第 2 章:线性代数与矩阵分析
Transformer 的每一步计算都是矩阵运算:注意力机制是
的矩阵乘法,前馈层是 的仿射变换,LoRA 微调是低秩矩阵分解,权重初始化依赖谱范数分析。本章从深度学习工程视角出发,系统梳理最常用的线性代数工具——从基本运算到特征分解、正定性判别、SVD 与低秩近似、谱范数与初始化策略,再到张量和图论基础。每个概念都配有数学推导、几何直觉和可运行的代码验证。
2.1 矩阵基本运算与 NumPy/SciPy 实践
本节建立向量与矩阵运算的几何直觉,并通过 NumPy 的广播机制、
ogrid等工具演示高效数值计算。这些基础操作在后续各节以及整本书中反复出现。
向量运算的几何含义
点积(Dot Product) 衡量两个向量的"对齐程度":
当两个向量方向完全一致时,点积取最大值;正交时为 0;方向相反时为最大负值。注意力机制中
叉积(Cross Product)
分母
矩阵乘法的多重视角
矩阵乘法
- 内积视角(逐元素):
,这是最基础的计算方式。 - 列变换视角:
的每一列是 的列的线性组合,组合系数由 的对应列给出。 - 外积之和视角:
,即若干秩 1 矩阵的叠加。
视角 3 尤其重要——它是 LoRA 低秩分解的直觉来源(详见第 2.4 节):一个秩为
NumPy 广播机制与 np.ogrid
NumPy 的广播机制(Broadcasting)允许不同形状的数组在运算时自动扩展维度,避免显式创建大矩阵,节省内存。np.ogrid 是利用广播的典型工具:
import numpy as np
height, width = 3, 4
y, x = np.ogrid[:height, :width]
# y: shape (3, 1) —— 列向量
# x: shape (1, 4) —— 行向量当对 y 和 x 进行运算时(如 y + x),NumPy 自动将它们"扩充"为完整的
print(y + x)
# [[0, 1, 2, 3],
# [1, 2, 3, 4],
# [2, 3, 4, 5]]整个过程中内存中只需存储
NumPy/SciPy 线性代数工具速查
NumPy 和 SciPy 提供了完整的线性代数操作接口,后续各节中的代码验证依赖于这些函数:
import numpy as np
from scipy import linalg
A = np.array([[2, 1], [1, 3]], dtype=float)
# 特征值与特征向量
eigvals, eigvecs = np.linalg.eigh(A) # 对称矩阵专用,保证实数特征值
# 奇异值分解
U, S, Vt = np.linalg.svd(A)
# 矩阵范数
norm_2 = np.linalg.norm(A, ord=2) # 谱范数(最大奇异值)
norm_F = np.linalg.norm(A, ord='fro') # Frobenius 范数
# 行列式与逆
det = np.linalg.det(A)
A_inv = np.linalg.inv(A)
# Cholesky 分解(要求正定)
L = np.linalg.cholesky(A) # A = L @ L.T这些函数在本章各节的数值实验中反复使用。在 PyTorch 中,对应的接口位于 torch.linalg 模块,API 命名高度一致。
2.2 特征值与特征分解
本节阐述特征值与特征向量的几何含义——"哪些方向只被缩放而不被旋转",以及特征分解(Eigendecomposition)在分析模型行为(如损失曲面的局部几何)中的作用。
特征值的几何直觉
对于方阵
则
直觉:线性变换
:沿该方向被放大 :沿该方向被压缩 :方向被翻转(同时可能伴随缩放)
特征值的代数性质
特征值蕴含了矩阵的全局信息:
- 行列式 = 特征值之积:衡量线性变换的"体积变换倍率"。若某个特征值为 0,则行列式为 0,矩阵奇异(不可逆)——存在某个方向被完全压扁。
- 迹 = 特征值之和:在优化中,Hessian 矩阵的迹反映了损失曲面在所有方向上的平均曲率。
import numpy as np
A = np.array([[4, 2], [1, 3]], dtype=float)
eigvals = np.linalg.eigvals(A)
print(f"特征值: {eigvals}") # [5. 2.]
