第 16 章:verl 与 TRL 训练框架
16.1 verl 架构概念与设计哲学
verl 的设计哲学:单控制器调度 + 多控制器执行的混合架构,让用户只关注数据流图。
为什么需要专用的 RL 训练框架
RLHF/RLVR 训练与标准 SFT 存在本质区别:
- 多模型协同:Actor、Critic、Reference Policy、Reward Model 需要同时在线,在有限 GPU 资源上合理共享显存。
- 推理-训练交替:Rollout(推理生成)和 Training(梯度更新)对 GPU 使用模式完全不同——前者需要 KV Cache,后者需要优化器状态和激活值。
- 数据流复杂:生成的轨迹需要携带 log prob、reward、advantage 等元信息在多个组件间流转。
verl(由字节跳动开源)通过"单控制器调度 + 多控制器执行"的混合架构解决了这些挑战。其核心设计哲学是:让用户只关注数据流图(Dataflow Graph),不需要操心分布式实现细节。
Single-Controller vs. Multi-Controller
verl 的架构分为两层:
Single-Controller(RayPPOTrainer)——控制层:
- 运行在普通 Python 进程中,不占用 GPU
- 负责训练循环的编排:生成 -> 奖励计算 -> 优势计算 -> 更新
- 不断地更新(维护)
DataProto数据容器 - Worker Procedure 之间按序执行,用户只需关注数据流依赖
Multi-Controller(WorkerGroup)——执行层:
- 每个 Worker Group 内部以 SPMD(Single Program, Multiple Data)方式运行
- 所有 GPU/进程跑同一段程序,只是各自处理不同的数据分片
- SPMD 是 DP(DDP/ZeRO/FSDP)、TP、PP、SP 等分布式方法的编程模型
# 概念上等价于:
out = wg.generate_sequences(batch)
# 底层实际执行:
shards = split(batch, world_size)
refs = [worker_i.generate_sequences.remote(shards[i]) for i in range(world_size)]
out = concat(ray.get(refs))Worker Group 与角色分工
verl 中的核心 Worker Group 及其方法映射:
| Worker Group | 关键方法 | 职责 |
|---|---|---|
actor_rollout_wg | generate_sequences, compute_log_prob, update_actor | 推理生成 + Actor 训练 |
ref_policy_wg | compute_ref_log_prob | 参考策略 KL 计算 |
critic_wg | compute_values, update_critic | 价值估计 + Critic 训练 |
Hybrid Engine:训练与推理的融合
verl 将传统上分离的 Actor(策略网络训练)和 Rollout(推理生成)融合到同一个 Worker 中,即同一 GPU 既可训练也可推理。这是通过 ActorRolloutRefWorker 实现的:
class ActorRolloutRefWorker:
# 可以被实例化为 standalone actor / standalone rollout /
# standalone reference policy / hybrid engine通过 rollout_mode() 和 trainer_mode() 在两种模式间切换。
EntryPoint:训练入口
# main_ppo.TaskRunner.run
resource_pool_spec = {
global_pool_id: [config.trainer.n_gpus_per_node] * config.trainer.nnodes,
}
# 所有角色映射到同一个 GPU 资源池(Colocation)
self.mapping[Role.ActorRollout] = global_pool_id
self.mapping[Role.Critic] = global_pool_id
self.mapping[Role.RefPolicy] = global_pool_id
# 创建 Worker Group
resource_pool_manager = ResourcePoolManager(
resource_pool_spec=resource_pool_spec, mapping=self.mapping
)
trainer = RayPPOTrainer(config, ...)
trainer.init_workers()
trainer.fit()Colocated Worker 机制
每个 Worker Group 对应一个 resource_pool(一组 GPU 资源)。多个角色共享同一个 pool 时,verl 使用 create_colocated_worker_cls 将它们合并:
resource_pool_to_cls = {
global_pool: {
"actor_rollout": RayClassWithInitArgs(ActorRolloutRefWorker, ...),
"critic": RayClassWithInitArgs(CriticWorker, ...),
"ref": RayClassWithInitArgs(RefPolicyWorker, ...),
}
}
worker_dict_cls = create_colocated_worker_cls(class_dict=...)RayWorkerGroup 在初始化时会扫描 Worker 类中所有带 @register 装饰器的方法,并动态通过 setattr 将它们挂载到自己身上。
16.2 verl 核心架构详解
DataProto 数据容器、WorkerGroup 执行层与参数同步机制的实现细节。
Training Step 同步序列
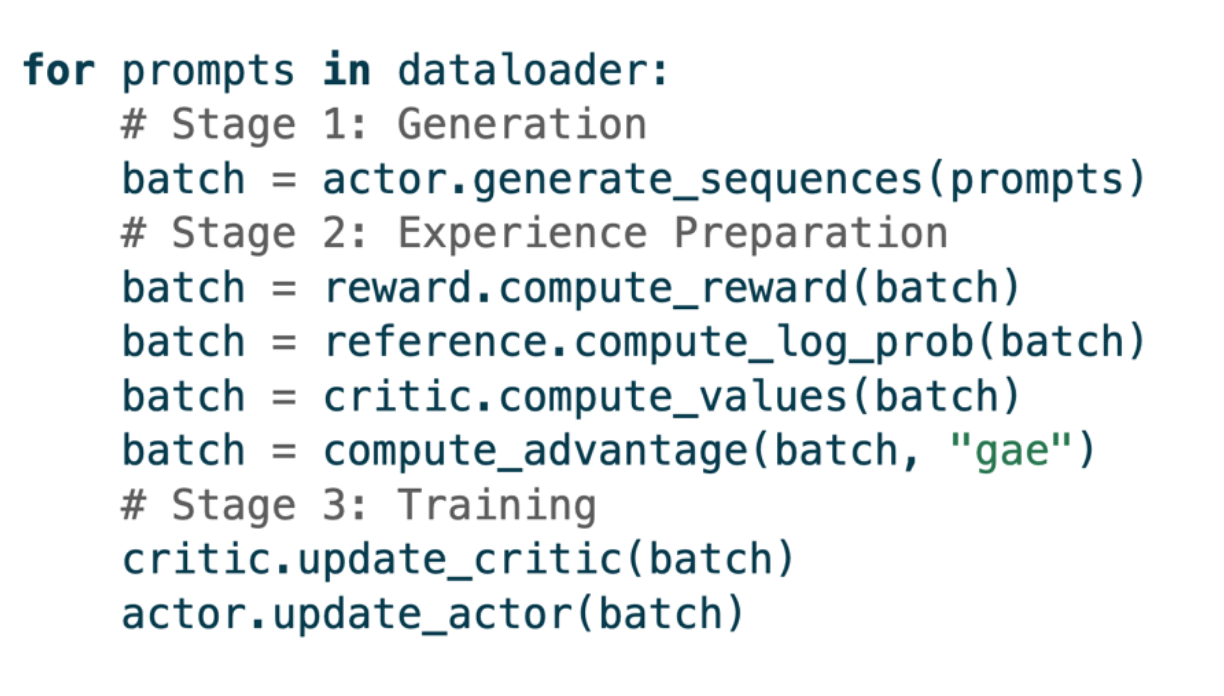
一个完整的训练 step 按以下顺序依次执行:
generate_sequences()— 所有 DP rank 生成完成compute_rm_score()— Reward Model 计算compute_log_prob()— Actor 重新计算 old log probcompute_ref_log_prob()— Reference Policy 计算compute_values()— Critic 计算 Values(PPO 模式)update_critic()— Critic 梯度更新(NCCL AllReduce)update_actor()— Actor 梯度更新(NCCL AllReduce)
Hybrid Colocate 模式下的显存分析
关于 FSDP/ZeRO 分片策略的原理与配置,参见第 14 章"分布式训练"。
核心挑战:Actor 需要同时承担 Rollout(vLLM 推理)和 Training(FSDP 训练)两个角色,但两种状态的显存需求完全不同,无法同时存放在 GPU 上。
verl 的解决方案是分时复用——通过 sleep 和 wake_up 在两个阶段间动态切换:
Rollout 阶段(vLLM 是主占用方):
- vLLM weights + KV cache + decode/prefill buffers
- Trainer 仍保留底座:optimizer state + grad buffer + CUDA/NCCL context
- 模型参数 shard 已经被 offload 到 CPU(
self.actor.engine.to("cpu", model=True, optimizer=False, grad=False))
