第 8 章:强化学习基础
本章概览
本章系统讲解强化学习(Reinforcement Learning, RL)的核心理论框架,为后续章节理解 PPO、GRPO、RLHF 等大模型对齐方法奠定数学基础。全章以一条主线贯穿:从 MDP 的形式化定义出发,经由动态规划到 RL 的认识论跃迁,逐步展开 Bellman 方程、MC/TD 估计、On/Off-policy 范式、Online/Offline 范式,最终落脚到 RL 目标函数与代理 Loss 之间的微妙关系——这一点对于理解 LLM 训练中的策略梯度至关重要。
8.1 MDP 定义与马尔可夫性判定
强化学习的数学语言:MDP 五元组定义与马尔可夫性的判定准则。
8.1.1 MDP 五元组
马尔可夫决策过程(Markov Decision Process, MDP)是 RL 的标准数学框架,由五元组
:状态空间(State Space),所有可能状态的集合 :动作空间(Action Space),智能体可执行的动作集合 :状态转移概率,在状态 执行动作 后转移到 的概率 :奖励函数(Reward Function),执行动作后环境返回的即时标量信号 :折扣因子,越接近 1 越重视长期回报
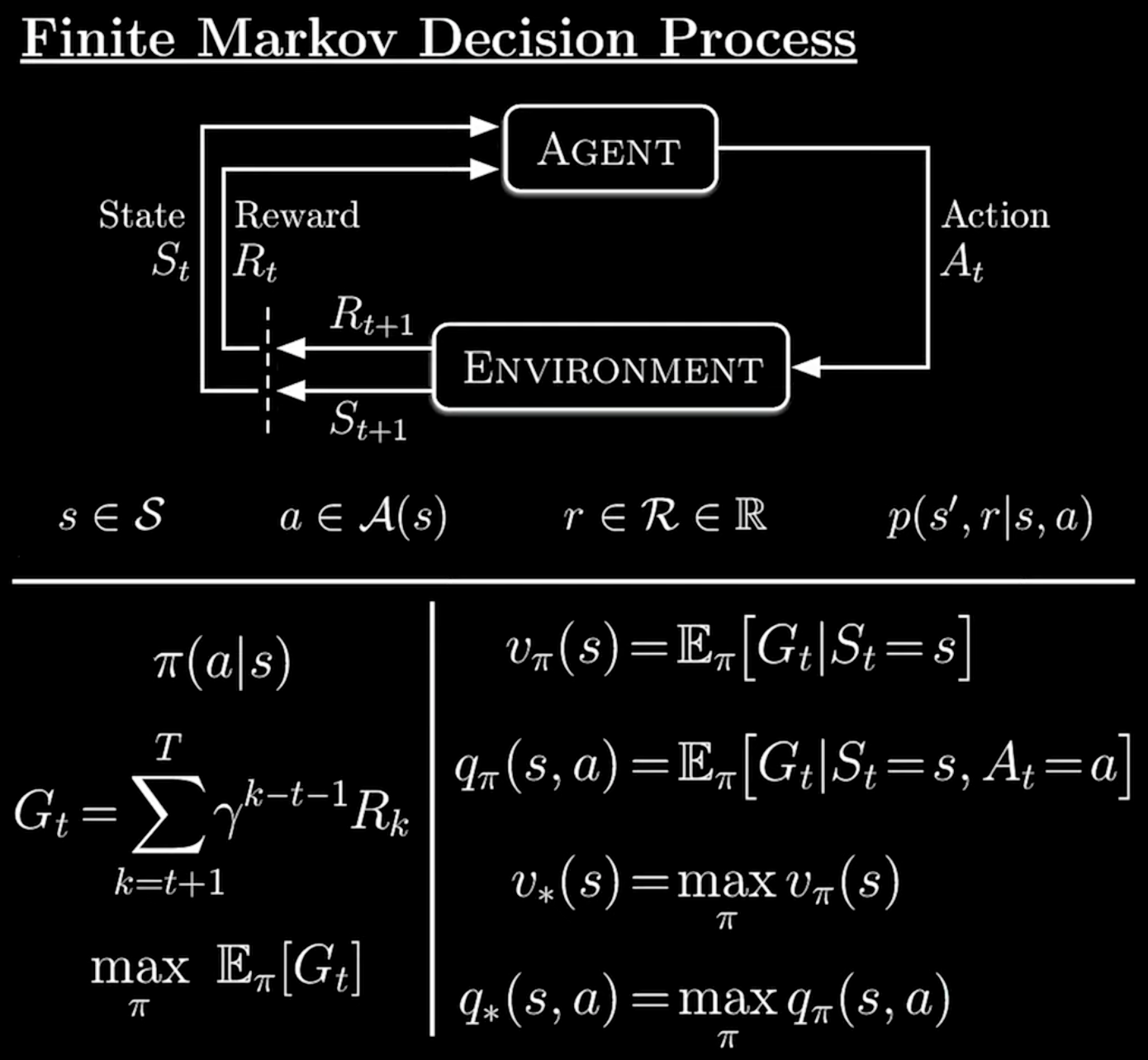
图 8-1:有限 MDP 的 Agent-Environment 交互循环与核心公式。上半部分展示了智能体在每个时间步接收状态
在标准 MDP 中存在一个隐含假设:世界是回合制的(Turn-based),具有原子性——每一步决策后环境立刻给出下一个状态和奖励,不存在异步或并发。
8.1.2 马尔可夫性(Markov Property)
马尔可夫性的核心是状态转移的无记忆性:下一个状态
直觉:状态
必须是一个"充分统计量"——它完整浓缩了所有影响未来所需的信息。如果状态定义不够充分,就需要依赖历史来预测未来,此时环境不满足马尔可夫性。
如何判断一个环境是否满足马尔可夫性? 关键在于状态的定义是否完整。以下用一个经典案例说明:
| 场景 | 状态定义 | 是否满足马尔可夫性 | 原因 |
|---|---|---|---|
| 抛物线运动小球 | (位置, 速度) | 是 | 速度已完整编码了历史动量信息,下一秒位置仅取决于当前 (位置, 速度) |
| 抛物线运动小球 | (仅位置) | 否 | 必须知道上一秒的位置才能推算速度,当前状态缺少信息 |
这个例子说明:同一个物理系统,状态定义不同,马尔可夫性的判定就不同。 非马尔可夫环境可以通过扩展状态定义(如把速度纳入状态)来"恢复"马尔可夫性。
8.2 Model-based vs. Model-free
按是否显式建模环境动力学,区分 Model-based 与 Model-free 两大范式及其技术路线。
8.2.1 核心区分
RL 算法按照是否显式建模环境动力学
| 特征 | Model-based RL | Model-free RL |
|---|---|---|
| 是否学习/使用环境 Dynamics | 是,学习或已知 | 否 |
| 学习目标 | 先建模环境,再用模型进行规划(Planning) | 直接从经验学习策略 |
| 数据效率 | 高(可用模型内部仿真生成虚拟经验) | 低(需大量真实环境交互) |
| 代表算法 | AlphaGo(MCTS)、MPC(模型预测控制) | Q-Learning、PPO、REINFORCE |
