第 12 章:推理增强与 RLVR
本章导读
大型语言模型在数学推理和代码生成等领域的"思考"能力,已经从简单的 Chain-of-Thought 提示发展到以 RL with Verifiable Rewards(RLVR)为代表的系统性训练范式。然而,RL 究竟是在"教会模型新能力"还是仅仅在"磨快已有的刀"?KL 散度惩罚的不同估计器在训练中会产生截然不同的效果——选错估计器可能导致梯度信号为零或方差爆炸。训练框架与推理框架之间毫秒级的数值差异,在数千 token 的长链条中如何被指数级放大?
本章从理论推导到工程实现,逐一拆解这些问题。
12.1 推理增强总览:从 CoT 到 RLVR
从 CoT 提示到 RLVR 训练的方法谱系,以及 RL 究竟是分布削尖还是能力提升的关键质疑。
方法谱系
推理增强方法可以按"奖励信号的来源"排列:
| 方法 | 奖励来源 | 特点 |
|---|---|---|
| CoT(Chain-of-Thought) | 无(提示工程) | 零成本,但依赖模型已有能力 |
| SFT on CoT 数据 | 人工标注推理路径 | 数据成本高,质量天花板由标注者决定 |
| RLHF | 人类偏好模型 | 奖励模型本身存在偏差,难以精确评估推理正确性 |
| RFT(Rejection Fine-Tuning) | 拒绝采样 + SFT | 只保留正确回答做 SFT,不涉及策略梯度 |
| RLVR | 可验证奖励(规则/验证器) | 奖励信号客观、无人为偏差,适用于数学/代码 |
RLVR 的核心思想:对于存在客观答案的任务(数学、代码),直接用验证器判断答案正误作为奖励信号,绕过人类偏好标注。DeepSeek-R1 的 GRPO 和后续的 DAPO 等算法都属于这一路线。
RL 到底在做什么?——一个关键质疑
"RL shifted the probability distribution and increased the probability of an otherwise less common correct answer trajectory."
论文 "Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?"(LeapLabTHU)通过大规模实验给出了三个结论:
- RL(RL-zero)仅仅是提升了采样效率,但远未"榨干"基座模型的潜力。
- RL 做的是 Distribution Sharpening(分布削尖),而非 Capability Uplift(能力提升)——RL 并没有让模型学会"做它以前不会做的题",而是让模型"更倾向于输出它以前偶尔能做对的答案"。
- RL 压缩了探索空间,对于那些低概率但原本能做对的题,RL 模型反而因为过拟合高奖励路径而彻底丧失了解题能力。
为什么会这样?可以从多个分析轴来理解 Distribution Sharpening 的内在机制。
Token Space 视角:经过充分预训练的基座模型,其 token 级别的条件分布已经高度集中。这意味着在每一步生成时,模型可供"探索"的有效空间非常有限——大部分概率质量已经集中在少数几个 token 上。RL 的策略梯度本质上依赖采样来发现新路径,但当基座模型的分布本身已经很尖锐时,采样几乎不可能跳出已有的高概率轨迹,进入全新的推理模式。换言之,RL 的探索空间被基座模型的预训练质量所"封顶"。
PPL 分析:实验中计算 Base Model 对 RL 模型生成内容的困惑度
尖峰分布与 KL 散度趋势:RL 训练的过程可以理解为持续压低策略分布的熵——将概率质量从多条可能的推理路径集中到少数高奖励路径上。从 KL 散度的角度看,
Temperature 效应:Temperature 参数直接控制采样时分布的尖锐程度。对于已经经过 RL Sharpening 的模型,降低 Temperature 会进一步放大尖峰效应,几乎退化为贪心解码;而提高 Temperature 虽然理论上能恢复多样性,但由于 RL 已经在权重层面重塑了分布的形状,仅靠推理时调温无法找回训练中被抹去的低概率路径。这也解释了为什么 RL 模型的 pass@k 曲线增长显著慢于 Base Model——分布的多样性已经在训练阶段被不可逆地压缩了。
