附录 A:开发工具链
本附录目标:系统梳理 GenAI 工程实践中所需的开发基础设施。从容器化环境、Python 包管理、AI 加速硬件选型,到版本控制、并发编程、语言特性、Web 前端与软件工程实践,构建一份可直接上手的工具链参考手册。
A.1 Docker 开发环境
Docker 将"在我机器上能跑"变成了"在任何机器上都能跑"。对于 GenAI 工程师而言,Docker 不仅是部署工具,更是搭建 GPU 训练/推理环境的核心基础设施。
A.1.1 核心概念:镜像与容器
镜像(Image)是静态的只读模板,类似面向对象编程中的"类(Class)";容器(Container)是镜像的运行实体,顶层可读写,类似"实例化对象"。
docker run = docker create + docker startdocker create 基于镜像创建容器(处于 Created 状态,未运行任何进程),docker start 启动容器中的主进程。两条命令的组合 docker run 是日常使用最多的入口。
常用容器操作速查:
docker start -ai <容器名> # 唤醒并以交互方式接管(-a attach, -i interactive)
docker exec -it <容器名> bash # 在已运行的容器内额外启动一个新进程
docker ps -a | grep <关键字> # 定位具体容器
docker logs <容器名> # 查看容器运行日志A.1.2 磁盘挂载与临时环境
绑定挂载(Bind Mount) 将宿主机目录与容器内目录映射到同一块物理磁盘空间,写入立即互通:
-v /home/user/downloads:/app/data当程序在容器的 /app/data 中写入文件时,该文件会立刻出现在宿主机的 /home/user/downloads 下。
临时环境(Ephemeral Environment) 是工程实践中常见的"阅后即焚"模式:
docker run -it --rm \
-v "$PWD":/work -w /work \
node:20 bash| 参数 | 含义 |
|---|---|
-it | 交互式终端 |
--rm | 容器退出后自动销毁 |
-v "$PWD":/work | 挂载当前宿主机目录到容器内 /work |
-w /work | 设定容器内工作目录 |
node:20 | 指定镜像版本 |
bash | 容器启动后运行的第一个进程 |
这种模式的价值在于环境隔离(无需 nvm 切换 Node 版本)和干净整洁(退出后所有环境依赖和缓存消失,只留挂载目录中的产物)。
持久化容器:去掉 --rm,给容器命名,后续可反复进入:
docker run -it --name codexbox -v "$PWD":/work -w /work node:20 bash
# 下次重新进入
docker start -ai codexboxA.1.3 多容器编排:Docker Compose
复杂系统通常由多个服务协同工作(前端、后端、数据库、缓存等)。compose.yml 将所有服务统一描述:
services:
frontend:
...
backend:
...
volumes:
...执行 docker compose up 后,所有服务同时拉起。Dockerfile 定义单个镜像的构建过程,Compose 则编排多个容器的协作关系。
A.1.4 GPU 容器化:以 verl 训练框架为例
以 verl(分布式强化学习训练框架)为例,展示 GPU 容器化开发的完整工作流。
创建 GPU 容器
docker create \
--runtime=nvidia --gpus all \
--net=host \
--shm-size="10g" \
--cap-add=SYS_ADMIN \
-v .:/workspace/verl \
--name verl \
<image:tag> \
sleep infinity关键参数解读:
| 参数 | 含义 |
|---|---|
--runtime=nvidia --gpus all | 使用 nvidia-container-runtime,向容器暴露宿主机所有 GPU。若只需特定显卡,写 --gpus '"device=0,1"' |
--net=host | 容器直接使用宿主机网络栈,共用 IP 和端口,取消网络隔离 |
--shm-size="10g" | 共享内存大小(容器内执行 df -h /dev/shm 查看) |
-v .:/workspace/verl | 宿主机当前目录 bind mount 到容器 |
sleep infinity | 赋予容器一个永不结束的主进程,使其无限期保持"运行中"状态 |
sleep infinity的本质:加与不加的区别在于容器启动后是"长久驻留后台待命",还是"执行完镜像默认任务后瞬间退出"。即使经过docker stop再docker start,容器仍会保持sleep infinity的性质。