print(f"特征值之积: {np.prod(eigvals)}") # 10.0
print(f"行列式: {np.linalg.det(A)}") # 10.0
print(f"特征值之和: {np.sum(eigvals)}") # 7.0
print(f"迹: {np.trace(A)}") # 7.0特征分解(Eigendecomposition)
实对称矩阵
其中
分解的含义:任何对称线性变换都可以拆解为"旋转到特征方向 → 沿各方向独立缩放 → 旋转回来"三步。
A_sym = np.array([[2, 1], [1, 3]], dtype=float)
eigvals, Q = np.linalg.eigh(A_sym) # eigh 专用于对称矩阵
Lambda = np.diag(eigvals)
# 验证分解:A = Q @ Lambda @ Q^T
A_reconstructed = Q @ Lambda @ Q.T
print(f"重构误差: {np.linalg.norm(A_sym - A_reconstructed):.2e}") # ~1e-16在深度学习中的应用:Hessian 分析
损失函数
- 所有特征值
(正定)→ 当前点是局部严格最小值,损失曲面呈"碗"形 - 特征值有正有负(不定)→ 鞍点(Saddle Point),存在上升和下降的方向
- 存在接近 0 的特征值 → 该方向上损失几乎是平坦的(平坦最小值,flat minima)
- 最大特征值 / 最小特征值(条件数)→ 衡量优化难度,条件数越大,梯度下降越难收敛
大规模模型中 Hessian 矩阵通常极大(参数数量的平方),实际应用中往往只需计算前几个最大和最小特征值(使用 Lanczos 算法等迭代方法),而非完整的特征分解。
2.3 矩阵正定性
本节将特征值与二次型联系起来,通过"能量曲面"的几何图景建立对正定性的直觉。正定性在优化(判断极值点类型)、概率(协方差矩阵必须半正定)和数值方法(Cholesky 分解要求正定)中都是核心概念。
二次型(Quadratic Form)
给定对称矩阵
结果是一个标量。展开后所有项都是关于
如果
这是因为任意方阵可以唯一分解为对称部分和反对称部分:
反对称部分对二次型的贡献恒为零。证明如下:
故
这个求导公式在推导梯度下降、Newton 法等优化算法时频繁出现。
五种正定性与"地形图"
将矩阵
| 类型 | 地形比喻 | 特征值条件 | 二次型性质 |
|---|---|---|---|
| 正定(Positive Definite, PD) | 碗,唯一最低点 | 所有 | |
| 负定(Negative Definite, ND) | 倒扣的碗,唯一最高点 | 所有 | |
| 不定(Indefinite, ID) | 马鞍面,有上有下 | 有正有负 | |
| 半正定(Positive Semi-Definite, PSD) | 山谷,最小值不唯一 | ||
| 半负定(Negative Semi-Definite, NSD) | 山脊,最大值不唯一 |
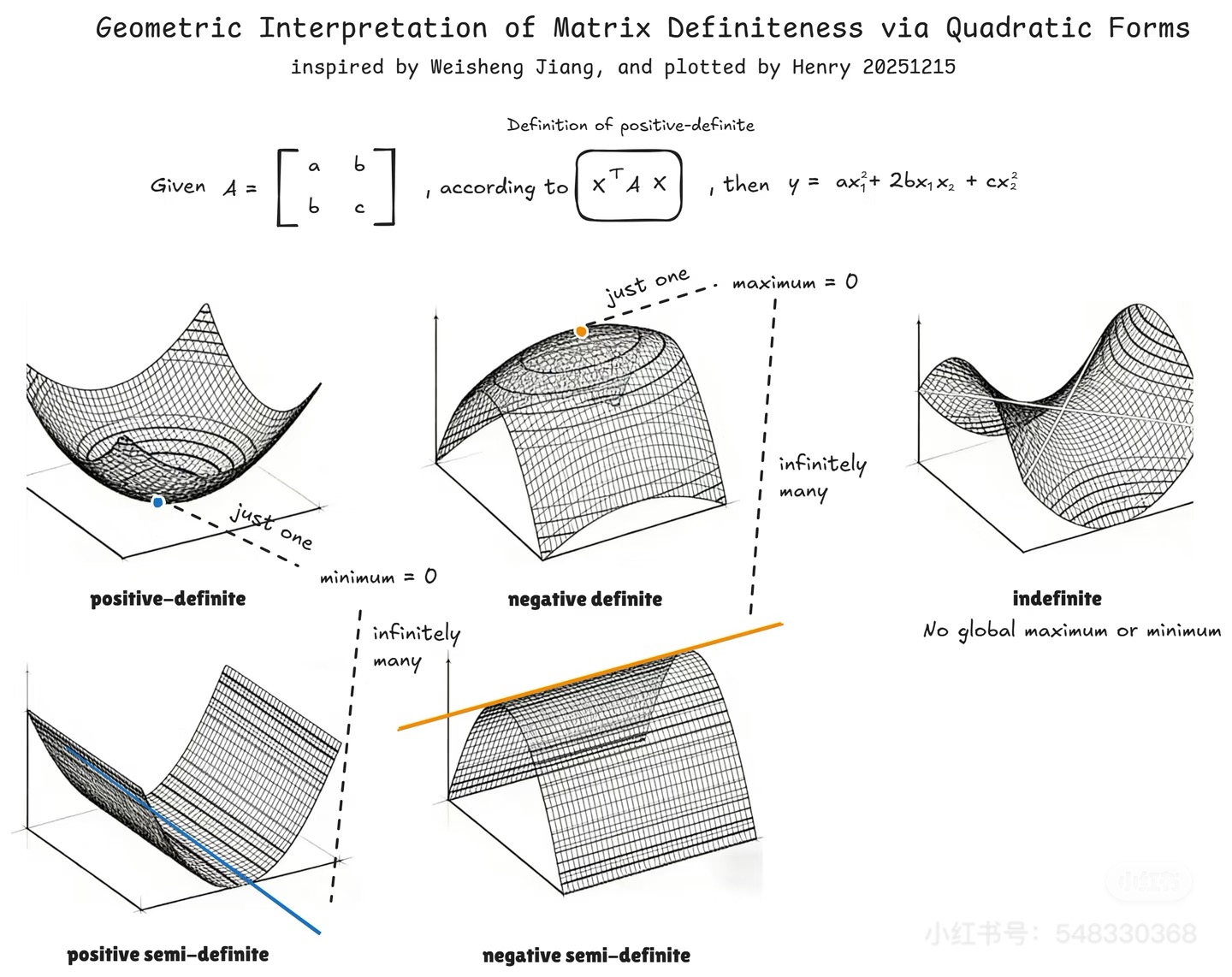
下面用代码绘制这五种典型曲面:
import numpy as np
import matplotlib.pyplot as plt
def plot_quadratic_form(A, title, ax):
"""绘制二次型 f(x) = x^T A x 的三维曲面"""
t = np.linspace(-10, 10, 30)
X, Y = np.meshgrid(t, t)
Z = A[0,0]*X**2 + (A[0,1]+A[1,0])*X*Y + A[1,1]*Y**2
ax.plot_surface(X, Y, Z, cmap='coolwarm', alpha=0.9,
edgecolor='k', linewidth=0.3)
ax.set_title(title, fontsize=11, fontweight='bold')
ax.set_xticks([]); ax.set_yticks([]); ax.set_zticks([])
matrices = {
"Positive Definite (Bowl)": np.array([[2, 0], [0, 2]]), # λ = 2, 2
"Negative Definite (Inv. Bowl)": np.array([[-2, 0], [0, -2]]), # λ = -2, -2
"Indefinite (Saddle)": np.array([[2, 0], [0, -2]]), # λ = 2, -2
"Positive Semi-Definite (Valley)": np.array([[1, -1], [-1, 1]]), # λ = 0, 2
"Negative Semi-Definite (Ridge)": np.array([[-1, 1], [1, -1]]) # λ = -2, 0
}
fig = plt.figure(figsize=(15, 8))
for i, (name, M) in enumerate(matrices.items()):
ax = fig.add_subplot(2, 3, i+1, projection='3d')
plot_quadratic_form(M, name, ax)
plt.tight_layout()输出解读:正定矩阵(
正定的判定方法
对称矩阵
- 所有特征值
- 所有顺序主子式(Leading Principal Minors)
- Cholesky 分解成功:
,其中 为下三角矩阵且对角元素全正
在优化中的意义
在梯度下降优化中,Hessian 矩阵
- Hessian 正定 → 当前点是局部严格最小值 → 梯度下降会收敛到该点
- Hessian 半正定且梯度为 0 → 可能是极小值或平坦区域
- Hessian 不定 → 鞍点,需要逃离
协方差矩阵
2.4 SVD 分解及其在 LoRA 中的应用
本节介绍奇异值分解(Singular Value Decomposition, SVD)——线性代数中最通用的矩阵分解工具。SVD 适用于任意矩阵(不要求方阵或对称),其低秩近似性质直接启发了 LoRA 参数高效微调方法。
奇异值分解
任意矩阵
其中:
:左奇异向量矩阵,列正交( ),描述"输出空间的旋转" :奇异值对角矩阵, :右奇异向量矩阵,列正交( ),描述"输入空间的旋转"
直觉:SVD 将任意线性变换分解为三步操作:
奇异值
SVD 与特征分解的关系:
低秩近似(Eckart-Young 定理)
Eckart-Young 定理:在 Frobenius 范数意义下,矩阵
近似误差为:
其中
LoRA:低秩权重更新
大语言模型微调时,直接更新所有参数
核心假设:预训练模型在下游任务上的权重更新
因此将权重更新分解为两个低秩矩阵之积:
其中
import torch
import torch.nn as nn
class LoRALinear(nn.Module):
def __init__(self, in_features, out_features, rank=8):
super().__init__()
self.W0 = nn.Linear(in_features, out_features, bias=False)
self.W0.weight.requires_grad = False # 冻结预训练权重
# 低秩更新矩阵
self.A = nn.Linear(in_features, rank, bias=False)
self.B = nn.Linear(rank, out_features, bias=False)
# 初始化:B=0 使得训练开始时 ΔW=BA=0,不改变预训练行为
nn.init.zeros_(self.B.weight)
nn.init.normal_(self.A.weight)
def forward(self, x):
return self.W0(x) + self.B(self.A(x))参数节省:原参数量为
即只需原参数量的 0.4% 即可微调。
为什么有效? SVD 的低秩近似理论提供了直觉:大矩阵的信息("能量")往往集中在前几个奇异值方向上。实际的权重更新
2.5 谱范数、奇异值与权重初始化
本节是全章的技术核心。谱范数决定了矩阵对向量的最大放大倍率,直接控制着梯度在深度网络中的传播行为。理解谱范数是掌握 Xavier/He 初始化、Spectral Normalization 等技术的前提。
谱范数:矩阵的"放大倍率"
谱范数(Spectral Norm) 定义为矩阵对向量模长的最大放大倍数,等于最大奇异值:
直觉:矩阵
: 是压缩映射,任何向量经过后模长变小 :存在某些方向使向量模长变大 :最大放大倍率恰好为 1(如正交矩阵、双随机矩阵)
梯度传播与连乘效应
深度网络反向传播时,梯度连续经过
谱范数的连乘决定了梯度的命运:
- 若所有层的
: ,梯度消失(Vanishing Gradient) - 若所有层的
: ,梯度爆炸(Exploding Gradient)
因此,控制每层权重矩阵的谱范数是保证训练稳定性的关键。
特殊矩阵的谱范数
全常数矩阵:若
维度越大,谱范数越大。用代码验证:
import torch
c = 0.001
# 小矩阵:谱范数 = 0.001 * 10 = 0.01
W_small = torch.full((10, 10), c)
print(torch.linalg.norm(W_small, ord=2)) # tensor(0.0100)
