第 4 章:Transformer 架构全景
本章概览
Transformer 已成为大语言模型(LLM)的基础骨架,但"Transformer"这三个字背后隐藏着大量设计选择:Attention 与 MLP 如何分工?多头注意力有哪些省显存的变体?Attention 矩阵中到底藏着什么规律?推理时的两个阶段为何性能特征截然相反?
本章以"一个 token 在 Transformer 中走完一层"为线索,从整体架构出发,逐步深入 QKV 注意力、GQA/MLA 等 KV Cache 压缩方案、线性注意力与高效注意力、Attention Pattern 的可解释性、新型注意力机制(DSA、Gated DeltaNet)、残差连接与多流残差(MHC),最后落地到 Prefill-Decode 两阶段推理的工程实践。
4.1 Transformer 整体架构:Attention vs MLP 的分工
核心观点:Transformer 的每一层由两个子模块串联组成——Self-Attention 负责 token 之间的信息交互,FFN 负责 token 内部的知识提取与特征变换。二者分工明确:一个管交流,一个管知识更新。
Attention 与 FFN 的职能划分
Transformer 的每个 Decoder Block 包含两个串联子模块:
Self-Attention:token interaction。让当前位置的 token 能够"看到"序列中其他位置的信息,建立长距离依赖。Attention 本质上是一种加权求和——当前 token 对过去所有 token 的 Value 做加权聚合,权重由 Query-Key 匹配度决定。
Feed-Forward Network(FFN / MLP):token projection。token 在 Attention 完成全局交互后,经由 FFN 中存储的训练知识来更新自身表示。FFN 实际承担着知识库的角色——将训练数据中习得的事实知识以参数形式储存,在推理时根据 Attention 的"交流结果"从中提取相关信息。
参数规模差异
在现代 LLM 中,FFN 的参数量远大于 Attention。对于隐藏维度为
- 标准 FFN(中间维度
)参数量约为 - MHA 参数量约为
(不含 GQA 优化的情况下)
FFN 大约是 Attention 的两倍。这也从侧面印证了 FFN 的"知识库"定位——存储知识需要更大的参数容量。
非线性的真正来源
一个容易被忽视的事实:Attention 本身不引入非线性。
- Softmax 仅用于归一化(将 logits 转换为概率分布),对
的加权求和是线性操作 - 模型真正的非线性来源是 FFN 中的激活函数(如 SiLU、GeLU)
- FFN 的升维(通常
或更大)配合非线性激活,赋予模型强大的特征提取能力
Cross-Attention 扩展
在多模态生成(如 Stable Diffusion 的 U-Net)中,Cross-Attention 将不同模态的信息注入主干:
其中
4.2 QKV 注意力机制详解
核心观点:Vocabulary Embedding 是 Q、K、V 的"原材料",
、 、 是对其进行线性加工的投影矩阵。多头并行让不同 head 各司其职,Causal Mask 保证自回归生成的因果律。
从 Embedding 到 Q、K、V
对于第
- RoPE(Rotary Positional Embedding)对 Q 和 K 注入位置信息,
代表 token 的绝对位置 - V 不加位置编码——位置信息已经通过 Q-K 匹配来体现,V 只需携带语义内容
- 深层网络中
不再是原始 Embedding,而是经过多层混合处理后的表示,但"乘 投影"的机制不变
注意力计算
:Query 与所有 Key 做点积,衡量"当前 token 应该关注哪些历史 token" :缩放因子,防止高维点积值过大导致 Softmax 进入饱和区(梯度消失) - Softmax 后的权重矩阵乘以
:按关注度加权聚合 Value 信息
多头注意力(Multi-Head Attention)
实际模型并行进行
- 不同 head 可以捕捉不同类型的依赖关系——有的 head 关注语法结构、有的关注指代关系、有的关注语义相似性
- 所有 head 的输出拼接后经过
投影回 维度
Causal Mask
在 LLM 的自回归解码中,当前 token 只能关注自己及之前的 token,通过下三角掩码实现因果律:
K1 K2 K3 K4 (Keys)
Q1 1 0 0 0
Q2 1 1 0 0