驱动与 CUDA 的分离原理
容器与宿主机共享 NVIDIA 内核驱动(/dev/nvidia* 设备映射进容器),但 CUDA 工具包(Runtime API / libcudart.so / nvcc)完全独立,由 Dockerfile 中的 FROM nvidia/cuda:12.x-devel-ubuntu22.04 决定。可分别在宿主机和容器内执行 nvidia-smi 验证驱动版本一致,而 nvcc --version 可能不同。
# 宿主机
ls -l /dev/nvidia*
docker info | grep -i runtime
# 容器内
ls -l /dev/nvidia*常用运维命令
docker start verl # 启动
docker exec -it verl bash # 进入
docker stop verl # 停止
docker top verl # 查看容器内运行进程
docker ps -a | grep verl # 状态查看
docker stats --no-stream verl # 资源查看
docker rm -f verl # 删除(谨慎)环境验证
nvidia-smi
python -c "import torch; print(torch.__version__)"
pip show verl
pip show vllm个性化创建示例(挂载 HuggingFace 缓存)
CACHE_REAL="$(readlink -f ~/.cache)"
docker create \
--runtime=nvidia --gpus all --net=host --shm-size="10g" --cap-add=SYS_ADMIN \
-v "$PWD:/workspace/verl" \
--mount type=bind,src="$CACHE_REAL",dst=/root/.cache \
-e HF_HOME=/root/.cache/huggingface \
-e TRANSFORMERS_CACHE=/root/.cache/huggingface \
--name verl-vllm \
--hostname verl \
<image:tag> \
sleep infinityIDE 远程连接:在 Cursor 中使用 anysphere.remote-containers 插件(而非 VS Code 官方的 ms-vscode-remote.remote-containers),可像本地开发一样操作容器内代码。VS Code 用户使用后者。
多实例部署(端口偏移模式)
通过宿主机端口偏移,在同一台机器上运行多个同类型容器实例:
# 实例 1:宿主机 5058 → 容器 5056
docker run -d -t --gpus "device=0" \
-e NVIDIA_DRIVER_CAPABILITIES=all \
-p 5058:5056 -p 50054:50052 -p 8304:8302 \
--name pool_0_5058 xx:xx
# 实例 2:宿主机 5059 → 容器 5056
docker run -d -t --gpus "device=0" \
-p 5059:5056 -p 50055:50052 -p 8305:8302 \
--name pool_0_5059 xx:xx训练工作流初始化
进入容器后,通常还需要登录模型仓库和实验追踪平台:
huggingface-cli login # 登录 HuggingFace(需要 Access Token)
huggingface-cli whoami # 验证登录状态
wandb login # 登录 Weights & Biases(实验追踪)注意
docker run --rm不加-it时的行为:如果镜像的默认 CMD 是交互式进程(如 bash),容器会因为没有 TTY 输入而瞬间退出并被销毁,整个过程不会产生任何实质性效果。
Docker 运维排查
docker ps -a | grep xxx # 定位具体容器
docker logs xxx # 查看容器运行日志A.2 环境配置:Ubuntu/macOS、uv 包管理
高效的开发环境配置是一切工程实践的起点。本节覆盖系统级常用操作和现代 Python 包管理工具 uv。
A.2.1 系统级常用操作
终端效率(macOS iTerm2)
| 快捷键 | 功能 |
|---|---|
Cmd+D | 水平分屏 |
Cmd+Shift+D | 垂直分屏 |
Cmd+Shift+Enter | 放大/还原当前面板 |
Cmd+Alt+箭头 | 切换面板 |
进程与端口排查
sudo lsof -i :8000 # 查看占用 8000 端口的进程(lsof = List Open Files, -i = internet)
