附录 B:杂项与资源
本附录目标:汇总 GenAI 学习与实践过程中积累的周边知识——从模型索引、学习资料,到 AI 交叉应用、数据可视化、算法笔记、开发工具,再到 Vibe Coding 方法论。这些内容虽不构成 GenAI 的核心技术栈,但在日常工程实践中反复被用到,是"把事情做成"的基础设施。
B.1 模型索引与资源汇总
快速定位主流模型、代码仓库与高质量学习资料,建立个人知识导航。
B.1.1 Embedding 模型速查
在语义检索和 RAG 系统中,选择合适的 Embedding 模型是第一步。下表列出在多个项目中实际使用过的模型:
| 模型 | 特点 | 典型用途 |
|---|---|---|
sentence-transformers/all-mpnet-base-v2 | 通用语义相似度,均衡精度与速度 | 语义检索、RAG 向量化、文本聚类 |
使用方式:
import sentence_transformers
st_model = sentence_transformers.SentenceTransformer(
'sentence-transformers/all-mpnet-base-v2'
)
embeddings = st_model.encode(texts, show_progress_bar=False)选型建议:
all-mpnet-base-v2在通用英文场景下表现稳定,是快速原型开发的默认选择。如果需要多语言支持或更高精度,可考虑multilingual-e5-large或bge系列,但要注意模型体积与推理延迟的权衡。
B.1.2 必读代码仓库
以下仓库按"从零理解 LLM → 数据准备 → 系统工程 → Agent 应用"的学习路径组织:
LLM 基础与从零实现
| 仓库 | 作者 | 内容定位 |
|---|---|---|
| Hands-On-Large-Language-Models | Jay Alammar | 可视化理解 LLM 内部机制,适合建立直觉 |
| LLMs-from-scratch | Sebastian Raschka | 从零用 PyTorch 实现 GPT,代码即教材 |
| reasoning-from-scratch | Sebastian Raschka | 从零实现推理模型,覆盖 CoT 等推理策略 |
| nanoGPT | Andrej Karpathy | 极简 GPT 实现(约 600 行),最佳入门代码 |
数据、基础设施与 Agent
| 仓库 | 内容定位 |
|---|---|
| llm-datasets | LLM 训练数据集汇总与质量分析 |
| rag-from-scratch | 基于 LangChain/LangGraph 的 RAG 从零实现 |
| Awesome-ML-SYS-Tutorial | ML 系统与 Infra 教程汇总,涵盖分布式训练、推理优化 |
阅读建议:先通读 nanoGPT 建立对 Transformer 训练流程的整体认知,再用 LLMs-from-scratch 补充细节,最后通过 Awesome-ML-SYS-Tutorial 了解工程化部署的挑战。
B.2 AI+ 交叉应用(化学等)
AI 技术正在渗透到自然科学的各个分支。本节以化学分子识别为例,展示"结构化知识 + 视觉-语言模型"的数据构建范式。
B.2.1 化学分子识别:SMILES 与 RDKit
DeepSeek-OCR 项目在化学公式识别任务上提供了一个值得参考的数据构建方案:
- 数据源:从 PubChem 获取 SMILES(Simplified Molecular-Input Line-Entry System)格式的分子表示
- 渲染:使用 RDKit 将 SMILES 字符串渲染为分子结构图像
- 规模:构建了 5M 图文训练对
整体流水线可以概括为:
