第 10 章:奖励模型与偏好学习
本章概览
奖励建模(Reward Modeling)与偏好学习(Preference Learning)是连接"人类意图"与"模型行为"的关键桥梁。本章从概率统计建模的基石——Bradley-Terry 模型出发,逐层推导奖励模型的训练目标,揭示 Loss 与梯度背后的学习动力学;接着通过严格的数学推导,展示 DPO 如何消去显式奖励模型、将强化学习转化为监督学习问题;随后讨论 DPO 在工程实践中的局限性与应用模式、Reward Shaping 的理论保证与工程实例、RaR 如何将奖励建模推广到非可验证领域、奖励标准化的常见误区与正确做法;最后覆盖偏好数据的构建方法和前沿研究话题。
10.1 Bradley-Terry 模型与奖励建模
从 Bradley-Terry 模型到 MLE 损失函数,奖励模型训练的三层建模框架与梯度动力学。
10.1.1 三层建模框架
奖励模型的训练可以理解为三层嵌套结构——从底层的工具到顶层的指导原则:
三层各自承担不同职责:
| 层级 | 名称 | 职责 |
|---|---|---|
| 底层(工具层) | 深度学习 | 参数化函数 |
| 中层(逻辑层) | Bradley-Terry 模型 | 赋予"数字差值"可解释的概率含义。它定义了两个数字的差值代表什么:偏好概率 |
| 顶层(指导层) | MLE(最大似然估计) | 定义 Loss Function,驱动参数学习。通过梯度的计算进一步求解,理解 Learning Dynamics |
核心洞察:概率统计建模(BT)定义 Loss 的语义,深度学习提供万能逼近器(Universal Approximator)来实现。理解 Loss 看"高度",理解 Learning Dynamics 看"坡度"(梯度)。
10.1.2 Bradley-Terry 模型
BT 模型的原始设定来自竞技体育的排名问题。如果选手 A 的隐藏实力(奖励分数)为
映射到语言模型场景:给定输入 prompt
直觉:Reward Model 本质上就是一个用神经网络去拟合的 Bradley-Terry 模型。或者说,它是 BT 模型的参数化载体(Parameterized Instance)。
10.1.3 从概率到损失函数
为了训练神经网络(找到最佳参数
第一步:写出似然函数
第二步:取对数
第三步:取负号,得到可最小化的 Loss
10.1.4 Loss 与梯度的深度洞察
设
| Loss 行为 | 含义 | |
|---|---|---|
| 模型明显分错,线性地狠狠惩罚 | ||
| 无法区分好坏,50/50 | ||
| 模型已分清,但曲线越来越平缓(梯度消失) |
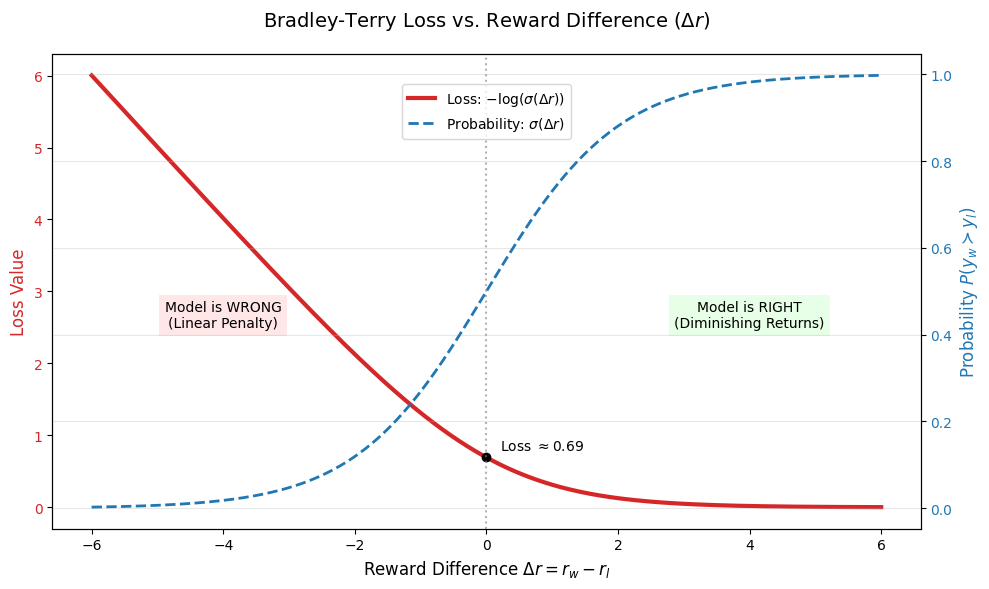
