第 7 章:多模态与可解释性
本章从计算机视觉的经典基石出发,沿"CNN → 目标检测/分割 → 视觉-语言对齐 → 图像生成 → VLM → 原生多模态"的技术路径逐层推进,最后深入 LLM 可解释性——Embedding 表示分析、Steering Vectors 与对齐的内部机制。目标是让读者既能搭建多模态应用,也能打开 Transformer 的"盖子"看清内部正在发生什么。
7.1 CV 基础:CNN、图像处理(OpenCV)
在进入多模态深水区之前,有必要先打下两块基石:卷积神经网络如何提取视觉特征,以及经典图像处理的核心操作。
7.1.1 深度 CNN
Deep CNN 的核心范式是堆叠卷积层并逐步降低空间分辨率、增加通道数:
- 卷积层(Conv Layer):用 filter(卷积核)在空间上滑动,输出特征图。通道数量通常随深度递增——从 RGB 的 3 通道到数百通道。每个通道可理解为"对图像的一种分析维度"。
- 池化层(Pooling Layer):降低空间分辨率("降 shape"),保留最显著的激活值。
直觉:浅层卷积学习边缘、纹理等低级特征;深层卷积学习物体部件乃至完整语义概念。这种从低级到高级的层次化特征提取,正是 CNN 在图像识别领域统治十年的根基。
7.1.2 OpenCV 图像处理
二值化
将灰度图转为 0/1 矩阵,是许多视觉分析的第一步:
# 依赖:from PIL import Image; import numpy as np
image = Image.open(input_path).convert("RGB")
gray = np.array(image.convert("L"))
binary_mask = (gray > 200).astype(np.uint8) # 阈值二值化距离变换
cv2.distanceTransform 计算每个前景像素到最近背景像素的距离:
其中
| 距离类型 | 公式 | 直觉 |
|---|---|---|
| L1(曼哈顿) | 城市棋盘路网,只能横竖移动 | |
| L2(欧氏) | 直线距离 | |
| Chessboard(切比雪夫) | "国王步数":横竖斜各算 1 步 |
形态学运算
基础操作是腐蚀(Erosion)和膨胀(Dilation),复合操作由它们组合而成:
# 依赖:import cv2; src 为二值图(numpy 数组),kernel 为形态学核(如 cv2.getStructuringElement 生成)
cv2.morphologyEx(src, cv2.MORPH_CLOSE, kernel) # 闭运算:先膨胀后腐蚀,填充裂缝
cv2.morphologyEx(src, cv2.MORPH_OPEN, kernel) # 开运算:先腐蚀后膨胀,去除噪点典型工作流:二值化 → 闭运算去小裂缝 → 连通性分析。
连通性分析
# 依赖:import cv2; binary_img 为经过二值化处理的 numpy uint8 数组
num_labels, labels, stats, centroids = cv2.connectedComponentsWithStats(
binary_img, connectivity=8 # 8 联通:斜向也算相邻
)以一个 5×5 的二值矩阵为例,4 联通(只计上下左右)识别出 3 个独立前景区域,而 8 联通(含斜向)将对角相邻的像素归为同一连通域,只识别出 2 个:
# 4 联通结果 # 8 联通结果
[[1, 0, 0, 0, 0], [[1, 0, 0, 0, 0],
[0, 2, 0, 0, 0], [0, 1, 0, 0, 0], # (0,0) 和 (1,1) 对角相邻 → 同一域
[0, 0, 0, 3, 3], [0, 0, 0, 2, 2],
[0, 0, 0, 3, 3], [0, 0, 0, 2, 2],
[0, 0, 0, 0, 0]] [0, 0, 0, 0, 0]]透视变换
M = cv2.getPerspectiveTransform(src_pts, dst_pts) # 计算单应性矩阵 H (3×3)
warped = cv2.warpPerspective(img, M, (width, height)) # 应用变换透视变换基于单应性矩阵(Homography Matrix)——描述两个平面之间的二维射影几何变换。给定 4 个畸变源点(梯形)和 4 个目标点(矩形),即可解算出
注意:透视变换的前提是"直线投影后还是直线"。如果跳过相机标定(Camera Calibration)和去畸变(Undistort),镜头的桶形/枕形畸变会导致图像边缘出现无法弥合的撕裂。
7.2 目标检测与分割:DETR、YOLO、SAM、Grounded-DINO
CV 的三大基础任务——检测(det)、识别(rec)、分割(seg, 生成 0/1 mask)——在 Transformer 时代迎来了范式变革。
7.2.1 DETR:基于 Transformer 的端到端检测
DETR(Detection Transformer, 2020)是第一个将 Transformer 引入目标检测的工作,彻底抛弃了 NMS(非极大值抑制)和 anchor box 设计:
- 架构:CNN 骨干提取特征图 → Transformer Encoder-Decoder → 直接预测
个目标的位置和类别 - 二分图匹配损失:将预测框与 ground truth 做一对一匹配,通过 Hungarian 算法求最优分配,从根本上消除重复检测
- 意义:证明了 Transformer 能直接处理目标检测这类密集预测任务,为后续 DINO、RT-DETR 等工作奠定基础
7.2.2 SAM 系列:从可提示分割到概念分割
SAM 系列(Meta AI)定义并持续演进了可提示视觉分割范式:
| 版本 | 范式 | 提示类型 | 核心特点 |
|---|---|---|---|
| SAM 1 | PVS(Promptable Visual Segmentation) | 点、框、掩码 | 图像分割基础模型 |
| SAM 2 | PVS + 视频追踪 | 点、框、掩码 | 跨帧追踪、Re-ID(消失再出现保持 ID) |
| SAM 3 | PCS(Promptable Concept Segmentation) | 文本、图像范例、混合 | 概念级分割、语义感知 |
PVS vs PCS——两种范式的本质区别:
- PVS(SAM 1/2):对象级、语义无关。每次交互指定一个特定物体。模型不需要"懂"物体是什么,只需根据点/框等几何提示把连通区域抠出来。
- PCS(SAM 3):概念级、语义感知。给出 "cat" 这样的名词短语,模型理解语义后在全图中找出所有匹配的实例。支持文本、图像范例及两者的混合输入。
SAM 2 代码示例:
from sam2.build_sam import build_sam2_video_predictor
from sam2.automatic_mask_generator import SAM2AutomaticMaskGenerator
