14.1 黑盒蒸馏
在上一章讨论了对齐的基本概念后,我们将视角转向一种在大模型时代极为流行的能力迁移技术——知识蒸馏(Knowledge Distillation, KD)。所谓"黑盒蒸馏",指的是学生模型(Student Model)仅利用教师模型(Teacher Model)的最终输出(即生成的文本序列)进行学习,而不需要访问教师模型的内部权重、中间层激活值或 logits 概率分布。在实际操作中,黑盒蒸馏的本质就是:用一个强大的教师模型生成高质量的训练数据,然后用这些数据对学生模型进行监督微调(Supervised Fine-Tuning, SFT)。
这种方法之所以被称为"黑盒",是因为教师模型完全可以是一个闭源 API(如 GPT-4、Claude),我们只需要它的输入-输出对即可,无需知道模型内部的任何信息。与之相对的"白盒蒸馏"则需要同时获取教师模型的 logits 或中间表示,我们将在下一节讨论。
14.1.1 知识蒸馏的三重角色
在大语言模型(LLM)时代,知识蒸馏不再仅仅是传统意义上的"模型压缩"工具。它承担着三个关键角色:
- 能力增强(Advance):从闭源大模型(如 GPT-4)中提取知识,增强开源模型的能力。这是黑盒蒸馏最典型的应用场景——将闭源模型的推理能力"蒸馏"到开源模型中。
- 模型压缩(Compress):将大模型的知识迁移到参数量更小的模型中,在保持性能的同时降低部署成本。例如从 671B 参数的 DeepSeek-R1 蒸馏到 7B 的学生模型。
- 自我改进(Self-Improvement):模型利用自身生成的数据进行迭代训练,实现能力的持续提升。这是一种新兴的"自蒸馏"趋势。
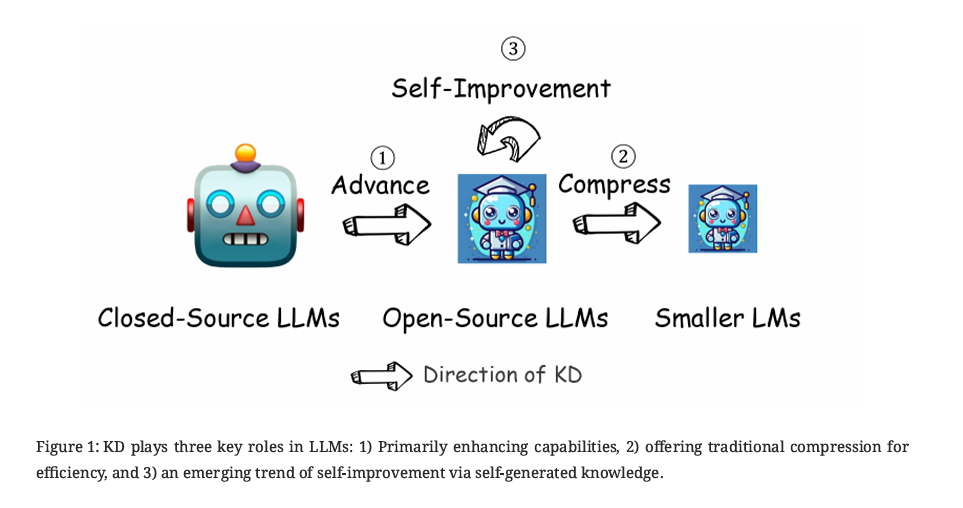
图 14-1:知识蒸馏在大模型时代的三重角色——能力增强、模型压缩与自我改进。
14.1.2 黑盒蒸馏的通用流程
黑盒蒸馏的完整流程可以分为四个阶段,构成一条清晰的"数据驱动"管线:
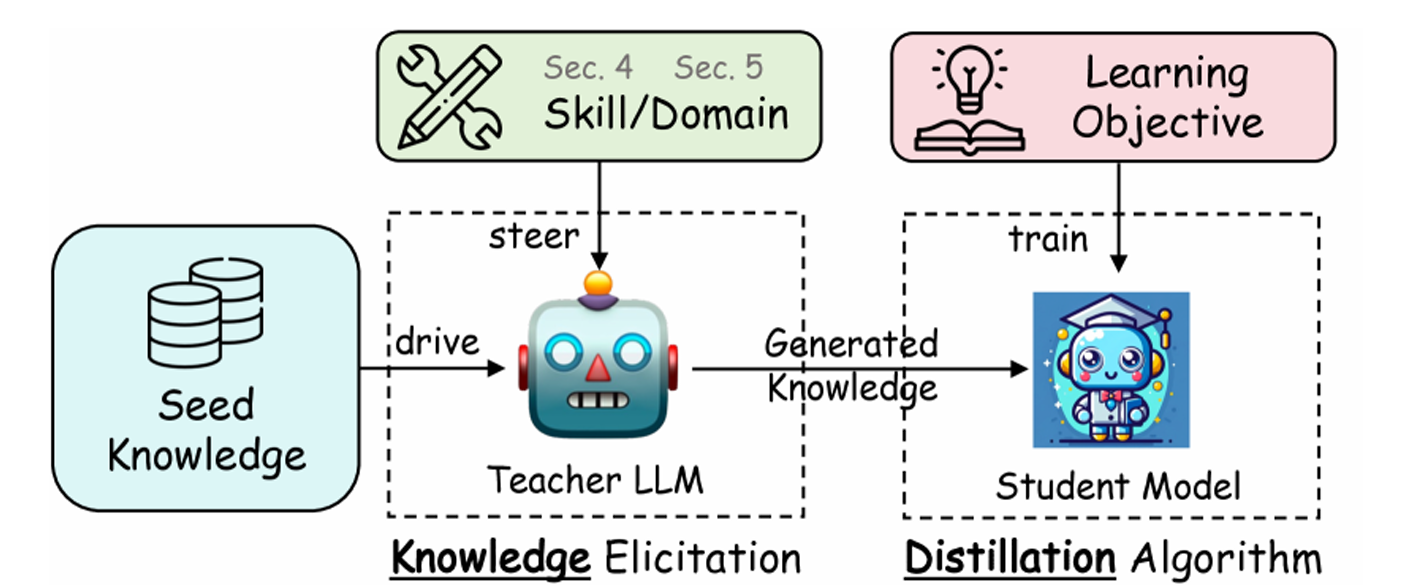
图 14-2:LLM 蒸馏的通用四阶段流程——从目标引导到学生训练。
第一阶段:目标技能引导。 确定希望学生模型学习的目标技能或领域。例如,我们可以将蒸馏目标聚焦在数学推理、代码生成或医学问答等特定能力上。这一步决定了后续数据的生成方向。
第二阶段:种子知识注入。 准备一批小规模的输入数据集(种子数据),包含与目标领域相关的问题或提示。例如,对于数学推理蒸馏,种子数据就是一组数学题目。种子数据为教师模型提供生成的起点。
第三阶段:蒸馏数据生成。 这是黑盒蒸馏的核心步骤。教师模型在种子数据的引导下,生成大量高质量的问答对。这些输出不仅包含最终答案,还可能包含推理链条(Chain of Thought, CoT)——即详细的思考过程。教师模型将自身的隐性推理能力外化为显性文本数据。
第四阶段:学生模型训练。 生成的蒸馏数据被用作 SFT 训练语料,学生模型通过标准的自回归交叉熵损失进行训练,学习教师模型的输出模式。
一句话总结黑盒蒸馏的核心思想:数据质量决定一切。 在高质量数据的支撑下,即使只使用最简单的 SFT 训练方法,也能实现显著的能力迁移。
14.1.3 蒸馏数据的生成实践
蒸馏数据的生成是整个流程中最关键的环节。根据教师模型的部署方式,主要有两种数据生成路径:本地生成和 API 调用生成。
本地生成(以 Ollama 为例)。 如果教师模型足够小(如 DeepSeek-R1 的 8B/32B 蒸馏版),可以在本地运行推理并生成蒸馏数据。以下是一个使用 OpenAI 兼容 API 格式调用本地模型生成蒸馏数据的 Python 脚本示例:
import json
import urllib.request
def query_local_model(prompt, model="deepseek-r1:8b", base_url="http://localhost:11434"):
"""调用本地 Ollama 服务生成教师输出"""
url = f"{base_url}/api/chat"
payload = {
"model": model,
"messages": [{"role": "user", "content": prompt}],
"stream": False
}
data = json.dumps(payload).encode("utf-8")