Q3 1 1 1 0
Q4 1 1 1 1
(Queries)import torch
mask = torch.tril(torch.ones(4, 4))
# tensor([[1., 0., 0., 0.],
# [1., 1., 0., 0.],
# [1., 1., 1., 0.],
# [1., 1., 1., 1.]])上三角位置填充
4.3 GQA(Grouped Query Attention)
核心观点:GQA 让多个 Query head 共享同一组 K、V head,在不显著损失性能的前提下大幅削减 KV Cache 显存开销。MHA、MQA、GQA 是统一框架下的三种特例。
动机:KV Cache 的显存瓶颈
标准 MHA 中,每个 Q head 都对应独立的 K、V head,KV Cache 大小随 head 数和序列长度线性增长。长序列推理时(如 128K token),KV Cache 动辄占据数十 GB 显存,成为部署瓶颈。
GQA 原理
核心思想:几个"查询专家"(Q head)共享同一份参考资料(K 和 V head)。
符号定义:
:Query head 数量( num_attention_heads):KV head 数量( num_kv_heads):每组 KV head 被共享的 Q head 数量(分组大小) :每个 head 的维度
投影:
模型为每个 Q head 生成独立的
分组注意力计算:第
输出拼接:
其中
三种特殊情况
| 变体 | 条件 | 分组大小 | 含义 |
|---|---|---|---|
| MHA | 每个 Q head 对应独立 KV,最强表达力 | ||
| MQA | 所有 Q head 共享同一 KV,显存最省 | ||
| GQA | 在性能与效率之间灵活权衡 |
Llama 3、Qwen 3 等主流模型均采用 GQA,典型配置如
KV Cache 代码示意
class KVCache:
def __init__(self):
self.cache = {"key": None, "value": None}
def update(self, key, value):
if self.cache["key"] is None:
self.cache["key"] = key
self.cache["value"] = value
else:
self.cache["key"] = torch.cat([self.cache["key"], key], dim=1)
self.cache["value"] = torch.cat([self.cache["value"], value], dim=1)KV Cache 的本质:Decode 阶段不需要重新计算历史 token 的 K 和 V,只需把新 token 的
验证:KV Cache 与全量计算等价
import torch
def causal_mask(n):
m = torch.triu(torch.ones(n, n), diagonal=1)
m = m.masked_fill(m.bool(), float("-inf"))
return m
def attn(Q, K, V, mask):
d = Q.size(-1)
logits = (Q @ K.transpose(-1, -2)) / (d ** 0.5)
logits = logits + mask
P = torch.softmax(logits, dim=-1)
return P @ V, P
# 全量计算 vs KV Cache 增量计算
# 1. 全量:把 prefix + 新 token 拼起来一次算完
X_full = torch.cat([X1, x2], dim=0)
Y_full, _ = layer(X_full, causal_mask(n+1))
# 2. 增量:先算 prefix,缓存 K1/V1,再只算新 token 的 q2
q2 = layer.Wq(x2); k2 = layer.Wk(x2); v2 = layer.Wv(x2)
K_cat = torch.cat([K1, k2], dim=0)
V_cat = torch.cat([V1, v2], dim=0)
y_last = layer.Wo(torch.softmax(q2 @ K_cat.T / (d**0.5), dim=-1) @ V_cat)