# 自动生成全图所有区域的 mask(无语义标签)
generator = SAM2AutomaticMaskGenerator(model)
masks = generator.generate(image)
# 视频追踪:在第 0 帧添加初始 mask,然后传播到整个视频
predictor.add_new_mask(inference_state, frame_idx=0, obj_id=1, mask=init_mask)
video_segments = predictor.propagate_in_video(inference_state)SAM 3 的文本驱动分割:
from transformers import Sam3Processor, Sam3Model
model = Sam3Model.from_pretrained("facebook/sam3").to(device)
processor = Sam3Processor.from_pretrained("facebook/sam3")
# 文本提示分割
inputs = processor(images=image, text="ear", return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_instance_segmentation(
outputs, threshold=0.5, mask_threshold=0.5,
target_sizes=inputs.get("original_sizes").tolist()
)[0]
print(f"Found {len(results['masks'])} objects")
# results 包含 masks(二值掩码)、boxes(边界框)、scores(置信度)SAM 3 还支持多框正负提示(正框圈选目标、负框排除干扰)和批量推理(一次对多张图使用不同文本提示)。
SAM3 Agent——VLM 作大脑、SAM 作双手:
SAM3 官方提供了 Agent 工作流,让 VLM(如 GPT-4o、Qwen3-VL)负责高层推理,SAM 3 负责底层分割:
| 工具 | 功能 |
|---|---|
segment_phrase | 调用 SAM 3 对全图按名词短语分割,返回带编号 Mask 的图片 |
examine_each_mask | 逐个放大 Mask 让 VLM 二次确认(Accept/Reject) |
select_masks_and_return | 提取指定 ID 的 Mask 作为最终输出 |
report_no_mask | 确认图中无符合描述的目标 |
System Prompt 明确禁止使用方位词("left child")和数量词作为 SAM 输入,强制要求使用通用名词("child")。VLM 负责在上一轮结果中进行空间推理和选择。
7.2.3 Grounded-DINO 与 Grounded-SAM
Grounding DINO:零样本开集目标检测——输入任意文本描述,输出边界框,无需预定义类别集。
Grounded-SAM2不是单一模型,而是一个串联工作流(Pipeline):
文本描述(如 "dog")
→ Grounding DINO:开集检测 → 边界框
→ SAM 2:以框为 prompt → 精确分割 Mask
→ SAM 2 Video Predictor:跨帧追踪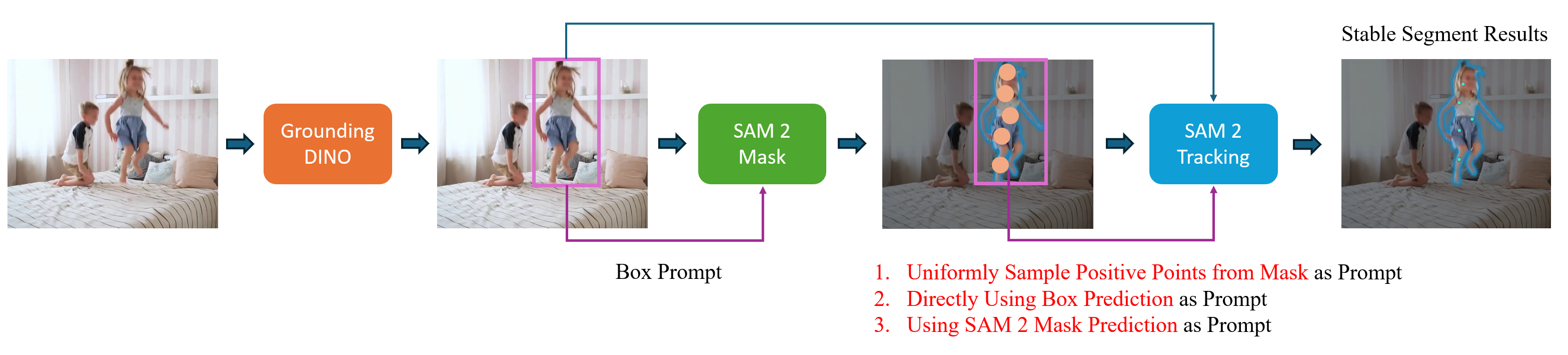
LangSAM 是更简化的变体:输入物体名称(如 "screwdriver"),直接生成对应 Mask,无需手动画框。
7.2.4 Gemini 的原生视觉分割能力
Gemini 2.5 Flash 已具备原生分割能力(目前 Gemini 3 暂未集成):
- 检测输出
box_2d(归一化矩形框坐标,[ymin, xmin, ymax, xmax],范围 0-1000) - 分割输出
mask(base64 编码的 PNG 二值图) - 内部可能使用 Visual Tokens 的自回归生成,但 API 层已转换为 base64 图片字符串
# 依赖:from google import genai; from google.genai import types
# img 为已加载的图片对象(如 PIL.Image),client 为 genai.Client 实例
prompt = """
Give the segmentation masks for the objects.
Output a JSON list where each entry contains "box_2d", "mask", and "label".
"""
config = types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_budget=0) # 关闭思考以获得更好的检测结果
)
response = client.models.generate_content(
model="gemini-2.5-flash", contents=[prompt, img], config=config
)未来趋势:检测/分割/识别能力将逐步融入原生多模态模型,实现端到端处理。
7.3 ViT 与 CLIP:视觉-语言桥梁
ViT 让 Transformer 接管了 CV,CLIP 让视觉和语言在同一个空间中相遇。
7.3.1 Vision Transformer(ViT)
ViT 将图像视为"patch 序列",直接套用 Transformer Encoder:
- 将
图像切分为 个 大小的 patch - 每个 patch 展平后线性投影为 token embedding
- 加上可学习位置编码
- 送入标准 Transformer Encoder
ViT vs CNN 的关键差异:
| CNN | ViT | |
|---|---|---|
| 感受野 | 随层数加深逐渐扩大(局部 → 全局) | 从第一层起就是全图(全局注意力) |
| 架构 | 多阶段异构设计(如 ResNet),需大量手动调参 | 每层结构相同,纯 Encoder,更易扩展 |
| Token 交互 | 局部卷积窗口内 | 每个 Token 都能看到所有其他 Token |
7.3.2 CLIP:对比语言-图像预训练
CLIP(OpenAI, 2021)用约 4 亿图文对学习视觉-语言对齐,核心是batch 内对比学习:
- Text Encoder:将文本编码为特征向量
- Visual Encoder:基于 ViT,将图像编码为特征向量
CLIP 损失函数(以 Image-to-Text 方向为例):
其中
CLIP 的使用代码:
import clip
model, preprocess = clip.load("ViT-B/16", device=device)
def get_img_feats(img):
img_in = preprocess(Image.fromarray(np.uint8(img)))[None, ...]
