第27章 GUI Agent:视觉感知与界面交互
本章来源:综合自 Hello-Agents Extra06(GUI Agent科普与实战)、Agentic Design Patterns 附录B(从GUI到真实世界环境的智能体交互)
核心问题 -- 本章要解答什么
传统智能体通过API和命令行与数字世界交互,但人类使用计算机的方式是通过图形用户界面(GUI)——点击按钮、填写表单、滑动屏幕。GUI Agent是一类能够像人类一样"看"屏幕、"理解"界面、"操作"控件的AI系统,它代表了智能体与数字世界交互方式的范式转变。
本章要解答的核心问题:
- GUI Agent与传统RPA的本质区别是什么?为什么称其为"范式转变"?
- 感知-推理-执行三层架构的设计权衡是什么?
- 纯视觉方案与DOM结构化方案各有何取舍?
- 当前技术的能力边界在哪里?距离实用还有多远?
设计空间 -- 可选方案与取舍
27.1 从RPA到GUI Agent的范式转变
理解GUI Agent的价值,需要先理解它超越了什么。
| 维度 | 传统RPA | GUI Agent |
|---|---|---|
| 工作原理 | 基于固定选择器(XPath/ID)的脚本回放 | 基于视觉理解和语言模型推理的自主操作 |
| 适应性 | 界面变化即失效 | 能适应界面变化,具备语义弹性 |
| 任务规划 | 需人工预设每步操作 | 根据自然语言指令自主分解任务 |
| 跨平台能力 | 需为每个平台编写专门脚本 | 通用视觉方案,天然跨平台 |
| 维护成本 | 极高(UI变化需重写脚本) | 低(模型自动适应) |
核心区别:RPA是"脆弱的自动化",GUI Agent是"智能的自主化"。RPA依赖于界面元素的精确标识符,一旦按钮从蓝色变成绿色或位置稍有移动,脚本就会失效。GUI Agent通过语义理解识别"这是登录按钮",而不依赖于按钮的具体样式或位置。
27.2 技术成熟的三个支柱
GUI Agent在2024-2025年的爆发并非偶然,而是三个技术领域同步成熟的结果:
多模态大模型的突破。GPT-4o、Claude 3.5 Sonnet、Qwen-VL 等模型不仅能理解文字,还能"看懂"图像 [OpenAI, 2024; Anthropic, 2024]。CogAgent [Hong et al., 2023] 作为专门面向 GUI 理解的视觉语言模型(18B 参数),在 ScreenQA 上达到 74.0% 的准确率,显著超越通用多模态模型。当一张屏幕截图输入这些模型时,它们能准确识别界面元素的类型和功能。