# 验证等价
torch.allclose(Y_full[n:n+1], y_last, atol=1e-6) # True输出解读:全量计算最后一个 token 的输出与 KV Cache 增量计算的结果完全一致(误差
4.4 MLA(Multi-head Latent Attention)
核心观点:MLA 将 K、V 压缩到低维潜在空间后存入 KV Cache,推理时再投影回原始大小。与 GQA "减少 head 数量"不同,MLA 的策略是"降低每个 head 的维度"(低秩压缩)。
核心思路
MLA 的关键操作是对 KV 做低秩压缩(Low-rank Compression):
存储阶段(写入 KV Cache):
其中
计算阶段(推理时还原):
从压缩表示投影回原始大小后,正常执行注意力计算。
缓存布局:哪些通道压缩,哪些不压缩
DeepSeek-V3 的 MLA 并非对所有 Q/K 维度统一处理,而是将每个 head 的 Q/K 分为两组通道:
- nope 通道(
qk_nope_head_dim = 128):不应用 RoPE 的维度。这部分只携带语义信息,与位置无关,因此可以通过压缩并在推理时还原——从 乘以 即可恢复完整的 nope 维度 K 向量。 - rope 通道(
qk_rope_head_dim = 64):应用 RoPE 的维度。这部分编码了位置相关信息(),而 RoPE 旋转后的向量无法从压缩表示中还原(旋转角度依赖于绝对位置 ,丢失后不可恢复),因此 rope 通道的 K 必须直接缓存,不经过压缩。
实际 KV Cache 中每个 token 存储的内容为:
即每 token 缓存
优势与代价
- 优势:KV Cache 显存从
压缩到 ,大幅降低存储开销 - 代价:每步推理多一次矩阵乘法(nope 通道的还原投影),计算量略增
与 GQA 的对比
| 维度 | GQA | MLA |
|---|---|---|
| 压缩策略 | 减少 KV head 数量 | 降低 KV 的表示维度(低秩压缩) |
| 推理额外开销 | 无 | 一次矩阵乘法(还原 nope 通道) |
| KV Cache 格式 | 完整的 K、V 向量 | 压缩表示 |
| 代表模型 | Llama 3、Qwen 3 | DeepSeek-V2 / V3 / R1 |
DeepSeek-V3 的 MLA 配置
- Query 低秩维度:
- KV 低秩维度:
- 部分 RoPE:
qk_rope_head_dim = 64(直接缓存),qk_nope_head_dim = 128(通过还原)
直觉理解:如果把 GQA 比作"多个查询专家共用一份参考资料",MLA 则是"把参考资料压缩成摘要存档,用的时候再展开"——但那些盖了位置戳记(RoPE)的页面无法压缩归档,必须原样保留。两种策略可以互补,但目前主流模型倾向于选择其中一种。
4.5 线性注意力与高效注意力
核心观点:标准 Softmax 注意力的
复杂度在长序列下代价极高。FlashAttention 通过分块 IO 优化解决显存瓶颈(但 FLOPs 不变),线性注意力则从数学上将复杂度降至 ,代价是精度损失。
标准注意力的复杂度
标准 Softmax 注意力的时间和空间复杂度均为
FlashAttention:IO 感知的分块计算
FlashAttention 的核心不是降低 FLOPs,而是矩阵分块(Matrix Tiling)——将注意力计算限制在 GPU 的 SRAM 中完成,避免大量 HBM 读写:
- 时间复杂度:仍为
- 显存复杂度:从
降至 ——无需显式存储完整的 注意力矩阵
在 Prefill 阶段(长 Prompt 的并行计算)收益尤为显著。
线性注意力
线性注意力通过对 Softmax 进行核函数近似(Kernel Approximation),利用矩阵乘法的结合律规避
关键技巧:改变计算顺序。标准注意力先算
代价:
4.6 Attention Pattern 与 Attention Sink
核心观点:通过可解释性(Mechanistic Interpretability)视角观察 LLM 的注意力矩阵,可以发现三种典型电路——Attention Sink(BOS 汇聚)、Previous Token Head(前缀传递)和 Induction Head(模式复制),它们分别对应 Softmax 的归一化压力、局部信息搬运和 In-Context Learning 的核心机制。
Attention 矩阵的基本结构
在 Causal Attention 下,注意力分数矩阵(Softmax 之前的 logits
Pattern 1:Attention Sink(注意力汇聚点)
