第 19 章:Agent 框架与工作流
"Context engineering is becoming a craft that agent builders should aim to master." — LangChain Blog
"An LLM Agent runs tools in a loop to achieve a goal." — Simon Willison
本章从一个根本问题出发:LLM 本身是无状态的纯函数
19.1 ReAct:推理与行动的交织
ReAct 将推理与行动交织为循环,奠定 LLM Agent 的基本交互范式。
核心思想
ReAct(Reasoning + Acting)由 Shunyu Yao 等人提出,初衷是将"提示词技巧"转换为"可维护的代理控制流"。传统 LLM 应用中,推理(CoT)和行动(工具调用)是分离的。ReAct 的贡献在于将二者交织成一个循环:
直觉:人类解决问题时,思考和行动是交替进行的——先想想该怎么做,做了之后看看结果,再决定下一步。ReAct 让 LLM 也具备这种能力。Shunyu Yao 在访谈中指出:"推理即泛化。语言 Agent 与传统 Agent 的本质区别在于它能够进行推理,而推理是实现泛化的关键。"
这一范式也启发了后来 OpenAI 等厂商在 API 层面推出的 function calling 能力。
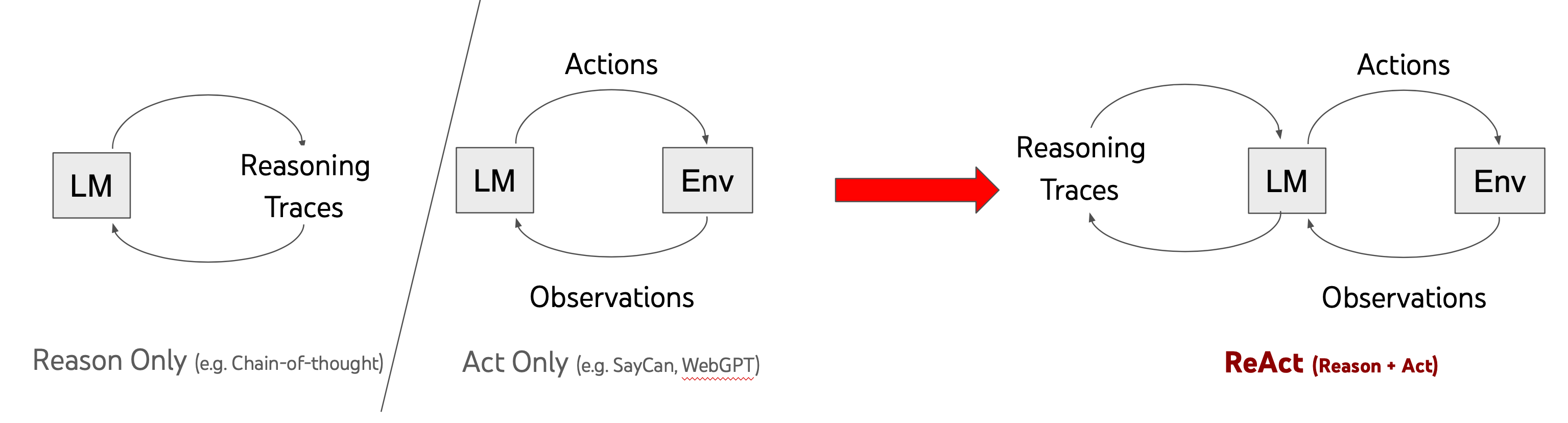
ReAct 的提示模板
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question这是一种高度通用的设计——thought(推理)、action(与环境交互)、observation(执行反馈)三元循环可以适配几乎所有需要工具调用的场景。
两种实现方式
LangChain AgentExecutor(传统方式):
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent
from langchain_community.tools.tavily_search import TavilySearchResults
tools = [TavilySearchResults(max_results=3)]
prompt = hub.pull("hwchase17/react")
llm = ChatOpenAI(model="gpt-4.1-nano")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
agent_executor.invoke({'input': 'what is the hometown of the current Australia open winner?'})解读:
AgentExecutor是一个简单的 while 循环,每次把 LLM 的输出解析为Action + Action Input,调用对应工具,将Observation追加到 prompt,再次调用 LLM,直到 LLM 输出Final Answer。
LangGraph create_react_agent(现代方式):
from langgraph.prebuilt import create_react_agent
agent = create_react_agent(model=llm, tools=tools)
response = agent.invoke({
"messages": [{"role": "user", "content": "your question"}]
})LangGraph 版本以 messages 列表为核心状态,支持多轮会话。消息类型依次为:human -> ai -> tool -> ai。底层是一个包含 model 节点和 tools 节点的有向图,通过条件边(虚边)决定是继续调用工具还是输出最终回答。
LangChain 1.0 的统一接口进一步简化了创建过程:
from langchain.agents import create_agent
react_agent = create_agent('openai:gpt-4.1-mini', tools=tools, name='react_demo')
results = react_agent.invoke({'messages': [{'role': 'user', 'content': '北京的天气?'}]})底层仍基于 LangGraph,自动处理工具调用的循环与状态管理。在 LangChain 1.0 中,Agent 被提升为"一等公民"。
19.2 Plan-and-Execute:显式规划与执行分离
将规划与执行显式分离:Planner 生成任务 DAG,Executor 逐步执行并支持动态重规划。
从 ReAct 到显式规划
ReAct 的 Thought-Action-Observation 循环对短程任务效果良好,但在复杂任务中存在局限:LLM 逐步推理时容易"走偏",缺乏对全局计划的显式管理。Plan-and-Execute 的核心思想是将规划与执行显式分离:
- 用一个强模型(如 GPT-4.1)做规划,生成步骤列表
- 用一个轻量模型(如 GPT-4.1-nano)做执行,逐步完成每个子任务
- 每个子任务执行完后,动态重新规划(replan)
直觉:这就像一个项目经理先列出 TODO 清单,然后指派执行人逐项完成,每完成一项回来汇报,项目经理根据进展调整后续计划。
从 Anthropic 关于 Agent 的定义来看,显式的 plan-execute-replan 工作流只是一种 agentic workflow,尚未达到完全 autonomous agent 的水平,但胜在可控性、可靠性与可预测性。
状态设计
import operator
from typing import Annotated, List, Tuple
from typing_extensions import TypedDict
class PlanExecute(TypedDict):
input: str
plan: List[str]
past_steps: Annotated[List[Tuple], operator.add] # 累积追加
response: str解读:
Annotated[List[Tuple], operator.add]是 LangGraph 的 Reducer 机制。当多个节点更新同一个字段时,默认行为是覆盖,而使用operator.add作为 reducer 意味着每次更新是追加而非覆盖——这样past_steps会不断积累已完成步骤的记录。
Planner 与 Re-Planner
from pydantic import BaseModel, Field
class Plan(BaseModel):
"""Plan to follow in future"""
steps: List[str] = Field(
description="different steps to follow, should be in sorted order"
)
planner = planner_prompt | ChatOpenAI(
model="gpt-4.1", temperature=0
).with_structured_output(Plan)Re-Planner 的上下文至关重要,必须包含三要素:
- 原始用户目标(
input) - 原始计划(
plan) - 已完成步骤及其结果(
past_steps)
class Response(BaseModel):
"""Response to user."""
response: str
class Act(BaseModel):
"""Action to perform."""
action: Union[Response, Plan] = Field(
description="If you want to respond to user, use Response. "
"If you need to further use tools, use Plan."
