第 1 章:概率统计与贝叶斯推断
生成式 AI 的每一步都在与不确定性打交道——语言模型逐 token 采样、VAE 从隐空间生成样本、扩散模型迭代去噪。支撑这些方法的统一语言是概率论。本章从最基础的随机变量出发,经由 MLE、贝叶斯推断、指数族分布,最终到达马尔可夫链与统计建模,为后续章节搭建完整的数学地基。
1.1 概率基础:随机变量、分布、期望与方差
本节目标:掌握概率论的基本词汇——随机变量、概率分布、联合与条件概率、期望与方差,并建立从数学定义到物理直觉的桥梁。
随机变量与概率分布
随机变量(random variable)是从样本空间
概率分布描述随机变量取各个值的可能性。根据取值空间的不同,分为两类:
| 类型 | 取值方式 | 典型分布 | AI 中的对应 |
|---|---|---|---|
| 离散型 | 取值可数 | Bernoulli、Categorical | token 预测的 softmax 输出 |
| 连续型 | 取值连续 | Gaussian、Beta | VAE 的隐变量 |
对离散型随机变量,分布由概率质量函数(PMF)
联合分布与条件分布
当我们同时关心多个随机变量时,需要联合分布
直觉:条件概率是在"已知
边际概率(marginal probability)通过对联合分布中的一个变量求和(或积分)得到:
这一操作称为边际化(marginalization),在贝叶斯推断中频繁出现(详见 1.3 节)。
轨迹的联合概率分解
条件概率的连乘分解在深度学习中无处不在。以强化学习为例,一条轨迹(trajectory)
其中:
是 policy,由 agent 控制,参数为 是 transition,由环境决定,agent 无法改变
这一分解把"优化轨迹"转化为"优化 policy 参数
期望与方差
期望(expectation)是分布的"重心",描述随机变量的平均行为:
方差(variance)度量数据围绕均值的散布程度:
方差的平方根
Z-score 标准化
不同量纲的数值无法直接比较。Z-score 将数据映射到"距离均值有多少个标准差"的统一尺度:
:恰好处于平均水平 :高于平均(正数越大越优秀) :低于平均
示例:小明数学 85 分(班级均值 90,标准差 5),小红英语 70 分(均值 60,标准差 10)。
# Z-score 跨科目成绩比较
z_xiaoming = (85 - 90) / 5 # = -1.0(低于数学平均 1 个标准差)
z_xiaohong = (70 - 60) / 10 # = +1.0(高于英语平均 1 个标准差)
# 原始分数看小明更高,标准化后小红表现更优Z-score 消除了"科目难度"和"评分尺度"的影响,使跨量纲比较成为可能。在深度学习中,Layer Normalization 本质上就是对每一层的激活值做 Z-score 变换(详见 1.6 节)。
1.2 似然与概率:MLE 参数估计
本节目标:区分似然与概率这两个易混淆的概念,理解最大似然估计(MLE)如何从数据中学习参数,以及对数技巧为何不可或缺。
似然 vs. 概率
同一个公式
- 概率:参数
固定, 变化——"在这个模型下,数据 出现的可能性多大?" - 似然:数据
固定, 变化——"观测到这批数据,哪个参数最合理?"