req = urllib.request.Request(url, data=data, headers={"Content-Type": "application/json"})
with urllib.request.urlopen(req, timeout=120) as resp:
result = json.loads(resp.read().decode("utf-8"))
msg = result["message"]
return msg.get("thinking", ""), msg.get("content", "")
def generate_distillation_data(problems, model="deepseek-r1:8b", out_file="distill_data.json"):
"""批量生成蒸馏数据集"""
results = []
for i, item in enumerate(problems):
prompt = f"Please solve the following math problem step by step.\n\n{item['problem']}"
thinking, content = query_local_model(prompt, model=model)
results.append({
"problem": item["problem"],
"gtruth_answer": item["answer"],
"message_thinking": thinking, # 教师的思考过程
"message_content": content # 教师的最终回答
})
# 增量保存,支持中断恢复
with open(out_file, "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print(f"[{i+1}/{len(problems)}] done")
return resultsAPI 调用生成(以 OpenRouter 为例)。 对于无法本地运行的超大模型(如 671B 参数的 DeepSeek-R1),可以通过云端 API 生成蒸馏数据。以下是使用 OpenAI 兼容接口调用远程模型的示例:
import json
import urllib.request
import os
def query_api_model(prompt, model="deepseek/deepseek-r1"):
"""通过 OpenRouter API 调用远程教师模型"""
api_key = os.environ.get("OPENROUTER_API_KEY")
if not api_key:
raise ValueError("请设置 OPENROUTER_API_KEY 环境变量")
# 构造 OpenAI 兼容格式的请求体
url = "https://openrouter.ai/api/v1/chat/completions"
payload = {
"model": model,
"messages": [{"role": "user", "content": prompt}]
}
data = json.dumps(payload).encode("utf-8")
req = urllib.request.Request(url, data=data, headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
})
# 发送请求并解析返回的思考过程与最终回答
with urllib.request.urlopen(req, timeout=120) as resp:
result = json.loads(resp.read().decode("utf-8"))
choice = result["choices"][0]["message"]
return choice.get("reasoning_content", ""), choice.get("content", "")蒸馏数据的格式。 无论使用哪种生成方式,最终产出的数据格式通常如下:
{
"problem": "求解方程 2x + 3 = 7",
"gtruth_answer": "2",
