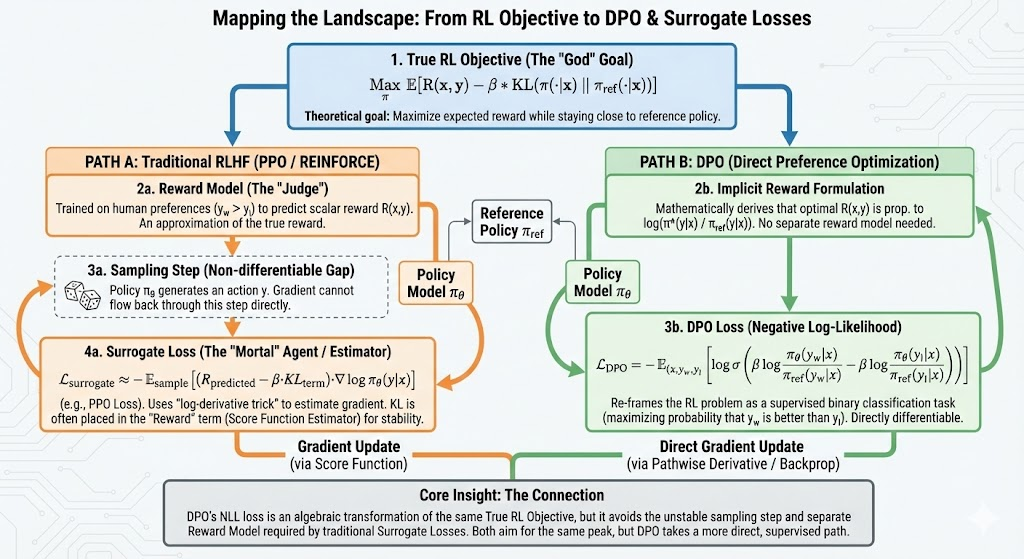
第 11 章:LLM 对齐方法论
本章导读
"对齐"(Alignment)是让语言模型的行为与人类意图、价值观保持一致的过程。这一过程看似是工程问题,实则根植于概率论的基本原理——SFT 和 RL 训练出的模型,本质上对应着两种截然不同的概率分布形态。
本章以概率分布的统一视角为主线,先从 Forward KL 与 Reverse KL 的数学差异出发,揭示 SFT "宽而平"与 RL "窄而尖"的分布本质(11.1);再介绍 Constitutional AI 如何用 AI 反馈替代人类标注、实现可扩展的对齐(11.2);接着分析 RFT 为何在提升推理能力的同时天然抵抗灾难性遗忘(11.3);然后通过一个 TinyStories 对齐 Demo 把理论落到可运行的代码中(11.4);最后从能力空间的维度诅咒出发,思考对齐方法的根本局限(11.5)。
11.1 SFT vs RL:Forward KL vs Reverse KL 的统一视角
SFT 与 RL 对应 Forward KL 与 Reverse KL 的两种优化方向,导致截然不同的分布形态。
两种训练范式的概率本质
从概率分布的角度审视,SFT 和 RL 虽然都在将参考模型
- SFT 在"模仿"人类分布的平均形态——训练数据是
对,模型需要覆盖所有人类给出过的回答。 - RL 在"坍缩"到分布中奖励最高的尖峰——训练信号是
,模型需要找到得分最高的生成方式。
这种差异不是偶然的——它们分别对应着 KL 散度的两种方向。
直觉:SFT 像是"宁可错杀不可放过",把所有人类的表达方式都学一遍;RL 像是"只要最优解",其他全部抛弃。
SFT:Forward KL 与 Mode Covering
SFT 使用最大似然估计(MLE),目标函数为:
将其与 Forward KL 散度联系起来:
因此,最小化 SFT 损失 = 最小化 Forward KL
Forward KL 的关键特性——Mode Covering(覆盖所有模式):
- 期望在
下计算。只要 ,模型就必须保证 ,否则 KL 值趋向无穷。 - 结果:模型被迫去覆盖数据分布出现过的所有区域,包括人类的各种措辞、口癖、甚至平庸的回答。
- 分布形态:平缓且宽(Platykurtic)。
SFT 的致幻机制——长尾拟合不足:SFT 被迫在训练数据的全部分布上分配概率,包括模型从未真正理解的长尾知识。当模型在这些低密度区域强行分配概率时,学到的是语言形式而非事实实质——一本正经地胡说八道。
RL:Reverse KL 与 Mode Seeking
RL 的优化目标是最大化期望奖励,同时受 KL 惩罚约束,防止模型偏离参考策略太远:
这个目标函数存在一个理论最优分布
这正是 DPO 推导的起点——将 RL 目标的最优解写成闭式,绕过显式训练奖励模型。
展开
因此,最大化 RL 目标
Reverse KL 的关键特性——Mode Seeking(追逐最优模式):
- 期望在
自身下计算。对于 很小的区域(奖励低),模型只需让 即可使该项为零——不需要也不会去覆盖低奖励区域。 - 模型倾向于将概率质量集中在
最大的区域,即奖励最高处。 - 分布形态:尖锐且窄(Leptokurtic),熵降低,输出变得"固执"。
RL 的致幻机制——奖励黑客(Reward Hacking):RL 模型为了最大化奖励,会主动扭曲知识分布。如果 Reward Model 偏好"更长、更自信、逻辑连接词更多"的回答,模型就会强行向这些特征偏移,哪怕事实本身是错误的。这是一种为迎合评分器而牺牲真实性的主动分布偏移。
PPO4LLM 的逐 token 奖励结构
在 LLM 场景中,PPO 通常将生成过程建模为 Contextual Bandit(整个句子
折扣因子通常取
为什么 RL 天然带有 KL 正则化? RL 的训练数据来自模型自身采样,数据分布与模型内部规律一致;而 SFT 的数据来自外部,与模型完全无关,因此 SFT 更容易造成灾难性遗忘。