关键观察:一旦
梯度分析:
权重项
- 错题(模型分错的,
):权重 ,大幅修正 - 难题(分不开的,
):权重 ,适度学习 - 送分题(已经分清的,
):权重 ,几乎不更新
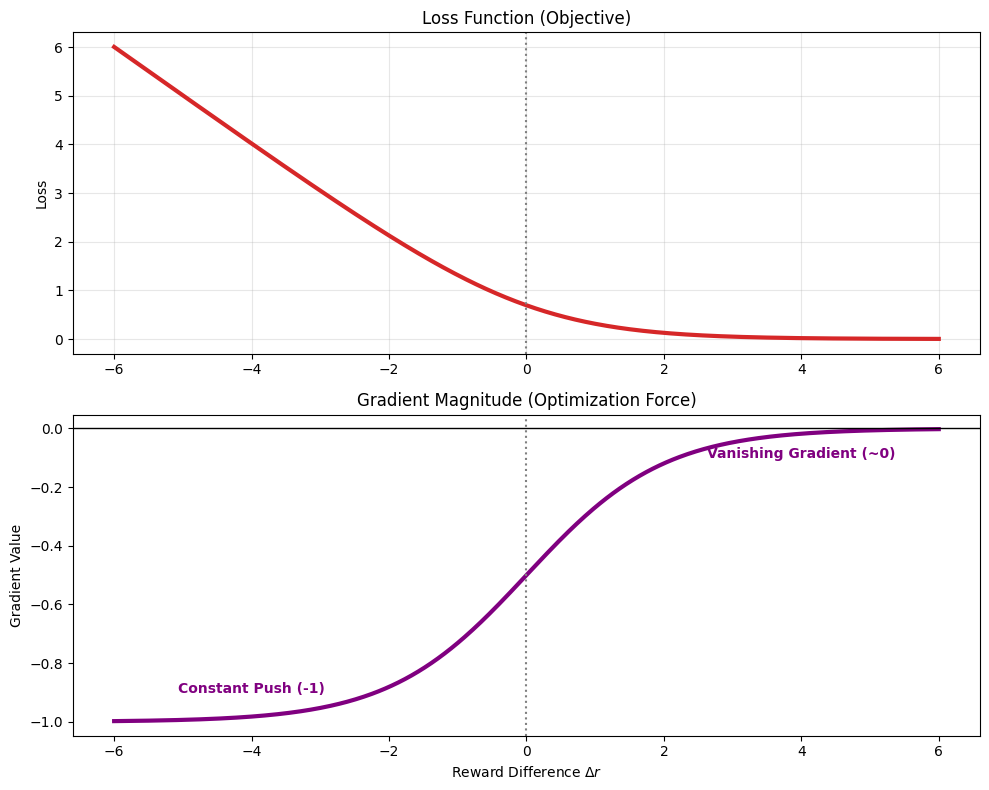
结论:Reward Model 训练是一个优雅的"自适应 Hard Negative Mining"过程——梯度(Learning Signal)自动将学习精力集中在最难区分的样本上,已经分清楚的"送分题"几乎不消耗计算资源。
10.1.5 非传递性偏好(Intransitive Preferences)
当偏好数据出现循环
为什么"强行分出胜负"不可行? 假设模型尝试设
在 Log Loss 中,"非常确信地预测错"带来的惩罚趋向无穷。为了满足前两个关系而把第三个概率压到接近 0,总 Loss 反而极大。
"承认无知"的策略:模型选择
实验验证(均匀循环偏好):
# 初始分数: A=1.0, B=2.0, C=3.0
# 数据: A>B, B>C, C>A 各 1 次(完美循环)
# 训练 500 步后:
# 最终分数: A=2.0000, B=2.0000, C=2.0000
# P(A > B) = 0.5000三者从不同初始值出发,最终完全收敛到相同分数——BT 模型的"投降"。
不均匀循环偏好下的"软多数投票"(Soft Majority Voting):
当偏好出现频次不均(
# 训练 500 步后:
# 最终分数: A=3.21, B=1.69, C=1.11
# P(A > B) = 0.82启示:MLE 在循环偏好中的行为本质上是一种带概率权重的多数投票。语言模型中常见类似循环:长文本 > 短文本 > 幽默文本 > 长文本。标准 BT 的 RM 会"磨平"这些差异,失去对特定风格的精细捕捉——这是单一标量奖励的固有局限。
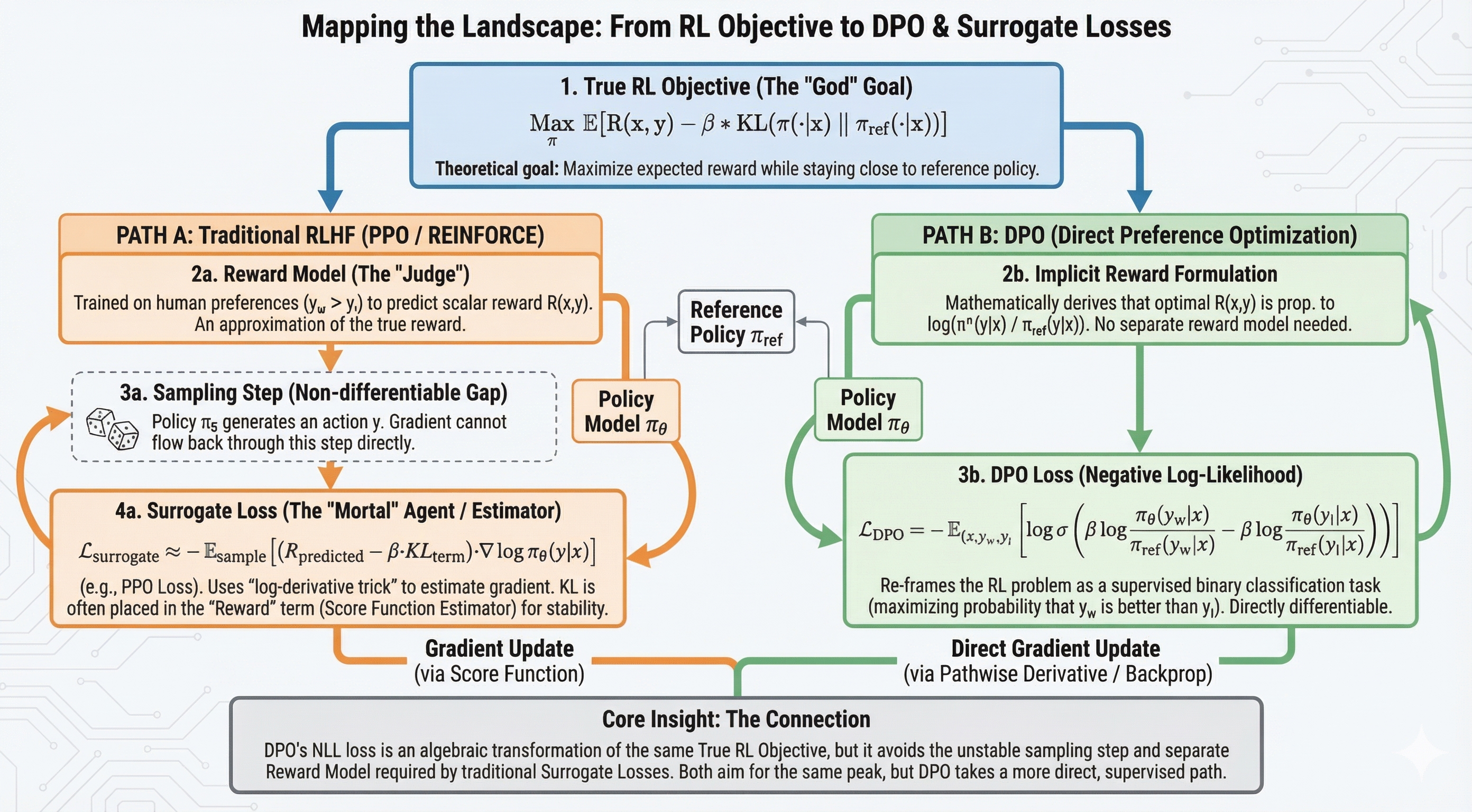
10.2 DPO:从 RLHF 到直接偏好优化
DPO 如何通过数学等价变换消去显式奖励模型,将 RLHF 转化为监督学习问题。
10.2.1 RLHF 的优化目标
标准 RLHF 的核心是 KL-constrained Reward Maximization:
KL 约束有双重作用:
- 分布安全:防止模型偏离奖励模型能准确评估的数据分布。RM 是在 SFT 模型的输出上训练的,一旦生成模型跑偏产生 Out-of-Distribution 文本,RM 打出的分数就不可信了(可能乱给高分)
- 多样性保持:避免 Mode Collapse——收敛到单一的高奖励答案
背景:DPO 的第一作者 Rafailov 是 Sergey Levine 的学生,Levine 也是 Maximum Entropy RL 的推手。KL 正则与 MaxEnt RL 的熵正则在精神上一脉相承。