ps -fp $PID # 查看指定进程详情文件同步:rsync 替代 scp
rsync -av test/src test/dst/rsync 的核心优势在于增量传输:只传有变化的部分(默认按大小/时间判断),大文件修改一小部分也无需重传整个文件。加 --delete 可做镜像同步(目标端删除源端已不存在的文件,慎用)。
A.2.2 uv:现代 Python 包管理器
uv 是用 Rust 实现的 Python 包管理器,集成了版本管理、虚拟环境、项目管理和工具安装,速度远超 pip。
Python 版本管理
uv python list # 列出支持的 Python 版本(含已安装版本)
uv python install cpython-3.12 # 安装指定版本
uv run -p 3.12 hello.py # 用指定版本运行脚本
uv run -p 3.12 python # 交互式解释器项目初始化与依赖管理
uv init -p 3.12 hello-world # 创建工程(自动生成 pyproject.toml,自动 git init)
uv add pydantic_ai # 添加依赖(写入 pyproject.toml,自动创建 .venv)
uv remove xxx # 删除依赖(连带相关依赖一并移除)
uv sync # 同步环境(手动编辑 pyproject.toml 后执行)
uv lock # 锁定依赖版本
uv run main.py # 在项目虚拟环境中运行脚本
uv tree # 查看依赖树拿到别人的 uv 项目时,只需:
uv sync # 根据 pyproject.toml / uv.lock 同步依赖全局工具安装
uv tool 安装的工具在整个系统中全局可用,不污染项目虚拟环境:
uv tool install ruff # 代码检查工具
uv tool install shell-gpt # AI 命令行助手
uv tool list # 查看已安装的全局工具A.3 硬件指南:GPU/NPU、CUDA Core vs Tensor Core、显存
理解硬件是选卡和性能调优的基础。本节从计算单元、存储层次到实际推理/训练场景,建立对 AI 加速硬件的系统认知。
A.3.1 CPU、GPU 与 NPU 的分工
| 硬件 | 优势 | 劣势 | 适合场景 |
|---|---|---|---|
| CPU | 强控制逻辑、低延迟单线程 | 并行度低,算力密度低 | 通用计算、逻辑控制 |
| GPU | 大规模并行,显存带宽大 | 能效相对 NPU 低 | LLM 训练/推理(当前主流) |
| NPU | 能效极高(Performance/Watt) | 内存小,通用性弱 | 端侧日常 AI 任务(语音识别、Face ID 等) |
GPU 的演进脉络:传统 GPU 的着色器核心(Shader Cores)为图形渲染设计,擅长向量运算(vector operations);而现代 LLM 需要的是矩阵乘法(Matrix Multiplication),这催生了专用的 Tensor Core。
TPU(Tensor Processing Unit)是 Google 的 AI 专用 ASIC,为 Transformer 中的
A.3.2 CUDA Core 与 Tensor Core
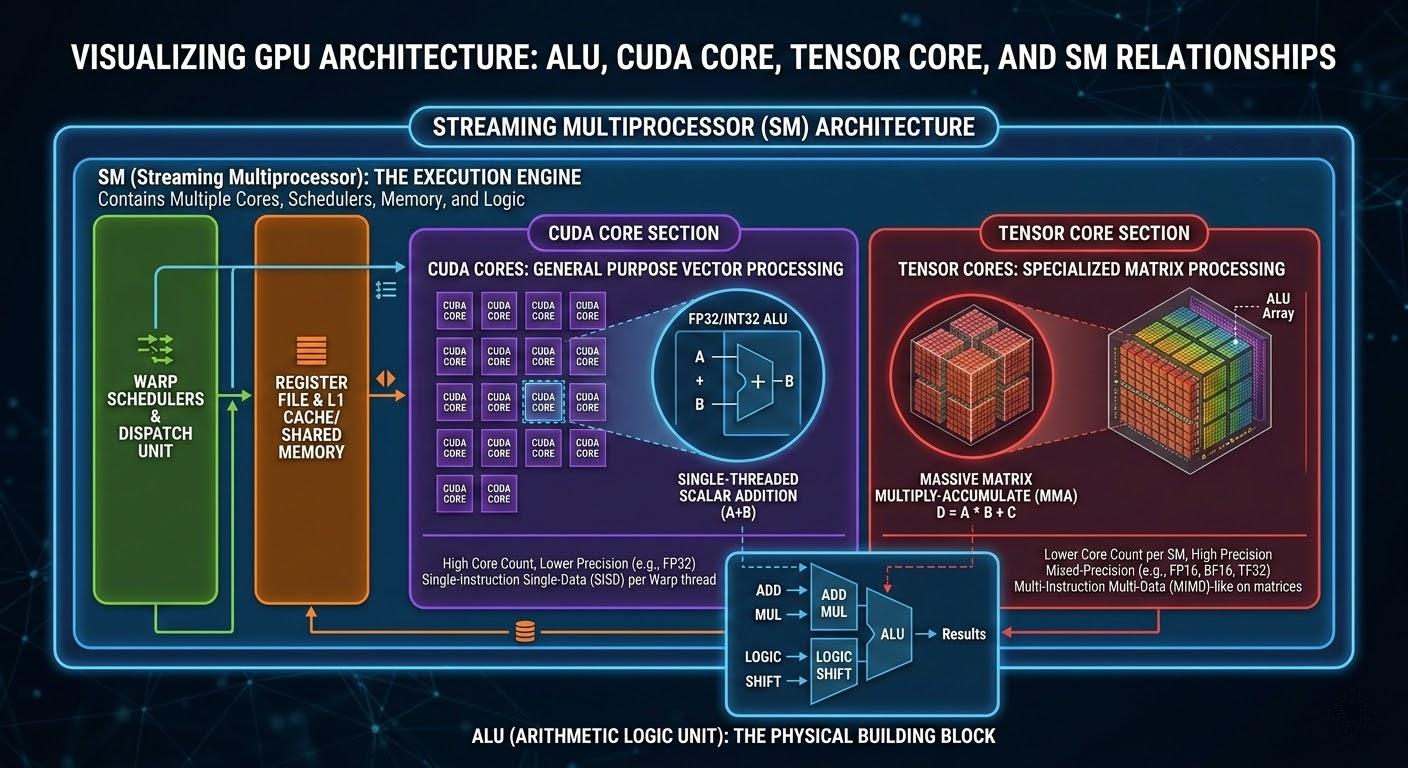
CUDA Core:GPU 内部最微小的算术逻辑单元(ALU),执行标量级 FP32/INT32 运算。一个 CUDA Core 在一个时钟周期内只为一个线程处理一个基础操作(如 FMA:
Tensor Core:自 Volta 架构引入的专用矩阵计算硬件单元。如果说 CUDA Core 执行一维标量计算,Tensor Core 则实现了二维矩阵计算——单时钟周期内吞下一个
在 LLM 训练和推理中,绝大部分算力(TFLOPS)由 Tensor Core 提供。CUDA Core 则负责非线性操作(ReLU 激活、LayerNorm、向量点积等)。
SM(Streaming Multiprocessor) 是 GPU 内部较大的执行/调度单元,内含独立的指令缓存、Warp 调度器、寄存器文件、L1 缓存/共享内存,以及大量 CUDA Core 和 Tensor Core。一个 SM 在逻辑层级上大致对应一个 CPU Core(但采用超宽 SIMD 架构)。
以 RTX 5090 为例:21,760 个 CUDA Core / 170 个 SM = 每个 SM 含 128 个 CUDA Core。
A.3.3 显卡核心参数
五大核心指标:
- 显存容量(GB):决定能装下多大的模型。7B 参数 FP16 模型需约 14 GB。
- 算力(TFLOPS):由 Tensor Core 的数量和代数决定,sparse 矩阵可进一步加速。
- 显存带宽(GB/s):显存每秒能向计算核心搬运多少数据。
