第 5 章:位置编码、Tokenizer 与 MoE
本章覆盖 LLM 架构中三个相对独立但同等重要的方向:(1)RoPE 位置编码的几何直觉、数学推导与工程实现;(2)YaRN 等长度外推方法;(3)Tokenizer 中的 Glitch Token 与训练数据分析;(4)Mixture of Experts 架构原理与 Qwen3-30B-A3B 实例;(5)Muon 优化器与梯度裁剪;(6)Chat Templates 与 Thinking Budget 机制。
5.1 RoPE 位置编码:几何直觉与数学推导
核心直觉:RoPE 以绝对位置编码的形式注入信息,却通过旋转矩阵的数学性质获得相对位置感知——两个绝对位置的向量内积只依赖于相对位置。
5.1.1 为什么需要位置编码
Multi-Head Attention 本质上是排列等变(Permutation Equivariant)的:若打乱输入 token 的顺序,输出也仅随之重排,不改变每个 token 的表示内容。换言之,MHA 本身是位置不敏感的——如果不注入位置信息,模型无法区分"猫追狗"与"狗追猫"。
5.1.2 RoPE 的诞生背景
苏剑林(2021)提出 RoPE 时的出发点很朴素:
"两个绝对位置的向量内积只依赖于相对位置。"
彼时(BERT 时代)训练长度短,RoPE 并无明显优势。RoPE 真正流行起来,是因为 Flash Attention 的出现。Flash Attention 封装了 Attention 内部的计算过程,大多数相对位置编码需要修改 Attention 内部计算,因而被否掉了。RoPE 以绝对位置编码的形式注入到
5.1.3 核心数学
对于第
注意力分数为:
结果只依赖于相对距离
5.1.4 高维旋转:2D 子空间分解
旋转必须在平面(2D)上进行。RoPE 将
其中 base 通常为 10000(Qwen3 扩展到 1,000,000)。
在每个 2D 子空间中,旋转可以用矩阵或复数表示:
等价于复数乘法:
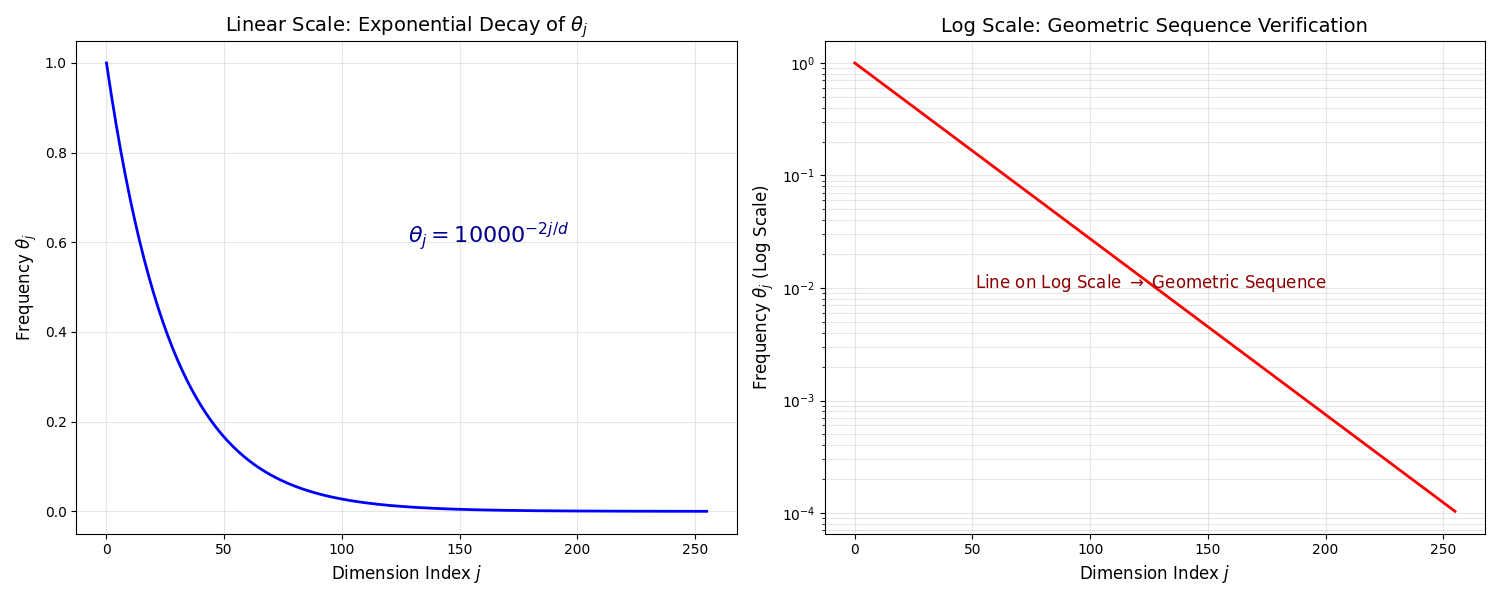
5.1.5 钟表类比:多尺度频率
不同维度旋转速度不同,随着维度
| 维度索引 | 波长(周期) | 类比 | 捕捉的依赖 | |
|---|---|---|---|---|
| 秒针 | 相邻 token 的精确关系(语法搭配) | |||
| 分针 | 短段落内依赖 | |||
| 时针 | 文档级长距离语义(如首段的"张三"与末段的"他") |
Base 定义了最慢的"时针"转一圈所需要的长度。base=10000 时,最低频维度周期约 62,831 token;base=1,000,000 时,周期约
每个嵌入向量同时包含所有频率的位置信息——RoPE 天然具有**多尺度(Multi-scale)**特性。纵向看(序列中不同 token),每个 token 对应一个 position id
可视化:下图展示了
5.1.6 注意力分数的解剖
定义相对距离
直觉解读:
项(语义相似度 位置衰减):语义越相关、距离越近,贡献越大; 项(正交分量 位置顺序):编码了 token 的先后顺序信息。
5.1.7 长程衰减的自然涌现
当
这个函数随
- 近距离(
小)——相干叠加:各维度 值接近 1,正数累加,总和大。 - 类比:
- 类比:
- 远距离(
大)——非相干/相消叠加:高频维度相位随机化, 值在 均匀分布,正负抵消,总和趋近于零。 - 类比:
- 类比:
根据大数定律,当采样点够多且相位分布均匀时,均值趋近于
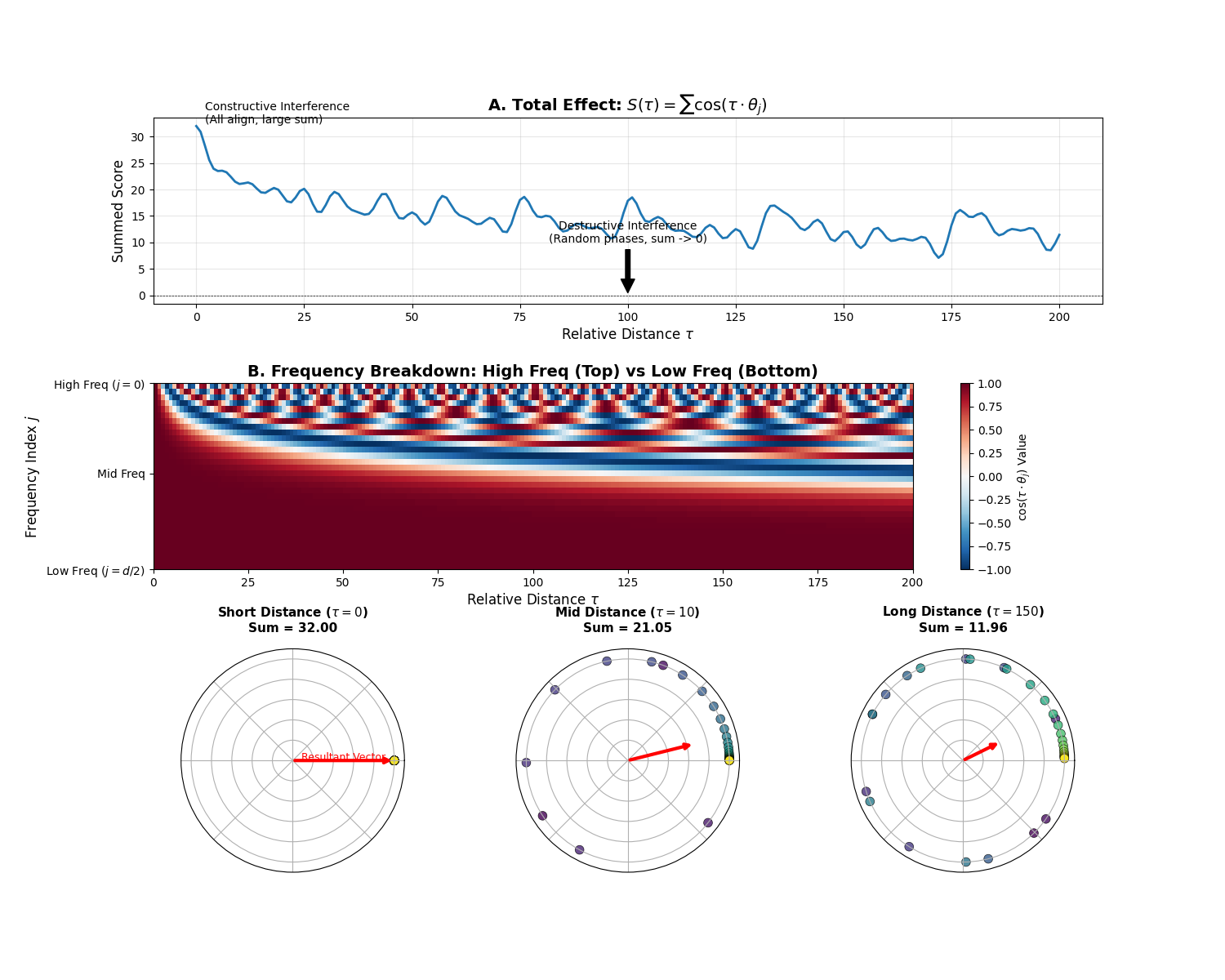
这种衰减并非人为设计,而是 RoPE 旋转频率多样性的自然涌现——"高频维度的完全抵消"加上"低频维度的缓慢下降"共同作用的结果。模型天然倾向于关注近邻,但也保留了远程关注的能力。
