第 20 章:高级 Agent 话题
"We are in the task-centric era of AI. The question is not what AI can do, but what tasks AI can complete." — Shunyu Yao
本章概览
第 19 章建立了 Agent 的基本循环:感知-推理-行动-反馈。本章将这根主线延伸到多个前沿方向:多智能体如何协作,推理和规划能力如何从"人类式"思维中汲取灵感,世界模型如何让 Agent 在行动前先"想象"结果,形式化规划和行为树如何提供结构化的决策框架,MCTS 与神经网络的联姻如何催生 AlphaGo 级别的搜索智能,DreamCoder 如何在"做梦"中学会编程,自进化 Agent 如何优化自身的提示词,多模态感知如何赋予 Agent 视觉能力,具身智能如何让 Agent 走进物理世界,以及 Agentic RL 如何在沙盒环境中训练更强的 Agent。
20.1 Multi-Agent 系统
多智能体系统的动机、通信拓扑与 Theory of Mind 协作机制。
20.1.1 为什么需要多智能体
单个 LLM Agent 有上下文窗口限制、角色混淆和能力边界。将复杂任务拆分给多个专职 Agent,每个 Agent 专注于自己的子领域,可以显著提升整体性能。这就是多智能体系统(Multi-Agent System, MAS)的核心动机。
Li 等人提出的 Agent-Oriented Planning(AOP) 框架体现了这一思路:一个元代理(Meta-Agent)负责将用户请求拆解为子任务,确保每个子任务可由适当的 Agent 解决、子任务集合完整覆盖需求且不冗余。AOP 通过奖励模型评估子任务完成质量,必要时动态调整分配。
20.1.2 通信拓扑
多 Agent 系统的通信拓扑决定了信息流动方式:
| 拓扑 | 信息流 | 适用场景 |
|---|---|---|
| 中心化(Centralized) | 所有 Agent 向 Orchestrator 汇报 | 任务分配、质量把控 |
| 去中心化(Decentralized) | Agent 间点对点通信 | 对等协作、辩论 |
| 层级化(Hierarchical) | 多层次指挥链 | 复杂长链任务分解 |
| 广播(Broadcast) | 一对多消息 | 状态同步、通知 |
20.1.3 Theory of Mind(心智理论)
有效的多 Agent 协作要求 Agent 能推测其他 Agent 的知识状态和意图。这种能力在认知科学中称为 Theory of Mind(ToM)。
LLM Agent 在合作游戏中表现出一定的高阶 ToM 推理能力——能够揣测他人的知识和意图,从而涌现出协作行为。 — "Theory of Mind for Multi-Agent Collaboration via Large Language Models"
在 LLM 多 Agent 框架中,ToM 的实现依赖于:
- 显式角色定义:"你是一个了解用户偏好但不了解系统状态的 Agent"
- 选择性信息传递:只把相关上下文传给对应 Agent,而非全量共享
- 行为预测:Agent A 在行动前推断 Agent B 可能的反应
20.1.4 多 Agent 辩论
多 Agent 辩论(Multi-Agent Debate)通过多个 LLM 实例相互质疑和辩驳来提升最终答案的质量。这一机制在事实性问答和数学推理中效果尤为突出:
Agent A: "答案是 42,因为..."
Agent B: "我不同意。考虑到...,答案应该是 37"
Agent A: "考虑 B 的论点后,我修正答案为..."
裁判 Agent: "综合双方论证..." → 最终答案其本质是:验证比生成容易。让一个 Agent 生成答案,另一个 Agent 验证和挑战,可以有效减少单 Agent 的幻觉和推理错误。