这一发现并不否定 RLVR 的实用价值——从工程角度看,提升采样效率(pass@1)本身就是极其重要的。但它提醒我们:RL 的主要贡献是"把正确答案推到更高概率",而非"让模型获得新的推理能力"。
蒸馏的不同:与 RL 不同,蒸馏(如 DeepSeek-R1-Distill)模型的 pass@k 曲线完全包围 Base Model 的曲线——蒸馏通过引入 Teacher 的知识,确实扩展了模型的推理边界。这一对比进一步印证了 Distribution Sharpening 的本质:RL 只在已有分布内做"重排序",而蒸馏通过知识迁移真正引入了新的推理模式。
12.2 RLVR(RL with Verifiable Rewards)详解
RLVR 的核心机制:可验证奖励的设计、GRPO 算法细节与 Advantage 归一化策略。
核心评估指标
pass@k
从
其中
展开组合数,数值稳定的计算方式为:
import numpy as np
import math
def pass_at_k(n, c, k):
"""数值稳定版本:避免直接计算大组合数"""
if n - c < k:
return 1.0
return 1.0 - np.prod(1.0 - k / np.arange(n - c + 1, n + 1))
# 等价的精确版本(适合 n 较小时)
def pass_at_k_exact(n, c, k):
if n - c < k:
return 1.0
return 1 - math.comb(n - c, k) / math.comb(n, k)直觉:如果 5 个样本里有 1 个正确,抽 3 个至少中一个的概率是 0.6——
pass_at_k(5, 1, 3)返回 0.6。
最终的数据集级指标是对所有
困惑度(Perplexity)
衡量 Base Model 对 RL 模型生成内容的"意外程度":
PPL 是联合概率几何平均的倒数。几何平均避免了联合概率随序列变长自然衰减的问题。
- 均匀猜测(每个 token 概率
): (最大困惑,相当于在整个词表中随机选) - 分布极度尖锐:
(完全确定) - PPL 为
:模型在每一步平均相当于在 种可能性中均匀且独立地选择
实验中若
采样效率差距(Sampling Efficiency Gap)
将 Base Model 采样
实验复现:Base Model 评估
Math 分支:MinervaMath
以 MinervaMath(272 道题)为数据集,每题采样 32 次,评估 Qwen2.5-7B Base Model:
# 使用与 RLVR 训练一致的 chat template(非默认 tokenizer.apply_chat_template)
prompt_temp = (
"<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n"
"<|im_start|>user\n{input}\nPlease reason step by step, "
"and put your final answer within \\boxed{{}}.<|im_end|>\n"
"<|im_start|>assistant\n",
"{output}",
"\n\n",
)
n_sampling = 32
sampling_params = SamplingParams(
temperature=0.6, top_p=0.95,
max_tokens=16000, n=1,
)结果:
{
"acc": 23.2,
"pass_acc": 58.5,
"pass@k": {
"1": 23.2, "2": 32.3, "4": 40.9,
"8": 48.2, "16": 53.9, "32": 58.5
}
}pass@1 = 23.2% vs pass@32 = 58.5%——Base Model 有远超"一次采样"所表现出的潜力,但需要多次采样才能挖掘。RL 的目标正是缩小这个差距。
Coding 分支:DeepCoder