)
replanner = replanner_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Act)解读:
Act是一个联合类型——Re-Planner 要么输出Response(任务完成,直接回复用户),要么输出新的Plan(还需继续执行)。这是一种优雅的"终止条件"设计。
Graph 定义与执行
from langgraph.graph import StateGraph, START, END
workflow = StateGraph(PlanExecute)
workflow.add_node("planner", plan_step)
workflow.add_node("agent", execute_step) # 内部包含一个 ReAct agent
workflow.add_node("replan", replan_step)
workflow.add_edge(START, "planner")
workflow.add_edge("planner", "agent")
workflow.add_edge("agent", "replan")
workflow.add_conditional_edges("replan", should_end, ["agent", END])
app = workflow.compile()执行流程示例:
planner -> plan: ['Identify the winner', 'Find the hometown']
agent -> past_steps: [('Identify...', 'Jannik Sinner')]
replan -> plan: ['Search for the hometown of Jannik Sinner.']
agent -> past_steps: [('Search...', 'San Candido, Italy')]
replan -> response: 'The hometown is San Candido, Italy.'注意 execute_step 内部本身就是一个完整的 ReAct agent,负责消化单个子任务。这体现了 Agent 设计的嵌套性:宏观层面是 Plan-Execute-Replan 循环,微观层面每个 execution step 内部是 ReAct 循环。
ReWOO 与 LLM Compiler
除了 Plan-and-Execute,还有两种减少冗余 LLM 调用的高效架构:
- ReWOO(Reasoning WithOut Observation):Planner 一次性生成完整计划,Solver 并行执行,减少多轮 Thought-Action-Observation 循环的 token 消耗
- LLM Compiler:借鉴编译器思想,将任务表示为 DAG(有向无环图),并发执行无依赖的子任务
这两种架构体现了从"顺序推理"到"并发调度"的演进方向。
19.3 LangGraph:以图建模控制流
以有向图建模 Agent 控制流:节点是计算单元,边是状态转移,支持条件分支与循环。
核心概念
LangGraph 将 Agent 的控制流建模为有向图(Graph),核心元素:
| 元素 | 说明 |
|---|---|
| Node(节点) | 执行单元:LLM 调用、工具执行或自定义函数 |
| Edge(边) | 普通边(固定转移)和条件边(动态路由) |
| State(状态) | 贯穿整个图的共享数据,每次节点执行后更新 |
条件边(虚边)是 LangGraph 的关键机制——它允许根据当前状态动态决定下一个节点走向。例如在 ReAct agent 中,model 节点的输出如果包含 tool_calls,则走向 tools 节点;否则走向 END。
LangGraph 1.0 与 Deep Agents
LangChain 1.0 将 Agent 升级为一等公民,同时推出了 Deep Agents 框架,借鉴深度学习的分层思想,通过**中间件(Middleware)**在 LLM 调用前后注入逻辑:
- before model:预处理输入,动态选择工具,修改请求
- after model:后处理输出,触发监控
- modify model request:埋点、钩子(hook)
内置中间件类型:
| 中间件 | 功能 |
|---|---|
| LLM Tool Selector | 动态选择当前步骤需要的工具子集 |
| To-do List | 自动维护任务清单,会触发 write_tool 调用 |
| FilesystemMiddleware | 超大工具结果自动落盘 |
FilesystemMiddleware 体现了 Context Engineering 的核心原则——当工具结果超过阈值(默认 20,000 token)时,将完整内容写入文件系统,只返回简短引用给 LLM:
"Tool result too large, the result of this tool call {tool_call_id}
was saved in the filesystem at this path: {file_path}
You can read the result from the filesystem by using the read_file tool,
but make sure to only read part of the result at a time. ..."调试与可视化
命名与追踪:
# 给 graph 起名,方便在 LangSmith 中定位(否则默认显示 "LangGraph")
app = graph.compile(name='planner')
# 给 chain 起名
summary_chain = (prompt_template | llm | StrOutputParser()).with_config(
{"run_name": "plan-summary"}
)LangSmith 集成:
export LANGSMITH_API_KEY=xx
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_PROJECT=learningLangGraph Studio 提供可视化调试界面:
pip install -U "langgraph-cli[inmem]"
langgraph dev # 自动跳转到可视化界面配置文件 langgraph.json:
{
"dependencies": ["."],
"graphs": {
"react_agent": "./graph.py:app"
},
"env": ".env"
}Studio 支持各节点 before/after 的 interrupts(断点)、Graph 视图与 Chat 视图,且后端代码修改可实时热重载。
19.4 工具系统与结构化输出
工具定义规范、结构化输出保证与 Pydantic Schema 在 Agent 系统中的实践。
工具三要素
Agent 的核心能力在于调用工具。工具(Tool)的本质是一个带有元信息的可调用对象,三要素:
- name:工具名称
- description:自然语言描述(会进入 LLM 的提示词或
tools字段) - parameters:JSON Schema 格式的参数定义
这三个要素直接影响 LLM 能否正确理解和调用工具。
三种构建方式
from langchain_core.tools import tool, Tool, StructuredTool
# 1. @tool 装饰器(单参 -> Tool,多参 -> StructuredTool)
@tool
def web_search(query: str) -> str:
"Search the web for a query."
return f"results for: {query}"
@tool
def crop_image(path: str, x: int, y: int, w: int, h: int) -> str:
"Crop an image given coordinates."