SMILES 字符串 → RDKit.Draw → 分子结构图 → (图, SMILES) 训练对这种"结构化知识 → 渲染为图像 → 训练视觉-语言模型"的范式在 AI+科学领域具有广泛适用性——只要目标领域存在可程序化渲染的结构化表示(如化学式、电路图、乐谱),就可以用类似方法大规模合成训练数据。
B.2.2 文档识别(OCR)
POINTS-Reader(腾讯)是一个面向复杂文档(含公式、表格、图表)的高精度 OCR 模型。
- 官方模型:tencent/POINTS-Reader
- 部署与微调:ninehills/POINTS-Reader
其架构由三个模块组成:
| 模块 | 功能 |
|---|---|
| LLM | 基于提取的特征生成文本描述 |
| vision_encoder | 提取图像的视觉特征 |
| vision_projector | 将视觉特征对齐到语言模型的嵌入空间 |
这是典型的"视觉编码器 + 投影层 + LLM"三段式多模态架构,与 LLaVA 等模型的设计思路一致。理解这一架构有助于快速上手其他多模态模型。
B.3 数据科学可视化
掌握对数坐标轴(Log Scale)的直觉理解与 Matplotlib 常用图表技巧,是分析模型 Scaling 曲线、Benchmark 对比等场景的基础能力。
B.3.1 对数坐标轴的直觉
对数坐标轴的核心思想:将刻度间距从绝对差改为倍数比。
线性 vs 对数坐标的区别:
- 线性坐标关注"加法"——1→2 和 8→9 的间距相同(都是 +1)
- 对数坐标关注"乘法"——1→2 的间距约 0.301(翻倍),8→9 的间距仅约 0.051(增长 12.5%)
何时使用 Log Scale:
- 数据跨越多个数量级(如模型参数量从 1M 到 100B)
- 关注增长率/倍数而非绝对值(如 AI Scaling Law 曲线)
- 底层关系服从
时,Log 坐标下曲线显示为直线,便于判断趋势
下面的代码演示了"收益递减"曲线在两种坐标下的表现——线性坐标下看到弯曲,对数坐标下看到直线:
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0.1, 100, 500)
y = 50 * np.log10(x) + 100 # Diminishing Returns:x 翻 10 倍,y 仅 +50
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(10, 8))
# 线性坐标:收益递减曲线看起来是弯曲的
ax1.plot(x, y, color='#00ff00', linewidth=2)
ax1.set_title("Linear Scale: 收益递减曲线")
ax1.set_ylabel("Performance Score")
ax1.grid(True, alpha=0.3)
# 对数坐标:同一曲线变为直线,揭示线性规律
ax2.plot(x, y, color='#00aaff', linewidth=2)
ax2.set_xscale('log') # 关键:对数 X 轴
ax2.set_title("Log Scale: 同一曲线变为直线")
ax2.set_xlabel("Cost / Input ($)")
ax2.set_ylabel("Performance Score")
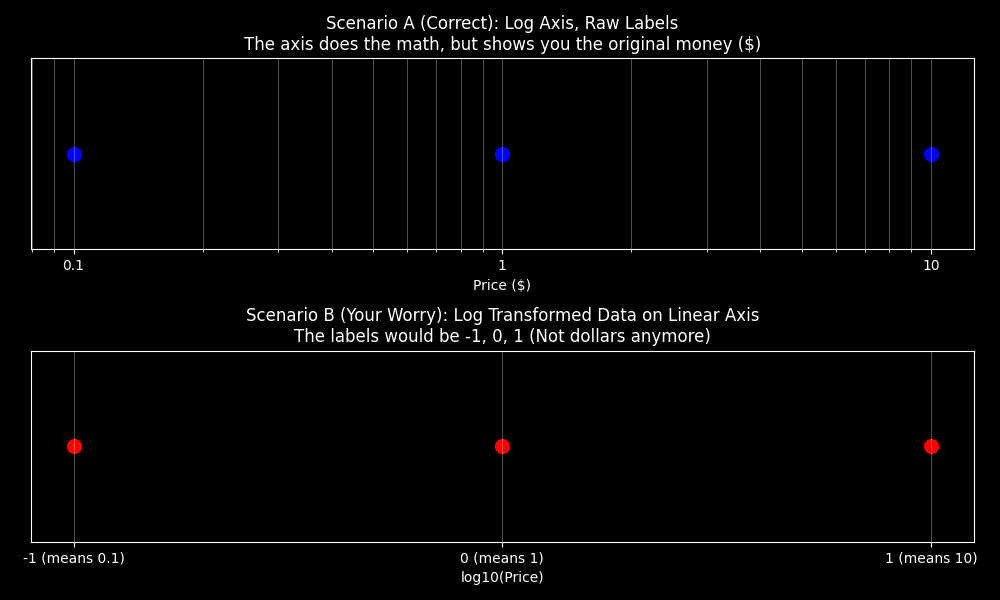
ax2.grid(True, which="both", alpha=0.3)一个常见困惑:Log Scale 轴 vs Log 变换数据
初学者容易混淆"设置对数坐标轴"和"对数据取对数":
- Log Scale 轴(
ax.set_xscale('log')):坐标轴按对数间距排列,但标签显示的仍然是原始值($0.1, $1, $10) - Log 变换数据(