定位能力的突破。早期视觉模型能识别"屏幕上有个按钮",但说不清按钮在哪里。GUI-Owl、Qwen-VL等专门训练的模型能精确输出UI元素的屏幕坐标(x, y)——不仅能"看见",还能"点准"。
推理能力的质变。大语言模型的链式思考能力让Agent拥有了"大脑"。它能将"订一张明天的高铁票"这样的模糊指令分解为"打开APP -> 选择日期 -> 输入地点 -> 筛选车次 -> 确认支付"的具体步骤,并在执行过程中反思和纠错。
架构解析 -- 深入分析核心架构
27.3 感知-推理-执行三层架构
一个完整的GUI Agent系统由三个闭环模块组成:感知(Perception)-> 推理(Reasoning)-> 执行(Action)。
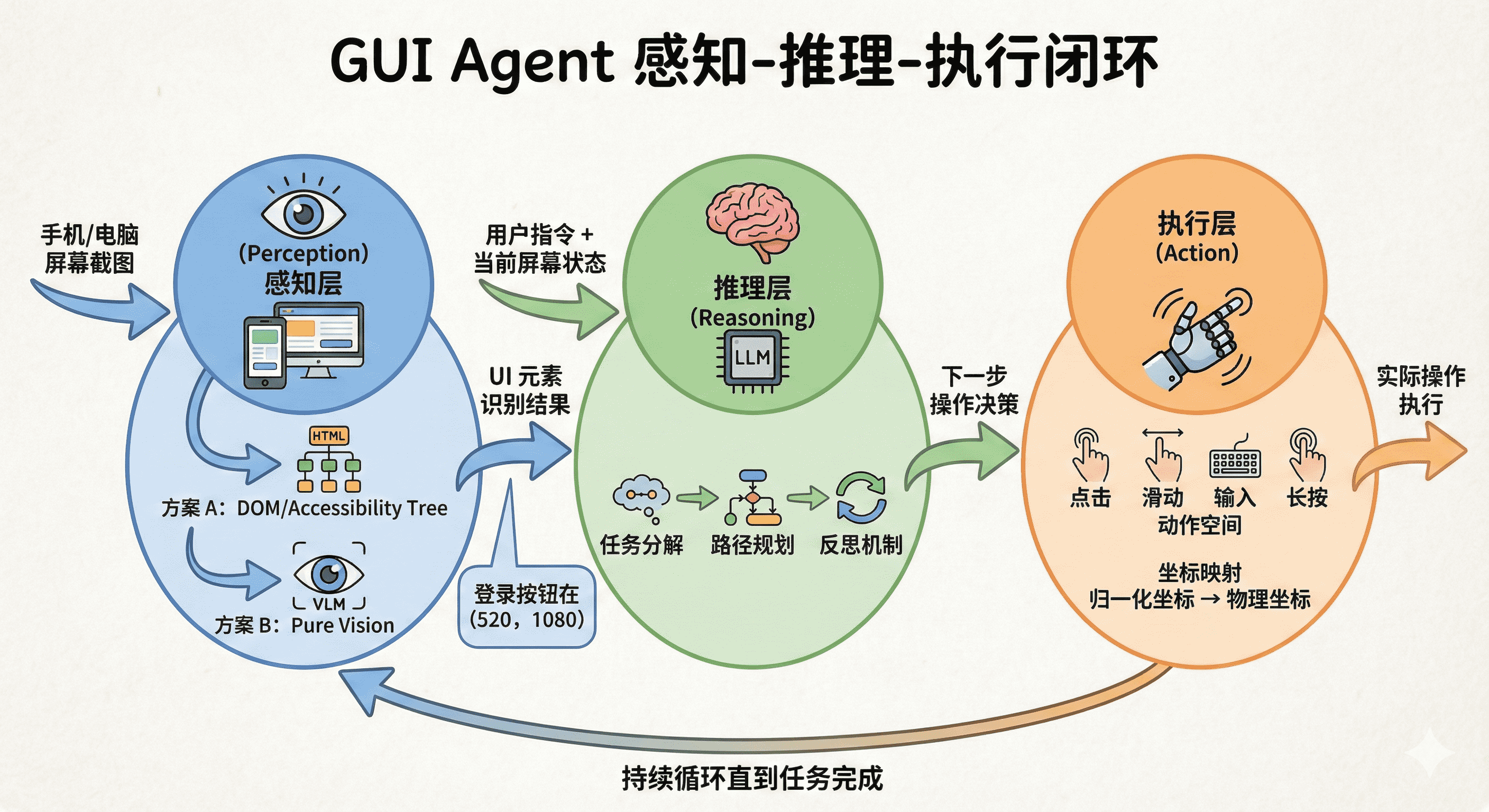
感知层:两种技术路线的取舍
感知层负责将屏幕信息转化为机器可理解的数据,存在两种截然不同的设计哲学。
路线一:基于DOM/可访问性树的结构化感知。通过系统API获取应用的内部结构——网页的HTML DOM树或Android的View Hierarchy。就像给Agent提供了一份"建筑图纸",能精确知道每个元素的类型和位置。优势是精确高效,但局限明显:Canvas绘制的界面、游戏、远程桌面等无法暴露结构化信息;丢失视觉布局信息,难以理解空间关系;跨平台兼容性差。
路线二:基于纯视觉的感知。Agent直接截取屏幕图像,用视觉大模型"看"屏幕。通用性极强——不管界面用什么技术实现,只要能显示在屏幕上,Agent就能理解。更重要的是具备"语义弹性":即使按钮颜色改变或位置移动,基于视觉的Agent仍能通过语义识别出"这是登录按钮"。最大挑战是定位精度——模型需要同时输出元素的语义标签和精确屏幕坐标。
当前最前沿的方向是纯视觉路线,其核心优势是通用性和语义弹性。实践中的折中方案是混合感知:以视觉为主,在可用时辅以DOM信息增强定位精度。
推理层:从指令到操作的智能转化
推理层是GUI Agent的"大脑",涉及三个关键能力。
任务分解。当用户说"帮我订一张明天去上海的高铁票,二等座,上午10点左右出发",Agent需要理解这句话背后的复杂逻辑,自动拆解为:打开12306 -> 点击"车票预订" -> 输入出发地 -> 输入目的地 -> 选择日期 -> 查询 -> 筛选车次 -> 预订 -> 填写乘客信息 -> 确认支付。