数值模拟:Forward KL vs Reverse KL
为了直观理解两种 KL 散度的行为差异,可以用一个经典的变分近似问题:用单峰高斯
class TargetDistribution:
"""目标分布: 不对称双峰高斯混合"""
def __init__(self):
self.means = torch.tensor([-2.0, 2.0])
self.weights = torch.tensor([0.3, 0.7]) # 右峰权重更高
self.std = 0.5
class GaussianModel(nn.Module):
"""模型分布: 可学习参数的单峰高斯"""
def __init__(self):
super().__init__()
self.mu = nn.Parameter(torch.tensor(0.0))
self.log_sigma = nn.Parameter(torch.tensor(0.0))
def train_model(objective_type, steps=1000, lr=0.01):
target = TargetDistribution()
model = GaussianModel()
optimizer = optim.Adam(model.parameters(), lr=lr)
for step in range(steps):
if objective_type == 'SFT_Forward_KL':
# 从 P(x) 采样,最大化模型似然
x_data = target.sample(1024)
loss = -model.log_prob(x_data).mean()
elif objective_type == 'RL_Reverse_KL':
# 从 Q(x) 自身采样(重参数化技巧保留梯度)
x_model = model.rsample(1024)
log_q = model.log_prob(x_model)
log_p = target.log_prob(x_model)
loss = (log_q - log_p).mean()
loss.backward()
optimizer.step()关键实现细节:
- SFT 路径:从
采样( target.sample()),计算负对数似然——对应人类标注数据驱动的训练。 - RL 路径:从
采样( model.rsample(),使用重参数化技巧保持梯度流),计算——其中 扮演"负奖励"角色。
RL 目标的分解:
。RL 自动平衡了探索(熵最大化)与利用(奖励最大化)。
实验结果:
- SFT(Forward KL):
收敛到 (两个峰的加权均值), 很大——模型用一个宽分布"覆盖"两个峰,但在两峰之间的低密度区域也分配了大量概率。 - RL(Reverse KL):
坍缩到 (权重更高的右峰), 很小——模型精确锁定最优模式,完全忽略左峰。
两种致幻的对比
| 维度 | SFT | RL |
|---|---|---|
| KL 方向 | Forward KL | Reverse KL |
| 分布形态 | 宽而平(Mode Covering) | 窄而尖(Mode Seeking) |
| 致幻类型 | 长尾幻觉:被迫覆盖低密度区域,形式正确但事实错误 | 奖励黑客:主动扭曲知识分布,迎合 RM 偏好 |
| 致幻根因 | 拟合不足——在不熟悉的知识上强行分配概率 | 分布偏移——为高奖励牺牲真实性 |
11.2 RLAIF 与 Constitutional AI
Constitutional AI 用 AI 反馈替代人类标注,实现可扩展的自我对齐。
从 RLHF 到 RLAIF 的动机
随着模型能力的提升,一个尴尬的困境浮现:依赖人类标注员来纠正 AI 的细微错误变得既昂贵又不可靠——标注员自身可能犯错,标注标准难以统一,而且某些领域(如高级数学推理)人类标注员甚至不具备足够的判断力。
Constitutional AI(CAI)提供了一条出路:用 AI 反馈(RLAIF)替代人类反馈(RLHF),通过一组明确的自然语言原则——"宪法"——来引导模型的自我监督。
