0.1 大语言模型范式与能力谱系
自然语言长期以来被视为人类智慧最核心的载体。从远古的甲骨文到互联网上的海量文本,语言记录着人类的思考与对世界的认知。然而,让计算机真正"理解"和"运用"自然语言,却是一条充满曲折的探索之路。在经历了人工规则、统计方法、神经网络等多个阶段的演进之后,大语言模型(Large Language Model, LLM)的出现,终于将自然语言处理(Natural Language Processing, NLP)推入了一个全新的纪元——一个模型可以胜任几乎所有语言任务的时代。
本节将从语言模型的基本定义出发,系统梳理 LLM 的三大架构家族,并深入讨论使大模型区别于传统模型的关键能力:涌现能力(Emergent Abilities)、上下文学习(In-context Learning)与指令跟随(Instruction Following)。这些概念构成了理解当代大模型研究的基础框架。
0.1.1 什么是语言模型
语言模型的核心思想出奇地简洁:给定一个 token 序列
这个看似简单的"下一个词预测"任务,蕴含着深刻的内涵。一个能够准确预测下一个词的模型,必然在某种程度上掌握了语言的语法结构、语义关联、事实知识乃至推理能力。正如 Wittgenstein 所言:"The limits of my language mean the limits of my world." ——语言的边界就是世界的边界。
语言模型的发展大致经历了四个阶段。统计语言模型时期(1990s),以 N-gram 模型为代表,基于马尔可夫假设用条件频率估计概率,简单高效但受困于数据稀疏和无法捕捉长距离依赖。神经语言模型时期(2003-2017),Bengio 等人首次将神经网络引入语言建模,随后 RNN/LSTM 通过循环隐藏状态处理序列信息,但顺序计算的本质限制了并行效率和长程建模能力。预训练语言模型时期(2018-2020),以 BERT 和 GPT 为标志,Transformer 架构登场,"预训练-微调"范式确立,模型开始在海量无标注文本上学习通用的语言表示,再针对下游任务做少量适配。大语言模型时期(2020 至今),模型参数量从亿级跃升至千亿甚至万亿级,配合大规模数据和算力,展现出前所未有的通用能力。
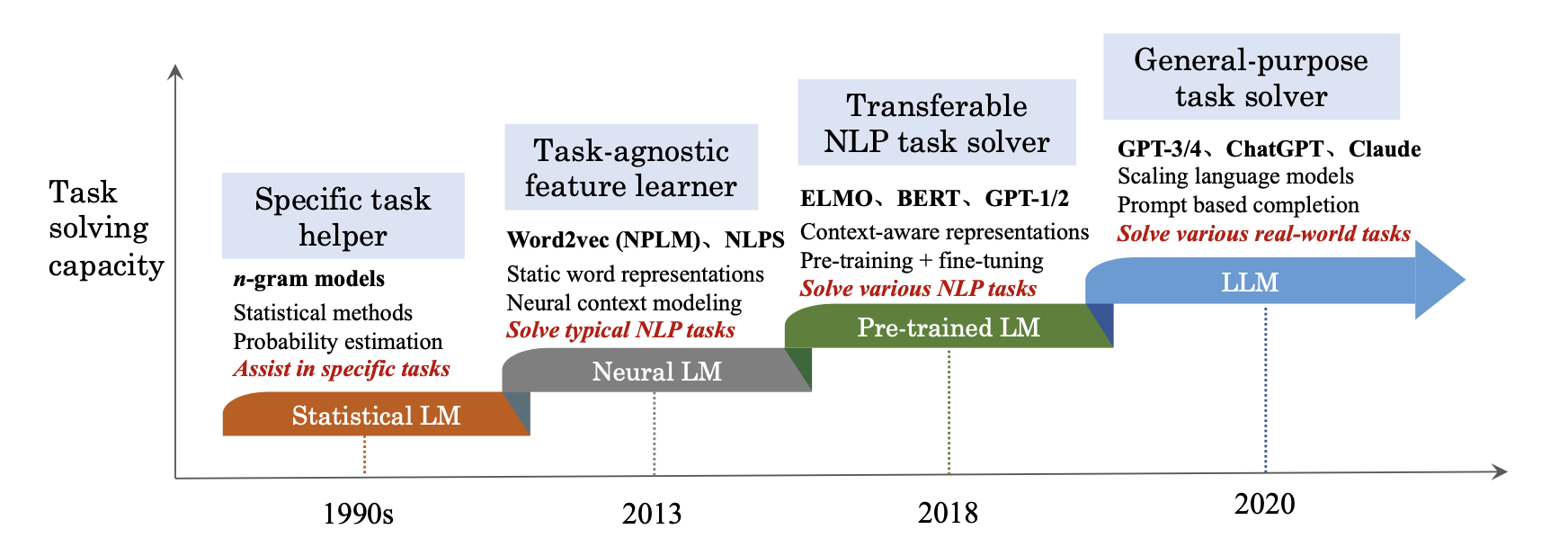
图 0-1:语言模型发展的四个阶段——从统计语言模型到大语言模型,任务解决能力持续跃升。
0.1.2 三大架构家族
2017 年,Vaswani 等人提出的 Transformer 架构彻底改变了 NLP 的格局。Transformer 以自注意力机制(Self-Attention)为核心,摆脱了 RNN 的顺序计算束缚,实现了对输入序列中所有位置关系的并行建模。在此基础上,后续研究沿着三条路径分化出了三大架构家族。