- 卡间通信带宽:NVLink(高速直连)vs PCIe(通过 CPU 中转),决定多卡并行效率。
- 精度支持:与架构直接相关——A100 最低 BF16;RTX 4090/H100 支持 FP8;RTX 5090 新增 FP4。
主流 GPU 对比(LLM 研究视角)
| 特性 | RTX 4090 | RTX 5090 | A100 SXM | H100 SXM | H200 | M4 Max |
|---|---|---|---|---|---|---|
| 显存容量 | 24 GB | 32 GB | 80 GB | 80 GB | 141 GB | 最高 128 GB(UMA) |
| 显存带宽 | 1,008 GB/s | 1,792 GB/s | 2,039 GB/s | 3,350 GB/s | 4,800 GB/s | 546 GB/s |
| 显存类型 | GDDR6X | GDDR7 | HBM2e | HBM3 | HBM3e | LPDDR5X |
| 显存位宽 | 384-bit | 512-bit | 5,120-bit | 5,120-bit | 6,144-bit | 512-bit |
| FP16 算力 | 165 TFLOPS | 210 TFLOPS | 312 TFLOPS | 989 TFLOPS | 989 TFLOPS | ~35 TFLOPS |
| CUDA Cores | 16,384 | 21,760 | 6,912 | 16,896 | 16,896 | N/A(40 GPU Cores) |
| Tensor Cores | 512(4代) | 680(5代) | 432(3代) | 528(4代) | 528(4代) | N/A(16 NPU Cores) |
| 卡间互联 | PCIe only | PCIe only | NVLink 600 GB/s | NVLink 900 GB/s | NVLink 900 GB/s | N/A |
| 典型功耗 | 450W | ~600W | 400W | 700W | 700W | ~70-100W |
出口管制版本:A800 是 A100 的阉割版,NVLink 带宽从 600 降至 400 GB/s(显存带宽未变);H800 是 H100 的阉割版,同样削减 NVLink。
卡间通信拓扑
nvidia-smi topo -m
# NV/NV# = NVLink连接(最快)
# PIX/PXB/PHB = PCIe连接(较慢)
# X = self卡间通信的两种模式:
- PCIe-only:GPU A <-> PCIe <-> CPU <-> PCIe <-> GPU B(经过 CPU 中转,带宽受限)
- NVLink:GPU A <-> NVLink Bridge/NVSwitch <-> GPU B(直连,最高 900 GB/s)
GPU 参数设置与查看
sudo nvidia-smi -i 0 -pl 400 # 将 0 号 GPU 功耗限制设为 400W
docker run --gpus all ubuntu nvidia-smi # 检测 Docker/NVIDIA 环境import torch
print(torch.cuda.get_device_capability())
# (8, 9) => Ada Lovelace (RTX 4090)
# (9, 0) => Hopper (H100)
print(torch.cuda.get_arch_list())A.3.4 LLM 推理:为什么显存带宽是瓶颈
LLM 推理分两个阶段,性质截然不同:
| 阶段 | 操作类型 | 瓶颈 | 特点 |
|---|---|---|---|
| Prefill(处理 Prompt) | 矩阵-矩阵乘法(GEMM) | 算力(Compute Bound) | 一次性并行处理所有输入 Token |
| Decode(逐 token 生成) | 矩阵-向量乘法(GEMV) | 显存带宽(Memory Bound) | token by token,自回归生成 |
Decode 阶段的算术强度分析(Batch=1)
生成每个 Token 时,GPU 必须将模型全部权重从 VRAM 搬运到计算核心,然后做一次前向传播:
- 搬运量(Bytes):模型参数量
,精度 2 Bytes(FP16),需搬运 Bytes - 计算量(FLOPs):约
FLOPs(每个参数对应一次乘法和一次加法)
而以 H100 为例,硬件理想比率为:
Decode 阶段的算术强度仅为 ~1,远低于硬件理想值,算力被浪费了 99% 以上,系统被显存带宽卡死。
生成速度估算
以 RTX 4090 运行 Qwen-7B(FP16,14 GB)为例:
- 搬运时间 = 14 GB / 1,008 GB/s
13.9 ms/token - 计算时间 = 14 GFLOPs / 83,000 GFLOPs/s