8.2.2 Model-free 的三条技术路线
Model-free 的本质是不显式学习
- 价值学习(Value-based):学习
或 ,通过贪心策略 导出动作。代表算法:DQN - 策略梯度(Policy Gradient):直接参数化并优化策略
。代表算法:REINFORCE、PPO - Actor-Critic:策略网络(Actor)与价值网络(Critic)联合学习,兼取两者优势。代表算法:A2C、SAC
注意:Model-free 与 Policy-based 不能简单等同。Value-based 方法(如 DQN)也是 Model-free 的——它不学习环境模型,只学价值函数。
8.3 从动态规划到强化学习(含 AlphaGo 案例)
RL 的本质是黑盒 DP——从白盒最短路径到黑盒采样估计,以 AlphaGo 为例解析两种范式的融合。
8.3.1 动态规划的两个充要条件
从算法(DSA)视角看,动态规划(Dynamic Programming)的适用性建立在两个充要条件之上,而这两个条件恰好对应 RL 的核心结构:
1. 最优子结构(Optimal Substructure)
当状态转移确定时简化为:
要找到节点 A 到终点 F 的最短路,算法不需要穷举所有路线。它只需要查看 A 的所有相邻节点,计算"A 到邻居的距离 + 邻居到 F 的最短距离",并从中选出最小值。Bellman 方程保证了这种"局部最优组合等于全局最优"的正确性。
2. 重叠子问题(Overlapping Subproblems)
仅仅能被拆分是不够的——如果子问题互相独立,那叫分治算法(如归并排序)。DP 的真正灵魂在于:这些子问题会被高频反复遇到。
为打破计算冗余,Bellman 方程在工程上天然要求引入记忆化(Memoization)或表格化(Tabulation):一个数组 V[s] 或 Q[s, a]。首次计算出状态
8.3.2 白盒 DP 实例:最短路径
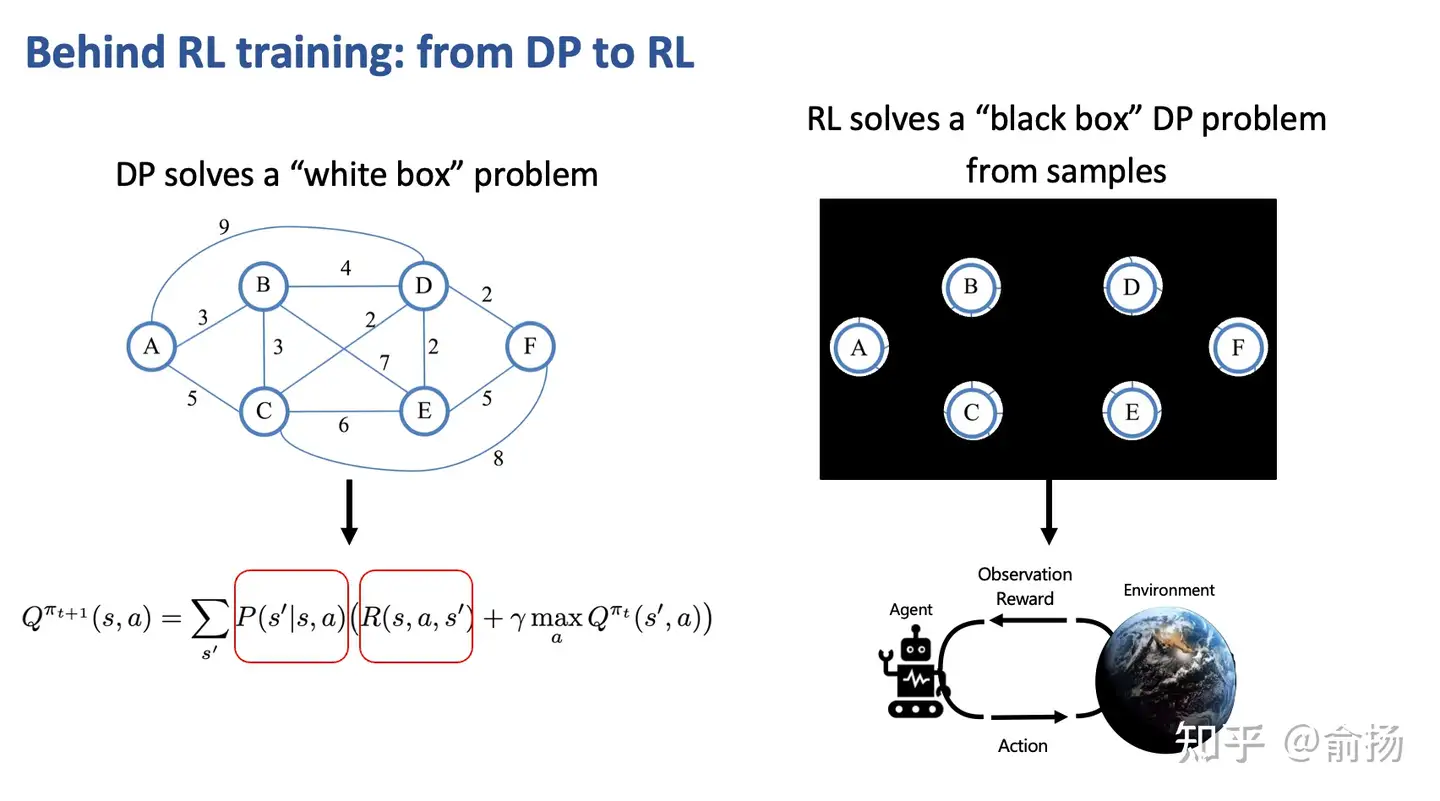
图 8-2:DP 与 RL 的对比。左侧 DP 求解"白盒"问题——环境的状态转移概率
以图 8-2 左侧的最短路径图(
import numpy as np
def solve_dp_white_box():
# 定义"白盒"环境模型——图的邻接关系与边权
# 代价转为负奖励,以适配带 max 的 Bellman 方程
graph = {
'A': {'B': 3, 'C': 5, 'D': 9},
'B': {'A': 3, 'C': 3, 'D': 4, 'E': 7},
'C': {'A': 5, 'B': 3, 'D': 2, 'E': 6, 'F': 8},
'D': {'A': 9, 'B': 4, 'C': 2, 'E': 2, 'F': 2},
'E': {'B': 7, 'C': 6, 'D': 2, 'F': 5},
'F': {} # 终点(吸收状态)
}
states = list(graph.keys())
# 初始化价值函数:终点 V(F)=0,其余为 -inf
V = {s: -float('inf') for s in states}
V['F'] = 0
Q = {s: {} for s in states if s != 'F'}
gamma = 1.0 # 最短路径问题折扣因子设为 1
threshold = 1e-5