np.log10(x)):数据本身被变换,标签变成了 -1, 0, 1,失去了原始含义
前者保留了数据的可读性,是绑大多数情况下的正确做法。
B.3.2 箱线图(Boxplot)
箱线图是展示数据分布的经典工具,通过 5 个关键统计量刻画数据:
- 下边缘:
(低于此为异常值) (下四分位数,第 25 百分位) - 中位数(
,第 50 百分位) (上四分位数,第 75 百分位) - 上边缘:
(高于此为异常值)
其中
应用场景:在实验结果分析中,箱线图适合对比多次运行的模型性能分布。相比单纯汇报均值和标准差,箱线图能直观展示中位数偏移、分布偏斜和异常值,更真实地反映模型稳定性。
B.4 LeetCode 算法笔记
梳理技术面试中的高频算法考点,重点覆盖动态规划和堆两类核心题型。
B.4.1 动态规划(Dynamic Programming)
高频考点:背包问题、编辑距离、二叉树 DP。
DP 问题的通用解题框架(三步法):
- 定义状态:明确
dp[i](或dp[i][j])表示什么——这是最关键的一步,状态定义错了后面全白费 - 写出转移方程:如何从已知子问题推导到当前问题
- 确定初始条件和计算顺序:哪些
dp值是已知的,应该按什么方向遍历
经验总结:DP 题的难点不在编码,而在状态定义。拿到题目后先花时间想清楚"什么信息需要被记住",状态定义对了,转移方程通常自然浮现。
B.4.2 堆(Heap)
堆是完全二叉树,天然适合用数组存储——0 号为根,按层序编码。
数组索引关系(0-indexed):
| 关系 | 公式 |
|---|---|
| 节点 | |
| 节点 | |
| 节点 |
最小堆性质:任意节点的值 data[0] 永远是全局最小值。
核心操作:
- 插入(Sift Up):将新元素追加到数组末尾,然后向上调整直到满足堆性质
- 删除堆顶(Sift Down):将末尾元素移到堆顶,然后向下调整
Python heapq 常用操作:
import heapq
data = [3, 1, 4, 1, 5, 9]
heapq.heapify(data) # O(n) 原地建堆
min_val = heapq.heappop(data) # O(log n) 弹出最小值
heapq.heappush(data, 2) # O(log n) 插入新元素
heapq.heapreplace(data, 7) # heappop + heappush 的高效合并(一次 sift down)建堆时间复杂度为什么是 O(n) 而不是 O(n log n):
heapify从最后一个非叶子节点开始自底向上调整。底层节点多但调整距离短,顶层节点少但调整距离长,数学上求和后总工作量为 O(n)。
典型应用场景:Top-K 问题、任务调度(最早空闲 Worker 优先)、合并 K 个有序链表、中位数维护(对顶堆)。
B.5 实用工具(Clash、Cursor、文档识别)
汇总 GenAI 开发日常所需的网络代理、编辑器配置、文档处理等实用工具。
B.5.1 网络代理与 IP 检测
Clash for Linux
在服务器上配置代理是访问外部模型 API 和下载 HuggingFace 资源的前提。Clash 提供了命令行代理方案:
# 1. 配置订阅地址(编辑 .env 文件)
# 2. 启动 Clash
sudo bash start.sh # 启动后会输出 secret 信息
source /etc/profile.d/clash.sh
proxy_on # 开启代理(设置环境变量)
# 3. Dashboard 管理(浏览器打开设置节点)
# http://<服务器IP>:9090/ui
# 填写 secret,add 后进入管理页面(label 随意填写)
# 4. 关闭代理
proxy_offClash 工作模式与规则:
| 概念 | 说明 |
|---|---|
| Rule Mode(规则模式) | 默认模式,按规则匹配流量走向 |