除数学推理外,论文同时在代码生成任务上验证了相同的结论。Coding 分支使用 DeepCoder 框架,基于竞赛编程题目评估模型的代码生成能力。
与数学分支的关键差异在于 Reward 函数的设计:数学任务通过字符串匹配判断最终答案的正误(binary reward),而代码任务则通过执行测试用例来验证程序的功能正确性——模型生成的代码需要通过预定义的输入-输出测试对,Reward 信号来自测试通过率。这种基于执行的验证方式是 RLVR 在代码领域的天然优势:测试用例提供了完全客观、无人为偏差的奖励信号。
实验结果与数学分支高度一致:RL 训练后模型的 pass@1 显著提升,但 pass@k 曲线仍然被 Base Model 的大规模采样所覆盖。这说明 Distribution Sharpening 而非 Capability Uplift 的结论具有跨任务的普适性——无论是数学推理还是代码生成,RL 的核心作用都是在基座模型已有的能力边界内提升采样效率。
PPL 计算的工程实现
def calculate_perplexity(llm, prompts, responses):
full_texts = [p + r for p, r in zip(prompts, responses)]
# prompt_logprobs=1: 返回每个位置的 top-1 token logprob
# max_tokens=1: 仅做评估,不生成新 token
eval_params = SamplingParams(prompt_logprobs=1, max_tokens=1, temperature=1.0)
outputs = llm.generate(full_texts, eval_params)
tokenizer = llm.get_tokenizer()
ppl_scores = []
for i, output in enumerate(outputs):
# 确定 Response 起始位置(Masking Prompt)
prompt_token_ids = tokenizer.encode(prompts[i], add_special_tokens=False)
start_idx = len(prompt_token_ids)
response_log_probs = []
for step, logprob_dict in enumerate(output.prompt_logprobs[start_idx:], start=start_idx):
if logprob_dict is None:
continue
actual_token_id = output.prompt_token_ids[step]
response_log_probs.append(logprob_dict[actual_token_id].logprob)
if response_log_probs:
ppl = np.exp(-np.mean(response_log_probs))
ppl_scores.append(ppl)
return ppl_scores关键实现细节:必须将 Prompt 和 Response 拼接后一次性输入 vLLM,通过
prompt_logprobs获取每个位置的 logprob,再用 Prompt 长度做偏移来提取 Response 部分。
12.3 KL 散度深度回顾:数值内涵与训练中的角色
KL 散度的四种估计器对比——选错估计器可能导致梯度信号为零或方差爆炸。
KL 散度的含义:从信息论到 LLM
KL 散度的信息论分解:
其中
KL 与 PPL 的关系:
直觉:如果 KL = 0.2 nats/token,那么交叉困惑度比自困惑度大
倍——模型 在预测每个 token 时,面临的有效选择数比"最优编码"多出约 22%。
import torch
import torch.nn.functional as F
p = torch.tensor([0.9, 0.1], dtype=torch.float64)
