第 9 章:从 Policy Gradient 到 PPO
深度强化学习的策略优化方法贯穿了一条清晰的演进脉络:REINFORCE 给出了原始的无偏梯度估计,Baseline 降低了方差,Importance Sampling 打开了数据复用的大门,TRPO 用信任域约束保证了单调改进,而 PPO-Clip 则以极简的裁剪操作实现了工程上的高效落地。本章沿这条主线,同时覆盖 DQN、Actor-Critic、SAC 等必要分支,最终连接到 GRPO——LLM 时代策略优化的直接前身。
前置知识:本章的策略梯度推导建立在第 3 章的变分推断框架之上(见 §3.3),特别是 KL 散度、对数导数技巧和期望的蒙特卡洛估计等工具。
9.1 Policy Gradient 定理推导
从目标函数出发,利用 Log-Derivative Trick 推导 Policy Gradient 定理的完整数学链路。
9.1.1 目标函数
RL 的优化目标(Utility)是最大化策略
其中轨迹概率
Reward vs. Return:Reward 是环境在单步给出的即时评分;Return(回报,又称累积奖励)是从某个时间步往后所有未来奖励的折扣总和。算法真正最大化的是 Return 的期望。
9.1.2 梯度推导——Log-Derivative Trick
直接对
问题在于
展开轨迹的对数概率,环境转移概率
将整条轨迹的回报
9.1.3 直觉:
- 我们只能从
采样,无法从 采样( 不是概率分布); - 通过
,把"对概率的梯度"变成"概率分布下可采样的期望"; 可微且可计算,乘以回报权重 即为梯度的蒙特卡洛估计量。
更高回报的轨迹会以更高的概率被复制,更低回报的轨迹概率被压低——这就是策略梯度的核心语义。
9.1.4 Surrogate Loss 与自动微分
深度学习框架默认做的是梯度下降(最小化 loss),而我们需要梯度上升(最大化
实现中把
关键认知:PG Loss 是"为拿到正确梯度而设计的代理",不是"可直接代表性能的目标值"。我们只需要
与 相等, 的数值本身没有可比性。
9.2 REINFORCE 算法与 Baseline 技巧
REINFORCE 的高方差问题及 Baseline 减方差技巧,奠定后续 Actor-Critic 方法的基础。
9.2.1 REINFORCE 算法
REINFORCE 是 Policy Gradient 的最直接实现:每条轨迹采样完毕后,从后向前计算折扣回报
CartPole 完整实现:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
import gymnasium as gym
GAMMA = 0.99
class Policy(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.network = nn.Sequential(
nn.Linear(state_dim, 128),
nn.ReLU(),
nn.Linear(128, action_dim),
nn.Softmax(dim=-1)
)
def forward(self, state):