数值验证:对于 base=10000,最低频维度
5.1.8 工程实现
实际实现中存在两种维度排列方式:
- Half-split(非交错):
构成一对。LLaMA/HuggingFace 采用此方式。 - Interleaved(交错):
构成一对。原始 RoPE 论文采用此方式。
以 Half-split 为例的完整实现:
def compute_rope_params(head_dim, theta_base=10_000, context_length=4096):
"""计算 RoPE 的 cos/sin 表"""
inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim, 2).float() / head_dim))
positions = torch.arange(context_length)
angles = positions.unsqueeze(1) * inv_freq.unsqueeze(0) # (context_length, head_dim//2)
angles = torch.cat([angles, angles], dim=1) # Half-split: cos 和 sin 各重复一次
return torch.cos(angles), torch.sin(angles)
def rotate_half(x):
"""LLaMA/HuggingFace 风格:将前半与后半交换并取负"""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rope(x, cos, sin):
"""应用旋转位置编码"""
return (x * cos) + (rotate_half(x) * sin)对应的数学展开(
等价性验证:将上述实数实现与复数实现对比,最大差异在
# 复数实现
x_complex = torch.complex(x[..., :head_dim//2], x[..., head_dim//2:])
rope_complex = torch.polar(torch.ones_like(angles), angles) # e^{i*theta}
x_out = x_complex * rope_complex # 复数乘法即旋转
result = torch.cat([x_out.real, x_out.imag], dim=-1)
# 验证: Max Difference ≈ 2.38e-07在模型中的应用位置:RoPE 应用于 GQA 内部,对 Query 和 Key 进行旋转编码(Value 不编码位置):
queries = self.W_query(x).view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)
keys = self.W_key(x).view(b, num_tokens, self.num_kv_groups, self.head_dim).transpose(1, 2)
queries = apply_rope(queries, cos, sin)
keys = apply_rope(keys, cos, sin)5.2 长度外推:YaRN 等方法
核心问题:如何让训练时上下文长度为
的模型,在推理时支持 的更长输入?核心策略是"内插而非外推"。
5.2.1 直接外推的失败
直接给模型输入超过训练长度的位置索引(如训练时最大 4096,推理时输入 5000),在 RoPE 上效果极差:旋转角度超出训练范围后变得极其混乱(Out-of-Distribution),Attention 机制崩溃。