q = torch.tensor([0.8, 0.2], dtype=torch.float64)
H_P = -(p * p.log()).sum() # 真分布的熵
H_PQ = -(p * q.log()).sum() # 交叉熵
KL_PQ = (p * (p.log() - q.log())).sum()
print(f"exp(H(P,Q) - H(P)) = {torch.exp(H_PQ - H_P).item():.4f}")
print(f"exp(KL(P||Q)) = {torch.exp(KL_PQ).item():.4f}")
# 两者相等:1.0374实践中 RL 训练的 per-token KL 通常在 0 ~ 0.2 nats 之间。KL 的单位是 nats/token(使用自然对数时),计算发生在词表空间上:
log_q = log_softmax(logits, dim=-1) # 当前模型 Q
log_p = log_softmax(ref_logits, dim=-1) # 参考模型 P
# D_KL(P || Q) = sum_v P(v) * [log P(v) - log Q(v)]
kl = F.kl_div(log_q, log_p, reduction="none", log_target=True)注意:
F.kl_div计算的是 Forward KL,惩罚"当前模型 在参考模型 有概率质量的地方给得太低"——典型的 Mode-Covering 倾向。
Forward KL vs Reverse KL
| Forward KL | Reverse KL | |
|---|---|---|
| 采样来源 | 从 | 从 |
| 行为倾向 | Mode-Covering( | Mode-Seeking( |
| 典型应用 | 监督学习、蒸馏 | 最大熵 RL、RLHF |
| 直觉 | 像"模仿/监督":从 | 像"带正则的反馈学习":从 |
为何无法精确计算 KL
对于 LLM,样本空间
由于
代码中计算的 (log_probs - ref_log_probs) 就是一个 [Batch_Size, Sequence_Length] 的张量。
三种 KL 估计器
设
K1 估计器(PPO 标准,朴素估计)
- 无偏:
- 高方差:数值波动大
- 致命缺陷——可负性:当
时 ,KL 惩罚( )变成了正向奖励,鼓励模型继续偏离
K2 估计器
- 方差最小
- 其期望不等于 KL 值(估计的是 KL 的二阶矩),但 Liu et al. 证明其梯度对于 Reverse KL 是无偏的
K3 估计器(GRPO/Schulman 估计器)
基于凸函数不等式
- 恒正性:KL 惩罚永远是惩罚,不会翻转成奖励
- 低方差(在两分布接近时)
( )附近的泰勒展开: ,与 KL 的二阶近似一致 - 方差陷阱:当
时, ,方差爆炸

图示:
与 。 在 时为负值(参考模型概率更高时), 始终非负,最小值在 处取到 0。
实验验证:当
# P = N(0, 1), Q = N(0.1, 0.2) — Q 更窄(模型过度自信/坍缩)
# 采样 10000 点| Estimator | Sample Mean | True KL | Estimator Bias | Std Dev |
|---|---|---|---|---|
| k1 (PPO) | 1.1303 | 1.1344 | -0.0041 | 0.6739 |
| k2 (RKL-Loss) | 0.8658 | (Not KL) | N/A | 0.5688 |
| k3 (GRPO) | 0.7749 | 1.1344 | -0.3595 | 9.8543 |
K1 作为 Reverse KL 的估计器几乎无偏(Estimator Bias 仅 -0.004),K3 的标准差是 K1 的 14.6 倍。
"Bias" 的两层含义辨析:在 KL 估计器的讨论中,"bias" 一词涉及两个不同层面的概念,需要明确区分:
估计器偏差(Statistical Estimator Bias):