0.17 ms/token
计算只占搬运时间的约 1%,GPU 的算力几乎在"空转等数据"。
训练 vs 推理的硬件选型
- 训练:计算密集型 + 通信密集型 → 看重算力和 NVLink 带宽
- 推理:显存带宽密集型 → 看重显存带宽和容量
A.3.5 内存层次结构
易失性存储(RAM)与非易失性存储(硬盘)
- DRAM(Dynamic RAM):独立于 CPU/GPU 芯片,off-chip
- DDR, LPDDR, GDDR, HBM 都属于 DRAM 家族
- SRAM(Static RAM):集成在 CPU/GPU 芯片内部的 L1/L2/L3 Cache,on-die,极快但容量极小
- 硬盘:HDD → SSD(Flash 材质)
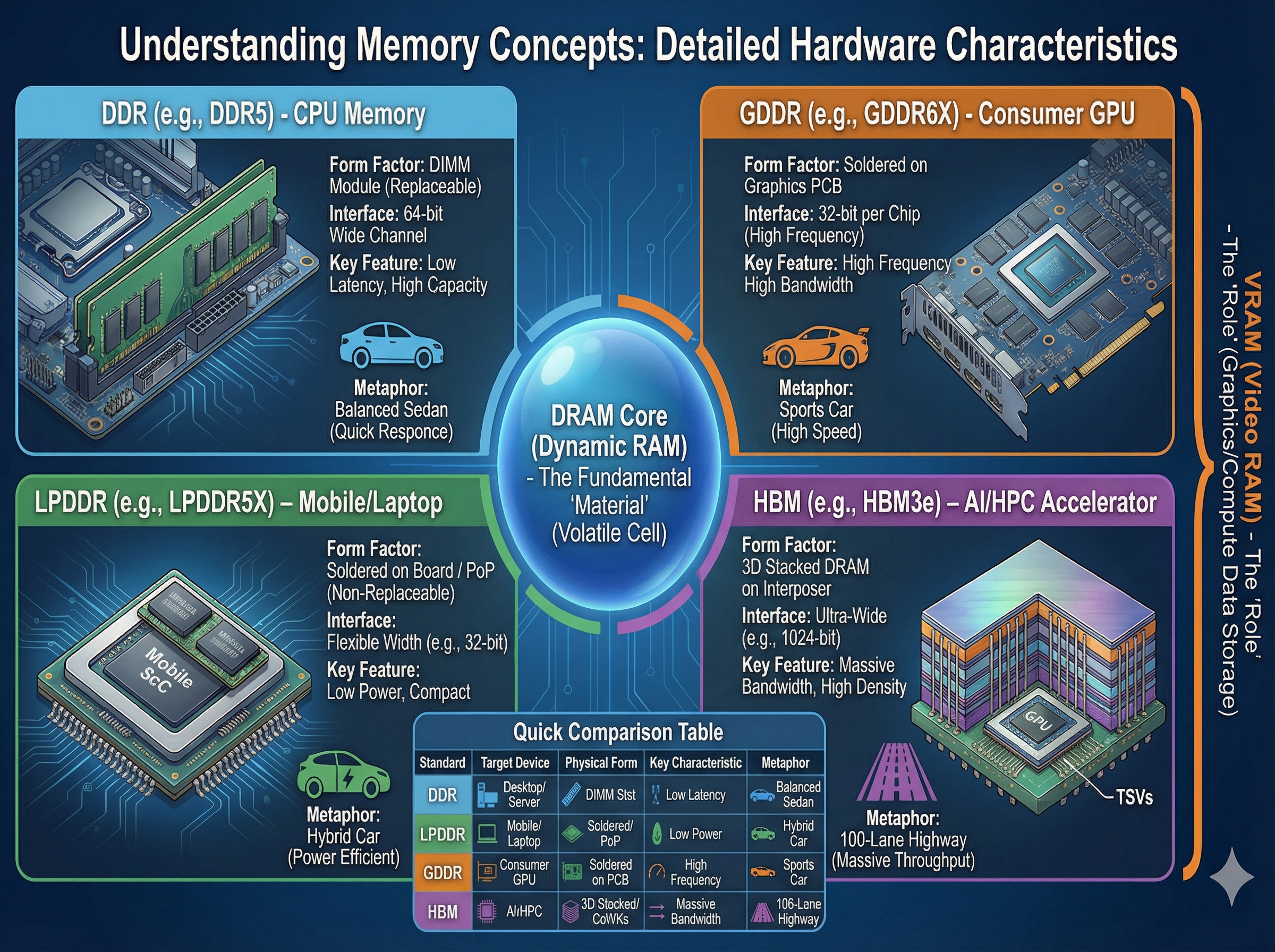
四种 DRAM 对比
| 类型 | 用途 | 特点 |
|---|---|---|
| DDR5 | CPU 内存(PC/服务器) | 标准内存条,可插拔 |
| LPDDR5/5X | Apple M 系列、手机 | 低功耗,焊在 SoC 封装内,不可更换 |
| GDDR6X/7 | 消费级显卡(4090/5090) | 高频率取胜(21~28 Gbps),焊在显卡 PCB 上 |
| HBM2e/3/3e | 数据中心 GPU(A100/H100/H200) | 3D 堆叠 + 硅通孔(TSV),极宽总线(5,120-bit),靠"路宽"取胜 |
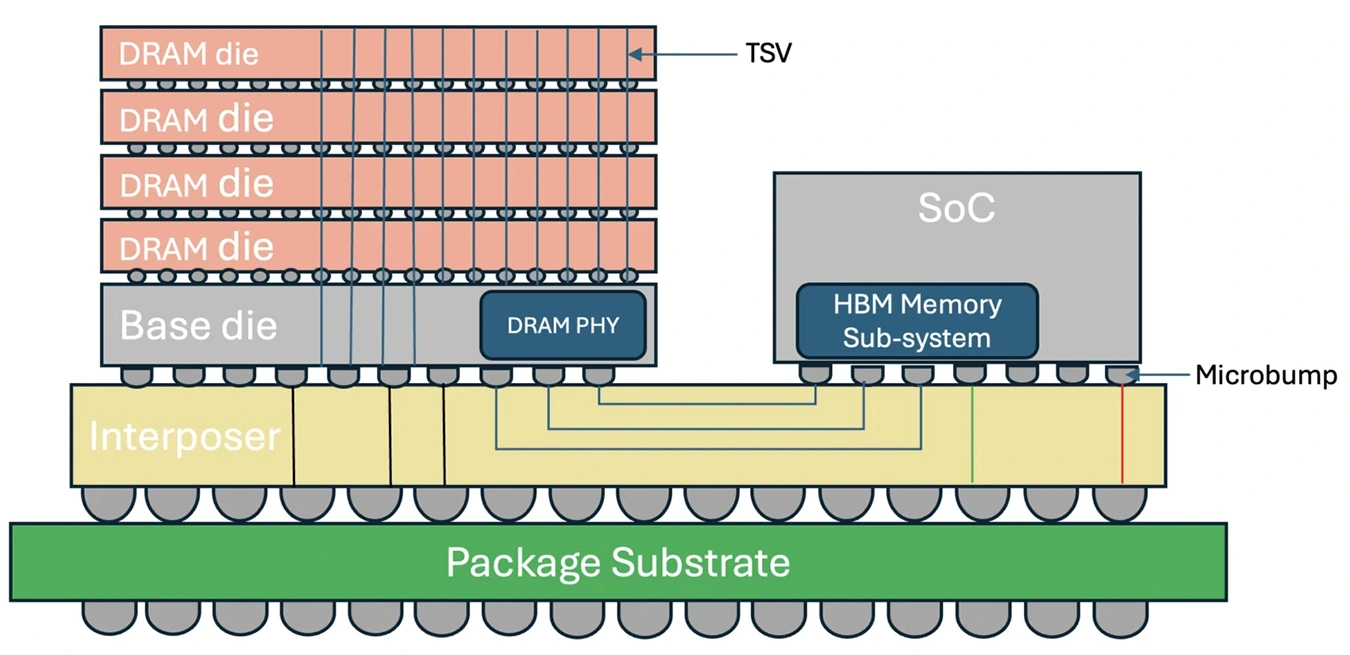
GDDR 的策略是"车速快"(高频率),HBM 的策略是"车道多"(超宽位宽)。GDDR 单芯片可能只有 32-bit 位宽,而 HBM 单堆栈就是 1,024-bit。
CPU+RAM vs GPU+VRAM 的形态差异
为什么显存必须焊在 GPU 旁边?根本原因是 GPU 对带宽的极致渴求改变了物理形态:
- CPU + RAM:通过主板 DDR 插槽连接,距离远,带宽低(双通道 128-bit)
- GPU + VRAM:显存颗粒焊在 GPU 芯片旁的 PCB 上,距离极近,位宽高达 384-bit(4090)
一块显卡实质上是一个自包含的计算子系统——GPU Die 类似 CPU,显存颗粒类似内存条,显卡 PCB 类似主板。
A.3.6 Apple 统一内存架构(UMA)
Apple M 系列芯片采用 SoC 架构,将 CPU、GPU、Neural Engine(NPU)、安全隔区等组件集成在同一块硅片上。最核心的设计是统一内存架构(UMA):
- 传统架构中,CPU 和独立 GPU 各自拥有独立内存(RAM 和 VRAM),数据在它们之间通过 PCIe 总线拷贝——这是主要的性能损耗来源
- M 系列芯片中,CPU、GPU、NPU 共享同一个高速内存池。GPU 需要处理 CPU 刚解压的数据时,只需读取同一个内存地址(零拷贝,Zero-copy),无需数据搬运
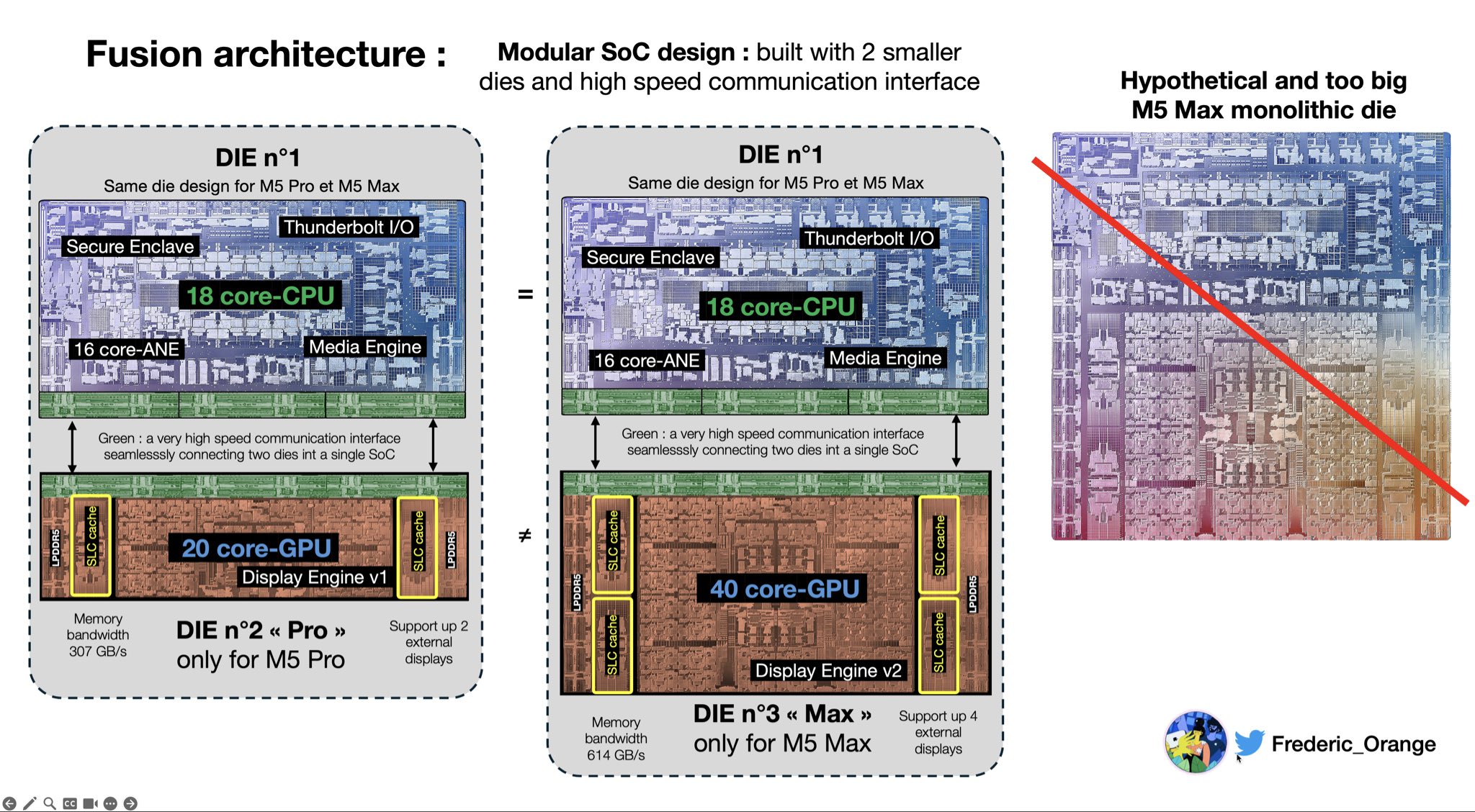
Apple GPU Core vs NVIDIA CUDA Core:苹果的 1 个 GPU Core 对应的不是 1 个 CUDA Core,而是 NVIDIA 的 1 个完整 SM。M5 的 40 个 GPU Core 内部各含大量 ALU、纹理单元和独立缓存。M5 代还在每个 GPU Core 内引入了 Neural Accelerator(专用矩阵乘法单元),类似 NVIDIA 的 Tensor Core。
M5 Fusion Architecture:M5 Pro/Max 不再是单一硅片,而是将两颗较小的晶粒(Die)通过先进封装与高速互连融合成逻辑上的单颗 SoC(Chiplet 技术,非对称 Die 设计),与 M3 Ultra 的对称拼接(UltraFusion)有本质区别。
M4 Max 在 LLM 推理中的独特价值:128 GB 统一内存可直接被 GPU 使用,是运行超大量化模型(如 Llama-3-70B 量化版)成本最低的方案,功耗仅为 NVIDIA 旗舰卡的 1/5 到 1/10,但纯算力差一个数量级,不适合从头训练。
A.4 Git/GitHub 高级用法
Git 是协作开发的基石。本节聚焦于 GenAI 工程中常见的高级操作与云端开发模式。
A.4.1 HEAD 状态与版本回退
detached HEAD:当 HEAD 直接指向具体 Commit ID(而非分支名)时产生。任何将 HEAD 移到具体提交哈希的操作都会触发此状态。
三种版本回退方式对比
| 命令 | 效果 | 历史 | 安全性 |
|---|---|---|---|
git reset --hard | 永久删除提交,指针回退 | 改变历史 | 危险 |
git revert | 创建新提交来撤销变更 | 保留历史 | 安全 |
git checkout <commit> | 临时切换到指定提交查看 | 不改历史 | 安全(但触发 detached HEAD) |