5.2.2 位置插值(Position Interpolation, PI)
最简单的方法是将所有位置均匀压缩到训练范围内:
原来
缺陷:高频维度原本用于区分相邻 token(近距离精度),压缩后分辨率大幅下降,近距离关系变模糊。
5.2.3 NTK-Aware 缩放
通过放大 theta_base(如
其中
5.2.4 YaRN(Yet another RoPE extensioN)
YaRN 结合了位置插值与 NTK-Aware 的优点,对不同频率维度采用差异化缩放策略:
| 维度类型 | 策略 | 理由 |
|---|---|---|
| 高频维度(低 dim index) | 不插值,保持原始旋转速度 | 保留近距离分辨率 |
| 中频维度 | 混合插值 | 平衡过渡 |
| 低频维度(高 dim index) | 纯位置插值 | 这些维度本就用于长距离 |
DeepSeek-V3 采用 YaRN 将预训练上下文从 4096 有效扩展到 163,840 token,并在 Attention 层中使用 Partial RoPE(仅部分维度 qk_rope_head_dim=64 应用 RoPE,另一部分 qk_nope_head_dim=128 不应用),平衡绝对位置与相对位置信息:
{
"rope_theta": 10000,
"rope_scaling": {
"type": "yarn",
"factor": 40,
"original_max_position_embeddings": 4096
}
}5.2.5 Qwen3 的实践
Qwen3 系列选择了更直接的路径:将 rope_theta 提升到
多模态扩展:RoPE 的数学框架天然可以从 1D 推广到多维。在多模态场景下,Qwen 系列将 RoPE 扩展为 M-RoPE(Multimodal RoPE),为视频/图像的时间-空间维度
分别编码位置信息。详见第 7 章 7.5.3 节"M-RoPE 的演进"。
5.3 Tokenizer:特殊 token、Glitch token、训练数据分析
核心观察:Tokenizer 与 LLM 主体在不同数据集上训练,可能导致词表中存在"有名无实"的 Glitch Token——Tokenizer 认识它,但模型完全不理解它。
5.3.1 特殊 token
现代 LLM 普遍采用 BPE 或其变体。词表中包含若干特殊 token,由 Tokenizer 直接映射(不经过 BPE 分割):
<bos>/<s>:序列开始,充当 Attention Sink;<eos>/</s>:序列结束,触发停止;<|im_start|>、<|im_end|>:聊天模板边界(如 Qwen 的 ChatML 格式);<think>、</think>:推理模型的思考过程边界(见 5.7 节)。
5.3.2 Glitch Token(故障 Token)
定义:Tokenizer 词表中存在的、模型却无法正确处理的 token。
真实案例(Qwen2.5-7B-Instruct 词表,按 Embedding L2 范数排序):
| Token ID | Token | L2 范数 | 来源推测 |
|---|---|---|---|
| 117332 | 法战组合 | 0.0150 | 传奇私服网站 |
| 115984 | 魔龙令牌 | 0.0213 | 游戏道具名 |
| 115992 | 鸟成长记 | 0.0263 | 游戏相关 |
| 118326 | 凡本网注 | 0.0295 | 新闻网站版权声明 |
| 109540 | 早餐加盟 | 0.0899 | 加盟广告 |
| 114068 | 搜狐首页 | 0.1211 | 门户网站 |
GPT-4o 中也有类似现象,如来自早期 QQ 空间留言板默认文案的 token。
成因(Tokenizer-Model Mismatch):