Training 阶段(Trainer 是主占用方):
- 训练开始前先让 rollout
sleep_replicas(),释放 weights 和 KV cache - vLLM 在 hybrid 模式下的
sleep(level=2)会释放 weights 和 kv_cache - 主占用方变成 actor model shard + optimizer states + grad buffers + activations
- vLLM 侧只剩进程本身、CUDA context 等少量 runtime 状态
瞬时显存峰值:在 update_weights() 阶段存在短暂的叠加:
- 先
resume(weights),触发 vLLM wake_up,权重显存重新映射回 GPU - 然后才从 actor 取参数并同步到 rollout
- 最后才把 actor offload 到 CPU
# engine_workers.py 中的关键顺序
rollout.resume(tags=["weights"]) # vLLM 唤醒,权重回 GPU
# 此时 actor 训练态显存还在 -> 瞬时叠加峰值
actor.engine.to("cpu", model=True, optimizer=False, grad=False) # actor offload
rollout.resume(tags=["kv_cache"]) # KV cache 恢复wake_up / sleep 实现:
# vllm_async_server.py
async def wake_up(self):
if self.rollout_mode == RolloutMode.HYBRID:
# 调用所有 worker 进行权重同步和显存准备
await asyncio.gather(*[worker.wake_up.remote() for worker in self.workers])
elif self.rollout_mode == RolloutMode.STANDALONE:
logger.info("skip wake_up in standalone mode")
async def sleep(self):
if self.rollout_mode == RolloutMode.HYBRID:
if self.node_rank == 0:
await self.engine.reset_prefix_cache() # 重置 Prefix Cache
await asyncio.gather(*[worker.sleep.remote() for worker in self.workers])在 Standalone 模式(推理和训练在不同 GPU 上)下,wake_up/sleep 不需要执行任何操作。
| Policy | 部署位置 | 角色 | 更新时机 |
|---|---|---|---|
| GPU 常驻 | 当前正在优化的策略 | 每个 PPO mini-batch 后 | |
| GPU 重算 | IS Ratio 分母 | 每个 Global Step 前 | |
| CPU 常驻,FSDP Offload | KL 惩罚基准 | 不更新 |
Actor(常驻 GPU):需要频繁 Forward/Backward/Optimizer Step,频繁搬运不可接受。
Ref Model(常驻 CPU):ref.fsdp_config.param_offload=True,且 forward_only=True。调用 compute_ref_log_prob 时,FSDP 会流式加载——算到第 i 层时将参数从 CPU 拷到 GPU,算完立即释放,同一时刻 GPU 上只有 Actor 全部参数 + Ref 一层参数。
Metrics
关键时间指标:timing_s/gen|old_log_prob|ref|values|update_critic|update_actor|save_checkpoint
16.3 Rollout Engine
Rollout Engine 的配置与调优:vLLM/SGLang 后端选择、采样参数与显存管理。
Rollout 引擎注册表
verl 通过注册表支持多种推理后端:
_ROLLOUT_REGISTRY = {
("vllm", "sync"): "verl.workers.rollout.vllm_rollout.vLLMRollout",
("vllm", "async"): "verl.workers.rollout.vllm_rollout.vLLMAsyncRollout",
("sglang", "sync"): "verl.workers.rollout.sglang_rollout.SGLangRollout",
("sglang", "async"):"verl.workers.rollout.sglang_rollout.SGLangRollout",
}- Sync 模式:同步批量推理,适合 GRPO 等单轮对话场景
- Async 模式:异步推理,适合多轮 Agent 任务(见 16.7 节)
vLLM Rollout 关键配置
actor_rollout_ref:
rollout:
name: vllm
mode: sync # sync / async
temperature: 1.0
n: 4 # 每个 prompt 采样 4 条轨迹
max_model_len: 8192
gpu_memory_utilization: 0.85
free_cache_engine: true # 启用 sleep/wake_upvLLM 调度参数:
max_model_len:最大生成长度(含 prompt + generated)max_num_batched_tokens:一次推理中处理的最大 token 数,把所有活跃序列的 prefill + decode token 合计max_num_seqs:同时处理的最大序列数
Prefill 分块调度示例:对于长 prompt(如 6000 token),vLLM 按 long_prefill_token_threshold=1024 分块,每步与短请求的 decode 混合执行,最大化 GPU 利用率。
@register Dispatch 模式
| 模式 | 含义 | 典型用途 |
|---|---|---|
Dispatch.DP_COMPUTE_PROTO | 数据按 DP 维度切分 | generate_sequences |
Dispatch.ONE_TO_ALL | 广播到所有 Worker | init_model |
16.4 目标函数与 Loss:GRPO、GSPO、DR-GRPO
本节涉及的 RL 基础概念(策略梯度、优势函数、GAE、PPO-Clip)在第 8 章有系统讲解。
带 KL 惩罚的 RL 目标
训练时关注的是 rewards curve,而不是 loss curve。PPO-Clip 的 loss 是一种保守的、低方差的代理目标(surrogate),其正负反映的是"当前 batch 中好动作占优还是坏动作占优"。
PPO-Clip 目标函数
其中
Clip 机制的直觉:
(好动作): 被上限 ,防止过度增强 (坏动作): 被下限 ,防止过度惩罚 不贡献梯度——它是一个不在计算图中的标量,来源于
Policy Loss 曲线的解读:
policy_loss < 0:好动作的正面影响超过坏动作,策略在改善policy_loss > 0:坏动作占优,策略在试错修正- 理想趋势:在 0 附近震荡,Actor 和 Critic 步调一致
Clip Fraction 监控:
- 理想范围:0.1~0.4
- 高 clip fraction + 高 KL:步子过猛(LR 大、epoch 多)
- 高 clip fraction 但 KL 不高:同一批数据被反复训练(epoch 太多/复用过度)
- 持续为 0:步子太小,学习停滞
Dual-Clip PPO

在