"message_thinking": "要求解 2x + 3 = 7,首先两边减 3 得到 2x = 4,再两边除以 2 ...",
"message_content": "解:2x + 3 = 7,解得 x = 2。答案是 \\boxed{2}。"
}其中 message_thinking 字段存储教师模型的思维链,message_content 存储最终答案。在训练时,可以将二者拼接为完整的推理序列:
# 示意代码
complete_answer = f"<think>{data['message_thinking']}</think>\n\n{data['message_content']}"成本估算。 以 DeepSeek-R1(671B)通过 OpenRouter API 生成为例:平均输入约 11 token、平均输出约 1524 token,生成 1000 条数学题答案的成本约 $3.82(输入 $0.70/百万 token,输出 $2.50/百万 token)。生成 12000 条数据约需 $46,使用 50 个并行进程可将时间从约 100 小时压缩到约 2 小时。
14.1.4 数据质量控制:拒绝采样
原始生成的蒸馏数据中不可避免地会包含错误答案和低质量样本。拒绝采样(Rejection Sampling) 是提升数据质量的关键手段——对教师模型的输出进行严格筛选,只保留高质量样本。
DeepSeek-R1 在蒸馏数据生成中就大量使用了拒绝采样,其筛选标准包括:
- 正确性验证:对比教师输出与标准答案,只保留答案正确的样本
- 格式过滤:剔除语言混杂(如中英混合)、包含过长代码块、格式混乱的思维链
- 长度控制:过滤掉极短(无信息量)或极长(冗余啰嗦)的回答
- 可读性检查:确保思维链逻辑清晰、有教学价值
以下是一个简化的拒绝采样实现:
import re
def extract_boxed_answer(text):
"""从 LaTeX 格式的回答中提取 \\boxed{} 内的答案"""
match = re.search(r"\\boxed\{([^}]+)\}", text)
return match.group(1).strip() if match else None
def rejection_sampling(raw_data, max_thinking_tokens=4096):
"""对蒸馏数据进行拒绝采样,只保留高质量样本"""
filtered = []
for item in raw_data:
# 1. 正确性验证
predicted = extract_boxed_answer(item["message_content"])
if predicted is None or predicted != item["gtruth_answer"]:
continue
# 2. 思维链长度控制
thinking = item.get("message_thinking", "")
if len(thinking.split()) > max_thinking_tokens:
continue
# 3. 语言一致性检查(示例:过滤中英混杂)
# \u4e00-\u9fff 为 Unicode 中文字符范围,用于统计中文字符数
cn_chars = len(re.findall(r"[\u4e00-\u9fff]", thinking))
en_chars = len(re.findall(r"[a-zA-Z]", thinking))
if cn_chars > 0 and en_chars > 0:
ratio = min(cn_chars, en_chars) / max(cn_chars, en_chars)
if ratio > 0.3: # 混合度过高则跳过
continue
filtered.append(item)
print(f"拒绝采样:{len(raw_data)} -> {len(filtered)} (保留率 {len(filtered)/len(raw_data)*100:.1f}%)")
return filteredDeepSeek-R1 最终用于蒸馏的教师数据集总计约 800k 样本,其中约 600k 是推理相关数据,约 200k 是通用非推理数据(写作、问答等)。经过严格的拒绝采样,这些数据的质量足以支撑仅使用 SFT 就实现显著的能力迁移。
14.1.5 基于蒸馏数据的 SFT 训练