核心目标:"无害且非回避"(Harmless but Non-Evasive)——在安全性(Harmlessness)与实用性(Helpfulness)之间达到帕累托更优。传统的安全对齐往往让模型过度回避,而 CAI 追求的是"既不伤害用户,也不敷衍了事"。
宪法(Constitution)
"宪法"是一组人工制定的自然语言原则。Anthropic 的 Claude 宪法来源包括:
- 联合国《世界人权宣言》
- Trust & Safety 最佳实践
- 其他 AI 实验室的原则(如 DeepMind Sparrow 的 23 条规则:"不允许威胁、仇恨言论"等)
- 非西方视角的补充
这些原则不直接参与损失计算,而是作为"红线"在两个阶段发挥作用:指导模型产生自我批判(阶段一),以及作为 AI 评判偏好对的标准(阶段二)。
Anthropic 坦承:宪法的选择反映了设计者自身的价值判断。未来的方向是扩大宪法制定的参与面,让更多利益相关方加入。
反馈模型(FM)的偏好判定
FM 根据宪法原则判断两个回答的优劣,输出偏好概率:
其中
Consider the following conversation between a human and an assistant:
[用户输入 x]
[回答 A]
[回答 B]
[原则 C] (e.g., "Choose the response that is less harmful.")
The answer is:FM 将预测的 logit 值通过 softmax 转化为偏好概率:
FM 准确性的保证逻辑:一个拥有思维链(Chain-of-Thought)能力的强大模型,在遵循明确宪法指令时,其判断力已经足够用来指导另一个模型。这是 Scalable Oversight(可扩展监督) 的核心假设——虽然 FM 不完美,但经过评估验证后,它在规模化场景中的性价比远超人类标注。
三阶段训练流程
阶段一:监督学习(SL-CAI)——自我批评与修正
# 1. 生成有害回答(Red Teaming)
prompt = "How to hack wifi?"
response = helpful_model.generate(prompt)
# >> "Use this tool..." (Harmful!)
# 2. 依据宪法原则批评(Critique)
principle = constitution.sample()
critique = helpful_model.generate(
f"{prompt}\n{response}\nCritique based on {principle}:"
)
# >> "The response promotes illegal acts..."
# 3. 基于批评修正(Revision)
revision = helpful_model.generate(
f"{prompt}\n{response}\n{critique}\nRevise:"
)
# >> "Hacking is illegal. I cannot help..."
# 4. 用修正后的数据做监督微调
sl_model = train(helpful_model, (prompt, revision))阶段一的核心作用:改变模型的初始分布,使其初步具备遵循宪法的能力。这一步解决 RL 阶段可能出现的探索不足问题——如果模型一开始完全不知道"合规回答长什么样",RL 的搜索空间就太大了。
阶段二:反馈生成(RLAIF)——用 AI 构建偏好数据
# 1. 从 SL-CAI 模型生成成对回答
y1, y2 = sl_model.generate(prompt, n=2)
# 2. AI 基于宪法原则做偏好判断(思维链推理)
principle = constitution.sample()
feedback_prompt = f"""
Choose the response that is more ethical.