10.2.2 最优策略的解析解
上述 KL 约束优化目标存在解析解(Closed-form Solution):
其中
直觉解读:最优策略 = 参考策略按奖励做指数加权后重新归一化。奖励高的地方概率放大,奖励低的地方概率压缩。
10.2.3 隐式奖励——从
上一节的解析解告诉我们,最优策略
DPO 的关键洞察在于:既然最优策略与奖励一一对应,我们可以用当前正在训练的策略
当
10.2.4 奖励差的消去——
现在计算两个回复的奖励差:
数学的"magic 时刻":归一化常数
因做差被完全抵消!显式的奖励函数 也消失了!剩下的只有策略模型与参考模型的 Log Ratio。
10.2.5 DPO Loss 的推导
将上述奖励差代入 Bradley-Terry 偏好概率
通过 MLE 最大化偏好概率,取负号得到 DPO Loss:
本质:DPO 把 RLHF 降维成了一个二分类监督学习问题。它就是逻辑回归(Logistic Regression)或二元交叉熵(Binary Cross Entropy):
- 定义"分差":
- 预测概率:
- 真实标签:数据集中
确实赢了(标签为 1) - 目标:
10.2.6 RLHF 与 DPO 的对比
| 对比维度 | RLHF(PPO 路线) | DPO |
|---|---|---|
| 训练流程 | 先训 RM,再 RL 优化策略 | 端到端直接训练 |
| 是否需要独立 RM | 是 | 否(隐式包含在 Log Ratio 中) |
| 是否需要在线采样 | 是(PPO 阶段需要 rollout) | 否(用静态偏好数据集) |
| 工程复杂度 | 高(三阶段流水线) | 低(一阶段训练) |
| 风险 | RM 过拟合、奖励 Hacking | 也可能 Reward Hacking(Log Ratio 漏洞) |
10.3 DPO 补充:数学细节与变体
DPO 的隐式奖励推导、IPO 变体,以及 DPO 在工程实践中的局限性分析。
10.3.1 DPO 在训练流程中的位置
DPO 通常置于 SFT(监督微调)之后,可选地在 RLVR/PPO 之前:
Pretraining → SFT → DPO → RLVR/PPO(可选)其核心作用:
- 决策细化(Refinement):SFT 阶段建立基本能力,DPO 进一步校准偏好方向
- 目标对齐(Alignment):使模型决策与任务目标更加一致
- 概率调整:提高生成"优选轨迹"(Preferred Trajectory)的概率,降低"非优选轨迹"的概率,巩固正确的推理模式