生产环境中强烈推荐
git revert:它通过创建新提交来"反向操作",不会篡改提交历史,对多人协作更安全。
A.4.2 GitHub Codespaces
GitHub Codespaces 是云端开发环境(cloud-based development environment)——托管在云端的 VS Code + Linux 开发主机。通过浏览器或本地 VS Code/Cursor 连接,代码和运行环境均在云服务器上。
适用场景:
- 临时需要特定环境(如特定 GPU 配置)
- 本地算力不足
- 多端协作、快速 onboarding
A.4.3 DNS 与网络排查
在开发中经常遇到网络连接问题,掌握基本的 DNS 排查能力很有必要:
nslookup ssh.github.com 8.8.8.8 # 使用 Google 公共 DNS(8.8.8.8)解析域名关键配置文件:
/etc/hosts:本地域名覆盖(优先级高于 DNS)/etc/resolv.conf:DNS 服务器配置
A.5 Python 多线程/异步:asyncio、GIL、concurrent
Python 并发编程是 GenAI 工程中的高频需求:批量调用 API、异步爬虫、并行数据处理。本节厘清三种并发模型的适用场景和核心机制。
A.5.1 GIL 与并发模型选择
Python 的 GIL(Global Interpreter Lock)是每个 Python 解释器实例都持有的一把全局锁——同一进程内同时只有一个线程能执行 Python 字节码。
| 并发方式 | 适用场景 | 并行能力 | 说明 |
|---|---|---|---|
threading | I/O 密集(网络、文件读写) | 伪并行(GIL 交替让出) | 线程共享内存 |
asyncio | I/O 密集(爬虫、Web 服务) | 单线程协程切换 | 更轻量,无锁竞争 |
multiprocessing | CPU 密集(数学计算、图像处理) | 真并行(独立进程,各自一把 GIL) | 进程独立内存 |
核心决策:I/O 密集用线程或协程,CPU 密集用多进程。多线程无法真正并行 CPU 密集任务。
A.5.2 asyncio:单线程协程并发
asyncio 是协程(Coroutine),在单线程内实现并发——所有协程共享同一个线程 ID。
Event Loop 工作原理
import asyncio
import time
async def toast_bread():
print("开始烤面包...")
await asyncio.sleep(3) # 遇到 await → 让出控制权给 Event Loop
print("面包烤好了")
async def brew_coffee():
print("开始冲咖啡...")
await asyncio.sleep(1)
print("咖啡冲好了")
async def main():
start = time.time()
await asyncio.gather(toast_bread(), brew_coffee()) # 并发注册
print(f"总耗时: {time.time() - start:.2f} 秒") # ~3s,非 4s
asyncio.run(main())执行流程:
asyncio.run(main())创建 Event Loop,将main()协程扔进 Loopasyncio.gather(...)将两个协程同时注册到 Looptoast_bread遇到await asyncio.sleep(3),让出控制权- Loop 切换到
brew_coffee,遇到await asyncio.sleep(1),也让出 - 1 秒后咖啡先完成,3 秒后面包完成——总耗时约 3 秒
await 的双重含义
resp = await client.get(url)- 对内(当前函数):红灯——强制暂停,等待网络响应,不会往下执行
- 对外(Event Loop):绿灯——通知 Loop "我在等 I/O,把 CPU 让给别人"
await 的目的是让你用写同步代码的逻辑,写出异步的程序。Python 自带的 requests 库是同步的,异步编程中通常用 httpx 或 aiohttp。
真实网络请求示例
import asyncio
import httpx
import time
async def fetch_price(platform, delay):
print(f"[发送请求] 正在连接 {platform}...")
async with httpx.AsyncClient() as client:
resp = await client.get(f"https://httpbin.org/delay/{delay}")
print(f"[接收响应] 拿到 {platform} 的数据了!")