GRPO(Group Relative Policy Optimization)

GRPO 是 DeepSeek 提出的无 Critic 算法。
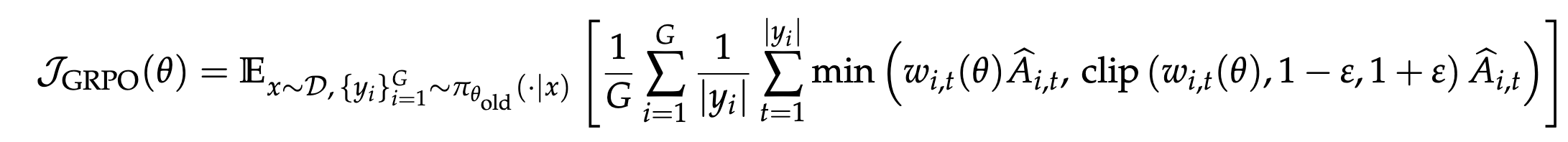
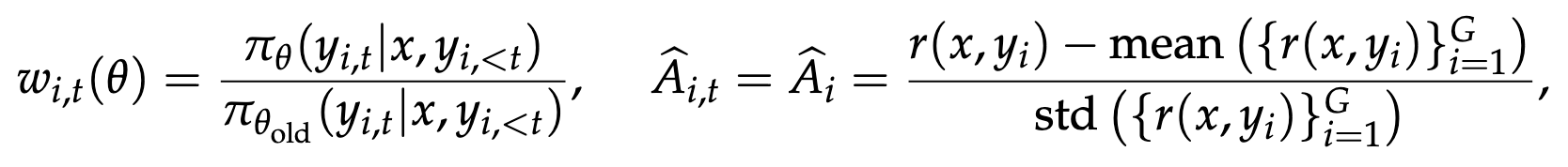
对每个 prompt
GRPO 的目标函数与 PPO-Clip 结构相同,区别仅在于优势估计从 Critic 的 token 级 GAE 替换为组内相对奖励(序列级常数)。其 token 级损失为:
其中
PPO vs. GRPO:PPO 比 GRPO 更精细,优势定义在 single step 上(基于每步的 Critic)。但 LLM 经过大规模 pretraining 后已足够稳定,初始策略本身就很好,GRPO 的序列级优势估计已经足够。在传统 RL 任务中,PPO 仍优于 GRPO。
GRPO 的 token-wise issue:
DeepSeek v3.2 改进:
- 去掉
: - 无偏 K3 估计的 KL 散度
- Off-policy 序列掩码:对 KL 散度过大的负样本进行掩码
GSPO(Geometric-mean Surrogate Policy Optimization)
GRPO 与 GSPO 的核心区别在于如何将 token 级 IS Ratio 聚合到序列级。GRPO 对 token 级 ratio 取算术平均,GSPO 改为几何平均:
注意:
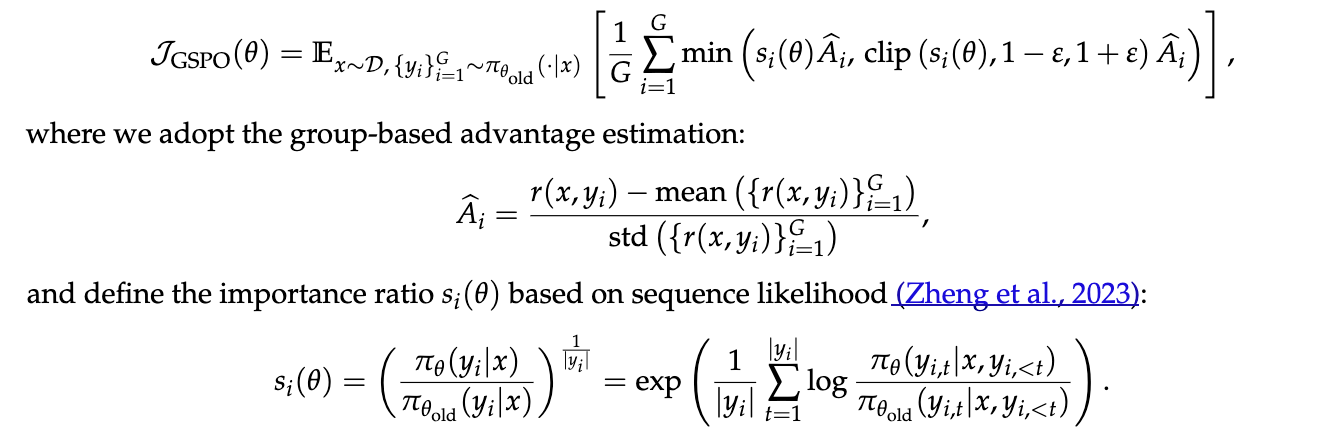
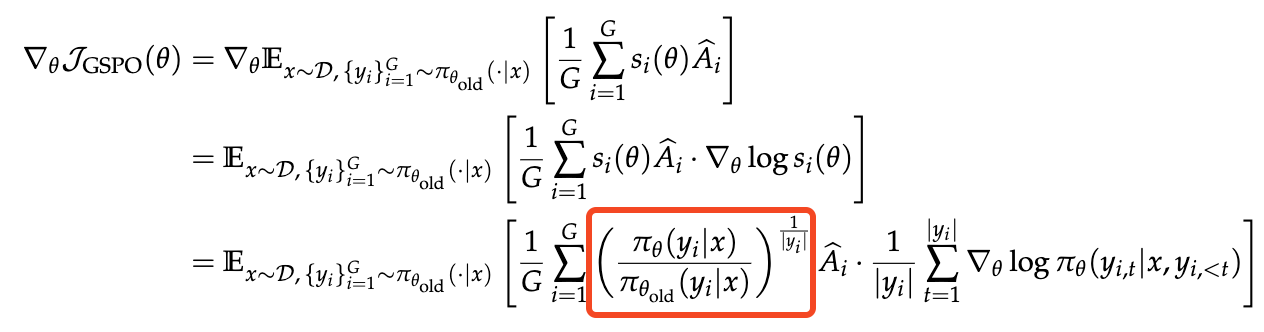
核心优势:在 GSPO 中,序列中所有 token 共享同一个序列级缩放因子
Stop-Gradient 实现技巧:
# verl/trainer/ppo/core_algos.py: compute_policy_loss_gspo
# 序列级几何平均 IS ratio(log 空间)
negative_approx_kl = log_prob - old_log_prob
seq_lengths = torch.sum(response_mask, dim=-1).clamp(min=1)
negative_approx_kl_seq = torch.sum(negative_approx_kl * response_mask, dim=-1) / seq_lengths
# 关键:stop-gradient 分离
# log(s_{i,t}(θ)) = sg[log(s_i(θ))] + log_prob - sg[log_prob]
log_seq_importance_ratio = (log_prob - log_prob.detach()
+ negative_approx_kl_seq.detach().unsqueeze(-1))negative_approx_kl_seq.detach():提供更新的"大小/幅度",不影响梯度方向log_prob - log_prob.detach():数值为 0(不影响前向),但保留梯度,提供更新的"方向"
为什么需要 Stop-Gradient:直接实现 GSPO 目标时,
将
verl 中已注册的损失函数
@register_policy_loss("vanilla") # 标准 PPO
@register_policy_loss("gpg") # Group Policy Gradient
@register_policy_loss("kl_cov") # KL 协方差
@register_policy_loss("clip_cov") # Clip 协方差
@register_policy_loss("geo_mean") # 几何平均变体
@register_policy_loss("gspo") # GSPO通过配置 actor.policy_loss.loss_mode 切换。自定义 Loss 只需在 core_algos.py 中用 @register_policy_loss 注册。
PPO 中 Actor 与 Critic 的关系

- Critic 网络提供 token 级别的价值
- Reward Model 通常只在序列最后一个 token 处有非零值
- Token 级奖励(含 KL 惩罚):
- TD error:
- GAE:
# ray_trainer.py, fit
with marked_timer("old_log_prob", timing_raw, color="blue"):
old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)熵与 KL Loss
Entropy 计算:
def entropy_from_logits(logits: torch.Tensor):
pd = torch.nn.functional.softmax(logits, dim=-1)
entropy = torch.logsumexp(logits, dim=-1) - torch.sum(pd * logits, dim=-1)
return entropy # [batch, seq_len],token 粒度Entropy 也需要经过 loss agg。actor.entropy_coeff 默认为 0.0。
KL Loss:使用 K3 近似估计(参考 http://joschu.net/blog/kl-approx.html),`policy_loss = policy_loss + kl_loss * kl_loss_coef`。
16.5 Aggregated Loss 与 Tinker
Aggregated Loss 的设计动机与 Tinker 框架对 token-level 梯度的精细控制。
损失聚合模式
设损失矩阵
| 模式 | 公式 | 推荐场景 |
|---|---|---|
token-mean | DAPO(推荐) | |
seq-mean-token-mean | 原始 GRPO 论文 | |
seq-mean-token-sum | 长序列时不稳定 | |
seq-mean-token-sum-norm | DrGRPO |
序列长度偏差问题

Implementation + data > algorithm
Policy Gradient 的标准推导要求对所有 token 的 log prob 求和(来自概率的链式分解
Vanilla GRPO 的问题:除以序列长度
一个案例说明:
- 序列 A:长度 20,总奖励
,平均 - 序列 B:长度 2,总奖励
,平均 - 正确逻辑下 A 远优于 B;但按平均奖励来看,模型会偏好 B
Tinker
Tinker 框架在 Loss 设计上提供了更多实验选项,可参考 https://tinker-docs.thinkingmachines.ai/losses。
16.6 Off-policy Mismatch 与缓解策略
Off-policy Mismatch 的根因分析与 Importance Sampling 修正策略。
重要性采样的本质
Objective (loss) vs. Gradient:理解 IS Ratio 需要区分目标函数和梯度。
Policy Gradient 的原始目标是最大化期望回报:
对其求梯度后才出现
当用
IS Ratio 的三重身份:
- 修正分布差异:保证用旧数据估计新策略梯度的无偏性
- 梯度缩放系数:决定梯度下降时在某方向上推多大劲
- 信任区域边界:
表示新策略更倾向该动作, 反之
Mismatch 问题
在 vLLM 与 FSDP 混合部署时,真正的 Behavior Policy 是 vLLM(
一个直观案例:
- vLLM 认为"好"的概率是 90%(0.9),因此容易采样到
- Actor 重算时得到 10%(0.1)
- 错误做法:
- 正确做法:
verl 的缓解方案
verl 通过 RolloutCorrectionConfig 提供两种模式:
Bypass Mode(旁路模式)——直接将