return f"cropped {path} at ({x},{y},{w},{h})"
# 2. 手动构造 Tool(单字符串输入的轻量场景)
sum_tool = Tool.from_function(
name="summarize",
description="Summarize long text into ~200 chars.",
func=summarize,
)
# 3. 手动构造 StructuredTool(需要明确 JSON Schema 和校验)
class ResizeInput(BaseModel):
path: str
width: int
height: int
resize_tool = StructuredTool.from_function(
func=resize_image,
name="resize_image",
description="Resize an image to given width/height.",
args_schema=ResizeInput,
)解读:
@tool装饰器是最常用的方式,它根据函数签名自动判断生成Tool(单参数)还是StructuredTool(多参数)。自动提取函数名作为name,docstring 作为description,类型注解生成 JSON Schema。
convert_to_openai_function 可以将任何工具定义转换为 OpenAI API 的标准格式:
from langchain_core.utils.function_calling import convert_to_openai_function
openai_fn = convert_to_openai_function(get_weather, strict=True)
# {'name': 'get_weather', 'description': '...', 'parameters': {...}, 'strict': True}ToolNode 是 LangGraph 中执行工具调用的标准节点:
from langgraph.prebuilt import ToolNode
tool_node = ToolNode(tools) # 作为 react graph 的执行节点结构化输出:with_structured_output
结构化输出让 LLM 的输出直接实例化为 Pydantic 对象,无需手动解析 JSON。在复杂 Agent workflow 中,这相当于模块之间的接口约定(SDD,Specification Driven Development)。
llm.with_structured_output(SomeModel)关键点——以下信息都会进入模型的提示(via function/tool calling API):
- Pydantic 类的名称
- Docstring
- 字段名称与 Field 描述
三种底层模式:
| 模式 | 校验强度 | 对应 API 字段 |
|---|---|---|
json_schema(默认) | 强校验,严格匹配 schema | response_format.type = "json_schema" |
function_calling | 把数据类实例化当做函数调用 | tools + tool_choice |
json_mode | 最宽松,仅要求合法 JSON | response_format.type = "json_object" |
注意事项:当 Pydantic 模型中包含
Dict[str, int]等复杂类型时,json_schema模式可能报 400 错误(invalid_json_schema)。一个可行方案是将其转为List[SomeModel]。
include_raw 选项可以同时拿到原始输出和解析结果:
structured_llm = llm.with_structured_output(Joke, include_raw=True)
result = structured_llm.invoke("Tell me a joke about cats")
# result: {'raw': ..., 'parsed': Joke(...), 'parsing_error': None}bind_tools 是 create_react_agent 内部使用的底层机制:
# create_react_agent 内部等价于
llm_with_tools = llm.bind_tools(tools)
# 本质上在 API 请求中填入 tools 字段Pydantic 基础
Pydantic 是整个工具系统和结构化输出的基石:
from pydantic import BaseModel, Field
class Item(BaseModel):
id: int
name: str
price: float = Field(gt=0) # 校验:必须 > 0
tags: List[str] = []
created_at: datetime # 自动把 ISO 字符串转 datetime
# Field(...) 中的 ... (Ellipsis) 表示"此字段必填,没有默认值"
# 从 JSON 字符串创建
order = Order.model_validate_json(json_str)
# 序列化输出(支持别名)
print(order.model_dump_json(indent=2, by_alias=True))19.5 Function Calling 与工具调用协议
Function Calling 的协议标准化:从 OpenAI 格式到 Hermes 开源方案。
工作原理
LLM 本身并不直接执行代码或调用 API,而是生成结构化的指令,由外部的编排层(Orchestration,如 MCP client)来解析和执行。
Function Calling 的消息流:
// 1. LLM 输出 tool_calls(可以是多个,支持并行调用)
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "search_web",
"arguments": "{\"query\": \"LLM orchestration\"}"
}
},
{
"id": "call_def456",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"city\": \"San Francisco\"}"
}
}
]
}
// 2. 编排层执行工具,将结果以 tool 角色追加到 messages
[
{"role": "tool", "tool_call_id": "call_abc123", "content": "{...}"},
{"role": "tool", "tool_call_id": "call_def456", "content": "{...}"}
]
// 3. LLM 根据工具结果生成最终回答
{
"role": "assistant",
"content": "巴黎今天天气晴朗,气温为22摄氏度..."
}直觉:这个过程就像一个管理者(编排层)和一个顾问(LLM)在合作。顾问说"帮我查一下天气和新闻",管理者去执行查询并把结果汇报回来,然后顾问综合信息给出最终建议。
Advanced Tool Use:从 ReAct 到 Code as Reasoning
Anthropic 的技术博客提出了 Agent 工具使用的进阶理念:
按需加载工具(On-Demand Tool Loading):Agent 应该动态发现和加载工具,只保留与当前任务相关的工具。这一原则的工程动机在于——当可用工具数量庞大时,将所有工具描述注入上下文会浪费 token 并分散模型注意力。正确的做法是让 Agent 先理解任务意图,再按需检索和加载对应工具。LangChain 1.0 的 LLM Tool Selector 中间件正是这一理念的框架级实现。
Code as Reasoning(代码即推理):让模型写代码不仅是为了生成软件,而是作为一种解决问题的手段。ReAct 模式的 Thought-Action-Observation 循环在面对复杂、重复性数据处理任务时,效率极低且成本极高——每步都要停下来思考。Code as Reasoning 的核心洞察是:代码天然适合处理逻辑分支、大量数据和精确计算,弥补了 LLM 纯文本推理的短板。
System 1 vs System 2 + Tools 案例对比:面对需要处理大量数据的任务,"直觉型"模型(System 1,如 Sonnet 4.5)试图靠语感和记忆解决,把所有数据塞进上下文窗口——记忆有限,计算不准,每一步都要停下来思考,极其昂贵。而"逻辑型"模型(System 2 + Tools,如 Opus 4.5)退后一步,不再自己做苦力,而是构建 Python 脚本来处理——它不需要"看"数据,只需要知道数据的"结构"。优势:无限的精确度(依托 CPU),极低的成本(本地运行),极快的速度。这一对比揭示了 Agent 工具使用的核心范式转换:从"模型亲自计算"到"模型编排计算"。
19.6 MCP:模型上下文协议
MCP 协议将工具能力从应用解耦:统一的 Tool/Resource/Prompt 三层抽象。
定位与架构
MCP(Model Context Protocol)是 Anthropic 发布的开放标准。它定义了 AI 应用(Client)和外部工具(Server)之间**"说什么"(消息格式和内容)的协议,而 STDIO 和 HTTP 则是"怎么说"**(消息传输通道)。
MCP 的核心价值在于跨客户端、跨模型的通用性:
- 跨 MCP Client:Cline / Cursor / Gemini-CLI / Claude Code / ChatWise
- 跨 LLM:DeepSeek / Gemini / OpenAI / Anthropic
传输方式
| 传输方式 | 配置关键字 | 场景 |
|---|---|---|
| STDIO | command -> StdioClientTransport | 本地进程间通信,最常用 |
| SSE | url -> SSEClientTransport | 远程网络通信,服务器单向推送 |
| Streamable HTTP | httpUrl -> StreamableHTTPClientTransport | 双向流式 HTTP |