return self.network(state)
class ReinforceAgent:
def __init__(self, state_dim, action_dim):
self.policy = Policy(state_dim, action_dim)
self.optimizer = optim.Adam(self.policy.parameters(), lr=0.01)
self.saved_log_probs = []
self.rewards = []
def select_action(self, state):
state = torch.from_numpy(state).float().unsqueeze(0)
probs = self.policy(state)
m = Categorical(probs)
action = m.sample()
self.saved_log_probs.append(m.log_prob(action)) # 记录 log pi
return action.item()
def finish_episode(self):
R = 0
returns = []
# 从后向前计算折扣回报
for r in reversed(self.rewards):
R = r + GAMMA * R
returns.insert(0, R)
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + 1e-6) # 标准化
policy_loss = []
for log_prob, G in zip(self.saved_log_probs, returns):
policy_loss.append(-log_prob * G) # Surrogate Loss
self.optimizer.zero_grad()
torch.cat(policy_loss).sum().backward()
self.optimizer.step()
del self.rewards[:]
del self.saved_log_probs[:]
# --- 训练入口 ---
env = gym.make("CartPole-v1")
agent = ReinforceAgent(state_dim=env.observation_space.shape[0],
action_dim=env.action_space.n)
for episode in range(1000):
state, _ = env.reset()
for t in range(500):
action = agent.select_action(state)
state, reward, terminated, truncated, _ = env.step(action)
agent.rewards.append(reward)
if terminated or truncated:
break
agent.finish_episode()
if episode % 50 == 0:
print(f"Episode {episode}, duration: {t+1}")代码解读:
select_action:从当前策略采样动作,同时记录; finish_episode:一条轨迹结束后,从后向前累积折扣回报,标准化后构造 loss = ,一次反向传播更新策略; - On-policy 特性:一条轨迹只训练一次,然后丢弃,数据不可复用。
9.2.2 Baseline 与 Advantage
理论依据:Score Function 的期望恒为零,即
简单证明:
因此减去任意不依赖动作的 Baseline
定义优势函数(Advantage):
:这次动作比预期好,增大其概率; :这次动作比预期差,降低其概率。
直觉例子(一直输的游戏):AI 目前水平的平均得分(Baseline)约为
分。某局得了 分,优势 。尽管还是输了,但比平时表现好,这些动作值得被鼓励。
带 Baseline 的 PG Loss:
9.2.3 折扣回报与信用分配
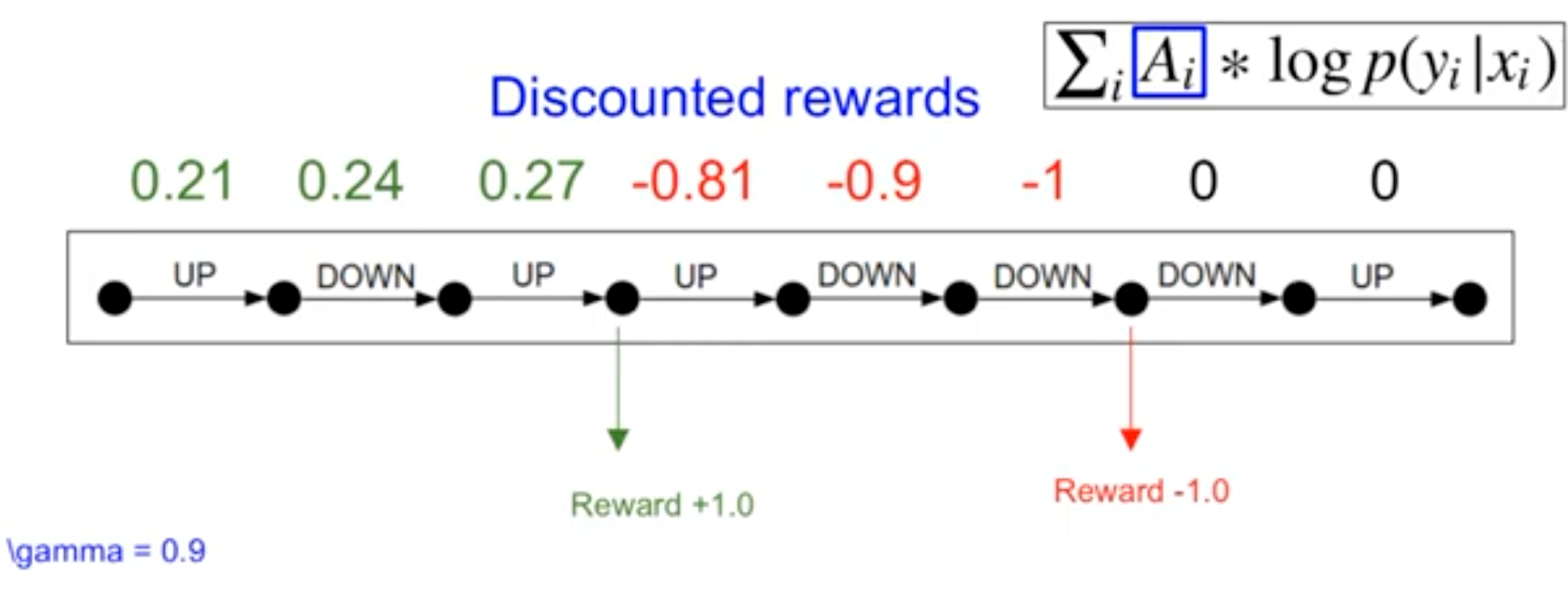
折扣因子
- 动作对越久之后的回报,所负责任越小(
衰减); - 离奖励信号越近的动作,责任越大。
例如
9.2.4 PG Loss vs. SL Loss
Karpathy 的经典对比揭示了 RL 与监督学习的本质差异:
两步操作:
- 采样:没有"正确答案",用当前策略
生成数据; - 加权优化:用 Advantage
告诉模型哪些动作该加强( )、哪些该抑制( )。
SL 最大化所有正确标签的似然;PG 选择性地放大好动作、压缩坏动作的似然。
9.3 Q-Learning 与 DQN
Value-based 路线的代表:Q-Learning 的表格版与深度网络版(DQN)的关键设计。
9.3.1 从 Q-Table 到 Deep Q-Network
- 有限离散状态空间:用 Q-Table 存储
,直接查表更新; - 连续/海量状态空间:Q-Table 不可行,用深度神经网络
参数化——Deep Q-Network (DQN)。
Q-Learning 的更新规则:
9.3.2 DQN 的目标函数
将 Q-Learning 的更新规则转化为深度学习的回归损失:
其中
9.3.3 DQN 的关键技术
Experience Replay(经验回放):将转移
- 打破数据间的时序相关性,使样本更接近 i.i.d. 假设;
- 同一条经验可被多次使用,提高数据利用率——这是 Off-policy 的直接体现。
Target Network(目标网络):固定 TD Target 的"地基",防止
DQN 中的策略:DQN 的最终目标是导出一个隐式的确定性贪心策略
。训练过程中使用 -greedy 行为策略保证探索。
9.3.4 DQN vs. PPO:根本差异
| 维度 | DQN(Value-based) | PPO(Policy-based) |
|---|---|---|
| 学习对象 | ||
| 策略类型 | 隐式确定性( | 显式随机策略 |
| On/Off-policy | Off-policy | On-policy(带重要性采样修正) |