不过需要注意:验证更容易这个假设对 LLM 未必成立。LLM 的能力来自在数据中学习模式——如果训练数据中缺少"纠错过程"的数据,它就没有理由能做出正确的批判。
20.2 推理与规划基础
System 1 与 System 2 思维的映射:LLM 如何从直觉响应走向深度推理。
20.2.1 三种推理模式
人类推理有三种基本范式,LLM Agent 的推理机制也与之对应。
演绎推理(Deductive Reasoning) —— 从一般到特殊,结论具有必然性:
大前提:所有人都会死
小前提:苏格拉底是人
结论: 苏格拉底会死 (必然为真)LLM 中的体现:给定规则 + 事实 → 推导结论。适合数学证明、逻辑推理。
归纳推理(Inductive Reasoning) —— 从特殊到一般,结论具有或然性:
观察1:公园的天鹅是白的
观察2:湖里的天鹅是白的
观察3:纪录片里的天鹅也是白的
归纳:所有天鹅都是白的(可能被证伪!)LLM 中的体现:few-shot learning——从少量示例中学习模式。更多的前提(示例)使结论更可靠。
溯因推理(Abductive Reasoning) —— 从结果推断最可能的原因:
观察:草坪是湿的
假设1:昨晚下雨了(最可能)
假设2:有人浇了水
结论:选择最简单/合理的解释LLM 中的体现:诊断型任务("这个代码为什么报错?")、Agent 失败后的根因分析。
20.2.2 任务分解:Planning 的核心
"Language agent = reasoning is generalization." — Shunyu Yao
有效的 Agent 推理建立在任务分解之上:将复杂任务拆解为 LLM 可单步处理的子任务。
三种分解策略:
- 顺序分解:A → B → C,每步依赖前一步
- 并行分解:A + B → 合并结果,无依赖的子任务并发执行
- 条件分解:根据中间结果动态选择后续路径
推理能力使 Agent 能泛化到未见过的新任务——传统 RL Agent 在新游戏中需要成千上万次训练,而人类可以通过常识推理快速上手("灯是黑的,可能有危险,需要先找灯")。这正是 ReAct 框架的核心洞察:将"推理"(Reasoning)和"行动"(Acting)结合,让 Agent 在执行任务时生成"内心独白",解释为什么这么做以及下一步计划。
20.3 世界模型
世界模型让 Agent 在行动前想象结果:从环境模拟到 Model-based Planning。
20.3.1 预测"说什么" vs. 预测"会发生什么"
| 语言模型(文本预测) | 世界模型 | |
|---|---|---|
| 目标 | 预测下一个 token | 预测行动的后果 |
| 输入 | token 序列 | 当前状态 + 行动 |
| 输出 | 下一 token 的概率分布 | 下一个世界状态 |
| 关键缺失 | 对物理世界的"惊讶"机制 | — |
一个拥有世界模型的智能体,当现实反馈与预测不符时会感到"惊讶",并据此调整自己的内部模型。而当前的 LLM 缺乏这种机制——它只是预测下一个 token,而非预测世界会发生什么。
20.3.2 心智模拟
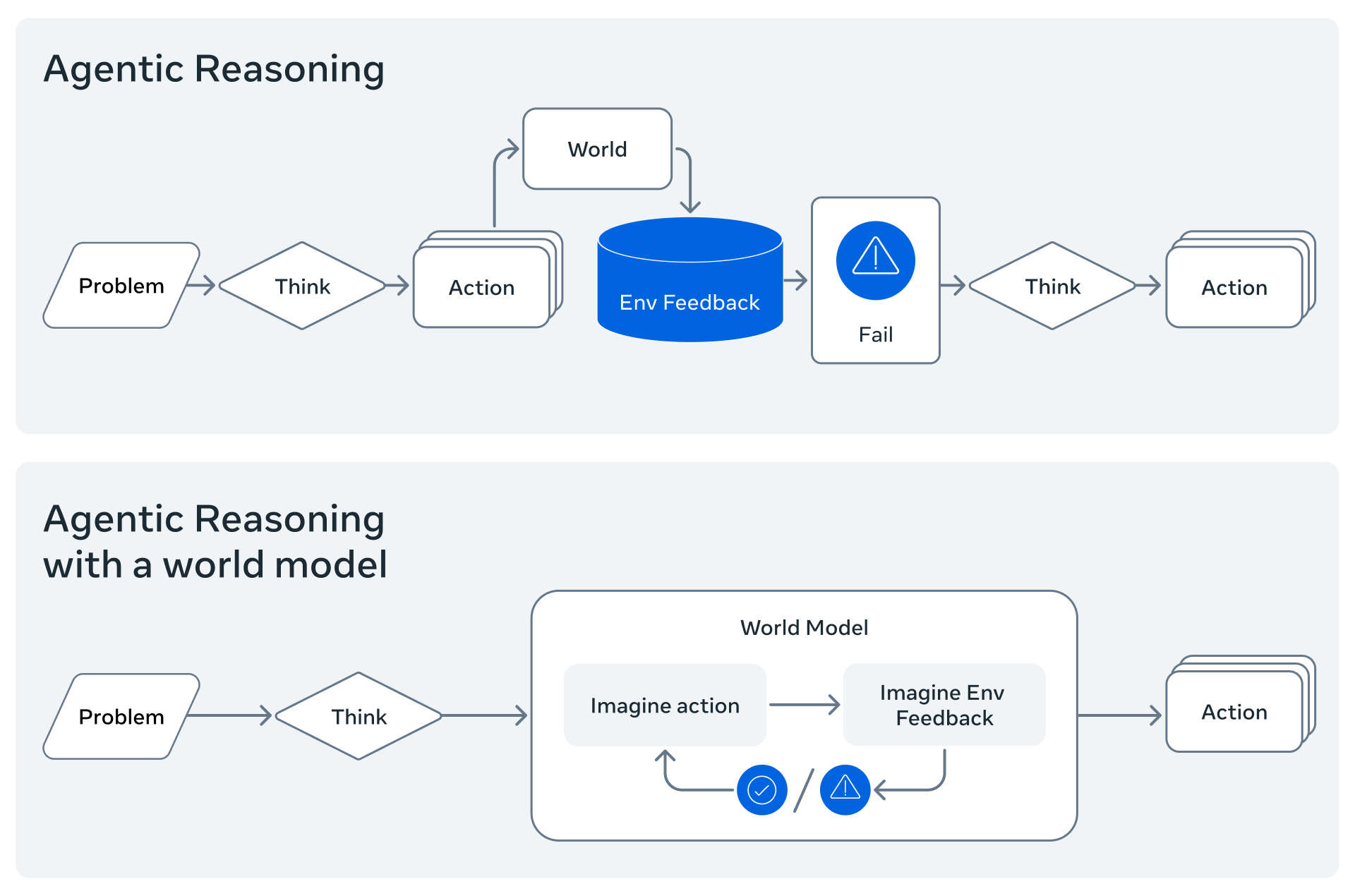
When humans plan, we imagine the possible outcomes of different actions. When we reason about code, we simulate part of its execution in our head.
在 Agent 系统中,世界模型允许 Agent 在实际执行前在大脑中模拟行动的后果:
当前状态 s_t
↓
候选行动 a_t
↓
世界模型预测 → 预测状态 s_{t+1}
↓
价值评估:s_{t+1} 是否更接近目标?