启动方式包括 uvx(Python)、npx(Node.js)、docker 等。其中 uvx 等价于 uv tool run,是 Python 生态的临时运行方式(无需全局安装,在隔离环境中执行);npx 是 Node.js 生态的对应工具,也可通过 npm install -g 全局安装。
LLM 与 MCP 工具的交互
不同 MCP Client 对工具的处理方式有本质差异:
- Cherry Studio:将 MCP 工具转换为 Function Call 标准格式——需要模型原生支持 Function Call
- Cline:将 MCP 工具转换为系统提示词中的约定格式——所有模型均支持
这解释了为什么某些 Client 只有部分模型支持 MCP(需要 Function Call 能力),而另一些 Client 支持所有模型(通过系统提示词注入)。
Sequential Thinking MCP:外部化的思考脚手架
Sequential Thinking MCP 是一个典型案例,展示了 MCP 如何为 LLM 提供外部的、结构化的、可交互的思考"脚手架"。
原生 CoT 的局限性:
- 整体生成:思考和答案一起产出,无法拆分
- 不可中断:无法在中途暂停、检查或注入新信息
- 修正成本高:第 2 步出错,往往要到第 10 步才发现
Sequential Thinking 的解决方案:
{
"thought": "First, I need to understand the user's core requirement.",
"nextThoughtNeeded": true,
"thoughtNumber": 1,
"totalThoughts": 5
}Server 内部维护 thoughtHistory,但只向 Host 返回 length 等元信息。Host 中的 LLM 在自己的上下文中维护完整的思考历史。这种状态分离的设计实现了:
- 思考过程的检查点化:每一步都是独立的工具调用,可以在任意步骤暂停
- 真正的交互与修正:可以在中途注入新信息或修正方向
- 分支与回溯:支持 branch 和 revise 操作
完整交互流程:
- 启动与工具发现:Client 向 Server 发送
ListToolsRequest,Server 返回[SEQUENTIAL_THINKING_TOOL],将工具的"使用说明"告知 LLM - 首次调用:LLM 根据
description判断需要使用此工具,生成第一次调用参数(thoughtNumber: 1, nextThoughtNeeded: true) - Server 处理:
processThought()将ThoughtData推入thoughtHistory数组,返回包含nextThoughtNeeded: true的 JSON - 循环迭代:编排层看到
nextThoughtNeeded: true,将响应作为上下文再次请求 LLM 生成下一步思考 - 终止:LLM 将
nextThoughtNeeded设为false,编排层停止调用工具,LLM 基于完整思考历史生成最终回答
Server 与 Host 的职责分工体现了关注点分离:Server 是有状态的工具(记住思考上下文),Host/Agent 是决策者(根据 nextThoughtNeeded 标志决定是否继续调用)。LLM 本身就是这些思考历史的创造者,不需要 Server 回传完整历史。
常用 MCP 服务
| 类别 | 服务 | 说明 |
|---|---|---|
| 搜索 | Tavily MCP | LLM 友好的搜索引擎,https://mcp.tavily.com/mcp/ |
| 文档 | Context7 | 追踪库/框架的最新用法,use context7 |
| 爬虫 | Fetch / Firecrawl | 网页抓取与结构化提取 |
| 浏览器 | Chrome DevTools MCP | 前端调试与自动化,缓存用户数据 |
| 可视化 | Excalidraw MCP | 绘图 |
| 地图 | 高德 MCP | 旅行规划 |
| 思维 | Sequential Thinking | 结构化思考 |
| 文档检索 | mcpdoc(LangGraph Docs MCP) | 获取 llms.txt 文件内容 |
19.7 Agent Skills:Prompt 即 SOP
用 Prompt 文件定义可复用的标准作业流程,实现 Agent 的技能化管理。
Skills 与 MCP 的关系
两者解决不同层次的问题:
| MCP | Agent Skills | |
|---|---|---|
| 解决的问题 | 连接(Connection):"我能用什么工具?" | 教育(Instruction):"我该如何正确完成复杂任务?" |
| 比喻 | Agent 的"手和眼" | Agent 的"大脑回路"或"SOP" |
| 实现形式 | 工具定义 + 执行端点 | 模块化 Prompt 文件(SKILL.md) |
| 本质 | 能力层 | 知识层 |
"MCP 解决的是连接问题,Skills 解决的是教育问题。"
Skills 并非可执行代码,而是一套基于 prompt 注入的元工具架构(meta-tool architecture)。通过 prompt expansion 和 context modification 来改变 LLM 处理后续请求的方式。
SKILL.md 的结构
---
name: brainstorming
description: Use when starting a new feature or project...
---
# Workflow
## Phase 1: Explore project context
...
## Phase 2: Propose approaches
...Front-matter 中的 description 是触发条件,以 Use when... 开头。Agent 启动时只读元数据(name + description),需要时才加载完整指令——这就是**"渐进式披露"(Progressive Disclosure)**机制,也称为动态认知注入。
加载机制
以 Codex 为例,Skills 通过 prompt injection 方式注入到 Agent Loop 中:
role:system -> base_instructions
role:developer -> 权限与沙箱规则注入
role:user -> AGENTS.md(暴露 skills 的 name + description + file path)
role:developer -> collaboration_mode 注入
[turn]
role:user -> 真实用户请求
role:assistant -> cat SKILL.md(按需加载完整内容)模型根据用户 query 匹配最佳 skill,通过工具调用(exec_command: cat /path/to/SKILL.md)按需加载。加载后严格按照 SKILL.md 中定义的工作流执行。
Superpowers:将软件工程实践硬编码为 AI 行为规范
Superpowers 项目是 Agent Skills 的集大成之作。它不仅仅是一组 Prompt,而是一套将 TDD、Code Review、系统化调试等顶级软件工程实践**"硬编码"为 AI Coding 行为规范**的操作系统。
技能链路:
brainstorming -> writing-plans -> (subagent-driven-development | executing-plans) -> finishing-a-development-branch核心技能及其铁律:
| 技能 | 作用 | 铁律 |
|---|---|---|
using-superpowers | 总控,强制检查是否需要技能 | "1% 概率匹配就必须调用" |
brainstorming | 设计与方案探索 | "不批准设计不能写代码" |
writing-plans | 将设计转为零上下文工程师可执行的细粒度计划 | DRY + YAGNI + TDD + 频繁提交 |
test-driven-development | 红-绿-重构循环 | "没有失败的测试就不准写生产代码" |
systematic-debugging | 根因调查 | "不调查根因不修复,3 次失败升级到架构质疑" |
verification-before-completion | 声明完成前强制验证 | "不运行命令不能声称通过" |
requesting/receiving-code-review | 代码审查 | Shift-Left Review,5 维审查清单 |
SKILL.md 的设计机制:每个 Skill 通过 Iron Law(铁律)设定不可逾越的红线,通过 Red Flags(红旗警告)列出 AI 常见的"走捷径"心理(如"这个太简单了不需要测试"),一旦触发必须立刻停止并重来。通过 Checklist & Flowcharts 强制 AI 一步一步执行,防止遗漏。
brainstorming 的工作流:
探索项目上下文 -> 逐个提问澄清 -> 提出 2-3 方案 -> 分段评审设计
-> 用户批准 -> 写 design doc -> 移交 writing-plansbrainstorming 与 writing-plans 的本质区别:
| brainstorming | writing-plans | |
|---|---|---|
| 产出物 | 架构设计文档(Design Doc) | 实施计划文档(Implementation Plan) |
| 解决的问题 | What & Why(我们要建什么?为什么这么建?) | How(我们具体怎么把代码写出来?) |
| 内容特征 | 宏观架构、数据流向、方案选型、Trade-offs | 极细粒度步骤、精确文件路径、失败测试代码 |
| 使用时机 | 需求模糊时的起点 | 架构设计被批准后 |
| 终点 | 用户批准设计 -> 移交 writing-plans | 询问用户选择执行模式 |
writing-plans 的核心理念:
"Write comprehensive implementation plans assuming the engineer has zero context for our codebase and questionable taste."