思维链机制。现代GUI Agent在每一步操作前生成"内心独白"。例如:当前屏幕是12306首页,Agent分析"我看到'车票预订'、'订单查询'等选项,需要点击'车票预订'",然后决策"点击坐标(540, 320)处的按钮"。这种显式思考过程不仅提升可解释性,还降低了多步操作的误差累积。
反思与纠错。如果Agent点击"查询"后发现弹出"请选择出发日期"的提示而非预期的车次列表,它能意识到"漏掉了选择日期的步骤",主动调整策略。这种自我修正能力是应对真实世界意外情况的关键。
执行层:从决策到物理操作
执行层是GUI Agent的"双手",负责将决策转化为实际系统操作。
动作空间。GUI操作的动作空间是有限且明确的:点击、双击、长按、滑动、输入、滚动、拖拽。每种动作有特定参数:点击需要坐标(x, y),滑动需要起点和终点(x1, y1, x2, y2),输入需要文本内容。
坐标系统转换。视觉模型通常输出归一化坐标(0-1000),而实际屏幕分辨率可能是1920x1080。执行层必须进行精确的坐标映射:将归一化坐标除以1000,乘以屏幕实际宽高,再取整得到物理坐标。不同设备的DPI和系统缩放比例也需要考虑。
多平台适配。同一个"点击"动作在不同平台的实现完全不同:
- Android:通过ADB发送指令(
adb shell input tap 500 1000) - iOS:通过WDA(WebDriverAgent)实现
- 桌面:使用pyautogui、pynput等库控制鼠标键盘
执行层需要为每个平台提供统一的抽象接口。
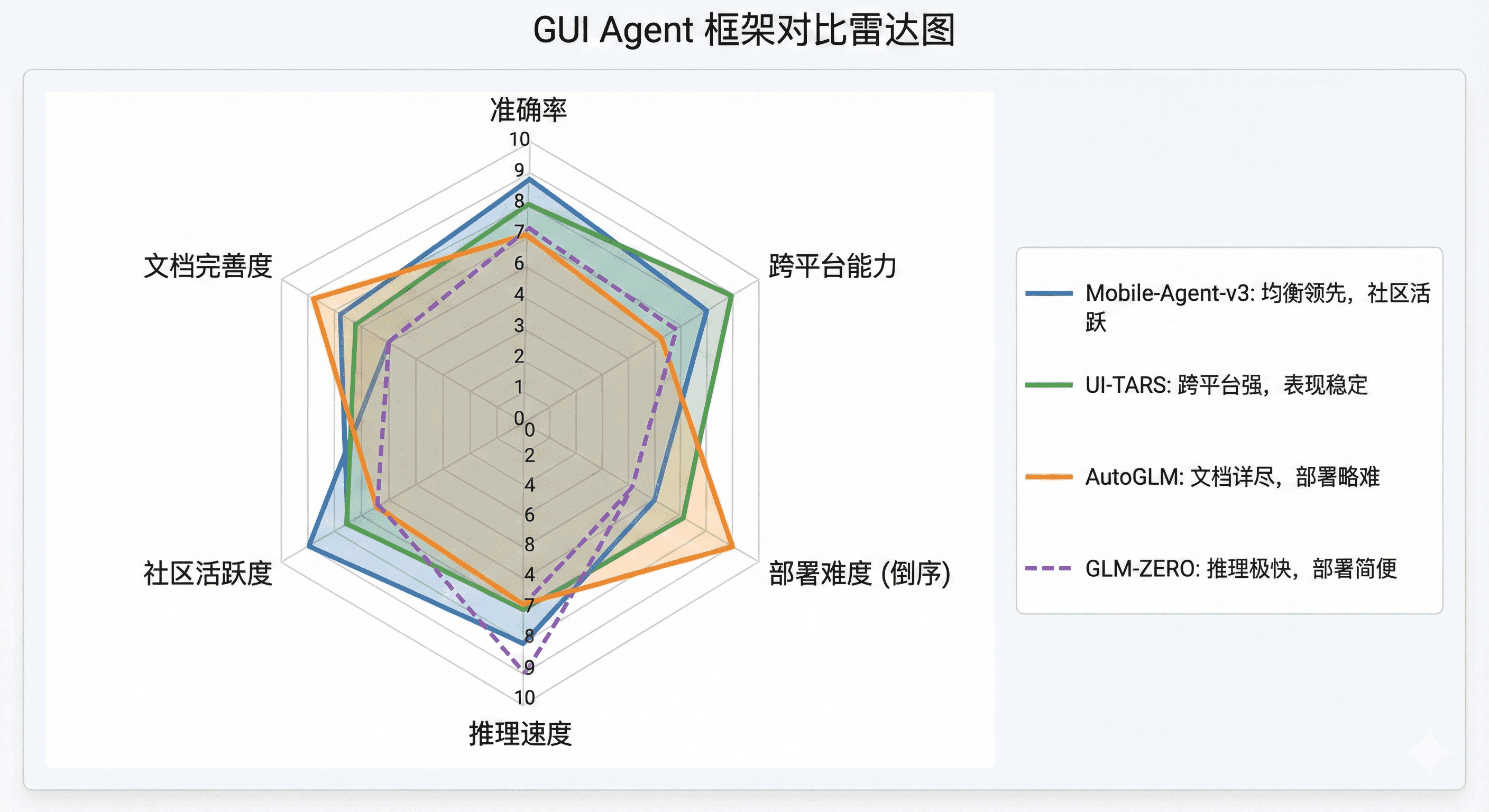
27.4 主流框架与产品
产业级产品
ChatGPT Operator(OpenAI):直接从桌面端自动化多种应用程序的任务,无需为每个服务配置专用API。能执行跨应用的复杂操作,如将电子表格数据导入CRM系统、规划复杂行程。
Google Project Mariner:在Chrome浏览器内运行的智能体。用户指令如"在特定预算和区域内寻找三套出租公寓",Mariner导航至房产网站,应用筛选条件,提取信息到文档。
Anthropic Computer Use:使Claude成为计算机桌面的直接操作用户。通过截屏感知和程序化控制,编排跨多个独立应用的工作流。
Browser Use:开源库,提供浏览器自动化的高级API,使Agent通过DOM控制与网页交互。
开源框架
Mobile-Agent-v3:支持手机和电脑的GUI操作,ModelScope提供在线Demo可零门槛体验。