↓
选择最优行动LLM 在预训练过程中隐式学到的世界知识(重力、因果、社会规范)使其可以充当近似的世界模型。但对精确数值预测和反事实推理仍有显著局限。
20.4 任务规划:To-do List 与 DAG
将复杂任务分解为 To-do List 或 DAG 结构,实现可追踪的任务规划与执行。
20.4.1 DAG 任务图
将任务表示为有向无环图(DAG),每个节点代表一个子任务,边代表依赖关系:
┌─── 搜索文献 ───┐
│ │
起始 ────┤ ├──── 综合总结 ──── 完成
│ │
└─── 分析代码 ───┘DAG 表示的优势:
- 明确依赖关系,避免循环等待
- 无依赖的子任务可并行执行
- 部分失败后只需重跑失败节点及其下游
20.4.2 Cursor 的 To-do List
Cursor IDE 的 Agent 自动为复杂任务创建 to-do list:
tasks = [
{"id": 1, "desc": "读取用户需求", "status": "completed"},
{"id": 2, "desc": "分析现有代码结构", "status": "in_progress"},
{"id": 3, "desc": "实现新功能", "status": "pending", "depends_on": [2]},
{"id": 4, "desc": "编写测试", "status": "pending", "depends_on": [3]},
]这里的关键设计:
- 自动生成:To-do list 由模型根据任务自动生成,不需要人工编写
- DAG 依赖:每个 item 可以声明对其他任务的依赖
- 实时更新:执行过程中发现新子任务可动态添加
- Context Engineering:To-do list 作为"写出上下文"策略——将规划结果外化,避免复杂规划占满上下文窗口
20.5 PDDL:形式化规划语言
PDDL 形式化规划语言的基本语法与在 Agent 系统中的应用潜力。
20.5.1 PDDL 的结构
PDDL(Planning Domain Definition Language)源于经典 AI 规划研究(STRIPS, 1971),将规划问题分为 Domain(规则)和 Problem(任务)两部分。
Domain 文件定义了世界的"物理规则":
(define (domain logistics)
(:requirements :strips :typing :equality)
(:types location vehicle package)
(:predicates
(at ?obj - object ?loc - location)
(in ?pkg - package ?veh - vehicle))
(:action load
:parameters (?pkg - package ?veh - vehicle ?loc - location)
:precondition (and (at ?pkg ?loc) (at ?veh ?loc))
:effect (and (in ?pkg ?veh) (not (at ?pkg ?loc)))))关键概念:
:strips:每个 action 通过前置条件(preconditions)、增加效果(add effects)和删除效果(delete effects)定义:typing:为对象定义类型(robot, location, item),防止不合逻辑的动作:equality:支持=/!=判断两个对象是否相同
Problem 文件定义具体的任务实例:
(define (problem deliver-pkg)
(:domain logistics)
(:objects pkg1 - package truck1 - vehicle city-a city-b - location)
(:init (at pkg1 city-a) (at truck1 city-a))
(:goal (at pkg1 city-b)))20.5.2 求解器与 LLM 的结合
Fast Downward 是目前最流行的 PDDL 求解器,通过启发式搜索找到最优行动序列:
fast-downward.py --alias lama --overall-time-limit 50s domain.pddl problem.pddlLLM + PDDL 的混合方案:
自然语言需求
↓ LLM 翻译
PDDL Problem 文件
↓ Fast Downward 求解
行动序列 [a1, a2, ..., an]
↓ LLM 解释执行
结果这种架构兼具 LLM 的语言理解能力和经典规划器的最优性保证。LLM 负责"翻译",规划器负责"求解",各司其职。
20.6 行为树
行为树的节点类型与遍历机制:为 Agent 决策提供可调试的结构化框架。
20.6.1 核心概念
行为树(Behavior Tree, BT)是将 Agent 决策逻辑组织为树状结构的方法,广泛用于游戏 AI 和机器人控制。
组合节点(控制流):
- Sequence(序列,→):AND 逻辑
- 依次执行子节点;某子节点返回 FAILURE → 立即返回 FAILURE
- 所有子节点 SUCCESS 才返回 SUCCESS
- Selector(选择,?):OR / 备选逻辑
- 依次执行子节点;某子节点返回 SUCCESS → 立即返回 SUCCESS
- 所有子节点 FAILURE 才返回 FAILURE
叶子节点(执行逻辑):
- Action(动作):执行具体任务,返回 RUNNING / SUCCESS / FAILURE
- Condition(条件):检查状态,通常只返回 SUCCESS 或 FAILURE
Blackboard(黑板):所有节点共享的数据中心。例如 Node A 看见了物体,把坐标写在黑板上;Node B 读取坐标去抓取。
20.6.2 实例:咖啡递送机器人
任务:机器人需要去厨房取咖啡送给主人,但电量低于 20% 时必须立即充电。
根节点 (Selector - 优先级仲裁)
├── 分支 1 (Sequence - 电池保护):
│ ├── [条件] 检查电池是否过低?
│ └── [动作] 去充电
└── 分支 2 (Sequence - 送咖啡任务):
├── [动作] 导航到厨房
├── [动作] 抓取咖啡杯
└── [动作] 导航到沙发用 py_trees 实现:
import py_trees
class CheckBattery(py_trees.behaviour.Behaviour):
"""条件节点:检查电量是否过低"""
def update(self):
robot.battery_level -= 5 # 模拟电量消耗
if robot.battery_level < 20:
return py_trees.common.Status.SUCCESS # 条件满足(低电量)
return py_trees.common.Status.FAILURE # 条件不满足
class MoveTo(py_trees.behaviour.Behaviour):
"""动作节点:移动到目标位置"""
def __init__(self, name, target_location):
super().__init__(name)
self.target = target_location
self.steps = 0
def initialise(self):
self.steps = 0
def update(self):
self.steps += 1
if self.steps >= 3:
robot.location = self.target
return py_trees.common.Status.SUCCESS
return py_trees.common.Status.RUNNING
# 构建行为树
root = py_trees.composites.Selector(name="Robot Brain", memory=False)
# 电池保护分支(高优先级)
battery_seq = py_trees.composites.Sequence(name="Battery Guard", memory=False)
battery_seq.add_children([CheckBattery(), ChargeRobot()])