数学上
最大似然估计
给定
直觉:在所有可能的参数中,MLE 选择那个让"已观测数据出现概率最大"的参数。掷一枚硬币 100 次得到 70 次正面,MLE 给出的正面概率估计就是
对数技巧:化积为和
直接优化连乘存在致命的数值问题——大量小概率相乘导致下溢(underflow)。因为对数是严格单调递增函数,最大化
这就是对数似然(log-likelihood)。将乘法转化为加法不仅解决数值稳定性问题,还让梯度计算变得简洁:
历史上,对数最初就是为了简化天文学中的大数乘法运算而发明的——通过查对数表,将乘法变为查表后的加法。这一"化积为和"的思想在现代机器学习中同样是核心工具。
MLE 与语言模型的联系
在 LLM 训练中,cross-entropy loss 就是负对数似然(NLL)取平均:
最小化 cross-entropy = 最大化对数似然 = MLE。三者是同一件事的不同表述——LLM 的预训练目标本质上就是在做最大似然估计。
1.3 贝叶斯定理与贝叶斯推断
本节目标:理解贝叶斯定理的四要素(先验、似然、证据、后验),掌握几率(odds)形式的贝叶斯更新规则,认识后验计算的困难及其近似方法。
贝叶斯定理
从条件概率的定义出发,
四个要素各有角色:
| 符号 | 名称 | 含义 |
|---|---|---|
| 先验(Prior) | 在看到数据前,对隐变量 | |
| 似然(Likelihood) | 给定 | |
| 证据(Evidence) | 数据在所有可能 | |
| 后验(Posterior) | 看到数据 |
一句话概括:后验
几率形式的贝叶斯更新
几率(odds)是事件发生与不发生的比值:
概率的范围是
对假设
取对数(再次运用化积为和性质):
直觉:每次观测到新证据
后验计算的困难
分母
为了绕过这个困难,发展出两类近似推断方法:
- 变分推断(Variational Inference):用一个简单的参数化分布
去近似真实后验 ,将积分问题转化为优化问题。这是 VAE 的理论基础(详见第 3 章)。 - MCMC 采样:构造一条马尔可夫链,使其稳态分布恰好是目标后验,通过长时间运行链来获得后验样本(详见 1.5 节)。
1.4 指数族分布与对数技巧
本节目标:理解指数与对数的直觉含义,掌握对数在 AI 中的三大核心用途,了解指数族分布的统一形式。
指数的直觉:增长的增长
指数描述的是复合增长。初始本金
反过来问"从
对数衡量的是达到某个规模所需付出的努力。在概率的语境下,
历史上,对数最早的实际应用之一是对数查找表:要计算
对数在 AI 中的三大用途
用途一:数值稳定性
大量小概率连乘导致浮点下溢。在对数空间中工作(log-probabilities),乘法变为加法,数值稳定得多。
用途二:化积为和——MLE 与 cross-entropy
对数似然将 MLE 的连乘优化转化为求和优化,使得梯度计算成为可能(详见 1.2 节)。
用途三:对数导数技巧(log-derivative trick)
等价地:
这一恒等式被称为 score function 技巧。它让我们可以将"对概率分布的梯度"转化为"对数概率的期望",从而用采样来估计梯度——这是 REINFORCE 算法和 Policy Gradient 方法的数学基石。
指数族分布
许多常见分布——正态分布、伯努利分布、泊松分布、指数分布、Beta 分布——可以写成统一的指数族(exponential family)形式:
各部分的含义:
| 符号 | 名称 | 作用 |
|---|---|---|
| 充分统计量(Sufficient Statistic) | 数据中与参数有关的全部信息 | |
| 自然参数(Natural Parameter) | 参数的标准化表示 | |
| 对数配分函数(Log-Partition Function) | 确保分布归一化 | |
| 基准测度(Base Measure) | 与参数无关的缩放因子 |
指数族分布的两个重要性质:
- MLE 有解析解:MLE 估计量只依赖充分统计量
的样本均值,计算高效。 - 与对数天然兼容:取对数后,指数族变为