return f"{platform}: 99元"
async def main():
start = time.time()
results = await asyncio.gather(
fetch_price("京东", 5),
fetch_price("淘宝", 3),
fetch_price("拼多多", 2)
)
for r in results:
print(r)
print(f"总耗时: {time.time() - start:.2f} 秒") # ~5s,非 10s
asyncio.run(main())线程 ID 验证:协程共享同一线程
可以通过 threading.get_ident() 直观验证所有协程运行在同一个线程中:
import asyncio
import threading
async def toast_bread():
print(f"[面包] 线程 ID: {threading.get_ident()}")
await asyncio.sleep(3)
print(f"[面包] 烤好了,线程 ID: {threading.get_ident()}")
async def brew_coffee():
print(f"[咖啡] 线程 ID: {threading.get_ident()}")
await asyncio.sleep(1)
print(f"[咖啡] 冲好了,线程 ID: {threading.get_ident()}")
async def main():
print(f"[主程序] 线程 ID: {threading.get_ident()}")
await asyncio.gather(toast_bread(), brew_coffee())
asyncio.run(main())
# 所有输出的线程 ID 完全相同——单线程并发的铁证信号量控制并发数
semaphore = asyncio.Semaphore(2) # 最多同时运行 2 个协程
async def limited_task():
async with semaphore:
await do_work()asyncio 适合 I/O 密集型任务。如果在 async 函数里做 CPU 密集计算(如计算圆周率),整个程序会卡死——单线程 CPU 被占用,Event Loop 无法调度其他任务。
A.5.3 concurrent.futures:线程池
concurrent.futures 提供高层线程池/进程池接口,适合将同步的 I/O 密集函数并行化。
基本用法:并行查询多个 API
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
def query_api(api_name, delay):
time.sleep(delay)
return f"{api_name} result"
with ThreadPoolExecutor(max_workers=3) as executor:
futures = {
executor.submit(query_api, name, delay): name
for name, delay in [("OpenAI", 2), ("Cerebras", 1), ("Memory", 0.5)]
}
for future in as_completed(futures, timeout=10): # 10 秒内若仍有未完成任务,迭代器抛 TimeoutError
api_name = futures[future]
try:
result = future.result()
print(f"{api_name}: {result}")
except Exception as e:
print(f"{api_name} failed: {e}")
# 输出顺序: Memory -> Cerebras -> OpenAIFuture 对象生命周期
submit -> PENDING -> RUNNING -> FINISHED / CANCELLED / EXCEPTIONfuture.done():是否完成future.result():获取结果(阻塞直到完成)future.cancel():只能取消尚未开始运行的任务,对正在运行的任务返回False
异步检查模式(非阻塞)
在需要"提交任务后继续做其他事"的场景下(如游戏循环中异步调用 LLM),可利用 future.done() 做非阻塞检查:
executor = ThreadPoolExecutor(max_workers=2)
def llm_generate(instruction):
time.sleep(2)
return f"Action for: {instruction}"
# 迭代 N:提交任务,不等结果
future = executor.submit(llm_generate, "拿起苹果")
# 迭代 N+1:检查是否完成
if future.done():
result = future.result() # 此时不阻塞
else:
pass # 返回占位动作,继续下一帧带进度条的批量处理
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor, as_completed
with ThreadPoolExecutor(max_workers=8) as executor:
future_to_file = {
executor.submit(process_file, f): f for f in file_list
}
with tqdm(total=len(file_list), desc="Processing") as pbar:
for future in as_completed(future_to_file):
success, path, error = future.result()
pbar.update(1)A.6 Python 高级特性与数据结构
本节覆盖闭包、堆、双端队列等 Python 进阶特性,这些在 GenAI 工程中频繁出现(回调函数、调度队列、流式处理等)。
A.6.1 闭包(Closure)
闭包是"一个函数对象",它引用了来自外层作用域的自由变量,并且这些变量在函数定义的作用域结束后仍然存在。
核心用途:隔离状态,避免全局变量污染
def make_id_generator(prefix):
n = 0
def next_id():
nonlocal n
n += 1
return f"{prefix}{n:04d}"
return next_id
user_id = make_id_generator("U")
order_id = make_id_generator("O")
print(user_id(), user_id(), user_id()) # U0001 U0002 U0003
print(order_id(), order_id()) # O0001 O0002 <- 独立状态,不受 user_id 影响如果用全局变量替代,不同类型的 ID 会互相"污染"——这就是闭包解决的核心问题。
延迟绑定(Late Binding)陷阱
闭包捕获的是变量的引用(绑定),而非创建时的快照值。闭包在被调用时才去外层作用域查找变量的当前值:
def make_funcs_wrong():
funcs = []
for i in range(3):
funcs.append(lambda: i) # 捕获的是变量 i 的引用
return funcs
fs = make_funcs_wrong()
print([f() for f in fs]) # [2, 2, 2] <- 全部看到循环结束后的 i=2修正方法:用默认参数捕获当时的值
def make_funcs_right():
funcs = []
for i in range(3):
funcs.append(lambda i=i: i) # 默认参数在定义时求值,固化当时的值
return funcs
print([f() for f in make_funcs_right()]) # [0, 1, 2]注意:使用默认参数后,函数不再是闭包(
__closure__为None),而是通过参数默认值绑定。
nonlocal vs global
nonlocal:指向最近一层外部函数作用域的变量global:指向模块级全局作用域
A.6.2 数据结构:heapq 最小堆
Python 的 heapq 模块提供最小堆操作,底层是数组表示的完全二叉树。
堆的数组索引关系:
- 父节点索引:
(k - 1) // 2 - 左子节点索引:
2k + 1 - 右子节点索引:
2k + 2 data[0](根节点)永远是最小值
import heapq
data = [3, 1, 4, 1, 5, 9, 2, 6]
heapq.heapify(data) # in-place 堆化,O(n)
# data = [1, 1, 2, 3, 5, 9, 4, 6]
heapq.heappop(data) # 弹出并返回最小值,O(log n)
heapq.heappush(data, 0) # 插入新值,O(log n)
heapq.heapreplace(data, 7) # 弹出最小值并插入新值(比 pop+push 更高效)实战:任务调度——最早空闲 Worker 优先
import heapq
# (可用时间, worker名) 作为堆元素,按可用时间排序
workers = [(0, 'Worker A'), (0, 'Worker B'), (0, 'Worker C')]
heapq.heapify(workers)
tasks_duration = [10, 30, 5, 20, 10, 50]
for duration in tasks_duration:
available_time, worker = workers[0] # 堆顶 = 最早空闲的 worker
new_time = available_time + duration
print(f"分配任务(耗时{duration}s) -> {worker} (空闲: {available_time} -> {new_time})")
heapq.heapreplace(workers, (new_time, worker)) # 原地替换,维持堆结构heapreplace 的语义是"弹出堆顶 + 压入新值"一步完成,堆大小固定不变。