优点:简单直接,理论上无偏。缺点:信任域约束变成了针对
Decoupled Mode(解耦模式)——保留
展开后约化为
批内陈旧(Batch-internal Staleness)
同一 batch 多轮 PPO 更新还会导致另一种 off-policy:ppo_epochs / mini-batch 迭代偏移,后续更新天然更 off-policy。
16.7 verl Agent Loop
verl 对 Tool-augmented RL 的支持:Agent Loop 中工具调用与奖励计算的集成。
问题背景
单轮 RL 中,一个 Rollout 就是一次"问-答"。Agentic RL 中,Agent 需要:生成思考 -> 调用工具 -> 接收反馈 -> 继续推理,直到任务完成。这种多轮交互使得不同样本的轨迹长度差异巨大(Straggler 问题),同步 Batching 效率极低。
架构全景
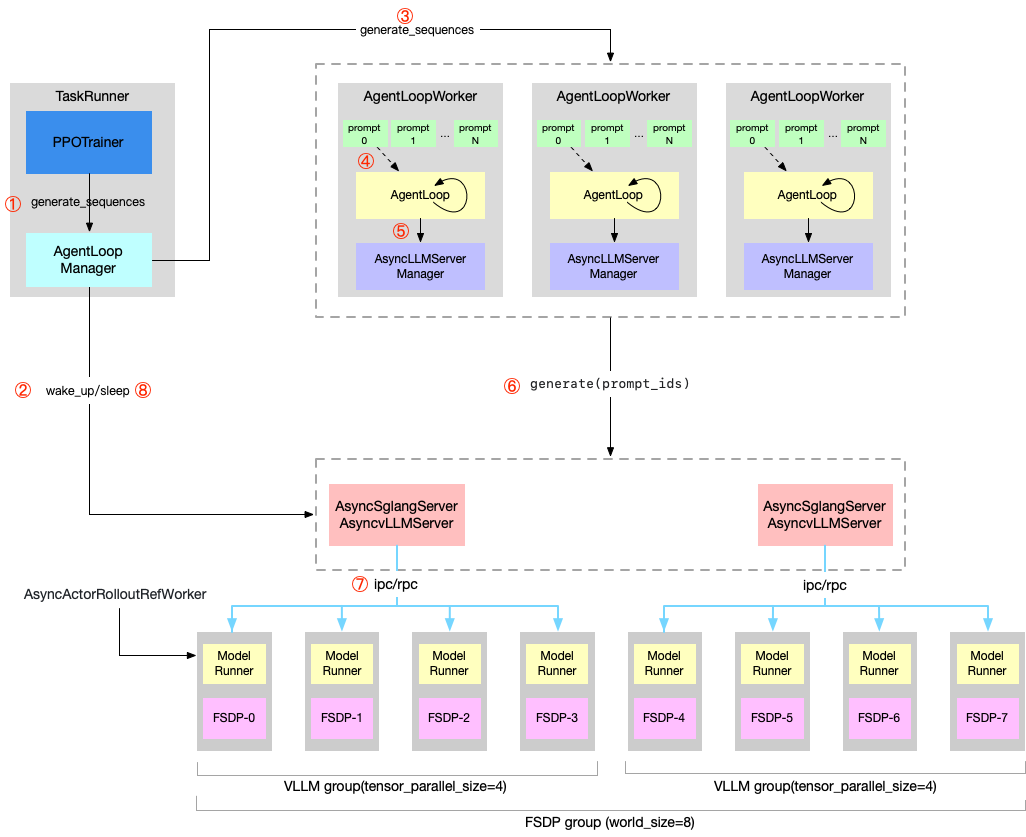
四层架构
RayPPOTrainer
└── AgentLoopManager (控制层:任务分发 + vLLM 服务管理)
├── AsyncLLMServerManager (服务层:负载均衡 + Sticky Session)
│ ├── vLLMReplica #0 (GPU 推理服务 replica)
│ ├── vLLMReplica #1
│ └── ...
└── AgentLoopWorker[i] (逻辑层:CPU 上的 Agent 状态机)
└── ToolAgentLoop (状态机:PENDING → GENERATING → PROCESSING_TOOLS → TERMINATED)AgentLoop 只关注"怎么聊"/调用工具(逻辑),Worker 只关注"怎么调度"(并发),ServerManager 只关注"怎么生成"(算力),三者互不干扰。
GPU 配置与 Replica 数
例如 16 GPU 集群,TP=4, DP=1, PP=1 -> 4 个独立的 LLM Server replica。
AgentData 状态容器
AgentData 在整个状态机生命周期中维护轨迹的完整状态:
@dataclass
class AgentData:
prompt_ids: list[int] = field(default_factory=list) # 不断追加的 token 序列
response_mask: list[int] = field(default_factory=list) # 标记 LLM 生成(1) vs 工具返回(0)
response_logprobs: list[float] = field(default_factory=list)
# 中间奖励
turn_scores: list[float] = field(default_factory=list) # 每轮 interaction 的 reward
tool_rewards: list[float] = field(default_factory=list) # 每次工具调用的 reward
# 计数器
user_turns: int = 0
assistant_turns: int = 0AgentLoopOutput
状态机运行结束后返回 AgentLoopOutput,包含完整轨迹信息:
class AgentLoopOutput(BaseModel):
prompt_ids: list[int] # Prompt token IDs
response_ids: list[int] # Response token IDs(含 LLM 生成 + 工具返回)
response_mask: list[int] # 1=LLM 生成, 0=工具返回
response_logprobs: Optional[list[float]] = None
reward_score: Optional[float] = None # 轨迹奖励
num_turns: int = 0 # 对话轮数(user + assistant + tool)
metrics: AgentLoopMetrics # 性能指标Agent 状态机
state = AgentState.PENDING
while state != AgentState.TERMINATED:
if state == AgentState.PENDING:
state = await self._handle_pending_state(...) # 初始化 prompt_ids
elif state == AgentState.GENERATING:
state = await self._handle_generating_state(...) # 调用 LLM,解析 tool_calls
elif state == AgentState.PROCESSING_TOOLS:
state = await self._handle_processing_tools_state(...) # 并行执行工具
elif state == AgentState.INTERACTING:
state = await self._handle_interacting_state(...) # 环境/用户反馈状态转换规则:
| 状态 | 处理函数 | 输出状态 |
|---|---|---|
| PENDING | _handle_pending_state | -> GENERATING |
| GENERATING | _handle_generating_state | -> PROCESSING_TOOLS / INTERACTING / TERMINATED |
| PROCESSING_TOOLS | _handle_processing_tools_state | -> GENERATING / TERMINATED(上下文超长) |
| INTERACTING | _handle_interacting_state | -> GENERATING / TERMINATED(should_terminate=True) |
终止条件:完成任务、达到最大轮数(max_turns)、达到长度限制。
INTERACTING 状态:当模型未调用工具且配置了交互环境(interaction 模拟器)时进入此状态。环境/用户模拟器根据当前轨迹返回反馈:
async def generate_response(self, instance_id, messages, **kwargs):
reward = await self.calculate_score(instance_id)
if reward == 1.0: # 答对了
response = "Your response is correct!"
should_terminate_sequence = True # 终止
else:
response = "Your response is incorrect! You need to reflect..."
should_terminate_sequence = False # 继续
return should_terminate_sequence, response, reward, {}AsyncLLMServerManager 负载均衡
class AsyncLLMServerManager:
def _choose_server(self, request_id: str):
# 1. Sticky Session:同一 trajectory 路由到同一 server
if request_id in self.request_id_to_server:
return self.request_id_to_server[request_id]
# 2. 最少请求数负载均衡(Min-Heap)
server = self.weighted_serveres[0][1][1]
heapq.heapreplace(...)