代表工作:MiroThinker(arXiv:2601.04888)将 DPO 用于 Research Agent 的决策细化——SFT 学基本行为,DPO 比较成功/失败的 Agent 轨迹来微调决策策略。
10.3.2 DPO 的三大局限性
局限一:评估能力
DPO 的训练过程仅教会模型如何"打分"——判断哪个回复更好。但这并不直接训练"生成能力"。
就像研读棋谱能学会评估招法的好坏,但不能保证在实际对弈中走出好棋。如果"学会评估就能生成好内容"的假设不成立,DPO 的训练就失去了意义。这一假设的有效性同样影响 SPIN 和 Self-Reward 等方法的理论根基。
局限二:Loss Margin 优先于生成质量
DPO 的优化目标完全依赖于奖励模型的评分机制,只关心好坏回复之间的分差是否增大,不关心生成文本是否流畅或具有吸引力:
- 好回复和坏回复的对数概率可能同时下降,只是好回复下降得少一些
- 梯度信号集中在"拉开差距",而非"生成高质量内容"
- 训练中常出现一个尴尬现象:双方 Loss 同时增加,需要额外的超参调整或约束来稳定
局限三:Reward Hacking 风险
DPO 的 Loss 只要
10.3.3 Reward Model 的准确性边界
DPO 的推导隐含一个关键假设:奖励模型(无论是显式的还是隐式的)在当前策略分布下是准确的。这正是 KL 约束的物理意义所在:
"The added constraint prevents the model from deviating too far from the distribution on which the reward model is accurate, as well as maintaining the generation diversity and preventing mode-collapse to single high-reward answers." —— DPO 论文
准确区(Trust Region):RM 通常在 SFT 模型的输出上训练。当语言模型生成的句子在语法、逻辑、长度和风格上与 SFT 输出相似时,RM 处于"舒适区",打分准确。
危险区(OOD):当模型为了"刷分"而过度优化,生成了偏离人类自然语言习惯、或利用了 RM 神经网络漏洞的文本时,RM 就会变得极不准确——可能对低质量文本乱给高分。
Goodhart's Law:When a measure becomes a target, it ceases to be a good measure. 一旦 RM 被当作优化目标,它就不再是好的衡量标准。
10.4 Reward Shaping 技术
Reward Shaping 的理论保证(势函数不变性)及其在 token 级奖励分配中的工程实例。
10.4.1 为什么需要 Reward Shaping?
