4.1 分词算法
在第三章中,我们构建了 Transformer 架构的核心组件——自注意力机制、前馈网络、层归一化等。然而,所有这些模块都假设输入已经是整数序列(token ID),并通过嵌入层映射为连续向量。那么,原始文本究竟是如何变成这些整数的?这正是分词(Tokenization) 要解决的问题。
分词是大语言模型的"第零层"——它不可训练、不可微分,却直接决定了模型能看到什么、怎么看。正如 Andrej Karpathy 所言,分词器是"语言模型中唯一一个用 C++/Rust 实现的层"。一个差的分词方案会让模型在还没开始学习之前就丢失关键信息。本节将从最朴素的分词思路出发,逐步推进到现代大语言模型普遍采用的子词分词算法,并给出 BPE 的从零实现。
4.1.1 从字符到子词:分词粒度的演进
分词的本质是在两个矛盾的目标之间寻找平衡:词汇表大小和序列长度。词汇表越大,每个 token 承载的信息越多,序列越短;但词汇表过大会增加 softmax 层的计算负担,且大量低频 token 难以获得充分训练。反之,词汇表越小,序列越长,自注意力的
词级分词(Word-based)。 最直觉的方案是按空格和标点切分。例如 "Hello, world." 被拆为 ["Hello", ",", "world", "."]。优点是每个 token 对应一个有语义的词,缺点是致命的:
- 词汇表爆炸:英语中 "love"、"loved"、"loving"、"lover" 被视为四个不同的词,屈折变化和复合词会让词汇表膨胀到数十万。
- 未登录词(OOV)问题:拼写错误、新造词、专有名词等不在词典中的词只能映射为
<UNK>,信息完全丢失。
import re
text = "Hello, world. Is this-- a test?"
tokens = re.split(r'([,.:;?_!"()\']|--|\s)', text)
tokens = [t.strip() for t in tokens if t.strip()]
print(tokens)
# ['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']字符级分词(Character-based)。 走向另一个极端:将文本拆为单个字符。英文字母加数字和常用符号只有一百多个,词汇表极小,也完全不存在 OOV 问题。但代价同样沉重:
- 序列过长:
"Hello"变成 5 个 token,一句话动辄上百个 token,远超词级方案。 - 语义碎片化:单个字符几乎不携带独立语义,模型必须从头学习字符如何组合成词,训练效率极低。
子词级分词(Subword-based)。 现代大语言模型几乎无一例外地采用子词分词,它在上述两个极端之间找到了最佳折中:
- 高频词保留为完整 token:如 "the"、"is"、"你好"。
- 低频词被拆分为有意义的子词单元:如 "tokenization" → "token" + "ization"。
- 任意未知词都能被逐步分解,最终退化为字节级表示,从根本上消除 OOV 问题。
主流子词算法有三种:
| 算法 | 代表模型 | 核心策略 |
|---|---|---|
| BPE(Byte-Pair Encoding) | GPT-2/3/4, LLaMA | 自底向上合并最高频相邻对 |
| WordPiece | BERT | 合并能最大化训练数据似然的相邻对 |
| Unigram LM | T5, SentencePiece | 自顶向下裁剪对似然影响最小的 token |
本节重点讲解 BPE,因为它是 GPT 系列和 LLaMA 系列共同采用的方案,也是理解其他子词算法的基础。
4.1.2 UTF-8 编码基础
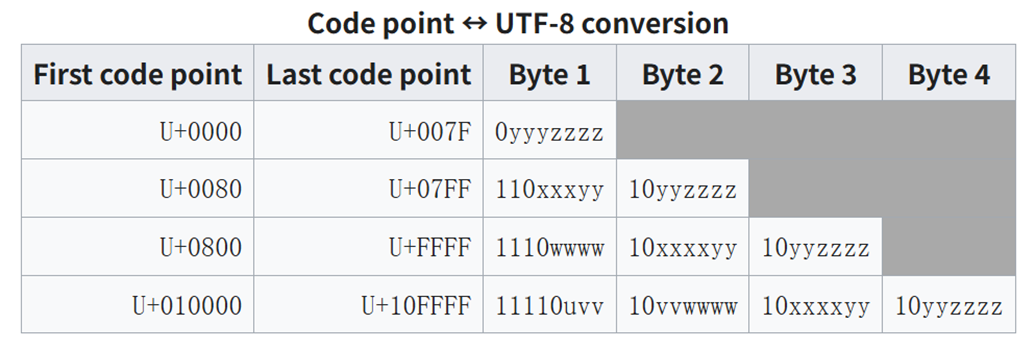
图 4-1:UTF-8 编码原理。不同 Unicode 码位范围使用 1-4 个字节表示,ASCII 字符保持单字节兼容。
在进入 BPE 之前,需要先理解一个前置知识:计算机如何表示文本字符。现代 BPE 算法的起点不是字符,而是字节(byte)——这一选择的基础正是 UTF-8 编码。
UTF-8 的变长规则。 UTF-8 是一种变长编码方案,用 1 到 4 个字节表示一个 Unicode 码点。编码规则如下:
| 码点范围 | 字节数 | 字节格式(二进制) | 示例 |
|---|---|---|---|
| U+0000 — U+007F | 1 | 0xxxxxxx | A → 0x41 |
| U+0080 — U+07FF | 2 | 110xxxxx 10xxxxxx | é → 0xC3 0xA9 |
| U+0800 — U+FFFF | 3 | 1110xxxx 10xxxxxx 10xxxxxx | 中 → 0xE4 0xB8 0xAD |
| U+10000 — U+10FFFF | 4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 😀 → 0xF0 0x9F 0x98 0x80 |