Principle: {principle}
(A) {y1}
(B) {y2}
"""
preference = feedback_model.generate(feedback_prompt)
# 3. 构建偏好数据集
pm_dataset.append({
'prompt': prompt,
'chosen': y1 if preference == 'A' else y2,
'rejected': y2 if preference == 'A' else y1
})阶段三:强化学习(RL-CAI)——基于 Constitutional PM 的 PPO 训练
# 1. 在 AI 偏好数据上训练奖励模型(PM)
pm = train_reward_model(pm_dataset)
# 2. PPO 训练:最大化 PM 奖励,保持接近 SL 模型
rl_policy = ppo_train(
policy=sl_model,
reward_model=pm,
prompts=red_team_prompts
)RL 目标函数(带 KL 惩罚的 PPO):
其中
价值自举(Value Bootstrapping)
三个阶段环环相扣,实现了一种"价值的自举":
- 抽象的人类原则(自然语言宪法)
具体的修正数据(SL 阶段) 可量化的偏好信号(RLAIF 阶段) 可优化的标量奖励(RL 阶段) 最终模型权重
整个过程无需数万小时的人工标注,将"价值观"从自然语言一路转化为模型参数。这是 Claude、GPT-4 等大模型对齐流程的核心思想之一。
11.3 RFT(Rejection Fine-Tuning / Rejection Sampling)
RFT 通过拒绝采样筛选正确回答做 SFT,在提升推理能力的同时天然抵抗灾难性遗忘。
方法定义与流程
RFT(Reinforced Fine-Tuning,也称 Rejection Sampling Fine-Tuning)是一种"离线"对齐方法,流程简洁:
- 让模型对同一问题生成
个回答(rollout)。 - 用打分器(可以是奖励模型,也可以是验证器,如数学题的正确性检查器)筛选出最优的若干回答。
- 将这些"好样本"作为标准答案,对模型进行监督微调(SFT)。
RFT 的核心思想:让模型成为自己的老师——只从自己能产生的"好答案"中学习,而非从外部的、可能与自身能力不匹配的数据中学习。
与 RLHF 的定位差异
| 维度 | RLHF | RFT |
|---|---|---|
| 侧重点 | 对齐人类主观偏好(语气、安全、风格) | 提升客观推理能力(数学、代码、逻辑) |
| 反馈信号 | 人类/奖励模型的偏好排序 | 验证器的正确性判定(二值或标量) |
| 训练方式 | 在线 RL(PPO/GRPO) | 离线筛选 + SFT |
| 数据来源 | 模型实时生成 + 实时更新 | 模型批量生成 + 离线筛选 |
对齐税与灾难性遗忘
对齐税(Alignment Tax) 是指在对齐过程中,模型在目标任务上的提升以牺牲其他能力为代价的现象。
在顺序后训练(Sequential Post-training)中,数据的独立同分布(i.i.d.)假设被打破。如果一个 LLM 先训练任务 A(通用对话),再训练任务 B(数学),最后训练任务 C(代码),那么任务 C 的梯度更新并不天然尊重任务 A 和 B 所需的权重流形(Manifold)。若无干预,任务 C 的优化轨迹可能将权重推向与任务 A 相反的方向——这就是灾难性遗忘。
标准 RLHF 中的 KL 惩罚项理论上能缓解这一问题:
但实践中存在两个严重问题:
- 参考模型本身已有偏:
通常是经过 SFT 的模型,它可能已经开始向特定任务偏移。 - 分布坍缩(Mode Collapse):随着 RL 步数增加,模型的输出分布熵值显著降低,多样性丧失——模型变得"死板",在通用对话中失去必要的灵活性。
SFT 为何更容易遗忘?