在绝大多数层(尤其是中后层),当前 token 的 Query 与第一个 token(BOS)的 Key 计算出的点积异常大,即使 BOS 在语义上毫无意义。
原因分析:
Softmax 的归一化压力:
强制所有权重之和为 1。当当前 token "无事可做"(不需要关注任何具体 token)时,需要一个"垃圾回收站"来卸载多余的概率质量。如果不集中投放,概率会平均分散,产生高熵分布——这通常不是模型期望的输出。 BOS 的位置特权(Universal Visibility):在 Causal Masking 下,BOS 是唯一所有后续 token 都能看到的 token。模型倾向于将其训练成通用的"默认关注点"——一个安全的概率垃圾桶。
Causal Mask 下的可见性:
- 第 100 个 token 能看到第 1~99 个
- 第 5 个 token 只能看到第 1~4 个
- 只有第 1 个(BOS)对所有后续 token 可见Pattern 2:Previous Token Head(PTH,前一 token 头)
某些 head(通常位于浅层)专门将前一个 token 的信息"搬运"到当前 token 的残差流中:
- 表现:注意力矩阵在副对角线(
)处高度集中 - 作用:让每个 token 的表示中暗含"我前面是谁"的信息——token B 的残差流中携带了 token A(B 的前驱)的副本
- 独立性:PTH 不负责预测下一个词,它始终盯着
,不管 是什么
PTH 的自动检测:
# 提取每个 Head 在"上一位置"的平均注意力权重
for layer_idx in range(num_layers):
for head_idx in range(num_heads):
attn_matrix = attentions[layer_idx][0, head_idx].numpy()
# 副对角线:每个 token 对其前一个 token 的注意力值
diag_vals = np.diag(attn_matrix, k=-1)
score = np.mean(diag_vals)
prev_token_scores[layer_idx, head_idx] = score输出解读:在 GPT-2 上运行上述代码,可以发现 Layer 4, Head 11 在副对角线上得分最高(约 0.65),其注意力热力图呈现清晰的"次对角线亮带"——每个 token 几乎只看前一个 token。
Pattern 3:Induction Head(归纳头)
Induction Head 是 In-Context Learning(ICL)的核心电路,通常出现在模型深度的 1/3 至 1/2 处。
工作原理(以序列 ... A B ... A 为例):
- PTH 先将 token A 的信息搬运到 B 的残差流中——B 的潜台词变成"我是 B,而且我紧跟在 A 后面"
- 当模型遇到第二个 A 时,其
将 A 映射到一个子空间,方向代表"呼叫所有前缀是 A 的 token" - B 的
不是读 B 本身的内容,而是读 B 身上"我跟在 A 后面"的标签—— 实际上是一个前缀提取器,而非内容提取器 - Query-Key 匹配成功,模型强力关注 B,预测下一个 token 也应该是 B
实验代码:
# 构造重复序列诱发 Induction Head
INPUT_TEXT = (
"The secret code is 1234. The magic word is abracadabra. "
"Repeat: The secret code is 1234. The magic word is"
# 此时模型应预测 abracadabra
)输出解读:在 Qwen2.5-3B-Instruct 上运行三种 pattern 的评分热力图(Sink / Local / Induction),可以观察到:
- Sink Score 在深层普遍较高(几乎所有 head 的第 0 列注意力权重显著)
- Local Score 在浅层某些 head 上极高(清晰的次对角线条带)
- Induction Score 在中层少数 head 上突出(对重复 pattern 的 target key 产生稀疏高注意力)
层级功能分化
| 层级 | 主要 | 功能 |
|---|---|---|
| 浅层 | 局部关注(前 1-3 token) | 构建 n-gram 特征与局部句法结构 |
| 中层 | Induction Head / 语义检索 | 长距离依赖、ICL 模式匹配 |