的线性形式,这是广义线性模型(GLM)的理论基础。
1.5 马尔可夫链与稳态分布
本节目标:理解马尔可夫链的无记忆性和转移矩阵,掌握稳态分布的存在性、唯一性判断及两种求解方法,通过三个典型案例建立直觉,并理解稳态分布在 MCMC 采样中的作用。
马尔可夫性质
马尔可夫链的核心假设是无记忆性(Markov property)——下一状态只依赖当前状态,与更早的历史无关:
系统的全部动态行为被编码在转移矩阵
稳态分布
如果经过一次状态转移后,概率分布保持不变,则该分布称为稳态分布(stationary distribution)
从线性代数的角度看,
根据 Perron-Frobenius 定理,有限状态的随机矩阵一定有至少一个等于 1 的特征值,因此稳态分布总是存在。但是否唯一、系统是否收敛,取决于链的结构。
案例一:存在且唯一
考虑 5 个状态的马尔可夫链:
手动求解
(A 列全为 0,无状态转入 A) ,得 ,即 - 归一化后:
方法一:特征值分解法(精确,通用)
import numpy as np
P = np.array([
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0.5, 0, 0.5, 0],
[0, 0, 1, 0, 0],
[0, 0.1, 0, 0, 0.9]
])
eigenvalues, eigenvectors = np.linalg.eig(P.T)
idx = np.argmin(np.abs(eigenvalues - 1))
pi = eigenvectors[:, idx]
pi = (pi / pi.sum()).real
print("特征值:", np.round(eigenvalues, 2))
print("稳态分布:", np.round(pi, 4))输出:
特征值: [ 1.+0.j -0.5+0.5j -0.5-0.5j 0.+0.j 0.9+0.j]
稳态分布: [-0. 0.2 0.4 0.4 -0. ]特征值
方法二:矩阵幂迭代法(直观,模拟长期运行)
P_n = np.linalg.matrix_power(P, 1000)
pi_power = P_n[0] # 当 n 足够大时,每行趋近于稳态分布直觉:反复应用转移矩阵,等价于让系统运行足够长时间,最终分布趋于稳态。
案例二:存在但不唯一
P = np.array([
[0, 0.5, 0, 0.5],
[0, 0, 1, 0 ],
[0, 1, 0, 0 ],
[0, 0, 0, 1 ]
])
eigenvalues, _ = np.linalg.eig(P.T)
print("特征值:", np.round(eigenvalues, 2))输出:[ 1. -1. 1. 0.]——两个特征值等于 1,稳态分布不唯一。
原因:链存在两个互不相通的吸收集——{B, C} 形成循环(
P_100 = np.linalg.matrix_power(P, 100)
P_101 = np.linalg.matrix_power(P, 101)
print("P^100:\n", P_100)
print("P^101:\n", P_101)输出:
P^100:
[[0. 0. 0.5 0.5] <- 从 A 出发:50% 在 {B,C},50% 在 D
[0. 1. 0. 0. ] <- 从 B 出发:偶数步回到 B
[0. 0. 1. 0. ] <- 从 C 出发:偶数步回到 C
[0. 0. 0. 1. ]] <- 从 D 出发:始终在 D
P^101:
[[0. 0.5 0. 0.5] <- 奇数步和偶数步结果不同
[0. 0. 1. 0. ]
[0. 1. 0. 0. ]
[0. 0. 0. 1. ]]不同行趋近于不同的分布,且奇偶步交替振荡——这正是多吸收集加周期性的表现。
案例三:存在稳态分布但不收敛
最简单的周期链
P = np.array([[0, 1], [1, 0]])
eigenvalues, _ = np.linalg.eig(P.T)
print("特征值:", eigenvalues) # [1. -1.]