# 工作分支:memory=True 表示子节点 RUNNING 后,下次 tick 从断点续接
work_seq = py_trees.composites.Sequence(name="Deliver Coffee", memory=True)
work_seq.add_children([
MoveTo("Go to Kitchen", "kitchen"),
GrabObject("Pick Coffee"),
MoveTo("Go to Sofa", "sofa"),
])
root.add_children([battery_seq, work_seq])运行效果——Selector 实现了优先级抢占:
Tick 1-2: 电量 25%→20%,Battery Guard 失败 → 执行送咖啡(前往厨房)
Tick 3: 电量 15% < 20%,Battery Guard 成功 → 抢占!立即充电
Tick 4-6: 电量恢复到 30% → 继续送咖啡任务
Tick 7: 电量再次 15% → 再次抢占充电
Tick 8-10: 充电后完成送达memory=False(电池分支)意味着每次 tick 都从头检查;memory=True(工作分支)意味着任务从上次中断的地方继续。
20.6.3 行为树 vs. 有限状态机
| 特性 | 行为树 | FSM |
|---|---|---|
| 模块化 | 高(子树可复用) | 低(状态间耦合) |
| 优先级 | 天然支持(Selector 顺序) | 需要显式编码 |
| 扩展性 | 添加行为 = 挂新子树 | 状态数量爆炸 |
| 反应性 | 每 tick 重新评估优先级 | 需要手动设计中断机制 |
20.7 MCTS:蒙特卡洛树搜索
MCTS 四阶段循环(选择-扩展-模拟-回传)与 UCT 公式的探索-利用平衡。
20.7.1 四个阶段
蒙特卡洛树搜索(Monte Carlo Tree Search)通过模拟随机博弈来估计节点价值:
- 选择(Selection):从根节点出发,按 UCB 公式选择最有潜力的子节点,直至叶子
- 扩展(Expansion):对叶子节点展开一个或多个未探索的子节点
- 模拟(Rollout):从新节点开始随机走子直到终局
- 反向传播(Backpropagation):将结果沿路径逆序更新各节点的
(访问次数)和 (累计奖励)
20.7.2 UCB → UCT → PUCT
三者的演进关系:UCB 是多臂老虎机的臂选择准则;UCT 将 UCB 搬到 MCTS 树上;PUCT 在 UCT 基础上引入策略先验。
直觉理解:
- 利用项
:选择历史表现好的动作 - 探索项
:少被访问的动作获得探索奖励 - 先验项
(PUCT 独有):策略网络认为有前途的动作获得额外权重
20.7.3 纯 MCTS vs. 神经网络 + MCTS
| 特性 | 纯 MCTS | MCTS + 神经网络(AlphaGo) |
|---|---|---|
| 是否需要训练 | 否 | 是(数百万盘自我对弈) |
| 核心驱动 | 大量随机模拟和统计 | 策略网络"直觉" + 价值网络"判断" |
| 模拟阶段 | 随机走到终局 | 价值网络直接评估叶子节点,省去随机打穿 |
| 选择策略 | UCT | PUCT(策略网络提供先验 |
| 性能 | 通用但相对较弱 | 极为强大(AlphaGo, AlphaZero) |
AlphaGo/AlphaZero 的两大核心网络:
- 策略网络(Policy Network):输入棋局,输出每步走法的概率分布——模拟"棋感"
- 价值网络(Value Network):输入棋局,输出当前胜率评估——替代随机模拟
纯 MCTS 完全依赖于随机模拟——在复杂游戏中,随机模拟的指导性很差。神经网络替代随机模拟后,搜索效率获得了数量级的提升。
20.8 DreamCoder:神经符号程序合成
DreamCoder 通过做梦构建程序库:神经引导搜索与抽象学习的联合优化。
20.8.1 核心思想
DreamCoder(Ellis et al., 2021)是一个神经符号系统,通过将神经网络的归纳能力与符号程序搜索的精确性结合,从示例中自动学习程序和抽象概念。
其核心循环模拟人类的"白天学习、夜间巩固":
Wake 阶段(学习):
任务示例 → 识别网络引导 → 枚举式程序搜索 → 求解程序
Sleep 阶段(巩固):
1. 训练识别网络(从任务特征到文法权重的映射)
2. 更新文法(提高常用 primitive 的概率)
3. 库学习——从已解决程序中提炼可复用子程序 → 更新程序库20.8.2 类型化 DSL 与概率文法
DreamCoder 在一个**类型化领域特定语言(DSL)**上搜索程序。以列表变换任务为例:
# 基础类型
Int = BaseType("int")
ListInt = BaseType("list[int]")
Tii = Arrow(Int, Int) # int -> int
Tll = Arrow(ListInt, ListInt) # list[int] -> list[int]
# Primitive 语义
env.add("add1", Tii, lambda x: x + 1)
env.add("mul2", Tii, lambda x: x * 2)
env.add("map", Arrow(Tii, Tll), lambda f: (lambda xs: [f(x) for x in xs]))
env.add("filter", Arrow(Tib, Tll), lambda p: (lambda xs: [x for x in xs if p(x)]))
env.add("compII", Arrow(Tii, Arrow(Tii, Tii)),
lambda f: (lambda g: (lambda x: f(g(x)))))概率文法为每个 primitive 赋予概率,程序的"描述长度"等于各 primitive 的
20.8.3 库学习:压缩即智能
库学习是 DreamCoder 最有创意的部分。其观察:在解决多个问题后,某些子表达式反复出现。将它们抽象为新的 primitive,就能用更短的程序描述相同的计算。
实际运行效果:
== Phase 0: 无学习时的 TEST ==
map_add1_then_mul2_test evals= 38 program=(map ((compII mul2) add1))
== Phase 1: WAKE — 在 TRAIN 集上求解 ==
map_add1 evals= 9 program=(map add1)
map_mul2 evals= 11 program=(map mul2)
map_add1_then_mul2 evals= 38 program=(map ((compII mul2) add1))
== Phase 3: 库学习 — 发现重复子结构 ==
Invented abstr1: type=(int->int) def=((compII mul2) add1)
Invented abstr2: type=(list[int]->list[int]) def=(map ((compII mul2) add1))
== Phase 4: 用学到的库再测 TEST ==
map_add1_then_mul2_test evals= 6 program=abstr2 ← 从 38 降到 6!abstr1 封装了"先加一再乘二"的组合,abstr2 封装了"对列表每个元素先加一再乘二"。有了这些抽象,原来需要 38 次搜索的问题,只需 6 次就能解决。
这个过程体现了"压缩即智能"的哲学:发现数据中的规律并压缩为更短的表示。学到的库就像人类编程中的函数库——你不需要每次从零开始实现排序算法。
20.9 自进化 Agent
Agent 自动优化自身 Prompt 和工具使用策略的自进化机制。
20.9.1 提示词优化 = 文本梯度下降
传统深度学习的参数更新:
提示词优化(Prompt Optimization)的类比:
| 深度学习 | 提示词优化 |
|---|---|
| 权重 | 提示词文本 |
| 梯度 | LLM 生成的改进建议("reflection") |
| 学习率 | 修改幅度 |
| 训练数据 | 测试任务的通过/失败结果 |
当前提示词 p_t
↓ 在任务集上执行
性能评估(通过率、错误样本)
↓ LLM 分析失败案例
"建议:应该更明确地要求...;避免..."