# 大矩阵:谱范数 = 0.001 * 4096 = 4.096 ← 梯度爆炸!
W_large = torch.full((4096, 4096), c)
print(torch.linalg.norm(W_large, ord=2)) # tensor(4.0960)
# 对比:同样标准差的随机矩阵,谱范数远小于全常数矩阵
torch.manual_seed(42)
W_random = torch.randn(4096, 4096) * c
print(torch.linalg.norm(W_random, ord=2)) # tensor(0.1279)输出解读:元素值仅为 0.001 的全常数矩阵,在
双随机矩阵(Doubly Stochastic Matrix):行和列和均为 1 且元素非负的矩阵,其谱范数恒等于 1。
证明分为上界和下界两步:
上界:利用矩阵范数的关系
- 行和为 1
(因为 ) - 列和为 1
- 故
下界:取全 1 向量
综合得
可以用 Sinkhorn-Knopp 算法生成双随机矩阵并验证:
import torch
def generate_doubly_stochastic(n, batch_size=1, max_iter=100):
"""使用 Sinkhorn-Knopp 算法生成双随机矩阵"""
matrix = torch.exp(torch.randn(batch_size, n, n))
for _ in range(max_iter):
matrix = matrix / matrix.sum(dim=2, keepdim=True) # 行归一化
matrix = matrix / matrix.sum(dim=1, keepdim=True) # 列归一化
return matrix
A = generate_doubly_stochastic(10, batch_size=10)
spectral_norms = torch.linalg.matrix_norm(A, ord=2)
print(spectral_norms)
# tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000,
# 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])
print(torch.allclose(spectral_norms, torch.ones(10), atol=1e-5)) # True随机矩阵的谱范数公式
对于
用数值实验验证这一渐近公式的精确度:
import torch, math
dimensions = [100, 500, 1000, 2000, 4096]
sigma = 1.0
for N in dimensions:
torch.manual_seed(42)
W = torch.randn(N, N) * sigma
actual = torch.linalg.norm(W, ord=2).item()
theory = 2 * math.sqrt(N) * sigma
print(f"N={N:>5d} 理论值={theory:.2f} 实际值={actual:.2f} 比值={actual/theory:.4f}")N= 100 理论值=20.00 实际值=19.93 比值=0.9964
N= 500 理论值=44.72 实际值=44.43 比值=0.9934
N= 1000 理论值=63.25 实际值=62.89 比值=0.9944
N= 2000 理论值=89.44 实际值=89.36 比值=0.9991
N= 4096 理论值=128.00 实际值=127.92 比值=0.9994输出解读:随着
He 初始化:应对 ReLU 的"放水"
深度网络中存在"加水"与"放水"的平衡游戏:
- 权重矩阵
是"加水龙头"——线性变换放大信号,方差 - ReLU 激活函数 是"放水阀"——将约一半神经元置零,使方差
为了保持每层信号的方差稳定(不增不减),需要:
这正是 He 初始化(Kaiming Initialization) 的公式。在此初始化下,谱范数约为:
import torch.nn as nn
# He 初始化(适用于 ReLU 网络)
layer = nn.Linear(1000, 1000, bias=False)
nn.init.kaiming_normal_(layer.weight, nonlinearity='relu')
print(torch.linalg.norm(layer.weight, ord=2)) # 约 2.8谱范数
import torch
import torch.nn as nn
N, L = 1000, 50 # 维度 1000,50 层
x = torch.randn(N)
x = x / torch.norm(x) * 0.001 # 初始信号强度 0.001
# 实验 A:纯线性网络,谱范数强制为 2(无 ReLU)
torch.manual_seed(42)
W_base = torch.randn(N, N)