AutoGLM(智谱):适合个人开发者入门的框架,架构清晰,支持云端API和本地部署两种模式。通过ADB连接Android手机,支持自动化执行真实任务。
UI-TARS(字节跳动):专注于UI理解和自主交互的视觉Agent模型,在界面元素定位精度上有突出表现。
27.5 提示词工程在GUI场景的特殊性
在GUI场景下,提示词工程有其独特的要求:
- 明确应用边界:避免"写个简介"这样的笼统指令,应指定"在WPS Office文档中写一段简介"。明确指定软件名称能减少Agent寻找工具的时间
- 步骤链式拆解:GUI操作具有严格的时序性,"第一步打开Edge搜索...第二步确认网页加载后截取数据...第三步打开Excel粘贴"比一句话指令的执行错误率低得多
- 视觉属性描述:Agent通过"看"屏幕操作,视觉特征描述更有效——"点击右上角的蓝色保存按钮"比"点击保存"更精确
关键实现决策 -- 工程实践中的关键选择点
27.6 当前技术的三大局限
安全性与幻觉风险。LLM的幻觉问题在GUI Agent上可能导致严重后果。用户要求"清理桌面",Agent可能误解为删除所有文件;转账操作中的一个数字错误可能造成经济损失。当前缓解方案包括:高风险操作强制人工确认、详细操作日志支持回滚、沙箱环境充分测试。
成本与效率问题。每步操作都需调用大模型推理,使用云端API时成本随调用次数线性增长。一个复杂任务可能需要数十次迭代,整体耗时较长。探索方向包括:操作缓存、模式识别、混合架构(简单任务用RPA,复杂任务用AI)。
准确率瓶颈。即使最好的系统在真实场景中的成功率也只有40-50%。WebArena 基准 [Zhou et al., 2023] 的评估显示,GPT-4V 在真实网页操作任务上的端到端成功率仅为 14.41%(人类为 78.24%),VisualWebArena [Koh et al., 2024] 中最强模型的成功率也仅为 16.4%。复杂界面的元素定位、动态内容处理(广告、弹窗)、长链条任务的错误累积,这些是实质性的技术难题。从50%到90%的商业可用水平,还需要更强的视觉大模型、强化学习优化操作策略、以及人机协同设计。
27.7 五大典型应用场景
- 智能座舱:语音指令跨应用协调(导航+外卖),理解复杂时间逻辑,适应不同品牌车机UI差异
- 软件测试:自适应UI变化的自动化测试,视觉回归测试,探索性测试发现人类可能忽略的边界情况
- 企业级RPA:处理没有API的老旧系统,跨系统工作流自动化(Excel -> ERP -> 邮件)
- 个人助理:跨平台内容发布、日程管理、数据采集等重复性数字劳动