self.request_id_to_server[request_id] = server # LRU cache
return serverSticky Session 保证同一 trajectory 的多轮对话路由到同一 vLLM replica,复用 KV Cache。request_id_to_server 使用 LRUCache(maxsize=10000) 实现,当活跃 trajectory 数量超过上限时,最早的映射被淘汰;被淘汰的 trajectory 如果继续请求,会重新分配 server(但推理引擎内部的 KV Cache 也是 LRU 淘汰,影响不大)。
异步并发的三个层次
# 层次 1:Worker 内部,batch 中每个样本并发
tasks = [asyncio.create_task(self._run_agent_loop(...)) for i in range(len(batch))]
outputs = await asyncio.gather(*tasks) # 64 个 trajectory 并发
# 层次 2:每轮工具调用并发
responses = await asyncio.gather(*[self._call_tool(tc)
for tc in tool_calls[:max_parallel_calls]])
# 层次 3:vLLM Continuous Batching
# 快 trajectory 立即发起下一轮请求,无需等慢 trajectorySync vs. Async 的本质区别:Sync 模式把"一批人"绑在一起——llm.generate(batch) 必须等所有样本生成完,工具执行也必须全部完成才能进入下一轮。Async 模式把"每个人"拆开——每个 Agent 在自己的独立世界里跑循环,互不阻塞。
Async Rollout 的双层协作:
- 客户端层面(asyncio):CPU 上非阻塞地发射请求,并发处理工具调用、Prompt 拼接等业务逻辑,快速产生新的 Request
- 服务端层面(Continuous Batching):GPU 上利用 vLLM 的 Continuous Batching,见缝插针地执行请求——快 trajectory 完成后立即腾出位置给新请求,消灭同步等待带来的算力空窗期
传统 Batching:
Batch 1: [req1, req2, req3, req4] -> 全部完成 -> 输出
Batch 2: [req5, req6, req7, req8] -> 全部完成 -> 输出
Continuous Batching:
t0: [req1, req2, req3, req4] 开始
t1: req1 完成 -> [req2, req3, req4, req5] <- req5 立即插入
t2: req3 完成 -> [req2, req4, req5, req6] <- req6 立即插入Response Mask
工具返回的 Observation token 不参与 policy gradient 计算:
# tool_agent_loop.py
agent_data.response_mask += [1] * len(llm_response_ids) # LLM 生成: mask=1
agent_data.response_mask += [0] * len(tool_response_ids) # Tool 返回: mask=0Token-in Token-out 原则
几乎所有 Agent 框架(LangGraph、CrewAI、LlamaIndex)都使用 Chat Completion API,以 messages 维护对话历史。但 verl 发现:
这种不一致对 serving 影响不大,但对 RL 训练是致命的——它导致轨迹偏离策略模型分布。verl 实测发现对最终 messages 做 apply_chat_template 会导致 PPO 训练不收敛。因此 verl 采用 token in / token out 方式,始终维护 token ID 序列。
RolloutReplica 注册与实例化
AsyncLLMServerManager 的 server 通过注册表模式选择后端:
# verl/workers/rollout/replica.py
RolloutReplicaRegistry.register("vllm", _load_vllm)
RolloutReplicaRegistry.register("sglang", _load_sglang)实例化流程:AgentLoopManager._initialize_llm_servers 根据 rollout.name 配置选择 Replica 类,创建 num_replicas 个实例,将 server_handles 注入 AsyncLLMServerManager,再传递给各 AgentLoopWorker。Worker 在运行 AgentLoop 时注入 server_manager、tokenizer 等基础设施。
数据流汇总:DataProto(Batch) -> Manager 切分 -> Worker 并发 -> AgentLoop 多轮交互 -> AgentLoopOutput(含完整轨迹) -> Worker Pad 成 Tensor -> Manager 拼合 -> 返回 DataProto。
奖励计算与时机
在 Async 模式下,Reward 的计算被前置到 Rollout 阶段内部完成(而非由 Trainer 单独计算),减少数据传递开销。
16.8 Fully Async 训练
Fully Async 训练模式下 Rollout 与 Training 的并行化架构。
动机
在 16.7 节的 Agent Loop 中,虽然 Rollout 阶段内部已经实现了异步并发,但 Rollout 与 Training 之间仍然是严格串行的:Rollout 完成全部轨迹生成后,才启动 Training 进行梯度更新;Training 完成后,才启动下一轮 Rollout。在大规模 Agent 任务中,Rollout 的耗时往往远长于 Training(工具调用、多轮交互导致延迟不可控),这意味着 Training 所在的 GPU 在 Rollout 阶段处于空闲状态,资源利用率低下。
与同步训练的架构差异
同步模式(标准 PPO):
Rollout_k -> Training_k -> Rollout_{k+1} -> Training_{k+1} -> ...
[GPU: 推理] [GPU: 训练] [GPU: 推理] [GPU: 训练]Training 必须等 Rollout 生成完整 batch 的轨迹后才能启动,GPU 在两个阶段之间存在"气泡"。
Fully Async 模式(recipe/fully_async_policy):
Rollout: |---R_k---|---R_{k+1}---|---R_{k+2}---|
Training: |--T_k--|---T_{k+1}--|---T_{k+2}--|Rollout 和 Training 在不同的 GPU 资源池上并行执行。当 Rollout_k 生成的轨迹就绪后,Training_k 立即开始;与此同时 Rollout_{k+1} 已经在用当前最新的策略参数启动下一批生成。两者流水线化,消除了等待气泡。
实现要点
- 资源池分离:Rollout Worker 和 Training Worker 分配到不同的 GPU 资源池,不再共享 GPU(与 Hybrid Colocate 不同)。这牺牲了 GPU 复用率,但换来了流水线并行。
- 参数同步:Training 每完成一步,将更新后的参数推送给 Rollout 引擎。Rollout 使用最新可用的参数启动下一批生成,而非严格等待当前 Training 完成。
- Off-policy 程度加深:由于 Rollout 使用的参数可能落后于 Training 正在优化的参数(间隔 1 步或更多),Fully Async 天然引入了更强的 off-policy 特性。需要更依赖 Clip 机制和 KL 惩罚来约束策略偏离(参见第 14 章关于分布式训练中参数同步延迟的讨论)。
适用场景
- 长 Rollout 任务:Agentic RL 中工具调用链路长、环境交互耗时大,Rollout 耗时远超 Training,Fully Async 可显著提升吞吐。
- 大规模集群:GPU 资源充足时,用额外 GPU 跑 Rollout 来换取整体训练速度的提升是合理的 trade-off。
- 对 off-policy 容忍度高的算法:GRPO/DAPO 等序列级优势估计算法对轻微的参数延迟较为鲁棒。
详见 https://verl.readthedocs.io/en/latest/advance/fully_async.html
16.9 verl 中的 Ray 使用
verl 中 Ray 的使用模式:资源分配、Worker 管理与常见问题排查。
Ray 基础
# @ray.remote 修饰函数 -> Ray Task(无状态,并行)
@ray.remote
def slow_square(x):
return x * x, os.getpid()
# @ray.remote 修饰类 -> Ray Actor(有状态,长活服务)
@ray.remote
class Worker:
...核心概念:
ref = f.remote(x):异步提交任务,返回ObjectRef(Future)ray.get(ref):取回结果- 把
ObjectRef作为参数传给下游任务,Ray 自动识别拓扑顺序,构建 DAG
Ray 在 verl 中的角色
- WorkerGroup:每个 Worker 是一个 Ray Actor,拥有独立 GPU
- AgentLoopWorker:调度到 CPU 节点的 Ray Actor
- AsyncLLMServerManager:持有一组 server handles(Ray Actor 句柄)