U, S, Vh = torch.linalg.svd(W_base, full_matrices=False)
W_2 = U @ torch.diag(torch.full((N,), 2.0)) @ Vh # 所有奇异值 = 2
val_linear = x.clone()
for _ in range(L):
val_linear = W_2 @ val_linear
# 实验 B:ReLU 网络,He 初始化
val_relu = x.clone()
for i in range(L):
layer = nn.Linear(N, N, bias=False)
nn.init.kaiming_normal_(layer.weight, nonlinearity='relu')
val_relu = layer(val_relu)
if i > 0:
val_relu = torch.relu(val_relu)
print(f"纯线性网络(谱范数=2)第 {L} 层信号强度: {torch.norm(val_linear):.2e}")
print(f"ReLU 网络(He Init)第 {L} 层信号强度: {torch.norm(val_relu):.4f}")纯线性网络(谱范数=2)第 50 层信号强度: 1.13e+12
ReLU 网络(He Init)第 50 层信号强度: 0.0008输出解读:纯线性网络中谱范数为 2 的矩阵连乘 50 次后信号放大到
Xavier vs. He 初始化小结
| 初始化方法 | 方差 | 适用激活函数 | 设计思想 |
|---|---|---|---|
| Xavier(Glorot) | tanh、sigmoid | 信号通过线性区域,无"砍半"效应 | |
| He(Kaiming) | ReLU | 额外 |
He 初始化的原始论文(He et al., 2015, "Delving Deep into Rectifiers")明确推导了:使用 ReLU 时,信号方差在每层减半,因此权重方差需设为
2.6 从矩阵到张量
本节讨论张量——矩阵的高维推广。深度学习中的数据和参数几乎都以张量形式存储和运算。本节重点是张量的形状变换操作及其对梯度传播的影响。
张量的阶(Order)
| 阶 | 名称 | 形状示例 | 在深度学习中的例子 |
|---|---|---|---|
| 0 | 标量(Scalar) | () | Loss 值 |
| 1 | 向量(Vector) | (d,) | Token embedding |
| 2 | 矩阵(Matrix) | (seq, d) | 单条序列的表示 |
| 3 | 3 阶张量 | (batch, seq, d) | 一个 batch 的序列 |
| 4 | 4 阶张量 | (batch, heads, seq, seq) | 多头注意力权重 |
注意:张量的"阶"(order/mode)与"秩"(rank,指可分解为多少个秩 1 张量之和)是不同概念,不要混淆。
形状变换与梯度累积
张量的核心操作是保持元素总数不变的形状重排和维度操作:
reshape/view:改变形状,不改变元素排列顺序unsqueeze/squeeze:增加 / 移除大小为 1 的维度permute/transpose:交换维度顺序tile/repeat:沿指定维度复制数据
以下示例展示了 tile 操作下梯度如何通过形状变换正确传播:
import torch
from torch import nn
a = nn.Parameter(torch.rand(1, 4)) # shape: (1, 4)
b = a.unsqueeze(0) # shape: (1, 1, 4)
c = b.tile(2, 1, 1) # shape: (2, 1, 4) ← a 被复制了 2 份
d = torch.rand(2, 1, 4)
loss = torch.mean(d - c)
loss.backward()
print(a.grad) # tensor([[-0.25, -0.25, -0.25, -0.25]])输出解读:tile(2, 1, 1) 将
不变性(Invariance)
矩阵运算具有若干重要的不变性,在推导梯度公式时经常使用:
- 迹的循环不变性:
- Frobenius 范数与迹:
- 标量对矩阵求导:
这些性质推广到高维张量后,对应的是爱因斯坦求和约定(Einstein Summation Convention, torch.einsum)下的收缩操作,在多头注意力等复杂运算的梯度推导中不可或缺。
2.7 图论基础:二部图
本节引入二部图(Bipartite Graph)和匹配问题的基本概念。图结构在注意力机制的解释、目标检测中的预测-标签匹配以及最优传输理论中均有直接应用。
二部图的定义
二部图(Bipartite Graph):顶点集可以分为两个不相交的子集
形式化定义:
在注意力机制中的解释:自注意力可以看作一个带权重的完全二部图:
:query 节点(每个位置的 query 向量) :key 节点(每个位置的 key 向量) - 边权重