| 深层 | 平滑分布或特定任务 | 语义高度抽象,微调输出分布,最终预测的置信度校准 |
位置局部性与 RoPE 的衰减
对角线附近(
与 位置相近)的点积通常较大;随距离 增加,点积幅度呈震荡衰减。
这来自 RoPE 的数学特性:对于相对距离
稀疏性与重尾分布
对于同一个 Query,绝大多数 Key 的点积接近 0 或负数,只有极少数 Key 产生显著正值。
原因:
- 高维正交性:在
的空间中,随机向量大概率近似正交(点积接近 0) - 训练目标的判别性:模型为降低 Cross-Entropy Loss 必须做出"确信"预测,反向传播迫使
与特定 高度对齐(大点积),与无关 保持正交,从而在 Softmax 后形成尖锐分布(Sharp Distribution)
4.7 Differential/State-space 注意力(DSA、Gated DeltaNet)
核心观点:标准 Softmax 注意力并非唯一选择。DeepSeek Sparse Attention(DSA)通过稀疏化降低长上下文的计算成本;Gated DeltaNet 将线性 RNN 与注意力融合,在推理时享有常数时间/常数显存的线性 RNN 优势,在训练时可并行化。
DeepSeek Sparse Attention(DSA)
DSA 是 GLM-5 等模型采用的稀疏注意力变体。核心思想:并非每个 token 都需要关注全部历史,通过局部窗口 + 全局 token的稀疏化模式减少计算量,在保持长上下文能力的同时显著降低部署成本。
Gated DeltaNet
Gated DeltaNet 是线性 RNN 与注意力机制的融合体,代表了近期 LLM 架构探索的一个重要方向:
- DeltaNet:借鉴"Delta 规则"(误差驱动学习)——用当前 token 的误差信号更新隐藏状态矩阵,而非简单地叠加或遗忘
- Gated DeltaNet:在 DeltaNet 基础上引入门控机制(类似 GRU/LSTM),控制信息写入隐藏状态的强度
- 双模态执行:训练时可并行化(类似注意力的矩阵运算);推理时等价为线性 RNN(逐 token 更新隐藏状态,
时间/ 显存)
Qwen3-Next、Kimi Linear 等模型正在探索这类混合架构(Hybrid Architecture):用线性 RNN 层替代部分 Softmax Attention 层,在长序列推理效率上超越标准 Transformer,同时保持相近的表达能力。
4.8 残差连接与 MHC
核心观点:残差连接(Skip Connection)通过 Identity 旁路保证梯度能无损地从深层回传到浅层,是训练深层网络的关键。MHC(Multi-Head Composition)将残差网络重新解读为多条并行信息流,用双随机矩阵实现稳定的流间混合。
残差连接(Skip Connection)
ResNet 提出的跳跃连接解决了深层网络的梯度消失问题:
:残差函数, 可以是 CNN / Attention / FFN - 直觉:网络只需学习"增量"(residual),而非完整映射
逐层展开:
这意味着任何浅层
梯度分析
项 1 的关键意义:深层
对比普通网络:
- 普通网络:
,连乘导致指数级衰减(Vanishing Gradient) - ResNet:梯度是加法形式
,始终有 Identity 保底
即使权重初始化很小(
Transformer 中的残差连接
标准实现(Pre-LN 架构):每个子层先 Normalize,再变换,最后加回输入。
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = GroupedQueryAttention(...)
self.ff = FeedForward(cfg)
self.norm1 = RMSNorm(cfg["emb_dim"], eps=1e-6)
self.norm2 = RMSNorm(cfg["emb_dim"], eps=1e-6)
def forward(self, x, mask, cos, sin):
# Attention 子层 + 残差
shortcut = x
x = self.norm1(x)
x = self.att(x, mask, cos, sin)
x = x + shortcut # 残差连接
# FFN 子层 + 残差
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = x + shortcut # 残差连接