↓ LLM 修改提示词
新提示词 p_{t+1}"gradient descent on text 其实就是 reflection"——一种将人类反思行为形式化的优化过程。
20.9.2 自进化的几条路径
- Reflection(反思):Agent 分析自身错误,生成改进计划,修正行为
- Prompt Learning:在 SWE-bench 等任务上迭代优化 system prompt
- Self-Instruction:用 LLM 生成更多训练样本来微调自身
- Policy Update via RL:通过 RLHF / GRPO 等算法持续改进策略
20.9.3 工程实践要点
- Prompt Learning 非常消耗 Token——Agent 生成代码 + 运行测试 + Judge 分析 + Optimizer 重写,一轮迭代成本很高
- 建议先在小数据集(10-20 个样本)上跑通流程
- 优化对象不仅是 system prompt,还包括工具调用策略、思维链格式等
- 从控制论视角看,Prompt Learning 相当于某种意义上的 Policy Update——反馈回路驱动的策略迭代
20.10 多模态 Agent
视觉感知赋予 Agent 多模态能力:从 GUI Agent 到 Agentic Vision。
20.10.1 Visual Prompting
与文本提示类似,视觉提示工程(Visual Prompting)通过对输入图像施加标注来引导 VLM 关注特定区域。核心思想:用视觉信号指挥视觉模型。
与其费力描述"请帮我把那个长得像圆柱体、银色、带把手的东西拿给我",不如直接用手指一指那个杯子。Visual Prompting 就是这根"手指"。
三代演进:
- 早期:帮助 VLM 进行物体定位(object localization trick)
- 中期:辅助空间推理——将回归问题(直接生成坐标)转化为选择问题(从标记中选)
- 当前:帮助模型 focus、稳定注意力、降低推理难度
20.10.2 SoM:Set-of-Mark
SoM 的核心想法:将图像分割为语义区域,给每个区域赋予可读的 ID 标记,让 VLM "看图说话"。
其中
GPT-4V 之所以对 SoM 效果极好,可能是因为其训练数据中包含大量带标签的图表、教科书插图——模型天然理解"图像上叠加的文字标记与区域的关联"。
20.10.3 PIVOT:迭代式视觉提示
PIVOT(Iterative Visual Prompting Elicits Actionable Knowledge for VLMs)通过多轮迭代逐步缩小搜索范围,将 VLM 的"模糊直觉"转化为精确的动作坐标。

形式化定义:
- 输入:图像
,语言指令 ,连续动作空间 - 映射函数
:将物理动作投影到图像平面,生成标注图和文本标签 - 优化目标:
,其中
迭代过程:
第 0 轮:全空间均匀采样候选点 → VLM 选出 Top-K
第 1 轮:在 Top-K 的高斯分布内采样 → VLM 再选 Top-K
第 2 轮:分布继续收敛 → 精确定位
第 3 轮:收敛到目标点附近这本质上是用 VLM 作为 oracle 的交叉熵方法(CEM)——每轮采样、评估、拟合精英分布、缩小搜索范围。
20.10.4 SAM 系列与 Grounded SAM2
SAM(Segment Anything Model)系列提供了通用的图像分割能力:
- SAM1/SAM2:instance-level 分割,接受点/框提示
- SAM3:promptable concept segmentation,支持文本名词短语和示例图片作为提示
- SAM3 Agent:VLM + SAM3,先用 VLM 理解语言指令,再用 SAM3 分割
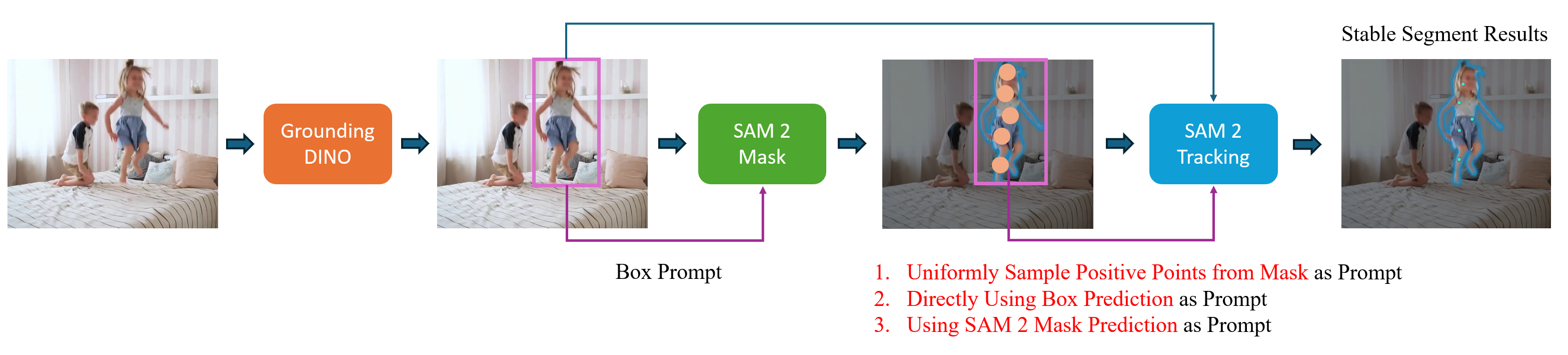
Grounded SAM2 = Grounding DINO + SAM2:先用 Grounding DINO 根据文本描述定位物体,再用 SAM2 精确分割。
20.10.5 机器人抓取中的 Visual Prompting(FreeGrasp)
FreeGrasp 展示了 Visual Prompting 在实际机器人系统中的应用:
- 物体定位:用 Molmo 模型获取物体中心点坐标("Point out all objects in the bin")
- 标记叠加:给每个物体分配数字 ID,在图像上绘制带数字的标记
- 推理抓取顺序:VLM 根据标记后的图像推理"哪个物体先拿"——考虑遮挡关系
Prompt: "Given a target object, determine the first object to grasp.