Encoder-only(仅编码器)架构。 代表模型为 BERT(Bidirectional Encoder Representations from Transformers)。其核心特征是双向注意力——模型在处理每个 token 时可以同时看到其左侧和右侧的全部上下文。BERT 的预训练任务是掩码语言模型(Masked Language Model, MLM):随机遮挡输入序列中约 15% 的 token,让模型根据双向上下文预测被遮挡的内容。这本质上是一道"完形填空题"。
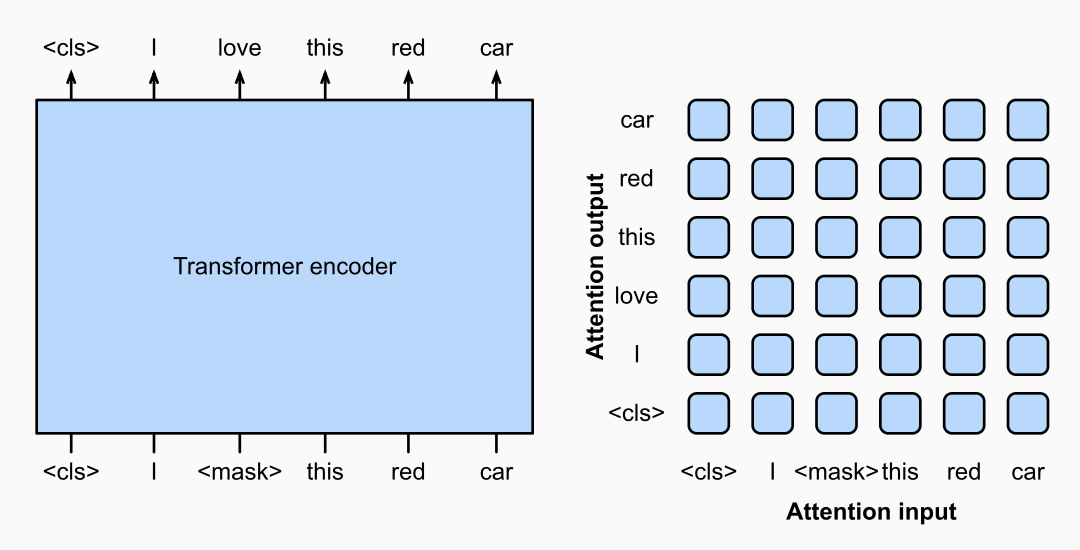
图 0-2:Encoder-only 架构的注意力模式。BERT 使用双向全注意力(右侧矩阵中所有位置均可互相关注),通过预测被 mask 的 token 进行预训练。
这种双向建模使 Encoder-only 模型特别擅长自然语言理解(Natural Language Understanding, NLU)任务,如文本分类、情感分析、命名实体识别、语义相似度计算等。BERT 在 2018 年发布后,迅速刷新了 11 项 NLP 任务的最优成绩,确立了"预训练-微调"的训练范式。其后续变体包括 RoBERTa、ALBERT、DeBERTa 等,均沿用了这一架构思路。
Decoder-only(仅解码器)架构。 代表模型为 GPT 系列(Generative Pre-trained Transformer)。其核心特征是因果注意力(Causal Attention)——模型在预测第
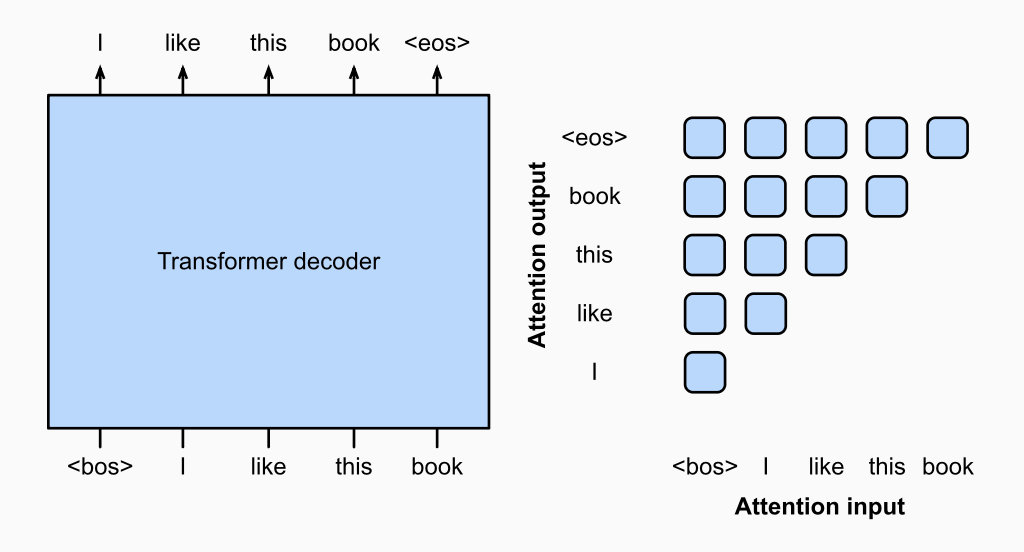
图 0-3:Decoder-only 架构的注意力模式。GPT 使用下三角因果注意力掩码(右侧矩阵),每个 token 只能关注自身及其之前的 token,天然适合自回归文本生成。
Decoder-only 架构天然适合文本生成任务。推理时,模型将上一步生成的 token 追加到输入序列中,迭代地执行"预测-采样-追加"的循环,即所谓的自回归生成(Autoregressive Generation)。2018 年 OpenAI 发布的 GPT-1(1.17 亿参数)率先验证了这条路线的可行性;GPT-2 将参数量扩展至 15 亿并首次观察到零样本迁移能力;GPT-3 进一步达到 1750 亿参数,展现出惊人的 In-context Learning 能力。此后,几乎所有主流大语言模型——包括 GPT-4、Claude、DeepSeek-V3、Qwen、LLaMA 等——都采用了 Decoder-only 架构。这使得 Decoder-only 成为当前大模型时代的绝对主流范式。
Encoder-Decoder(编码器-解码器)架构。 这是原始 Transformer 论文("Attention Is All You Need")所采用的完整架构。编码器处理输入序列,生成上下文表示;解码器根据编码器输出和已生成的 token,自回归地产生目标序列。两者之间通过交叉注意力(Cross-Attention)机制连接。代表模型包括 T5(Text-to-Text Transfer Transformer)和 BART。这类架构特别适合输入与输出都是序列的任务,如机器翻译和文本摘要。