,即估计器期望值与真实 KL 值之间的差距。上表中的 "Estimator Bias" 列正是这一含义——K1 是 Reverse KL 的无偏估计器,而 K3 的样本均值系统性地偏离真实 KL 值。 梯度方向的语义(Gradient Semantics):即便 K3 作为 KL 值的估计器是有偏的,其梯度
的期望却等价于 Forward KL 的梯度(详见下节推导)。这意味着 K3 in Loss 虽然"估计的不是 Reverse KL",但其优化方向具有明确的物理意义——Mode-Covering 蒸馏。将这种梯度语义上的"不匹配"笼统地称为"有偏"容易造成误解:K3 in Loss 并非在优化一个"错误的目标",而是在优化一个"不同但合理的目标"。
KL 的两种使用场景与梯度分析
这一部分是理解 KL 惩罚的核心:同一个估计器,放在 Reward 里和放在 Loss 里,产生的梯度完全不同。
梯度的两种计算方式
- Score Function Estimator(REINFORCE):不需要
可导,只依赖结果(Reward)和概率。将 KL 放入 Reward 时使用。 - Path-wise Derivative(路径导数/自动求导):通过计算图精确追踪每一步的微分。将 KL 放入 Loss 时使用。
Reverse KL 的真实梯度
推导关键:对
求梯度时会出现两项。第二项中 ,只剩第一项。
K1 in Reward(Reverse KL 的无偏估计,正确做法)
这完全匹配 Reverse KL 梯度的定义。
K1 in Loss(灾难——期望梯度为零)
K1 直接放入 Loss 做自动微分时,期望梯度为 0——论文称之为 "Comedy",你只是在优化噪声。
K3 in Loss(作为 KL 估计器有偏,但梯度等价于 Forward KL 蒸馏)
K3 的梯度:
注意梯度系数是
取期望:
这正是 Forward KL
因此,K3 in Loss 的准确定位是:作为 Reverse KL 的值估计器,它是有偏的(
原论文的表述更为精确:K3 in Loss 的梯度估计是 token 级 Forward KL 散度的无偏梯度估计之和,使得该配置等价于"一个基于 Forward KL 的稳定 Logit 蒸馏目标,以 on-policy 方式训练,以 Base Model 为 Teacher"("equivalent to a stable forward KL-based logit distillation objective trained on-policy, with the base model as a teacher")。这解释了为何 K3 in Loss 在实践中表现出蒸馏般的稳定性。
K3 in Reward(危险——方差爆炸)
当
Off-Policy 下的 KL 偏差
在 GRPO 或 PPO 中,数据是旧策略
On-Policy KL 估计器
KL 散度的定义要求从当前策略
如果我们能从
这是无偏估计。但在 RL 训练的 mini-batch 更新中,样本
引入 Importance Sampling Ratio
为了在
因此,正确的 off-policy 无偏估计应为:
其中
不加 IS 修正的有偏估计
如果直接用旧策略样本计算 K3 而不加重要性采样权重:
偏差来源与实践影响
偏差的根本来源在于
然而,加入 IS 修正也并非没有代价:重要性采样比率
最佳实践总结
| 用法 | 推荐估计器 | 原因 |
|---|---|---|
| KL in Reward(PPO) | K1 | Reverse KL 的无偏估计器,梯度匹配 Reverse KL 定义 |
| KL in Loss(GRPO) | K3 | 恒正、稳定;作为 KL 值估计器有偏,但梯度等价于 Forward KL 蒸馏 |
| K1 in Loss | 禁止 | 期望梯度为 0,纯噪声 |
| K3 in Reward | 慎用 | 重要性比率项导致方差爆炸 |
12.4 Entropy 在训练中的作用
策略熵在训练中的双重角色:探索激励与模式坍缩的早期预警信号。
熵的定义与直觉
熵衡量策略的"随机性"或"多样性":
:策略完全确定(只输出一种答案),探索能力丧失 :策略完全随机(均匀分布在词表上),没有任何偏好