规则非常简洁:首字节的高位 1 的个数标识了该字符占多少字节,后续字节一律以 10 开头。这意味着在任意位置截断字节流后,解码器都能重新同步——找到下一个不以 10 开头的字节即可。
text = "A中😀"
byte_seq = text.encode("utf-8")
print(list(byte_seq))
# [65, 228, 184, 173, 240, 159, 152, 128]
# A=1字节, 中=3字节, 😀=4字节为什么 BPE 从字节开始。 既然一个字节只有 256 种取值(0x00 到 0xFF),以全部 256 个字节值作为初始词汇表,就能无损地表示任意语言的任意文本。这比以字符作为初始词汇表更优雅:中文常用字就有数千个,如果用字符初始化,初始词汇表就已经很大;而字节初始化将所有语言统一到同一个起点。
Overlong 编码与安全风险。 UTF-8 的一个安全隐患值得了解。例如字符 /(U+002F)正常编码为单字节 0x2F,但如果故意用两字节编码为 0xC0 0xAF,仍然能被某些有缺陷的解码器解析为 /。这种"过长编码(Overlong Encoding)"曾被用于绕过安全过滤器——攻击者用过长编码的 ../ 穿越目录,而过滤器只检查正常编码的 ../。现代 UTF-8 标准已明确禁止 overlong 编码,合规的解码器会拒绝此类输入。在实现分词器时,只要使用标准库(如 Python 的 str.encode('utf-8'))就不会产生这一问题。
4.1.3 BPE 算法原理
BPE(Byte-Pair Encoding)最初由 Philip Gage 于 1994 年提出,是一种数据压缩算法。其核心思想极其简单:反复找到序列中出现频率最高的相邻对,将其合并为一个新符号。
训练过程。 给定一个文本语料库和目标词汇表大小
- 初始化:将语料库中的所有文本转换为字节序列,初始词汇表为 256 个字节值(ID 0–255)。
- 迭代合并:重复以下步骤
次(每次向词汇表中新增一个 token): - 统计当前序列中所有相邻 token 对的出现频率。
- 找到频率最高的一对
。 - 创建新 token
,分配下一个可用 ID。 - 在整个语料库中,将所有相邻的
替换为 。 - 记录合并规则
。
- 完成:最终词汇表 = 256 个字节 +
个合并产生的 token。
一个具体的例子。 假设训练文本为 the cat in the hat:
- 初始序列:
[t, h, e, ' ', c, a, t, ' ', i, n, ' ', t, h, e, ' ', h, a, t] - 第 1 次合并:
(t, h)出现 3 次,频率最高 → 新建 tokenth(ID 256)- 序列变为:
[th, e, ' ', c, a, t, ' ', i, n, ' ', th, e, ' ', h, a, t]
- 序列变为:
- 第 2 次合并:
(th, e)出现 2 次,频率最高 → 新建 tokenthe(ID 257)- 序列变为:
[the, ' ', c, a, t, ' ', i, n, ' ', the, ' ', h, a, t]
- 序列变为:
- 第 3 次合并:
(the, ' ')出现 2 次 → 新建 tokenthe·(ID 258)- 序列变为:
[the·, c, a, t, ' ', i, n, ' ', the·, h, a, t]
- 序列变为:
- ……以此类推,直到达到目标词汇表大小。
合并过程的贪心性质使得高频子串被优先"凝聚"为单个 token,低频子串则保持拆分状态。
编码过程。 训练完成后,对新文本进行编码时:将输入转为字节序列,然后按训练时合并规则的顺序依次扫描并执行匹配的合并。先学到的规则优先级更高——这是因为先合并的对在训练时频率更高,理应优先应用。
解码过程。 解码极其简单:将 token ID 序列中的每个 ID 映射回其对应的字节序列,拼接后用 UTF-8 解码即可还原原始文本。

图 4-2:BPE 训练过程。左侧为当前 token 序列,中间统计相邻对频率,右侧执行合并并更新词汇表。每轮新增一个 token,重复直至词汇表达到目标大小。
4.1.4 BPE 从零实现
下面给出一个完整的、自包含的 BPE 分词器 Python 实现,包含训练(train)、编码(encode)和解码(decode)三个核心方法。这是一个教学版实现,优先考虑可读性而非性能。
from collections import Counter, deque
class BPETokenizer:
"""一个教学用的 BPE 分词器,从字节级开始训练。"""
def __init__(self):
# token_id -> 字节序列的映射
self.vocab = {i: bytes([i]) for i in range(256)}