三种架构的核心差异可以从注意力模式的角度统一理解:Encoder-only 使用全连接的双向注意力矩阵,Decoder-only 使用下三角的因果注意力矩阵,Encoder-Decoder 则在编码端使用双向注意力、在解码端使用因果注意力加交叉注意力。这些注意力模式的设计直接决定了各架构的信息流向与适用场景。
| 架构类型 | 注意力模式 | 预训练目标 | 优势场景 | 代表模型 |
|---|---|---|---|---|
| Encoder-only | 双向全注意力 | 掩码语言模型(MLM) | 语言理解(NLU) | BERT, RoBERTa, DeBERTa |
| Decoder-only | 因果注意力 | 下一词预测(NTP) | 文本生成(NLG) | GPT 系列, LLaMA, DeepSeek |
| Encoder-Decoder | 双向 + 因果 + 交叉 | 多种(如 span corruption) | Seq2Seq 任务 | T5, BART, mBART |
表 0-1:三大 Transformer 架构家族对比。
值得一提的是,Decoder-only 架构之所以在大模型时代胜出,并非因为它在理论上优于其他架构,而是因为自回归目标的训练效率极高(每个 token 都提供监督信号),且在规模扩展(Scaling)过程中展现出更好的性能增长趋势。正如 Karpathy 的 llm.c 项目所展示的,一个完整的 GPT-2 训练实现仅需约 1000 行 C 代码——这种架构上的简洁性也是其工程优势的重要来源。
0.1.3 从 GPT-1 到 ChatGPT:走向统一的道路
理解大语言模型的能力谱系,离不开对 GPT 系列发展脉络的梳理。这条技术路线清晰地展示了"规模化"如何逐步解锁新能力。
GPT-1(2018,1.17 亿参数)的核心贡献在于验证了"生成式预训练 + 判别式微调"的可行性。在 BooksCorpus 上预训练后,GPT-1 只需在 Transformer 顶部添加一个简单的线性层,就能适配文本分类、文本蕴含、语义相似度等多种下游任务,在 12 项 NLP 任务中有 9 项刷新了当时的最优成绩。这证明了自回归语言模型所学到的表示具有强大的迁移能力。
GPT-2(2019,15 亿参数)在更大的 WebText 数据集上训练,首次观察到了零样本迁移(Zero-shot Transfer)能力。其论文标题 "Language Models are Unsupervised Multitask Learners" 直接点题:一个足够大的语言模型无需微调,仅凭自回归生成就能隐式地完成翻译、摘要、问答等任务。例如,当模型在续写一段包含翻译上下文的文本时,它实质上就在执行翻译任务。但此时的零样本能力仍然不稳定,高度依赖 prompt 的设计。
GPT-3(2020,1750 亿参数)实现了关键突破。参数量扩大 100 倍后,模型在 42 项 NLP 任务上展现出显著的 In-context Learning 能力。OpenAI 首次系统区分了三种使用范式:

图 0-4:GPT-3 的三种 In-context Learning 设定——Zero-shot、One-shot 与 Few-shot。模型无需更新权重,仅通过在 prompt 中提供任务描述和示例即可执行任务。
- Zero-shot:仅提供任务描述,不提供示例。
- One-shot:提供一个输入-输出示例。
- Few-shot:提供若干个示例。
GPT-3 的 Few-shot 能力在许多任务上可以与专门微调的模型相媲美,这在当时是令人震撼的。但它仍有显著局限:输出不够稳定、使用成本高昂、缺乏持续对话能力。
从 GPT-3 到 ChatGPT(2022)的跨越,关键在于后训练(Post-training)技术的成熟。后训练并不改变模型的基础架构,而是通过少量的高质量数据进一步释放预训练阶段已经蕴含的能力:
- 监督微调(Supervised Fine-Tuning, SFT):在精心构造的"指令-回答"对上进行微调,使模型学会理解用户意图、遵循特定的输入输出格式。
- 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF):训练一个奖励模型来拟合人类偏好,再用 PPO 等强化学习算法优化语言模型的输出策略。
经过 SFT 和 RLHF 的 GPT-3.5 模型(即 ChatGPT 背后的模型)具备了稳定的指令遵循能力、多轮对话能力和高度的输出可控性。2022 年 11 月 30 日 ChatGPT 正式发布,标志着 NLP 大一统时代的来临——一个模型可以胜任翻译、摘要、问答、代码生成、创意写作等几乎所有语言任务。此后,所有主流大模型均采用了相似的"预训练 + SFT + RLHF"三阶段训练流程。
0.1.4 涌现能力:规模的礼物
涌现能力是大语言模型最引人入胜也最具争议的特性之一。Jason Wei 等人在 2022 年的论文 "Emergent Abilities of Large Language Models" 中给出了经典定义:涌现能力是指那些在小型模型上不存在、但在模型规模超过某个临界阈值后突然出现的能力。其核心特征是"突然性"——模型性能并非随规模平滑增长,而是在某个临界点从接近随机猜测一跃至远超随机的水平。
典型的涌现能力包括:
- 上下文学习(In-context Learning, ICL):无需更新模型权重,仅在 prompt 中给出少量任务示例,大模型即可"学会"执行该任务。这是 GPT-3 展示的标志性能力,而同等架构的小模型完全不具备。
- 思维链推理(Chain-of-Thought, CoT):当面对需要多步推理的复杂问题时,通过提示模型"一步一步地思考"(Let's think step by step),大模型可以生成连贯的推理链条并得出正确答案。这种能力在参数量低于约 100 亿的模型上几乎不存在。
- 指令跟随(Instruction Following):经过 SFT 后,大模型能够理解并执行各种复杂的自然语言指令,而小模型即使经过同样方式的微调,效果也远为逊色。