- TokenBucketWorker:全局限流器,Ray Named Actor 单例
- ExecutionWorker pool:工具执行池,Ray Actor with
max_concurrency
ray.wait 完成即消费
refs = [preprocess.remote(bid, arr) for bid, arr in batches.items()]
remaining = set(refs)
while remaining:
done, pending = ray.wait(list(remaining), num_returns=1)
remaining -= set(done)
out = ray.get(done[0])
# 处理结果Map-Reduce 示例
# Map 阶段(并行)
parts = [map_count.remote(t) for t in texts]
# Reduce 阶段(树形合并,依赖于前序结果的 ObjectRef)
while len(parts) > 1:
nxt = []
for i in range(0, len(parts), 2):
if i+1 < len(parts):
nxt.append(reduce_merge.remote(parts[i], parts[i+1]))
else:
nxt.append(parts[i])
parts = nxt16.10 Tokenizer 处理
Tokenizer 在 RL 训练中的特殊处理:Chat Template、特殊 token 与 padding 策略。
Encode-Decode 不可逆性
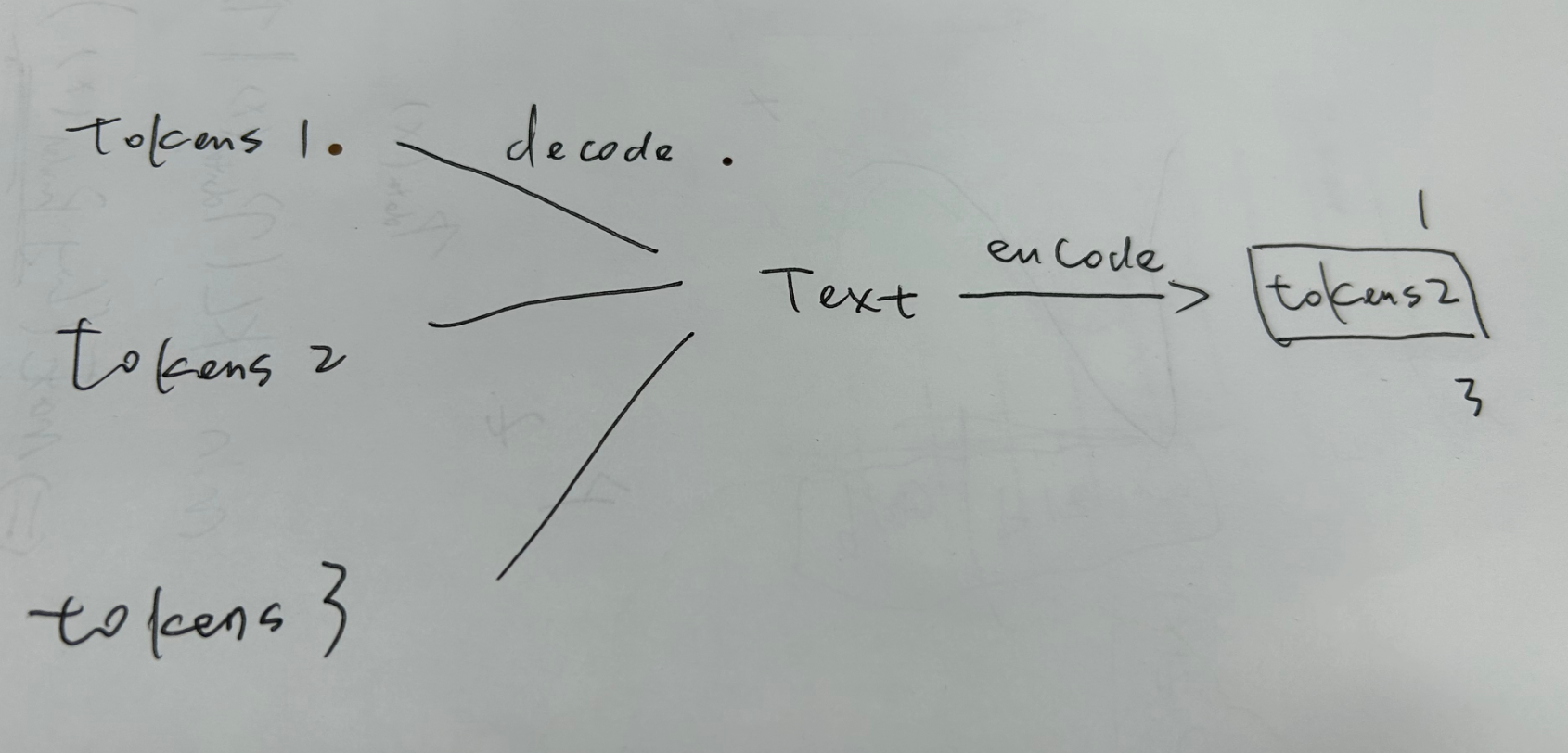
关键事实:D(E(text)) = text,但 E(D(token_ids)) != token_ids。
T = AutoTokenizer.from_pretrained('Qwen/Qwen2.5-7B-Instruct')
# <think> 有两种 tokenization:
T.decode([13708, 766, 29]) # ['<th', 'ink', '>'] -> '<think>'
T.decode([27, 26865, 29]) # ['<', 'think', '>'] -> '<think>'
# 但 encode 只会产生一种(贪心最长匹配):
T.encode('<think>') # [13708, 766, 29]
T.encode(T.decode([27, 26865, 29])) # [13708, 766, 29] != [27, 26865, 29]生成时模型每步从整个词表里挑一个 token,可能依次挑出 <、think、> 这条"非规范"路径。但 encode 会按贪心/最长匹配走另一条路径。这对 RL 训练的影响:在计算 IS Ratio 时,如果 token_ids 不一致,
Qwen3 的 Thinking Token
<think>/</think>:special tokens/no_think//think:软开关,且非 special tokens(语义指令,普通文本)
Vocabulary Size 差异
tok = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
cfg = AutoConfig.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
print(tok.vocab_size) # 151643
print(cfg.vocab_size) # 152064 (= 297 * 512,对齐到 512 倍数)填充区间 [tok.vocab_size, cfg.vocab_size) 中的 token 在 embedding 表中有权重但不会被 tokenizer 产生。
16.11 ReTool:工具增强 RL
ReTool 在 verl 中的实现:工具调用的 Reward 设计与多轮交互训练。
总览
ReTool 是 verl 上实现的工具增强 RL 训练 recipe,核心是"冷启动 SFT + RL with Tool Integration"两阶段流水线。目前主要支持 Code Interpreter(代码执行器)。
交错生成格式
:自然语言推理步骤(Thought) :代码片段(Action, <code>...</code>):执行器反馈(Observation, <interpreter>...</interpreter>)
冷启动 SFT
将普通数学推理数据
- 收集 OpenThoughts 等高质量 Text-based CoT 数据
- 使用模板自动将手动计算步骤替换为 Python 代码块
- 双重验证:格式验证(语法正确、标签闭合)+ 答案验证(与 Ground Truth 一致)
2000 条高质量 SFT 数据就足够(Qwen2.5-32B-Instruct)。
MultiTurnSFT Loss Mask:只对 Assistant 的输出计算 Loss(loss_mask=1),System/User/Tool 消息被掩码。Assistant 的 reasoning、tool_call(name + params)、<|im_end|> 都计算 loss。
RL 阶段
# Algorithm: ReTool Training Pipeline
for epoch in range(MAX_EPOCHS):
prompts = sample(Data)
trajectories = []
while not done:
tokens = Policy.generate()
if "</code>" in tokens:
result = Sandbox.exec(tokens.code)
tokens += f"<interpreter>{result}</interpreter>"
rewards = compute_outcome_reward(trajectories)
Policy = PPO_Update(Policy, rewards)奖励函数
对于错误答案,更多工具调用尝试(更大的
奖励放置
Reward 放在 response 的最后一个有效 token 位置,整个 trajectory 前面的 token 位置 reward 均为 0:
# naive.py
reward_tensor[i, valid_response_length - 1] = reward运行配置
actor_rollout_ref.rollout.mode: async
actor_rollout_ref.rollout.multi_turn.format: hermes
actor_rollout_ref.rollout.multi_turn.tool_config_path: recipe/retool/sandbox_fusion_tool_config.yamlsandbox_fusion_tool_config.yaml 中指定沙箱 URL(sandbox_fusion_url: "http://localhost:8080/run_code")及 num_workers、rate_limit 参数。
CustomSandboxFusionTool 实现
CustomSandboxFusionTool 继承自 SandboxFusionTool(BaseTool),重写了 execute 方法,在调用沙箱前对代码做两步预处理:
预处理 1:Markdown 代码块提取——模型生成的代码常包裹在 Markdown fenced block 中(如 ```python ... ```),CustomSandboxFusionTool 会自动提取其中的纯代码内容,确保发送到沙箱的是可直接执行的 Python 代码。
预处理 2:自动补 print(...)——沙箱执行服务依赖 stdout 返回结果。如果模型生成的代码只做了计算而没有 print,沙箱将返回空结果。因此 execute 方法逆序遍历代码行,找到最后一行非空行,如果该行不以 print 开头,则强制将其包裹为 print(...)。
预处理后的代码通过 ExecutionWorker 池(Ray Actor with max_concurrency)投递到沙箱执行。
SandboxFusion 执行环境
# 部署
docker run -it -p 8080:8080 volcengine/sandbox-fusion:server-20250609
# 测试
curl 'http://localhost:8080/run_code' \
-H 'Content-Type: application/json' \
-d '{"code": "print(42)", "language": "python"}'SandboxFusion 充当 Code Interpreter 后端,接收 HTTP POST 请求并返回 run_result(含 stdout/stderr/return_code)。
并发限流架构
PPO step -> rollout.n=16 条轨迹
-> AgentLoopWorker(num_workers=8)
-> ToolAgentLoop(per-sample 实例)
-> CustomSandboxFusionTool
-> ExecutionWorker pool(num_workers=128)
-> 全局 TokenBucketWorker(rate_limit=128) <- 保护沙箱
-> HTTP POST to /run_code各层的并发控制职责:
| 层 | 参数 | 作用 |
|---|---|---|
| AgentLoop 分片 | agent.num_workers(默认 8) | 把轨迹切块并发执行 |
| 单轨迹工具并发 | max_parallel_calls(默认 1) | 每条轨迹每轮最多并行几个工具 |