- Tokenizer 在数据集 A 上训练(含网络爬取的低质量文本),LLM 主体在清洗后的高质量数据集 B 上预训练。
- 某些 token(如
法战组合)在数据集 A 中频率足够高被 BPE 合并为独立 token,但在数据集 B 中极少或从未出现。 - 该 token 的 Embedding 向量因梯度更新极少,停留在随机初始化状态(范数极小),被推到向量空间的"角落"。
- 推理时遇到该 token,
和 的点积异常,导致 Attention Collapse(注意力坍缩)或 Semantic Void(语义真空)。
Q/K 失效的具体过程:以输入 "[Glitch]" 什么意思 为例,当模型读到"意思"这个 token 时,它生成查询向量
表现:输入包含 Glitch token 的提示时,模型输出彻底乱语。这与"幻觉"不同——幻觉是言之成理但事实错误,Glitch token 导致的是完全的语义崩溃。
5.3.3 Glitch Token 检测
方法 1:嵌入范数筛查
Glitch token 的 Embedding 向量 L2 范数异常小:
embeddings = model.get_input_embeddings().weight.data # [vocab_size, hidden_size]
norms = torch.norm(embeddings, p=2, dim=1)
# 在 L2 范数最小的 top-10000 中筛选多字中文 token
k = 10000
smallest_norms, indices = torch.topk(norms, k, largest=False)
# 过滤含中文字符 + 长度>1 的 token
zh_pattern = re.compile(r'[\u4e00-\u9fa5]')
for token_id, norm in zip(indices, smallest_norms):
token_str = tokenizer.decode([token_id])
zh_chars = zh_pattern.findall(token_str)
if len(zh_chars) > 1:
print(f"ID={token_id}, norm={norm:.4f}, token={token_str}")在 Qwen2.5-7B-Instruct(词表 152,064,嵌入维度 3,584)上,范数最小的 10,000 个 token 中发现 137 个多字中文 Glitch token 候选。
方法 2:字面异常扫描
for token_id in range(vocab_size):
token_str = tokenizer.decode([token_id])
if len(token_str) > 20 and "<|" not in token_str:
# 过长的 token(超过 20 字符的非特殊 token)
suspicious_tokens.append(token_id)在同一模型上发现 410 个字面可疑 token(包括超长空格序列、连续分隔符等)。
方法 3:复读机测试(Repetition Task)
给模型指令"请重复以下内容",正常 token 会被忠实复读,Glitch token 会导致模型输出完全无关的幻觉内容。
5.3.4 训练数据分析:嵌入范数分布
通过绘制所有 token 嵌入的 L2 范数直方图(log y 轴),可以分析训练数据质量:
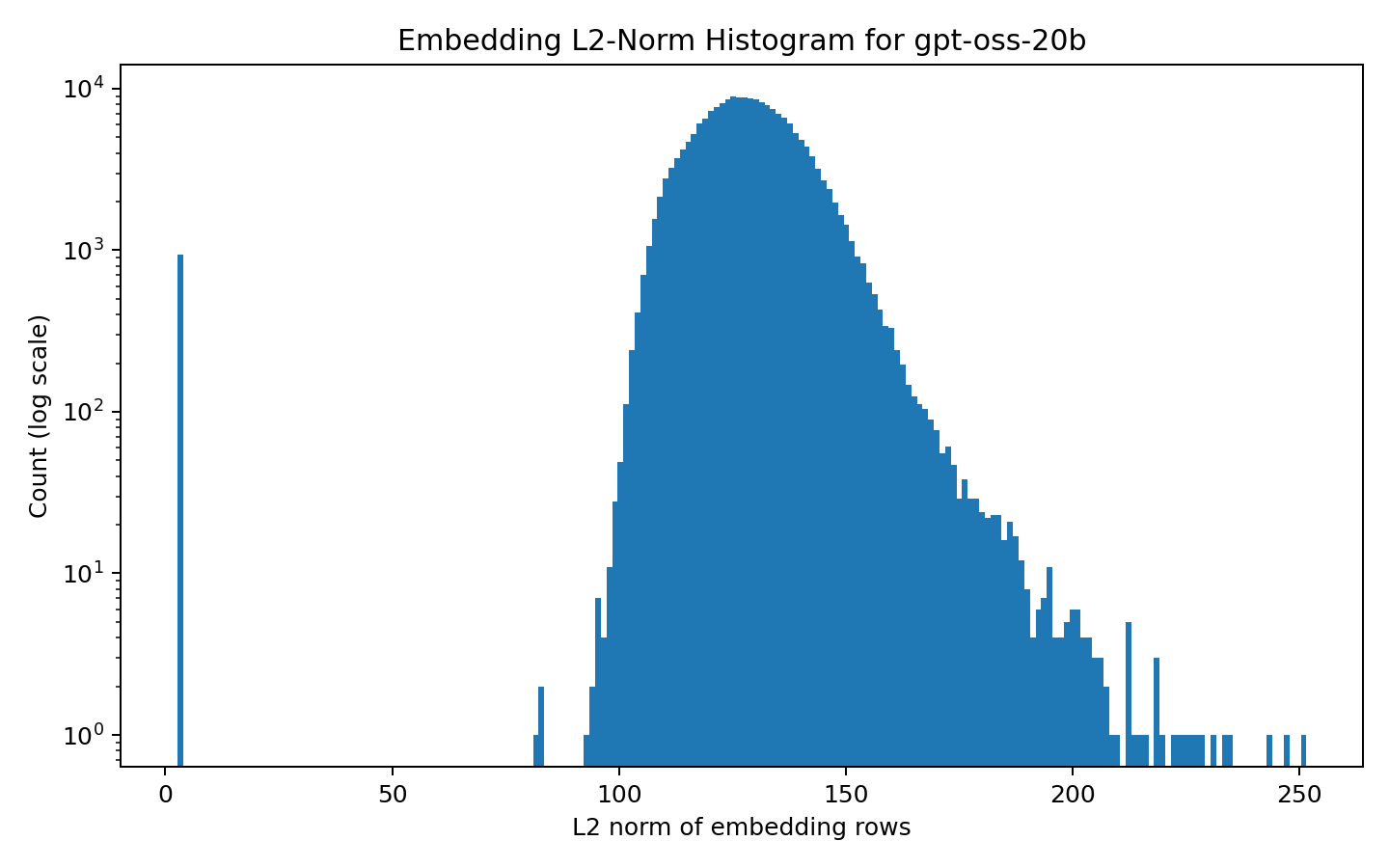
- 主体分布:大多数 token 范数集中在某个正常区间;
- 左侧长尾:范数极小的 token 是欠拟合的 Glitch token 候选;