with torch.no_grad():
feats = model.encode_image(img_in.to(device)).float()
feats /= feats.norm(dim=-1, keepdim=True)
return np.float32(feats.cpu())
def get_text_feats(texts, batch_size=64):
tokens = clip.tokenize(texts).to(device)
with torch.no_grad():
feats = model.encode_text(tokens).float()
feats /= feats.norm(dim=-1, keepdim=True)
return np.float32(feats.cpu())
# 最近邻检索:余弦相似度
scores = text_feats @ img_feats.T7.3.3 SigLIP:从多分类到成对二分类
SigLIP(Google, 2023)改变了 CLIP 的损失函数设计,解决 Softmax 的固有局限。
CLIP 的问题:Softmax 强制概率和为 1。如果图片
SigLIP 的方案:放弃 Softmax,将每一个
展开来看:
SigLIP 允许一张图同时与多个文本高度匹配(Sigmoid 输出都可以很高),更符合真实语义。Qwen2.5-VL 和 Qwen3-VL 的视觉编码器均基于 SigLIP-2 架构。
7.4 图像生成:从 Transformer 视觉化到扩散模型
在进入 Stable Diffusion 之前,有必要梳理 AIGC(AI 生成内容)在视觉领域的技术谱系。
7.4.1 AIGC 视觉谱系
Transformer 最初被引入视觉领域时,主要用于理解(分类、检测),而非生成。生成方向的发展可以分为两条路线:
自回归(AR)路线——将图像离散化为 token 序列,然后自回归生成:
- ImageGPT(OpenAI, 2020):Pixel 级 tokenize,Decoder-only Transformer 自回归预测下一个像素。验证了 GPT 范式可以直接用于图像,但 pixel 级序列极长,效率低下。
- VQGAN(2021):先用 VQ-VAE 将图像量化为离散 codebook token(大幅缩短序列),再用 Transformer 自回归生成 token 序列,最后解码为图像。
- MaskGiT(Google, 2022):借鉴 BERT 的 Masked Language Modeling,在离散 visual token 上做"完形填空"——随机 mask 部分 token 后预测,可以并行生成(非逐 token),速度更快。
扩散(Diffusion)路线——从噪声分布逐步净化为图像分布:
- DDPM(2020):奠定了扩散模型的基础框架——前向过程逐步加噪,反向过程学习去噪。
- Stable Diffusion(2022):将扩散过程从像素空间搬到潜空间(Latent Space),大幅降低计算成本(见 7.4.2 节)。
- Flow Matching(2023+):扩散模型的数学推广,用最优传输理论构造更直的去噪路径,训练更稳定、采样更快。视频生成领域的主流已从 Stable Diffusion 演进到 Flow Matching。
两条路线的本质区别在于"过去生成的东西能否修改":
| 自回归(AR) | 扩散(Diffusion) | |
|---|---|---|
| 核心建模 | ||
| 已生成内容 | 不可修改 | 每步都可修改所有位置 |
| 序列长度 | 动态(遇到 EOS 停止) | 固定(shape 需事先确定) |
| 代表工作 | VQGAN, MaskGiT | DDPM, Flow Matching |
7.4.2 Stable Diffusion 原理
Stable Diffusion 证明了扩散模型在潜空间中可以高效生成高质量图像,成为现代图像/视频生成的技术基石。
架构概览
Stable Diffusion(SD)由三个核心组件构成:
文本输入 → CLIP Text Encoder → 文本 Embedding
↓ (Cross-Attention)