在实际 RL 训练中,奖励信号常常是稀疏的——例如数学题只在最终答案正确时给 +1,中间推理步骤没有任何反馈。这导致智能体在漫长的探索中缺乏学习信号。
Reward Shaping 在环境奖励之上叠加辅助奖励信号,为智能体提供中间引导,加速学习过程。
10.4.2 势能形式的理论保证
为保证 Shaping 后的最优策略与原始最优策略一致(即辅助奖励不会"带偏"学习方向),辅助奖励必须满足**势能函数(Potential-based Shaping)**形式:
其中
10.4.3 工程实例
案例一:Cursor Tab 的奖励设计
Cursor 的代码补全(Tab 功能)使用 RL 来优化建议时机,其奖励设计权衡了"建议被接受"(正向价值)与"打扰用户"(负向代价):
| 事件 | 奖励值 | 设计意图 |
|---|---|---|
| 用户接受(Accept)建议 | 鼓励有用的建议 | |
| 用户拒绝(Reject)建议 | 惩罚打扰,但力度小于接受的正奖励 | |
| 不显示建议(No Show) | 中性基线 |
不对称的奖励幅度(+0.75 vs. -0.25)是典型的多目标 Reward Shaping:希望模型在不确定时宁可不显示,但一旦显示就要有把握被接受。
案例二:verl 中的 GSM8K Tool Call Shaping
在多轮工具调用场景中,verl 框架对中间步骤施加 Shaping 奖励:
# verl/examples/sglang_multiturn/gsm8k_toolcall_shaping/
# 工具调用结果正确:+1.0(完全正确)
# 工具调用格式正确但结果错:+0.2(鼓励格式学习)
# 格式错误:0.0(不惩罚,但也不鼓励)这种分层 Shaping 让模型先学会"正确调用工具"(格式),再学会"调用对的工具"(结果),降低了学习难度。
10.4.4 RLHF 中的 KL 惩罚即 Reward Shaping
RLHF 的 KL 正则项本质上就是对奖励函数的一种 Shaping:
它把"偏离参考模型的程度"编码为负奖励——偏离越大,惩罚越重。这同时实现了:
- 防止 OOD:模型不敢跑到 RM 评估不准确的区域
- 保持多样性:偏离参考模型太远的单一策略会被惩罚
从 Reward Shaping 的视角看,KL 惩罚定义了一个以
为中心的"势能场",策略越偏离这个中心,"势能"越高(惩罚越大)。
10.5 RaR(Reward-aware Reasoning)
RaR 将奖励建模从可验证任务推广到非可验证领域,通过推理过程评估回答质量。
10.5.1 动机:超越可验证领域
RLVR(Reinforcement Learning with Verifiable Rewards)在数学和代码领域取得了巨大成功,因为这些领域有天然的正确/错误信号——答案是 42 就是 42,代码能通过测试就是通过了。
但在医学诊断、科学推理、开放式写作等真实世界任务中,答案往往没有单一的"真理"。评价一个回答的好坏,依赖于多个维度的细微判断(Nuanced, Multi-criteria Judgments)。
RaR(Rubrics as Rewards)的核心思路:将"好答案的标准"解构为一系列可解释的、细粒度的检查清单(Checklist)。
10.5.2 RaR 的形式化定义
对于输入 prompt
:第 条标准的权重 :二元正确性函数,判断是否满足该标准
显式聚合(Explicit Aggregation):直接计算加权满足率,标准化到
隐式聚合(Implicit Aggregation):将所有 Rubric criteria 作为上下文输入给 LLM Judge,由模型直接打分:
10.5.3 RaR vs. Standard LLM-as-Judge
| 维度 | Standard LLM-as-Judge | RaR |
|---|---|---|
| 标准来源 | 通用 System Prompt("请打分 1-10,标准是准确性、有用性...") | 每个 Prompt 生成专属 Rubrics(如"是否计算了碳酸氢盐量?") |
| 输出结构 | 黑盒标量分数,不可解释 | 结构化多维检查项,每条可追溯 |
| Reward Hacking 风险 | 高(容易被长度、语气等肤浅特征欺骗) | 低(必须逐条满足具体标准) |
| 对 Judge 能力的要求 | 高(弱模型直接打分很随机) | 低(7B 模型 + Rubrics |
| 本质 | 主观推理任务 | 近似于数学题的伪客观验证任务 |