- 右侧高范数:可能对应训练数据中高频出现的"语义核心"词,或某些特殊 token。
GPT-OSS-20B 的词表大小为 201,088,嵌入维度 2,880。范数分布可反推训练数据的语言组成和质量特征。
5.4 Mixture of Experts(MoE)架构
核心思想:MoE 是对 Transformer FFN 层的替换——不改变 Attention,只用"Router + N 个专家 FFN"替代单一 FFN,每次只激活 Top-K 个专家,用接近 Dense 模型的算力享受更大参数带来的知识容量。
5.4.1 MoE Transformer Block 的结构
标准 Transformer Block 包含两部分:
- 共享部分(Attention 层):所有 token 必经,负责 token 间的交互。
- MoE 部分(替代 FFN 层):由门控网络(Router)和多个专家(Experts)组成,负责 token 级别的特征变换。
:第 个专家,本质上是独立的 GLU-FFN(SwiGLU 结构); :Router 为当前 token 分配给专家 的权重(Top-K 内 softmax 归一化); - TopK:只激活权重最高的
个专家,其余不参与计算。
关键区分:Attention 层是 token interaction(token 间交互),FFN/MoE 是 token projection(token 级投影)。
5.4.2 参数量 vs 激活量
| 概念 | 含义 | 示例(DeepSeek-V3) |
|---|---|---|
| 总参数量 | 所有专家的参数之和 | |
| 激活参数量 | 单次推理实际参与计算的参数 |
MoE 的核心价值:用激活参数量决定推理 FLOPs(成本),用总参数量决定知识容量(能力)。
5.4.3 DeepSeekMoE:Shared + Routed 专家
DeepSeek 引入两类专家:
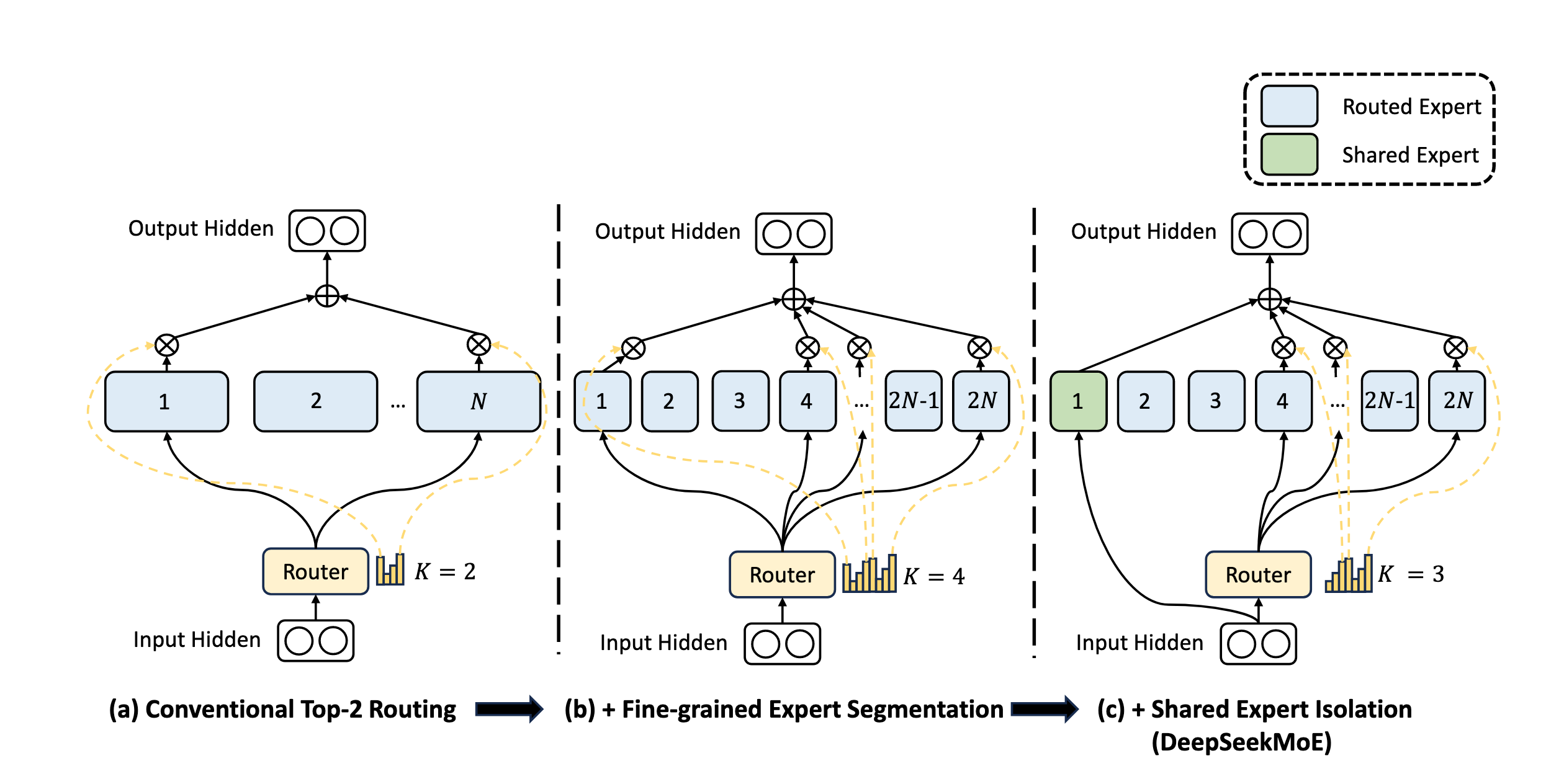
- Routed Expert(路由专家):根据 token 特征动态路由,每次激活 Top-K 个,提供专业化知识。
- Shared Expert(共享专家):所有 token 必经,提供通用知识的兜底。
输出整合为直接加和:
演化脉络:从
DeepSeek-V3 的层级安排:61 层解码器中,前 3 层使用标准 Dense MLP,后 58 层使用 MoE 结构。前几层保持 Dense 的设计考量是:低层 Transformer 仍在学习基础的 token 表示和浅层语法特征,此时表示尚未充分分化,Router 难以做出有意义的路由决策——强行稀疏激活反而会丢失关键的低层特征。等表示在低层 Dense 层中经过充分混合和分化后,中高层再引入 MoE 的稀疏路由,让不同专家处理不同类型的高层语义。
5.4.4 Router 与 Gating 机制
Router 的完整流程(以 norm_topk_prob=true 为例):
- 计算门控分数:
- 取 Top-K:选择分数最高的
个专家及其索引 - 仅在 Top-K 内做 softmax 归一化:
,保证
每个被选中的专家独立计算 GLU-FFN 输出后,按概率线性加权求和:
5.4.5 等效宽度与 FLOPs
Dense FFN 的 FLOPs:
MoE 激活
拉齐后,等效 Dense 宽度 =
关于"加权求和 vs concat"的矩阵视角:Top-K 的加权求和可等价改写为 concat 后乘一个按块稀疏矩阵:
验证(
V_concat = np.concatenate([v1, v2, v3]) # shape (6,)
A = np.kron(alpha.reshape(1, -1), np.eye(2)) # shape (2, 6)