# 价值迭代:反复应用 Bellman 方程
iteration = 0
while True:
delta = 0
V_new = V.copy()
for s in states:
if s == 'F':
continue
for s_next, cost in graph[s].items():
# P(s'|s,a)=1(确定性转移),R(s,a,s')=-cost
Q[s][s_next] = -cost + gamma * V[s_next]
best_value = max(Q[s].values())
delta = max(delta, abs(V[s] - best_value))
V_new[s] = best_value
V = V_new
iteration += 1
if delta < threshold:
break
# 提取最优策略
policy = {s: max(Q[s], key=Q[s].get) for s in Q}
return iteration, V, policy运行结果:DP 在 4 次迭代后收敛,找到最优路径
关键观察:在确定性转移的图中,
,Bellman 方程中的求和 退化为单项,等式简化为 。
同一问题也可以用 DSA 中经典的 Bellman-Ford 算法求解。两者本质相同——都是 Bellman 方程的迭代应用,只是状态定义的视角不同:
def solve_shortest_path_bellman_ford():
edges = [
('A','B',3), ('A','C',5), ('A','D',9),
('B','C',3), ('B','D',4), ('B','E',7),
('C','D',2), ('C','E',6), ('C','F',8),
('D','E',2), ('D','F',2), ('E','F',5)
]
# 无向图:双向添加
all_edges = [(u,v,w) for u,v,w in edges] + [(v,u,w) for u,v,w in edges]
nodes = ['A','B','C','D','E','F']
dp = {n: float('inf') for n in nodes}
dp['A'] = 0 # 起点代价为 0
parent = {n: None for n in nodes}
# Bellman-Ford 松弛迭代
for i in range(len(nodes) - 1):
updated = False
for u, v, w in all_edges:
if dp[u] + w < dp[v]: # dp[v] = min(dp[v], dp[u] + w)
dp[v] = dp[u] + w
parent[v] = u
updated = True
if not updated:
break
return dp, parent两种方法找到的最优路径完全一致:
8.3.3 RL 是"黑盒 DP"
理解了 DP 的白盒机制后,RL 的定位就清晰了:
强化学习的本质:在环境模型
未知的情况下,通过与环境的试错采样来近似求解动态规划问题。
关键区别:
- DP 直接用
计算精确期望 - RL 用一次或多次实际采样来估计这个期望,因此不可避免地引入方差
RL 的不同分类也由此展开:
- Model-based RL:先学一个近似的