- 无障碍辅助:视障用户的语音控制手机、智能阅读屏幕内容、复杂操作简化为语音指令
27.8 从 GUI 到物理世界:Embodied Agents
GUI Agent 的"感知-推理-执行"架构并非终点——当感知从屏幕扩展到真实世界,执行从鼠标点击扩展到机械臂操作,我们进入了 Embodied Agent(具身智能体) 的领域。
PaLM-E [Driess et al., 2023, arXiv:2303.03378] 是具身多模态语言模型的代表。它将视觉、语言和机器人状态信息统一编码到同一个 Transformer 中,使模型能够直接从视觉观察生成机器人控制指令。PaLM-E 展示了一个关键能力:在真实机器人上执行自然语言指令(如"把红色积木放到绿色碗里"),模型需要同时理解语言指令、识别视觉场景中的目标对象、并生成精确的运动轨迹。
RT-2 [Brohan et al., 2023, arXiv:2307.15818] 提出了"视觉-语言-动作模型(VLA)"的概念——将机器人动作视为一种"语言",与自然语言和视觉信息在同一框架下学习。RT-2 在 Web 规模的视觉-语言数据上预训练,然后在机器人数据上微调,成功实现了从互联网知识到物理操作的迁移。例如,模型从未在训练数据中见过"将垃圾扔进垃圾桶"的机器人轨迹,但通过语义理解能够泛化执行这一指令。
Voyager [Wang et al., 2023, arXiv:2305.16291] 在 Minecraft 虚拟环境中展示了具身智能体的终身学习能力。Voyager 自动编写和执行代码来探索世界、获取资源、制造工具,并将成功的技能存储为可复用的代码库。其"课程学习 + 技能库"的设计使得智能体能够在无人干预的情况下持续发展新能力——不断探索、学习和积累,而非停留在预设技能上。
GUI Agent 与 Embodied Agent 的共性与差异:
| 维度 | GUI Agent | Embodied Agent |
|---|---|---|
| 感知空间 | 2D 屏幕截图 | 3D 真实/虚拟世界 |
| 动作空间 | 离散(点击、输入、滑动) | 连续(力、位移、角度) |
| 反馈延迟 | 毫秒级(界面即时响应) | 秒级(物理执行需要时间) |
| 容错性 | 高(操作可撤销) | 低(物理操作不可逆) |
| 安全要求 | 中(数据安全) | 极高(人身安全) |
| 共同架构 | 感知-推理-执行循环 | 感知-推理-执行循环 |