y_matrix = A @ V_concat # [0.6, 4.1]
y_sum = alpha[0]*v1 + alpha[1]*v2 + alpha[2]*v3 # [0.6, 4.1] -- 完全一致5.4.6 Expert Parallelism(EP)
在多卡部署时,MoE 层采用专家并行。以 2 GPU、4 专家、6 token 为例:
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1 | Attention 计算 | 纯数据并行,每卡用本地 Attention 副本处理各自 batch |
| 2 | Router 计算 | 每卡独立计算 token 的目标专家 |
| 3 | All-to-All 通信 | token 按目标专家迁移到对应 GPU(如 T1 需要 E2,从 GPU-0 发到 GPU-1) |
| 4 | 专家计算 | 各 GPU 用本地专家处理收到的 token |
| 5 | 第二次 All-to-All | 计算结果返回原 GPU |
| 6 | 聚合输出 | 每个 GPU 将返回的结果聚合 |
关键存储分配:GPU-0 持有完整 Attention 副本 + 完整 Router 副本 + 专家 E0、E1(独有);GPU-1 持有同样的共享副本 + 专家 E2、E3(独有)。
5.4.7 MoE 代码实现
完整的按专家分桶实现(只计算被选中的 token,省显存/省 FLOPs):
class MoEFeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.gate = nn.Linear(cfg["emb_dim"], cfg["num_experts"], bias=False)
self.fc1 = nn.ModuleList([...]) # up projection, per expert
self.fc2 = nn.ModuleList([...]) # gate projection, per expert
self.fc3 = nn.ModuleList([...]) # down projection, per expert
def forward(self, x):
scores = self.gate(x) # (b, seq_len, num_experts)
topk_scores, topk_indices = torch.topk(scores, k, dim=-1)
topk_probs = torch.softmax(topk_scores, dim=-1) # 仅在 Top-K 内归一
x_flat = x.reshape(batch * seq_len, -1)
out_flat = torch.zeros_like(x_flat)
for expert_id in torch.unique(topk_indices_flat):
mask = topk_indices_flat == expert_id
selected_idx = mask.any(dim=-1).nonzero().squeeze(-1)
expert_input = x_flat.index_select(0, selected_idx)
# GLU-FFN: SiLU(up(x)) * gate(x), then down
hidden = F.silu(self.fc1[expert_id](expert_input)) * self.fc2[expert_id](expert_input)
expert_out = self.fc3[expert_id](hidden)
# 取出该专家对应的概率并加权
selected_probs = ...