| Global Mode(全局模式) | 所有流量走代理,global 组仅在此模式下生效 |
| 节点选择 | 走代理节点 |
| 全球直连 | 直接连接,不走代理 |
| 漏网之鱼 | 未匹配任何规则时的兜底策略 |
IP 检测
curl https://ipinfo.io # 查看当前出口 IP 基本信息
curl -L ping0.cc/geo # 查看 IP 纯净度、带宽类型、是否原生 IP、共享人数B.5.2 Cursor 远程服务器配置
在无法联网的服务器上使用 Cursor Remote,需要手动安装 Cursor Server:
# 1. 从 Cursor 的 Output 日志中找到 commit ID
COMMIT=b3573281c4775bfc6bba466bf6563d3d498d1070
# 2. 在有网络的机器上下载
curl -L -o vscode-reh-linux-x64.tar.gz \
"https://cursor.blob.core.windows.net/remote-releases/${COMMIT}/vscode-reh-linux-x64.tar.gz"
# 3. 传到服务器后解压安装
mkdir -p ~/.cursor-server/cli/servers/Stable-${COMMIT}/server
tar -xvzf ~/vscode-reh-linux-x64.tar.gz \
-C ~/.cursor-server/cli/servers/Stable-${COMMIT}/server \
--strip-components=1推荐插件:
- Git Blame 类插件:在编辑器右侧显示每行代码的提交记录,方便追溯变更历史
B.5.3 PDF 与文档处理
Python 轻量 PDF 解析(基于 pypdf):
from pypdf import PdfReader
reader = PdfReader("document.pdf")
for page in reader.pages:
text = page.extract_text()
print(text)
pypdf适合纯文本提取。如需处理含公式/表格的复杂 PDF,可考虑 B.2.2 提到的 POINTS-Reader 等多模态 OCR 方案。
B.5.4 终端图片显示
在 macOS iTerm2 中,可通过 imgcat 在命令行直接显示图片:
curl -L https://iterm2.com/utilities/imgcat > imgcat
chmod +x imgcat
sudo mv imgcat /usr/local/bin/
# 使用
imgcat screenshot.pngB.5.5 Ubuntu 常用配置
在 Ubuntu 服务器上开发时的一些常用工具和配置备忘,可根据实际需求选装。
B.6 Vibe Coding 与 Spec 驱动开发
AI 辅助编程已成为日常,但"怎么用"比"用不用"更重要。本节讨论两种对立的 AI 编程范式——Vibe Coding 和 Spec 驱动开发——以及如何在效率与能力保持之间找到平衡。
B.6.1 Vibe Coding 的问题
"Vibe Coding"指让 AI 一气呵成地写代码,不加审视地接受输出。这种方式在原型开发阶段很有效率,但存在根本性风险:
- 思维能力退化:无脑 LLM input/output 会极大降低自己的架构能力与工程能力
- 缺乏全局视角:AI 生成的代码适合局部实现,但缺乏系统级设计考量
- 核心能力被掩盖:问题的关键是找到关键的问题——提炼问题的能力比让 AI 生成答案更重要
Reasoning(深度思考)和 Design(设计)应当前置到 prompt 中,而不是后置到 review 中。先想清楚要什么,再让 AI 去实现。
B.6.2 Spec 驱动开发(SDD)