,再用 DP/规划做推演(如 MPC、AlphaGo) - Model-free RL:不显式学
,直接从样本学 或
8.3.4 AlphaGo:Model-based 与 Model-free 的混合典范
AlphaGo 是理解两种范式如何协同的经典案例。它同时包含 Model-free 的网络训练和 Model-based 的搜索规划。
Model-free 侧——神经网络训练
AlphaGo 的策略网络和价值网络最初通过人类专家棋谱进行监督学习,随后利用自我对弈的 RL 不断更新。在网络评估阶段,模型只是在拟合一种"直觉",不涉及对环境状态的显式推演。
策略网络
:先通过 SL 学习 ,再通过 RL 自我对弈更新 价值网络
:输入棋盘状态 ,输出标量胜率预测,通过最小化与真实胜负 的 MSE 进行梯度下降
Model-based 侧——MCTS 规划
在实际落子阶段,AlphaGo 依赖蒙特卡洛树搜索(MCTS),而 MCTS 的有效运行建立在一个核心前提:完美的围棋规则引擎(即完美的环境动态模型
MCTS 利用这个预先给定的模型在内部推演数万步。选择阶段使用 PUCT 算法:
叶节点评估采用价值网络和快速走子的混合策略:
总结:AlphaGo 是 Model-free 学习(神经网络训练提供"直觉")+ Model-based 规划(MCTS 利用完美规则进行"深思")的有机结合。就其核心规划能力而言,它属于依赖已知模型的 Model-based 系统。
8.4 Bellman 方程与最优控制
We consider all of the work in optimal control also to be, in a sense, work in reinforcement learning. —— Sutton & Barto
8.4.1 价值函数的两种定义
定义一(最终清算式):
含义:如果智能体站在当前状态
定义二(Bellman 递推式):
含义:当前状态的价值 = "眼前的收益" + "打了折的下一个状态的价值"的期望。
为什么需要 Bellman 方程?
不可计算性:第一种定义在实践中几乎不可用。对于稍复杂的任务(下围棋、自动驾驶),未来轨迹
的分支呈指数爆炸,直到终局才能结算 ,穷举计算代价是天文数字 Bootstrapping(自举)使之可计算:第二种定义建立了
和 之间的递归关系,算法可以用对后续状态的估计来更新对当前状态的估计——"用猜测更新猜测"(Updating a guess based on another guess) 马尔可夫性保证递推成立:Bellman 方程能成立的前提是环境满足马尔可夫性——
完整浓缩了历史信息
8.4.2 Bellman 最优方程
等号的含义:左边问"在状态
选择动作 ,总回报是多少?"右边答"即时奖励 + 遍历所有可能的 对应的最大未来价值(折现)"。 期望的来源是转移的不确定性。当转移确定时,方程简化为:
8.4.3
这两个符号的区分是理解 RL 训练过程的关键:
(不带星号):智能体初始时持有的 Q 估值,充满误判 (带星号):全局最优策略对应的动作价值函数,是数学上的极限
整个训练循环的终极数学目标:通过无数次迭代,将不带星号的
一步步推向带星号的极限 。一旦 ,智能体自动领悟最优策略 。
8.4.4 Q-Learning:Model-free 的 Bellman 实现
Q-Learning 是 Model-free 框架下直接利用 Bellman 方程的经典算法:
等价形式:
各项含义:
- TD Target
: 是对 的一次采样(与环境交互获得), 是对 的当前估计 - 学习率
:控制旧知识 和新知识 的混合比例
注意:Q-Learning 不需要知道
,也不需要知道 的解析形式——它只需要与环境交互得到的样本 。
8.5 Monte Carlo vs. Temporal Difference
MC 与 TD 两种价值估计范式的 Bias-Variance 权衡,以及 GPI 框架下的统一理解。
8.5.1 两种估计目标
MC 和 TD 是 RL 中估计价值函数的两种基本范式,核心区别在于用什么作为更新目标:

图 8-3:Monte Carlo 方法的核心思想。MC 不知道
8.5.0 广义策略迭代(GPI)
图 8-3 中提到的 GPI(Generalized Policy Iteration)是理解几乎所有 RL 算法的统一框架。
定义:GPI 是指策略评估(Policy Evaluation)和策略改进(Policy Improvement)两个过程交替执行、相互驱动的通用范式。无论具体算法如何实现这两个步骤,只要它们交替推进,就属于 GPI 的范畴。
- 策略评估(E):给定策略
,估计其价值函数 或 。DP 通过迭代求解 Bellman 方程;MC 通过多次采样取均值;TD 通过一步 Bootstrapping。 - 策略改进(I):给定价值函数,贪心地构造更好的策略
。
收敛性保证:Policy Improvement Theorem 保证每次改进后策略不会变差——
与具体算法的关系:
| 算法 | 策略评估方式 | 策略改进方式 |
|---|---|---|
| Policy Iteration | 迭代至 | 贪心改进 |
| Value Iteration | 每次仅执行一步 Bellman 更新(截断评估) | 隐式改进(max 操作内嵌) |
| MC Control | 采样回报取均值 | |
| SARSA / Q-Learning | TD 一步更新 |
关键洞察:Policy Iteration 和 Value Iteration 并非两种不同的算法,而是 GPI 框架下"评估的完整度"不同的两个极端——前者将评估做到精确收敛,后者只做一步截断评估就立刻改进。实际算法介于二者之间,都遵循 GPI 的"评估-改进"交替结构。
MC 的目标:必须 rollout 到 episode 结束,用真实发生的完整回报
TD 的目标:只走一步,用下一步的价值估计来替代后续的完整回报
8.5.2 Bias-Variance 权衡
| 特性 | MC (Monte-Carlo) | TD (Temporal Difference) |
|---|---|---|
| 更新目标 | 真实回报 | 估计值 |
| 随机性来源 | 整个序列 | 仅当前这一步 |
| Variance(方差) | 高(噪声累积) | 低(噪声截断) |
| Bias(偏差) | 无(无偏估计) | 有(依赖不准确的 Critic) |
| 收敛速度 | 慢(方差大,需更多样本平均) | 快(方差小,且每步都能学) |
| 能否在线更新 | 否(需等 episode 结束) | 是(每步更新) |
8.5.3 为什么 MC 无偏而 TD 有偏?
MC 无偏:
TD 有偏:TD 目标中包含
- 在训练初期,
可能是完全随机初始化的,是错误的 - 当用一个错误的猜测