P_100 = np.linalg.matrix_power(P, 100) # [[1, 0], [0, 1]](偶数步:回到原位)
P_101 = np.linalg.matrix_power(P, 101) # [[0, 1], [1, 0]](奇数步:对换)稳态分布
三个案例的总结
| 情况 | 特征值 | 链的性质 | 结论 |
|---|---|---|---|
| 存在且唯一 | 恰好 1 个 | 不可约 + 非周期(遍历,ergodic) | |
| 存在不唯一 | 大于 1 个 | 可约(有多个吸收集) | 稳态取决于初始分布 |
| 不收敛 | 1 个,但有 | 周期 > 1 |
关键认识:"存在稳态分布"
"系统会收敛到稳态分布"。只有同时满足不可约性和非周期性(合称遍历性)的链,才保证从任意初始分布出发都收敛到唯一的稳态。
与 MCMC 采样的联系
MCMC(Markov Chain Monte Carlo)正是利用了上述理论:设计一个转移核,使其稳态分布恰好是目标后验
1.6 统计建模概述
本节目标:建立"用均值和方差压缩描述数据规律"的统计建模思维,理解正态分布的中心地位及其在深度学习中的应用,将 MLE 与贝叶斯推断统一到参数估计的框架中。
统计建模思维:
面对大量数据,统计建模的第一步是用少量参数概括其规律。最基本的两个参数:
- 均值
:群体的平均水平,分布的"重心" - 标准差
(或方差 ):数据的波动程度,分布的"宽度"
直觉:
正态分布
当用
直觉:正态分布是一个以
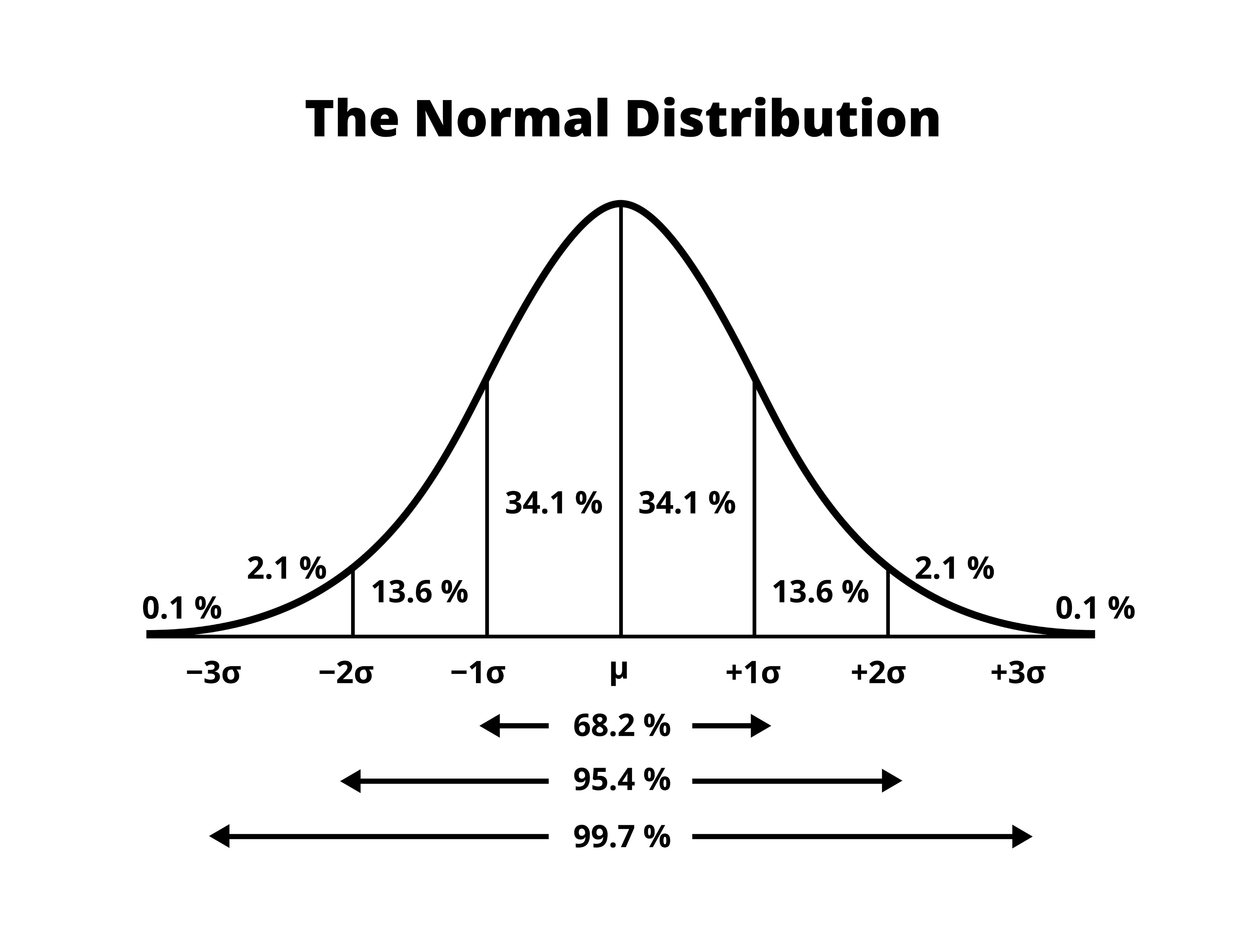
正态分布的中心地位来自中心极限定理(CLT):在温和条件下,大量独立随机变量之和(或均值)的分布趋向正态分布,无论原始变量服从何种分布。这解释了为什么正态分布在自然界和工程中无处不在——很多宏观现象是大量微观独立因素叠加的结果。
正态分布在深度学习中的角色
| 场景 | 使用方式 |
|---|---|
| 权重初始化 | Xavier/Kaiming 初始化从正态分布采样,标准差依赖于层的输入/输出维度 |
| VAE 先验 | |
| 扩散模型 | 前向过程每步添加高斯噪声 |
| Layer Normalization | 将激活值标准化为近似 |
从描述到推断:MLE 与贝叶斯的统一视角
统计建模不只是描述数据,更重要的是在参数空间中搜索最佳描述。这就回到了 MLE(1.2 节)和贝叶斯推断(1.3 节):
- MLE 回答:"哪个参数值最合理?"——给出一个点估计
- 贝叶斯推断 回答:"参数值有多不确定?"——给出一个完整的后验分布
当数据量足够大时,贝叶斯后验集中在 MLE 估计附近,两者趋于一致。贝叶斯方法的优势在数据稀少或需要量化不确定性时更加显著。