熵与 RL 优化的内在关系
在 Reverse KL 的损失分解中:
最小化
熵崩塌(Entropy Collapse)
RLVR 训练中最常见的失败模式之一。随着训练进行,模型输出熵单调下降,最终坍缩到只会生成少量固定模式,泛化能力完全丧失。
Output Token Entropy 的计算(每个 token 位置的平均香农熵):
def calculate_metrics(llm, prompts, responses, top_k_for_entropy=20):
full_texts = [p + r for p, r in zip(prompts, responses)]
# prompt_logprobs 需要设大(如 20)以获取分布信息
# 仅 top-1 无法计算熵,因为 H = -sum(p * log p) 需要分布
eval_params = SamplingParams(
prompt_logprobs=top_k_for_entropy,
max_tokens=1, temperature=1.0,
)
outputs = llm.generate(full_texts, eval_params)
tokenizer = llm.get_tokenizer()
ppl_scores, entropy_scores = [], []
for i, output in enumerate(outputs):
prompt_token_ids = tokenizer.encode(prompts[i], add_special_tokens=False)
start_idx = len(prompt_token_ids)
response_log_probs, step_entropies = [], []
for step, logprob_dict in enumerate(
output.prompt_logprobs[start_idx:], start=start_idx
):
if logprob_dict is None:
continue
actual_token_id = output.prompt_token_ids[step]
response_log_probs.append(logprob_dict[actual_token_id].logprob)
# 提取 Top-K 的 logprobs 计算当前步的熵
current_step_logprobs = np.array(
[lp.logprob for lp in logprob_dict.values()]
)
current_step_probs = np.exp(current_step_logprobs)
# H = -sum(p * log p)(Top-K 近似,概率和不一定为 1)
current_entropy = -np.sum(current_step_probs * current_step_logprobs)
step_entropies.append(current_entropy)
if response_log_probs:
ppl_scores.append(np.exp(-np.mean(response_log_probs)))
if step_entropies:
entropy_scores.append(np.mean(step_entropies))
return ppl_scores, entropy_scores实验中 Qwen2.5-7B Base Model 的平均 Token Entropy 约为 0.265 nats,可作为 RL 训练中监控熵崩塌的参考基准线。
12.5 训练-推理 Mismatch 问题
训练框架与推理框架之间的数值差异如何在长序列中被指数级放大。
问题来源
"训推一致"不仅仅是模型权重相同,而是指:同一套参数在训练框架和推理框架中前向传播出的 Log Probability 必须完全一致。
实际工程中,二者往往存在差异:
| 阶段 | 典型框架 | 特点 |
|---|---|---|