关于涌现能力的成因,学术界尚未形成共识,但存在几种有影响力的假说。多步计算假说认为,许多复杂任务需要模型内部执行一系列计算步骤,小模型的深度或宽度不足以支撑完整的计算链,而大模型具备了执行这些必要步骤的"组件"和"工作空间"。组合泛化假说认为,大模型学习到了更多、更鲁棒的基础"知识原子",并具备将这些原子以新颖方式组合的能力——当原子数量和组合能力同时超过临界点,涌现能力便出现了。评估指标假说则质疑涌现的"突然性"可能是选用了非线性评估指标(如精确匹配率)所导致的观测效应——若换用更平滑的指标(如对数概率损失),性能增长可能是连续的。
无论涌现是"真实的相变"还是"评估指标的伪影",一个不争的事实是:当模型规模超过某个阈值后,它确实能够完成小模型无法完成的任务。这一观察深刻地影响了大模型的研究方向——它为持续的规模扩展提供了动力,同时也带来了安全层面的隐忧:如果有益的能力可以涌现,那么有害的能力同样可能在不可预测的时刻出现。
0.1.5 从能力到应用:ICL 与指令跟随的统一视角
In-context Learning 和指令跟随可以被视为大语言模型能力谱系中两个互补的维度。
ICL 体现的是基座模型(Base Model)通过预训练习得的"元学习"能力。当模型在海量文本上进行下一词预测时,它隐式地学会了在推理时根据上下文中给出的模式(pattern)来调整自己的行为。这不涉及任何参数更新——模型完全是在推理时"临时学习"的。ICL 的存在意味着一个足够强大的自回归语言模型已经是一个通用的任务求解器:只要你能将任务表述为一段文本,并在 prompt 中给出恰当的示例,模型就能执行。
指令跟随则体现的是对齐模型(Aligned Model)通过后训练获得的"任务理解"能力。基座模型虽然具备 ICL 能力,但它的行为本质上是"续写训练语料中最可能出现的文本",而非"遵循用户的意图"。SFT 让模型学会了将用户的自然语言指令映射为期望的行为模式;RLHF 进一步强化了模型在"有帮助"(helpful)、"诚实"(honest)和"无害"(harmless)等维度上的表现。
两者的关系可以这样理解:ICL 是大模型在预训练阶段涌现的"原始能力",指令跟随则是通过后训练将这种原始能力转化为可靠、可控的"产品能力"的过程。ChatGPT 之所以能让普通用户也能轻松使用大模型,正是因为指令跟随能力将 ICL 的潜力封装在了一个直观的对话界面之后。
小结
本节从语言模型的基本定义出发,梳理了从统计语言模型到大语言模型的发展脉络,系统比较了 Encoder-only、Decoder-only 和 Encoder-Decoder 三大 Transformer 架构家族的设计哲学与适用场景,并深入讨论了涌现能力、In-context Learning 和指令跟随这三项使大模型区别于传统模型的关键特性。这些概念共同构成了一幅完整的图景:大语言模型之所以"大",不仅是参数量的增长,更是能力的质变——从专用工具到通用智能体的范式跃迁。在后续章节中,我们将深入 Transformer 架构的内部机制、训练方法和系统优化,逐步揭开这一范式跃迁背后的技术细节。