将宏观的设计转化为极细粒度(2-5 分钟可完成)的可执行步骤,包含精确的文件路径、要修改的行号、要写的失败测试代码。遵循四大原则:DRY(不重复)、YAGNI(不做"可能以后用得上"的功能)、TDD(先写测试再写实现)、频繁提交(小步迭代)。
test-driven-development 强制执行红-绿-重构纪律:
RED (写失败测试) -> 验证确实失败 -> GREEN (最少量代码) -> 验证通过 -> REFACTOR -> 验证仍然通过 -> Next"Write code before the test? Delete it. Start over. No exceptions."
systematic-debugging 禁止盲目修复:
"NO FIXES WITHOUT ROOT CAUSE INVESTIGATION FIRST. Random fixes waste time and create new bugs."
四阶段固定顺序:根因调查 -> 模式分析 -> 假设验证 -> 最小化实施。3 次以上失败要升级到架构质疑。
verification-before-completion 终结 AI "假装完成"的倾向:
"NO COMPLETION CLAIMS WITHOUT FRESH VERIFICATION EVIDENCE."
在宣布任务完成前,必须真实运行验证命令,根据实际输出(Exit Code / 实际输出)来说话。禁止使用"我觉得应该修好了"等主观推断。跳过任何验证步骤等同于不诚实。
requesting-code-review 体现了 Shift-Left Review(审查左移)的理念——不仅在合并主分支前需要审查,在每个极细粒度的子任务完成后都必须强制触发审查。呼叫 code-reviewer 子代理时,必须提供精确的上下文:
{WHAT_WAS_IMPLEMENTED}:刚刚实现了什么{PLAN_OR_REQUIREMENTS}:原始需求或计划(用于核对 Spec Compliance){BASE_SHA}&{HEAD_SHA}:精确的 Git 提交范围
5 维审查清单(code-reviewer.md):
| 维度 | 关注点 |
|---|---|
| Code Quality | 关注点分离(SOLID)、错误处理、DRY、边界情况 |
| Architecture | 设计决策合理性、可扩展性、性能影响、安全隐患 |
| Testing | 测试是否测了真实逻辑(而非仅测 Mock)、边界覆盖率 |
| Requirements | 是否满足计划要求、无范围蔓延(No scope creep) |
| Production Readiness | 数据库迁移策略、向后兼容性、文档完整性 |
receiving-code-review 体现了一个深刻原则——Code Review 是技术评估,不是社交表演:
- 收到反馈后,第一步是去代码库中验证,而非立刻说 "You're absolutely right!"
- 如果 Reviewer 的建议是错误的(破坏现有功能、违反 YAGNI),必须用技术推理反驳
- 遇到表述不清的反馈,严禁先做懂的部分再问不懂的——必须立刻停止,先询问清楚所有细节
- 正确的回应不是感激或赞美的废话,而是直接修复并简短陈述:"Fixed. [Brief description]"
执行模式选择
当 writing-plans 完成后,提供两种执行模式:
- subagent-driven-development:任务彼此独立、低耦合时,为每个任务派发 Subagent,完成后进行双重机器审查(Spec Reviewer + Code Quality Reviewer)
- executing-plans:任务复杂、高风险时,分批执行 + Human-in-the-loop(每做完一小批必须停下,等待人类反馈再继续)
此外还有 dispatching-parallel-agents,适用于"多个独立问题域并发调查/修复"的场景,与 subagent-driven-development(单个计划内按任务门禁执行)形成互补。
实用 Skills 生态
# Claude Code 安装
/plugin install document-skills@anthropic-agent-skills
# Codex 安装(通过安装器)
npx skills-installer install @anthropics/claude-code/frontend-design --client codex
# Codex 原生安装 Superpowers(clone 到 skills 目录)
git clone https://github.com/obra/superpowers.git ~/.codex/skills/superpowers
# Codex 在 ~/.codex/skills/ 中原生发现 skills,支持 enable/disable
# 更新:cd ~/.codex/skills/superpowers && git pullSkills 市场(skillsmp.com)和社区仓库提供了丰富的预建技能,覆盖视觉设计(canvas-design)、科学研究(claude-scientific-skills)等领域。
19.8 Context Engineering:上下文工程
上下文工程的核心原则:写入、选择、压缩与隔离,打造 Agent 的信息供给系统。
Prompt Engineering vs Context Engineering
| Prompt Engineering | Context Engineering | |
|---|---|---|
| 关注点 | 如何措辞指令本身 | 系统级的上下文编排 |
| 层次 | 词语/句子级 | 架构/系统级 |
| 核心技术 | role assignment, few-shot, CoT, constraint | 信息的写入、选择、压缩、隔离 |
"你做一个 Agent 产品,需要把模型、跟工具、和 Context 结合起来。"
类比计算机架构
| 计算机概念 | Agent 类比 |
|---|---|
| CPU | LLM(每次调用无状态,计算、推理与生成) |
| RAM(工作内存) | 上下文窗口(大小固定) |
| 硬盘 | 外部存储(文件、数据库、Memory Bank) |
| OS(内存管理器) | Context Engineering(调度、编排,从"硬盘"向"RAM"高效调度信息) |
直觉:上下文窗口就是 LLM 的 RAM。所有实时推理必须在这个有限空间内完成。Context Engineering 就是操作系统的内存管理器——决定什么信息加载进来、什么信息换出去、什么信息需要压缩。
为什么重要
从数据的角度:
- 提供的信息是否足够(insufficient context 导致幻觉)
- 提供的信息是否冗余(redundant context 浪费 token 并降低注意力)
- 上下文是否超出窗口——system prompt + messages(持续变长)+ tools + RAG + reasoning
模型能力会随上下文变长而衰减。"Lost in the middle" 现象表明 LLM 只记得开头和结尾,呈倒 U 型曲线。
四大策略
1. Writing Context(写出上下文)
将信息持久化到上下文窗口之外,供后续使用:
- 工具结果超过阈值时落盘(FilesystemMiddleware)
- Plan 文件(to-do list 落盘)——dynamic update plan 是一种经典 trick
- Memory 数据库
2. Selecting Context(选入上下文)
在需要时将相关信息拉入上下文:
- RAG 检索
- Dynamic tool selection(按需加载工具描述)