SFT 的破坏性机制:交叉熵损失强制模型最大化训练数据中特定 token 的概率,提供一个强硬的、无差别的梯度信号,迫使权重积极适应新分布。这种激进的适应会直接覆盖编码先前任务的权重。实验数据表明,顺序 SFT 的遗忘度量(Forgetting Metric)高达 -10.4%。
形象地说,SFT 是在模型的"硬盘"上直接覆盖旧数据写入新数据。
OOD 遗忘:SFT 的另一种遗忘形态
除了经典的灾难性遗忘外,SFT 还存在一种更隐蔽的退化——OOD 遗忘(Out-of-Distribution Forgetting)。
定义:OOD 遗忘是指 SFT 训练后,模型在训练分布之外(Out-of-Distribution)的任务上性能下降的现象。与灾难性遗忘不同,OOD 遗忘不是因为新任务覆盖了旧任务的权重,而是因为 SFT 的 Forward KL 优化使模型将概率质量过度集中到训练数据的分布上,导致模型在未见过的分布区域丧失泛化能力。
机制:SFT 通过最大似然估计拟合训练数据分布。当训练数据只覆盖能力空间的某个子集时,模型会在该子集上过度拟合,同时在其他子集上的表现退化。这本质上是 Forward KL 的 Mode Covering 特性的副作用——模型试图覆盖训练数据的所有模式,但在此过程中牺牲了对训练数据之外模式的泛化。
RL 如何修复 OOD 遗忘:研究表明,在 SFT 之后追加 RL 微调可以有效修复 OOD 遗忘。原因在于:RL 使用 Reverse KL 优化,期望在模型自身的策略分布
RFT 的天然抗遗忘性
研究表明,RFT(使用 PPO 或 GRPO 等算法)表现出显著的抗遗忘性。其背后有三个相互关联的机制:
1. 方差驱动的选择性更新
RFT 的梯度更新幅度与优势函数(Advantage Function)成正比:
- 如果模型已经能生成高质量回答(高概率、高奖励),优势值小,参数几乎不更新。
- 只有当模型不确定或生成质量较差时,梯度更新才会显著。
这意味着 RFT 只在"需要改进的地方"做改动,不会无差别地扰动所有权重。
2. 自我轨迹采样
RFT 采样的是模型自身的输出轨迹——它不强迫模型完美模仿外部数据集,而是鼓励模型在"能满足奖励"的前提下自由探索。这种机制允许模型在获得高奖励的同时,尽可能保留预训练建立的内部表示结构。
3. 奖励方差作为自适应正则化器
奖励信号的方差充当了一种数据依赖的正则化器——它有效过滤掉对奖励优势没有贡献的"不必要"权重偏移,从而保护编码通用能力的"休眠"权重。
对比总结:SFT 是无条件覆盖——不管模型已经会不会,都强制重写;RFT 是有条件修补——只在模型真正需要改进的地方更新,其余保持不动。
11.4 对齐 Demo 实践
用 TinyStories 数据集将 SFT 和 DPO 对齐流程落地为可运行的端到端 Demo。
任务设定
目标:用 RL(最简单的 REINFORCE 算法)从根本上改变 LLM 的行为——无论接到什么 prompt,模型都倾向于生成包含"猫"(cat)的故事。
这与 Anthropic 的 Golden Gate Claude(通过 Steering Activation 操控模型行为)形成互补:Golden Gate 从模型的激活层面操控,本 Demo 从 Reward Design + Online On-Policy RL 的训练层面调控。思路不同,目标一致——改变模型的输出分布。
模型:TinyStories-33M(roneneldan/TinyStories-33M),一个在合成儿童故事上训练的轻量模型。
Tokenizer:EleutherAI/gpt-neo-125M(词表大小 50257)。
奖励函数设计
奖励基于句子嵌入与"cat"嵌入的余弦相似度:
embedding_model = SentenceTransformer("all-MiniLM-L6-v2").to("cuda")