| 工具执行池 | num_workers(如 128) | ExecutionWorker Actor 的 max_concurrency |
| 全局限流 | rate_limit(如 128) | 集群内同时执行的 tool 请求硬上限 |
TokenBucketWorker 是 Ray Named Actor 单例,使用 threading.Semaphore(rate_limit) 实现全局并发上限控制。其命名虽含"Token Bucket",但实际实现的是并发上限控制器(Max Concurrency Limiter),确保同一时刻正在沙箱中执行的代码任务不超过 rate_limit 个:
@ray.remote(concurrency_groups={"acquire": 1, "release": 10})
class TokenBucketWorker:
def __init__(self, rate_limit):
self._semaphore = threading.Semaphore(rate_limit)
def acquire(self):
self._semaphore.acquire() # 名额为 0 时阻塞等待
def release(self):
self._semaphore.release() # 归还名额concurrency_groups 的设计确保 acquire(可能阻塞)不会占满 Ray Actor 的并发槽位而导致 release 饥饿。
ReTool 端到端执行流程
完整的一个 PPO Step 中 ReTool 的执行路径:
- Trainer 将 batch 扩展为
rollout.n份 - 调用
AgentLoopManager.generate_sequences - Manager
wake_uprollout replicas,按 worker 数切块分发 - 每个 Worker 对 chunk 内每个样本
asyncio.create_task并发运行 - 进入
ToolAgentLoop状态机:PENDING -> GENERATING -> PROCESSING_TOOLS -> ... - GENERATING 调
server_manager,从某个 vLLM replica 取 token 输出 format=hermes时,parser 从<tool_call>...</tool_call>提取函数调用- 进入 PROCESSING_TOOLS,每轮最多
max_parallel_calls个 tool call 并发执行 _call_tool调tool.create->tool.execute->tool.releaseCustomSandboxFusionTool.execute做代码清洗(提取 fenced python、补最后一行 print),投递到执行池- 执行池内部先
acquire全局 token(Semaphore 许可),再requests.post(/run_code) - 工具返回文本追加到消息,observation token 的
response_mask=0 - 满足终止条件后回传 Trainer(长度/轮数上限)
- 奖励函数
compute_score读取num_turns,错误答案时给多轮调工具正向修正
16.12 相关工作:DAPO
DAPO 算法的核心改进:动态采样、token-level 策略梯度与 overlong 过滤。
Dynamic Sampling(动态采样)
DAPO 过滤全奖励相同的 prompt:如果一个 prompt 的所有
# recipe/dapo/dapo_ray_trainer.py
kept_prompt_uids = [
uid for uid, std in prompt_uid2metric_std.items()
if std > 0 or len(prompt_uid2metric_vals[uid]) == 1
]实现上,RayDAPOTrainer(RayPPOTrainer) 只覆盖了 fit 函数。
Overlong Penalty
当
DAPO 推荐配置
- Loss 聚合:
token-mean(对 batch 中所有 token 平等对待) - Loss mode:与 GRPO 兼容,可直接在 verl 中配置
16.13 vLLM Rollout 与 CLI
vLLM Rollout 后端的配置参数与 verl CLI 命令行使用方法。
verl CLI
python3 -m verl.trainer.main_ppo \
--config-path=xx/verl/verl/trainer/config \
--config-name xx.yamlvLLM Rollout 调度细节
假设 5 个请求同时到来(max_num_batched_tokens=4096,long_prefill_token_threshold=1024):
| Step | 操作 | Token 计数 |
|---|---|---|
| 1 | R1 prefill 1024 + R2/R3/R4 各 200 + R5 prefill 1024 | 2648 |
| 2 | R1 prefill 1024 + R5 余 476 + R2/R3/R4 decode 3 | 1503 |
| 3 | R1 prefill 1024 + 4 个 decode | 1028 |
| ... | 继续混跑直到所有 prefill 完成 | ... |
vLLM 把 prefill 与 decode 放在迭代级混合批里(Chunked Prefill),最大化利用率。
FSDP Offload 配置
# Actor 训练阶段:不开 offload(GPU 够用时)
actor_rollout_ref.actor.fsdp_config.param_offload: False
actor_rollout_ref.actor.fsdp_config.optimizer_offload: False
# Ref Policy:常驻 CPU
actor_rollout_ref.ref.fsdp_config.param_offload: True注意区分:FSDP 内部的 offload(训练阶段每层动态搬运)与 Hybrid Colocate 的 sleep/wake_up(跨阶段资源调度)是两个不同层次的控制。
16.14 训练调参经验
RL 训练调参的实战经验:学习率、batch size、KL 系数与 reward 工程。
Batch Size 配置层次
Global Batch Size (data.train_batch_size=128)
x rollout.n=4
= 512 条 Responses(本 Global Step 的总轨迹数)
/ DP Size (e.g. 8)
= 每 DP Rank 64 条
/ actor.ppo_mini_batch_size=32 (prompts 级,实际 32*4=128 responses)
-> 4 次 Optimizer Step per Global Step
/ actor.ppo_micro_batch_size_per_gpu=2 (response 级)
-> Global micro-batch = 8*2=16
-> Gradient Accumulation Steps = 128/16 = 8Dynamic Batch Size
actor_rollout_ref.actor.use_dynamic_bsz: True
actor_rollout_ref.actor.ppo_max_token_len_per_gpu: 8192按 Token 总量而非序列数量切分 micro-batch。Loss 缩放因子动态调整:
其中
序列并行
序列并行(SP)与张量并行(TP)等分布式策略的原理与对比,参见第 14 章。
长序列训练时启用 SP(序列并行)主要用于节省显存,不加速训练:
data.max_length: 16384
ulysses_sequence_parallel_size: 4
use_remove_padding: trueLogits 是显存瓶颈:
显存分析(7B 模型)
| 组件 | 大小 | 备注 |
|---|---|---|
| 模型权重(BF16) | 7B * 2 = 14 GB | FSDP 4卡分片 -> 3.5 GB/卡 |
| AdamW Optimizer(FP32) | 7B * 4 * 2 / 4 = 14 GB/卡 | 一阶矩 + 二阶矩 |
| 梯度 | 7B * 4 / 4 = 7 GB/卡 | |
| 激活值 | 动态 | 取决于 micro_batch_size + gradient checkpointing |
精度注意事项
# 危险配置(不要加):
actor_rollout_ref.actor.fsdp_config.model_dtype=bfloat16
# 原因:会导致优化器也变成 BF16,损失 FP32 精度CPU vs. GPU OOM
- GPU OOM:
torch.cuda.OutOfMemoryError - CPU OOM:exit code -9(SIGKILL),由内核 OOM killer 触发
- Checkpoint 保存时有峰值 CPU 内存占用:params(14GB) + AdamW(56GB) 需要序列化
Grad Norm 监控
actor_rollout_ref.actor.grad_clip: 1.0Grad Norm 突然爆炸(NaN)通常由 IS Ratio 爆炸引起:
RL Collapse
训练崩溃的常见征兆与根因可参考 https://yingru.notion.site/When-Speed-Kills-Stability-271211a558b7808d8b12d403fd15edda ——核心论点是训练-推理 mismatch 是 RL collapse 的重要诱因。
常用监控指标
| 指标 | 含义 | 理想状态 |
|---|---|---|
