一化"有助于稳定深层网络的训练,尤其是在使用较大 head_dim 和较小 emb_dim 的不对称配置下。
7.3.5 掩码构造:全局与局部
两种掩码的构造逻辑如下:
def create_masks(seq_len, sliding_window, device):
ones = torch.ones(seq_len, seq_len, dtype=torch.bool, device=device)
# 全局掩码:标准上三角因果掩码(j > i 的位置为 True)
mask_global = torch.triu(ones, diagonal=1)
# 远距离掩码:距离超过窗口大小的位置为 True(i - j >= sliding_window)
far_past = torch.triu(ones, diagonal=sliding_window).T
# 局部掩码 = 因果掩码 OR 远距离掩码
mask_local = mask_global | far_past
return mask_global, mask_local以 seq_len=8、sliding_window=4 为例,两种掩码的可视化(0 表示可见,1 表示被遮蔽):
mask_global: mask_local:
j: 0 1 2 3 4 5 6 7 j: 0 1 2 3 4 5 6 7
i i
0: 0 1 1 1 1 1 1 1 0: 0 1 1 1 1 1 1 1
1: 0 0 1 1 1 1 1 1 1: 0 0 1 1 1 1 1 1
2: 0 0 0 1 1 1 1 1 2: 0 0 0 1 1 1 1 1
3: 0 0 0 0 1 1 1 1 3: 0 0 0 0 1 1 1 1
4: 0 0 0 0 0 1 1 1 4: 1 0 0 0 0 1 1 1 ← 位置 0 超出窗口
5: 0 0 0 0 0 0 1 1 5: 1 1 0 0 0 0 1 1
6: 0 0 0 0 0 0 0 1 6: 1 1 1 0 0 0 0 1
7: 0 0 0 0 0 0 0 0 7: 1 1 1 1 0 0 0 0mask_local 在 mask_global 的基础上,将距离超过窗口大小的历史位置也遮蔽掉,形成一个沿对角线移动的"可见带"。
7.3.6 零偏心 RMSNorm 与嵌入缩放
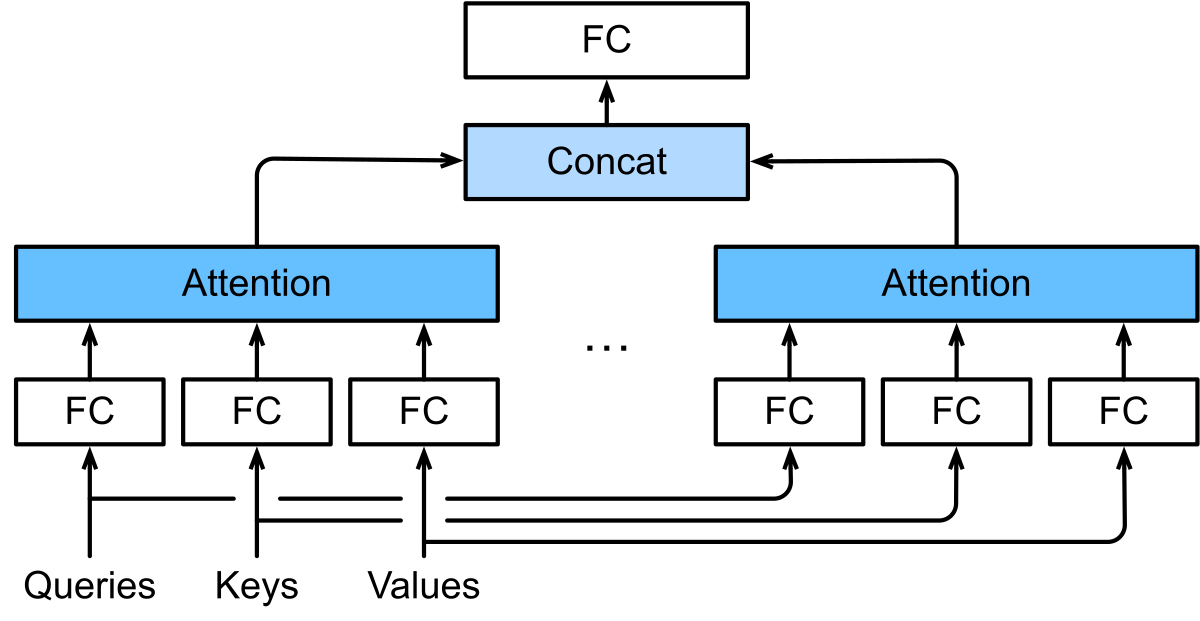
图 7-12:多头注意力的并行计算过程。输入分别投影为多组 Q/K/V,各头独立计算注意力后拼接输出。Gemma 3 使用 MQA(所有头共享一组 KV)进一步压缩缓存。
Gemma 3 的 RMSNorm 采用零中心参数化:权重初始化为零向量,前向传播时使用
class RMSNorm(nn.Module):
def __init__(self, emb_dim, eps=1e-6):
super().__init__()
self.eps = eps
self.scale = nn.Parameter(torch.zeros(emb_dim)) # 初始化为 0,非 1
def forward(self, x):
x_f = x.float()
var = x_f.pow(2).mean(dim=-1, keepdim=True)
x_norm = x_f * torch.rsqrt(var + self.eps)
return (x_norm * (1.0 + self.scale.float())).to(x.dtype)标准 RMSNorm 将权重初始化为全 1,前向传播时直接乘以
此外,Gemma 3 在嵌入层之后乘以
这一缩放补偿了嵌入向量在高维空间中范数偏小的问题(随机初始化的嵌入向量各分量量级约为
7.3.7 注意力缩放因子 query_pre_attn_scalar
标准注意力使用 query_pre_attn_scalar,值为 256(恰好等于 head_dim)。缩放因子计算为:
这与标准公式
7.3.8 GeGLU 前馈网络
Gemma 3 的 FFN 使用 GELU 激活的门控变体(GeGLU),而非 Llama 系列常用的 SwiGLU:
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.fc1 = nn.Linear(cfg["emb_dim"], cfg["hidden_dim"], bias=False) # gate
self.fc2 = nn.Linear(cfg["emb_dim"], cfg["hidden_dim"], bias=False) # up
self.fc3 = nn.Linear(cfg["hidden_dim"], cfg["emb_dim"], bias=False) # down
def forward(self, x):
return self.fc3(
nn.functional.gelu(self.fc1(x), approximate="tanh") * self.fc2(x)
)GeGLU 与 SwiGLU 的唯一区别在于激活函数:前者使用
7.3.9 完整模型与推理性能
将所有组件组装为完整的 Gemma3Model:
class Gemma3Model(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"])
# 按 layer_types 列表创建不同类型的 TransformerBlock
self.blocks = nn.ModuleList([
TransformerBlock(cfg, attn_type)
for attn_type in cfg["layer_types"]
])
self.final_norm = RMSNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False, dtype=cfg["dtype"])
self.cfg = cfg
# 预计算两套 RoPE 参数
cos_local, sin_local = compute_rope(cfg["head_dim"], cfg["rope_local_base"], cfg["context_length"])
cos_global, sin_global = compute_rope(cfg["head_dim"], cfg["rope_base"], cfg["context_length"])
self.register_buffer("cos_local", cos_local)
self.register_buffer("sin_local", sin_local)
self.register_buffer("cos_global", cos_global)
self.register_buffer("sin_global", sin_global)
def forward(self, input_ids):
b, seq_len = input_ids.shape
# 嵌入 + 缩放
x = self.tok_emb(input_ids) * (self.cfg["emb_dim"] ** 0.5)
# 统一构造两种掩码
mask_global, mask_local = create_masks(seq_len, self.cfg["sliding_window"], x.device)
for block in self.blocks:
x = block(x, mask_global, mask_local,
self.cos_global, self.sin_global,
self.cos_local, self.sin_local)
x = self.final_norm(x)
return self.out_head(x)layer_types 驱动的异构堆叠。 模型的层类型由配置中的 layer_types 列表显式指定,而非通过 if layer_idx % 6 == 5 之类的硬编码规则推断。这种设计使得混合比例可以灵活调整——只需修改配置列表,无需改动模型代码。
推理性能基准。 下表展示了 Gemma 3 270M 在不同硬件和优化配置下的生成速度:
| 硬件 | 模式 | 吞吐量(tokens/sec) | 显存占用 |
|---|---|---|---|
| Nvidia A100 GPU | 基础 | 28 | 1.84 GB |