# 合并规则:(token_id_a, token_id_b) -> merged_token_id
self.merges = {}
# ---- 训练 ----
def train(self, text: str, vocab_size: int):
"""在给定文本上训练 BPE,直到词汇表达到 vocab_size。
Args:
text: 训练语料(字符串)。
vocab_size: 目标词汇表大小,必须 >= 256。
"""
assert vocab_size >= 256, "词汇表大小不能小于 256(字节数)"
# 将文本转为字节 ID 列表
ids = list(text.encode("utf-8"))
num_merges = vocab_size - 256
for new_id in range(256, 256 + num_merges):
# 1. 统计所有相邻对的频率
pair_counts = self._count_pairs(ids)
if not pair_counts:
break # 序列长度 <= 1,无法继续合并
# 2. 找到最高频的对
best_pair = max(pair_counts, key=pair_counts.get)
# 3. 执行合并:将序列中所有 best_pair 替换为 new_id
ids = self._merge(ids, best_pair, new_id)
# 4. 记录合并规则和新 token 的字节表示
self.merges[best_pair] = new_id
self.vocab[new_id] = self.vocab[best_pair[0]] + self.vocab[best_pair[1]]
@staticmethod
def _count_pairs(ids: list[int]) -> dict[tuple[int, int], int]:
"""统计列表中所有相邻元素对的出现次数。"""
return Counter(zip(ids, ids[1:]))
@staticmethod
def _merge(ids: list[int], pair: tuple[int, int], new_id: int) -> list[int]:
"""将 ids 中所有出现的 pair 替换为 new_id。"""
result = deque(ids)
merged = []
while result:
current = result.popleft()
if result and (current, result[0]) == pair:
merged.append(new_id)
result.popleft() # 跳过被合并的第二个元素
else:
merged.append(current)
return merged
# ---- 编码 ----
def encode(self, text: str) -> list[int]:
"""将字符串编码为 token ID 列表。"""
ids = list(text.encode("utf-8"))
# 按合并规则的学习顺序依次应用
for pair, new_id in self.merges.items():
ids = self._merge(ids, pair, new_id)
return ids
# ---- 解码 ----
def decode(self, ids: list[int]) -> str:
"""将 token ID 列表解码回字符串。"""
byte_seq = b"".join(self.vocab[i] for i in ids)
return byte_seq.decode("utf-8", errors="replace")使用示例:
# 训练
corpus = "the cat in the hat sat on the mat"
tokenizer = BPETokenizer()
tokenizer.train(corpus, vocab_size=276) # 学习 20 条合并规则
# 编码
ids = tokenizer.encode("the cat in the hat")
print(ids)
# 输出类似 [259, 99, 97, 116, 32, 105, 110, 259, 104, 97, 116]
# "the " "c" "a" "t" " " "i" "n" "the " "h" "a" "t"
# 解码
print(tokenizer.decode(ids))
# "the cat in the hat"
# 验证往返一致性
assert tokenizer.decode(tokenizer.encode("the cat in the hat")) == "the cat in the hat"关键实现细节解析:
_count_pairs:用Counter(zip(ids, ids[1:]))一行完成相邻对计数,简洁且高效。zip(ids, ids[1:])生成(ids[0], ids[1]), (ids[1], ids[2]), ...的迭代器。_merge:使用deque的popleft()实现的单遍扫描替换。注意合并后可能产生新的可合并对(例如合并 (a,b)后,如果前一个元素恰好和ab构成另一条规则中的对),但在当前轮次中不会继续合并——这些新对会在后续轮次中被发现。encode中的规则应用顺序:遍历self.merges字典时,Python 3.7+ 保证字典按插入顺序迭代,因此合并规则天然按学习顺序排列。先学到的规则对应更高频的对,理应优先应用。
4.1.5 BPE 性能优化
图 4-3:从原始文本到嵌入向量的完整流水线。文本经分词器切分为 token 序列后,通过嵌入层映射为密集向量表示。
上述教学版实现的训练复杂度为
瓶颈分析。 用 Python 的 cProfile 或更现代的 Scalene 进行性能分析,会发现两个热点:
_count_pairs:每轮都对整个序列做一次遍历。但实际上,大多数对的频率在一次合并后并不会改变——只有涉及被合并对的局部区域才会变化。 _merge:同样需要遍历,且创建了大量临时列表。
# 使用 cProfile 分析
import cProfile
cProfile.run('tokenizer.train(large_corpus, vocab_size=1000)')
# 使用 Scalene(推荐,支持逐行 CPU/内存分析)
# 命令行: scalene train_tokenizer.py优化策略一:增量式计数器更新。 核心思路是维护一个全局的相邻对频率计数器,每次合并后只更新受影响的局部区域,而不是重新统计全部:
def _update_counts_after_merge(counts, ids, merged_positions, pair, new_id):
"""合并后增量更新计数器,而非重新全局统计。
只需处理每个合并位置的左邻居和右邻居:
- 旧的对 (left, a), (a, b), (b, right) 频率各减 1
- 新的对 (left, ab), (ab, right) 频率各加 1
"""
for pos in merged_positions:
a, b = pair
# 减去旧的对
if pos > 0:
left = ids[pos - 1]
counts[(left, a)] -= 1
if pos + 2 < len(ids):
right = ids[pos + 2]
counts[(b, right)] -= 1
counts[(a, b)] -= 1
# 执行合并
ids[pos] = new_id
ids[pos + 1] = None # 标记删除
# 加上新的对
if pos > 0:
left = ids[pos - 1]
counts[(left, new_id)] = counts.get((left, new_id), 0) + 1
if pos + 2 < len(ids):
right = ids[pos + 2]
counts[(new_id, right)] = counts.get((new_id, right), 0) + 1
# 清除标记为 None 的位置
ids[:] = [x for x in ids if x is not None]这将每轮合并的代价从
优化策略二:使用优先队列。 为了避免每轮都遍历整个计数器寻找最大值,可以用最大堆(优先队列)维护对的频率,将查找最高频对的复杂度从
工程级实现。 在实际生产中,这些优化通常用 Rust 或 C++ 实现。OpenAI 的 tiktoken 库和 Google 的 SentencePiece 库都采用了类似的策略。HuggingFace 的 tokenizers 库底层同样用 Rust 编写,在多线程加持下能在几分钟内完成 GB 级语料的 BPE 训练。
4.1.6 预分词与正则表达式
实际的 BPE 分词器在训练和编码时,并不是直接在整个文本的字节序列上运行 BPE。它们会先进行一步预分词(Pre-tokenization):用正则表达式将文本切分为"单词"级别的块,然后在每个块内部独立运行 BPE。
预分词的作用是防止 BPE 学习到跨越词边界的合并。例如,如果不做预分词,BPE 可能会把 "the dog" 中间的 "e " 和 "d" 合并为 "e d",产生一个跨越空格的无意义 token。
GPT-2 使用的预分词正则表达式为:
import re
GPT2_PAT = re.compile(
r"""'s|'t|'re|'ve|'m|'ll|'d"""
r"""| ?\p{L}+""" # 可选空格 + 连续字母
r"""| ?\p{N}+""" # 可选空格 + 连续数字
r"""| ?[^\s\p{L}\p{N}]+""" # 可选空格 + 连续符号
r"""|\s+(?!\S)""" # 尾部空白
r"""|\s+""" # 其余空白