加上当前奖励 作为目标去更新 时,误差被传播 - 这就是 Bootstrapping:用自己的估计更新自己的估计,系统性估计误差即为 Bias
随着训练进行,
8.5.4 为什么 TD 方差低?
方差来源于环境的随机性,主要有两个源头:
- 状态转移的随机性:
- 动作选择的随机性:
MC 承受整条轨迹的随机性叠加——从
8.5.5 三种更新方式对比
| 算法类型 | 更新目标 (Target) | 采样方式 | 特点 |
|---|---|---|---|
| REINFORCE | Monte-Carlo | 无偏,但在长序列中方差极大 | |
| Actor-Critic | TD(时序差分) | 引入偏差,但显著降低方差;利用 Critic 进行 Bootstrapping | |
| n-step PG | 混合(MC + TD) | 介于两者之间,向前看 |
n-step 方法的设计思路:
是一个旋钮—— 退化为 TD, 退化为 MC。通过调节 ,可以在 Bias-Variance 之间找到最佳平衡点。
8.6 On-policy vs. Off-policy
行为策略与目标策略是否一致——SARSA 与 Q-Learning 的核心差异,以及 Policy Gradient 的 On-policy 本质。
8.6.1 两个策略的区分
理解 On/Off-policy 的关键在于区分两个角色:
- 行为策略(Behavior Policy):用于与环境交互、生成训练数据的策略
- 目标策略(Target Policy):被优化/学习的策略
| 范式 | 定义 | 数据使用 |
|---|---|---|
| On-policy | 行为策略 = 目标策略 | 数据必须由当前最新策略生成,用后即弃 |
| Off-policy | 行为策略 ≠ 目标策略 | 可使用其他策略(甚至历史数据)产生的数据训练 |
Off-policy 的核心优势:解耦了数据采集与训练过程。智能体可以"通过观察别人(或者自己过去)的行为来学习",即使那些行为并非当前最优的。
8.6.2 SARSA(On-policy)vs. Q-Learning(Off-policy)
SARSA 和 Q-Learning 都是 TD 学习的具体算法,它们唯一的区别在于如何构造 TD 目标值——即如何估计下一步的价值。
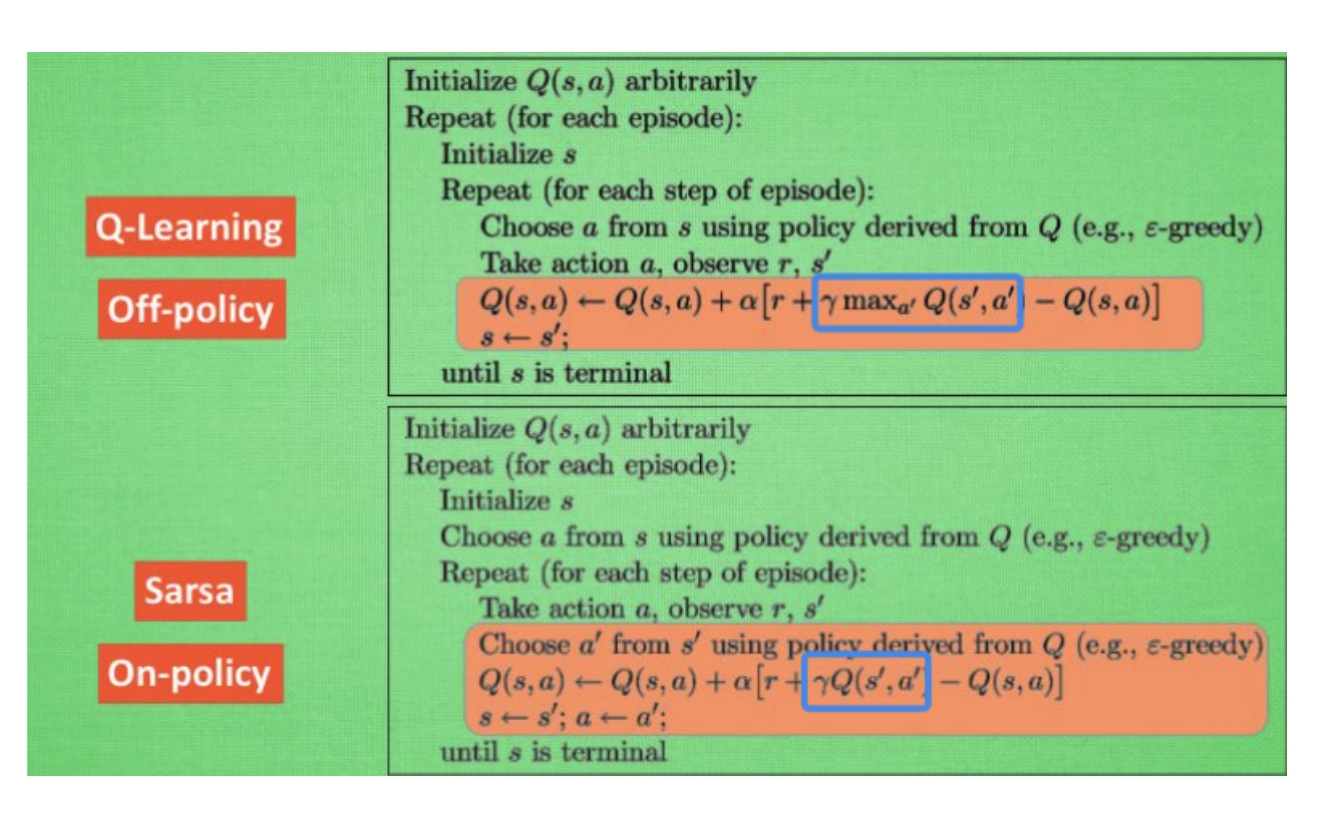
图 8-4:Q-Learning(Off-policy)与 SARSA(On-policy)的伪代码对比。蓝框标出了二者的核心差异:Q-Learning 使用
SARSA 的工作流程(On-policy):
SARSA 名字来源于完整序列
- 在状态
,根据当前策略(如 -greedy)选择动作 - 执行
,获得奖励 ,进入新状态 - 在
,再次用相同的策略选出下一个动作 - 用
构建 TD 目标,更新
选择
Q-Learning 的工作流程(Off-policy):
Q-Learning 在更新时不关心在
Q-Learning 的"内心独白":"我不管下一步实际会怎么走(可能因为探索走了臭棋),在评估过去时,永远假设下一步会做出最完美的选择。"
用于评估的策略(永远取 max,即贪心策略)和用于执行动作的策略(
DQN 的 Loss 函数直接体现了这一点:
其中经验
8.6.3 为何 Policy Gradient 本质上是 On-policy?