获得高质量的蒸馏数据后,下一步就是用它来训练学生模型。黑盒蒸馏中的训练方法与标准的 SFT 完全一致——学生模型通过最大化教师生成序列的似然度来学习。
训练数据的构造。 在 SFT 中,需要将蒸馏数据转换为"提示-回答"格式,并构建合适的 loss mask,确保模型只在回答部分计算损失,不学习提示部分:
import torch
from torch.utils.data import Dataset
class DistillationDataset(Dataset):
"""将蒸馏数据转换为 SFT 训练格式"""
def __init__(self, data, tokenizer, max_seq_len=2048, use_think_tokens=True):
self.tokenizer = tokenizer
self.max_seq_len = max_seq_len
self.samples = []
for item in data:
# 构建完整的训练文本
prompt = f"Please solve the following math problem step by step.\n\n{item['problem']}"
if use_think_tokens and item.get("message_thinking"):
answer = f"<think>{item['message_thinking']}</think>\n\n{item['message_content']}"
else:
answer = item["message_content"]
# 分别编码提示和回答,用于构建 loss mask
prompt_ids = tokenizer.encode(prompt, add_special_tokens=True)
answer_ids = tokenizer.encode(answer, add_special_tokens=False)
eos_id = [tokenizer.eos_token_id]
input_ids = prompt_ids + answer_ids + eos_id
if len(input_ids) > max_seq_len:
continue # 过滤超长样本
# loss mask: 只在回答部分计算损失
loss_mask = [0] * len(prompt_ids) + [1] * (len(answer_ids) + 1)
self.samples.append((input_ids, loss_mask))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
input_ids, loss_mask = self.samples[idx]
x = torch.tensor(input_ids[:-1], dtype=torch.long)
y = torch.tensor(input_ids[1:], dtype=torch.long)
mask = torch.tensor(loss_mask[1:], dtype=torch.float)
return x, y, mask训练循环。 以下是一个完整的 SFT 训练循环实现:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from transformers import AutoModelForCausalLM, AutoTokenizer
def train_distillation(model_name, train_data, epochs=3, lr=1e-5, max_seq_len=2048):
"""使用蒸馏数据对学生模型进行 SFT 训练"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
model = model.cuda()
dataset = DistillationDataset(train_data, tokenizer, max_seq_len=max_seq_len)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=0.01)
model.train()
for epoch in range(epochs):
total_loss = 0.0