论文标题的深意:"Beyond Verifiable Domains"——在没有标准答案的领域,人造出标准。RaR 将一个主观推理任务转化为了伪可验证任务。
10.5.4 Rubrics 生成的 Prompt 设计
Rubrics 的质量直接决定 RaR 的效果。论文提出的生成 Prompt 遵循四项原则:
- Grounded in Expert Guidance:Rubric 条目需有专业依据
- Comprehensive Coverage:覆盖回答质量的所有关键维度
- Criterion Importance:为每条标准赋予合理权重
- Self-Contained Evaluation:每条标准独立可判,不依赖外部信息
10.5.5 Weak-to-Strong 的实现
RaR 的核心发现:Weak Judge + Rubrics
| 角色 | 模型选择 |
|---|---|
| Rubrics 生成(一次性) | GPT-4o(强模型) |
| Policy Model(待训练的策略模型) | Qwen2.5-7B-Instruct / LLaMA-3.1-8B |
| Judge / Reward Model(打分) | 同等或更小规模模型(Qwen2.5-7B/3B)+ Rubrics |
一旦有了清晰的 Rubrics 作为"脚手架",即使是 7B 的小模型也能做出接近 GPT-4 级别的准确评审。这使得用小模型监督大模型训练(Weak-to-Strong Generalization)成为可能,大幅降低了奖励建模的成本。
10.6 奖励标准化的讨论
奖励标准化的常见误区与正确做法:batch-level 与 group-level 归一化的差异。
10.6.1 问题的提出
一个常见的工程问题:如果奖励模型的输出分数范围从
手动归一化的两个陷阱:
- Sigmoid 归一化
:当 RM 输出绝对值很大(如 或 )时,Sigmoid 的导数趋近于 0,导致梯度消失,大量学习信号丢失 - Min-Max 归一化
:必须在 batch 内或全局统计 min/max,引入分布偏移与训练不稳定性
10.6.2 GRPO 的内置归一化
GRPO(Group Relative Policy Optimization)算法的设计初衷就是解决奖励尺度问题。它不需要外部归一化,因为其优势函数自带"相对化"处理。
对于同一个 Prompt
正确的做法:
- 不要做
- 不要做
(除非 RM 训练时最后一层就是 Sigmoid,但通常直接用 logits 更好) - 直接使用 RM 的原始 Logits/分数
- 依靠 GRPO 组内标准化自动适应分数范围
Why it works:标准化后的优势是"相对值"——不管原始奖励是
10.6.3 Dr. GRPO 的边界情况处理
标准 GRPO 在两种极端情况下会出问题:
全错的难题组:
R_hard = torch.tensor([0.0, 0.2, 0.2, 0.0, 0.0, 0.1, 0.0, 0.0])
# std = 0.0857,极小
# 标准化后优势绝对值被放大到 10+,梯度信号严重失真全对的易题组:
R_easy = torch.tensor([1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0])
# std = 0,除以 0!Dr. GRPO 的解决方案:检测到 std 过低(或全对/全错)的 batch 时,跳过梯度更新,避免虚假梯度信号。这是一种简单但有效的"安全阀"——宁可不学,也不被错误的梯度信号误导。
10.7 数据构建与偏序数据
偏好数据的构建方法论:从人工标注到 AI 反馈,数据质量对齐效果的决定性影响。
10.7.1 数据策展:配方与配比
后训练数据的构建不仅是"从哪来"的问题,更是一个配方(Recipe)与配比问题——不同来源的数据以何种比例混合,直接决定了模型的能力边界。
数据来源:
| 来源 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 已有开源数据集 | Anthropic HH、OpenAI TL;DR 等 | 成本低,可快速启动 | 分布可能与目标任务不匹配 |
| 人类标注 | 专业标注员对比评价回复好坏 | 质量高,贴合真实偏好 | 昂贵、慢、主观差异大 |
| 合成数据 | 采样 Agent 轨迹,RM 打分排序 | 可规模化,成本可控 | 质量依赖 RM 本身的质量(循环依赖) |
| 参考范文回溯 | 人类执行任务,LLM 反推思维链 | 数据自然真实,蒸馏人类隐性知识 | 工程复杂,需要高质量 LLM |