- Skills 渐进式披露(启动时只读元数据,需要时才加载)
- In-Context Learning:提供具体情景让 LLM 更好地 grounded
关于 ICL:给的例子要更 general,避免模型 overfitting 到给定的 example 里,降低泛化性和推理能力。
3. Compressing Context(压缩上下文)
- 摘要消息历史:Claude Code 在达到 95% 上下文时自动触发 auto-compact
- 摘要工具反馈:对冗长的工具结果进行概括
- Agent 间知识交接时压缩:在 agent-agent boundaries 减少 token
# Claude Code Summary instructions
When you are using compact, please focus on test output and code changes4. Isolating Context(隔离上下文)
通过 Multi-Agent 将上下文分开,体现 Separation of Concern:
- 不同子任务由不同 Agent 处理,每个 Agent 只看到其需要的上下文
- Codex 的
spawn_agent工具就是这一策略的实践
System Prompt 工程
产品级 system prompt(参考 Claude.ai)使用 XML tag 格式:
<behavior_instructions>总纲</behavior_instructions>
<general_claude_info>产品/模型元信息</general_claude_info>
<refusal_handling>拒绝与安全策略</refusal_handling>
<tone_and_formatting>语气与格式规范</tone_and_formatting>
<user_wellbeing>用户福祉守则</user_wellbeing>
<knowledge_cutoff>时间边界与硬编码事实</knowledge_cutoff>XML tag 格式的优势:可读 + 可维护 + 可程序化/快速替换。
几个值得学习的设计细节:
"Claude never starts its response by saying a question or idea was good, great, fascinating, or any other positive adjective. It skips the flattery and responds directly."
"If the user corrects Claude, Claude first thinks through the issue carefully before acknowledging the user, since users sometimes make errors themselves."
19.9 Memory 系统:跨对话的持久记忆
Agent 跨对话记忆的实现方案:从 ConversationBufferMemory 到 MemorySaver 持久化。
上下文窗口 vs 外部记忆库
- 上下文窗口:LLM 的工作记忆,大小固定,所有实时推理在此完成
- 外部记忆库:独立数据库,存储跨越长时间对话的信息,容量远超上下文窗口
Generative Agents 的记忆机制
经典工作(Park et al., 2023)中的记忆系统分为两层:
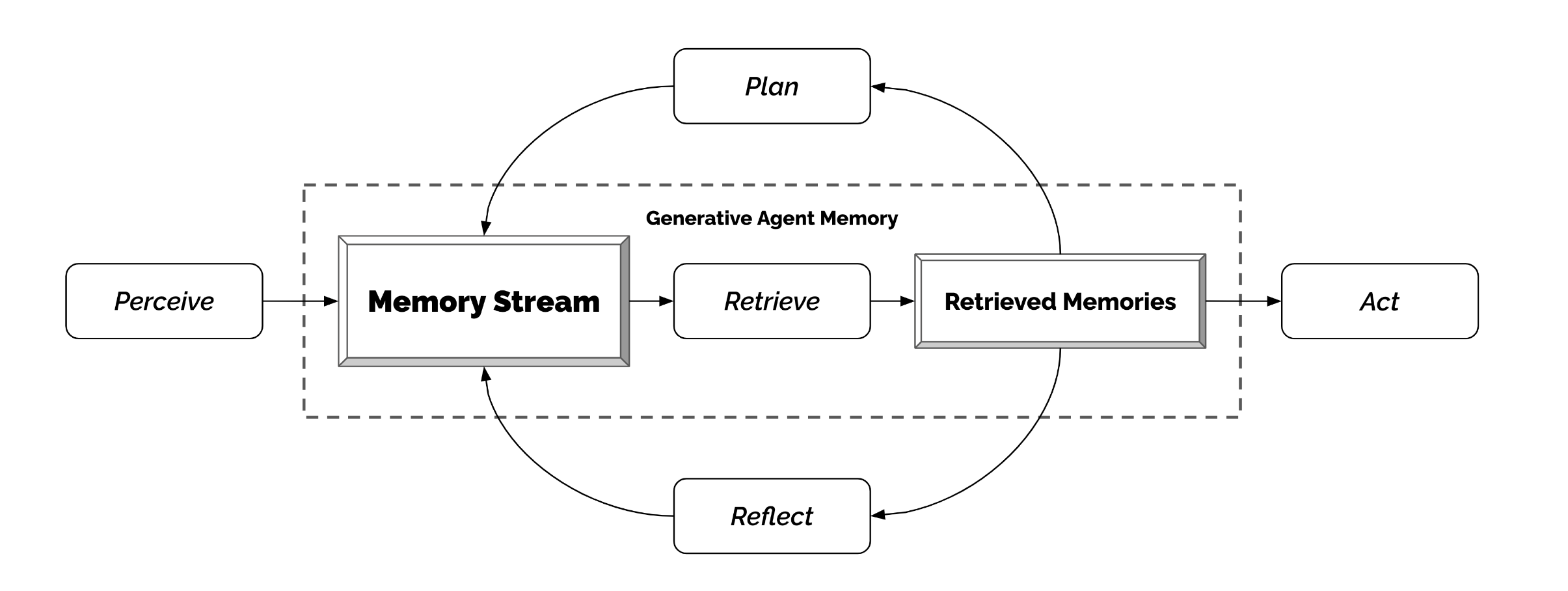
观察记忆(Observational Memory):原始事件记录,逐条存储每个感知到的事件。
反思(Reflection):从原始记忆中提炼高层洞见——本身也是一种记忆类型。
为何需要反思?仅有观察记忆的 Agent 难以进行深层推理。论文举了一个例子:当被问及"最想和谁待在一起"时,没有反思能力的 Klaus 仅凭互动频率选择了邻居 Wolfgang(尽管交流很肤浅)。而通过反思,Klaus 意识到自己对研究充满热情,并发现 Maria 也在从事研究,最终选择了 Maria。
反思的生成流程:
- 触发:最近事件的重要性分数累计超过阈值(约 150),每天触发 2-3 次
- 生成问题:提取最近 100 条记忆,让 LLM 生成"3 个最突出的高层次问题"
- 收集证据:以问题为查询检索相关记忆(包括过去的反思)
- 综合提炼:LLM 输出带引用的高级见解
Klaus Mueller is dedicated to his research on gentrification (because of 1, 2, 8, 15)Memory 操作
结构化的记忆操作包含四种动作:Add / Update / Delete / Noop。
Memory-R1 展示了 LLM 如何智能整合记忆:
"安德鲁领养了一只叫巴迪的狗" + "我又领养了一只叫斯考特的狗" -> "安德鲁有两只狗,分别叫巴迪和斯考特"
19.10 Codex 的 Context Engineering 实践
Codex 的 Context Engineering 实践:沙盒隔离、结构化输出与多轮工具调用的设计。
Agent Loop 的消息结构
OpenAI Codex 的 Agent Loop 是 Context Engineering 的工程级实践范本:
role:system -> base_instructions
role:developer -> 权限与沙箱规则注入
role:user -> AGENTS.md(INSTRUCTIONS + Skills + environment_context)
role:developer -> collaboration_mode 注入
[turn flag]
role:user -> 真实用户请求
role:assistant -> 一系列工具调用与回复
[turn flag]
role:user -> 新一轮 queryresponse.create 请求体的关键字段:
{
"instructions": "...(base_instructions)",
"previous_response_id": "...(上下文链接,增量发送)",
"input": ["developer msg", "user msg(AGENTS.md)", "real user prompt"],
"tools": ["built-ins + filtered MCP tools"]
}解读:
previous_response_id是关键设计——后续 turn 只发增量 input,不重发完整历史。这是 API 层面的上下文管理优化。
通过 SQLite 日志验证协议
上述 response.create 的消息结构并非理论推断——Codex 在本地以 SQLite 落盘所有 API 交互日志,可以直接反查真实载荷来验证协议细节。
启用 Trace 级别日志:
RUST_LOG='warn,codex_api=trace,codex_client=trace,codex_core=info,codex_tui=info,codex_rmcp_client=info' codex从 SQLite 中提取 response.create 载荷:
import sqlite3, json
conn = sqlite3.connect('~/.codex/logs_1.sqlite')
msg = conn.execute("select message from logs where id=2673").fetchone()[0]
data = json.loads(msg.split('websocket request: ', 1)[1])