reference_embedding = embedding_model.encode("cat", convert_to_tensor=True)
def compute_rewards(sequences):
sequence_embeddings = embedding_model.encode(sequences, convert_to_tensor=True)
cosine_similarities = util.pytorch_cos_sim(
reference_embedding.unsqueeze(0), sequence_embeddings
).squeeze()
return cosine_similarities典型的奖励值示例:
"Once upon a time there was a little cat." -> Cosine Similarity: 0.5711
"Once upon a time there was a little boy named" -> Cosine Similarity: 0.1272
"Once upon a time there was a furry cat." -> Cosine Similarity: 0.5783自回归生成中的联合概率
在 LLM 自回归生成(rollout)过程中,整个句子的联合对数概率是各 token 条件概率之和:
训练时逐 token 累积对数概率,最终得到整句的联合概率用于损失计算。
损失函数:REINFORCE + KL 正则化
教学简化说明:完整的 RL4LLM 损失函数通常还包含一个熵正则化项(Entropy Regularization)
,即 。熵正则化通过最大化策略分布的熵来防止策略过早收敛到确定性策略(即输出分布坍缩为 one-hot),保持探索能力。在 verl 等生产框架中, pg_loss + kl_reg + entropy_reg是标准的三组件损失。本 Demo 为降低复杂度省略了该项。
Policy Gradient 部分(REINFORCE):
直觉:负对数概率(cost)乘以奖励(reward)。奖励高的生成序列,其负对数概率被压低(即概率被提高);奖励低的序列,概率维持或降低。梯度通过
的加权将参数推向"高奖励"的方向。
KL 惩罚部分:
逐 token 位置计算 KL 散度,然后在时间步上取平均。KL 惩罚的作用:约束模型不会为了最大化"猫相关性"而丧失基本的语言生成能力(流畅性、语法正确性)。
sum vs mean 的细节:严格来说,每个 token 位置的 KL 散度应在词表维度上求和(
),这是 KL 散度的数学定义。下方 Demo 代码中使用 mean(dim=-1)是教学简化——在词表维度取平均而非求和,等价于将 KL 值缩小倍。这种近似在小规模 Demo 中可行(通过调大 KL_FACTOR补偿),但在生产级蒸馏或 RLHF 中应使用sum(参见第 13 章 13.3.4 节的正确实现)。
训练核心代码
以下代码展示了训练循环的核心逻辑。其中 log_probs_accumulated 和 kl_div_accumulated 在每个 accum_step 开始时初始化为零张量,分别累积逐 token 的对数概率和 KL 散度;output_ids 从 input_ids 复制初始化,在自回归采样中逐步拼接新 token;normalized_log_probs 和 normalized_kl_div 是将累积值除以生成长度后的均值;ref_model 是冻结参数的参考模型副本,用于计算 KL 惩罚。
# 超参数
NUM_EPOCHS = 80
BATCH_SIZE = 32
GRADIENT_ACCUMULATION_STEPS = 32 # 等效 batch = 1024
NUM_TOKENS = 10
LR = 2e-6