| Nvidia A100 GPU | + torch.compile | 128 | 2.12 GB |
| Nvidia A100 GPU | + KV 缓存 | 26 | 1.77 GB |
| Nvidia A100 GPU | + KV 缓存 + torch.compile | 99 | 2.12 GB |
| Mac Mini M4 CPU | 基础 | 8 | — |
| Mac Mini M4 CPU | + KV 缓存 | 130 | — |
| Mac Mini M4 CPU | + KV 缓存 + torch.compile | 224 | — |
表 7-4:Gemma 3 270M 推理性能基准。
几个值得注意的现象:
torch.compile在 GPU 上效果显著:从 28 提升到 128 tokens/sec,加速比约 4.6x。torch.compile通过算子融合和内存优化大幅减少了 Python 解释器和 CUDA kernel launch 的开销,对小模型尤其有效。- KV 缓存在 GPU 上反而不加速:从 28 降至 26 tokens/sec。这是因为 270M 模型本身很小,KV 缓存的额外索引和拼接操作引入的开销抵消了减少重计算的收益。KV 缓存的优势在长序列和大模型场景下才能显现。
- CPU 上 KV 缓存效果突出:从 8 提升到 130 tokens/sec。CPU 的计算能力远弱于 GPU,减少重复计算带来的收益相对更大。
7.3.10 设计理念总结:Gemma 3 做对了什么
Gemma 3 的架构设计体现了一种"预算分配"思维——将有限的计算和参数预算分配到最需要的地方:
- 注意力预算不均匀分配。 5:1 的 SWA:Full 混合让 83% 的层以极低成本处理局部模式,只让 17% 的层承担全局信息整合的任务。消融实验证明这一分配接近最优。
- 窗口大小激进缩小。 512 的滑动窗口远小于常见的 4096,但质量损失可忽略不计。这说明"有效感受野"远小于"理论感受野",多余的注意力范围是浪费。
- 头维度独立于嵌入维度。 通过将 head_dim 设为 256(大于 emb_dim/n_heads = 160),在不增加整体模型宽度的情况下增强了每个注意力头的表达能力。
- 工程友好的异构设计。
layer_types列表、双 RoPE 基频、可配置的注意力缩放因子——这些设计使混合注意力策略的调整成为纯配置变更,无需修改模型代码。
这些选择共同使得一个仅 270M 参数的模型能够在 A100 上以 128 tokens/sec 的速度生成文本(配合 torch.compile),同时保持与更大模型可比的生成质量。对于资源受限的部署场景(边缘设备、移动端、教学实验),这种"用架构设计换计算效率"的思路具有很强的实用价值。
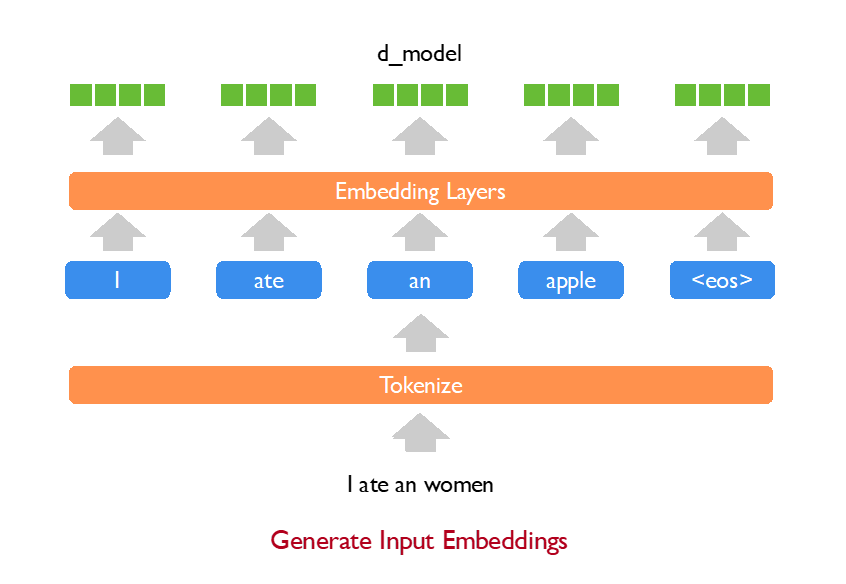
图 7-13:Gemma 3 的混合注意力策略。每 6 层中仅 1 层使用全局注意力,其余 5 层使用滑动窗口注意力,大幅减少 KV 缓存内存。
本节小结
本节以 Gemma 3 270M 为案例,剖析了混合注意力架构的设计与实现:
- 混合注意力策略:18 层中 15 层使用滑动窗口注意力(窗口 512)、3 层使用全局注意力,比例 5:1。消融实验表明这一比例对模型质量的影响可忽略不计,但节省了超过 80% 的注意力计算量和大部分 KV 缓存。
- 架构特色:独立 head_dim(256)、Multi-Query Attention、双 RoPE 基频(局部 10K / 全局 1M)、四重 RMSNorm(Pre+Post 三明治归一化)、零中心参数化、嵌入缩放、GeGLU FFN、权重绑定。
- 掩码设计:全局掩码为标准因果掩码,局部掩码在因果掩码基础上叠加窗口限制。两种掩码统一预计算,每层按类型选用。
- 推理性能:270M 参数 +
torch.compile在 A100 上达到 128 tokens/sec,显存仅占 2.12 GB。KV 缓存在 CPU 场景下收益更大(8 → 130 tokens/sec)。 - 核心启示:注意力资源的最优分配是高度不均匀的。大部分层的有效感受野远小于全局范围,将全局注意力预算集中到少数关键层是一种高性价比的架构设计策略。