A.6.3 数据结构:deque 双端队列
from collections import deque
dq = deque(maxlen=3) # 有界队列,超出时自动丢弃最旧元素
dq.append(1) # 右端入队
dq.appendleft(0) # 左端入队
dq.popleft() # 左端出队:O(1),比 list.pop(0) 的 O(n) 快deque 的 popleft() 和 appendleft() 都是 O(1) 操作,而 list.pop(0) 需要移动全部元素,是 O(n)。在需要频繁从队列头部操作的场景(如滑动窗口、BFS)中,deque 是正确选择。
A.6.4 Queue(线程安全队列)
from queue import Queue
q = Queue()
q.put(item) # 入队(线程安全)
q.get() # 出队(线程安全,阻塞直到有元素)Queue 内部已做好加锁,适合多线程生产者-消费者模型;deque 是纯数据结构,多线程下需自行加锁。
A.7 Web 前端基础
GenAI 应用通常需要一个快速搭建的演示界面。Python 生态提供了两个轻量方案:Streamlit 和 Gradio,无需前端开发经验即可使用。
A.7.1 Streamlit:脚本即应用
Streamlit 采用"脚本化"思路——像写 Python 脚本一样写网页,每次用户交互都从头重跑脚本。适合数据仪表盘(Dashboard)。
import streamlit as st
st.title("大写转换器")
user_input = st.text_input("请输入文字")
if st.button("转换"):
st.write(user_input.upper())streamlit run streamlit_demo.pyA.7.2 Gradio:接口即应用
Gradio 以函数签名定义输入/输出接口,更适合 AI 模型演示。
import gradio as gr
def to_upper(text):
return text.upper()
demo = gr.Interface(fn=to_upper, inputs="text", outputs="text")
demo.launch()python gradio_demo.py| 框架 | 最适合 | 开发模式 |
|---|---|---|
| Streamlit | 数据仪表盘 | 脚本化,每次交互重跑 |
| Gradio | AI 模型演示 | 以函数签名定义 I/O 接口 |
A.7.3 Node.js 基础
Node.js 不是一门编程语言,而是让 JavaScript 在服务器端运行的运行时环境。
node index.js # 执行 JS 文件
npm init # 初始化 package.json(项目元数据与配置)package.json 记录项目名称、版本、程序入口、依赖及构建脚本,定义了如何构建、运行和管理 Node.js 程序。创建新项目时,npm init 会引导式补充配置信息。
A.8 设计模式与软件工程
良好的工程实践是将原型变为产品的关键。本节覆盖 GenAI 项目中高频使用的设计模式和协作开发规范。
A.8.1 单例模式(Singleton)
保证某个类全局只有一个实例,适用于线程池、数据库连接池等资源管理场景。
import threading
from concurrent.futures import ThreadPoolExecutor
class SimplePoolManager:
def __init__(self, max_workers=5):
self._executor = None
self._lock = threading.Lock()
def get_executor(self):
with self._lock: # 线程安全
if self._executor is None: # 懒初始化
self._executor = ThreadPoolExecutor(max_workers=5)
return self._executor
def submit(self, fn, *args, **kwargs):
return self.get_executor().submit(fn, *args, **kwargs)
# 使用
manager = SimplePoolManager()
future = manager.submit(lambda x: x**2, 10)
print(future.result()) # 100核心三要素:
- 单例:全局只有一个线程池实例,避免线程泛滥
- 懒初始化:第一次使用时才创建 executor,避免提前占用资源
- 线程安全:用
threading.Lock()保护初始化过程,防止并发创建多个实例
A.8.2 软件工程素养
测试层次
| 层次 | 英文 | 目标 |
|---|---|---|
| 单元测试 | Unit Testing | 测试最小功能单元(函数/方法) |
| 模块测试 | Component Testing | 测试一个独立模块的内部逻辑 |
| 集成测试 | Integration Testing | 测试多个模块组合后的行为 |
最佳实践:先独立实现功能并做单元测试,测试稳定后再集成到系统中。
面向对象复用原则
- 封装:类隐藏内部状态,只暴露必要接口
- 继承:复用父类逻辑,减少重复代码
A.8.3 代码风格工具链
| 工具 | 功能 | 自动修复 | 使用方式 |
|---|---|---|---|
| black | 格式化(空格、换行) | 是 | uv run black xx.py |
| ruff | 语法 + 风格检查(全能替代 flake8) | 是 | ruff check --fix xx.py |
| flake8 | 语法 + 基础风格 | 否(仅报错) | flake8 xx.py |
| pylint | 逻辑 + 质量 + 复杂度 | 否(仅报错) | pylint xx.py |
A.8.4 pre-commit 自动检查
pre-commit 在 git commit 时自动触发代码检查,确保提交的代码符合团队规范。
工作流程:Git 触发 .git/hooks/pre-commit 脚本 -> pre-commit 读取 .pre-commit-config.yaml -> 下载并在隔离环境中执行 hooks。
# .pre-commit-config.yaml
repos:
- repo: https://github.com/psf/black
rev: 23.x.x
hooks:
- id: black
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.x.x
hooks:
- id: ruff
args: [--fix]pre-commit install # 安装 hooks(仅需一次)
git commit ... # 自动触发 black / ruff 等检查A.8.5 技术栈补充
配置中心:分布式系统中常用 ETCD(分布式强一致键值存储)管理配置。其名字来源于 Linux /etc 目录(存放系统配置的标准位置)加上 "distributed" 的缩写。
本章小结
本附录系统梳理了 GenAI 工程师的开发工具链,要点回顾:
Docker:镜像/容器模型是基础;bind mount 实现宿主机-容器文件互通;GPU 容器化需
--runtime=nvidia,以 verl 训练框架为例建立持久化开发工作流;多容器用 Compose 编排。环境配置:
uv统一管理 Python 版本、虚拟环境与项目依赖,uv add/sync/run三命令覆盖日常工作流;rsync 做增量文件同步。硬件理解:CUDA Core 做标量运算,Tensor Core 做矩阵 MMA——LLM 的算力主要来自后者。推理的 Decode 阶段是带宽瓶颈(算术强度 ~1 FLOP/Byte),选卡优先看显存带宽和容量;训练看算力和 NVLink。HBM 靠"路宽"取胜,GDDR 靠"车速"取胜。Apple UMA 实现零拷贝,M4 Max 128 GB 统一内存是低成本大模型推理的独特方案。
Git/GitHub:
git revert比git reset --hard安全,保留历史;Codespaces 提供云端开发环境;DNS 排查用nslookup。Python 并发:GIL 导致多线程无法并行 CPU 密集任务;asyncio 协程在单线程内通过 Event Loop 实现 I/O 并发,
await是"对内暂停、对外让出";concurrent.futures线程池适合同步 I/O 函数的并行化。Python 特性:闭包延迟绑定陷阱——用默认参数固化循环变量值;heapq 最小堆实现优先队列和调度;deque 双端队列提供 O(1) 的头部操作。
Web UI:Streamlit 适合数据仪表盘(脚本即应用),Gradio 适合 AI 模型演示(接口即应用)。
软件工程:单例+懒初始化+线程安全三要素管理共享资源;测试分单元/模块/集成三层递进;black/ruff/pre-commit 保障代码质量和团队一致性。
延伸阅读
- CUDA C++ Programming Guide:NVIDIA 官方 CUDA 编程指南,理解 GPU 编程模型(Thread/Block/Grid)、内存层次和 Kernel 优化的权威参考。NVIDIA CUDA Docs
- Docker 官方文档:容器化开发的完整参考,涵盖 Dockerfile 编写、Compose 编排、网络与存储卷配置。Docker Docs
- uv 官方文档:Astral 团队维护的现代 Python 包管理器文档,覆盖项目管理、依赖解析和工具安装。uv Docs
- The Missing Semester of Your CS Education:MIT 课程,系统讲解 Shell、Git、Vim、tmux 等开发者日常工具链的高效用法。missing.csail.mit.edu
- Python asyncio 官方文档:协程、Event Loop、Task 和同步原语的完整参考,配合本附录 A.5 节阅读。Python asyncio Docs