随机噪声 → UNet(在 Latent 空间去噪) → 最终 Latent → VAE Decoder → 像素图像- VAE:像素域 ↔ 潜空间(latent)的编解码器。把图片压缩到更小但"语义密集"的 latent 表示,再从 latent 还原为像素图。预训练好的 VAE 在整个 SD 训练过程中保持冻结。
- UNet:在 latent 空间做去噪/反扩散的核心网络。每个去噪步根据文本条件预测当前噪声方向,逐步将随机噪声变成"干净的" latent。
- Cross-Attention:文本 Embedding 作为 Key/Value,latent 特征作为 Query。这是文本条件注入扩散过程的关键机制。
应用场景:text2img(文本生成图像)、img2img(图像编辑/inpainting)。
图像生成领域在两个方向并行发展:AR 方向将图像量化为离散 token 序列再自回归生成;Diffusion 方向从噪声分布逐步净化为图像分布。视频生成领域的主流已从 Stable Diffusion 演进到 Flow Matching。
7.5 VLM:Qwen-VL、Qwen3-VL(M-RoPE)
Qwen VLM 系列展示了"组合式多模态"架构如何通过精巧设计达到"原生级"融合体验。M-RoPE 的演进尤其值得细读。
7.5.1 Qwen-VL 基础架构
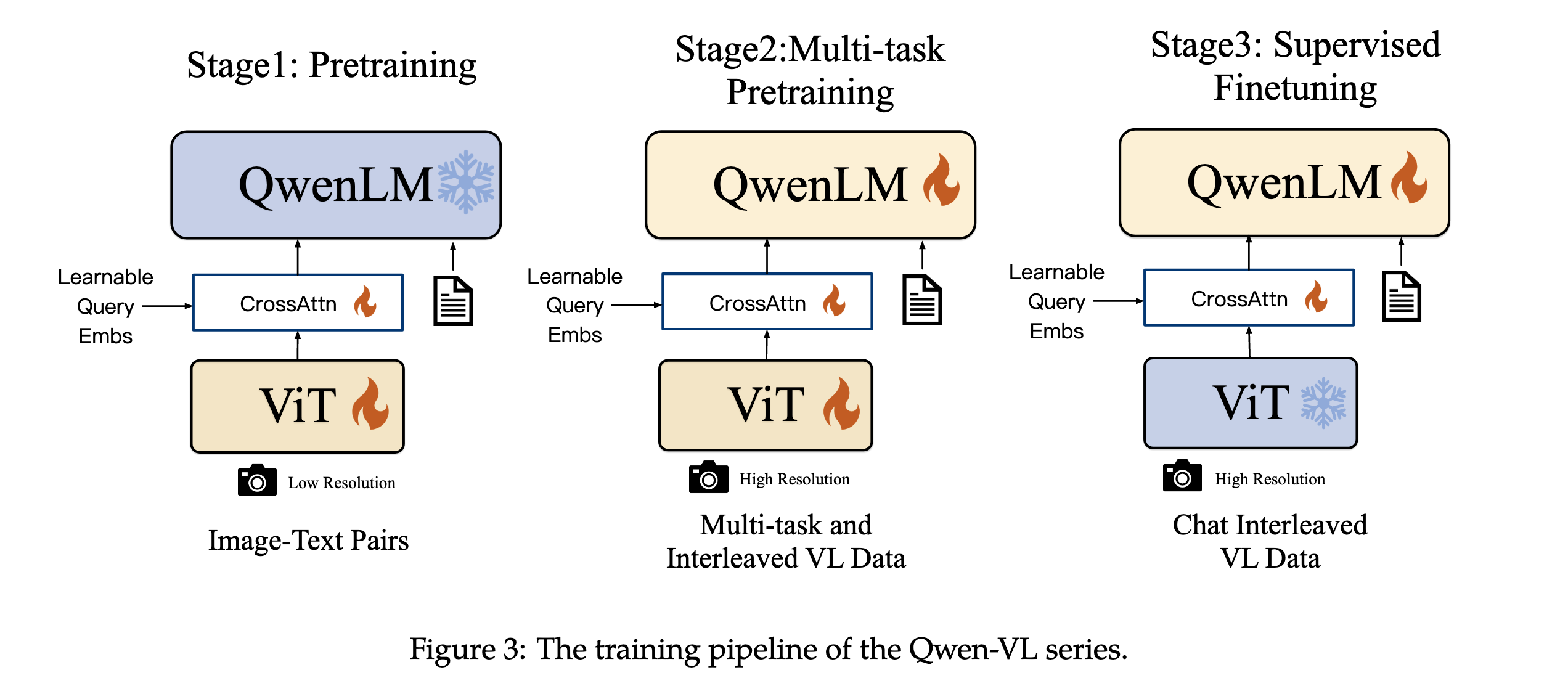
Qwen-VL 采用经典的三模块设计:
- Visual Encoder:基于 OpenCLIP 的 ViT-bigG
- Position-aware Vision-Language Adapter:单层 Cross-Attention 模块
- 一组可训练的向量(Embeddings)作为 Query
- 视觉编码器输出作为 Key/Value
- 2D 绝对位置编码
- LLM:Qwen 基础语言模型
输入/输出使用特殊标记:<img></img>(图像)、<box></box>(边界框)。

7.5.2 Qwen2.5-VL:原生动态分辨率
Qwen2.5-VL 引入了几项关键改进:
原生动态分辨率(Naive Dynamic Resolution):
输入图像的高宽被调整为 28 的倍数,然后以步长 14 切分为 patch。以
- 宽方向
个 patch,高方向 个 patch - ViT 生成
个原始视觉 token - Vision-Language Merger 将
的相邻 patch 特征合并为 1 个 token(4x 压缩) - 最终
个 token 送入 LLM - 合并过程:
维 → 两层 MLP → LLM 隐层维度
动态 FPS 采样:
视频以动态帧率(1/8 fps 到 8 fps)采样训练,M-RoPE 中的时间维度与视频的绝对时间对齐。例如 8 秒视频在 0.5 fps 下采 4 帧、2 fps 下采 16 帧,配合 Conv3D(2×14×14) 处理后的时间 ID 分别为 (0, 15) 和 (0, 2, 4, 6, 9, 11, 13, 15)。这让模型感知真实时间间隔。
Window + Full Attention 混合:
大部分 ViT 层(28 层)使用 Window Attention(窗口大小
7.5.3 M-RoPE 的演进
从 1D-RoPE 到 2D-RoPE
M-RoPE 建立在 1D RoPE 的数学基础上(核心性质
标准 RoPE 为一维序列位置
展开注意力得分:
利用 RoPE 的关键性质
Qwen2.5-VL 的 M-RoPE(Chunking 策略)

视频 token 的位置从标量
问题:RoPE 中低维度索引对应高频分量(捕捉局部/细节),高维度索引对应低频分量(捕捉全局/长距离)。Chunking 策略将时间维度
Qwen3-VL 的 Interleaved M-RoPE(交错策略)
Qwen3-VL 提出交错排列方案:每 3 个维度对轮流分配给
每组 3 个维度对共享同一个基准频率:
旋转矩阵为块对角矩阵,每个
这种 Round-robin 分布确保
| 维度对索引 | 位置 | 频率特性 |
|---|---|---|
| 0, 1, 2 | 高频(捕捉细节) | |
| 3, 4, 5 | 中频 | |
| ... | ... | ... |
| Max-2, Max-1, Max | 低频(捕捉全局) |
对比总结:
| 方案 | 维度排列 | 频谱情况 | 长视频效果 |
|---|---|---|---|
| Chunking(Qwen2.5-VL) | `[t...t | h...h | w...w]` |