REINFORCE 的梯度公式要求期望
如果用旧策略
8.6.4 Rollout-Training Mismatch:工程中的实际问题
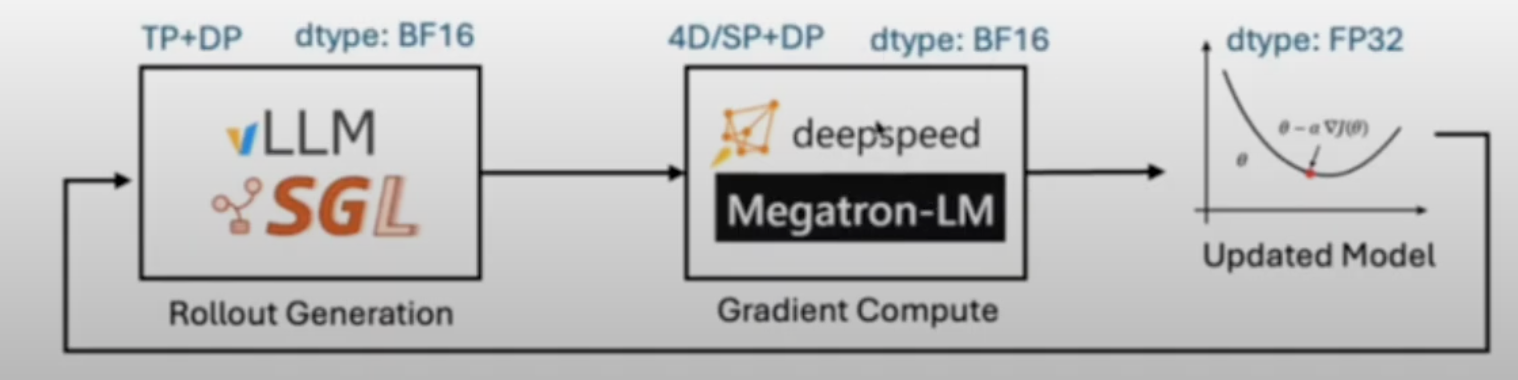
图 8-5:veRL 框架的 Hybrid Engine 架构。Rollout 阶段使用 vLLM/SGLang 进行高效推理,Training 阶段使用 DeepSpeed/Megatron-LM 进行梯度计算,二者使用不同的计算后端。
在 LLM 的 RL 训练中,理论上策略梯度公式要求 rollout 和 training 使用同一策略:
但工程实现中,rollout 阶段使用高效推理引擎(如 vLLM),training 阶段使用训练框架(如 FSDP),二者是不同的计算实例:

图 8-6:Rollout-Training mismatch 的具体体现。上方是理论期望的 PPO 梯度公式,下方是 veRL/OpenRLHF 的实际实现——rollout 来自
解决方案是通过重要性比率(Importance Ratio) old_log_prob,确保 importance ratio 的分母精确:
old_log_prob = actor_rollout_wg.compute_log_prob(batch):,一个 batch 只算一次 ref_log_prob = actor_rollout_wg.compute_ref_log_prob(batch):- PPO training loop 内更新 Actor
,importance ratio
8.7 Online vs. Offline RL
与 On/Off-policy 正交的另一维度:智能体能否实时与环境交互,及其在 LLM 训练中的映射。
Online/Offline 的区分与 On/Off-policy 是正交的,它关注的是是否能与环境实时交互。
8.7.1 Online RL
定义:Online RL 指智能体在学习过程中可以实时与环境交互,不断采集新鲜数据来更新策略。它形成一个正反馈循环:
绝大多数经典 RL 算法(PPO、DQN、SAC、REINFORCE 等)默认工作在 Online 模式下。
与 Offline RL 的关键对比:
| 维度 | Online RL | Offline RL |
|---|---|---|
| 数据来源 | 实时与环境交互生成 | 静态历史数据集,不可追加 |
| 策略更新 | 每轮交互后立刻更新 | 在固定数据集上多次迭代 |
| 探索能力 | 可主动探索未知区域 | 受限于数据集覆盖范围 |
| 核心挑战 | 探索-利用权衡(Exploration-Exploitation) | 分布外动作(OOD Action) |
探索-利用权衡(Exploration-Exploitation Tradeoff)
Online RL 的核心难题:智能体在每一步都面临选择——
- 利用(Exploit):执行当前已知最优的动作,最大化即时收益
- 探索(Explore):尝试未知或低频动作,发现可能更优的策略
如果只利用,智能体可能陷入局部最优;如果只探索,智能体无法积累回报。经典的平衡策略包括:
-greedy:以 概率执行贪心动作,以 概率随机探索 - 熵正则化:在目标函数中加入策略熵
,鼓励动作分布的多样性(SAC 的核心思想) - UCB(Upper Confidence Bound):选择"乐观估计"最高的动作,兼顾均值和不确定性
在 LLM 训练中的体现
在 PPO/GRPO 等 LLM 对齐方法中,Online RL 表现为:模型(策略
8.7.2 Offline RL
智能体无法与环境交互,只能使用一个静态的历史数据集来学习策略。环境是"死的"——只有 millions 条
核心挑战——分布外动作(OOD Action):离线数据集中没有某些状态-动作对,但 Q 网络可能对这些未见过的动作给出虚假的高估值,导致学到的策略在实际部署时失败。
典型算法:
TD3+BC(行为克隆约束):
通过约束策略接近数据集中的行为来缓解 OOD 问题
DPO:可视为 Offline RL 在语言模型领域的特殊实现,利用静态偏好数据集优化策略
8.7.3 与 LLM 训练的对应关系
| RL 范式 | LLM 训练阶段 | 交互方式 |
|---|---|---|
| Online RL | PPO/GRPO | 模型持续生成 rollout,实时与 reward model 交互获得反馈 |
| Offline RL | DPO | 使用静态偏好数据集 |
8.8 目标函数与代理 Loss
采样操作打断了梯度流——Log-Derivative Trick 如何修复,Surrogate Loss 为何不等于 Objective。
8.8.1 RL4LLM 的目标函数
在 RL 对齐 LLM 的场景下,标准目标函数为:
展开 KL 散度可以看到其三重作用:
8.8.2 核心问题:为什么 AutoGrad 会"失明"?