| 适用动作空间 | 离散有限 | 连续或离散均可 |
| 数据复用 | 经验回放,高复用率 | 数据生命周期短 |
Off-policy 的直觉:DQN 学习的是 Q 值——动作的"客观价值"。无论当时是出于新手好奇还是专家判断做出的动作,结果(奖励)是客观存在的,因此用过去的经验来更新价值判断完全合理。PPO 学习的是"当前策略下应该怎么做",策略一变,旧数据的梯度方向就不再准确。
9.4 Actor-Critic 架构
策略网络与价值网络联合学习,兼取 Policy Gradient 的灵活性与 TD 的低方差优势。
9.4.1 双网络架构
Actor-Critic 结合了 Policy Gradient 和价值函数两条路线:
- Actor(策略网络
):负责决策,输出动作概率分布; - Critic(价值网络
):负责评分,估计当前状态的价值。
9.4.2 TD 形式的优势函数
REINFORCE 使用蒙特卡洛回报
分解来看:
9.4.3 Bias-Variance 权衡
Critic 的核心价值在于用偏差换方差:
| 来源 | 效果 | 解释 |
|---|---|---|
| Bootstrap: | 方差下降,引入偏差 | 不再依赖未来数百步的随机结果,用 Critic 的预测值直接替代 |
| Baseline: | 不影响期望,降低方差 | 减去一个只与状态有关的基线,数学上梯度期望不变 |
方差来源:REINFORCE 的
需要把整条轨迹从当前步到终止全部跑完,其中每一步的随机性(环境转移 + 策略采样)都会累积;TD Error 只看一步,随机性大幅减小。代价是 本身是近似值,引入了偏差。
9.4.4 Actor 与 Critic 的更新
Critic 更新(最小化 TD 误差):
Actor 更新(用 Advantage 加权
两个网络交替更新:Critic 先打分,Actor 再根据打分调整策略。
9.5 SAC(Soft Actor-Critic)基础
最大熵框架下的 Actor-Critic:SAC 如何通过熵正则化实现稳定的连续控制。
9.5.1 最大熵强化学习目标
SAC 在标准 RL 目标中加入熵奖励,鼓励策略在完成任务的同时保持随机性:
其中
直觉:在回报相近的多条路径中,SAC 倾向于选择"保持更多选择余地"的策略,避免过早收敛到局部最优。
9.5.2 与 KL 正则化的等价关系
当参考策略
这个形式正是 RLHF 中 KL 惩罚项的理论来源。SAC 的思想——"最大化回报同时不要偏离参考分布太远"——在 LLM 对齐中被直接继承。
9.5.3 SAC 的核心特点
- Off-policy:使用经验回放,数据效率高;
- 自动温度调节:
可以自动学习,无需手动调参; - 连续动作空间:天然适合连续控制任务。
9.6 从 PG 到 PPO-Clip 的演进
从 Importance Sampling 到 Trust Region 再到 PPO-Clip,策略优化的稳定性演进之路。
9.6.1 REINFORCE 的局限
REINFORCE 每次更新必须使用当前策略采样的数据——一条数据只训练一次,用完即弃。