for i, (x, y, mask) in enumerate(dataset):
x, y, mask = x.cuda().unsqueeze(0), y.cuda().unsqueeze(0), mask.cuda().unsqueeze(0)
logits = model(x).logits # [1, seq_len, vocab_size]
# 带 mask 的交叉熵损失:只计算回答部分
loss_per_token = F.cross_entropy(
logits.view(-1, logits.size(-1)),
y.view(-1),
reduction="none"
).view(y.size())
loss = (loss_per_token * mask).sum() / mask.sum()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item()
if (i + 1) % 100 == 0:
print(f"Epoch {epoch+1}, Step {i+1}, Loss: {total_loss/(i+1):.4f}")
print(f"Epoch {epoch+1} 完成, 平均 Loss: {total_loss/len(dataset):.4f}")
# 保存检查点
torch.save(model.state_dict(), f"distill_epoch{epoch+1}.pth")
return model上述代码的核心要点包括:
- Loss Mask 机制:只在教师回答部分计算交叉熵损失,提示部分的损失权重为 0。这确保模型学习"如何回答",而不是学习"如何提问"
- 梯度裁剪:
clip_grad_norm_防止梯度爆炸,这在微调预训练模型时尤为重要 - 学习率选择:蒸馏 SFT 通常使用较小的学习率(如
),避免破坏预训练的基础能力
14.1.6 DeepSeek-R1 蒸馏实践:从 671B 到 7B
DeepSeek-R1 的蒸馏实践是黑盒蒸馏最具代表性的工业案例。它清晰地展示了一个核心观点:在高质量数据的支撑下,仅使用简单的 SFT 就能实现惊人的能力迁移。
蒸馏流程。 DeepSeek-R1 的教师模型是一个 671B 参数的 MoE 模型,经过大规模强化学习训练后具备了强大的推理能力。蒸馏的关键步骤是:
- 使用 RL 收敛后的 DeepSeek-R1 作为教师,通过拒绝采样生成约 800k 条高质量推理数据
- 对 Qwen 和 Llama 系列的小型密集模型(1.5B 至 70B)进行 SFT
- 不使用额外的强化学习阶段——纯 SFT 即可
蒸馏效果。 下表展示了 DeepSeek-R1 蒸馏模型在多个推理基准上的表现:
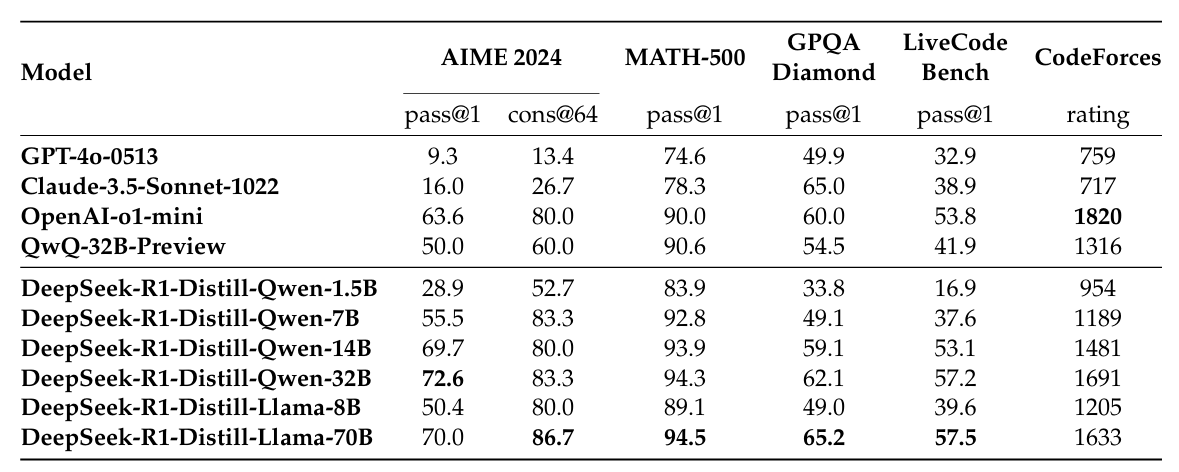
表 14-1:DeepSeek-R1 蒸馏模型与同级别模型在推理基准上的对比。7B 蒸馏模型在多项指标上超越 GPT-4o,14B 模型显著超越 QwQ-32B-Preview。
结果显示,DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024(pass@1: 55.5%)和 MATH-500(pass@1: 92.8%)上的表现全面超越了 GPT-4o-0513(AIME: 9.3%, MATH-500: 74.6%)。这个 7B 的小模型通过蒸馏获得的数学推理能力,远超一个百倍参数量的通用模型。
蒸馏 vs. 纯 RL 训练。 一个更令人瞩目的对比是:同样是 32B 参数的 Qwen 模型,蒸馏路线(DeepSeek-R1-Distill-Qwen-32B)在所有推理基准上都显著优于纯 RL 训练路线(DeepSeek-R1-Zero-Qwen-32B)。

表 14-2:蒸馏模型 vs. 纯 RL 训练模型。在相同参数量下,蒸馏策略在所有基准上大幅领先。
蒸馏模型在 AIME 2024 上取得 72.6%(pass@1),而纯 RL 模型仅有 47.0%;在 MATH-500 上分别是 94.3% vs. 91.6%。这说明从高质量教师数据中学习,比让模型自己通过 RL 摸索更加高效。
14.1.7 自蒸馏:模型的自我进化