out_flat.index_add_(0, selected_idx, expert_out * selected_probs.unsqueeze(-1))
return out_flat.reshape(batch, seq_len, emb_dim)手工验证:使用 3 个专家、2 维 embedding、3 个 token 的极小示例,逐步追踪每个 token 的路由、各专家的计算和概率加权过程,确认模块输出与手工重构完全一致(Allclose = True)。
5.5 Qwen3-30B-A3B 实例分析
"30B-A3B"的含义:总参数约 30B,激活参数约 3B——128 个专家中每次只激活 8 个。
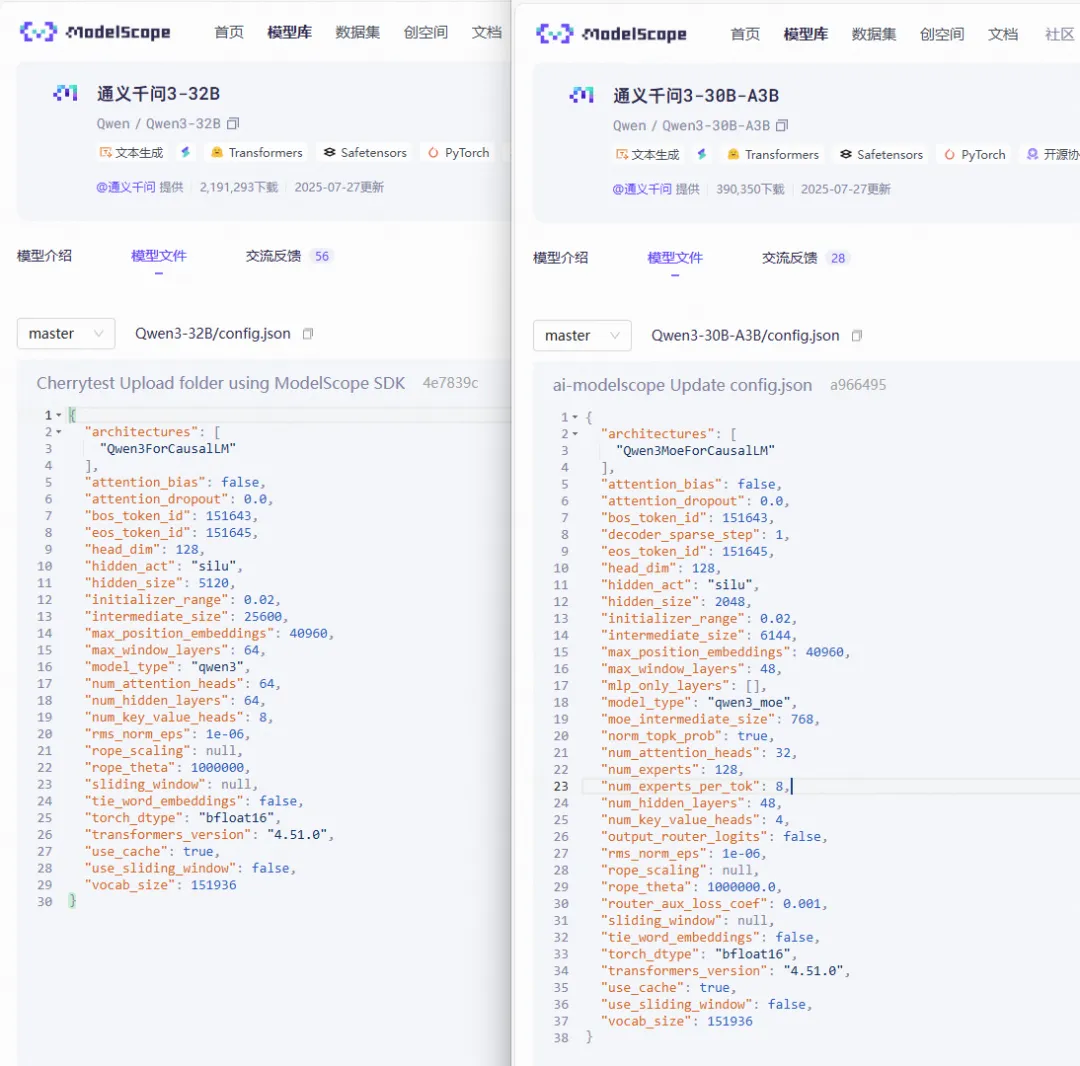
5.5.1 架构对比:Qwen3-30B-A3B vs Qwen3-32B
| 参数 | Qwen3-30B-A3B(MoE) | Qwen3-32B(Dense) |
|---|---|---|
| 架构 | Qwen3MoeForCausalLM | Qwen3ForCausalLM |
hidden_size | 2048 | 5120 |
num_hidden_layers | 48 | 64 |
num_attention_heads | 32 | 64 |
num_key_value_heads | 4 | 8 |
head_dim | 128 | 128 |
intermediate_size(Dense MLP) | 6144 | 25600 |
num_experts | 128 | -- |
num_experts_per_tok | 8 | -- |
moe_intermediate_size | 768 | -- |
decoder_sparse_step | 1(每层均 MoE) | -- |
norm_topk_prob | true | -- |
router_aux_loss_coef | 0.001 | -- |
rope_theta | 1,000,000 | 1,000,000 |
vocab_size | 151,936 | 151,936 |
关键设计差异:
- MoE 版本
hidden_size仅 2048(Dense 为 5120),但专家数量多(128 vs 无),形成"窄模型 + 多专家"的架构。 - 瘦专家:
moe_intermediate_size=768,远小于 Dense 的intermediate_size=25600。等效 Dense 宽度 =。 - GQA:MoE 版本 32 个 Q 头共享 4 组 KV 头(每 8 个 Q 头共享一组),Dense 版本 64 个 Q 头共享 8 组。
decoder_sparse_step=1且mlp_only_layers=[]:每一层都是 MoE 层。hidden_size不等于num_attention_heads * head_dim:的形状是 [hidden_size, num_heads * head_dim] = [2048, 4096]。
5.5.2 参数量计算
GQA(每层 Attention):
: :各 :
MoE(每层):
- Router:
- 每专家 FFN(SwiGLU 3 个矩阵):
- 128 个专家合计:
总参数量:
# Embedding(tie_word_embeddings=false,输入+输出各一份)
# + 48 层 * (Attention + Router + 128 Experts)
total = 151_936 * 2048 * 2 + 48 * (
(2048*4096 + 2048*512 + 2048*512 + 4096*2048) # Attention
+ 2048*128 # Router
+ 128 * (2048*768*3) # 128 Experts
)
# ≈ 30.5B激活参数量(Top-8):
active = 151_936 * 2048 * 2 + 48 * (
(2048*4096 + 2048*512 + 2048*512 + 4096*2048)
+ 2048*128
+ 8 * (2048*768*3) # 只有 8 个专家激活
)
# ≈ 3.35B -- 即"A3B"5.5.3 参数分布对比
| 组成部分 | 总参数占比 | 激活参数占比 |
|---|---|---|
| Attention(GQA) | ||
| MoE(Router + 128 Experts) | ||
| Embedding(输入 + 输出) |
对比 Dense 32B:Attention 占
推论:在 MoE 模型中,Embedding 层的激活参数占比远高于 Dense 模型(因为 MoE 激活参数少,Embedding 相对比重更大)。
5.5.4 残差一致性
MoE 层的输入/输出维度与 Attention 层保持一致(均为 hidden_size=2048),使残差连接无缝工作:
RMSNorm 不减均值(与 LayerNorm 不同),只按幅度归一再做逐维缩放:
每层两个 RMSNorm(Attention 前、FFN 前),加上模型末尾一个,参数量极小(
5.6 优化器:Muon、CLIP 梯度裁剪
关键词:Muon 通过矩阵正交化提升 token efficiency,CLIP 梯度裁剪防止 MoE 训练中 logits 爆炸。
5.6.1 Muon 优化器
Muon(读作
核心思想:将梯度投影到参数矩阵"最正交"的方向,减少冗余更新。效果是提升 token efficiency——相同训练 token 数下达到更低的损失。
Muon 适用于中间层的线性变换矩阵,通常与 Adam 混合使用(Embedding 和输出头仍用 Adam)。
5.6.2 梯度裁剪
标准梯度范数裁剪(Gradient Norm Clipping):
当梯度范数超过阈值
5.6.3 Muon CLIP