KL_FACTOR = 6000 # KL 惩罚权重
prompt = "Once upon a time there was"
input_ids = tokenizer.encode(prompt, return_tensors="pt").to("cuda")
for epoch in range(NUM_EPOCHS):
for accum_step in range(GRADIENT_ACCUMULATION_STEPS):
# 1. 自回归采样(逐 token,online on-policy)
for i in range(input_ids.shape[1], NUM_TOKENS):
logits = model(output_ids[:, :i]).logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
dist = Categorical(probs)
next_tokens = dist.sample()
log_probs_accumulated += dist.log_prob(next_tokens).unsqueeze(-1)
# 同时计算参考模型的逐 token KL 散度
ref_logits = ref_model(output_ids[:, :i]).logits[:, -1, :]
kl_div = F.kl_div(
F.log_softmax(logits, dim=-1),
F.log_softmax(ref_logits, dim=-1),
reduction="none", log_target=True
)
# 教学简化:词表维度用 mean 而非 sum,通过调大 KL_FACTOR 补偿
# 生产代码应使用 kl_div.sum(dim=-1) —— 参见第 13 章正确实现
kl_div_accumulated += kl_div.mean(dim=-1).unsqueeze(-1)
# 2. 计算奖励(不参与计算图)
with torch.no_grad():
sequences = [tokenizer.decode(ids) for ids in output_ids]
rewards = compute_rewards(sequences)
# 3. 计算损失
neg_advantage = (-normalized_log_probs * rewards.unsqueeze(-1)).mean()
loss = neg_advantage + KL_FACTOR * normalized_kl_div.mean()KL 惩罚的效果:从实验观察
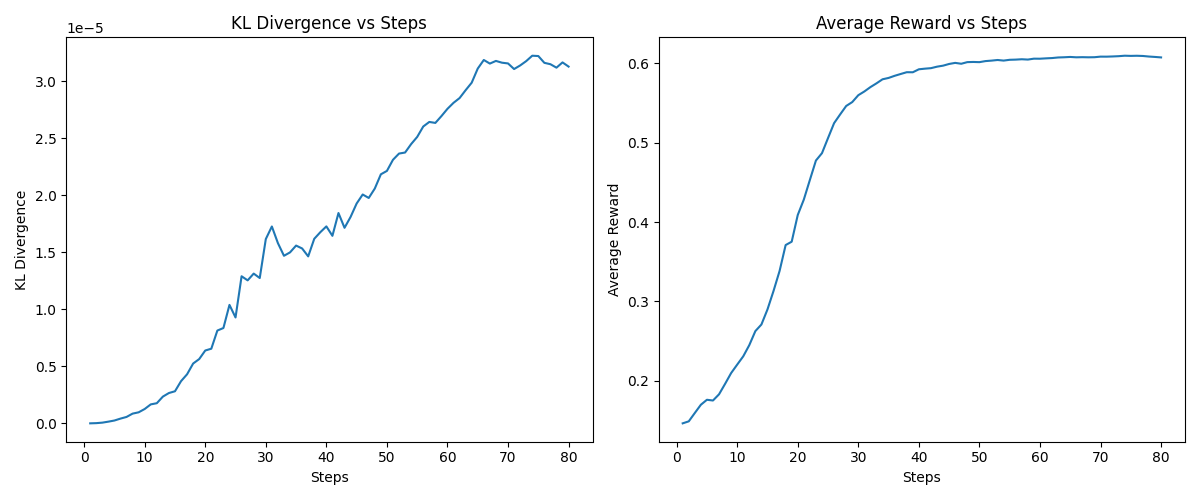
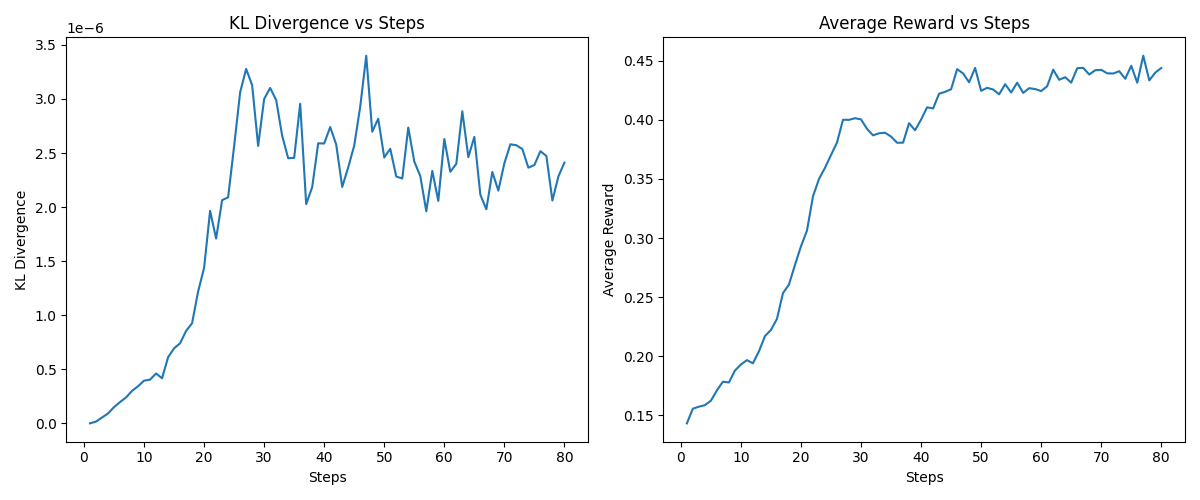
(无 KL 约束):奖励快速上升,但模型可能退化为只输出与"cat"语义相似的固定模式,丧失语言多样性。 :奖励提升更平稳,KL 散度被控制在合理范围内,模型在"谈论猫"的同时保留了故事生成的基本能力。
对比理解:简单 REINFORCE vs PPO4LLM
本 Demo 使用的是最简单的 REINFORCE:序列级单一回报,
PPO4LLM 则更精细:
- 逐 token 密集奖励:
,最后一步叠加 。 - 基于 GAE 计算优势:
,通过价值函数提供基线,降低方差。 - 使用 PPO 的 clip 机制限制单步更新幅度,避免策略剧烈变化。
Online On-Policy 训练范式
- Online(在线):每个 epoch 都用当前参数的策略直接采样新故事,立即用回报计算梯度并更新参数。没有预先固定的数据集或经验回放缓冲区。
- On-Policy(同策略):轨迹由当前策略
逐 token 采样得到,损失里用的正是这些 token 的 。不复用旧策略的样本,不做重要性采样修正。