| Interleaved(Qwen3-VL) | [t,h,w, t,h,w, ...] | 三轴均匀覆盖全频段 | 更好 |
7.5.4 Qwen3-VL 视觉 Token 计算
Qwen3-VL 使用 Patch Size 16 + 2×2 池化,有效步长 32 像素/token:
其中 <|vision_start|> 和 <|vision_end|>)。
- 第 1 层(ViT):把图切成 16×16 像素的小块,每块生成一个特征向量
- 第 2 层(Adapter):将
的特征向量网格合并为 1 个更浓缩的向量 - 结果:LLM 看到的 1 个 token 包含了原图中
像素的信息
7.5.5 DeepStack:突破"最终层"局限
传统做法只将视觉编码器最终层的输出送给 LLM。Qwen3-VL 引入 DeepStack 机制——抽取 ViT 的中间层特征,以**残差连接(直接相加)**方式注入 LLM 的不同层:
- 视觉浅层特征(纹理、边缘)注入 LLM 低层
- 视觉深层特征(语义、抽象)注入 LLM 高层
- 不改变序列长度(因为是加法而非拼接)
7.5.6 Qwen3-VL 多阶段训练
Qwen3-VL 采用"先部分冻结,后全参数解冻"的策略,分四个阶段逐步扩展能力:
| Stage | 训练目标 | 可训练组件 | 冻结组件 | 数据量 | 上下文长度 | 主要数据与任务 |
|---|---|---|---|---|---|---|
| S0:视觉-语言对齐 | 打通模态连接 | 仅 Merger | ViT + LLM | ~67B tokens | 8K | 高质量 Image-Caption 对、OCR 数据;任务为图像描述和文字识别 |
| S1:多模态预训练 | 全面联合训练 | 全参数解冻 | 无 | ~1T tokens | 8K | 图文交错文档、VQA、视觉定位(Box/Point)、STEM 推理、视频数据、纯文本语料 |
| S2:长上下文预训练 | 扩展上下文 | 全参数 | 无 | ~1T tokens | 32K | 长文本理解、时间感知视频数据、多步 Agent 指令数据 |
| S3:超长上下文适配 | 极长上下文 | 全参数 | 无 | ~100B tokens | 256K | 2 小时以上长视频、书籍级长文档、Needle-in-a-Haystack 检索 |
阶段设计逻辑:S0 仅训练 Merger("胶水层"),目的是在不破坏预训练好的视觉和语言特征的前提下,快速建立模态间的初步连接。S1 全参数解冻后进行大规模联合训练,让视觉编码器适应复杂任务,同时让 LLM 深度理解视觉信息。S2/S3 在全参数训练的基础上逐步扩展上下文窗口(8K → 32K → 256K),确保长距离依赖的学习效果。
Qwen3-VL 团队明确提出了**"分而治之"**的理念:先分别开发最强的视觉感知能力(SigLIP-2)和语言推理能力(Qwen3),再通过协同方式集成——与"从零联合训练"的原生路径在理念上有本质区别。
7.6 原生多模态模型
"原生"与"组合"的区别不在于最终效果,而在于模态融合发生的时机。
7.6.1 什么是原生多模态
模态鸿沟:文本是一维的(sequence),图像是二维的(height × width),视频是三维(temporal + spatial)甚至四维(加上 audio)。
原生多模态的三个核心特征:
- 单一模型架构:不区分明显的"视觉编码器"和"语言解码器",两者融合极其紧密
- 从头联合训练:预训练初期就同时接触多模态数据,而不是先训练强 LLM 再"看图"
- 任意输入输出(Any-to-Any):输入视频可以直接输出语音,中间无须文本桥接
组合式多模态(如 Qwen-VL):先独立训练强大的视觉编码器和语言模型,再通过对齐层连接。
7.6.2 Gemini:原生多模态的代表
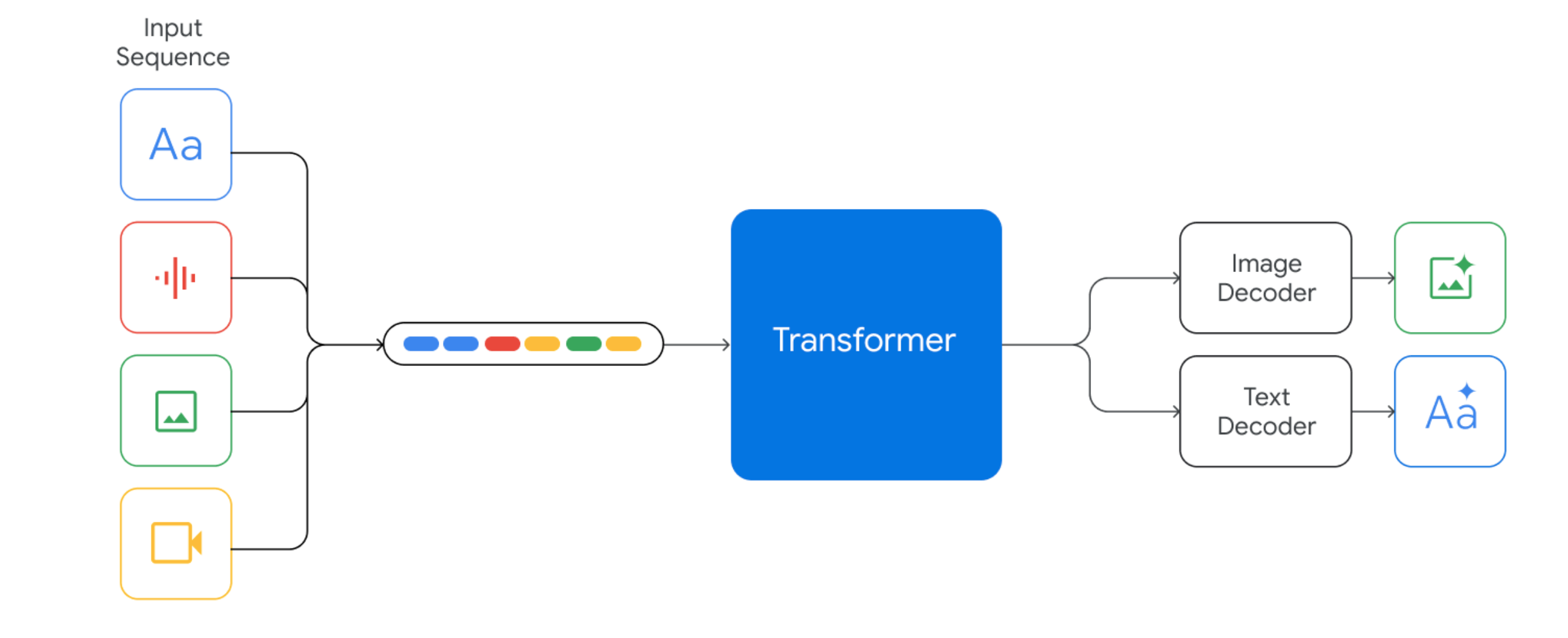
Gemini 从预训练第一天就随机初始化,同时在文本、图像、音频、视频数据上联合训练:
"Gemini models support interleaved sequences of text, image, audio, and video as inputs. They can output responses with interleaved image and text."