| Rollout(推理) | vLLM、TensorRT-LLM、自研推理引擎 | 追求吞吐量,可能使用 FP8/Int8 量化、特定 Kernel 优化、近似计算 |
| Update(训练) | PyTorch、Megatron | 追求梯度精度,使用 BF16 或 FP32 |
即使同一权重、同一输入,两个框架计算的 logprobs 也会有细微差异。在长 CoT 序列中(数千 tokens),这种微小的数值误差会随序列长度累积放大,导致重要性采样比率(
此外还有配置差异:训练时 Temperature=0.8,部署时 Temperature=1.0;Tokenizer 处理的细微差别等。
内存估算:为何需要分离训练与推理框架
一个直觉是:为何不在同一个框架中完成采样和更新?问题在于内存:
# 完整 logits 的显存估算 [Batch, Seq, Vocab]
32 * 2048 * 128000 * 4 / (1024**3) * 2 # ≈ 62.5 GB仅 logits 张量就需要 62.5 GB 显存,推理框架通过流式处理和 KV Cache 优化规避了这个问题,但这也引入了数值差异。
Kimi K2.5 的 Token-level Clipping 方案
Kimi K2.5 技术报告提出了一种直接有效的修复方法:
当任何一个 token 的概率比率超出
与标准 PPO Clipping 的关键区别:
- 标准 PPO:依赖 Advantage 的正负号决定是否截断(正 Advantage 时截上界,负 Advantage 时截下界)
- K2.5:仅依赖 Log-ratio,与 Advantage 无关。无论该 token 是"好"还是"坏",只要框架误差导致概率偏移过大,就强制停止更新
为何在长 CoT 下特别必要:一个长链可能包含数千个 token。如果不加限制,框架 Mismatch 导致的微小误差会在序列末端被指数级放大。Token-level Clipping 对每个 token 独立检查——即使某一步因框架误差导致比率异常,也只丢弃那一步的梯度,保留其他正常步骤的梯度。
12.6 Rewarding Unlikely:稀有 Token 的奖励问题
稀有 token 在 RLVR 中获得异常高奖励的机制及其缓解方案。
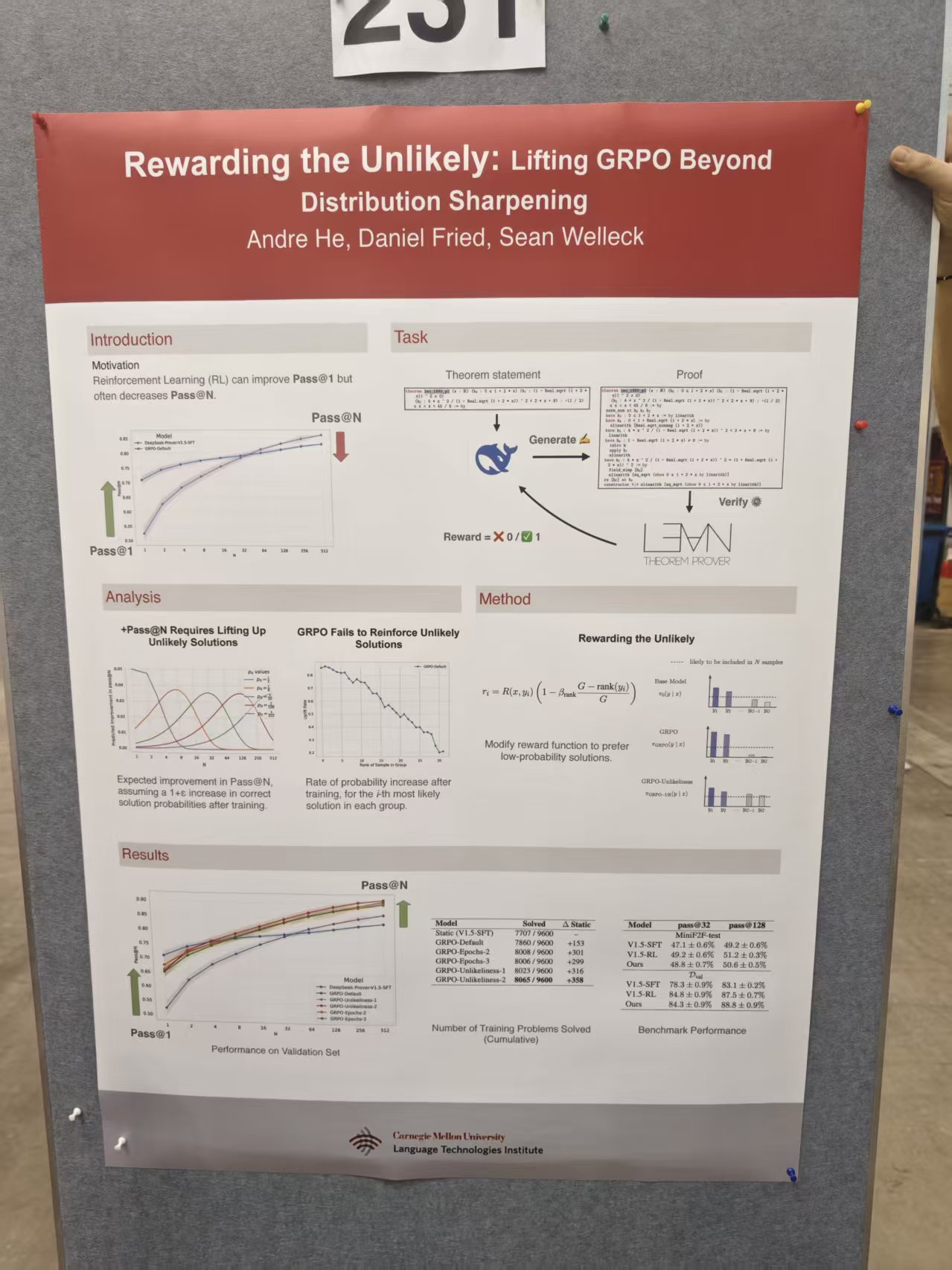
K3 在稀有 Token 上的梯度爆炸
当 RL 训练试图奖励"不常见但正确"的 token 时,若使用 K3 估计器,梯度系数为:
当
论文原文:"In such cases, the gradient of the K3 estimator assigns disproportionately large, unbounded weights to maximize the likelihood of these tokens..."
这意味着:K3 会给稀有 token 分配不成比例的巨大梯度权重,破坏训练稳定性。这个问题在 RLVR 场景中尤为突出——RL 恰恰应该鼓励模型探索那些低概率但正确的路径,而 K3 的这一特性恰好与之矛盾。
应对策略
- K1 in Reward:
,当 很小时 趋向 ,但作为 Reward 传入 REINFORCE 后梯度仍然有界 - Token-level Clipping(如 K2.5 方案):直接截断比率异常的 token
- 奖励设计:在 Reward Function 层面区分"稀有 token"与"高奖励 token",避免二者叠加引发数值爆炸
12.7 DeepSeek-Math v2 案例分析
DeepSeek-Math v2 的训练流程复盘:SFT、RL 与蒸馏各阶段的设计决策。
核心思路:用 Verifier 对抗 Reward Hacking
避免 RL 训练中 Reward Hacking 的核心方法:仔细观察 rollout,找出 hack 模式,然后在 Reward Function 中设计额外项来惩罚。
identify: look at your rollouts; solve: extra reward terms to penalize hack.