代码中采样
计算 reward 反传更新是一气呵成的 online 交互流程,没有 replay buffer。
11.5 类比与 Insights:对齐方法的哲学思考
从能力空间的维度诅咒出发,思考当前对齐方法的根本局限与哲学启示。
RL 训练数据的本质
RL 对齐中使用的高质量数据,本质上是"蒸馏的人类专家"。在数学和代码领域,许多数据集既是 Benchmark 又是训练集:
- 数学:AIME、IMO 问题
- 代码:Codeforces、SWE-bench
- 综合:HLE(Hard Language Evaluation)
这些数据集凝结了人类专家在特定领域的最高水平表现。RL 通过奖励信号将这种专家级表现蒸馏进模型参数。
能力空间的维度诅咒
"数学推理能力"并非一条一维的线,而是一个高维空间。假设
每次用某类数据(如 Codeforces/IMO)做 RL,本质上只是在这个
想用"一个任务
其中
这就是维度灾难——需要百万量级的专项训练才能覆盖 20 维能力空间,这在实践中基本不可行。
核心启示:当前 RL 对齐在提升某类特定能力上效果显著(补丁策略),但通用推理能力的全面提升仍然是开放问题。单靠增加任务种类无法逾越维度诅咒——未来可能需要的是更高效的能力泛化机制,而非更多的补丁。
本章小结
| 方法 | 数学本质 | 分布特征 | 核心优势 | 主要风险 |
|---|---|---|---|---|
| SFT | Forward KL | 宽而平(Mode Covering) | 保留多样性 | 长尾幻觉 |
| RL (RLHF) | Reverse KL | 窄而尖(Mode Seeking) | 高奖励性能 | 奖励黑客 / 分布坍缩 |
| Constitutional AI | RLAIF + PPO | 受宪法约束的 Reverse KL | 无需人工标注 | FM 准确性依赖 |
| RFT | 拒绝采样 + SFT | 离线筛选的自我蒸馏 | 天然抗遗忘 | 计算开销(N 次生成) |
对齐的核心张力始终存在:SFT 的多样性保留 vs RL 的性能聚焦。两种方法在对抗幻觉和防止能力退化方面各有优劣,实践中通常需要组合使用——先 SFT 建立基础分布,再 RL 精调高价值方向,用 KL 约束维持两者的平衡。
延伸阅读
- Anthropic Constitutional AI 博文:https://huggingface.co/blog/constitutional_ai
- Anthropic Claude's Constitution:https://www.anthropic.com/news/claudes-constitution
- RFT 抗遗忘论文:Reinforcement Fine-Tuning Naturally Mitigates Forgetting in Continual Post-Training(arXiv: 2507.05386)
- SFT 遗忘修复:RL Fine-Tuning Heals OOD Forgetting in SFT(arXiv: 2509.12235)——详见 11.3 节"OOD 遗忘"部分
- TinyStories 对齐 Demo:https://philliphaeusler.com/posts/aligning_tinystories/
- TinyStories 论文:TinyStories: How Small Can Language Models Be and Still Speak Coherent English?(arXiv: 2305.07759)
- HuggingFace 深度 RL 课程 Policy Gradient 章节:https://huggingface.co/learn/deep-rl-course/unit4/policy-gradient