联合训练带来的核心优势:
- 统一的内部表示空间:不同模态的概念在同一个高维空间中被编码,而非"在已有的文本世界观里为图像找个位置"
- 深层跨模态推理:因为底层表示统一,可以进行更复杂的跨模态推理
训练流程:随机初始化 → 大规模多模态联合预训练 → SFT → 奖励模型训练 → RLHF。
7.6.3 Flamingo 与 PaLI:组合式方案的两条路线
Flamingo(DeepMind, 2022)——"冻结 + 插入"策略:
- Perceiver Resampler(核心创新):将数量不定的视觉特征"重采样"为固定数量(64 个)的视觉 Token,解决不同分辨率/长视频导致的输入过长问题
- Gated Cross-Attention:在冻结 LLM 层间插入可训练的交叉注意力层
- 冻结策略:视觉编码器(NFNet)和 LLM(Chinchilla)权重完全冻结,只训练 Resampler 和交叉注意力层
- Interleaved Data:使用图文交错的网页数据(M3W 数据集),赋予 Few-shot 学习能力
PaLI(Google, 2022)——"直接拼接 + 联合微调"策略:
- 使用巨型 ViT(ViT-e/G)直接输出 Visual Tokens,拼接到 Encoder 前端
- 采用 Encoder-Decoder(mT5)架构
- 不冻结视觉编码器,进行联合微调
- 多语言支持(100+ 语言),任务混合训练(Span Corruption + Captioning + VQA + OCR)
Gemini 的视觉编码灵感正是来自 Flamingo、CoCa 和 PaLI 这些基础工作。
7.6.4 视觉 Token 与文本 Token 的本质差异
这是理解多模态架构时容易忽略的关键点:
| 文本 Token | 视觉 Token | |
|---|---|---|
| 来源 | 有限词表的离散 ID(查表嵌入) | 连续向量(无码本索引),由编码器/投影直接生成 |
| 生成方式 | 可 decode(自回归生成) | 通常只作为输入(project + 对齐),不直接 decode |
| 信息密度 | 相对稀疏 | 一个视觉 embedding >> 一个文本 token embedding |
7.6.5 DeepSeek-OCR:高精度 OCR 的视觉编码设计
DeepSeek-OCR 专为密集文本场景设计,采用 SAM → Conv Compressor → CLIP 串联架构:
- SAM 编码器:将 1024×1024 图像切分为细粒度 patch,生成 4096 个局部 token
- 卷积压缩器:下采样 16x,压缩为 256 个高密度 token
- CLIP 编码器:对浓缩 token 进行全局语义理解
关键发现:当文本 token 数量不超过视觉 token 数量的 10 倍(压缩比 < 10×)时,OCR 解码精度可达 97%。
两阶段训练流程
DeepSeek-OCR 的训练分为两个阶段:
- 阶段一:独立训练 DeepEncoder。以 SAM 和 CLIP 的预训练权重为起点,训练卷积压缩器和编码器之间的连接,使视觉编码管线能够生成高质量的浓缩 token 表示。此阶段不训练 LLM 部分。
- 阶段二:端到端训练完整的 DeepSeek-OCR 模型。冻结或微调视觉编码器,将其输出接入 LLM,进行端到端的联合训练,让模型学会从视觉 token 中解码出结构化的文本内容。
Prompt 格式与结构化标记语法
DeepSeek-OCR 使用特定的 prompt 模板控制任务类型:
<image>\n<|grounding|>Convert the document to markdown.— 文档转 Markdown(启用检测定位)<image>\nParse the figure.— 解析图表<image>\nDescribe this image in detail.— 图像描述
输出采用结构化标记语法,每个子区域都带有检测标签 <|det|><|/det|>,可精准定位并渲染原文档中的各类元素:
| 标记 | 含义 |
|---|---|
| `< | ref |
| `< | ref |
| `< | ref |
| `< | ref |
| `< | det |
<--- Page Split ---> | 多页文档(如 PDF)的分页标记 |
这套标记语法使 DeepSeek-OCR 不仅能 OCR 出文本内容,还能保留原文档的空间布局结构——每个被识别的元素都附带位置信息,支持精准的文档渲染还原。
7.7 可解释性:Embedding 表示分析
打开 LLM 的"盖子",观察每一层 Embedding 正在编码什么信息。
7.7.1 输入 Embedding 层的语义
LLM 的 Embedding Table 存储了词表中每个 token 的初始表示向量:
input_embedding = model.state_dict()["model.embed_tokens.weight"].cpu().numpy()
# shape: (151936, 2048) — 词表大小 × 隐层维度用余弦相似度检索"王"的最近邻:
from sklearn.metrics.pairwise import cosine_similarity
token_id = tokenizer.encode("王")[0] # 99445
sims = cosine_similarity([input_embedding[token_id]], input_embedding)[0]
nearest = sims.argsort()[::-1][1:21]
for idx in nearest:
print(f"{tokenizer.decode(idx)} (score: {sims[idx]:.4f})")结果(Qwen2.5-3B-Instruct):
King (0.5865), king (0.5286), Vương (0.4260), kings (0.4254),
KING (0.4165), Wang (0.3742), 国王 (0.3698), 왕 (0.3359),
王国 (0.3355), 王子 (0.3081) ...即使在输入层(还没经过任何 Transformer 层),Embedding 已经包含了跨语言的语义关联——"王"与 King、Wang、국왕 等多语言对应词距离很近。
7.7.2 上下文化表示(Contextualized Representation)