在监督学习中,数据分布固定,对
为什么不相等?因为期望的算符
完整展开:
- 第一项(Score Function Term):"因为
变了,采样到 的概率变了,进而总期望变了"——这是 Policy Gradient 的核心来源 - 第二项(Pathwise Derivative Term):"对于固定的
,如果 变了, 的得分怎么变"——这是 AutoGrad 能看到的部分
在 RL 中,
根本问题出在采样操作上:
正常计算流(可导):θ → Logits → Softmax → Prob → Loss
RL 计算流(含采样):θ → Prob → [采样动作 x] → f(x)采样操作 Categorical(probs).sample() 是阶跃函数,导数几乎处处为 0。AutoGrad 把采样出来的
AutoGrad 的盲区:在监督学习中数据分布固定(来自数据集),
不依赖 ,第一项为 0,AutoGrad 完全正确。但在 RL 中,数据是自己生成的,最大化奖励主要靠"让高分样本出现的概率变大"(改变 ),而不是"改变样本的分数"。
8.8.3 Log-Derivative Trick 与 REINFORCE
丢失的第一项是:
困难在于:
Log-Derivative Trick 解决了这个问题:
代入丢失的第一项:
现在它是期望形式了,可以通过采样近似!
直觉:
不可用——"如果我参数变一点,抽出来的这个样本会变成什么?"(采样不可导)。但 可用——"如果我参数变一点,抽中这个样本的概率会怎么变?"(概率是可导的)。 只是一个权重,告诉你该把这个概率往高了拉还是往低了踩。
8.8.4 Surrogate Loss(代理 Loss)
既然推导出了正确的梯度方向应该是
执行 .backward() 时,AutoGrad 把 detach(f(x)) 当作常数系数
这正好是负的 Policy Gradient。梯度下降(minimize
8.8.5 关键洞察
Loss 是 Objective 的"梯度估计器"(Gradient Estimator),而不是 Objective 本身。
| 监督学习 | 强化学习 | |
|---|---|---|
| Loss 与 Objective 的关系 | Loss = Objective(如 MSE) | Loss 是为了凑出正确梯度而构造的"替身函数" |
| Loss 下降的含义 | 性能提升 | 不一定代表性能提升 |
| Loss 曲线的可解读性 | 直接反映训练质量 | 绝对值和单调性无直接意义 |
这是 RL 训练时 Loss 曲线不能像监督学习那样直接解读的根本原因。RL 中真正的性能指标是奖励(或 episode return),而非 Loss。
本章小结
| 概念 | 核心要点 |
|---|---|
| MDP | 马尔可夫性 = 状态是充分统计量;五元组 |
| Model-based / free | 是否显式建模 |
| 从 DP 到 RL | RL = 黑盒 DP;DP 用精确期望,RL 用采样估计;AlphaGo 是两种范式的混合 |
| Bellman 方程 | 递推定义价值函数;自举(Bootstrapping)是核心思想; |
| MC vs. TD | MC 无偏高方差(需完整 rollout);TD 有偏低方差(仅看一步);n-step 折中 |
| On/Off-policy | 行为策略是否等于目标策略;SARSA(On)vs. Q-Learning(Off);PG 本质 On-policy |
| Online / Offline | 是否可与环境实时交互(正交于 On/Off-policy);DPO 是 Offline RL 的 LLM 实现 |
| 目标函数与代理 Loss | AutoGrad 看不到采样操作的梯度;Log-derivative trick 修复;Surrogate Loss |
延伸阅读
- Sutton & Barto, Reinforcement Learning: An Introduction(第 2 版)——RL 最权威教材,本章多数概念均出自此书
- David Silver, UCL RL Course(视频公开课)——对 Bellman 方程、MC/TD、On/Off-policy 的讲解尤为清晰
- 《动手学强化学习》(hrl.boyuai.com)——含 Q-Learning、DQN、Policy Gradient 完整代码实现
- Silver et al., Mastering the game of Go with deep neural networks and tree search, Nature, 2016 —— AlphaGo 原始论文
- RLHF pipeline 博客——RL 在 LLM 对齐中的应用概览
- veRL 源码 —— PPO 训练中 Rollout-Training mismatch 的工程解决方案