当与环境交互的成本很高时(如机器人、LLM),这种数据效率是不可接受的。
改进目标:先用旧策略
9.6.2 重要性采样与 CPI 代理目标
定义概率比(Likelihood Ratio):
CPI(Conservative Policy Iteration)代理目标:
在
这正是 vanilla PG(Advantage 版本)的梯度。换言之,CPI 用
PG 用
;CPI 用 。前者是绝对量,后者是相对量(比值),但在 处它们给出相同的更新方向。
9.6.3 TRPO:信任域约束
CPI 的问题在于:当
TRPO 在 CPI 目标上加 KL 信任域约束:
约束方向:KL 散度
度量的是"在旧策略的支撑上、新策略偏离了多少"。选择 作为 KL 的第一个参数(而非 ),是因为我们希望在旧策略已覆盖的区域内约束新策略的行为——这正是 TRPO 原始论文(Schulman et al., 2015)中使用的方向。
直觉:以
为圆心画一个 KL 球(信任域,Trust Region),在球内找使代理目标最大的新策略。
问题:TRPO 需要计算二阶 Fisher 信息矩阵的逆,计算代价高,难以与现代深度学习框架(自动微分 + 一阶优化器)高效集成。
9.6.4 PPO-Clip:简洁的工程实现
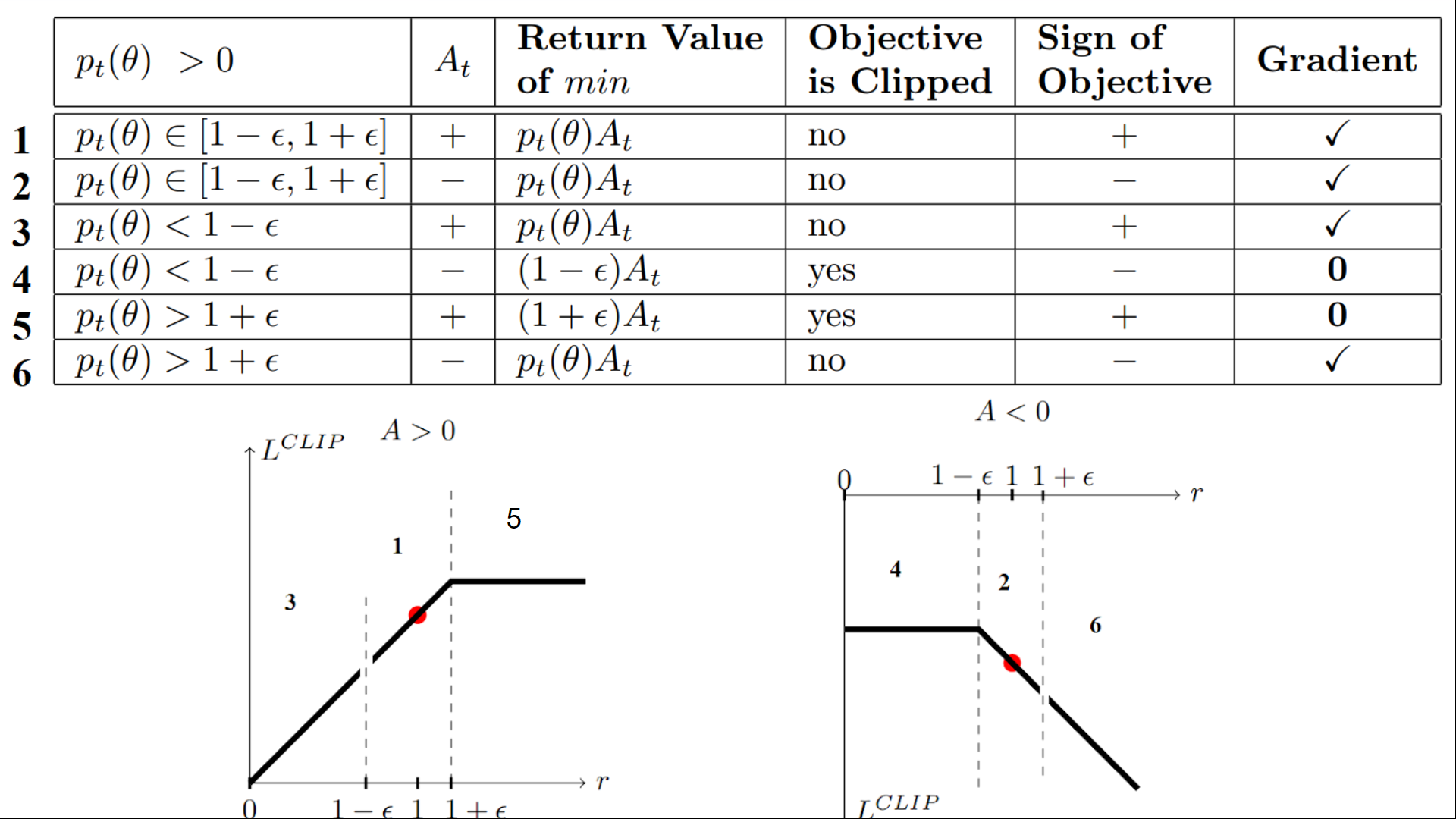
PPO 用简单的裁剪操作近似替代 TRPO 的信任域约束:
裁剪逻辑(以
| 情形 | 条件 | 处理 | 原因 |
|---|---|---|---|
| 截至 | 涨太猛,防止过度乐观 | ||
| 不截,梯度拉回 | 好动作概率太低,继续拉升 | ||
| 不截,梯度压低 | 坏动作概率太高,继续惩罚 | ||
| 截至 | 降太猛,防止过激 |
核心原则:只在"有利方向"超出阈值时截平(防止过激乐观),在不利方向保持完整梯度(让惩罚保真)。
9.6.5 探索与利用:PPO 的上界约束
PPO 的 clip 机制对高概率 token(exploitation)和低概率 token(exploration)的影响并不对称。以
- 当
时,上限 ,高概率 token 可以轻松获得显著的概率增量; - 当
时,上限 ,低概率 token 被严格限制,难以获得实质性增长。
这意味着 PPO 的上界约束天然倾向于利用已有的高概率动作,而抑制了对低概率动作的探索。这一观察在 DAPO 等后续工作中被明确指出并修正。
9.7 PPO from Scratch 实现
从零实现 PPO:包含 Actor-Critic 网络、GAE 优势估计与 Clip 目标函数的完整代码。
9.7.1 PPO 完整目标函数(RL4LLM 版本)
其中
- PG 项:正优势回答的
被拉大(概率上升),负优势回答的概率下降; - KL 项:防止策略偏离参考模型太远。
9.7.2 PG Loss 的数值含义
单样本的 PG Loss 项为:
:当前策略对已选动作的对数概率——增大它等于沿梯度让该动作更可能; :这次选择的信用分——高于基线就奖励,低于基线就惩罚; - 乘积效果:好动作的
变大,坏动作的 变小。
9.7.3 优势标准化对 Loss 的影响
优势标准化(Whiten)后