本章小结
本章建立了生成式 AI 的概率论基础。核心概念与应用的对应关系如下:
| 概念 | 核心公式 | 在 AI 中的应用 |
|---|---|---|
| 条件概率 | 策略 | |
| MLE | LLM 预训练目标(cross-entropy loss) | |
| 贝叶斯定理 | 后验 | VAE、贝叶斯神经网络 |
| 对数导数技巧 | Policy Gradient、REINFORCE | |
| 指数族分布 | 广义线性模型、自然梯度 | |
| 稳态分布 | MCMC 采样、扩散模型 | |
| Z-score 标准化 | Layer Normalization、特征预处理 |
三条贯穿全书的核心直觉:
- 对数将乘法变为加法——从 MLE 的对数似然,到贝叶斯的对数几率更新,再到 policy gradient 的 log-derivative trick 和 ELBO 的推导,对数技巧是所有概率推导的基础工具。
- 贝叶斯思维是序贯信念更新——每观测到新数据,后验 = 似然
先验,不断修正对世界的认识。这一思想贯穿 VAE、强化学习中的 reward shaping 以及 LLM 对齐。 - 均值和方差是描述分布最经济的方式——正态分布的普适性来自中心极限定理,标准化操作(Z-score、Layer Norm)在整个深度学习流程中无处不在。
延伸阅读
- 概率论与贝叶斯推断:Christopher Bishop, Pattern Recognition and Machine Learning(PRML),第 1-2 章。对概率分布、贝叶斯推断和指数族分布有深入而清晰的阐述。
- 信息论视角:David MacKay, Information Theory, Inference, and Learning Algorithms。开源免费,从信息论角度理解概率和推断,对理解交叉熵、KL 散度等概念极有帮助。
- MCMC 方法:Radford Neal, "MCMC Using Hamiltonian Dynamics"。HMC 方法的经典综述,为理解扩散模型的采样过程提供理论背景。
- Policy Gradient 的数学起源:Ronald J. Williams (1992), "Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning"。REINFORCE 原始论文,对数导数技巧的首次系统应用。
- 指数族与自然梯度:Shun-ichi Amari, "Natural Gradient Works Efficiently in Learning"。从信息几何角度解释指数族分布在优化中的特殊地位。