DeepSeek-R1 的蒸馏流程中还蕴含着一种更深层的机制——自知识蒸馏(Self-Knowledge Distillation)。在 DeepSeek-R1 的训练流程中,模型在强化学习阶段收敛后,以自身(RL 收敛检查点)作为教师,生成并精炼推理轨迹,再用这些高质量数据微调自身参数。这本质上是一个"自我教学-自我学习"的闭环。
自蒸馏的价值体现在三个方面:
- 修复 RL 缺陷:纯 RL 训练的模型(如 DeepSeek-R1-Zero)存在可读性差、语言混杂等问题。通过生成格式规范的数据再 SFT,可以有效修复这些缺陷
- 增强通用能力:在蒸馏数据中加入约 200k 条通用数据(写作、问答等),使模型在获得推理能力的同时不丧失通用性
- 知识迁移基础:自蒸馏产出的 800k 数据集,同时也是后续蒸馏小模型(Qwen-7B、Llama-8B 等)的教师数据集
这种从"压缩"到"自我进化"的转变,代表了知识蒸馏在大模型时代的新方向。
14.1.8 Qwen 蒸馏数据实践
除了 DeepSeek 之外,Qwen 系列模型也广泛使用了蒸馏技术。以下实验数据展示了不同教师模型蒸馏 Qwen3-0.6B 的效果对比:
| 实验设置 | 教师模型 | 训练轮数 | MATH-500 准确率 | 验证集损失 |
|---|---|---|---|---|
| 基线(Base) | 无 | - | 15.2% | - |
| 基线(Reasoning) | 无 | - | 48.2% | - |
| DeepSeek-R1 蒸馏 | DeepSeek-R1 (671B) | 1 | 30.6% | 0.5436 |
| DeepSeek-R1 蒸馏 | DeepSeek-R1 (671B) | 3 | 33.6% | 0.5343 |
| Qwen3-235B 蒸馏 | Qwen3-235B-A22B | 1 | 45.0% | 0.4043 |
| Qwen3-235B 蒸馏 | Qwen3-235B-A22B | 3 | 44.2% | 0.3948 |
表 14-3:不同教师模型蒸馏 Qwen3-0.6B 在 MATH-500 上的效果。
几个关键观察:
- 教师模型的选择至关重要:同样是蒸馏 Qwen3-0.6B,使用 Qwen3-235B 作为教师(同家族模型)的效果(45.0%)远优于使用 DeepSeek-R1 作为教师的效果(30.6%)。这可能是因为同家族模型的 tokenizer 和内部表示更加兼容
- 更多训练轮数并非总是更好:Qwen3-235B 蒸馏在第 1 轮就达到了 45.0% 的峰值,第 3 轮反而略有下降(44.2%),说明在小规模数据上可能存在过拟合风险
- 蒸馏效果显著:即使是一个仅 0.6B 参数的微型模型,经过蒸馏后在数学推理上也能从 15.2% 提升到 45.0%,接近其自带推理模式(48.2%)的水平
14.1.9 黑盒蒸馏的局限性与未来方向
黑盒蒸馏虽然简单高效,但也存在明显的局限性:
信息损失。 黑盒蒸馏只利用了教师模型的最终输出文本,丢失了 logits 分布中包含的丰富"暗知识"(Dark Knowledge)——即各个候选 token 之间的概率关系。例如,教师模型对"答案是 42"的 logit 为 8.5,对"答案是 43"的 logit 为 7.2,这种"近似正确"的信息在黑盒蒸馏中完全丢失了。
教师能力上限。 学生模型的性能受限于教师模型的输出质量。如果教师模型在某些问题上也会犯错,那么蒸馏数据中就会包含错误信息,而学生模型难以区分哪些是正确的、哪些是错误的。
数据效率。 相比白盒蒸馏(每个 token 位置都能获得完整的概率分布作为监督信号),黑盒蒸馏的信号密度较低,通常需要更多的训练数据才能达到同样的效果。
针对这些局限性,社区正在探索几个方向:将黑盒蒸馏与强化学习结合(如 DPO),利用教师偏好信号而非单纯输出进行训练;多教师蒸馏,综合多个教师模型的输出以提高数据多样性和鲁棒性;以及自蒸馏的迭代化,让模型通过多轮"生成-筛选-训练"循环持续进化。
本节小结。 黑盒蒸馏的核心理念极为朴素:让强大的教师模型生成高质量数据,然后用这些数据训练学生模型。这种方法的成功关键不在于算法的复杂性,而在于数据质量——特别是通过拒绝采样进行严格的数据筛选。DeepSeek-R1 的实践有力地证明了,在高质量蒸馏数据的支撑下,仅使用最基础的 SFT 训练就能让 7B 参数的小模型在数学推理上超越 GPT-4o。下一节我们将转向白盒蒸馏,讨论如何利用教师模型的内部信息(logits 分布)实现更精细的知识迁移。