- Cov > 0(好动作概率高):Loss < 0,优化方向正确,继续推进;
- Cov < 0(策略更偏好坏动作):Loss > 0,梯度强力纠正;
- Cov
0:策略无明显偏好,或已接近收敛。
9.7.4 Loss 围绕 0 震荡的案例分析
import numpy as np
def ppo_terms(A, r, eps=0.2):
A = np.asarray(A, dtype=float)
r = np.asarray(r, dtype=float)
r_clip = np.clip(r, 1 - eps, 1 + eps)
term_pg = r * A
term_clip = np.minimum(term_pg, r_clip * A)
return term_clip
# Case A:好样本概率上升、坏样本概率下降(正常训练状态)
A_A = [2.0, 1.0, -1.5, -1.5] # 均值 = 0
R_A = [1.18, 1.10, 0.90, 0.92] # 全在 clip 范围内
L_A = -np.mean(ppo_terms(A_A, R_A)) # ≈ -0.18(Loss < 0)
# Case B:好样本概率下降、有坏样本概率大幅上升被 clip
A_B = [2.0, 1.0, -1.5, -1.5]
R_B = [0.85, 0.88, 0.82, 1.50] # 最后一个触发上界 clip
L_B = -np.mean(ppo_terms(A_B, R_B)) # ≈ +0.22(Loss > 0)- Case A:正优势样本的
,负优势样本的 ,正贡献略占优, ; - Case B:好样本概率下降(
,削弱正贡献),有坏样本 大涨且被不利地记账,负贡献占优, 。 - 纯 On-policy 时:
,所有 ,加上优势被标准化(均值为 0),Loss = 0。但 Loss = 0 不代表梯度 = 0——在 处,梯度 仍然存在。
9.7.5 为什么 RL Loss 曲线不能像 SL 那样解读
监督学习的 loss 函数固定(数据集不变,只有参数在动),所以"同一函数值"的下降有意义。RL 中,每一步的 loss 函数本身不同——数据是从不断变化的策略中采样的。第
步优化的是 (期望对 求),第 步优化的是 (期望对 求),它们根本不是同一个函数。
横向比较不同步的 Loss 值,就像把苹果、橘子、土豆、番茄的"甜度"放在一条线上——数值没有可比性。
监控建议:训练 RL 时应关注 Reward/Return 曲线,而非 PG Loss 曲线。Loss 的增长往往反映的是 KL 散度在增大(模型在学习),而非训练出了问题。
9.8 稀疏奖励与奖励分配问题
奖励稀疏时的信号分配问题:GAE 与 Reward Shaping 的解决思路。
9.8.1 信用分配难题
在大多数现实任务中,奖励是稀疏的:智能体在一段很长的序列末尾才得到奖励(如游戏结束时才知道胜负、LLM 生成完整回答后才得到评分),中间步骤的"功劳"难以分配。
本质困难:奖励信号只在序列末尾出现一次,但整个序列有数十甚至数百步——哪些步骤"应该负责"这个奖励?