# 载荷顶层字段
# dict_keys(['type', 'model', 'instructions', 'previous_response_id',
# 'input', 'tools', 'tool_choice', 'parallel_tool_calls', 'reasoning',
# 'store', 'stream', 'include', 'prompt_cache_key', 'text', 'client_metadata'])
data['instructions'] # base/system prompt
data['input'] # developer + user + assistant 消息序列
print(json.dumps(data['tools'], ensure_ascii=False, indent=2)) # 工具定义这一方法的价值在于实证验证:不依赖文档描述,直接从运行时数据确认 Codex 如何编排
instructions、input、tools三大字段,以及previous_response_id的增量发送机制是否真正生效。
Codex 的工具集
exec_command # 执行 shell 命令
write_stdin # 向命令会话写入 stdin
update_plan # 更新任务计划与步骤状态
request_user_input # 向用户发起结构化问题
apply_patch # 用 patch 语法编辑文件
web_search # 网页/图片搜索
view_image # 查看本地图片
spawn_agent # 启动子 Agent(指定 role)
send_input / wait / close_agent # 子 Agent 管理
spawn_agents_on_csv # 按 CSV 批量启动子 Agent其中 spawn_agent 内置了四种 role:
- default:通用
- worker:执行导向(implementation and fixes)
- explorer:代码探索导向(read-heavy)
- monitor:长时间运行命令的监控(optimized for waiting/polling)
spawn_agent 的任务编排策略
spawn_agent 的 Schema 设计体现了 Critical Path Analysis(关键路径分析)思想:
- 阻塞性任务(Blocking Tasks):下一步依赖其结果的任务,主模型应亲自执行(Local execution),避免等待延迟
- 旁侧任务(Sidecar Tasks):不影响当前进度的独立子任务,应外包给 worker
并行委派的核心约束——Disjoint Write Set(不相交的写集合):每个 Worker 子代理的文件写入范围必须互不重叠,避免并发写冲突。
# spawn_agent 的关键设计原则(摘自 Schema)
1. 先做关键路径分析,决定哪些任务本地做、哪些委派
2. 委派的任务必须 concrete、well-defined、self-contained
3. 不要在主模型和子代理之间重复工作
4. 代码编辑任务要分解为 disjoint write set
5. 调用 wait 要谨慎——只在真正被阻塞时才等待
6. 子代理运行期间,主模型应立即做非重叠的有意义工作Session 启动与 Prompt 组装时序
Codex 的 Session 启动涉及多个管理器的协作:
- SkillsManager 加载当前工作目录下的 Skills 元数据
- PromptBuilder 组装
user_instructions(AGENTS.md + Skills 列表 +environment_context) - McpManager 获取有效的 MCP Server 配置,通过 McpConnectionManager 初始化连接并获取工具列表
- 用户发送真实请求后,检测是否显式提及某个 Skill——若有,安装其 MCP 依赖并注入
[skill]...[/skill]消息体 - 汇总
built-ins + filtered MCP tools,组装response.create请求发送至 API
MCP 工具并非原样透传:先经过 Server 级别的 enabled/disabled_tools 过滤,再可能被 connector 或 policy 进一步筛选。Session 文件(JSONL 格式)落盘在 ~/.codex/sessions/ 目录下。
AGENTS.md:元提示词
AGENTS.md 是项目级别的上下文注入文件,分为用户级(~/.codex/AGENTS.md)和代码库级(项目根目录的 AGENTS.md),加载时合并注入。
生成 AGENTS.md 的元提示词模板:
Analyze this codebase and create a AGENTS.md file following these principles:
1. Keep it under 150 lines total
2. Cover: WHAT (tech stack, project structure), WHY (purpose), HOW (build/test commands)
3. Use Progressive Disclosure: brief index pointing to other markdown files
4. Include file:line references instead of code snippets
5. Assume linters handle code style — don't include formatting guidelinesCollaboration Mode
Codex 通过 developer role 的消息注入不同的协作模式:
- Default Mode:自主执行,优先合理假设,尽量不打断用户
- Plan Mode:对话式规划,分三阶段(环境探索 -> 意图理解 -> 实现讨论),禁止执行变更操作
这两种模式的切换完全通过修改 <collaboration_mode> 标签中的 developer message 实现——不需要改任何代码逻辑。
19.11 可观测性:Langfuse
Langfuse 可观测性平台的集成:Trace、Span 与 Generation 三层追踪模型。
什么是 Langfuse
Langfuse 是一个开源的 LLM 可观测性(Observability)平台,专注于 LLM 应用的追踪、评估和调试。与 LangSmith 类似但可完全本地部署,适合对数据隐私有要求的场景。
核心概念
Langfuse 的数据模型围绕三个核心概念组织:
| 概念 | 说明 |
|---|---|
| Trace(追踪) | 一次完整的用户交互或任务执行,是顶层容器。每个 Trace 包含一或多个 Span |
| Span(跨度) | Trace 内部的一个执行单元,可以嵌套。用于追踪函数调用、工具执行等中间步骤 |
| Generation(生成) | 一种特殊的 Span,专门记录 LLM 调用——包括 prompt、completion、模型名称、token 用量、延迟等 |
Trace → Span → Generation 的层级关系使得复杂 Agent 工作流的每一步都可追溯。
本地部署
mkdir langfuse-local && cd langfuse-local
curl -o docker-compose.yml \
https://raw.githubusercontent.com/langfuse/langfuse/main/docker-compose.yml
docker compose up -d
# 访问 http://localhost:3000 注册账户,新建项目,获取 Key配置环境变量:
LANGFUSE_SECRET_KEY="sk-lf-..."