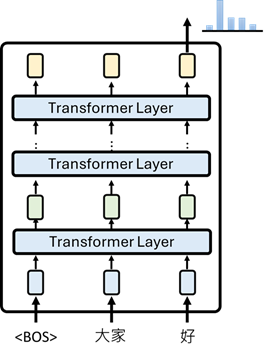
每经过一个 Transformer 层,token 的表示就融合更多上下文信息:
outputs = model(inputs, output_hidden_states=True)
hidden_states = outputs.hidden_states
# hidden_states[0]: 输入 Embedding(与上下文无关的查表结果)
# hidden_states[l]: 第 l 层 Transformer Block 的输出(上下文化表示)多义词实验:
- 句子 1:
"I ate an apple for breakfast."(apple = 水果) - 句子 2:
"The company that brought us the iPad and AirPods is apple."(apple = 公司)
在底层(Layer 0),两句中的 "apple" 余弦相似度很高(初始 Embedding 相同,token ID 都是 23268)。随着层数增加,相似度持续下降——模型根据上下文为同一 token 赋予了越来越不同的语义表示。用平均相似度归一化后,这种分化趋势更加明显。
7.7.3 Logit Lens:每层在"想"什么
核心思想:不等到最后一层,在每层的隐状态上直接施加 LM Head(Unembedding),看模型"此刻最想预测哪个 token"。
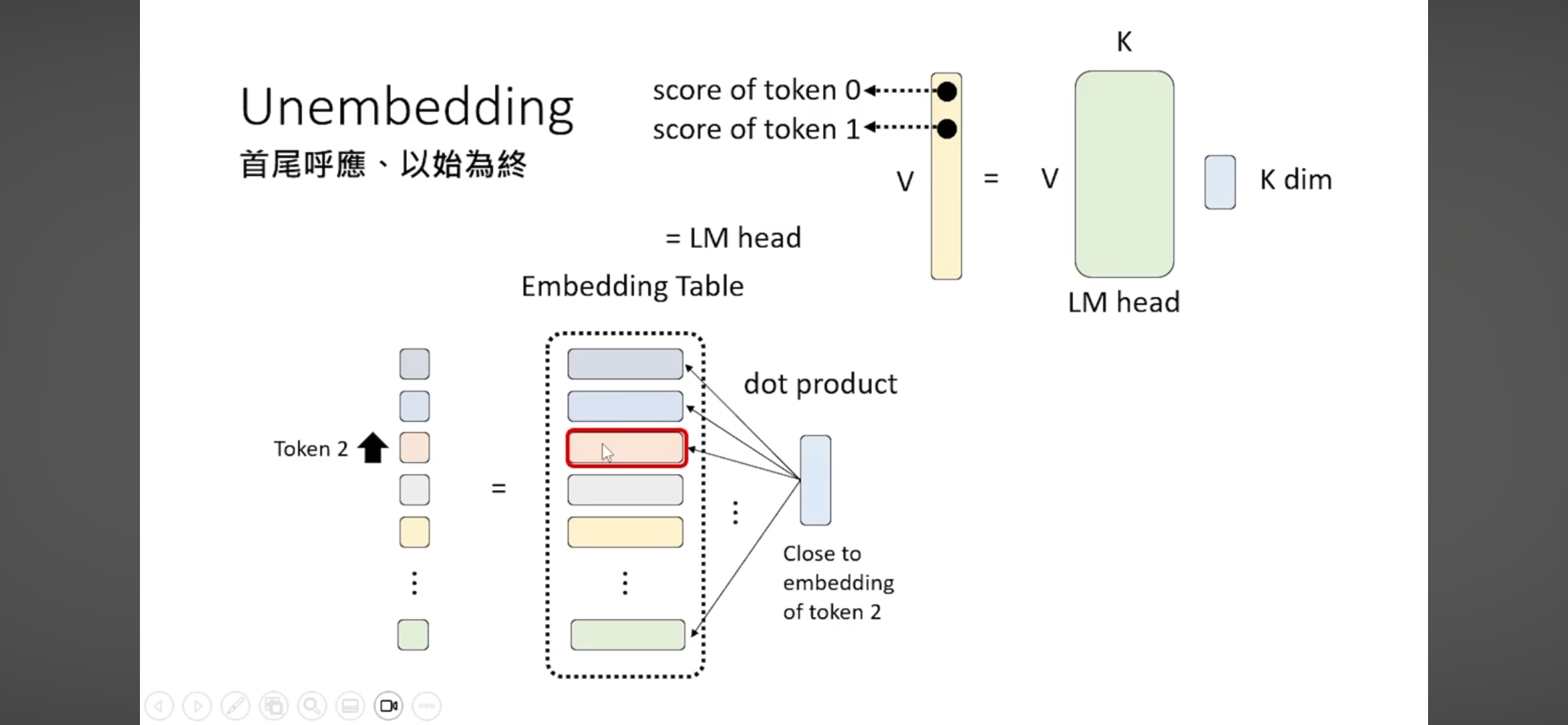
text = "天气"
input_ids = tokenizer.encode(text, return_tensors="pt").to(device)
outputs = model(input_ids, output_hidden_states=True)
for l in range(len(outputs.hidden_states)):
logits = model.lm_head(outputs.hidden_states[l])
next_token = torch.argmax(logits[0, -1])
print(f"Layer {l:2d} → {tokenizer.decode(next_token)}")Qwen2.5-3B-Instruct 上的实验结果(输入"天气",预测下一个词):
| 层数 | 预测 | 含义 |
|---|---|---|
| Layer 0-1 | 天气 | 直接"复制"输入,还没开始推理 |
| Layer 2-30 | 乱码 | 中间层表示不直接对应词表中的任何 token |
| Layer 34-35 | 空格 | 已开始形成方向但还没收敛 |
| Layer 36(最终) | 预报 | 正确答案浮现 |
Logit Lens 揭示了 LLM 的推理是层层渐进的——答案在最后几层才真正"浮现"。
LM Head 的本质:如果模型使用 tie_word_embeddings(如 Qwen2.5-3B),LM Head 就是 Embedding Table 的转置——预测下一个 token 本质上就是计算"当前隐状态"与"词表中每个 token Embedding"的内积(相似度)。
7.7.4 Attention 权重分析
model.config._attn_implementation = "eager" # 关闭 SDPA,才能拿到 attention 权重
outputs = model(inputs, output_attentions=True)
attentions = outputs.attentions
# attentions[layer]: shape [batch, num_heads, seq_len, seq_len]以 "The apple is green. What color is the apple?" 为输入,可视化某一层某一 head 的 11×11 attention 矩阵,观察到三个关键规律:
右上角全为 0:Decoder-only 模型的因果 Mask——未来位置的 logit 在 Softmax 前被设为
,Softmax 后变为 0。因此 attention 矩阵是严格下三角的。(如果是 Encoder 或 Cross-Attention,不会出现三角形。) 第一列"竖条"高亮:许多 head 将句首 token 作为全局锚点。即使没有显式 BOS,某些 head 会学到"从句子开头收集全局语境"的策略。
不同 Head 捕捉不同模式:在一个 36 层 × 16 head 的模型中,有的 head 关注语法依赖(主谓关系),有的关注语义共指(两个 "apple" 之间的高注意力权重),有的关注局部位置。
7.8 Steering Vectors 与 Persona Vectors
如果 Logit Lens 是"观察"模型内部,Steering Vectors 则是"干预"——在激活空间中找到概念方向,推理时加减偏移量来控制行为。
7.8.1 残差流视角
LLM 的内部计算可以用**残差流(Residual Stream)**来理解:每个 Transformer 层在前一层输出上叠加增量,整个模型是增量的累加:
Logit Lens 就是在每个
7.8.2 Activation Steering
Activation Steering(又名 Representation Engineering、Activation Engineering)的核心思想:
找到模型激活空间中某个概念(如"拒绝回答"、"诚实"、"有害内容")的方向向量,在推理时在该方向上加/减偏移量,从而控制模型行为。
典型方向发现流程:
- 准备一组"正例"输入(如包含有害内容的 prompt)和一组"负例"输入
- 在某一中间层提取两组的平均激活值
- 差值向量 = Steering Vector
# 在前向传播中注入 steering vector
def hook(module, input, output):
output[0][:, :, :] += alpha * steering_vector
return output
model.layers[target_layer].register_forward_hook(hook)加上 steering vector(
7.8.3 Persona Vectors
Persona Vectors 是 Steering 概念在"性格特质"维度的延伸。研究发现,以下行为特征在模型激活空间中是线性可分的方向:
- 邪恶方向(evil direction):增大 → 模型更倾向于有害回复
- 谄媚方向(sycophancy direction):增大 → 更倾向于顺从用户而非给出诚实答案
- 幻觉方向(hallucination direction):增大 → 更可能编造信息
Persona Vectors 在安全研究中有重要价值:通过理解这些方向的存在与分布,可以开发更鲁棒的对齐检测和干预机制。
7.9 对齐的可解释性视角
可解释性不是学术装饰,而是对齐的手术刀——当我们能定位"模型在哪一层决定拒绝",就能更精确地修复对齐问题。
7.9.1 Values in the Wild
Anthropic 发布的"Values in the Wild"(2025)通过大规模分析真实用户对话,研究模型在实际部署中表现出的价值观层级。
3H 价值观框架:
- Helpful(有用):帮助用户完成合理任务
- Honest(诚实):不编造信息,不进行错误归因
- Harmless(无害):避免产生对用户或社会有害的内容
当三个价值存在冲突时,模型的实际决策远比规则系统复杂——"有用性"有时会与"无害性"直接碰撞,模型需要动态权衡。
7.9.2 可解释性对对齐的意义
机制可解释性(Mechanistic Interpretability)研究的核心问题:
"模型内部表示了什么?它是如何做决定的?"
当我们能通过 Steering Vectors 直接操控模型的"谄媚程度"或"拒绝倾向"时,这意味着三件事:
- 线性表示假说成立:这些行为特征在模型内部确实是线性可分的方向
- 外科手术式干预可行:通过对激活空间的精确干预,可以在不重新训练模型的情况下修改其行为
- 运行时对齐新思路:用可解释性工具诊断和修复对齐问题——不再依赖"重新训练-评估-部署"的沉重循环,而是在推理时实时调整
本章小结
| 主题 | 核心内容 | 关键概念 |
|---|---|---|
| CV 基础 | CNN 特征提取、OpenCV 图像处理 | 卷积/池化、形态学、连通性分析、透视变换 |
| 目标检测与分割 | DETR 端到端检测、SAM 1/2/3、Grounded-SAM | Hungarian 匹配、PVS → PCS、VLM + SAM Agent |
| ViT + CLIP | Patch 序列化、对比学习、SigLIP | 全局感受野、Softmax vs Sigmoid 损失 |
| 图像生成 | AIGC 视觉谱系、Stable Diffusion | AR vs Diffusion、ImageGPT/VQGAN/MaskGiT、潜空间扩散、Flow Matching |
| VLM | Qwen-VL 系列、M-RoPE 演进 | 动态分辨率、Interleaved M-RoPE、DeepStack |
| 原生多模态 | Gemini vs Flamingo vs PaLI、DeepSeek-OCR | 联合预训练、Perceiver Resampler、两阶段训练、结构化标记 |
| Embedding 分析 | 多义词分化、Logit Lens、Attention 可视化 | 残差流、上下文化表示、因果 Mask |
| Steering | Activation Steering、Persona Vectors | 方向发现、运行时行为控制 |
| 对齐可解释性 | 3H 价值观、线性表示假说 | 外科手术式干预、运行时对齐 |
本章揭示了多模态 AI 的两条发展轨迹:
"外挂视觉"到"原生融合":从 Flamingo 的冻结 Adapter 到 Qwen3-VL 的 DeepStack 再到 Gemini 的从头联合预训练,模态鸿沟在逐渐消融。但"组合式"与"原生式"并非孰优孰劣,而是不同的工程权衡——Qwen3-VL 的"分而治之"策略证明了组合式方案同样可以达到极高的融合水平。
"黑盒推理"到"可解释干预":Logit Lens 和 Steering Vectors 让我们不再是模型行为的旁观者。当我们能精确定位"谄媚"方向在激活空间中的位置,就能在推理时实时修正——这为"运行时对齐"打开了全新的可能性。
延伸阅读
- ViT 论文:An Image is Worth 16x16 Words, Dosovitskiy et al., 2020
- CLIP 论文:Learning Transferable Visual Models From Natural Language Supervision, Radford et al., 2021
- SigLIP 论文:Sigmoid Loss for Language Image Pre-Training, Zhai et al., 2023
- DETR 论文:End-to-End Object Detection with Transformers, Carion et al., 2020
- SAM 论文:Segment Anything, Kirillov et al., Meta AI, 2023
- SAM 2 论文:SAM 2: Segment Anything in Images and Videos, Ravi et al., 2024
- Stable Diffusion 论文:High-Resolution Image Synthesis with Latent Diffusion Models, Rombach et al., 2022
- Qwen-VL 论文:Qwen-VL: A Versatile Vision-Language Model, Bai et al., 2023
- Qwen2.5-VL 技术报告:Qwen Team, 2025
- Qwen3-VL 技术报告:Qwen Team, 2025
- Gemini Technical Report:Google DeepMind, 2023
- Flamingo 论文:Flamingo: a Visual Language Model for Few-Shot Learning, Alayrac et al., 2022
- DeepSeek-OCR:DeepSeek-OCR, 2025
- Logit Lens:Nostalgebraist, "Interpreting GPT: the logit lens", 2020
- Representation Engineering:Zou et al., 2023
- Anthropic Values in the Wild:Anthropic, 2025