配比视角:实际训练中,SFT 与 RL 后训练的核心区别不在于数据来源,而在于数据格式和混合策略。SFT 需要"标准答案"(response),RL 只需要"评判标准"(reward model),这使得 RL 后训练可以利用更多无标注数据。但无论哪种方式,数据配比都需要平衡三个维度:
- 能力覆盖:数学、代码、通识、安全等不同领域的比例
- 难度梯度:简单题用于稳定训练,难题用于拓展能力边界
- 新旧平衡:任务特定数据与通用能力保持数据的比例(防止灾难性遗忘)
参考范文回溯的案例:SIMA 2 中,人类在游戏中交互产生具体动作,Gemini Pro 根据输入和人类的输出"脑补"推理过程(Reasoning Trace),从而构造出带思维链的训练数据。这种方法将人类的隐性操作知识转化为可训练的显式推理链,是"配方"设计中高质量数据的典型来源。
10.7.2 偏序数据(Partial Order Data)
偏好数据本质上是偏序关系(Partial Order):
与全序数据(可以对所有回复排出一个完整序列)不同,偏序数据允许"无法比较"(Incomparable)的情况存在——两个回复可能各有优劣、无法判定谁更好。这更贴近真实的人类偏好结构。
Bradley-Terry 模型正是将离散的偏序关系转换为连续奖励值的数学工具:从一堆"A 比 B 好"的偏序对中,推断出每个回复的隐含分数。
DPO 直接在偏序数据上训练,以
10.7.3 不同后训练方式的数据格式
| 后训练方式 | 数据格式 | 说明 |
|---|---|---|
| SFT | Prompt + 期望的 Response | |
| RLHF / PPO | Prompt + 训练好的 Reward Model | |
| DPO | Prompt + 偏好回复 + 拒绝回复 | |
| RLVR / GRPO | Prompt + 可验证奖励(如数学判题器) |
10.7.4 数据质量与 Reward Hacking
When a measure becomes a target, it ceases to be a good measure. —— Goodhart's Law
一旦奖励模型被当作优化目标,模型会寻找 RM 的盲点来"刷分",而非真正提升质量。
常见的 Reward Hacking 形式:
- 长度偏好:RM 倾向给更长的回复打高分,模型学会废话连篇
- 格式偏好:RM 偏好特定格式(如 Markdown 列表),模型机械套用
- 关键词偏好:特定词汇(如"当然"、"很高兴为您服务")得分更高
缓解方法:
- KL 正则:限制偏离参考模型的程度,防止过度优化
- 多维奖励:使用多个 RM 或多维评估标准,避免单一 RM 的盲点被利用
- 可验证奖励(RLVR):在可能的领域,使用无法被 Hack 的形式化验证替代 RM
- 混合训练策略:在 RL 训练数据中混入通用能力保持数据,防止灾难性遗忘
10.8 前沿研究话题
奖励模型与偏好学习领域的前沿研究方向与开放问题。
10.8.1 Value Implicit Pre-training(VIP)
VIP 范式提出了一种从人类演示中无监督学习奖励信号的方法:人类完成任务的视频本身就是一条价值递增的轨迹。
人类在视频中执行任务的过程,本质上是从低价值状态向高价值状态优化的过程。VIP 通过学习这种时间上的平滑性,在没有任何显式奖励标签的情况下构建出指导动作的势能场。
对于视频序列中的帧
即距离目标状态
意义:从人类演示视频中无监督地提取奖励信号,极大扩展了可训练任务的范围,无需人工设计每个任务的奖励函数。
10.8.2 带 Value Head 的奖励模型架构
现代奖励模型的典型架构设计:
- 基于预训练 LLM(如 Llama-3-8B、Nemotron-340B-Base)
- 移除原语言建模头(Unembedding Layer)
- 添加一个随机初始化的线性 Value Head,将最后一个 Token 的隐状态映射为标量
class RewardModel(nn.Module):
def __init__(self, base_model):
super().__init__()
self.base = base_model # 预训练 LLM
self.value_head = nn.Linear(base_model.config.hidden_size, 1)
def forward(self, input_ids, attention_mask):