9.8.2 折扣回报的信用分配视角
折扣因子
- 越靠近奖励信号的动作,分配到的权重越大;
- 越远离奖励信号的动作,权重按
指数衰减。
但在奖励极度稀疏的场景中(例如只在最后一步给
9.8.3 常见解法
1. Reward Shaping(奖励塑形)
在环境奖励之上叠加辅助信号,引导智能体更快找到目标。例如:
- Cursor Tab RL 中:接受建议
,拒绝 ,不显示 ; - 机器人导航中:每靠近目标一步给正奖励。
2. Potential-based Shaping(基于势能的塑形)
为保证最优策略不变,辅助奖励必须满足势能函数形式:
其中
3. Intrinsic Motivation(内在动机)
引入探索奖励(好奇心驱动、新颖性检测)鼓励智能体访问未见过的状态,缓解稀疏奖励下的"漫无目的"问题。
4. Hierarchical RL(分层强化学习)
将大问题分解为子目标,子目标有更密集的奖励信号。高层策略选择子目标,低层策略执行具体动作。
9.9 Group Policy Optimization(GRPO 前身)
去除 Critic 的组内相对优势估计,从 PPO 走向 GRPO 的理论铺垫。
9.9.1 设计动机
标准 PPO 依赖 Critic 网络来估计优势函数。但在 LLM 场景中:
- Critic 网络的参数量与 LLM 本身相当,训练代价翻倍;
- 对于有明确打分机制的任务(数学题、代码题),可以直接用实际奖励做对比,无需 Critic 近似。
GRPO(Group Relative Policy Optimization)的核心想法:用组内采样的实际奖励做相对比较,替代 Critic 网络。
9.9.2 组内相对优势
对同一个 Prompt
高于组内均值的输出获得正优势,低于均值的获得负优势。
9.9.3 目标函数
结构上与 PPO-Clip 一致(min-clip 项 + KL 正则),区别在于优势
9.9.4 GRPO Loss 为 0 的推导
在纯 on-policy(
因此
9.9.5 Dr. GRPO:处理退化组
标准 GRPO 的组内标准化在两种极端情况下会出问题:
难题(几乎全错):
R_hard = torch.tensor([0.0, 0.2, 0.2, 0.0, 0.0, 0.1, 0.0, 0.0])
# mean=0.0625, std=0.0857方差极小,标准化后那些"勉强答对"(
简单题(几乎全对):
R_easy = torch.tensor([0.2, 0.9, 1.0, 0.4, 1.0, 0.1, 0.9, 0.0])
# mean=0.5625, std=0.4029方差适中,标准化后的优势分布合理,梯度信号有效。
Dr. GRPO 的修正策略:检测"组内方差过低"或"全部正确/错误"的退化情况,跳过该组的更新,避免被噪声梯度误导。
9.9.6 GRPO vs. PPO 对比
| 维度 | PPO | GRPO |
|---|---|---|
| 优势估计 | Critic 网络(TD 自举) | 组内奖励标准化 |
| 额外参数 | 需要 Critic(参数量 | 无需 Critic |
| 适用场景 | 通用 RL 任务 | 有明确打分的生成任务(RLVR) |
| 每个 Prompt 采样 | 1 个输出 | |
| 信号质量 | 低偏差(Critic 拟合好时) | 依赖组内多样性 |
本章小结
| 主题 | 核心内容 |
|---|---|
| Policy Gradient 定理 | Log-derivative trick; |
| REINFORCE | 完整轨迹 MC 估计;On-policy;高方差;Surrogate Loss |
| Baseline / Advantage | |
| Q-Learning / DQN | Off-policy;Experience Replay;Target Network |
| Actor-Critic | TD 优势估计;Bias-Variance 权衡;Critic 截断未来 |
| SAC | 最大熵 RL;熵奖励 |
| IS | |
| PPO Loss 分析 | 非单调;Loss=0 时梯度非零;应看 Reward 曲线 |
| 稀疏奖励 | 信用分配;Reward Shaping;势能形式 |
| GRPO | 组内相对优势;无需 Critic;Dr. GRPO 退化组修正 |
延伸阅读
- PPO 原始论文:Schulman et al., 2017
- TRPO 原始论文:Schulman et al., 2015
- SAC 原始论文:Haarnoja et al., 2018
- GRPO / DeepSeek-R1:DeepSeek-AI, 2025
- PPO 100 行实现
- Karpathy RL 博客:PG 与 SL 的对比讲解
- Andrej Burkov 关于 RL Loss 的 X 帖:RL Loss 曲线增长不代表训练出了问题
- 动手学强化学习:DQN、策略梯度等中文教程