reward | 平均奖励 | 稳定上升 |
kl_div | 与 ref policy 的 KL 散度 | 保持合理范围 |
clip_fraction | PPO Clip 触发比例 | 0.1~0.4 |
actor_entropy | 策略熵(生成多样性) | 不要过快下降 |
grad_norm | 梯度 L2 范数 | 无剧烈波动或 NaN |
response_len | 生成长度 | 不要崩塌到极短 |
timing_s/* | 各阶段耗时 | 关注瓶颈 |
SFT 训练经验
data.micro_batch_size_per_gpu真正影响显存- 4卡 7B,2000/32 * 6 epochs,约 1 小时可完成
- 每个 epoch 结束时 loss 会有一个陡降(新 epoch 开始数据重排)
- 每个 epoch 保存一个 checkpoint
Checkpoint 转换
# 新版 API
python -m verl.model_merger merge \
--backend fsdp \
--local_dir checkpoints/.../global_step_X/actor \
--target_dir /path/to/merged_hf_model
# 旧版 API
python scripts/legacy_model_merger.py merge \
--backend fsdp \
--local_dir /xxx/global_step_372 \
--target_dir /xxx/weights16.15 TRL 训练示例
TRL 框架的 GRPO/DPO/SFT 训练示例与关键配置说明。
TRL 与 verl 的定位对比
| 维度 | TRL(HuggingFace) | verl(ByteDance) |
|---|---|---|
| 目标用户 | 学术研究、快速原型 | 生产级、大规模训练 |
| 部署复杂度 | 低(pip install trl) | 中等(Ray + FSDP) |
| 扩展性 | 单机/小集群 | 大规模多机 |
| 推理引擎集成 | 有限 | 深度集成 vLLM/SGLang |
| 算法支持 | SFT/DPO/PPO/GRPO | PPO/GRPO/GSPO/DAPO |
官方示例
TRL 提供了丰富的 Notebook 示例:
SFT 微调(支持 QLoRA):
- Qwen3-VL-4B-Instruct 视觉语言模型微调:使用
SFTTrainer对 Qwen3 VL 多模态模型进行 SFT,演示了图像-文本对数据的处理流程,支持在 Colab 环境运行。关键配置包括max_seq_length和多模态 tokenizer 的初始化。 - Qwen3-14B with Unsloth 4-bit 量化:通过
unsloth/qwen3-14b-unsloth-bnb-4bit预量化模型,结合 LoRA/QLoRA 在单卡上完成 14B 模型的 SFT 微调。Unsloth 的 Triton kernel 加速使训练吞吐量提升约 2x,显存占用降低约 60%。
GRPO 强化学习:
- Qwen3-VL-4B-Instruct GRPO 训练:端到端演示视觉语言模型的 GRPO 训练,使用
GRPOTrainer替代 PPO,无需 Critic 网络。数据格式为 prompt + 多条采样轨迹 + 组内相对奖励,适合在有限 GPU 资源上验证 RLVR 流程。
Agent Training(工具调用):
- Tool Use Agent 微调:使用工具调用格式数据(function calling)进行 SFT,训练模型学习何时调用工具、如何构造工具参数。数据包含
tool_calls字段和tool_response反馈,适用于构建可调用外部 API 的 Agent。
代码示例参考:https://github.com/huggingface/trl/tree/main/examples/notebooks
适用场景
- 快速实验验证:单卡或少量 GPU,验证算法思路
- 视觉语言模型微调:原生支持多模态
- QLoRA + GRPO:在有限资源上进行 RL 训练
- 学术竞赛:结合 Unsloth 加速,适合 Kaggle/Colab 环境
16.16 Unsloth 资源
Unsloth 框架的资源汇总与高效训练方案。
Unsloth 通过手写 Triton kernel 实现训练/推理加速,与 bitsandbytes(QLoRA)深度集成:
- 将 Flash Attention Backward 融合进 Triton 内核,减少 HBM 读写
- 优化 Cross-Entropy Loss 计算,支持超大词表
- 典型使用:在 RTX GPU 或 Colab 上用 4-bit 量化模型做 RLVR
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/qwen3-14b-unsloth-bnb-4bit",
max_seq_length=2048,
load_in_4bit=True,
)
# 配合 TRL 的 GRPOTrainer 使用相关资源:
- NVIDIA + Unsloth RLVR Tutorial: https://www.youtube.com/watch?v=9t-BAjzBWj8
- RTX AI Garage Fine-Tuning: https://blogs.nvidia.com/blog/rtx-ai-garage-fine-tuning-unsloth-dgx-spark/
本章小结
本章系统覆盖了 verl 框架的核心设计、算法实现与工程实践:
verl 架构采用"单控制器(RayPPOTrainer)+ 多控制器(SPMD WorkerGroup)"模式,通过 DataProto 统一数据协议,Hybrid Engine 融合训练与推理。
Hybrid Colocate 通过 sleep/wake_up 在 Rollout(vLLM)和 Training(FSDP)之间分时复用 GPU 显存,存在短暂的切换峰值。
目标函数谱系:PPO-Clip -> Dual-Clip PPO -> GRPO(无 Critic,组内相对奖励)-> GSPO(几何平均 IS Ratio,stop-gradient 技巧)。损失聚合模式(
token-mean/seq-mean-token-mean等)对长 CoT 影响显著,seq-mean-token-mean会引入长度偏差。Off-policy Mismatch 来源于 vLLM 与 FSDP 的数值不一致以及批内多轮更新的陈旧性,可通过 Bypass/Decoupled 模式缓解。
AgentLoop 四层架构(Manager -> AsyncLLMServerManager -> Worker -> 状态机)支持多轮 Agentic RL;asyncio + Continuous Batching 解决 Straggler 问题;Token-in Token-out 原则保证训练-推理的 token 级一致性。
ReTool 展示了完整的工具增强训练流水线:冷启动 SFT(2000 条数据)-> RL with Code Interpreter;Response Mask 确保工具 Observation 不参与策略梯度;TokenBucketWorker 实现全局限流。
DAPO 通过动态采样和 Overlong 惩罚进一步稳定训练。
训练调参:理解 batch size 多层嵌套关系、Dynamic Batch Size、序列并行、显存分析、精度陷阱、Grad Norm 监控是稳定训练的基础。
TRL + Unsloth 提供轻量级替代方案,适合学术研究与快速原型,与 verl 的大规模生产定位互补。
延伸阅读
- verl 官方文档:https://verl.readthedocs.io/en/latest/
- verl 性能调优:https://verl.readthedocs.io/en/latest/perf/perf_tuning.html
- verl Agent Loop:https://verl.readthedocs.io/en/latest/advance/agent_loop.html
- verl Fully Async:https://verl.readthedocs.io/en/latest/advance/fully_async.html
- verl 配置参考:https://verl.readthedocs.io/en/latest/examples/config.html
- ReTool Recipe:https://github.com/verl-project/verl-recipe/tree/main/retool
- GSPO 论文:https://arxiv.org/pdf/2507.18071
- DAPO 文档:https://verl.readthedocs.io/en/latest/algo/dapo.html
- DrGRPO 文档:https://verl.readthedocs.io/en/latest/algo/grpo.html
- KL 近似估计:http://joschu.net/blog/kl-approx.html
- RL Collapse 分析:https://yingru.notion.site/When-Speed-Kills-Stability-271211a558b7808d8b12d403fd15edda
- TRL 官方示例:https://github.com/huggingface/trl/tree/main/examples/notebooks
- SandboxFusion:https://bytedance.github.io/SandboxFusion/
- Ray Debug Tutorial:https://verl.readthedocs.io/en/latest/start/ray_debug_tutorial.html