return x输出解读:每个 Transformer Block 包含两次残差连接——Attention 后一次、FFN 后一次。梯度可以通过两条 shortcut 通道无损回传。
多流残差(MHC,Multi-Head Composition)
从"并行信息流"的视角重新审视残差网络。设第
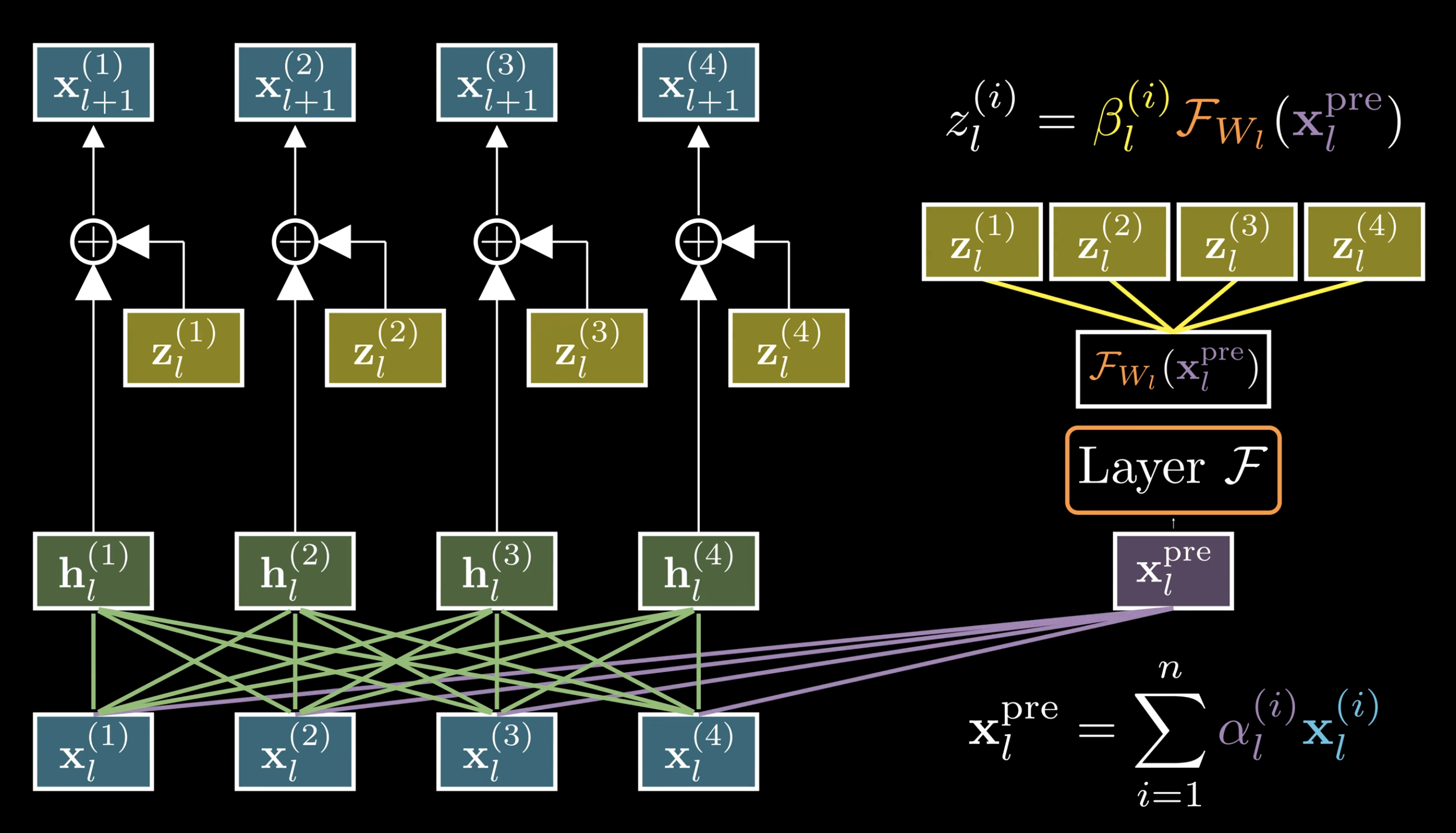
每层操作分为三步:
- 聚合(Aggregate Streams):
,其中 - 变换并扩展(Transform & Expand):
,其中 - 混合(Mix Streams):
,其中
最终输出:
双随机矩阵的稳定性保证
当
- 谱范数恒为 1:矩阵连乘不会导致梯度消失或爆炸
- 乘法封闭性:两个双随机矩阵之积仍为双随机矩阵
- 几何结构:双随机矩阵构成 Birkhoff 多面体(Birkhoff Polytope),是置换矩阵的凸包
# Sinkhorn-Knopp 算法生成双随机矩阵
def generate_doubly_stochastic(n, max_iter=1000, tol=1e-6):
A = torch.rand(n, n)
for _ in range(max_iter):
A = A / A.sum(dim=1, keepdim=True) # 行归一化
A = A / A.sum(dim=0, keepdim=True) # 列归一化
if torch.allclose(A.sum(dim=1), torch.ones(n), atol=tol):
break
return A
# 验证乘法封闭性
A = generate_doubly_stochastic(10)
B = generate_doubly_stochastic(10)
C = A @ B
print(torch.allclose(C.sum(dim=1), torch.ones(10), atol=1e-5)) # True
print(torch.allclose(C.sum(dim=0), torch.ones(10), atol=1e-5)) # True输出解读:乘积矩阵
4.9 Prefill-Decode 两阶段推理
核心观点:LLM 推理包含两个性能特征截然相反的阶段——Prefill 是计算密集型(Compute-bound),GPU 利用率高;Decode 是访存密集型(Memory-bound),GPU 核心频繁空转。针对两个阶段的不同瓶颈,工程上有各自的优化策略。
两阶段对比
| 特征 | Prefill(上下文处理) | Decode(逐 token 生成) |
|---|---|---|
| 数学运算类型 | GEMM(矩阵 | GEMV(矩阵 |
| 输入形状 | ||
| Attention 维度 | ||
| Causal 实现 | 显式 Mask 矩阵(Masked Fill) | 隐式(只用当前 Query 查过去 KV) |
| 瓶颈 | Compute-bound(算力) | Memory-bound(显存带宽) |
| GPU 利用率 | 高(Tensor Core 跑满) | 低(等待显存读取) |
| KV Cache | 写入(Write Only) | 读取 + 追加(Read + Append) |
Prefill 阶段:并行计算(Compute-bound)
目的是"阅读"并理解 Prompt,一次性处理所有
注意力计算:
虽然所有 token 并行计算,但 Causal Mask 保证因果律——第
监控表现:
nvitop gpu-util:瞬间飙升至接近 100%(Tensor Core 全速运转)nvitop memory:阶梯式突增(一次性为所有 Prompt token 写入 KV Cache)
Decode 阶段:串行自回归(Memory-bound)
每步只处理 1 个 token,计算量极小,但需从 HBM 中读取全部 KV Cache:
注意这里是向量
监控表现:
nvitop gpu-util:相对较低,呈锯齿状波动nvitop memory:随生成长度增加缓慢线性爬升(逐 token 累积 KV Cache)
系统级优化
| 技术 | 主要受益阶段 | 原理 |
|---|---|---|
| FlashAttention | Prefill | 分块计算(Matrix Tiling),将 |
| PagedAttention(vLLM) | Decode | 非连续内存管理,减少 KV Cache 碎片化,支持更大 Batch Size |