hidden = self.base(input_ids, attention_mask).last_hidden_state
# 取最后一个 Token 的表征作为整个序列的"摘要"
# ⚠️ 右侧 padding 风险:如果 tokenizer 使用右侧 padding,
# hidden[:, -1, :] 取到的是 [PAD] token 的表征而非真实末尾 token。
# 正确做法:用 attention_mask 找到每条序列的最后一个非 padding 位置,
# 例如 last_idx = attention_mask.sum(dim=1) - 1
reward = self.value_head(hidden[:, -1, :]).squeeze(-1)
return reward这种架构的设计思路:最大程度保留基座模型的语义理解能力(只修改最后的 head),同时通过微调学习人类偏好的评分逻辑。基座模型负责"理解",Value Head 负责"打分"。
10.8.3 DPO 在 Agentic 场景中的应用
代表工作 MiroThinker 展示了 DPO 在 Research Agent 决策细化中的三阶段应用模式:
阶段 1(SFT):学习基本 Agent 行为(工具使用、推理格式)
阶段 2(DPO):比较成功/失败的 Agent 轨迹,细化决策策略
阶段 3(RLVR):基于可验证的任务完成度进一步强化DPO 阶段的核心机制:通过最大化"正样本"(成功轨迹)与"负样本"(失败轨迹)之间的似然差来优化策略,使模型学会在关键决策点选择更优的行动路径。
10.8.4 SIMA 2 的混合数据策略
为防止灾难性遗忘(Catastrophic Forgetting),SIMA 2 在 RL 微调时采用混合训练策略:
- 任务特定数据:新任务的 RL 轨迹,驱动能力提升
- 通用能力保持数据:原始 SFT / 预训练数据,维持已有能力
这种"训新保旧"的策略在实践中被广泛采用,核心思想是:RL 后训练不应以牺牲通用能力为代价。
10.8.5 开放研究问题
- 奖励泛化(Reward Generalization):RM 如何在训练分布之外保持准确性?能否构建对 OOD 输入鲁棒的奖励模型?
- 细粒度偏好建模:如何在单一奖励信号中区分"更准确"vs."更礼貌"vs."更有创意"等不同维度?
- 多模态奖励:图像、视频、音频任务中的偏好建模,如何处理跨模态的偏好对比?
- 奖励校准(Reward Calibration):RM 输出的分数是否有绝对意义?不同 RM 的分数能否直接比较?
- Process Reward Model(PRM):对推理过程的每一步打分,而非仅对最终答案打分——这是 OpenAI PRM800K 和 DeepSeek-R1 所关注的核心方向
本章小结
| 主题 | 核心要点 |
|---|---|
| Bradley-Terry 模型 | 三层建模(DL + BT + MLE);偏好概率 |
| DPO 推导 | KL 约束最优策略的解析解 |
| DPO 局限 | 评估 |
| Reward Shaping | 势能形式保证最优策略不变;KL 惩罚是 Shaping 的特殊形式;Cursor Tab 与 verl 工程实例 |
| RaR | Rubrics 将主观评估转化为伪客观验证;Weak Judge + Rubrics |
| 奖励标准化 | GRPO 组内标准化替代手动归一化;Dr. GRPO 跳过全对/全错 batch |
| 偏序数据 | 三元组 |
| 前沿方向 | VIP(无标签奖励学习);Value Head 架构;PRM(过程奖励);Agentic DPO;混合训练策略 |
延伸阅读
- Bradley & Terry, 1952:Rank Analysis of Incomplete Block Designs——原始 BT 模型论文
- DPO 原始论文:Rafailov et al., 2023
- InstructGPT / RLHF:Ouyang et al., 2022
- RaR: Rubrics as Rewards:多标准奖励建模,扩展 RLVR 到非可验证领域
- PRM800K:OpenAI 过程奖励数据集
- VIP: Value Implicit Pre-training:从视频中无监督学习奖励信号
- MiroThinker:DPO 在 Agentic 场景的应用
- RLHF Pipeline 详解:HuggingFace 实战指南
- Cursor Tab RL:Reward Shaping 的工业实践