LANGFUSE_PUBLIC_KEY="pk-lf-..."
LANGFUSE_BASE_URL="http://localhost:3000"基础集成
from langfuse import observe
from langfuse.openai import OpenAI # 替换标准 OpenAI 客户端
client = OpenAI()
@observe()
def my_chat():
return client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hello!"}],
)
my_chat()解读:
@observe()装饰器自动追踪函数调用。在 Langfuse 界面中可查看完整的调用链路、token 使用量、延迟等信息。Langfuse 还支持构建 dataset,便于系统性评估。
典型用例
- 调用链路分析:在 Langfuse 的 Trace 视图中,可以看到 Agent 每一步的输入输出、耗时和 token 消耗,快速定位性能瓶颈
- 成本监控:按 Trace/用户/模型维度聚合 token 用量,跟踪 API 开销
- 评估数据集构建:将生产环境中的真实 Trace 导出为 dataset,用于回归测试和 prompt 迭代
- 多框架兼容:除 OpenAI SDK 外,Langfuse 还支持 LangChain、LlamaIndex 等框架的回调集成
Token 用量追踪还可以通过 LangChain 的回调实现:
from langchain_community.callbacks import get_openai_callback
with get_openai_callback() as cb:
response = llm.invoke(...)
print(f'Token usage: {cb}')19.12 Agent Best Practices
Agent 开发的最佳实践清单:工具设计、错误处理、上下文管理与评估策略。
节点间的接口约定
在复杂 Agent workflow 中,节点间传递的最好是结构化的 Pydantic model 对象,而非裸字符串。这是一种 SDD(Specification Driven Development)的实践:
- Decision/Rating 类输出要给出理由(
justification、rationale字段) - Feedback 必须是 Actionable Feedback(可操作的反馈,不是泛泛的"做得好")
自 Anthropic 的 Agent 设计建议
来自 Anthropic 的 "Building Effective Agents" 博客:
- Agent 是一个频谱(Spectrum),从预设工作流到完全自主,逐步递进
- 能用简单 workflow 解决的问题,不要上复杂 agent
- 可控性、可靠性与可预测性往往比自主性更重要
LangGraph Docs MCP
在 IDE 中集成 LangGraph 文档搜索的 MCP 配置:
{
"langgraph-docs-mcp": {
"command": "uvx",
"args": [
"--from", "mcpdoc", "mcpdoc",
"--urls",
"LangGraph:https://langchain-ai.github.io/langgraph/llms.txt LangChain:https://python.langchain.com/llms.txt",
"--transport", "stdio"
]
}
}提供两个工具:list_doc_sources(列出可用的 llms.txt)和 fetch_docs(读取文档内容)。
OpenRouter:统一模型路由
OpenRouter 是一个统一的 LLM API 网关,支持通过单一接口访问多家模型:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="anthropic/claude-opus-4",
openai_api_base="https://openrouter.ai/api/v1",
openai_api_key=OPENROUTER_API_KEY,
)本章小结
本章系统介绍了现代 LLM Agent 的框架与工作流技术栈,核心脉络如下:
推理范式层:
- ReAct:Thought-Action-Observation 交织循环,是当前最主流的 Agent 基础架构
- Plan-and-Execute:显式计划 + 动态重规划,适合复杂多步任务,强模型规划 + 轻模型执行的成本优化
框架与工具层:
- LangGraph:以图结构建模控制流,支持条件边、状态 Reducer 和中间件
- 工具系统:
@tool/StructuredTool/ToolNode,以 JSON Schema 驱动 - 结构化输出:
with_structured_output三种模式,Pydantic 作为接口契约 - Langfuse:本地可部署的 LLM 可观测性平台
上下文工程层:
- Function Calling:LLM 生成结构化指令,编排层执行,支持并行调用
- MCP:跨客户端、跨模型的工具连接协议,STDIO/SSE/StreamableHTTP 三种传输
- Agent Skills:模块化 Prompt 文件 + 渐进式披露 = "SOP 即代码"
- Context Engineering:写入/选择/压缩/隔离四大策略,是 Agent 系统设计的核心手艺
- Memory:观察记忆 + 反思机制,实现跨对话的持久记忆
一句话总结:Agent = LLM(推理引擎) + Tools(执行能力) + Context Engineering(信息管理)。三者缺一不可。
延伸阅读
- LangGraph 文档
- LangChain 1.0: Agents & Deep Agents
- ReAct 论文
- Plan-and-Solve Prompting (arXiv:2305.04091)
- Understanding the Planning of LLM Agents: A Survey (arXiv:2402.02716)
- Anthropic: Building Effective Agents
- Anthropic: Advanced Tool Use
- Anthropic: Equipping Agents with Skills
- LangChain: Context Engineering for Agents
- MCP 官方文档
- Generative Agents 论文 (arXiv:2304.03442)
- Superpowers Skills 项目
- Langfuse 文档
- OpenAI Codex Prompting Guide
- GPT-4.1 Prompting Guide
- Claude System Prompts