SDD(Spec-Driven Development)的核心理念:先思考,后编码。
工作流程:
新需求 → 充分理解需求 → 给出实现思路 → 与团队讨论 → 确认决策点 → 开始编码关键实践:
- 在 Prompt 中前置 reasoning 和 design:让 AI 先分析需求、给出方案,而非直接写代码
- 使用 PRD(Product Requirements Document):将需求结构化,减少歧义和遗漏
- 在 Cursor Rule / System Prompt 中明确约束:
新需求首次沟通时,末尾强调:
"不要急着写代码!先理解需求,给出实现思路,我们先讨论,
看还有什么需要我决策的点?ultrathink"或更简洁的 Cursor Rule:
不明白的地方反问我,先不着急编码B.6.3 AI 辅助编程的分工原则
| 适合交给 AI | 应当自己把控 |
|---|---|
| 样板代码(Boilerplate) | 系统架构设计 |
| 单元测试编写 | 技术选型与取舍 |
| 代码格式化与重构 | 需求拆解与优先级排序 |
| 文档生成 | 性能瓶颈定位 |
| 调试线索收集 | 边界情况处理策略 |
核心观点:AI 工具是"放大器"——它放大你已有的工程能力,而无法替代你没有的判断力。数据结构、系统设计、调试能力这些基础功在 AI 时代比以往更有价值,因为它决定了你能否看出 AI 的输出哪里是错的。
本章小结
本附录覆盖了 GenAI 工程师所需的周边知识与资源地图:
模型与资源(B.1):
all-mpnet-base-v2是通用 Embedding 的默认选择;nanoGPT 和 LLMs-from-scratch 是从零理解 LLM 的最佳代码资产;Awesome-ML-SYS-Tutorial 汇聚了 ML 系统进阶资料。AI+科学(B.2):DeepSeek-OCR 在化学分子识别上采用"SMILES → RDKit 渲染 → 图文对"的数据构建方法,展示了 AI 与领域知识融合的通用范式;POINTS-Reader 提供了多模态文档 OCR 能力。
数据可视化(B.3):Log Scale 将倍数关系映射为等间距,是解读 Scaling Law 曲线的必备工具;箱线图通过 5 分位统计量刻画分布,比均值更能反映实验的真实稳定性。
算法基础(B.4):DP 三步法(定状态 → 写转移 → 定初值)是动态规划的通用框架;堆的数组实现利用完全二叉树的索引规律,
heapq的heapreplace是合并操作的高效技巧。实用工具(B.5):Clash for Linux 解决服务器网络代理问题;Cursor Server 手动安装应对离线场景;
pypdf提供轻量 PDF 文本提取。Spec 驱动开发(B.6):SDD 要求在 prompt 中前置 reasoning 与 design,先讨论再编码;Vibe Coding 虽然高效,但保持架构能力和问题提炼能力才是 AI 时代的核心竞争力。
延伸阅读
- Matplotlib 官方教程:Python 数据可视化的核心库文档,覆盖 Figure/Axes 模型、样式定制和子图布局,配合本附录 B.3 节使用。Matplotlib Tutorials
- Statistics Done Wrong:Alex Reinhart 著,以实际案例讲解常见统计误用(p-hacking、多重比较、样本量不足等),适合 AI 实验结果分析的批判性阅读。statisticsdonewrong.com
- Sentence Transformers 文档:语义检索和 Embedding 模型的使用指南,覆盖模型选型、微调和评估,配合本附录 B.1 节阅读。SBERT Docs
- Writing in the Sciences (Stanford Online):斯坦福学术写作课程,讲解科学论文的结构、用词精简和数据呈现技巧。Coursera