在 MoE 场景中,部分专家可能出现 max logits exploding(输出 logits 极端大),导致训练不稳定。Muon CLIP 在正交化更新的基础上,对 logits 的最大值加以裁剪,稳定 MoE 大规模训练。
5.7 Chat Templates 与 Thinking Budget
实用知识:Chat Template 标准化多轮对话格式,Thinking Budget 通过早停提示软性控制推理模型的思考深度。
5.7.1 Chat Templates
现代 Instruct 模型通过 Chat Template 将多轮对话格式化为单一 token 序列。以 Qwen 的 ChatML 格式为例:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
你好<|im_end|>
<|im_start|>assistant<|im_start|>/<|im_end|>是特殊 token,由 Tokenizer 直接映射;- 每个角色(system/user/assistant)的内容被包裹在这对标记之间;
- 模型在
<|im_start|>assistant\n之后开始生成回复。
5.7.2 Thinking Token
推理增强模型(如 QwQ、DeepSeek-R1)在生成最终回答前输出一段"思考过程":
<think>
... 模型内部推理过程 ...
</think>
最终答案:...<think> 和 </think> 是特殊 token,框定思考内容。模型被训练为在 </think> 后输出更准确的最终答案。
5.7.3 Thinking Budget(早停提示)
Thinking Budget 允许用户控制模型思考的"深度"(token 数量)。当需要快速响应时,可以在系统提示中注入早停提示:
Considering the limited time by the user, I have to give the solution
based on the thinking directly now.
</think>这种机制通过自然语言指令触发模型"提前结束思考",相当于软性的 Thinking Token Budget 控制。与硬性截断不同,早停提示让模型在思考中间主动过渡到输出模式,通常能保持更好的答案质量。
本章小结
RoPE 以绝对旋转编码实现相对位置感知,核心性质
;多尺度频率 赋予其天然的长程衰减特性(波的干涉导致远距离注意力趋零);实现时采用 Half-split 模式配合 rotate_half,等价于复数乘法。 长度外推的核心策略是"内插而非外推"。位置插值(PI)均匀压缩但损失近距离分辨率;NTK-Aware 放大 base 降低频率;YaRN 对不同频率维度差异化缩放,兼顾近距离精度与远距离覆盖。Qwen3 直接将
rope_theta提至配合长文本训练。 Glitch Token 是 Tokenizer-Model 不一致的产物:Tokenizer 训练数据含低质量文本(游戏私服、垃圾站),LLM 预训练数据已清洗这些内容,导致部分 token Embedding 欠拟合、范数极小。检测方法:嵌入范数筛查、复读机测试。嵌入范数分布可作为训练数据质量的间接指标。
MoE 将 FFN 替换为"Router + N 个专家",每次只激活 Top-K 个。DeepSeekMoE 引入 Shared Expert 作为通用基座 + Routed Expert 提供专业化。多卡部署采用 Expert Parallelism + All-to-All 通信。等效 Dense 宽度
。 Qwen3-30B-A3B 的参数构成:128 专家中每次激活 8 个,MoE 占总参数的
但仅贡献 的激活参数。"窄模型 + 多瘦专家"(hidden_size=2048, moe_intermediate_size=768)是其核心设计。 Muon 通过梯度矩阵正交化提升 token efficiency;CLIP 梯度裁剪防止 max logits 爆炸;两者在 MoE 大规模训练中尤为重要。
Chat Templates 将多轮对话标准化为 token 序列(ChatML 格式);Thinking Budget 通过早停提示软性控制推理深度,平衡响应速度与答案质量。
延伸阅读
- RoPE 原始论文:Su et al., RoFormer: Enhanced Transformer with Rotary Position Embedding (2021)
- 苏剑林 RoPE 心路历程:知乎回答
- YaRN:Peng et al., YaRN: Efficient Context Window Extension of Large Language Models (2023)
- NTK-Aware 插值:Reddit Thread by bloc97
- DeepSeekMoE:DeepSeek-AI, DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models (2024), arXiv:2401.06066
- MoE 综述:Fedus et al., Switch Transformers: Scaling to Trillion Parameter Models (JMLR 2022)
- Glitch Token 检测:GlitchMiner GitHub
- Muon 优化器:Kosson et al., Mechanistic Analysis of Muon Optimizer (2025), arXiv:2502.16586
- Qwen3 架构对比:Sebastian Raschka, The Big LLM Architecture Comparison
- Qwen3-MoE 实现:rasbt/LLMs-from-scratch Qwen3-MoE Notebook
- HuggingFace MoE 博客:https://huggingface.co/blog/moe