If the target is free of obstacles, return itself. Otherwise,
identify an occluding object that is free. Output: [object_id, color class_name]"20.10.6 计算机使用 Agent(CUA)
CUA(Computer-Use Agent)是能像人类一样操作计算机界面的 Agent:
- 输入:屏幕截图或无障碍树(accessibility tree)
- 行动空间:点击、输入、滚动、快捷键
- 实现路径:截图 + 坐标预测、AX 树解析、SoM 标注
20.11 具身智能与机器人学
具身智能将 Agent 带入物理世界:感知-决策-执行的闭环与 Sim-to-Real 迁移。
20.11.1 3D 空间感知基础
机器人需要理解三维世界才能有效行动。
RGB-D 相机同时捕获颜色(H x W x 3)和深度(H x W x 1)信息,像素值代表该点距相机的真实物理距离。
从像素到 3D 点云——通过相机内参矩阵反投影:
已知像素
将所有像素进行这样的转换,就得到了点云(Point Cloud)——无数离散点在 3D 空间中的集合。
**体素(Voxel)**是 3D 的"像素"——将连续空间划分为规则网格,如果网格内有点则填充。点云是原始的、无序的;体素化后是结构化的、可用 3D 卷积处理的。
占用图(Occupancy Map):3D 空间划分为体素,每个体素标记为 occupied / free / unknown。它是 SLAM 系统的建图结果。
20.11.2 Entity 与碰撞检测
在 3D 引擎(Unreal Engine、Unity)中,Entity 是场景中的基本对象单位。每个 Entity 有一个锚点(Anchor)——当设置 Position = (10, 0, 0) 时,是将锚点放在世界坐标 (10, 0, 0) 处,而非几何中心。理解锚点与几何中心的区别是正确操作 3D 物体的前提。
AABB vs OBB 碰撞检测:
| 类型 | 全称 | 特点 |
|---|---|---|
| AABB | Axis-Aligned Bounding Box(轴对齐包围盒) | 始终与世界坐标轴对齐,计算极快 |
| OBB | Oriented Bounding Box(有向包围盒) | 随物体旋转,贴合更紧密 |
当物体旋转时,AABB 为了保持坐标轴对齐会剧烈膨胀,导致视觉上未接触时就产生碰撞误判(需要窄相二次确认)。而 OBB 紧密贴合物体,但代价是需要执行多达 15 次的**分离轴定理(SAT)**投影测试。
工程中常用的优化:先用 Relative AABB(物体局部坐标系下的 AABB)的 8 个角点进行矩阵变换,取变换后坐标的最大最小值,快速得到新的 World AABB——避免对完整网格做矩阵运算。
20.11.3 IMU 传感器
**IMU(Inertial Measurement Unit,惯性测量单元)**是机器人感知自身运动状态的核心传感器,包含三个组件:
- 加速度计(Accelerometer):测量线性加速度
- 陀螺仪(Gyroscope):测量角速度(旋转速率)
- 磁力计(Magnetometer):测量磁场方向(提供绝对朝向参考)
IMU 在机器人中的核心作用:
- 姿态平衡:实时感知倾斜和旋转,驱动平衡控制器(对双足/四足机器人尤为关键)
- 定位与导航:通过积分加速度估算位移,与 SLAM 的视觉定位互补(IMU 提供高频短时估计,视觉提供低频长时校正)
20.11.4 位姿与坐标变换
3D 空间中描述物体姿态的最常用方式是四元数(Quaternion)
欧拉角是"三次连续旋转",四元数是"绕任意一根轴的一次旋转"。四元数避免了欧拉角的万向节死锁(Gimbal Lock)问题。
3D → 2D(投影):
2D → 3D(反投影):从像素坐标构造相机坐标系射线,再通过相机外参(旋转四元数)变换到世界坐标系。如果已知深度,直接求出 3D 点;如果只知道平面方程
20.11.5 主动感知与 Frontier 探索
主动感知(Active Perception):机器人执行动作(walk-to, rotate-to)是为了获得更好的观测视野。什么是"好的视野"是一个多目标优化问题——覆盖面积、目标占比、居中程度、移动距离等。
Frontier Exploration:机器人朝向已知自由空间与未知空间的交界处(frontier)移动,贪心地最大化信息增益,高效扩展地图覆盖范围。
20.11.6 3D 场景图
3D 场景图用结构化的图
- 节点
:位置、尺寸、属性集合(颜色、材质)、类别标签 - 边:空间关系
| 关系类别 | 示例 |
|---|---|
| 垂直邻近 | support, above, below, inside, mounted on |
| 水平邻近 | near, besides, far, next to |
| 他心方向 | left, right, behind, in front of |
将 3D 场景图序列化后输入 LLM,可实现精准的空间推理:"桌子上有几个物体?""杯子在椅子的哪个方向?"
20.11.7 Rasterized Representation
将 3D 环境投影为 2D 栅格化图像(Rasterized Image),是 VLM 理解 3D 空间的一种高效方式:
- 空间结构:哪里是墙(不可通行)、空地(可通行)、未知区域
- 轨迹:机器人从起点到当前的移动路径
- 地标:带数字标记的关键物体和采样点
这是把 Visual Prompting(SoM 标记)应用到栅格地图上——VLM 通过标记编号"阅读"地图,理解空间布局。
20.11.8 VLM → VLA:从理解到行动
**SIMA2(Google DeepMind)**将具身交互建模为基于历史观测和指令的序列决策:
视觉、语言、动作处于同一个 Token Stream 中,允许模型在输出动作前进行内部推理(CoT)。为防止灾难性遗忘,SIMA2 使用混合数据微调——同时训练游戏交互数据和通用语言数据。
Bridge Data的合成过程尤为巧妙:
- 输入:人类玩游戏的视频 + 键鼠操作记录 + 任务指令
- 将视频和动作喂给强力 Gemini Pro 模型
- 提问:"作为专家玩家,看到这个画面并执行了这些动作,请解释你的内心推理"
- 产出:填补了人类数据中缺失的"思维过程"
没有 Bridge Data,AI 只知道"这个时候该按 W";有了 Bridge Data,AI 知道"按 W 是因为前方有道路,目标在那个方向"。
Thinking in Space:研究发现,主流的语言推理技术(CoT, self-consistency, ToT)无法改善 VLM 的空间距离推理能力。但显式生成认知地图(Cognitive Map)——在 10x10 BEV 网格上标注物体位置——能显著提升性能。

Qwen-VL 的空间检测:支持多种定位输出格式:
// 2D 边界框
{"bbox_2d": [341, 258, 397, 360]}
// 3D 边界框(中心坐标 + 尺寸 + 姿态)
{"bbox_3d": [x_center, y_center, z_center, x_size, y_size, z_size, roll, pitch, yaw]}
// 2D 关键点
{"point_2d": [394, 105]}20.11.9 具身智能 Benchmark:Anywhere3D-Bench