)GPT-4 进一步改进了这个正则表达式,增加了对大小写混合词、多位数字等的更细致处理。预分词的设计直接影响分词器的行为——相同的 BPE 合并规则,配合不同的预分词正则,会产生截然不同的编码结果。
4.1.7 SentencePiece 与 Tiktoken 对比
在工程实践中,开发者通常不会从零实现 BPE,而是使用成熟的分词器库。两个最主流的选择是 Google 的 SentencePiece 和 OpenAI 的 Tiktoken。
图 4-4:三种分词器方案的定位对比。教学版适合理解原理,SentencePiece 适合从零训练自定义分词器,Tiktoken 适合加载和使用预训练好的分词器。
SentencePiece 是一个独立于语言的分词工具,支持 BPE 和 Unigram 两种算法:
- 直接处理原始文本:不依赖预分词,将空格视为普通字符(用特殊符号
▁标记词的起始位置),因此能统一处理中文、日文等不以空格分词的语言。 - 支持训练:给定语料库和目标词汇表大小,可以从零训练出分词器。LLaMA、T5 等模型都使用 SentencePiece 训练分词器。
- C++ 实现:性能远高于纯 Python 实现。
import sentencepiece as spm
# 训练
spm.SentencePieceTrainer.train(
input="corpus.txt",
model_prefix="my_tokenizer",
vocab_size=32000,
model_type="bpe"
)
# 使用
sp = spm.SentencePieceProcessor(model_file="my_tokenizer.model")
ids = sp.encode("Hello world", out_type=int)
text = sp.decode(ids)Tiktoken 是 OpenAI 开源的分词器库,核心算法用 Rust 实现:
- 仅支持编码/解码:不支持训练,只能加载预训练好的词汇表和合并规则。
- 极致性能:在编码速度上比 SentencePiece 快 3–6 倍(取决于文本类型和长度)。
- 预训练分词器丰富:内置 GPT-2(
gpt2,50,257 个 token)、GPT-4(cl100k_base,100,256 个 token)和 GPT-4o(o200k_base,199,997 个 token)的分词器。
import tiktoken
enc = tiktoken.get_encoding("cl100k_base") # GPT-4 分词器
ids = enc.encode("Hello world")
text = enc.decode(ids)
print(ids) # [9906, 1917]
print(text) # "Hello world"两者的关键差异总结如下:
| 维度 | SentencePiece | Tiktoken |
|---|---|---|
| 核心语言 | C++ | Rust |
| 支持训练 | 是 | 否 |
| 算法 | BPE / Unigram | BPE |
| 空格处理 | ▁ 标记词首 | 正则预分词 |
| 典型用途 | 从零训练分词器 | 加载预训练分词器进行推理 |
| 使用模型 | LLaMA, T5, MiniMind | GPT-2, GPT-3, GPT-4 |
在实际项目中,如果需要为自己的语料库训练一个定制化的分词器,SentencePiece 是首选;如果只是使用 GPT 系列模型或需要一个高性能的编码器,Tiktoken 更合适。HuggingFace 的 tokenizers 库则提供了一个折中方案:底层用 Rust 实现,同时支持训练和高速编码,且与 HuggingFace 的模型生态无缝集成。
4.1.8 小结
本节的核心要点如下:
- 分词粒度的取舍:词级分词语义清晰但词汇表爆炸、OOV 严重;字符级分词无 OOV 但序列过长;子词级分词在两者之间取得最佳平衡,是当前所有主流大模型的选择。
- UTF-8 为 BPE 提供了统一的字节级起点:256 个字节值构成初始词汇表,任何语言的任意文本都能被无损表示。理解 UTF-8 的变长编码规则有助于理解为什么 BPE 能处理多语言文本。
- BPE 的训练过程是一个贪心压缩过程:每轮合并最高频的相邻对,逐步从字节构建出子词和完整词。编码时按学习顺序应用合并规则,解码时直接查表还原字节序列。
- 性能优化的核心是避免重复全局遍历:增量式计数器更新和优先队列能将训练加速一到两个数量级,但工程级实现通常需要 Rust/C++ 来进一步榨取性能。
- SentencePiece 和 Tiktoken 代表了两种不同的使用范式:前者面向"训练新分词器",后者面向"使用已有分词器",两者各有所长。
理解了分词的原理和实现后,下一节我们将讨论如何将 token ID 映射为连续向量——即嵌入层(Embedding Layer)的设计,这是将离散的 token 序列送入 Transformer 之前的最后一步。