Generator-Verifier 是一个稳健高效的工作流:Iterative Verification & Refinement 的过程不断提升 generation 质量。关键在于 verification rubrics 需要依赖领域专家的构建。
三层 Verifier 架构
第一层:Initial Verifier
- 输入:问题
、模型生成的解答 、高级评分标准 (文本 prompt 驱动) - 输出:问题摘要 + 三档分数
- 训练数据:
,其中 由数学专家标注
给定
,RL 在线产生的是 ,与专家标注 对比计算 。
第二层:Meta-Verifier
- 输入:问题
、解答 、Verifier 输出 、Meta 评分标准 - 输出:Verifier 分析质量的评估 + 质量分数
- 训练数据:
, 为专家对 Verifier 输出 的打分 - RL 目标与 Verifier 训练结构相同
最终 Verifier 奖励
三重乘积确保形式规范、答案正确、分析质量三者同时达标。
Generator 训练
其中
自我验证(Self-Verification)
关键发现:模型有能力根据外部反馈修正错误(can refine based on external feedback),但缺乏自己发现错误的能力(fails to evaluate its own work)——尤其是当模型既充当"作者"又充当"检查员"时,做不到像外部专门检查员那样严厉和客观。
从 one-shot 走向 iterative verification & refinement,赋予 Proof Generator 真正的验证能力:
其中
12.8 Gemini Parallel Thinking
Gemini 的并行思考机制:同时生成多条推理路径并选取最优。
Gemini Deep Think 与 IMO 金牌
Google DeepMind 公布 Gemini Advanced(Deep Think 版)在国际数学奥林匹克(IMO)达到金牌标准。核心技术要素:
- 新颖的 RL 技术:利用更多的多步推理(Multi-step Reasoning)、问题求解和定理证明数据(Theorem-proving data) 进行训练
- 高质量数学解题语料:精心策划的高质量数学问题解法语料,而非仅依赖自动生成
- Parallel Thinking(并行思考):推理阶段并行生成多条思维链,再汇总最优结果
To make the most of the reasoning capabilities of Deep Think, we additionally trained this version of Gemini on novel reinforcement learning techniques that can leverage more multi-step reasoning, problem-solving and theorem-proving data.
POLARIS 配方
POLARIS(POst-training recipe for scaling reinforcement Learning on Advanced ReasonIng modelS)代表了当前推理增强的前沿方向:
- 在 RL 后训练阶段引入高质量、高难度的数学题和定理证明数据
- 扩展多步推理数据的规模
- Parallel Thinking 本质上是对 pass@k 思想的系统性工程化:通过并行采样多条推理路径并选取最优,将"多次采样才能找到正确答案"的能力在实际部署中兑现
本章小结
| 主题 | 核心结论 |
|---|---|
| RLVR 本质 | 分布削尖(Sharpening),提升采样效率,但不扩展推理边界 |
| pass@k 与 | 衡量 RL 挖掘基座潜能的效率,当前算法差距 > 40% |
| KL 估计器选择 | K1 in Reward(Reverse KL 无偏估计器);K3 in Loss(恒正、稳定,梯度等价于 Forward KL 蒸馏,但作为 KL 值估计器有偏);K1 in Loss 禁止使用 |
| Entropy 监控 | 熵崩塌是 RL 训练最常见的失败模式,需持续监控 Average Token Entropy |
| 训推 Mismatch | 框架差异导致 logprob 数值不一致,在长 CoT 中被指数级放大;Token-level Clipping 是有效工程解法 |
| 稀有 Token 奖励 | K3 在 |
| DeepSeek-Math v2 | Verifier + Meta-Verifier 双重验证,迭代 Refinement,对抗 Reward Hacking |
| Gemini IMO | Parallel Thinking + 定理证明数据 + POLARIS 配方 |
延伸阅读
- RLVR 能力上限分析:LeapLabTHU, "Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?" https://github.com/LeapLabTHU/limit-of-RLVR
- KL 估计器原理:John Schulman, "Approximating KL Divergence" http://joschu.net/blog/kl-approx.html
- KL 估计器在 RL 中的系统分析:https://www.arxiv.org/abs/2512.21852
- KL 估计器梯度分析参考:https://xihuai18.github.io/reinforcement-learning/2025/12/01/kl-estimators-en.html
- 训推 Mismatch:Kimi K2.5 技术报告;verl 文档 https://verl.readthedocs.io/en/latest/algo/rollout_corr.html
- Gemini IMO:DeepMind 博客 https://deepmind.google/blog/advanced-version-of-gemini-with-deep-think-officially-achieves-gold-medal-standard-at-the-international-mathematical-olympiad/
- POLARIS:https://honorable-payment-890.notion.site/POLARIS-A-POst-training-recipe-for-scaling-reinforcement-Learning-on-Advanced-ReasonIng-modelS-1dfa954ff7c38094923ec7772bf447a1