评测具身 Agent 在 3D 环境中的任务完成能力需要专门的 benchmark。Anywhere3D-Bench 聚焦于 3D 空间理解与导航任务的评测,其核心设计特点:
- 多样化 3D 场景:覆盖室内(家庭、办公室)和室外环境,测试 Agent 的空间泛化能力
- 任务层次:从基础的物体定位、空间关系推理到复杂的多步导航与操作
- 评测维度:不仅关注任务成功率,还考察路径效率、碰撞次数、指令理解准确度等
这类 benchmark 的价值在于提供了标准化的评测基础设施,使不同方法(纯 VLM 推理、VLA 端到端、经典规划 + VLM 组合等)在统一条件下可比较。
20.12 Agentic RL 任务
Agentic RL 任务的定义:在沙盒环境中通过 RL 训练更强的工具使用和推理能力。
20.12.1 SWE-bench:软件工程基准
SWE-bench 评估 AI Agent 自主解决真实 GitHub Issue 的能力:
- 任务:给定 Issue 描述,Agent 修改代码使测试通过
- 评测流程:
predictions → TestSpec → 容器执行 → 解析日志 → report - 分层 Docker 镜像:base → env → instance,保证环境一致性
SWE-Gym 在此基础上构建了 RL 训练环境,提供单元测试驱动的执行反馈。
20.12.2 tau-bench:工具调用 Agent 评测
SWE-bench 评测的是代码修改能力,而 tau-bench 专注于评测 Agent 的工具调用(Tool-Use)能力——在真实业务场景中,Agent 能否通过多轮工具调用完成用户的具体需求。
评测目标:衡量 LLM Agent 在给定一组工具(API)的情况下,通过多轮交互完成实际业务任务的能力。与 SWE-bench 的"修改代码"不同,tau-bench 关注的是"正确使用 API"。
任务设计:tau-bench 构造了零售(retail)和航空(airline)两个领域的模拟环境,每个环境包含:
- 一组业务 API(如查询订单、修改航班、处理退款)
- 一个模拟数据库
- 用户请求描述(自然语言)
- 预期的正确操作序列
Agent 需要理解用户意图,选择正确的 API,按正确的顺序和参数调用,最终完成任务。
关键指标:任务通过率(pass rate)——Agent 完成任务后,数据库状态是否与预期一致。这比单纯的"生成质量"更严格,因为工具调用的结果是确定性的,错误立即暴露。
20.12.3 Cursor Tab:on-policy RL 驱动的代码补全
Cursor Tab 将代码补全建模为强化学习问题:
MDP 定义:
- State:代码上下文 + 光标位置
- Action:补全建议或"保持沉默"
- Reward:用户接受 +0.75 / 拒绝 -0.25 / 不显示 0
REINFORCE 策略梯度:
核心约束是 on-policy:用于更新
Cursor 的架构要求从"部署模型"到"收集数据"再到"开始训练"的闭环在 1.5-2 小时内完成。极速闭环 = Deploy → Rollout → Update。
核心洞察:数据管线优于复杂算法。
20.12.4 DeepResearch:深度研究 Agent
DeepResearch 能够进行多轮搜索、阅读文献并综合撰写研究报告。
评估框架:
- RACE(报告质量):Comprehensiveness、Insight、Instruction Following、Readability 四维度,使用相对评分法(与标杆报告对比)避免分数膨胀
- FACT(引用真实性):检查每一个引用是否支持其对应的陈述,不依赖文本生成质量
训练视角:Step-Level Asynchronous RL
DeepResearch 不仅是一个评测框架,也是 RL 训练的对象。通义研究团队在 rLLM 框架之上实现了 step-level asynchronous RL training loop,其核心思想是将 Agent 的多轮搜索-阅读-写作过程拆解为独立的 step,每个 step 异步执行并即时回传奖励信号:
Step 1: 生成搜索查询 → 执行搜索 → 获取结果 → 计算 step reward
Step 2: 阅读并筛选文献 → step reward
Step 3: 综合撰写段落 → step reward
...
最终: 汇总所有 step reward + 终局 reward → 策略更新与传统的 episode-level RL(等整个报告生成完毕才给一个奖励)相比,step-level 训练的优势在于:
- 信号更密集:每个中间步骤都有反馈,缓解稀疏奖励问题
- 异步执行:多个 Agent 实例的不同 step 可以并行训练,提高 GPU 利用率
- 更细粒度的 credit assignment:哪一步搜索查询质量差、哪一步综合能力不足,可以精确归因
20.12.5 搜索 Agent 与 Multi-Turn RL
搜索 Agent 的 RL 训练面临独特挑战:每轮搜索-阅读-决策构成一个多步骤的交互过程。Multi-Turn Search RL 需要在"节省 Token 成本"和"保持搜索质量"之间取得平衡。
20.13 沙盒环境
Agent 训练与评测的沙盒环境:从代码执行到网页交互的标准化基础设施。
20.13.1 为什么需要沙盒
Agent 在执行代码、访问文件系统、调用网络时可能产生破坏性副作用。沙盒提供:
- 隔离性:Agent 行动不影响宿主系统
- 可重置性:每次评测从相同初始状态开始
- 并发性:多个 Agent 实例可并行评测
- 安全性:防止越权访问
20.13.2 Docker 沙盒
Docker 容器是最常见的沙盒实现。SWE-bench 的评测流程:
启动 Docker 容器(包含目标代码仓库)
↓
Agent 读取 Issue,执行代码修改(apply_patch)
↓
运行测试套件 → 记录通过/失败
↓
清理容器关键设计:
- SandboxFusion:异步代码沙箱环境,沙箱以 pods 组成 worker pool,按容量拉取任务,异步并行避免慢线程拖累吞吐
- 并发更多由"工具调用限流"决定,而非"Docker 数量 = 并发数"
- 即便只起 1 个 server 容器,也可在内部用多 worker 处理并发;横向起多个 server 容器则做负载均衡
20.13.3 并发规模与调度瓶颈
沙盒并发规模差异极大——从个位数到单机两百以上、集群到上千/上万"沙箱单位"都存在。核心决定因素:
| 因素 | 影响 |
|---|---|
| 环境重量 | Code Interpreter(轻)vs 浏览器/OS 模拟(重),重环境启动慢、资源占用大 |
| 启动/重置成本 | Docker 秒级启动,完整 VM 分钟级,microVM 亚秒级 |
| GPU 推理吞吐 | RL 训练时,沙盒并发数需匹配 GPU 推理吞吐——沙箱开太多但 GPU 喂不满则浪费资源 |
调度瓶颈通常不在沙盒本身,而在工具调用的限流和序列化。SandboxFusion 通过 K8s Pod 级别的 worker pool 设计,以 pull-based 模式按容量拉取任务,避免了 push-based 调度中慢任务阻塞整个队列的问题。
20.13.4 microVM:更强隔离
E2B 等服务使用 microVM(微型虚拟机)替代 Docker,提供内核级隔离:
- 每个任务运行在独立轻量级 VM 中
- 启动时间 < 300ms(远快于完整 VM)
- Manus 等产品用 E2B 提供"虚拟电脑"体验
20.13.5 OpenEnv + TRL
OpenEnv 提供标准化的 Agent 环境接口,与 TRL(Transformer Reinforcement Learning)深度集成:
- 统一环境接口:定义标准的
reset()/step()/reward()API,使 RL 训练代码与具体沙盒后端解耦 - 后端可切换:同一份训练代码可以在 Docker、microVM、远程服务等不同沙盒后端间切换
- 与 TRL 的集成:直接嵌入 TRL 的训练循环,Agent 的环境交互结果作为 RL 奖励信号回传给策略更新
20.14 研究视角
Agent 研究的开放问题与未来方向:评估标准、安全性与规模化挑战。
20.14.1 Shunyu Yao:从训模型到用模型
ReAct 论文第一作者 Shunyu Yao 的几个核心洞见:
AI 的"上半场"与"下半场":
- 上半场:核心是方法——如何训练更强模型(BERT → GPT 的演进)
- 下半场:核心是任务——有了强大通用模型后,用它解决什么问题
推理即泛化:语言 Agent 与传统 Agent 的本质区别在于推理能力。传统 RL Agent 需要大量样本才能泛化到新环境;LLM Agent 通过推理可以快速适应未见过的任务。
ReAct 的启示:研究如何更好地"使用"模型,而不仅是"训练"模型,是极具价值的方向。当时学术界对 Prompting 是否是"真正的研究"存疑,但事实证明 ReAct 架构已成为构建 Agent 最主流的方法之一。
20.14.2 ProAgent:零样本多智能体协调
ProAgent(北京大学)聚焦于零样本多智能体协调——在没有联合训练的情况下,多个 Agent 如何协调完成共同任务。与 MARL 需要大量联合训练不同,ProAgent 利用 LLM 的推理能力和 Theory of Mind 在推理时完成协调。
20.14.3 控制论视角
将 Agent 系统类比为闭环控制系统:
期望状态(目标)
↓
控制器(LLM)
↓
执行器(工具调用)
↓
被控系统(真实世界)
↓
传感器(观察/反馈)
↑__________________|
(反馈回路)这一视角的启示:
- 稳定性:Agent 需要避免振荡(在多个状态间来回切换而不收敛)
- 鲁棒性:面对不确定性仍能完成任务
- Prompt Learning ≈ Policy Update:反馈回路驱动的策略迭代
20.14.4 ARC-AGI 与程序合成
ARC-AGI 是测试抽象推理能力的基准——给定少量颜色网格的输入输出示例,推断变换规则并泛化到新输入。开源求解器(如 poetiq-arc-agi-solver)通常结合视觉特征提取、程序合成和 MCTS 搜索。
20.14.5 来自一线的经验
LLM 提供了两种能力:记忆能力(来自训练语料)和推理能力(来自对齐)。构建 Agent 时我们希望 AI 只用推理能力,通过 tool call 获取上下文执行任务。但 AI 总是会把记忆混进去,导致幻觉——尤其是上下文与 AI 认为的常识差别较大时。
关于 Workflow 设计:
- 复杂的 prompts 对应较高的认知负荷,要适配模型能力——任务拆分对应着 workflow 节点设计
- 试图 principled 地设计 prompts,避免 case by case 的补丁
- 设计 workflow 基于现代 LLM 框架(如 LangGraph)反而是相对容易的,调 prompts 可能花费更多时间
古代炼金术的问题不在于化学没有用,而在于人们妄图欺骗自己——只要用正确的咒语(prompt),神奇的化学就能变成点石成金的核物理。今天我们对 LLM 的困惑,与此并无二致。
本章小结
本章系统探讨了高级 Agent 话题,涵盖从理论基础到工程实践的完整图景:
- Multi-Agent 系统:AOP 框架、通信拓扑、Theory of Mind、辩论机制——协作的核心是信息共享与意图推理
- 推理与规划:演绎/归纳/溯因三种推理模式是 Agent 智能的基础;"推理即泛化"是语言 Agent 区别于传统 Agent 的本质
- 世界模型:从"预测 token"到"预测后果"——内部模拟使 Agent 能在行动前评估方案
- 任务规划:DAG 任务图 + To-do List 是管理复杂任务的工程化方案
- PDDL:形式化规划语言提供最优性保证,与 LLM 结合实现"可解释的最优规划"
- 行为树:模块化、优先级抢占、反应式——机器人与游戏 AI 的经典决策架构
- MCTS:UCB → UCT → PUCT 的演进,NN+MCTS 是 AlphaGo 级系统的核心引擎
- DreamCoder:Wake-Sleep 循环 + 库学习,"压缩即智能"的神经符号范例
- 自进化 Agent:提示词优化 = 文本梯度下降;反思、自指令、RL 是三条自进化路径
- 多模态 Agent:SoM、PIVOT、SAM 系列为 Agent 赋予视觉感知和精准定位能力
- 具身智能:RGB-D、点云、Entity/碰撞检测、IMU、场景图、VLM → VLA、Anywhere3D-Bench——让 Agent 从数字世界走进物理世界
- Agentic RL:SWE-bench、tau-bench、Cursor Tab RL、DeepResearch(含 step-level async RL 训练闭环)代表多类重要的 Agent 评测与训练范式
- 沙盒环境:Docker / microVM / OpenEnv+TRL 提供安全、可重置、可规模化的评测与训练基础设施
- 研究视角:任务中心、推理即泛化、控制论视角——多角度理解 Agent 的本质
延伸阅读
- Multi-Agent Collaboration: Harnessing the Power of Intelligent LLM Agents
- ReAct: Synergizing Reasoning and Acting in Language Models
- DreamCoder: Bootstrapping Inductive Program Synthesis with Wake-Sleep Library Learning
- ProAgent: Building Proactive Cooperative Agents with Large Language Models
- PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs
- Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
- SIMA: Scaling Instructable Agents Across Many Simulated Worlds
- SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
- Cursor Tab: Training a Tab Model with Reinforcement Learning
- Fast Downward 规划器
- py_trees 文档
- ARC-AGI 挑战
- E2B 沙盒文档
- OpenEnv: TRL Integration for Training LLMs with Environments
- Qwen-VL 技术报告