:注意力分数
每个 query 节点与所有 key 节点相连,权重之和为 1(softmax 归一化),注意力矩阵就是这个二部图的加权邻接矩阵。
二部图匹配与匈牙利算法
最大匹配(Maximum Matching):在二部图中找到最多的边,使得每个顶点最多参与一条边。匈牙利算法(Hungarian Algorithm) 在
在深度学习中的应用
1. 目标检测中的预测匹配(DETR)
DETR(DEtection TRansformer)将目标检测建模为集合预测问题。模型输出
:预测框集合 :真实框集合 - 边权重:预测框与真实框之间的匹配代价(分类损失 + 位置损失)
匈牙利算法找到总代价最小的一一匹配,避免了传统方法中非极大值抑制(NMS)等启发式后处理。
2. 最优传输(Optimal Transport)与 Sinkhorn 算法
找到两个离散概率分布之间的最优"运输方案",本质上是带权重的二部图匹配的连续松弛。Sinkhorn-Knopp 算法通过交替进行行归一化和列归一化,将任意非负矩阵投影到双随机矩阵空间:
import torch
def sinkhorn(cost_matrix, num_iter=100):
"""最优传输的 Sinkhorn 迭代"""
matrix = torch.exp(-cost_matrix) # 负代价 → 相似度
for _ in range(num_iter):
matrix = matrix / matrix.sum(dim=1, keepdim=True) # 行归一化
matrix = matrix / matrix.sum(dim=0, keepdim=True) # 列归一化
return matrix # 收敛到双随机矩阵(最优运输方案)Sinkhorn 迭代的收敛结果是一个双随机矩阵——行和列和均为 1、元素非负。这正是第 2.5 节中证明谱范数恒为 1 的那类矩阵。同一个 Sinkhorn-Knopp 算法,在数值线性代数中用于矩阵归一化,在机器学习中用于可微最优传输——最优传输方案作为线性映射,对向量模长既不放大也不缩小(谱范数 = 1),这一性质在将 Sinkhorn 嵌入可微神经网络管线时保证了梯度传播的稳定性。
本章小结
| 工具 | 核心公式/概念 | 在深度学习中的应用 |
|---|---|---|
| 矩阵乘法 | 注意力 | |
| 特征分解 | Hessian 分析、损失曲面几何 | |
| 正定性 | 优化极值判断、协方差矩阵 | |
| SVD | LoRA 低秩微调、低秩近似 | |
| 谱范数 | 梯度稳定性、权重初始化 | |
| 张量 | 矩阵的高阶推广 | Batch 计算、多头注意力 |
| 二部图 | DETR 匹配、最优传输 |
三条工程直觉:
谱范数决定梯度命运。初始化时控制每层权重的谱范数在合适范围,是训练稳定的第一道防线。Xavier 初始化让谱范数
(适配 tanh/sigmoid),He 初始化让谱范数 (额外补偿 ReLU 的方差减半)。本质不是"让元素小",而是"让谱范数与激活函数的衰减率平衡"。 低秩是大模型的内在结构。SVD 告诉我们,大矩阵的信息往往集中在少数奇异值方向上。LoRA 将这一数学观察变成了参数高效微调的工程实践——只需原参数 0.4% 的可训练参数就足以适配下游任务。
形状变换不改变信息量。
reshape、permute、tile只是换了一种"看法"或复制了数据,梯度通过自动微分引擎按链式法则正确传播。参数共享(tile/expand)场景下梯度会在共享点累加——这就是参数共享的数学基础。
延伸阅读
- 线性代数基础:Gilbert Strang, Introduction to Linear Algebra(MIT 18.06 课程配套教材,覆盖本章所有基础概念)
- SVD 与数值方法:Trefethen & Bau, Numerical Linear Algebra,第 4-5 章(SVD 的理论与算法细节)
- LoRA:Hu et al. (2021), "LoRA: Low-Rank Adaptation of Large Language Models"(arXiv:2106.09685)
- He 初始化:He et al. (2015), "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification"(Kaiming 初始化的原始论文,推导了 ReLU 网络方差传播的完整数学)
- 谱归一化:Miyato et al. (2018), "Spectral Normalization for Generative Adversarial Networks"(将谱范数约束应用于 GAN 训练稳定性)
- 随机矩阵理论:Marchenko-Pastur 分布描述了大随机矩阵奇异值的渐近分布,是理解
的理论基础 - 最优传输:Cuturi (2013), "Sinkhorn Distances: Lightspeed Computation of Optimal Transport"(可微最优传输的开创性工作)