| Chunked Prefill | 两者 | 将长 Prefill 拆成小块与 Decode 穿插执行,避免 Head-of-line blocking |
本章小结
本章从宏观架构到微观机制,系统覆盖了现代 Transformer 的核心设计:
Attention vs MLP:Attention 负责 token 间信息交互,FFN 负责知识存储与特征变换;模型的非线性来源是 FFN 的激活函数,而非 Softmax。
QKV 机制:线性投影将 Embedding 加工为 Q、K、V,配合 RoPE 注入位置信息;多头并行捕捉不同类型的依赖关系;Causal Mask 保证自回归的因果律。
GQA:多个 Q head 共享 KV head,在几乎不损失性能的前提下大幅削减 KV Cache 显存。MHA(每 Q 独立 KV)、MQA(所有 Q 共享一 KV)、GQA(分组共享)是统一框架下的三种特例。
MLA:低秩压缩 KV 后存入 Cache,推理时还原。与 GQA "减少 head 数"互补,策略是"降低表示维度"。DeepSeek 系列的关键设计。
线性注意力:通过核函数近似和计算顺序调换,将
降至 ,代价是精度损失。FlashAttention 则在不改变数学的前提下通过 IO 优化解决显存瓶颈。 Attention Pattern:Attention Sink(BOS 作为概率垃圾桶)、PTH(搬运前一 token 信息)、Induction Head(ICL 的模式复制电路)是三大典型可解释性电路。注意力的稀疏性、RoPE 的远程衰减、层级功能分化共同塑造了 LLM 的行为。
DSA 与 Gated DeltaNet:稀疏注意力和线性 RNN-Attention 混合架构代表了超越标准 Softmax Attention 的新方向,Qwen3-Next 和 Kimi Linear 等模型正在探索这条路线。
残差连接与 MHC:Identity 旁路保证梯度无损传播,即使权重初始化很小也能训练;MHC 框架用双随机矩阵实现稳定的多流残差混合。
Prefill-Decode 两阶段:Prefill 是 Compute-bound(矩阵乘法,GPU 满载),Decode 是 Memory-bound(向量乘法,等待数据搬运)。FlashAttention / PagedAttention / Chunked Prefill 分别针对各自瓶颈提供优化。
延伸阅读
- Attention Is All You Need:Vaswani et al., Attention Is All You Need (NeurIPS 2017) — Transformer 原始论文
- GQA 原始论文:Ainslie et al., GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (2023)
- MLA / DeepSeek-V2:DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient MoE Language Model (2024)
- FlashAttention:Dao et al., FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (NeurIPS 2022)
- Induction Heads:Olsson et al., In-context Learning and Induction Heads (2022) — ICL 的核心可解释性工作
- Attention Sink:Xiao et al., Efficient Streaming Language Models with Attention Sinks (ICLR 2024)
- ResNet 残差连接:He et al., Identity Mappings in Deep Residual Networks (ECCV 2016)
- Gated DeltaNet:rasbt/LLMs-from-scratch DeltaNet 章节
- LLM 架构全景对比:Sebastian Raschka, The Big LLM Architecture Comparison (2024)
- KV Cache 详解:HuggingFace Blog: KV Caching
- How LLMs Store Facts:3Blue1Brown, Deep Learning Chapter 7 — FFN 作为知识库的直觉解释