两个领域的核心架构高度一致,但 Embodied Agent 面临更严峻的挑战:连续动作空间的控制精度、物理约束的满足、以及远高于 GUI 操作的安全性要求。这些挑战使得 Embodied Agent 目前仍主要在仿真环境中验证,距离大规模实际部署还有较大距离。
前沿动态 -- 学术界/工业界最新进展
端侧部署趋势。将GUI Agent模型部署在手机/PC端侧,避免隐私数据上传云端,同时降低延迟。这需要模型压缩和端侧推理芯片的配合发展。
多模态实时交互。Google Project Astra和Gemini Live展示了超越屏幕操作的愿景:Agent通过摄像头和麦克风"看见"和"听见"周围环境,在提供实时协助的同时进行自然对话。这将GUI Agent从"操作屏幕"扩展到"理解世界"。
强化学习优化操作策略。通过在模拟环境中大量练习,Agent可以学会更高效的操作策略。例如,学会"先滚动到底部查看全部选项再做选择"而不是"逐个检查每个选项"。
标准化评估基准。GUI Agent的评估标准正在建立:任务完成率、操作步骤效率、错误恢复能力、跨应用泛化能力等维度的标准化测试集正在形成。
⚠️ 已知局限:GUI Agent 面临三个结构性瓶颈阻碍其实用化。第一是视觉定位的脆弱性——当前最优模型在动态页面(含动画、弹窗、悬浮层)中的元素定位准确率下降 30-40%,广告弹窗和 Cookie 同意框等干扰元素是导致操作链中断的首要原因。第二是长链条任务的指数衰减——假设单步操作成功率为 90%,一个需要 10 步的任务端到端成功率仅为 (0.9)^10 = 34.9%,20 步任务更降至 12.2%,这解释了为何 WebArena 中的多步任务成功率远低于单步任务。第三是安全性的不可控——GUI Agent 直接操作用户界面,一次错误的"确认支付"或"删除文件"操作可能造成不可逆后果,而当前缺乏可靠的操作前安全验证机制(模型无法 100% 准确判断操作的风险等级)。
本章小结
GUI Agent代表了智能体与数字世界交互方式的根本性转变——从依赖API的"后门"访问,转向通过视觉理解的"前门"操作。感知-推理-执行三层架构提供了清晰的设计框架,纯视觉方案以其通用性和语义弹性成为主流方向。
然而,当前技术仍处于早期阶段。40-50%的实际成功率、高昂的推理成本、以及安全性隐患,意味着GUI Agent距离成为可靠的日常工具还有距离。短期内,混合方案(简单任务RPA+复杂任务AI)和人机协同设计(关键步骤人工确认)是更务实的部署策略。长期来看,随着视觉大模型的持续进步和端侧推理能力的提升,GUI Agent有望成为未来人机交互的重要范式。